

Enhancing Software Effort Estimation with Pre-Trained Word Embeddings: A Small-Dataset Solution for Accurate Story Point Prediction



Abstract
1. Introduction
1.1. Problem
1.2. Prior Research
1.3. Approach
1.4. Objectives and Research Questions
- What is the average best-performing pre-trained embedding model when evaluated across diverse software repositories and traditional machine learning methods, particularly for small datasets?
- Which pre-trained embedding model provides the best trade-off between computational efficiency and semantic richness for effort estimation tasks in small datasets?
- How do pre-trained embedding models compare to TF-IDF in individual and cross-project scenarios for software effort estimation, especially in data-constrained environments?
- How do the performance and efficiency of traditional machine learning methods with pre-trained embeddings compare to deep learning models and those without embeddings, particularly for small datasets?
2. Background and Related Work
2.1. Background of Pre-Trained Models
2.2. Related Work
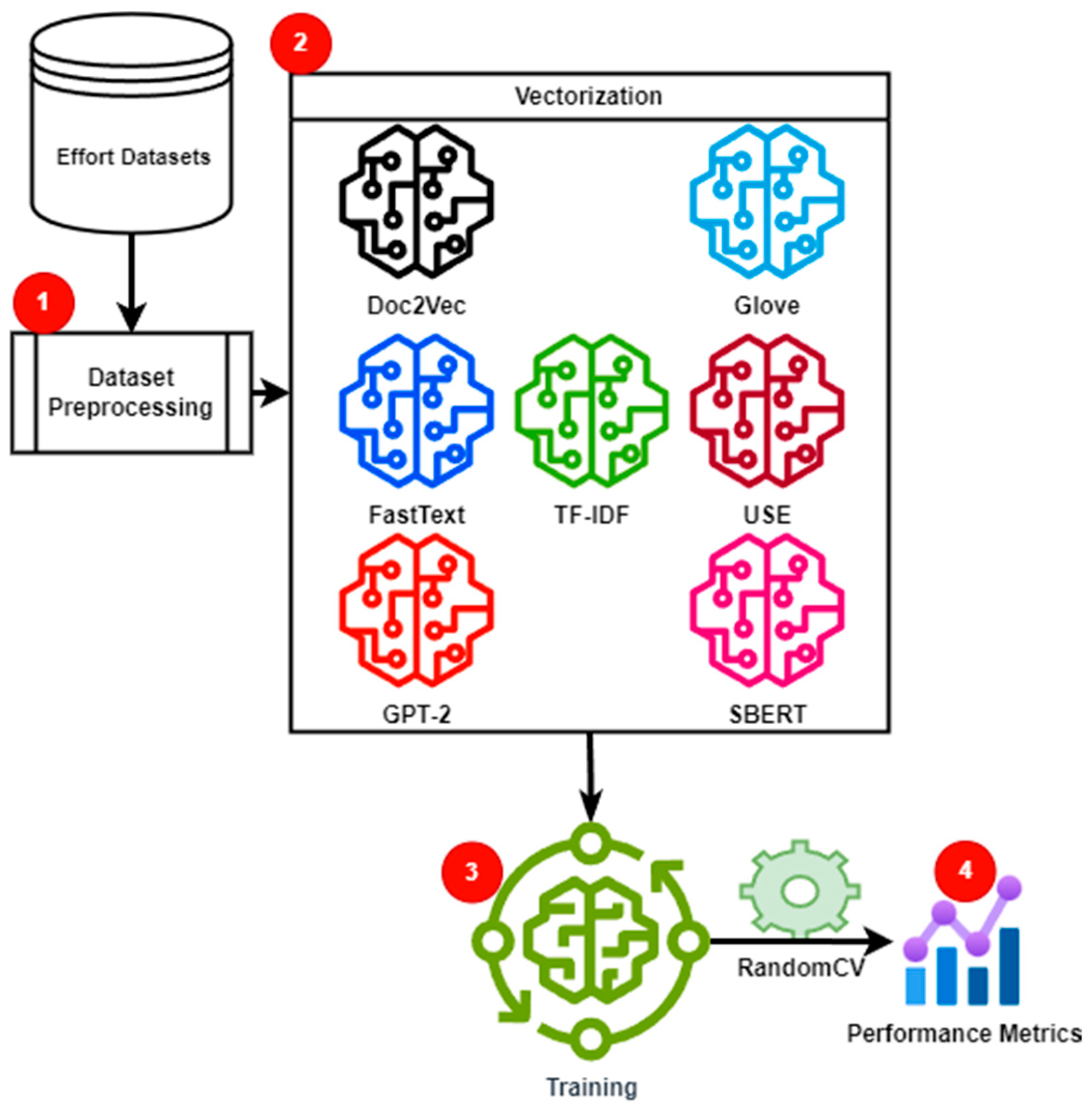
3. Methodology
3.1. Step 1: Data Preprocessing
3.2. Step 2: Text Vectorization
| Algorithm 1: Preprocessing and Vectorization |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Algorithm 2: Training and testing pre-trained models step 3: Model training |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.3. Step 3: Model Training
3.4. Step 4: Performance Metrics Evaluation
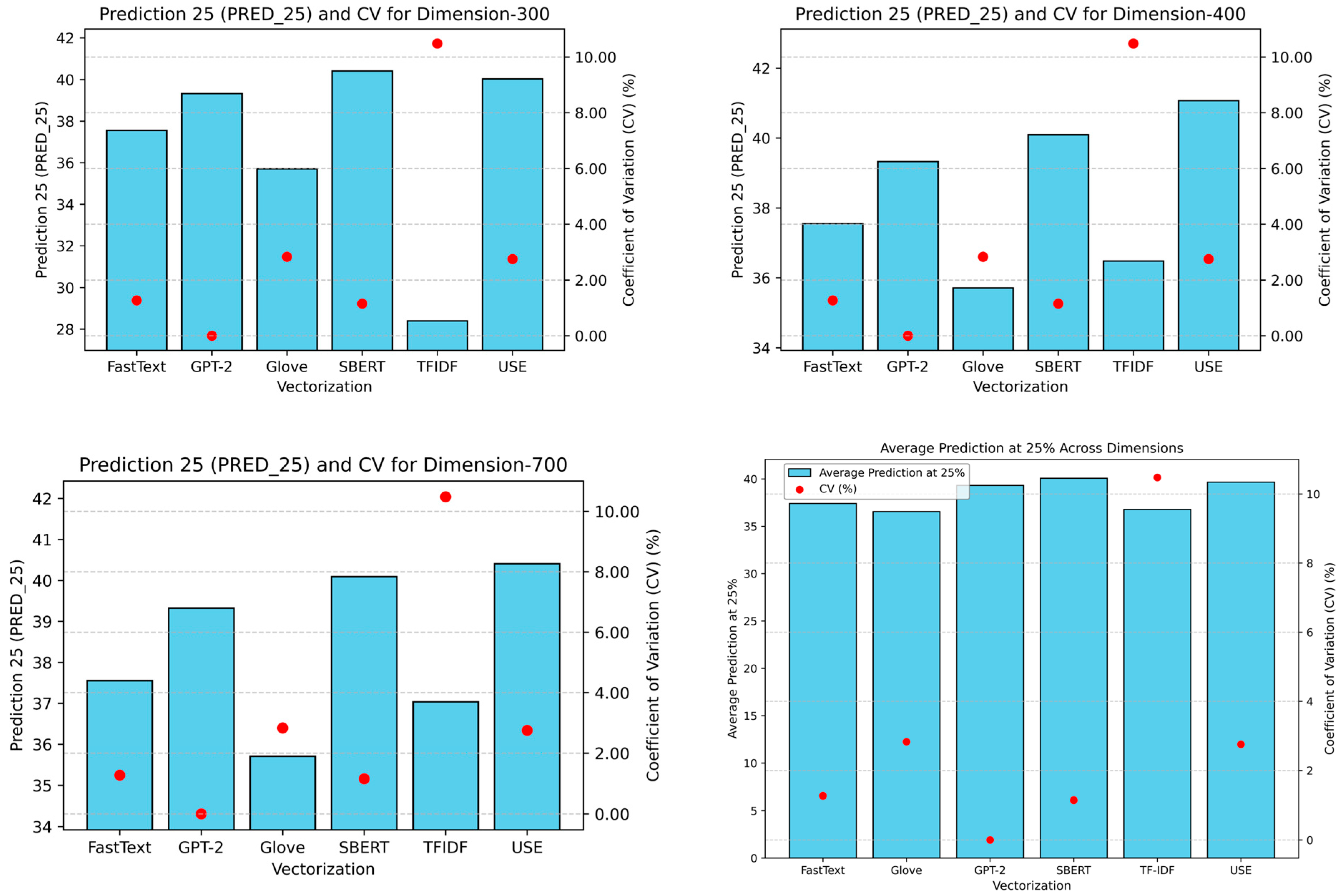
4. Results
4.1. Step 1: Data Preprocessing
4.2. Step 2: Text Vectorization
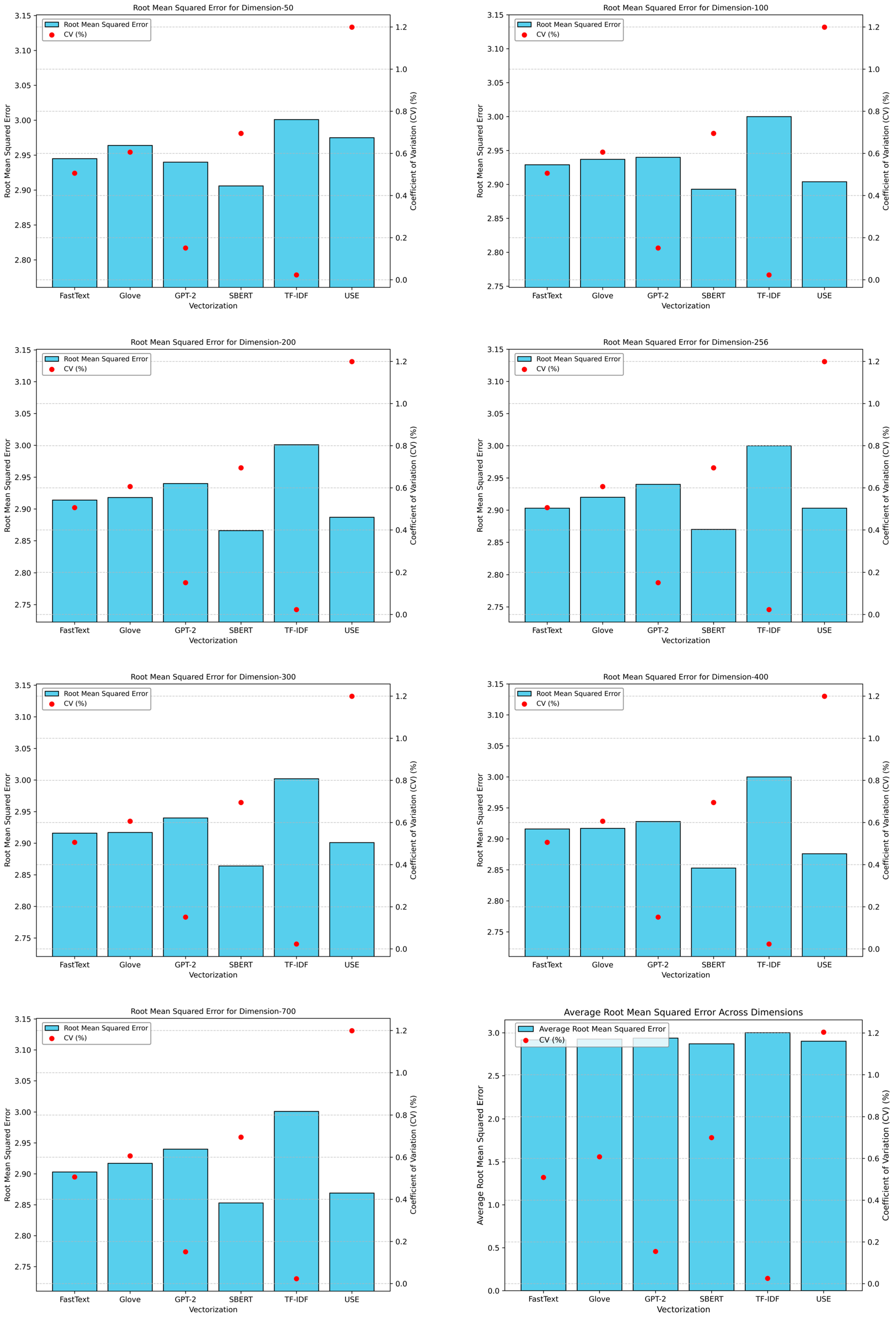
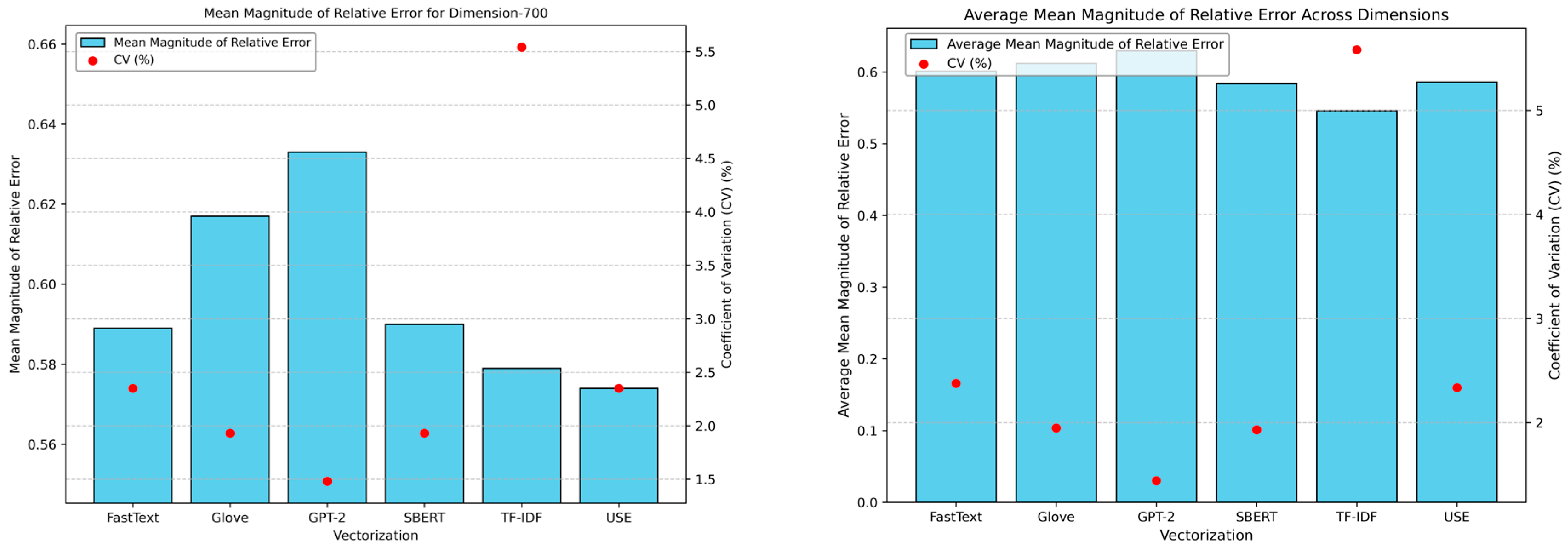
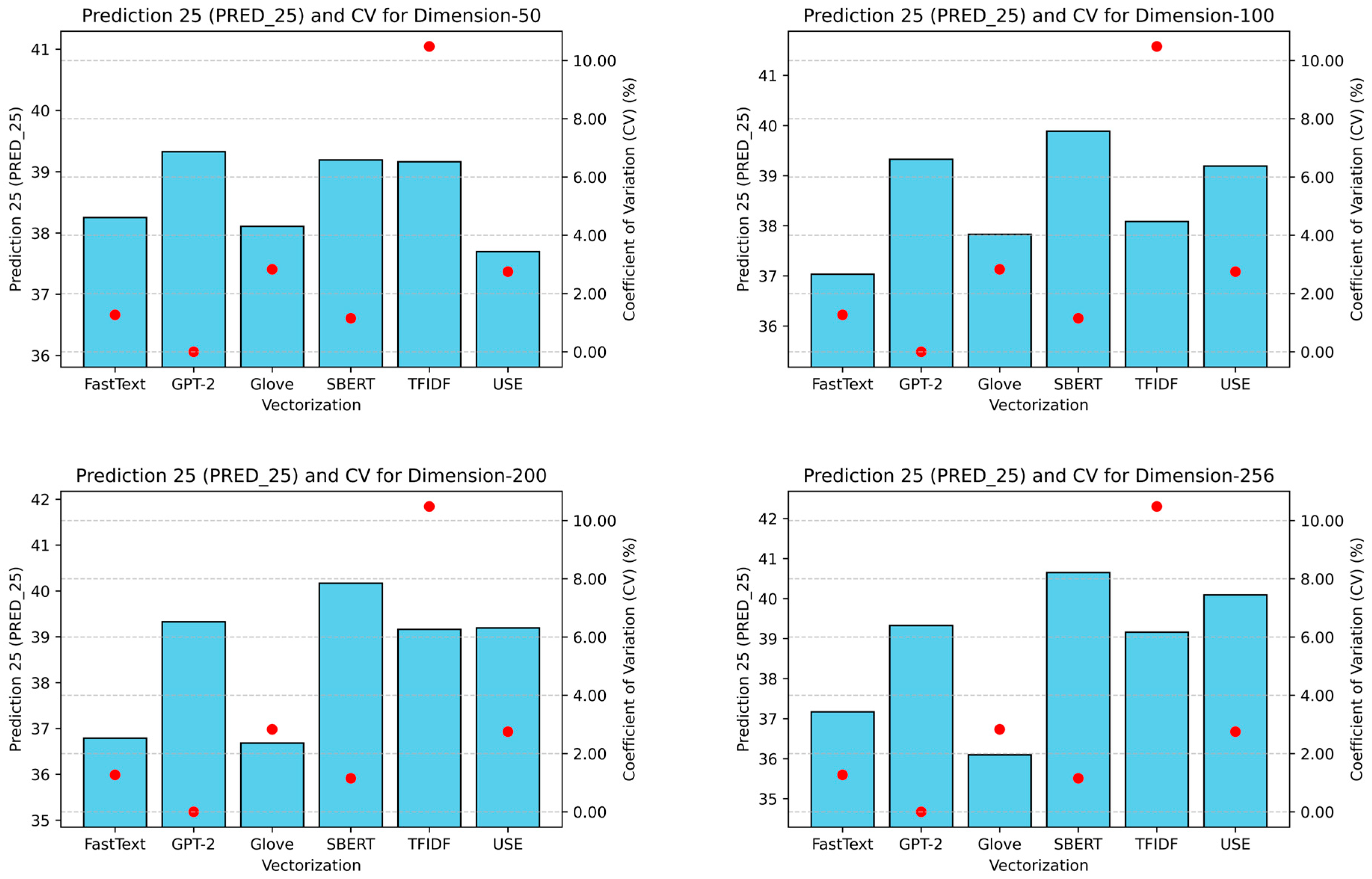
4.3. Step 3: Model Training
4.4. Step 4: Performance Metric Evaluation
5. Discussion
6. Limitations and Threats to Validity
7. Conclusions and Future Direction
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jadhav, A.; Shandilya, S.K.; Izonin, I.; Gregus, M. Effective Software Effort Estimation Leveraging Machine Learning for Digital Transformation. IEEE Access 2023, 11, 83523–83536. [Google Scholar] [CrossRef]
- Ritu; Bhambri, P. Software Effort Estimation with Machine Learning—A Systematic Literature Review. In Agile Software Development; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2023; pp. 291–308. ISBN 9781119896838. [Google Scholar]
- Li, Y.; Ren, Z.; Wang, Z.; Yang, L.; Dong, L.; Zhong, C.; Zhang, H. Fine-SE: Integrating Semantic Features and Expert Features for Software Effort Estimation. In Proceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE), Lisbon, Portugal, 14–20 April 2024; IEEE Computer Society: Los Alamitos, CA, USA, 2024; pp. 292–303. [Google Scholar]
- Molla, Y.S.; Yimer, S.T.; Alemneh, E. COSMIC-Functional Size Classification of Agile Software Development: Deep Learning Approach. In Proceedings of the 2023 International Conference on Information and Communication Technology for Development for Africa (ICT4DA), Bahir Dar, Ethiopia, 26–28 October 2023; pp. 155–159. [Google Scholar]
- Swandari, Y.; Ferdiana, R.; Permanasari, A.E. Research Trends in Software Development Effort Estimation. In Proceedings of the 2023 10th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Palembang, Indonesia, 20–21 September 2023; pp. 625–630. [Google Scholar]
- Rashid, C.H.; Shafi, I.; Ahmad, J.; Thompson, E.B.; Vergara, M.M.; De La Torre Diez, I.; Ashraf, I. Software Cost and Effort Estimation: Current Approaches and Future Trends. IEEE Access 2023, 11, 99268–99288. [Google Scholar] [CrossRef]
- Gong, L.; Zhang, J.; Wei, M.; Zhang, H.; Huang, Z. What Is the Intended Usage Context of This Model? An Exploratory Study of Pre-Trained Models on Various Model Repositories. ACM Trans. Softw. Eng. Methodol. 2023, 32, 1–57. [Google Scholar] [CrossRef]
- Sonbol, R.; Rebdawi, G.; Ghneim, N. The Use of NLP-Based Text Representation Techniques to Support Requirement Engineering Tasks: A Systematic Mapping Review. IEEE Access 2022, 10, 62811–62830. [Google Scholar] [CrossRef]
- Li, Z.; Lu, S.; Guo, D.; Duan, N.; Jannu, S.; Jenks, G.; Majumder, D.; Green, J.; Svyatkovskiy, A.; Fu, S.; et al. Automating Code Review Activities by Large-Scale Pre-Training. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1035–1047. [Google Scholar]
- Lin, Z.; Li, G.; Zhang, J.; Deng, Y.; Zeng, X.; Zhang, Y.; Wan, Y. XCode: Towards Cross-Language Code Representation with Large-Scale Pre-Training. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–44. [Google Scholar] [CrossRef]
- Li, M.; Yang, Y.; Shi, L.; Wang, Q.; Hu, J.; Peng, X.; Liao, W.; Pi, G. Automated Extraction of Requirement Entities by Leveraging LSTM-CRF and Transfer Learning. In Proceedings of the 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME), Adelaide, Australia, 28 September–2 October 2020; pp. 208–219. [Google Scholar] [CrossRef]
- Hadi, M.A.; Fard, F.H. Evaluating pre-trained models for user feedback analysis in software engineering: A study on classification of app-reviews. Empir. Softw. Eng. 2023, 28, 88. [Google Scholar] [CrossRef]
- Chen, Y.; Su, C.; Zhang, Y.; Wang, Y.; Geng, X.; Yang, H.; Tao, S.; Jiaxin, G.; Minghan, W.; Zhang, M.; et al. HW-TSC’s participation at WMT 2021 quality estimation shared task. In Proceedings of the Sixth Conference on Machine Translation, Online, 10–11 November 2021; Barrault, L., Bojar, O., Bougares, F., Chatterjee, R., Costa-jussa, M.R., Federmann, C., Fishel, M., Fraser, A., Freitag, M., Graham, Y., et al., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 890–896. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the EMNLP 2014—2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. In Proceedings of the 1st Workshop on Subword and Character Level Models in NLP, Copenhagen, Denmark, 7 September 2017; pp. 56–65. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 3982–3992. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Few-Shot Learners. arXiv 2019, arXiv:2005.14165. [Google Scholar]
- Patil, R.; Boit, S.; Gudivada, V.; Nandigam, J. A Survey of Text Representation and Embedding Techniques in NLP. IEEE Access 2023, 11, 36120–36146. [Google Scholar] [CrossRef]
- Cui, Z.; Gong, G. The effect of machine learning regression algorithms and sample size on individualized behavioral prediction with functional connectivity features. Neuroimage 2018, 178, 622–637. [Google Scholar] [CrossRef]
- Duszkiewicz, A.G.; Sørensen, J.G.; Johansen, N.; Edison, H.; Rocha Silva, T. Leveraging Historical Data to Support User Story Estimation. In Proceedings of the Product-Focused Software Process Improvement; Kadgien, R., Jedlitschka, A., Janes, A., Lenarduzzi, V., Li, X., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 284–300. [Google Scholar]
- Li, Y.; Zhang, T.; Luo, X.; Cai, H.; Fang, S.; Yuan, D. Do Pretrained Language Models Indeed Understand Software Engineering Tasks? IEEE Trans. Softw. Eng. 2023, 49, 4639–4655. [Google Scholar] [CrossRef]
- Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I.D.; Gebru, T. Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 220–229. [Google Scholar]
- Arnold, M.; Bellamy, R.K.E.; Hind, M.; Houde, S.; Mehta, S.; Mojsilović, A.; Nair, R.; Ramamurthy, K.N.; Olteanu, A.; Piorkowski, D.; et al. FactSheets: Increasing trust in AI services through supplier’s declarations of conformity. IBM J. Res. Dev. 2019, 63, 6:1–6:13. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, Y.; Wang, J.; Liu, B.; Li, D.; Guo, Y.; Chen, X.; Liu, Y. Remos: Reducing defect inheritance in transfer learning via relevant model slicing. In Proceedings of the Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 22–27 May 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1856–1868. [Google Scholar]
- Bailly, A.; Blanc, C.; Francis, É.; Guillotin, T.; Jamal, F.; Wakim, B.; Roy, P. Effects of dataset size and interactions on the prediction performance of logistic regression and deep learning models. Comput. Methods Programs Biomed. 2022, 213, 106504. [Google Scholar] [CrossRef]
- Guo, Y.; Hu, Q.; Cordy, M.; Papadakis, M.; Le Traon, Y. DRE: Density-based data selection with entropy for adversarial-robust deep learning models. Neural Comput. Appl. 2023, 35, 4009–4026. [Google Scholar] [CrossRef]
- De Bortoli Fávero, E.M.; Casanova, D.; Pimentel, A.R. SE3M: A model for software effort estimation using pre-trained embedding models. Inf. Softw. Technol. 2022, 147, 106886. [Google Scholar] [CrossRef]
- Phan, H.; Jannesari, A. Story Point Level Classification by Text Level Graph Neural Network. In Proceedings of the 1st International Workshop on Natural Language-based Software Engineering, Pittsburgh, PA, USA, 8 May 2022; pp. 75–78. [Google Scholar] [CrossRef]
- Iordan, A.-E. An Optimized LSTM Neural Network for Accurate Estimation of Software Development Effort. Mathematics 2024, 12, 200. [Google Scholar] [CrossRef]
- Hoc, H.T.; Silhavy, R.; Prokopova, Z.; Silhavy, P. Comparing Stacking Ensemble and Deep Learning for Software Project Effort Estimation. IEEE Access 2023, 11, 60590–60604. [Google Scholar] [CrossRef]
- Choetkiertikul, M.; Dam, H.K.; Tran, T.; Pham, T.T.M.; Ghose, A.; Menzies, T. A Deep Learning Model for Estimating Story Points. IEEE Trans. Softw. Eng. 2019, 45, 637–656. [Google Scholar] [CrossRef]
- Tawosi, V.; Moussa, R.; Sarro, F. Agile Effort Estimation: Have We Solved the Problem Yet? Insights From a Replication Study. IEEE Trans. Softw. Eng. 2023, 49, 2677–2697. [Google Scholar] [CrossRef]
- Alhamed, M.; Storer, T. Evaluation of Context-Aware Language Models and Experts for Effort Estimation of Software Maintenance Issues. In Proceedings of the 2022 IEEE International Conference on Software Maintenance and Evolution (ICSME), Limassol, Cyprus, 2–7 October 2022; pp. 129–138. [Google Scholar] [CrossRef]
- Amasaki, S. On Effectiveness of Further Pre-Training on BERT Models for Story Point Estimation. In Proceedings of the 19th International Conference on Predictive Models and Data Analytics in Software Engineering, San Francisco, CA, USA, 8 December 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 49–53. [Google Scholar]
- Fu, M.; Tantithamthavorn, C. GPT2SP: A Transformer-Based Agile Story Point Estimation Approach. IEEE Trans. Softw. Eng. 2023, 49, 611–625. [Google Scholar] [CrossRef]
- Porru, S.; Murgia, A.; Demeyer, S.; Marchesi, M.; Tonelli, R. Estimating story points from issue reports. In Proceedings of the ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar]
- Mustafa, E.I.; Osman, R. A random forest model for early-stage software effort estimation for the SEERA dataset. Inf. Softw. Technol. 2024, 169, 107413. [Google Scholar] [CrossRef]
- Sánchez-García, Á.J.; González-Hernández, M.S.; Cortés-Verdín, K.; Pérez-Arriaga, J.C. Software Estimation in the Design Stage with Statistical Models and Machine Learning: An Empirical Study. Mathematics 2024, 12, 1058. [Google Scholar] [CrossRef]
- Raza, A.; Espinosa-Leal, L. Predicting the Duration of User Stories in Agile Project Management. In Proceedings of the Smart Technologies for a Sustainable Future; Auer, M.E., Langmann, R., May, D., Roos, K., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 316–328. [Google Scholar]
- Kassem, H.; Mahar, K.; Saad, A.A. Story Point Estimation Using Issue Reports With Deep Attention Neural Network. E-Inform. Softw. Eng. J. 2023, 17, 1–15. [Google Scholar] [CrossRef]
- Phan, H.; Jannesari, A. Heterogeneous Graph Neural Networks for Software Effort Estimation. Int. Symp. Empir. Softw. Eng. Meas. 2022, 103–113. [Google Scholar] [CrossRef]
- Sousa, A.O.; Veloso, D.T.; Goncalves, H.M.; Faria, J.P.; Mendes-Moreira, J.; Graca, R.; Gomes, D.; Castro, R.N.; Henriques, P.C. Applying Machine Learning to Estimate the Effort and Duration of Individual Tasks in Software Projects. IEEE Access 2023, 11, 89933–89946. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Min Length | Max Length | Training Data |
|---|---|---|---|---|
| TF-IDF | Provides a fixed representation for each word or sentence. | Fixed | Fixed | Off the shelf |
| GloVe | Creates embeddings based on global word co-occurrence statistics. | Variable | Variable | Global word–word co-occurrence statistics |
| Doc2Vec | Creates fixed-length vectors for documents, allowing the model to understand document context. | Fixed | Fixed | Local word–word co-occurrence statistics |
| FastText | Embedding method that represents words as n-grams, capturing subword information for better understanding. | Variable | Variable | Subword information, n-grams |
| USE | Embedding method designed to generate contextualized representations for entire sentences. | Variable | Variable | Various datasets |
| BERT | Pre-trained transformer model designed for bidirectional context understanding and offering contextual embeddings. | Variable | Variable | Various datasets |
| SBERT | Embedding method based on BERT architecture, fine-tuned for sentence-level tasks, enhancing contextual understanding. | Variable | Variable | Various datasets |
| GPT-2 | Generates context-aware embeddings with variable lengths. | Variable | Variable | Various datasets |
| Dataset | Original Dataset Characteristics | Processed Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| C1 | MAX-SP | Mean-SP | Max-Tokens | C2 | Min-Token2 | Max-Token2 | ||
| 1 | appceleratorstudio | 2919 | 40 | 5.64 | 20,003 | 2876 | 44 | 16,815 |
| 2 | aptanastudio | 829 | 40 | 8.02 | 20,003 | 771 | 79 | 16,247 |
| 3 | bamboo | 521 | 20 | 2.42 | 20,003 | 373 | 33 | 16,784 |
| 4 | cloVer | 384 | 40 | 4.59 | 15,381 | 361 | 39 | 10,072 |
| 5 | datamanagement | 4667 | 100 | 9.57 | 12,520 | 4026 | 30 | 9114 |
| 6 | duracloud | 666 | 16 | 2.13 | 5948 | 612 | 50 | 4631 |
| 7 | jirasoftware | 352 | 20 | 4.43 | 7367 | 286 | 55 | 5411 |
| 8 | mesos | 1680 | 40 | 3.09 | 20,003 | 1562 | 41 | 13,568 |
| 9 | moodle | 1166 | 100 | 15.54 | 6742 | 1164 | 30 | 4526 |
| 10 | mule | 889 | 21 | 5.08 | 20,003 | 889 | 33 | 13,549 |
| 11 | mulestudio | 732 | 34 | 6.40 | 20,003 | 731 | 40 | 15,172 |
| 12 | springxd | 3526 | 40 | 3.70 | 20,003 | 3054 | 32 | 17,201 |
| 13 | talenddataquality | 1381 | 40 | 5.92 | 20,003 | 1135 | 34 | 16,515 |
| 14 | talendesb | 868 | 13 | 2.16 | 20,003 | 775 | 40 | 16,046 |
| 15 | titanium | 2251 | 34 | 6.32 | 20,003 | 2122 | 43 | 14,658 |
| 16 | usergrid | 482 | 8 | 2.85 | 20,003 | 333 | 53 | 16,516 |
| Total | 23,313 | 100 | 5.49 | 20,003 | 21,070 | 30 | 17,201 | |
| Regression Method | Description |
|---|---|
| Lasso | The linear model with L1 regularization is helpful for feature selection and high-dimensional data. |
| Support vector | Uses support vector machines for regression, is effective in high-dimensional spaces, and captures patterns between features. |
| Random forest | Ensemble of decision trees, providing robustness and capturing complex semantic relationships. |
| Gradient boosting | Builds trees sequentially, correcting errors, and is powerful for capturing intricate patterns. |
| K-nearest neighbors | Predictions based on the average of k-nearest neighbors are simple, yet effective for local patterns. |
| XGBoost | Gradient boosting algorithms are known for high performance, efficiency, and flexibility in handling various data types. |
| Performance Metrics | Description | Formula |
|---|---|---|
| Mean Absolute Error (MAE) | Measures the average absolute difference between predicted and actual story points. | |
| Mean Magnitude of Relative Error (MMRE) | Measures the average magnitude of relative errors between predicted and actual story points | |
| Root Mean Square Error (RMSE) | Measures the square root of the mean squared differences between predicted and actual story points. Provides a metric that gives relatively high weight to significant errors. Useful when significant errors are particularly undesirable. | |
| Pred (25) | Measures percentage of predictions within x of true values. The larger the value of Pred (25), the better the predictions are considered. It indicates higher accuracy in predicting values within the specified range. |
| Regression Method | Key Parameters |
|---|---|
| Lasso Regression | alpha: [0.001, 0.005, 0.01, 0.05, 0.1] fit_intercept: [True, False] |
| Support Vector Regression | nu: [0.01, 0.05, 0.1] C: [0.1, 1, 10] kernel: [‘linear’, ‘rbf’] |
| Random Forest Regression | max_depth: [None, 5, 10] min_samples_split: [2, 5, 10] |
| Gradient Boosting Regression | learning_rate: [0.01, 0.1] max_depth: [3, 5, 10] subsample: [0.8, 1.0] loss: [‘squared_error’, ‘huber’] |
| K-Nearest Neighbors Regression | n_neighbors: [3, 5, 7] weights: [‘uniform’, ‘distance’] leaf_size: [20, 30, 40] |
| XGBoost Regression | n_estimators: [50, 100, 200] learning_rate: [0.01, 0.1] max_depth: [3, 5, 7] subsample: [0.8, 1.0] colsample_bytree: [0.8] |
| DS | GPT2SP [40] | Deep-SE [36] | HAN [45] | HeteroSP [46] | GNN [33] | SVM * |
|---|---|---|---|---|---|---|
| 1 | 0.84 | 1.36 | 1.35 | 1.30 | 2.67 | 2.20 |
| 2 | 1.93 | 2.71 | 2.63 | 3.24 | 5.16 | 3.92 |
| 3 | 0.44 | 0.74 | 0.67 | 0.75 | 0.00 | 1.06 |
| 4 | 1.98 | 2.11 | 1.81 | 3.64 | 1.22 | 3.32 |
| 5 | 3.10 | 3.77 | 3.63 | 6.19 | 13.40 | 7.29 |
| 6 | 0.48 | 0.68 | 0.6 | 0.78 | 0.07 | 1.03 |
| 7 | 0.92 | 1.38 | 1.27 | 1.62 | 1.31 | 2.30 |
| 8 | 0.66 | 1.02 | 0.93 | 1.21 | 0.28 | 1.38 |
| 9 | 4.09 | 5.97 | 5.66 | 5.34 | 25.16 | 11.72 |
| 10 | 1.43 | 2.18 | 1.86 | 2.47 | 4.03 | 2.54 |
| 11 | 2.04 | 3.23 | 2.56 | 3.58 | 5.84 | 3.41 |
| 12 | 0.96 | 1.63 | 1.2 | 1.72 | 1.08 | 1.79 |
| 13 | 1.58 | 2.97 | 2.49 | 2.20 | 1.50 | 3.56 |
| 14 | 0.50 | 0.64 | 0.6 | 0.91 | 0.14 | 0.89 |
| 15 | 1.36 | 1.97 | 1.7 | 2.04 | 2.30 | 3.17 |
| 16 | 0.68 | 1.03 | 0.84 | 1.16 | 0.03 | 0.88 |
| AVG | 1.44 | 2.09 | 1.86 | 2.38 | 4.01 | 3.15 |
| Mdn | 1.16 | 1.79 | 1.53 | 1.88 | 1.41 | 2.42 |
| Min | 0.44 | 0.64 | 0.6 | 0.75 | 0 | 0.88 |
| Max | 4.09 | 5.97 | 5.66 | 6.19 | 25.16 | 11.72 |
| Dataset | SVM * | Best | Best Model (Machine, Learning, Pre-Trained Model, Vector Size) | Description |
|---|---|---|---|---|
| appceleratorstudio | 2.20 | 2.10 | SVM, SBERT, 200 | SBERT effectively captures semantic context, enhancing prediction accuracy. |
| aptanastudio | 3.92 | 3.82 | GBOOST, FastText, 200 | GBOOST’s boosting approach combined with FastText’s embeddings improves model performance. |
| bamboo | 1.06 | 1.05 | SVM, USE, 100 | USE’s universal sentence embeddings provide a solid contextual understanding. |
| clover | 3.32 | 3.17 | SVM, USE, 100 | USE captures nuanced semantic relationships, improving SVM performance. |
| datamanagement | 7.29 | 7.27 | SVM, GloVE, 100 | GloVe’s pre-trained vectors on a large corpus enhance semantic accuracy. |
| duracloud | 1.03 | 1.01 | GBOOST, USE, 200 | The combination of GBOOST’s algorithm with USE embeddings increases prediction accuracy. |
| jirasoftware | 2.30 | 2.11 | SVM, USE, 256 | Even with a larger vector size, USE’s embeddings provide superior semantic capture. |
| mesos | 1.38 | 1.35 | SVM, USE, 300 | USE embeddings with larger vector sizes enhance semantic understanding. |
| moodle | 11.72 | 11.72 | SVM, FastText, 300 | FastText handles out-of-vocabulary words well, which is crucial for diverse project terminologies. |
| mule | 2.54 | 2.49 | SVM, XGBOOST, 400 | XGBOOST’s gradient boosting improves model performance with larger vector sizes. |
| mulestudio | 3.41 | 3.34 | SVM, SBERT, 100 | SBERT embeddings improve semantic context understanding, enhancing prediction accuracy. |
| springxd | 1.79 | 1.77 | SVM, USE, 300 | USE’s larger vector size provides better semantic representation. |
| talenddataquality | 3.56 | 3.53 | SVM, USE, 400 | USE embeddings with even larger vector sizes to improve contextual capture. |
| talendesb | 0.89 | 0.87 | SVM, SBERT, 200 | SBERT’s embeddings improve performance by capturing semantic nuances effectively. |
| titanium | 3.17 | 3.12 | GBOOST, SBERT, 400 | SBERT embeddings combined with GBOOST enhance semantic understanding and prediction. |
| usergrid | 0.88 | 0.85 | GBOOST, Doc2Vec, 256 | Doc2Vec captures document-level context well, boosting GBOOST performance. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atoum, I.; Otoom, A.A. Enhancing Software Effort Estimation with Pre-Trained Word Embeddings: A Small-Dataset Solution for Accurate Story Point Prediction. Electronics 2024, 13, 4843. https://doi.org/10.3390/electronics13234843
Atoum I, Otoom AA. Enhancing Software Effort Estimation with Pre-Trained Word Embeddings: A Small-Dataset Solution for Accurate Story Point Prediction. Electronics. 2024; 13(23):4843. https://doi.org/10.3390/electronics13234843
Chicago/Turabian StyleAtoum, Issa, and Ahmed Ali Otoom. 2024. "Enhancing Software Effort Estimation with Pre-Trained Word Embeddings: A Small-Dataset Solution for Accurate Story Point Prediction" Electronics 13, no. 23: 4843. https://doi.org/10.3390/electronics13234843
APA StyleAtoum, I., & Otoom, A. A. (2024). Enhancing Software Effort Estimation with Pre-Trained Word Embeddings: A Small-Dataset Solution for Accurate Story Point Prediction. Electronics, 13(23), 4843. https://doi.org/10.3390/electronics13234843