Abstract
This paper explores the application of the YOLOv5s algorithm integrated with the DeepSORT tracking detection algorithm in vehicle target detection, leveraging its advantages in data processing, loss function, network structure, and training strategy. Regarding detection frame regression, adopting Focal-EIOU can improve vehicle detection accuracy by precisely measuring overlap and better handle complex scenarios, enhancing the overall performance. The CoordConv convolution layer with more spatial position information is employed to enhance the original network structure’s convolution layer and improve vehicle positioning accuracy. The principle and effectiveness of the Shuffle Attention mechanism are analyzed and added to the YOLOv5s network structure to enhance training, improve detection accuracy and running speed. And the DeepSORT tracking detection algorithm is designed to achieve high-speed operation and high-accuracy matching in target tracking, enabling efficient and reliable tracking of objects. Simultaneously, the network structure is optimized to enhance algorithmic speed and performance. To meet the requirements of vehicle detection in practical transportation systems, real-world vehicle images are collected as a dataset for model training to achieve accurate vehicle detection. The results show that the accuracy rate P of the improved YOLOv5s algorithm is increased by 0.484%, and mAP_0.5:0.95 reaches 92.221%, with an increase of 1.747%.
1. Introduction
According to the International Society for Road Travel Safety (ASIRT), an annual figure of over 1.3 million fatalities is attributed to traffic accidents, while an additional 20 to 50 million people suffer injuries or disabilities. Vehicle detection via surveillance video can strengthen the operation and maintenance supervision of expressways, optimize vehicle efficiency and safety, alleviate traffic congestion, and notably facilitate accident handling and early warning on expressways. Furthermore, it assumes a crucial role in safeguarding people’s lives and property and promoting economic development.
Currently, in terms of the recognition and detection of vehicle targets, the neural network algorithm based on deep learning is of the highest utility. Among all neural network algorithms, the YOLO algorithm stands out for its end-to-end nature, single-shot detection capability, high speed, strong generalization ability and high precision. In the field of vehicle detection and tracking, a large number of valuable studies have been carried out. For example, in 2022, Dongyuan Ge et al. [1] proposed a vehicle tracking method based on the Gaussian mixture background model. This method used multiple ways to segment the detection targets to achieve vehicle tracking. In 2023, Jiandong Wang et al. [2] proposed a high-precision vehicle detection and tracking method based on the attention mechanism. By adding a normalization-based attention module to the classic Yolov5s model, they constructed the Yolov5-nam detection model. Moreover, they further proposed the real-time small-target vehicle tracking method named JDE-YN, which effectively improved the detection and tracking accuracy. In 2023, Yang Peng [3] released the deep learning methods for 3D object detection and tracking in autonomous driving. He introduced both two-stage and one-stage object detection methods as well as the advantages and challenges of point cloud data in object detection, providing guidance for related research. Li Changyu et al. [4] proposed an end-to-end lightweight target detection algorithm named LL-YOLO (Low Light YOLO). They designed an algorithm for generating low-illumination images and utilized depthwise separable convolution and the attention mechanism to capture peripheral information, thus improving the accuracy of low-illumination target detection and recognition. Li Daoliang et al. [5] proposed a novel combined network algorithm. Based on YOLO v5, they integrated the DeepSORT multi-target tracking algorithm. By combining the learning rate warm-up and cosine annealing strategy, they optimized the training performance. Additionally, they added the Swin Transformer module to improve the target monitoring accuracy. All these studies have laid a solid foundation for the work of this paper. However, dealing with the following issues, such as complex backgrounds (vehicles are detected against complex backgrounds with various objects), occlusion (vehicles may be occluded by other vehicles, objects or environment parts, causing traditional detection methods to miss or misclassify them), scale variation (vehicles in images have different sizes based on their distance from the camera) and real-time requirements (the detection algorithm needs to operate in real time), the above methods seem to be neither convenient nor highly efficient.
This paper centers on the application of the YOLO algorithm in vehicle detection and puts forward improvements to the existing YOLOv5s algorithm to achieve better performance. A theoretical analysis of IOU and its variants in vehicle detection is carried out, with a specific focus on the regression of detection frames. FocalEIOU, which yields superior results, is selected. As an advanced loss function, it improves the bounding box regression by focusing on the most challenging regions where the traditional loss functions may fail to provide sufficient guidance. To enhance the precision of vehicle positioning, a CoordConv convolution layer that incorporates spatial position information is employed to refine the convolutional layer of the original network structure. By doing so, it provides the network with additional geometric information, which is particularly useful for handling objects in different positions and scales. The attention mechanism of Shuffle Attentain is analyzed in terms of its principle and effect, and integrated into the network architecture of YOLOv5s to optimize training, thereby improving detection accuracy and operational efficiency. Moreover, the DeepSORT algorithm is utilized for real-time tracking and monitoring of vehicles in video streams while simultaneously displaying the detection results of vehicles to provide additional valuable information for other analyses and applications. The main contents are presented in Figure 1.
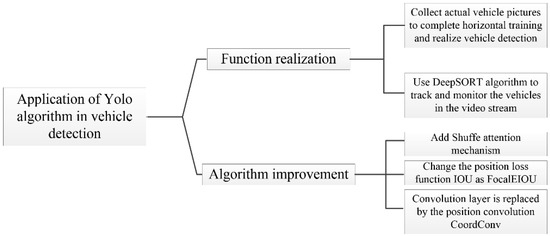
Figure 1.
Main contents.
2. Improved YOLOv5s Model
2.1. Structure of YOLOv5s Model
The YOLOv5s algorithm is a regression-based one-stage object detection method that utilizes deep convolutional neural networks to transform image data into target object location and category information with high precision. Figure 2 illustrates the structure of this model, comprising three components: Backbone, Neck and Head.
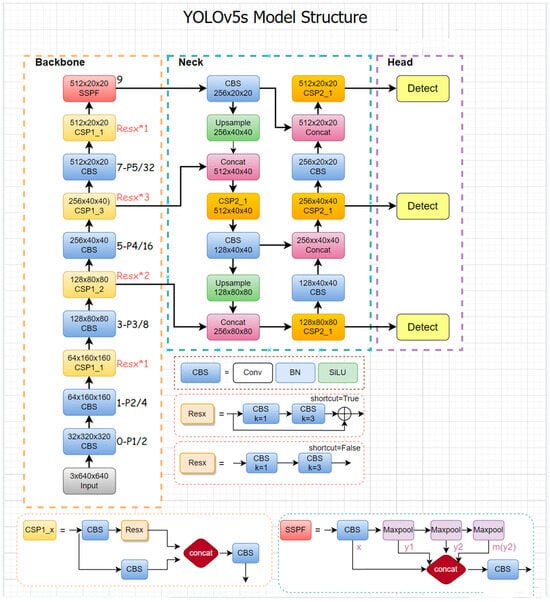
Figure 2.
Structure of YOLOv5s model.
Backbone: Use the CSPDarknet53 backbone network to extract features from the input image. Neck: Use SPP, PAN, and ASPP modules to enhance and fuse features extracted by the backbone network. Head: Use the detection head network of YOLOv5 to process the feature map and obtain the position and category information of the detection boxes [6,7,8,9,10,11].
The reasons for choosing YOLOv5s mainly encompass three aspects. First, it has excellent performance with high detection accuracyThe algorithm performance test chart of YOLOv5s is shown in Figure 3. It can accurately locate and identify targets through multi-scale feature fusion. Moreover, it has a fast detection speed and is suitable for real-time scenarios. Second, it is easy to use and deploy. The training process is simple. It supports multiple data augmentation methods. It is convenient for cross-platform deployment and can adapt to various hardware platforms and be easily integrated with other software systems. Third, it has active community support. The model is continuously updated and improved. At the same time, it provides abundant resources and cases for users to learn and reference.
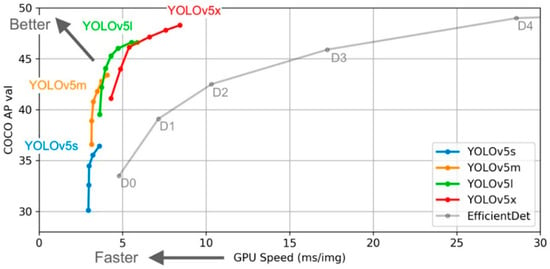
Figure 3.
Algorithm performance test chart of YOLOv5s.
2.2. YOLOv5s Algorithm Improvement
Although YOLOv5s has made significant progress in detection speed and accuracy, it still faces challenges such as false positives or missed detections. By enhancing the model architecture and training methods, its detection accuracy can be further improved. Additionally, real-world road conditions present issues such as a large amount of required data, high levels of noise, and frequent object changes; therefore, optimizing and adjusting the model is necessary to address these problems. In this section, the vehicle detection performance of the YOLOv5s algorithm is enhanced by incorporating the attention mechanism, convolutional layer method and detection box regression for more precise localization and classification of vehicles [12,13,14,15].
2.2.1. Add Shuffle Attentain Mechanism
The attention mechanism is designed to enable a computer to disregard irrelevant information and concentrate on significant data during deep learning. Designing a model incorporating attention mechanism enhances the training process by emphasizing spatial and channel information, enabling effective capture of the interplay between channels and spatial pixel relationships. Consequently, this leads to improved vehicle detection and positioning accuracy in practical scenarios. The Shuffle attention mechanism structure, as depicted in Figure 4, partitions the input feature graph into multiple groups. Shuffle Units are utilized to effectively integrate the spatial and channel attention mechanisms within each group, facilitating information exchange between features through the “Channel Attention” operator while leveraging the feature information of each group. The Shuffle Attention mechanism divides the input into g groups along the channel, and further partitions each group into two parts: one for spatial attention and the other for channel attention. As illustrated in Figure 4, the blue part performs spatial attention while GroupNorm divides channels into groups to obtain spatial feature information through normalization. The green component implements the channel attention mechanism by utilizing global average pooling (GAP) to embed global information, followed by concatenation to combine group information. Finally, channel rearrangement is performed to facilitate inter-group information exchange. In this paper, the Shuffle Attention module is placed at the end of the backbone network so that it can have a global view of the feature map.
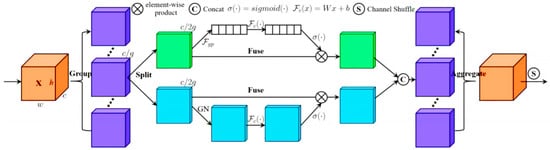
Figure 4.
Shuffle Attentain.
2.2.2. Add CoordConv in Convolutional Layer
Traditional convolution has translation invariance, which can realize the classification problem in object detection very well, but it is not very good for sensing position information. Therefore, by using CoordConv convolution to improve the original convolution, the spatial information of the feature graph can be perceived in the convolution process. The construction of CoordConv is shown in Figure 5. In contrast to traditional convolution, CoordConv introduces two additional channels to the input feature map. The green channel encodes the x-coordinate and the red channel encodes the y-coordinate. Another advantage of utilizing CoordConv, akin to the residual network, lies in its equivalence to two additional channels of ordinary convolution if the coordinate channels fail to learn any information. This equivalence not only minimizes computational requirements but also preserves the translation invariance characteristic of ordinary convolution. However, when CoordConv’s coordinate channel successfully learns positional information, it leads to a change in output characteristics based on this spatial data.
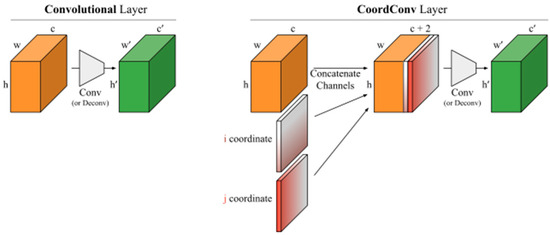
Figure 5.
CoordConv.
During the convolution of feature maps, the previous convolution’s feature maps contain more precise and comprehensive positional information. However, after multiple convolutions, the feature maps possess richer semantic information but significantly less positional information. Therefore, it is recommended to apply CoordConv as early in the convolution process as possible. As such, this study utilizes only CoordConv to replace the initial convolution layer in FPN and PANET, while also adding a single instance of CoordConv before head output to ensure that positional information can be transmitted with minimal impact on training results.
As shown in Figure 6, the CoordConv model achieves perfect training and testing performance for both supervised coordinate classification and supervised rendering tasks in the separation of training and test sets (compared with traditional convolution, that is, convolutional neural network (CNN)). In addition, the parameters of the CoordConv model are reduced by 10–100 times, and training is completed in seconds instead of over an hour, as required by CNN’s best performance standards.
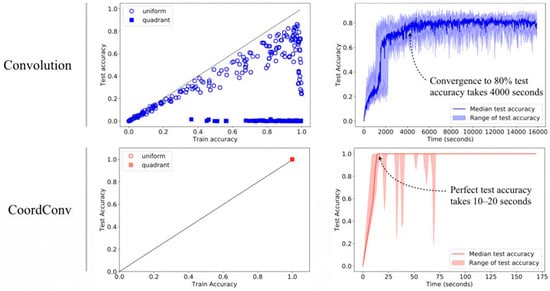
Figure 6.
Advantages of the CoordConv model.
2.2.3. Improve the Position Loss Indicator-IOU (Intersection over Union)
IOU (Intersection over Union) is a widely used metric in object detection, which calculates the ratio of intersection to union. In the context of vehicle detection, multiple predictive bounding boxes are generated to determine the precise location of the vehicle. The actual location of the vehicle corresponds to the true positive detection box. Therefore, the Intersection over Union (IOU) of certain features between the predicted detection box and the actual detection box can serve as an indicator of the disparity between the prediction and reality, thereby reflecting the accuracy of target detection. The key advantage of IOU lies in its ability to calculate independently from image resizing.
With the enhancement and optimization of the algorithm, a multitude of IOU variations have emerged, and the YOLOv5s algorithm also encompasses a diverse range of improved IOU options. For instance, GIOU (Generalized-IOU) is introduced based on IOU, followed by the introduction of DIOU (Distance-IOU) based on GIOU, and then CIOU (Complete-IOU) based on DIOU. Additionally, the aspect ratio parameters are divided into length and width. The distinction between IOU and other calculations is illustrated in Table 1.

Table 1.
The distinction between IOU and other calculations.
Focal-EIOU: The concept of FocalLoss is introduced to address the issue of imbalanced training samples in frame regression. In such cases, high-quality anchors with minimal regression error are often scarce compared to those with low quality and large errors, leading to a significant gradient impact on training due to an abundance of low-quality samples. FocalLoss aims at reducing the loss incurred by low-quality samples so that the network can prioritize high-quality ones. It is developed on the basis of EIOU. By combining the idea of Focal Loss, it further improves the performance of the model in object detection under complex scenes, especially its ability to handle hard-to-classify samples.
Focal-EIOU combines EIoU (Efficient Intersection over Union), the efficient loss function, and Focal L1 loss function. The EIoU loss function improves the part of CIoU loss function dealing with aspect ratio, speeds up the convergence speed and significantly improves the regression effect. Its definition is shown in Formula (1):
In the formula, and are the distance loss function and the aspect ratio loss function, respectively. and are the width and height of the minimum circumscribed rectangle of the predicted bounding box and the real bounding box.
To make EIoU loss function pay more attention to high-quality samples and make the high-quality anchor frame play a greater role, FocalEIoU loss function is proposed by combining the Focal L1 loss function with EIoU loss function. Its definition is shown in Formula (2):
In the formula, the default value of is 0.5. It is a parameter that controls the degree of outlier suppression.
As can be seen from the above formula, the FocalEIoU loss function can reduce the loss of hard samples so that the neural network pays more attention to simple samples. According to the above formula, the higher the IoU, the greater the loss, which is more conducive to improving the regression accuracy.
In Figure 7, the blue curve represents the IOULoss curve, while the orange curve represents the Focal-EIOULoss curve. The loss for low-quality samples with an IOU less than 0.8 is reduced, while the loss for higher-quality samples with an IOU greater than 0.8 remains essentially unchanged. This effectively diminishes the impact of low-quality samples on overall loss computation. Focal-EIOU integrates IOU, center point distance, aspect ratio and FocalLoss into the detection framework to achieve superior regression performance.
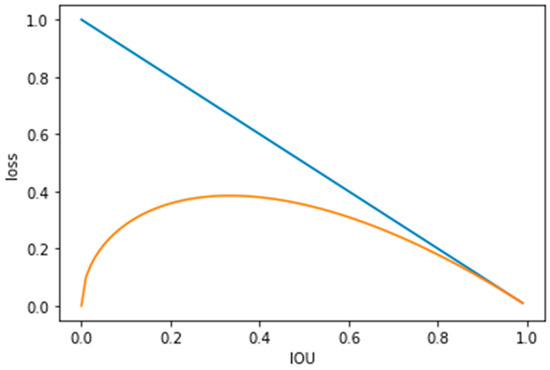
Figure 7.
Schematic diagram of Focal-EIOU for mitigating the impact of low-quality samples on result accuracy.
2.2.4. Model Improvement Summary and Verification of Improvement Effects
The changes in the architecture of the entire YOLOv5s network after adding Shuffle Attention, CoordConv, and Focal-EioU are mainly reflected in the following aspects:
- (1)
- Shuffle Attention
Feature Processing: Shuffle Attention modules are added after the convolutional layers in the backbone network, neck network, or head. These modules process the feature maps and redistribute the feature weights. For example, when Shuffle Attention is added to the C3 modules in the backbone network or the feature fusion parts in the PANet structure of the neck network, the network can adaptively focus on more important feature channels and suppress unimportant ones. This helps to highlight features related to objects and reduce the interference of background noise on features.
Network Connections: From the perspective of network connections, adding Shuffle Attention modules inserts a new processing step between the original convolutional layers and subsequent operations (such as feature fusion, up-sampling, or down-sampling). For example, in the backbone network, when Shuffle Attention modules are connected after the outputs of some convolutional layers, their outputs are then connected to the next-level operations, which may be the next convolutional layer or feature fusion operation, etc., changing the way features are passed.
- (2)
- CoordConv
Convolution Layer Modifications: Some convolutional layers in the YOLOv5s backbone and neck networks are replaced with CoordConv. CoordConv adds coordinate information to traditional convolution operations. For example, when CoordConv is used in some down-sampling convolutional layers (such as 3-P3/8, 5-P4/16, etc.) in the backbone network, the network can better perceive the position information of objects in the image. This is very helpful for dealing with objects at different positions, especially when objects are close to the image edges or distributed in irregular positions.
Feature Representation: Since CoordConv introduces coordinate information, each pixel in the feature map contains not only the original image content information but also its position information in the image. This enables subsequent feature processing and object detection operations to use position information for more accurate positioning and classification. For example, when performing feature fusion in the neck network, feature maps with coordinate information can better match features at different levels, improving the effect of feature fusion.
- (3)
- Focal-EIoU
Loss Function-related: Focal-EIoU mainly affects the loss function part. In the training process of YOLOv5s, the function used to calculate the bounding box regression loss is replaced or improved with Focal-EIoU. In the detection head, when calculating the loss between the predicted boxes and the ground-truth boxes, Focal-EIoU comprehensively considers factors such as intersection-over-union (IOU), center point distance, aspect ratio, etc., and combines the idea of Focal Loss, paying more attention to hard-to-classify samples.
Training Dynamics: From the perspective of network training dynamics, using Focal-EIoU changes the convergence speed and effect of the network during training. Since it deals with the bounding box regression problem more effectively, the network can converge to better detection performance faster and be more stable when dealing with objects of different sizes and shapes.
In general, after adding these modules, the YOLOv5s network undergoes significant changes in feature processing, feature representation, and loss calculation, aiming to improve the network’s object detection accuracy and efficiency.
Next, a comparison is made between the model with added shuffle attention mechanism, the model with added CoordConv convolution layer and the model using FocalEIOU (Improved YOLOv5) and the unimproved model (YOLOv5). Whether the improvement can enhance the training effect is verified from the position loss (box_loss), object loss (obj_loss), and recognition accuracy (mAP0.5) of the verification set. As can be seen from the following Figure 8, the performance of the optimized model on parameters such as box_loss, obj_loss, and mAP0.5 is significantly improved.
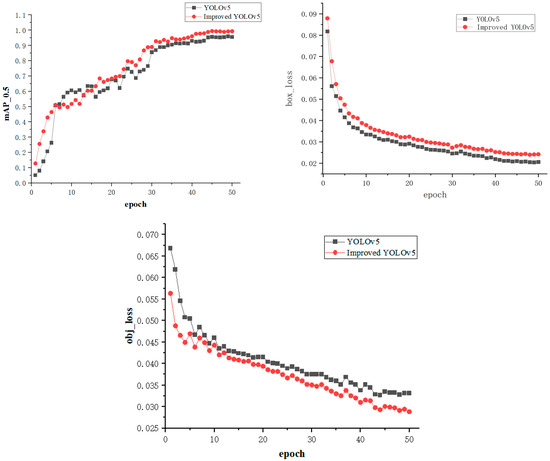
Figure 8.
Comparison between Improved YOLOv5 and YOLOv5.
2.3. The Object Tracking Method—DeepSORT Algorithm
DeepSORT algorithm is a multi-target tracking algorithm, and its recognition process is shown in Figure 9. Kalman filter is used to predict targets between successive frames and update detection boxes, and each target can be assigned an ID and tracked and identified. The IOU between the detection box and the prediction box and the appearance information of the target are associated and matched by the Hungarian algorithm. Even if the target is obscured for a short period of time, the ID can still be correctly matched as long as it appears again within a certain period of time [16].
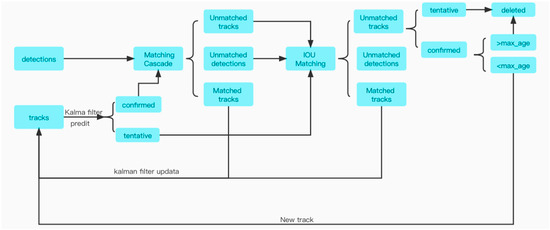
Figure 9.
Implementation flow of DeepSORT algorithm.
The tracking and recognition method of DeepSORT algorithm is as follows:
(1) Revised sentence: Utilize the YOLO target detection algorithm to identify targets within video frames and employ pre-trained detection models to extract distinctive features of each identified target.
(2) Associated goals: for each target in the current frame that has been associated with tracking targets in previous frames, a distance matrix is obtained by calculating both Mahalanobis and Euclidean distances. The Mahalanobis distance (Formula (3)) measures the similarity between vehicles in the image by taking into account their correlation and covariance. The Euclidean distance (Formula (4)) is utilized to quantify the positional information between vehicles by computing the linear distance among data points, and each target is associated with its nearest tracked target based on a weight matrix pair.
where is the covariance matrix and and are the picture information matrix between different frames. represent coordinate position information of targets in different frames.
(3) State prediction: Based on the historical trajectory of the tracked target, a Kalman filter is employed to estimate the state variables of each target, encompassing position, velocity, and acceleration.
(4) Revised sentence: Updating the tracking characteristics in the current frame is achieved by utilizing the unique features of each target.
(5) Utilizing the Kalman filter, each detected object ID set counter is evaluated and deleted based on a specified threshold (e.g., IoU) and track conditions such as time. When the prediction result aligns with the testing results of YOLO, indicating accurate prediction, the counter is reset to zero. Conversely, if inconsistent detection results persist for an extended period of time, it is deemed that the tracked target has been lost and its corresponding ID will be removed.
(6) Label: If a frame in the new test results (i.e., with the current tracking results) fails to match the test result, it suggests a potential new target. If the predicted trajectory of the new tracker on this target matches its detection result for three consecutive frames, then it is confirmed that a new target has emerged and is assigned a unique ID. Otherwise, the ID will be deleted.
By cycling through the above six steps, continuous track vehicle detection can be realized.
3. Experimental Verification and Result Analysis
The experimental flow of vehicle detection, as implemented by YOLOv5s, is illustrated in Figure 10.

Figure 10.
Flowchart of vehicle detection.
3.1. Data Pre-Processing
- (1)
- Training data acquisition
After data augmentation and label processing, a training set of 6400 images is obtained, while a verification set of 300 images and a test set of 600 images are selected.
To mitigate the risk of overfitting during training, the mosaic data augmentation method is employed to preprocess our training images. This involved randomly selecting four images and combining them through techniques such as random cropping, scaling, occlusion, and layout adjustments, as shown in Figure 11.
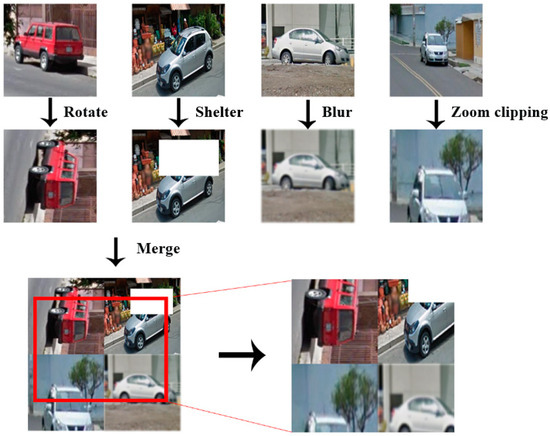
Figure 11.
Data enhancement by mosaic.
- (2)
- Label processing
After the training image data are enhanced, the operation of adding labels is carried out. The position of labels will directly affect the training effect of the model. Here, the labelme label making tool is adopted, and the vehicle in the picture is selected with the frame selection tool, and the category information is marked for the selected area of the frame. The label information in.json format is obtained by the labelme tool after annotation, while the label format supported by YOLOv5s is in .txt format, which is converted to the corresponding format and used. The annotated picture is shown in Figure 12.
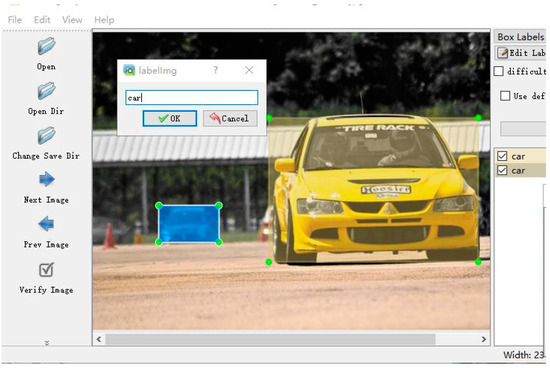
Figure 12.
Label processing.
- (3)
- Model training
The computer GPU used for training in this paper is GTX 1650 with 4G of video memory. Considering the actual operating conditions and data set size, YOLOv5s.yaml is adopted as the model configuration file in the actual training. The sizes of ‘depth_multiple’ and ‘width_multiple’ are 0.33 and 0.5, respectively.
On the command line, the configuration file of the training image, the pre-training weight file, the number of times the epoch is run, the batchsize size, and the configuration of hyperparameters are specified, as shown in Table 2.
Table 2.
Training parameters.
The training iteration process is shown in Figure 13:
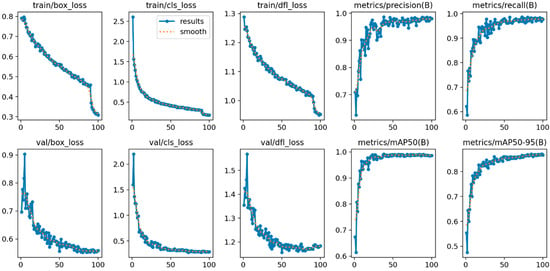
Figure 13.
Training iteration process.
3.2. Analysis of Target Detection Results
3.2.1. Evaluation Indicator
To evaluate the accuracy of the YOLOv5s model in mussel image recognition, this paper adopts the performance indicators commonly used in object detection, including precision (Precision, P), recall (Recall, R), mean average precision (mean average precision, mAP), and detection time (Time, t). The specific calculation formulas are as follows: precision refers to the proportion of correctly predicted targets among all targets predicted by the model and can be called the precision rate.
In the formula, is the number of detection frames with IoU > 0.5, that is, the number of mussels correctly identified by the model; is the number of detection frames with IoU ≤ 0.5, that is, the number of mussels incorrectly identified by the model. Recall refers to the proportion of correctly predicted targets among all true targets and can be called the recall rate.
In the formula, is the number of mussels that the model fails to recognize.
(average precision) refers to the average precision of a single category, and mAP refers to the average of the AP of various categories. In this paper, mAP_0.5 and mAP_0.5:0.95 are used to evaluate the model. mAP_0.5 represents the average precision when IoU is set to 0.5, and mAP_0.5:0.95 represents the average precision when IoU ranges from 0.5 to 0.95 with a step size of 0.05.
In the formula, is the number of category of targets that the model can detect.
3.2.2. Attention Mechanism Experiment
To study the effect of the Shuffle attention mechanism (SA) in the YOLOv5s mode, coordinate attention mechanism CA, squeeze-and-excitation network mechanism SE, and parameter-free attention mechanism SimAM are experimentally compared on the vehicle dataset. The experimental results are shown in Table 3, and the mAP_0.5:0.95 of different attention mechanisms is shown in Figure 14. The experimental results show that the SA attention mechanism has the best effect, improves the average accuracy, and verifies its effectiveness in feature extraction.
Table 3.
Experimental results of attention mechanism.
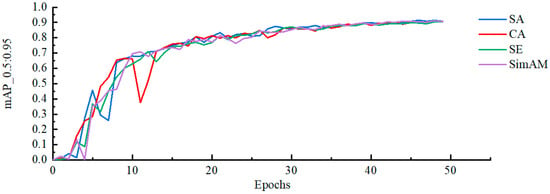
Figure 14.
Different attention mechanisms mAP_0.5:0.95 curve plot.
3.2.3. Loss Function Experiment
To verify the high efficiency of the Focal-EIoU bounding box regression loss function in the YOLOv5s model, in this section, a comparison experiment is conducted between it and the complete loss function CIoU and the effective loss function EIoU bounding box regression loss functions. The experimental results of the loss function are shown in Table 4, and the mAP_0.5:0.95 and box_loss of different loss functions are shown in Figure 15 and Figure 16. The experimental results showed that Focal-EIoU had the lowest loss function box_loss, and the mAP_0.5:0.95 was improved to 90.833%, which was better than the other two. This indicates that the Focal-EIoU loss function can improve the accuracy of mussel target detection.
Table 4.
Experimental results of Loss function.
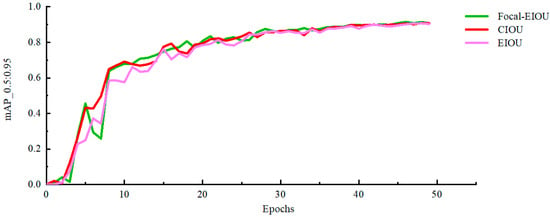
Figure 15.
Loss function mAP_0.5:0.95 curve plot.
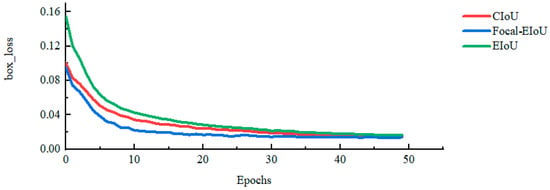
Figure 16.
Loss function box_Loss curve.
3.2.4. Ablation Experiment
To verify the effectiveness of the optimized algorithm in improving model performance, this paper conducts a series of ablation experiments to compare the impacts of different modules and their combinations on the performance of the object detection algorithm. Selecting YOLOv5s as the baseline algorithm, experiments are conducted on the self-made vehicle dataset. The ablation experiment results are shown in Table 5, and the mAP_0.5:0.95 situation is shown in Figure 17.
Table 5.
Results of ablation experiment.
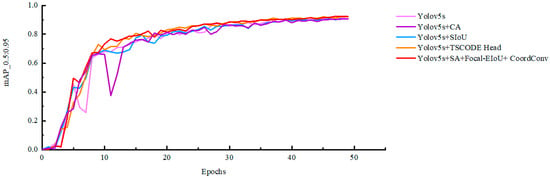
Figure 17.
Ablation experiment mAP_0.5:0.95 curve.
The experimental results show that the best object detection performance is achieved when the fused attention mechanism SA is adopted simultaneously, the Focal-EIoU bounding box regression loss function is introduced, and the convolutional network is replaced with CoordConv. Compared with YOLOv5s, the precision of the CST-YOLO algorithm is increased by 0.484%, the recall rate is decreased by 0.131%, mAP_0.5 is increased by 0.003%, and mAP_0.5:0.95 is increased by 1.747%. The results indicate that the optimized algorithm can improve the object detection effect and prove its advantage in vehicle object detection performance.
3.2.5. Contrast Experiment
To prove the effectiveness of the algorithm proposed in this paper for mussel object detection, in this section, it is experimentally compared with the YOLOv5s algorithm and the Faster R-CNN algorithm on the self-made mussel dataset. The experimental results are shown in Table 6.
Table 6.
Comparison of experimental results.
The experimental results show that Faster R-CNN, as a two-stage object detection algorithm with ResNet50 as the main network, has a large model structure and slow detection speed, with mAP_0.5:0.95 being 91.3%. The detection speed of the Optimized-YOLO algorithm is 83 times higher than that of the Faster R-CNN algorithm. Although it has decreased compared to the YOLOv5s algorithm, it can still meet the real-time detection requirements. The mAP_0.5:0.95 of the Optimized-YOLO algorithm is 92.221%, which is 1.747% higher than that of the YOLOv5s algorithm. The experimental results indicate that the Optimized-YOLO algorithm improves the detection accuracy while ensuring the detection speed and shows superiority in mussel object detection.
3.3. Identify Processes and Operational Results
Image detection: Figure 18 illustrates the result of image detection, wherein the identified vehicle is enclosed in a rectangular box and its category and confidence level are displayed at the top. A higher confidence value indicates a greater likelihood that the object is indeed a car.

Figure 18.
Original image (upper half of the layer) and detection result (lower half of the layer).
In addition, vehicle recognition has also been carried out under some special backgrounds such as “Rainy day, Night-time, Shadow, Shied, Dim and Pale”. The recognition results are shown in Figure 19. It can be seen from the recognition results that the optimized recognition algorithm has relatively good robustness and has met the practical requirements.

Figure 19.
Recognition under special backgrounds.
Video detection: It enables the prediction of vehicle movement across consecutive frames and facilitates the updating of detection boxes. The identified vehicles are enclosed within rectangular bounding boxes, displaying category information and ID details on top. Even if a target vehicle is temporarily obscured, its ID can still be accurately matched as long as it reappears within a specific time period. As depicted in Figure 20, the video detection system employs a monitoring screen of the intersection in MP4 format and captures three consecutive frames sequentially. It is evident that the movements of vehicles with ID-2, ID-5, and ID-6 can be continuously tracked and monitored.

Figure 20.
Video detection and vehicle tracking by DeepSORT.
By synthesizing all the improved effects, separate tests were conducted on vehicle tracking detection in pictures and videos, yielding satisfactory results.
4. Conclusions
(1) In this paper, the YOLOv5s network architecture and the process of vehicle detection are deeply studied. Combined with the understanding of the YOLOv5s algorithm, the backbone in the network architecture of the YOLOv5s algorithm was analyzed, and the model optimization direction was determined according to the characteristics of the target objects. And the overall process of vehicle detection is determined, including data set collection, data enhancement and model training. The trained weight file and DeepSORT tracking detection algorithm are used to realize vehicle detection.
(2) In terms of the regression effect of detection frame, this paper provides a theoretical analysis on the advantages and disadvantages of IOU and its variants in vehicle detection. The CoordConv convolutional layer, which contains more spatial position information, enhances the original network structure and improves the accuracy of vehicle positioning. The attention mechanism of Shuffle Attentain is analyzed and incorporated into the network structure of YOLOv5s to enhance training, improve detection accuracy, and increase running speed. Additionally, the network structure is optimized to further improve algorithm performance.
(3) Through conducting comparative experiments on the self-made vehicle dataset, the results demonstrate that compared with the YOLOv5 algorithm, the accuracy rate P of the improved YOLOv5s algorithm is increased by 0.484%. Moreover, mAP_0.5:0.95 reaches 92.221%, an increase of 1.747%. This indicates that the algorithm can effectively enhance the detection accuracy of vehicle targets and provides certain technical support for addressing issues such as image blur and target occlusion in practical applications.
Discussion of Model Limitations
One of the main limitations is its performance under extremely low-light or high- noise conditions. Although the model has shown good results in general scenarios, the accuracy of object detection may decrease when the image quality is severely degraded. The possible reasons for the model’s performance limitations under extremely low-light or high-noise conditions are as follows. First, the feature extraction is restricted due to blurred object information and lack of samples in training data. Second, the model structure has limitations. Third, noise and low-light change object features and interfere with pixel values.
Another limitation is the model’s computational complexity. Although efforts have been made to optimize the model structure, it still requires significant computational resources during training and inference, which may limit its application in resource-constrained environments. Potential future improvement directions include exploring advanced feature extraction techniques for poor-quality images, developing efficient architectures to cut computational costs, incorporating more relevant data sources or augmentation strategies, and improving the training process with better optimization algorithms.
Funding
This research received no external funding.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The author declares no conflict of interest.
References
- Ge, G.-y.; Yao, X.-f.; Xiang, W.-j.; Chen, Y.-p. Vehicle detection and tracking based on video image processing in intelligent transportation system. Neural Comput. Appl. 2022, 35, 2197–2209. [Google Scholar] [CrossRef]
- Wang, J.; Dong, Y.; Zhao, S.; Zhang, Z. A High-Precision Vehicle Detection and Tracking Method Based on the Attention Mechanism. Sensors 2023, 23, 724. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y. Deep learning for 3D object detection and tracking in autonomous driving: A brief survey. arXiv 2023, arXiv:2311.06043. Available online: https://arxiv.org/pdf/2311.06043 (accessed on 24 November 2024).
- Li, C.; Ge, L. A Lightweight Low-illumination Object Detection Algorithm Based on YOLOv7. Laser Optoelectron. Prog. 2024, 61, 1437004. [Google Scholar]
- Li, D.; Jiang, G.; Yang, J.; Bai, Y.; Xie, Y.; Wang, C. Detection and Tracking Algorithm for Hypoxic Stress Behavior of Fish Based on Computer Vision. Trans. Chin. Soc. Agric. Mach. 2023, 54, 399–406. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. YOLOv5s[EB/OL]. Available online: https://github.com/ultralytics/yolov5 (accessed on 24 November 2024).
- Zhan, W.; Sun, C.; Wang, M.; She, J.; Zhang, Y.; Zhang, Z.; Sun, Y. An improved YOLOv5s real-time detection method for small objects captured by UAV. Soft Comput. 2022, 26, 361–373. [Google Scholar] [CrossRef]
- Liu, R.; Lehman, J.; Molino, P.; Petroski Such, F.; Frank, E.; Sergeev, A.; Yosinski, J. An intriguing failing of convolutional neural networks and the CoordConv solution. arXiv 2018, arXiv:1807.03247. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. arXiv 2017, arXiv:1703.07402. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).