Abstract
The increase in set-valued data such as transaction records and medical histories has introduced new challenges in data anonymization. Traditional anonymization techniques targeting structured microdata comprising single-attribute- rather than set-valued records are often insufficient to ensure privacy protection in complex datasets, particularly when re-identification attacks leverage partial background knowledge. To address these limitations, this study proposed the Local Generalization and Reallocation (LGR) + algorithm to replace the Normalized Certainty Penalty loss measure (hereafter, NCP) used in traditional LGR algorithms with the Information Gain Heuristic metric (hereafter, IGH). IGH, an entropy-based metric, evaluates information loss based on uncertainty and provides users with the advantage of balancing privacy protection and data utility. For instance, when IGH causes greater information-scale data annotation loss than NCP, it ensures stronger privacy protection for datasets that contain sensitive or high-risk information. Conversely, when IGH induces less information loss, it provides better data utility for less sensitive or low-risk datasets. The experimental results based on using the BMS-WebView-2 and BMS-POS datasets showed that the IGH-based LGR + algorithm caused up to 100 times greater information loss than NCP, indicating significantly improved privacy protection. Although the opposite case also exists, the use of IGH introduces the issue of increased computational complexity. Future research will focus on optimizing efficiency through parallel processing and sampling techniques. Ultimately, LGR+ provides the only viable solution for improving the balance between data utility and privacy protection, particularly in scenarios that prioritize strong privacy or utility guarantees.
1. Introduction
1.1. Necessity and Purpose of the Study
To protect information related to individual records, traditional data anonymization methods primarily focus on structured microdata. These records typically comprise attributes in the form of single numerical or textual values such as age or address. However, there is an increasing trend toward set-valued data, which include multiple items within a single record, such as purchase histories from large marketplaces or medical records. Set-valued data pose challenges for existing anonymization techniques because such datasets afford limited privacy protection and may be vulnerable to re-identification attacks, particularly when quasi-identifiers are involved. For instance, if a large marketplace discloses customers’ purchase histories, even if the k-anonymity model is applied, an attacker with background knowledge (e.g., knowing some of the items in the target’s shopping cart) could easily infer specific items purchased by the target. This demonstrates the need for additional anonymization techniques specifically designed for set-valued data.
This paper presents the Local Generalization and Reallocation (LGR) + algorithm, which addresses the anonymization challenges of set-valued transaction data. This algorithm incorporates the Information Gain Heuristic (IGH) metric to overcome the limitations of the traditional NCP (Normalized Certainty Penalty) loss measure. The entropy-based IGH metric enables a more precise evaluation of information loss and provides a better balance between privacy protection and data utility, particularly when dealing with sensitive data. In the following sections, we review various studies that have addressed set-valued data anonymization and discuss the strengths and limitations of the NCP metric.
1.2. Research Background
Data privacy models such as k-anonymity [1], l-diversity [2], and t-closeness [3] have been proposed for structured data anonymization. These models have been well documented in international standards such as ISO/IEC 20889 [4,5]. Significant research efforts have been made regarding the anonymization of set-valued microtransaction data, as summarized in Table 1 below.

Table 1.
Approaches that address the anonymization challenges in set-valued transaction data.
Recent studies have explored various methods for protecting privacy, including data anonymization through disassociation and local suppression [25,26,27,28,29,30,31,32,33,34] and evaluating big data anonymization in IoT environments [35,36]. Certain studies have focused on anonymizing electronic health records (EHR) [26,27] and improving horizontal partitioning algorithms [25,31]. Additionally, vertical partitioning algorithms for applying km-anonymity have been enhanced [33], and methods to prevent attribute disclosure risks in datasets with disassociated attribute links have been proposed [28,29,30]. Andrew et al. [34] proposed a fixed-interval approach and l-diversity slicing technique to protect sensitive medical data. Although several studies allow analysis using reconstructed datasets by disassociating cell links that contain set values, this process can be highly time-consuming [25]. In particular, some studies have introduced the lρ-suppression technique [37] to improve privacy protection in transactional datasets while maintaining data utility. Research that combines AI and machine learning to anonymize quasi-identifiers suggests the potential to achieve better privacy protection and data utility balance compared with existing techniques [38]. Other notable studies include data anonymization in edge-storage environments [39] and the protection of medical data using a cluster-based anonymity model [40]. Additionally, ARX tools have been utilized to minimize information loss in traditional k-anonymity-based anonymization [41], and new models have been proposed for the real-time anonymization of big data streams [42,43]. These studies aimed to prevent information leakage and minimize information loss in big-data-processing environments. Notably, studies on secure re-identification frameworks [44] and large-scale data anonymization using Spark distributed computing [45] have presented efficient privacy protection methods for modern big data environments. Furthermore, research on the performance evaluation and scalability of anonymization algorithms [46] continues to advance this field.
Several studies have addressed privacy issues and the linkage re-identification risks in complex networks. For instance, ref. [47] emphasizes the risks associated with re-identification through data matching and linkage, providing an important context for how the IGH metric proposed in this study can mitigate such risks. Furthermore, ref. [48] discusses the threat of privacy leakage due to de-anonymization in multiple social networks, illustrating how the IGH metric could potentially contribute to reducing these de-anonymization risks. Last, ref. [49] proposes a data-publishing algorithm utilizing connectivity-based outlier detection and Mondrian techniques, offering a valuable benchmark for comparative analysis with the IGH metric.
The anonymization problem must balance privacy protection with data utility. As anonymized data must still be useful for analysis, the balance between security and utility is crucial. Utility, which is associated with information loss, refers to the extent to which useful information is preserved. The lower the information loss, the higher the utility. These two aspects— privacy and utility—are always in a tradeoff relationship, and achieving a balance between them is critical. For set-valued microtransaction data, privacy is typically measured using probabilistic re-identification risks, similar to traditional structured data models such as k-anonymity, with a 1/k probability of re-identification. However, most algorithms proposed to measure the utility (as listed in Table 2), including [9,10,12,14,16,17,19,20,21,23,24], use the Normalized Certainty Penalty (NCP) metric [50,51]. NCP measures the extent of generalization or suppression applied to the anonymized data compared to its original state. Higher levels of generalization indicate a greater loss of information. Table 2 summarizes the strengths and weaknesses of the anonymization algorithms based on metrics.
Table 2.
Comparison of strengths and weaknesses of NCP-based anonymization algorithm strengths.
1.3. Contributions of This Study
This paper presents the LGR + algorithm, which addresses the anonymization challenges of set-valued transaction data, and makes several major research contributions. The LGR+ algorithm replaces the traditional loss measure based on NCP used in the LGR algorithm with the IGH [52,53,54] metric. The IGH metric is entropy-based and allows for a more precise evaluation of information loss, thereby better balancing data utility and privacy protection. The LGR+ algorithm addresses the limitations of the NCP-based approach by enhancing privacy protection through the entropy-based evaluation of information loss. Using IGH also offers researchers more flexibility in balancing privacy and utility because it reflects both the distribution and the significance of the data.
The traditional NCP-based approach is simple and computationally fast, but has limitations in reflecting the meaning of data or considering the importance of attributes. In particular, this approach fails to capture data uncertainty and distribution adequately, which can result in limited protection for sensitive data. This study points out these limitations in existing research and emphasizes how the IGH metric contributes to addressing this issue. By utilizing entropy to assess information loss, IGH reflects data uncertainty and distribution, enabling a more precise and meaningful evaluation of information loss. This allows for strong privacy protection for sensitive information while preserving data utility. The study highlights the limitations of existing research by comparing the strengths and weaknesses of NCP and IGH, emphasizing the accuracy of information loss evaluation using IGH. Hereby, researchers can enhance their understanding of information loss assessment methods and reinforce the significance of their research findings.
The experimental evaluation used the BMS-WebView-2 and BMS-POS datasets [55]. BMS-WebView-2 comprises 77,512 records of clickstream data from an e-commerce website containing 3340 items, whereas BMS-POS contains 515,597 records of electronic retail transaction logs representing 1657 items. These datasets were used to compare the performance of the LGR+ algorithm with that of the traditional NCP-based LGR algorithm. This study employed an experimental approach to evaluate the proposed LGR+ algorithm’s performance. The levels of information loss and privacy protection were measured for different k-anonymity values. To compare with the NCP, normalized differences were calculated to assess the relative information loss between the two algorithms. In conclusion, this study provided a novel approach for enhancing the balance between data utility and privacy protection, particularly for the secure use of sensitive datasets. The proposed LGR+ algorithm offers a practical and effective solution for improving privacy protection while maintaining data utility, thereby addressing significant challenges in data anonymization.
Section 2 of this paper defines the existing NCP metric and the newly proposed IGH metric and provides examples, followed by a comparison of their strengths and weaknesses. Thereafter, we propose a metric that is more suitable for specific applications. Chapter 3 presents and analyzes the results of experiments using the same datasets from [24], comparing the average information loss values of NCP and IGH as measured by applying the LGR+ algorithm, where IGH replaces NCP. Section 4 concludes the paper.
2. The NCP and IGH Metrics
This section introduces the definitions and differences between the traditional NCP information loss measurement method and the proposed IGH metric. Both measure the information loss that occurs during data anonymization. NCP focuses primarily on the generalized data range, whereas IGH evaluates the loss based on entropy, which reflects the uncertainty of the information. In this section, we present the definitions and calculation methods of both metrics and explain, using concrete examples, how they assess information loss differently in actual datasets.
2.1. NCP Metric
The NCP metric evaluates information loss based on the level of generalization of specific attributes. It was first introduced in [54] and subsequently used in various algorithms [6,7,8,9,10,11,12,13,14,15,16,17,18,19,23,24,35,36]. It is defined as the proportion of generalized items to the total data items, with higher generalization resulting in greater information loss. For example, if the original value “Seoul” is generalized to “South Korea”, information loss occurs within the group containing that value because the specific information necessary for data analysis is lost. NCP is calculated by defining the ratio of generalized items relative to the total |I|, where p represents an item in I, and |up| represents the number of nodes below the generalized node when p is generalized (i.e., nodes at the same level as p). This is defined as follows:
When the total occurrence of item p in database D is denoted as Cp, the overall information loss NCP(D) in dataset D is defined as follows:

Figure 1.
Example of NCP-based anonymization for the original dataset (when {a1, a2} are generalized to A).
When {a1, a2} are generalized to A, and the information loss is 2.5/11 (=20.5 + 30.5 + 0 + 0/11). In Figure 1a, there are two occurrences of a1, three of a2, three of b1, and three of b2. Therefore, the total Cp is 11. Additionally, the NCP values were 2/4, 2/4, 0, and 0 because b1 and b2 were not generalized, resulting in an NCP of 0.
However, NCP is limited by only evaluating the extent of range expansion without reflecting the actual distribution or importance of the data. For example, even if sensitive information is generalized, its significance is not considered, which could limit the assessment of critical information loss.
2.2. The IGH Metric
The IGH metric [37,38,39] evaluates information loss based on entropy, which represents uncertainty in the data, with higher values indicating greater uncertainty. IGH assesses the extent to which a particular attribute reduces the uncertainty of the data and allows information loss in generalized data to be measured more precisely. First, the entropy metric measures the uncertainty in the data, where higher entropy values indicate greater uncertainty and lower values indicate less uncertainty. When P(xi) is the probability of item xi in dataset D, the entropy H(D) is calculated as follows:
Next, given a specific attribute, the conditional entropy H(D|A) measures the uncertainty of the data. Here, P(Aj) is the probability of value Aj for attribute A, and H(D|A) represents the entropy when attribute A takes value Aj. The conditional entropy H(D|A) is calculated as follows:
Finally, IGH indicates the extent to which the entropy of the data is reduced when a specific attribute A is given. It evaluates the extent to which an attribute contributes to reducing data uncertainty and is calculated as follows:
For example, if two values, ‘apple’ and ‘banana’, are generalized to ‘fruit,’ the uncertainty within this category is reduced. This is because an attacker would only know the generalized category ‘fruit,’ making it difficult to infer specific values. In this manner, IGH calculates the extent to which the generalized data reduce the uncertainty of the original data, thereby evaluating the information loss. Additionally, the entropy decreasing from 0.9 to 0.4 indicates that the information loss is minimal and privacy protection has been significantly strengthened. Unlike NCP, the IGH method can reflect the data distribution and importance of the information.
2.3. Comparison Between NCP and the Proposed IGH Metric
For example, as shown in Table 3, when comparing the information loss between NCP and IGH applied to five transaction datasets, the former simply calculates the information loss based on the range expansion of each attribute, whereas the latter calculates the information loss more precisely by considering the data distribution and entropy. Consequently, NCP and IGH, respectively, record information losses of 3.8 and 2.3, demonstrating that IGH better preserves data utility through a more detailed information loss evaluation. In Table 3, the frequencies of each item were a1 (five occurrences), a2 (four occurrences), b1 (two occurrences), and b2 (two occurrences). Thus, the probabilities for each item were . The entropy of the entire dataset was calculated as follows:
Table 3.
Comparison of information loss values between NCP- and IGH-based anonymization (2-Anonymity) in transaction datasets.
Next, the information loss for each transaction was calculated as follows: For T1–T3, the original and generalized entropies were the same, resulting in a difference of 0. For T4 and T5, the original entropies were:
and the generalized entropy was:
resulting in an information loss of 0.667 (1.585–0.918).
For T6, the original entropy was:
and the generalized entropy was 0, resulting in an information loss of 1 (=1-0).
Therefore, the total information loss using the IGH method was 2.334 (=0 + 0 + 0 + 0.667 + 0.667 + 1).
Conversely, the information loss using the NCP method was calculated as follows:
T1 is 1.0 (=1/1), T2 is 0.5 (=1/2), T3 is 0.5 (=1/2), T4 is 0.6667 (=2/3), T5 is 0.6667 (=2/3), and T6 is 0.5 (=1/2).
Therefore, the total information loss using the NCP method was:
3.8334 (=1.0 + 0.5 + 0.5 + 0.6667 + 0.6667 + 0.5)
Table 3 highlights the distinct differences in how NCP and IGH measure information loss, reflecting the strengths and weaknesses of each approach. The simplicity of the NCP method, which calculates the information loss based on the range generalization of each attribute, has the advantage of low computational complexity. However, this simplification often fails to capture the actual impact on data utility, particularly when important data attributes are generalized without considering their significance. By contrast, the IGH method provides a more detailed approach. By utilizing entropy, IGH considers both generalization and the inherent uncertainty and distribution of the data. For example, although the results for T4 and T5 show similar values for both IGH and NCP, the IGH approach evaluates information loss more precisely, offering better insights into how data utility is preserved. This is particularly evident because IGH-based anonymization induces a lower total information loss (2.334), whereas NCP records a higher total information loss (3.8334).
This comparison is elucidated in more detail in Table 4, explaining how the two metrics play complementary roles in optimizing privacy protection and data utility. Specifically, NCP focuses on simple range expansion, allowing for low computational complexity and fast evaluation, but is limited by not reflecting the meaning or distribution of the data. Conversely, being based on entropy, IGH evaluates data uncertainty and importance, enabling information loss to be measured more precisely. This demonstrates that IGH can contribute to preserving data utility more effectively and goes beyond simple information loss assessment by considering the distribution of the data and the relative importance of attributes.
Table 4.
Comparison of strengths and weaknesses: NCP and the proposed IGH metric (+ represents strengths, and − represents weaknesses).
Although the examples in Table 3 show that, compared with NCP, the IGH value results in 1.5 times less information loss, in some cases, the IGH value is even greater. This is because IGH provides a more detailed assessment by reflecting the meaning, uncertainty (entropy), and data distribution compared to NCP. Therefore, if IGH induces a higher information loss, it implies that privacy has been strengthened through a more refined evaluation, whereas a lower value indicates that data utility has improved. However, data anonymization requires a balance between privacy and utility, as these two factors are in a tradeoff relationship and ultimately demand a choice. This is illustrated in Table 4 and Table 5.
Table 5.
Considerations when using the IGH metric.
Table 4 compares the strengths and weaknesses of the NCP and proposed IGH metrics. Both NCP and IGH measure information loss in data anonymization, but their methods and purposes differ significantly. NCP calculates the information loss based on the range of data generalization, and the calculation process is simple and intuitive. However, it fails to reflect the loss of important information and does not consider data distribution. By contrast, IGH evaluates data uncertainty using entropy, considering both the importance and distribution of data to measure information loss more precisely.
When using the IGH metric, as shown in Table 5, certain factors, such as the characteristics and purpose of the data, must be considered. Setting thresholds for the measurement results is crucial in balancing data protection and utility, considering the data’s sensitivity, legal obligations, and intended use. If data utility is important or the amount of sensitive information is relatively low, a low IGH value (e.g., 0 <= IGH <= 1) should be chosen as the threshold. In cases where a balance between privacy protection and data utility is required, a moderate IGH value (e.g., 1 <= IGH <= 5) is appropriate. Conversely, if privacy protection is the top priority, particularly in high-risk data leakage scenarios, a relatively high IGH value (e.g., IGH > 5) should be set.
We next examine how the NCP and IGH metrics are applied to the proposed LGR+ algorithm and its experimental results.
3. The Proposed LGR+ Algorithm (Micro-Transaction Data Anonymization Using the IGH Metric)
We previously proposed a new LGR algorithm that maintains the same level of privacy protection as existing methods, e.g., k-anonymity (local generalization) [11] and HgH [13], while exhibiting the least amount of NCP information loss [24]. This section introduces our LGR algorithm and then presents the differences and advantages of the improved algorithm based on IGH as an information loss metric, replacing the previously used NCP.
3.1. Existing LGR Algorithm
The existing LGR algorithm [24] for anonymizing transaction data comprises the following steps:
[STEP 1] Anonymize(partition): Begin partitioning the transaction data to satisfy k-anonymity. This initial procedure constructs a generalization tree and partitions the transaction items. Next, the Pick_node() function is used to select the first partition, which then expands to the lower nodes. Each transaction is assigned to an expanded partition, and the Distribute_data() procedure processes the partitioned transactions. The Balance_partition() routine ensures that the partitions are balanced and checks whether k-anonymity is satisfied. If k-anonymity is met, the transactions move to Final_partition(); otherwise, a rollback occurs, and the Expand_node() procedure is called again.
[STEP 2] Pick_node() and Expand_node(): The optimal node is sequentially selected from the partition. In Expand_node(), the selected partition is expanded to the lower nodes in the tree structure. To minimize information loss during transaction distribution, the NCP values are calculated in order to choose the node that causes the least information loss among the expanded partitions.
[STEP 3] Distribute_data() and Balance_partition(): Transactions are distributed to the partitions, maintaining a balance between them. In Distribute_ Data (), transactions are assigned to each expanded partition. Balance_partition() checks whether each partition satisfies k-anonymity. Otherwise, transactions are stored in a waiting queue.
[STEP 4] WaitForQ_data() and FinalQ_data: Partitions not satisfying k-anonymity are stored in a waiting queue (WFQ), and transactions that satisfy k-anonymity are ultimately saved in FinalQ. In WaitForQ_data(), the partitions and transactions not satisfying k-anonymity are stored in WFQ, whereas FinalQ_data stores those that do.
[STEP 5] Final_partition(): The transactions and partitions not satisfying k-anonymity are reassigned via an upward search. We explore the remaining partitions in the waiting queue (WFQ) and match them with the partitions in FinalQ. If a matched partition satisfies k-anonymity, it moves to FinalQ; otherwise, the generalization occurs upward until k-anonymity is satisfied. Reallocation starts with the partition with the least information loss (NCP).
[STEP 6] Results Publication: After assigning all transactions to the partitions, transactions that satisfy k-anonymity are published. Once all the transactions in the waiting queue are processed, the transactions in FinalQ are publicly released, and the algorithm concludes.
3.2. Proposed LGR+ Algorithm
The proposed LGR+ algorithm’s overall flow is identical to that of the original algorithm, with the main difference being that IGH instead of NCP is used as the information loss metric. Algorithm 1 shows the proposed LGR+ algorithm’s pseudocode, and the key differences between the proposed IGH-based LGR+ algorithm and the existing NCP-based LGR algorithm are given in Table 6:
Table 6.
Comparison of differences between the existing LGR algorithm [24] and the proposed LGR+.
Information Loss Calculation Scheme: NCP evaluates information loss based on range expansion, whereas IGH measures information loss by assessing data uncertainty using entropy.
Transaction Assignment Criteria: NCP aims to minimize the loss due to range expansion within each partition, whereas IGH assigns transactions in a way that minimizes uncertainty.
Upward Rollback Process: In the upward rollback process, NCP considers losses due to range expansion, whereas IGH reduces information loss by minimizing probabilistic information loss (entropy). Thus, replacing NCP with IGH shifts the information loss evaluation criterion of the LGR algorithm to a more sophisticated entropy-based assessment.
| Algorithm 1. Pseudocode of our proposed LGR+ Algorithm. |
| 1. Algorithm LGR+_Algorithm(Partition, IGH_metric): List of Partitions 2. Input: 3. Partition—The initial data partition to be processed. 4. IGH_metric—The entropy-based metric used for evaluating information loss and guiding partitioning decisions. 5. Output: 6. List of Partitions—The resulting partitions after the anonymization process, where each partition satisfies k-anonymity. 7. Steps: 8. if (no further drill down possible for Partition) then // If no further drill-down is possible for the given partition 9. return and add Partition to the global list of returned partitions // Return the partition and add it to the global list 10. else 11. expandedNode <- pickNode(Partition, IGH_metric) // Pick a node from the partition based on the IGH metric 12. for each transaction in Partition do 13. resultPartitions <- distributeData(transaction, expandedNode, IGH_metric) // Distribute the data to the expanded nodes with IGH metric consideration 14. end for 15. balancePartitions(resultPartitions, IGH_metric) // Balance the partitions to ensure k-anonymity and minimize entropy-based information loss 16. for each transaction in resultPartitions do 17. WFQ <- addToWaitForQueue(transaction, resultPartitions) // Add to waiting queue if k-anonymity is not satisfied 18. FinalQ <- addToFinalQueue(transaction, resultPartitions) // Add to the final queue if k-anonymity is satisfied 19. end for 20. for each subPartition in resultPartitions do 21. LGR+_Algorithm(subPartition, IGH_metric) // Recursively anonymize the sub-partition 22. end for 23. end if 24. Final_partition(WFQ, FinalQ, IGH_metric) // Final reallocation of transactions in the waiting queue and publish results once k-anonymity is achieved |
Our LGR+ algorithm primarily uses IGH to evaluate information loss. IGH is entropy-based and calculates loss by considering data uncertainty, reflecting the inherent distribution and significance of the data. This algorithm assigns transactions to partitions and maintains balanced partitions to satisfy k-anonymity. By providing a more precise evaluation of information loss than the traditional NCP-based method, the proposed LGR+ algorithm achieves a better balance between privacy protection and data utility. Using the IGH allows the evaluation of information loss to reflect the meaning and uncertainty of data, providing stronger privacy protection for more sensitive datasets.
3.3. Algorithm Analysis and Experimental Results
The most significant difference between the LGR and LGR+ algorithms is the method used to measure information loss. Based on NCP, the LGR algorithm supports relatively simple and fast calculations for data range expansion, whereas the LGR+ algorithm requires more complex computations owing to the inclusion of entropy calculations based on IGH. In particular, the computational complexity of IGH can significantly affect processing time when dealing with large datasets.
The next section compares the time complexities of the two algorithms and proposes optimization strategies to address this issue.
3.3.1. Time Complexity of the LGR Algorithm
In the LGR algorithm, information loss calculated using the NCP metric depends primarily on each transaction’s generalization range. The specific steps for computing the time complexity are: (a) exploration of the transaction dataset: The main task of the LGR algorithm is to explore the transaction dataset. Let n be the number of transactions and h be the height of the generalization tree. Each transaction is processed to determine the appropriate partition and proceeds recursively to the depth of the tree. (b) Generalization range calculation: During exploration, the information loss is calculated based on the extent to which each item’s attributes in the transaction are generalized to satisfy k-anonymity. Thus, the generalization range expansion is calculated at each level and repeated until a leaf node is reached or k-anonymity is satisfied. (c) Time complexity calculation: When calculating information loss using the NCP metric, the worst-case time complexity occurs when each transaction processes all the levels of the tree. Since n transactions are processed through h levels, the time complexity is given by , where n is the number of transactions and h is the height of the generalization tree.
3.3.2. Time Complexity of the LGR+ Algorithm
The LGR+ algorithm increases the complexity compared to the existing LGR algorithm by adding the entropy calculation. The specific steps for computing the time complexity are as follows: (a) Entropy calculation for each transaction: In addition to exploring the dataset, the LGR+ algorithm calculates the entropy for each transaction. It is based on the distribution and frequency of items, represented by for item , and involves logarithmic operations, denoted as . Entropy is calculated by traversing the dataset to evaluate each partition’s uncertainty using the IGH metric. (b) Recursive processing through tree levels: Similarly to the LGR algorithm, the LGR+ algorithm processes each transaction recursively through the levels of the generalization tree, but with the added entropy calculation. However, the depth of the recursive exploration remains h. (c) Time complexity calculation: In the LGR+ algorithm, the computational complexity of each transaction includes both tree traversal and entropy calculations. Thus, complexity is given by , where n is the number of transactions, h is the height of the generalization tree, and represents the complexity of the logarithmic operations involved in the entropy calculation. This logarithmic operation reflects the complexity of the entropy calculation, increasing the overall computational cost compared with the LGR algorithm. This time complexity represents the worst-case scenario, in which each transaction is recursively processed through all levels of the tree and the entropy is calculated for each item in the transaction.
3.3.3. Optimization Strategies for Time Complexity
The IGH-based LGR+ algorithm offers a more precise evaluation of information loss than the NCP-based algorithm, but has higher computational complexity, leading to increased processing time for large datasets. To address this, the following optimization strategies can be introduced:
(a) Parallel Processing: Parallel processing distributes the entropy calculations across multiple processors, reducing the overall processing time. When optimized, computational complexity can be reduced to , where n is the number of transactions, h is the height of the generalization tree, and p is the number of processors.
(b) Sampling Techniques: By calculating entropy using only a portion of the dataset, the computational load can be reduced. For example, using a 10% sample of the data can decrease overall computational complexity from to .
(c) Data Structure Optimization: Utilizing efficient data structures (e.g., B-trees, hash tables) can improve data retrieval and entropy calculation speeds, thus reducing the time complexity. Implementing such structures can boost data access and calculation efficiency, improving algorithm performance.
(d) Approximation Methods: Approximation methods can simplify calculations, thus reducing time complexity. This approach can further lower computational costs and improve performance in real-time processing.
(e) Memory Optimization: Dynamic memory allocation and caching strategies can reduce memory usage during entropy calculations, improving the time complexity. These strategies help alleviate memory bottlenecks and maintain efficiency depending on the dataset size.
These optimization strategies enhance the computational efficiency of the IGH-based LGR+ algorithm, particularly for large datasets, making real-time processing more feasible.
3.3.4. Performance Comparison of LGR and LGR+ Algorithms: Analysis of Information Loss and Data Utility
In this study, we compared the performance of the traditional LGR algorithm and the IGH-based LGR+ algorithm using the BMS-POS and BMS-WebView-2 datasets [24,55], which were also utilized in previous experiments for the original LGR [24]. The BMS-POS dataset consists of 515,597 electronic retail transaction logs containing up to 1657 items, with each record potentially including up to 164 items. Each item is represented by a four-digit product code purchased by customers, ranging from 0 to 1404. For example, if the product code is ‘1302’, the major category is ‘1’, the subcategory is ‘3’, the minor category is ‘0’, and the detailed category is ‘2’. Based on this structure, we constructed a generalization tree with a maximum depth of 5. The experiment was conducted using the 345,204 data points remaining after data preprocessing and cleaning, which involved correcting data errors and removing unnecessary or inconsistent records.
The BMS-WebView-2 dataset includes 77,512 records, representing up to 3340 items. This dataset comprises clickstream data collected over several months from an e-commerce website. Similar to the BMS-POS dataset, product codes ranging from 55,267 to 330,285 represent individual items purchased. Based on this structure, a generalization tree with a maximum depth of 7 was constructed, and each record could contain up to 161 items. This tree was designed to accommodate various levels of generalization, enabling the effective classification of complex set-valued data.
The main specifications of the experimental data are summarized in Table 7, and Table 8 shows a sample of the data used in the experiments, where each item is delimited by the ‘|’ symbol.
Table 7.
Main specifications of the data used in the experiments.
Table 8.
Sample of original data used in the experiments.
To implement the LGR and LGR+ algorithms, we used Python along with the pandas library for reading and processing the CSV files. The generalization tree, which is a core data structure for both algorithms, was defined and constructed to support the hierarchical generalization of data attributes. This tree structure was implemented to allow multiple child nodes to be connected to a parent node, thereby supporting flexible and precise data generalization processes. The data were input and partitioned using this tree, with the transaction data stored in the generalization tree class for efficient processing.
The LGR+ algorithm employed an additional entropy calculation to evaluate information loss, analyzing the distribution and frequency of items within the generalization tree class to compute entropy effectively. This allowed the IGH-based algorithm to consider data uncertainty and distribution during the anonymization process. Additionally, the LGR+ algorithm introduced a recursive rollback process, generalizing data to higher nodes when k-anonymity was not met, ensuring compliance with privacy constraints.
The experiments were conducted on a Windows 10 system equipped with a 12th Gen Intel(R) Core(TM) i9-12900KS 3.40 GHz PC and 64 GB of memory. The k-anonymity values were set to 3, 5, 10, 25, and 50, and the average NCP and IGH values for each dataset were measured and compared. The experimental results are summarized in Table 9 and illustrated in Figure 2.
Table 9.
Experimental results: comparison of average NCP, IGH values, and their normalized differences.
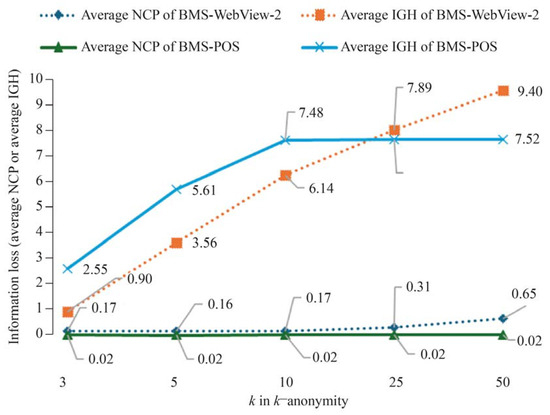
Figure 2.
Comparison of information loss between the BMS-WebView-2 and BMS-POS datasets using the NCP and IGH metrics under different k-anonymity values.
Figure 2 compares the BMS-WebView-2 and BMS-POS datasets using different metrics (NCP and IGH) under varying k-anonymity values. The y-axis represents “information loss”, measured as either an average NCP or average IGH value. NCP measures information loss based on range generalization, whereas IGH evaluates information considering data uncertainty (entropy). The dashed lines represent the average NCP and IGH values for BMS-WebView-2, providing a clear distinction from the values corresponding to the BMS-POS data. The metrics were derived by calculating the loss for each anonymized transaction, with higher values indicating greater generalization and potentially lower utility.
(a) Analysis of Information Loss and Data Utility: As described in Section 2.1, NCP measured information loss based on the range of generalization and showed relatively low values across both datasets. Figure 2 compares information loss for the BMS-WebView-2 and BMS-POS datasets under varying k-anonymity values. Specifically, the NCP value for the BMS-POS dataset was <0.02, indicating minimal information loss. Conversely, IGH generally resulted in higher information loss. For example, in the BMS-POS dataset at k = 3, the IGH value was 2.55, approximately 100 times higher than the NCP value of 0.02. This suggests that while IGH enhances the protection of sensitive data, it may reduce data utility.
(b) Impact of Information Loss on Data Utility: Higher information loss can generalize data characteristics, limiting the accuracy and insights arising from analysis. For instance, when analyzing customer purchase patterns to develop targeted marketing strategies, substantial information loss can reduce the reliability of the analysis. Conversely, lower information loss retains more specific data, enhancing the utility of subsequent analyses but potentially compromising privacy. The normalized differences shown in Table 7 highlight the variance in information loss between NCP and IGH. Specifically, at k = 3 for the BMS-POS dataset, the normalized difference was 0.9924, confirming that IGH induced significantly higher information loss than NCP. This indicates that, while IGH is effective for scenarios requiring robust privacy protection, it may limit utility in data analysis.
(c) Scenario-Based Analysis of Information Loss: The impact of information loss on data utility can vary depending on the analytical scenario. For instance, in real-time financial data analysis, where quick processing and utility are paramount, the NCP-based approach with lower information loss may be more suitable. In contrast, for scenarios prioritizing privacy, such as medical data or sensitive personal information, the IGH-based LGR+ algorithm may be more effective in safeguarding sensitive data.
As such, while IGH provides strong privacy protection with higher information loss, its effect on data utility must be strategically considered based on the analytical objective and the scenario. Ultimately, the choice between IGH and NCP should be made by comprehensively reviewing the data’s sensitivity, analysis goals, and legal requirements.
4. Discussion
This study compared the LGR+ algorithm using the IGH metric with the traditional NCP-based LGR algorithm to analyze the differences in information loss and privacy protection. The experimental results clearly demonstrate how IGH improves the balance between data utility and privacy protection. Furthermore, in this section, we discuss the advantages and disadvantages of LGR+ compared to other metrics, the impact of information loss on data utility, various optimization strategies, and the observed variations in information loss among the metrics from the experiments.
4.1. Research Contributions and Significance
This paper introduces the entropy-based IGH metric to address the limitations of NCP, which fails to account adequately for data uncertainty and distribution, as identified in previous studies. For instance, prior research [6,7,8,14] has emphasized that methods such as km-anonymity and global suppression can only provide limited data protection. In contrast, IGH enhances privacy protection for sensitive data by evaluating data uncertainty more effectively. This approach expands upon the issues discussed in previous studies and enables stronger privacy protection, particularly for sensitive datasets.
The main contribution of this study lies in identifying the limitations of NCP-based methods and demonstrating that an IGH-based approach can improve the balance between data utility and privacy protection by more precisely evaluating data uncertainty and importance. IGH measures information loss by considering the inherent data distribution and entropy rather than relying solely on range expansion. This characteristic allows for a more accurate reflection of the information’s significance and utility, providing a robust foundation for researchers to effectively employ IGH in privacy protection strategies.
As presented in Table 4 of Section 2.3, this study highlights the limitations of existing research by comparing NCP and IGH and underscores the precision of information loss assessment when using IGH. This enhances the understanding of information loss evaluation methods and strengthens the significance of the study’s findings. The IGH-based LGR+ algorithm, which was experimentally validated under various k-anonymity levels, demonstrated its ability to provide stronger privacy protection for sensitive datasets compared to the traditional NCP-based methods.
Moreover, this study addresses the shortcomings of NCP-based methods, which maintain data utility but fail to adequately reflect significant information loss [9,23,24]. By incorporating entropy, IGH more accurately reflects data distribution and uncertainty, thus enhancing the precision of information loss assessment and filling gaps in existing research. This contribution marks a significant advancement in data anonymization and privacy protection, assisting researchers in understanding and applying more sophisticated information loss evaluation methods.
4.2. The Comparative Analysis of LGR+ and Other Entropy-Based Metrics
The IGH-based LGR+ algorithm is described in terms of its differences from the traditional NCP-based approach concerning information loss, data utility, computational complexity, and privacy protection levels. To highlight the strengths and limitations of LGR+, this analysis particularly focuses on comparing LGR+ with other entropy-based metrics, such as Shannon entropy and conditional entropy. The comparative performance analysis is summarized in Table 10.
Table 10.
Comparative performance analysis of LGR+ and other entropy-based metrics.
The LGR+ algorithm using the IGH metric evaluates information loss based on entropy, which accurately reflects data uncertainty and distribution. While LGR+ results in higher information loss, it is more precisely assessed using entropy calculations. This increased information loss enhances sensitive data protection but comes at the cost of greater computational complexity, necessitating optimization strategies for real-time data processing. The data utility of LGR+ varies depending on the application and analysis objectives, making it particularly effective for scenarios where privacy protection is paramount.
Shannon entropy [56,57] is an efficient metric known for evaluating the information content of data. It generally results in moderate information loss and high data utility. The computational complexity is relatively low, making it effective even for large datasets. Shannon entropy is widely used in various data analysis applications due to its simplicity, which makes it suitable for real-time processing. However, its level of privacy protection is lower compared to LGR+, which may make it less effective in protecting sensitive data.
Conditional entropy [58,59] measures the information loss given specific attributes, maintaining high data utility with relatively low computational complexity, which is ideal for real-time processing. However, its privacy protection level is lower compared to LGR+, making it more suitable for scenarios where privacy protection is not a priority. Conditional entropy can be advantageous in applications where analyzing the relationships between data attributes is essential.
In conclusion, while LGR+ incurs higher information loss, it is highly beneficial in situations where protecting sensitive data is crucial. The IGH-based evaluation more precisely reflects data uncertainty and importance, providing robust privacy protection, especially for sensitive datasets. However, the increased computational complexity may hinder performance in real-time data processing, necessitating optimization strategies. Conversely, Shannon entropy and conditional entropy provide lower computational complexity and higher data utility, making them more suitable for real-time analysis and data use, although their privacy protection levels are more limited.
4.3. Information Loss and Privacy Protection
Experiments using the BMS-WebView-2 and BMS-POS datasets showed that the IGH-based LGR+ algorithm tended to cause greater information loss than the NCP-based algorithm. IGH allows for a more precise evaluation of information loss by assessing data uncertainty through entropy, thereby enhancing privacy protection. For example, on the BMS-POS dataset with k = 3, IGH recorded approximately 100 times more information loss than NCP, indicating a higher level of privacy protection. Conversely, NCP maintained lower information loss and preserved data utility better.
These results suggest that IGH provides stronger privacy protection for datasets that contain sensitive information. High information loss implies more generalized data, making it more difficult for an attacker to infer specific personal information. Conversely, lower information loss indicates that more specific information is retained, ensuring higher utility for subsequent data analysis.
4.4. Balancing Data Utility and Privacy Protection
In this study, IGH and NCP exhibited contrasting performances regarding privacy protection and data utility. IGH enhances privacy protection by providing a more detailed measurement of information loss, although it can also reduce utility. While maintaining relatively low information loss, NCP exhibited a weaker privacy protection performance than IGH. This highlights the importance of balancing privacy and utility in data anonymization and selecting an appropriate metric based on data characteristics and purposes.
For example, when privacy is prioritized for sensitive information, IGH may be more suitable. In contrast, when maintaining utility for data analysis, NCP could be a better choice. Thus, the choice between IGH and NCP should comprehensively consider factors such as data sensitivity, analytical purpose, and legal requirements.
4.5. Computational Complexity and Optimization Strategies
The high computational complexity of the IGH-based LGR+ algorithm can impact performance in real-time applications. While IGH’s entropy-based approach accurately evaluates data uncertainty and distribution, it can reduce processing efficiency due to its complex calculations. To address this, various optimization strategies, including parallel processing and sampling techniques, are proposed in Section 3.3.3. This section discusses additional measures to enhance the algorithm’s applicability in real-time scenarios:
(a) Impact on Real-Time Applications: The computational load of the IGH-based LGR+ algorithm can affect response times in real-time data processing. The complexity of entropy calculations can be particularly challenging for large datasets, requiring additional optimization to ensure real-time performance. Effective memory management and caching strategies are crucial for maintaining speed and efficiency. The pre-computation and caching of frequently used entropy values can reduce repetitive calculations and improve processing speed, significantly enhancing real-time responsiveness.
(b) Dynamic Algorithm Adjustment: Another approach is to dynamically adjust the algorithm’s complexity based on data characteristics and analysis goals during real-time processing. Adjusting the precision of entropy calculations as needed can optimize processing speed and performance, balancing speed and accuracy in real-time analysis.
(c) Lightweight Approximation Methods: Approximation methods can simplify entropy calculations, helping to maintain real-time processing performance. These techniques reduce computational complexity while ensuring the adequate accuracy of information loss, making them beneficial for real-time applications.
(d) Entropy Calculation Optimization: Minimizing unnecessary operations or improving the mathematical processes involved in entropy calculations can boost processing speed. Such optimizations are vital for reducing computational overhead and maintaining performance in real-time scenarios.
When applying the IGH-based LGR+ algorithm in real-time applications, high computational complexity can pose challenges. However, employing techniques such as memory management, caching, dynamic algorithm adjustment, and approximation methods can effectively address these issues. This enables the IGH-based LGR+ algorithm to maintain strong privacy protection and efficiency in real-time environments.
4.6. Limitations of the Study
Although this study demonstrates the effectiveness of IGH in enhancing privacy protection, further validation with diverse datasets is required to generalize the findings. Additionally, the effectiveness of optimization techniques to address the computational complexity of IGH should be further explored.
5. Conclusions
This study proposed a novel LGR+ algorithm incorporating the information gain heuristic (IGH) to address the limitations of normalized certainty penalty (NCP)-based methods in anonymizing set-valued transaction data. By providing a more precise assessment of data uncertainty, this algorithm improves the balance between privacy protection and data utility.
The primary goal is to overcome NCP’s limitations in evaluating information loss through simple range expansion and to propose a more sophisticated method that better protects sensitive data. The experimental results show that the IGH-based LGR+ algorithm offers stronger privacy protection for sensitive datasets, essential in sectors like e-commerce, finance, and healthcare.
The findings demonstrate that IGH more accurately reflects the data distribution and uncertainty, enhancing privacy protection compared to NCP. However, the increased computational complexity poses efficiency challenges for large datasets.
Future research will focus on improving the computational efficiency of the LGR+ algorithm through parallel processing and sampling techniques to enable real-time processing. Additionally, integrating other privacy models, such as l-diversity and t-closeness, will be explored to meet diverse privacy requirements.
Funding
This work was supported by a Korea Internet Security Agency (KISA) grant funded by the Korean government (PIPC) (No. 1781000005, Development of personal information pseudonymization and anonymization processing technology in semi-structured transactions and real-time collected structured data) and the Innovative Human Resource Development for Local Intellectualization program through the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (IITP-2024-RS-2023-00260267).
Data Availability Statement
The data presented in this study are openly available in the KDD Cup 2000 domain at https://kdd.org/kdd-cup/view/kdd-cup-2000 (accessed on 30 November 2024).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in designing the study; collecting, analyzing, or interpreting the data; writing the manuscript; or deciding to publish the results.
References
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkitasubramaniam, M. l-Diversity: Privacy beyond k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering 2006, Atlanta, GA, USA, 3–7 April 2006. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 15–20 April 2007; pp. 106–115. [Google Scholar] [CrossRef]
- ISO/IEC 20889:2018; Privacy Enhancing Data De-Identification Terminology and Classification of Techniques. International Organisation for Standardisation: Geneva, Switzerland, 2018.
- Cunha, M.; Mendes, R.; Vilela, J.P. A Survey of Privacy-Preserving Mechanisms for Heterogeneous Data Types. Comput. Sci. Rev. 2021, 41, 100403. [Google Scholar] [CrossRef]
- Terrovitis, M.; Mamoulis, N.; Kalnis, P. Privacy Preserving Anonymization of Set-Valued Data. In Proceedings of the VLDB En-dowment, Auckland, New Zealand, 24–30 August 2008; pp. 115–125. [Google Scholar]
- Terrovitis, M.; Liagouris, J.; Mamoulis, N.; Skiadopoulos, S. Privacy Preservation by Disassociation. In Proceedings of the VLDB Endowment, Istanbul, Turkey, 27–31 August 2012; pp. 944–955. [Google Scholar]
- Terrovitis, M.; Tsitsigkos, D. Amnesia, Institute for the Management of Information Systems. Available online: https://amnesia.openaire.eu/ (accessed on 29 May 2024).
- Xu, Y.; Fung, B.C.M.; Wang, K.; Fu, A.W.C.; Pei, J. Publishing Sensitive Transactions for Itemset Utility. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, K.; Fu, A.W.; Yu, P.S. Anonymizing Transaction Databases for Publication. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’08), Las Vegas, NV, USA, 24–27 August 2008; pp. 767–775. [Google Scholar]
- He, Y.; Naughton, J. Anonymization of Set-Valued Data via Top-Down, Local Generalization. In Proceedings of the VLDB Endowment, Lyon, France, 24–28 August 2009; pp. 934–945. [Google Scholar]
- Agrawal, R.; Srikant, R. Privacy-Preserving Data Mining. ACM SIGMOD Rec. 2000, 29, 439–450. [Google Scholar] [CrossRef]
- Liu, J.; Wang, K. Anonymizing Transaction Data by Integrating Suppression and Generalization. In Proceedings of the 14th Pa-cific-Asia Conference on Knowledge Discovery and Data Mining, Hyderabad, India, 21–24 June 2010; Advances in Knowledge Discovery and Data Mining, Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2010; Volume 6118. [Google Scholar]
- Cao, J.; Karras, P.; Raïssi, C.; Tan, K.-L. ρ-uncertainty: Inference-Proof Transaction Anonymization. In Proceedings of the VLDB Endowment, Singapore, 13–17 September 2010; pp. 1033–1044. [Google Scholar]
- Loukides, G.; Gkoulalas-Divanis, A. Utility-aware Anonymization of Diagnosis Codes. IEEE J. Biomed. Health Inform. 2013, 17, 60–70. [Google Scholar] [CrossRef] [PubMed]
- Jia, X.; Pan, C.; Xu, X.; Zhu, K.Q.; Lo, E. ρ-uncertainty Anonymization by Partial Suppression. In Proceedings of the International Conference on Database Systems for Advanced Applications, Bali, Indonesia, 21–24 April 2014; pp. 188–202. [Google Scholar]
- Nakagawa, T.; Arai, H.; Nakagawa, H. Personalized Anonymization for Set-Valued Data by Partial Suppression. Trans. Data Priv. 2018, 11, 219–237. [Google Scholar]
- Puri, V.; Sachdeva, S.; Kaur, P. Privacy Preserving Publication of Relational and Transaction Data: Survey on the Anonymization of Patient Data. Comput. Sci. Rev. 2019, 32, 45–61. [Google Scholar] [CrossRef]
- Puri, V.; Kaur, P.; Sachdeva, S. (k, m, t)-anonymity: Enhanced Privacy for Transactional Data. Concurr. Comput. Pract. Exp. 2022, 34, e7020. [Google Scholar] [CrossRef]
- Yao, L.; Chen, Z.; Wang, X.; Liu, D.; Wu, G. Sensitive Label Privacy Preservation with Anatomization for Data Publishing. IEEE Trans. Dependable Secur. Comput. 2021, 18, 904–917. [Google Scholar] [CrossRef]
- Xiao, X.; Tao, Y. Anatomy: Simple and Effective Privacy Preservation. In Proceedings of the VLDB Endowment, Seoul, Republic of Korea, 12–15 September 2006; pp. 139–150. [Google Scholar]
- Li, T.; Li, N.; Zhang, J.; Molloy, I. Slicing: A New Approach to Privacy Preserving Data Publishing. IEEE Trans. Knowl. Data Eng. 2012, 24, 561–574. [Google Scholar] [CrossRef]
- Andrew, J.; Jennifer, E.R.; Karthikeyan, J. An Anonymization-based Privacy-Preserving Data Collection Protocol for Digital Health Data. Front. Public Health 2023, 11, 1125011. [Google Scholar] [CrossRef]
- Kim, S.-S. A New Approach for Anonymizing Transaction Data with Set Values. Electronics 2023, 12, 3047. [Google Scholar] [CrossRef]
- Awad, N.; Couchot, J.-F.; Bouna, B.A.; Philippe, L. Publishing Anonymized Set-Valued Data via Disassociation Towards Analysis. Future Internet 2020, 12, 71. [Google Scholar] [CrossRef]
- Loukides, G.; Liagouris, J.; Gkoulalas-Divanis, A.; Terrovitis, M. Disassociation for Electronic Health Record Privacy. J. Biomed. Inform. 2014, 50, 46–61. [Google Scholar] [CrossRef] [PubMed]
- Loukides, G.; Liagouris, J.; Gkoulalas-Divanis, A.; Terrovitis, M. Utility-constrained Electronic Health Record Data Publishing Through Generalization and Disassociation. In Medical Data Privacy Handbook; Gkoulalas-Divanis, A., Loukides, G., Eds.; Springer: Cham, Switzerland, 2015; pp. 149–177. [Google Scholar]
- Sara, B.; Al Bouna, B.; Mohamed, N.; Christophe, G. On the Evaluation of the Privacy Breach in Disassociated Set-Valued Datasets. In Proceedings of the 13th International Joint Conference on e-Business and Telecommunications, Lisbon, Portugal, 26–28 July 2016; pp. 318–326. [Google Scholar]
- Awad, N.; Al Bouna, B.; Couchot, J.F.; Philippe, L. Safe Disassociation of Set-Valued Datasets. J. Intell. Inf. Syst. 2019, 53, 547–562. [Google Scholar] [CrossRef]
- Puri, V.; Kaur, P.; Sachdeva, S. Effective Removal of Privacy Breaches in Disassociated Transactional Datasets. Arab. J. Sci. Eng. 2020, 45, 3257–3272. [Google Scholar] [CrossRef]
- Awad, N.; Couchot, J.F.; Al Bouna, B.; Philippe, L. Ant-driven Clustering for Utility-aware Disassociation of Set-Valued Datasets. In Proceedings of the 23rd International Database Applications and Engineering Symposium, Athens, Greece, 10–12 June 2019; pp. 1–9. [Google Scholar]
- Bewong, M.; Liu, J.; Liu, L.; Li, J.; Choo1, K.-K.R. A Relative Privacy Model for Effective Privacy Preservation in transactional data. Concurr. Comput. Pract. Exp. 2019, 31, e4923. [Google Scholar] [CrossRef]
- Liu, X.; Feng, X.; Zhu, Y. Transactional Data Anonymization for Privacy and Information Preservation via Disassociation and Local Suppression. Symmetry 2022, 14, 472. [Google Scholar] [CrossRef]
- Andrew Onesimu, J.; Karthikeyan, J.; Jennifer, E.; Marc, P.; Hien, D. Privacy Preserving Attribute-focused Anonymization Scheme for Healthcare Data Publishing. IEEE Access 2022, 10, 86979–86997. Available online: https://ieeexplore.ieee.org/document/9858117 (accessed on 1 March 2023). [CrossRef]
- Lawrance, J.U.; Jesudhasan, J.V.N.; Rittammal, J.B.T. Parallel Fuzzy C-Means Clustering Based Big Data Anonymization Using Hadoop MapReduce. Wirel. Pers. Commun. 2024, 135, 2103–2130. [Google Scholar] [CrossRef]
- Ni, C.; Cang, L.S.; Gope, P.; Min, G. Data Anonymization Evaluation for Big Data and IoT Environment. Inf. Sci. 2022, 605, 381–392. [Google Scholar] [CrossRef]
- Gunawan, D.; Nugroho, Y.S.; Al Irsyadi, F.Y.; Utomo, I.C.; Andreansyah, I.; Islam, S. ℓρ-suppression: A Privacy Preserving Data Anonymization Method for Customer Transaction Data Publishing. In Proceedings of the 2022 International Conference on Information Technology Systems and Innovation (ICITSI), Bandung, Indonesia, 25–26 October 2022; pp. 171–176. [Google Scholar] [CrossRef]
- Biswas, S.; Nagar, V.N.V.; Khare, N.; Jain, P.; Agrawal, P. LDCML: A Novel AI-Driven Approach for Privacy-Preserving Anonymization of Quasi-Identifiers. Data Metadata 2024, 3, 287. [Google Scholar] [CrossRef]
- Chen, M.; Cang, L.S.; Chang, Z.; Iqbal, M.; Almakhles, D. Data Anonymization Evaluation against Re-identification Attacks in Edge Storage. Wirel. Netw. 2024, 30, 5263–5277. [Google Scholar] [CrossRef]
- Jayapradha, J.; Abdulsahib, G.M.; Khalaf, O.I.; Prakash, M.; Uddin, M.; Abdelhaq, M.; Alsaqour, R. Cluster-based Anonymity Model and Algorithm for 1:1 Dataset with a Single Sensitive Attribute using Machine Learning Technique. Egypt. Inf. J. 2024, 27, 100485. [Google Scholar] [CrossRef]
- Shyamasundar, R.K.; Maurya, M.K. Anonymization of Bigdata using ARX Tools. In Proceedings of the 2024 15th International Conference on Information and Communication Systems (ICICS), Bangkok, Thailand, 20–22 August 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Shamsinejad, E.; Banirostam, T.; Pedram, M.M.; Rahmani, A.M. Anonymizing Big Data Streams Using In-memory Processing: A Novel Model Based on One-time Clustering. J. Signal Process. Syst. 2024, 96, 333–356. [Google Scholar] [CrossRef]
- Shamsinejad, E.; Banirostam, T.; Pedram, M.M.; Rahmani, A.M. Representing a Model for the Anonymization of Big Data Stream Using In-Memory Processing. Ann. Data Sci. 2024, 1–30. [Google Scholar] [CrossRef]
- Ye, M.; Shen, W.; Zhang, J.; Yang, Y.; Du, B. SecureReID: Privacy-preserving Anonymization for Person Re-identification. IEEE Trans. Inf. Forensics Secur. 2024, 19, 2840–2853. [Google Scholar] [CrossRef]
- Graba, A.G.; Toumouh, A. Big data Anonymization using Spark for Enhanced Privacy Protection. Int. J. Electr. Comput. Eng. 2024, 14, 4. [Google Scholar] [CrossRef]
- Shamsinejad, E.; Banirostam, T.; Pedram, M.M.; Rahmani, A.M. A Review of Anonymization Algorithms and Methods in Big Data. Ann. Data Sci. 2024, 1–27. [Google Scholar] [CrossRef]
- Wong, W.; Alomari, Z.; Liu, Y.; Jura, L. Linkage Deanonymization Risks, Data-Matching and Privacy: A Case Study. In Proceedings of the 2024 8th International Conference on Cryptography, Security and Privacy (CSP), Osaka, Japan, 20–22 April 2024; pp. 10–16. [Google Scholar]
- Wang, H.; Yang, W.; Man, D.; Wang, W.; Lv, J. Anchor Link Prediction for Privacy Leakage via De-Anonymization in Multiple Social Networks. EEE Trans. Dependable Secur. Comput. 2023, 20, 5197–5213. [Google Scholar] [CrossRef]
- Kara, B.C.; Eyüpoğlu, C. A New Privacy-Preserving Data Publishing Algorithm Utilizing Connectivity-Based Outlier Factor and Mondrian Techniques. Comput. Mater. Contin. 2023, 76, 1515–1535. [Google Scholar] [CrossRef]
- Liu, J.; Wang, K. On Optimal Anonymization for l+-Diversity. In Proceedings of the 2010 IEEE 26th International Conference on Data Engineering, Long Beach, CA, USA, 1–6 March 2010. [Google Scholar] [CrossRef]
- Xu, J.; Wang, W.; Pei, J.; Wang, X.; Shi, B.; Fu, A. Utility-based anonymization using local recoding. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2006, Philadelphia, PA, USA, 20–23 August 2006; pp. 785–790. [Google Scholar] [CrossRef]
- Wan, M.; Fan, X.; Zang, F.; Nan, J. Application of information gain based heuristic search in optimal test strategy. In Proceedings of the 2010 IEEE International Conference on Information and Automation, Harbin, China, 20–23 June 2010; pp. 2291–2295. [Google Scholar] [CrossRef]
- Wenhao, S.; Zhenchao, Y.; Jianhui, Y.; Wenbin, Q. Information gain-based semi-supervised feature selection for hybrid data. Appl. Intell. 2023, 53, 7310–7325. [Google Scholar]
- Jie, L.; Chaoqun, W.; Wenzheng, C. Estimated path information gain-based robot exploration under perceptual uncertainty. Robotica 2022, 40, 2748–2764. [Google Scholar]
- Zheng, Z.; Kohavi, R.; Mason, L. Real world performance of association rule algorithms. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2001, San Francisco, CA, USA, 26–29 August 2001; pp. 401–406. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Wan, Q.; Xu, X.; Han, j. A dimensionality reduction method for large-scale group decision-making using TF-IDF feature similarity and information loss entropy. Appl. Soft Comput. 2024, 150, 111039. [Google Scholar] [CrossRef]
- Cover, T.M.; Tomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Fischer, I. The conditional entropy bottleneck. Entropy 2020, 22, 999. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).