Abstract
For information security, entity and relation extraction can be applied in sensitive information protection, data leakage detection, and other aspects. The current approaches to entity relation extraction not only ignore the relevance and dependency between name entity recognition and relation extraction but also may result in the cumulative propagation of errors. To solve this problem, it is proposed that an end-to-end joint entity and relation extraction model based on the Attention mechanism and Graph Convolutional Network (GCN) to simultaneously extract named entities and their relationships. The model includes three parts: the detection of entity span, the construction of an entity relation weighted graph, and the inference of entity relation type. Firstly, the detection of entity spans is viewed as a sequence labeling problem, and a multi-feature fusion approach for word embedding representation is designed to calculate all entity spans in a sentence to form an entity span matrix. Secondly, the entity span matrix is employed in the Multi-Head Attention mechanism for constructing the weighted adjacency matrix of the entity relation graph. Finally, for the inference of entity relation type, considering the interaction between entities and relations, the entity span matrix and relation connection matrix are simultaneously fed into the GCN for integrated extraction of entities and relations. Our model is evaluated on the public NYT dataset, attaining a precision of 66.4%, a recall of 63.1%, and an F1 score of 64.7% for joint entity and relation extraction, significantly outperforming other approaches. Experiments demonstrate that the proposed model is helpful for inferring entities and relations, considering the interaction between entities and relations through the Attention mechanism and GCN.
1. Introduction
In information security situational awareness systems, entity relation extraction can help construct entity relationship networks in cyberspace, enabling real-time monitoring and analysis of security incidents and abnormal behaviors within the network [1]. Through in-depth mining and analysis of entity relationships, potential security threats and attack paths can be discovered. How to extract effective information from text quickly and efficiently has become an important issue.
The end-to-end method maps the input sentence into meaningful vectors and then produces the tag sequence. This method is widely used in sequence tagging tasks [2] as well as in entity and relation extraction [3]. As the core task of information extraction, the main task of entity relation extraction is to simultaneously detect entities and their relations from unstructured texts. Entities are words in the given sentence. Relation words are extracted from a predefined relational set, which may not be explicitly present in the given sentence. For instance, in the phrase “Qingdao is in the territory of Shandong Province”, “Qingdao” is an entity, “Shandong” is an entity, and the relation of the two entities is classified as “located in” in the predefined relational set. Entity recognition and relation extraction are pivotal stages in constructing knowledge bases and are instrumental in diverse natural language processing applications, such as semantic analysis and question answering systems, occupying a vital role in enhancing the understanding and utilization of text data.
To solve the problems of entity relation extraction, many methods have been proposed. According to the order of name entity recognition and relation extraction, these methods can be divided into two classes: pipeline learning and joint extraction learning. In the pipeline models, named entity recognition and relation extraction are regarded as independent subtasks. Firstly, named entity extraction is used to extract entities, and then the relation is extracted based on named entity recognition. The separated framework is conducive to the modularization of different stages of language understanding, making tasks easier to handle and each component more flexible. However, each subtask is treated as an independent model, which ignores the correlation between the two subtasks. The results of named entity recognition may potentially affect the results of relation extraction. Seriously, it will lead to error propagation, producing unsatisfactory performance.
In contrast to pipeline methods, joint extraction approaches concurrently identify entities and their relations within a unified model. These methods can utilize the mutual information between entities and relations, achieving superior results in the field of entity relation extraction. However, the majority of current joint extraction techniques rely heavily on feature engineering [4], which involves constructing feature vectors by extracting semantic features from sentences. Subsequently, algorithms such as Conditional Random Field (CRF) and Support Vector Machine (SVM) are employed to extract relations. These methods require intricate feature engineering and a large workload. They also rely heavily on Natural Language Processing (NLP) toolkits, which may lead to error propagation. In order to reduce the workload of feature engineering, an end-to-end entity relation extraction based on neural networks has been successfully applied to the task. In recent years, the research of Graph Neural Networks (GNN) has received more and more attention, and GNN has been successfully applied to many NLP tasks, such as Machine Translation [5], Text Classification [6], Semantic Role Labeling [7], and Relation Extraction [8].
However, the intricate interactions between entities are ignored in the above models. In this paper, an end-to-end relation extraction model is proposed that utilizes GCNs and an attention mechanism to jointly learn entities and their relations. The proposed joint extraction model is divided into three parts: entity span detection, construction of an entity–relation weighted graph, and inference of entity relation types. Firstly, entity span detection is treated as a sequence labeling problem. A multi-feature fusion word vector representation approach is devised to identify all entity spans within sentences, thereby constructing an entity span matrix. Then, for the construction of the entity relation weighted graph, based on the attention mechanism, the entity span matrix is input into the Multi-Head attention model. The entity relation weights are calculated to form the relation adjacency matrix. Finally, for the inference of entity relation types, considering the interaction between entities and relations, a joint model based on GCN is proposed. Based on the entity span matrix and relation adjacency matrix obtained in the previous stages, the entities and relations are jointly inferred to get the final entity relations.
2. Related Work
The task of joint extraction of entities and relations is to simultaneously extract entities and relations between two entities. There has been a lot of research on entity and relation extraction. The problem we focused on is related to GCN, attention mechanisms, and extraction of entities and relations.
2.1. GCN
GCN is a network structure that performs semi-supervised learning on graph structure data in a scalable method and is an effective variant of neural network. In GCN, the convolution is performed directly, and the convolution architecture is improved by the first-order approximate localization of the spectral graph convolution.
Several studies have demonstrated the powerful capabilities of GCNs. Gilmer et al. [9] explored the effectiveness of message passing in quantum chemistry by applying GNNs to predict molecular properties. Garcia & Bruna [10] demonstrated the capability of GNNs to learn classifiers on image datasets in a few-shot learning paradigm. Dhingra et al. [11] applied message passing on graphs constructed from common reference links to answer relational questions. Kipf & Welling (2016) [12] introduced GCNs and applied them to citation networks and knowledge graph datasets, marking a significant milestone. Marcheggiani & Titov [6] further extended GCNs to sequence labeling for semantic role labeling, while Liu et al. (2018) [13] utilized GCNs to encode long documents for text matching tasks. Schlichtkrull et al. [14] applied GNNs to knowledge base completion and Zhang et al. [15] encoded dependency trees with GNNs for relation extraction. Lastly, Cao et al. [16] demonstrated the effectiveness of GNNs in multi-hop question answering by encoding co-occurrence and coreference relations.
GCNs offer several advantages in text mining by providing a powerful and flexible framework for modeling and analyzing textual data as graphs. Their ability to capture complex relationships, incorporate contextual information, and propagate relevant information efficiently makes them a valuable tool for tackling a wide range of text mining tasks.
2.2. Attention Mechanism
The attention mechanism dynamically assigns varying weight parameters to each input element, thereby emphasizing relevant aspects while suppressing irrelevant information. Its main advantage lies in its capability to concurrently consider both global and local connections, facilitating parallel computing.
As the attention mechanism has been widely applied to image processing tasks, some researchers have tried to use the attention mechanism to enhance neural networks and apply them to NLP. The Google team [17] propelled attention to the forefront of research by proposing the Self-Attention mechanism for machine translation, revolutionizing text representation learning. Zheng Y. et al. [18] devised a deep learning architecture that seamlessly fused BiLSTM (Bidirectional Long Short-Term Memory) with an attention mechanism, emphatically demonstrating the important role of the attention mechanism in enhancing the model’s performance for text classification tasks. The integration emphasized the significance of guiding the model’s focus on the most informative parts of the text, thereby improving classification accuracy and efficiency. Furthermore, Y. Liu et al. [19] introduced an innovative approach that harnesses both the attention mechanism and an embedding perturbed encoder, significantly bolstering the style transfer quality of text sentiment.
Attention mechanisms help capture context-specific details that might otherwise be overlooked by traditional models. This targeted focus results in a more precise understanding and representation of the text’s content, leading to better performance in tasks such as sentiment analysis, topic classification, and question answering.
2.3. Extraction of Entities and Relations
Joint extraction of entities and relations is a crucial step in constructing knowledge bases, which can significantly benefit numerous NLP applications. At present, two main frameworks have been widely used to solve the problem of entity relation extraction. One is the pipeline method, and the other is the joint learning method.
Pipeline methods, employed in earlier works [20], treat the task as two discrete tasks. Initially, entities within sentences are identified and extracted. Subsequently, the relations among these recognized entities are obtained. Ultimately, these entity–relation triples are output as the predicted outcomes. However, the inherent error propagation in pipeline methods has promoted the emergence of joint extraction of entities and relations. Based on the principle of parameter sharing strategy, Miwa and Bansal [21] first used neural networks to jointly extract entities and relations. The approach incorporated sentence-level Recurrent Neural Networks (RNNs) for entity extraction and dependency tree-based RNNs for relation prediction. Furthermore, Katiyar and Cardie [22] first used the attention mechanism and BiLSTM to jointly extract entities and relations. The model can extend the defined relation types and is the first joint extraction model of a neural network in the true sense.
The aforementioned joint methods, while achieving joint learning through parameter sharing, often lack explicit interaction during type inference. Zheng et al. [3] proposed an entity relation extraction method based on a novel labeling strategy. Then the original joint model, which contained two subtasks of named entity recognition and relation extraction, had completely become a sequence labeling problem. Sequence labeling was used in the model to identify entities and relations at the same time, which avoided complex feature engineering. The entity relation triplets were directly obtained through an end-to-end neural network model, which solved the problem of entity redundancy. Zeng et al. [23] proposed to use a BiLSTM encoder and multiple LSTM (Long Short-Term Memory) decoders to get the relation triplets dynamically. A transition-based method was proposed to generate directed graphs that convert the joint task into a directed graph, which can model both entity–relationship and relationship–relationship dependencies [24]. Hidden layer vectors obtained from a pre-trained named entity recognition model were utilized as entity features, and there was no need to manually design entity features [25]. COTYPE was introduced, a domain-independent framework that learned embeddings from both text corpora and knowledge bases [26]. Utilizing heuristic data from knowledge bases, COTYPE extracted type entities and relations concurrently, demonstrating remarkable versatility and adaptability [27]. A prediction framework was designed that double-headed entities and relations based BERT are extracted. Relation Attention-Guided Graph Neural Networks were designed to extract joint entities in Chinese electronic medical records [28].
Owing to the excellent expressive capabilities of graphs, the research of GNN has received more and more attention. Initially, GNN was proposed by Gori et al. in an attempt to extend the neural network to handle arbitrary graphs. Sun et al. [29] proposed to use GCN to construct a graph structure to extract entity relations in sentences. A tagging scheme and designed Character Graph Convolutional Network was proposed to obtain character vectors in the text [4]. The Multi-Head Self-Attention Mechanism was seamlessly integrated within the BiLSTM encoding architecture, while the Dense Connected Convolutional Network was elegantly embedded in the decoding framework, facilitating a unified and efficient method for joint extraction of entities and relations from textual data. GCN was used to capture feature representations of the document-level dependency graph, where the dependency graph was used to capture dependency syntactic information across sentences [30]. The Multi-Head attention mechanism was used to learn relatively important contextual features from different semantic subspaces. Chen, Y. [31], on the other hand, presented a causality–extraction approach that integrated an entity-location-aware graph attention (GAT) mechanism. This innovative strategy effectively mitigated redundant content within graph-dependency trees and strengthened the connections between long-span entities, thereby enhancing the overall extraction capability.
Different from the above methods, an end-to-end relation extraction model is proposed in this paper. First, a multi-feature fusion word vector representation method is proposed to calculate all entity spans in sentences to form an entity span matrix. Then, based on the attention mechanism, the entity span matrix is input into the Multi-Head Attention model. The entity relation weights are calculated to form the relation adjacency matrix. Finally, a joint model based on GCN is put forward, the entities and relations are jointly inferred to get the final entity relations based on the entity span matrix and relation adjacency matrix obtained in the previous stages.
3. Research Methods
Firstly, the integrated extraction task of entities and relations is defined. Assuming is a sentence, , where represents a word and n denotes the sentence length. The task objective is to extract a group of entity span E and relation R from a given context s. The relation R is formulated as a triplet , where and represent the two distinct entity spans, and l signifies the specific type of relationship that interconnects these two entities.
The frame figure of the whole process is shown in Figure 1.
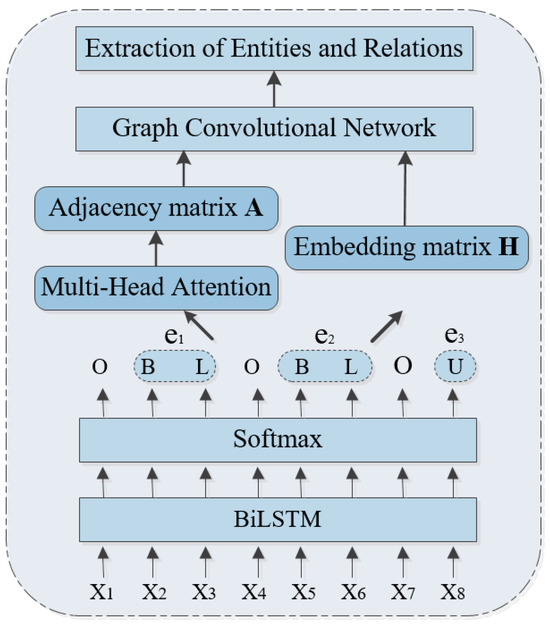
Figure 1.
The integrated extraction frame of entities and relations.
3.1. Entity Span Detection
For entity span detection, a tagging scheme is used to switch the task to a labeling question. Figure 2 is an example of how to mark the result of entity span.
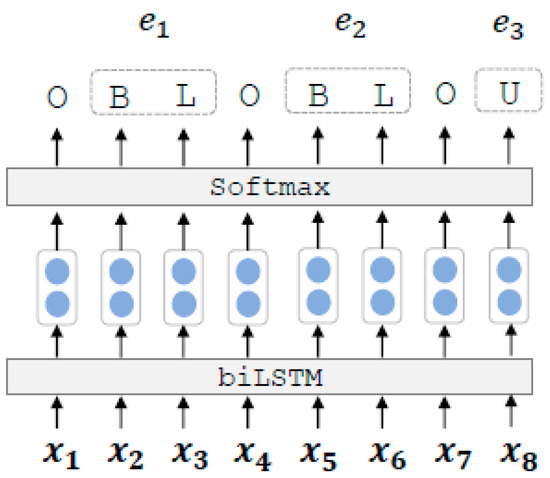
Figure 2.
Diagram of entity span detection.
The method of multi-feature fusion is used to train word embedding. In addition to using distributed word vector features, part-of-speech tagging and dependency parsing will also be used. Then the three parts of embedding are stitched together to form word embedding.
In the model of conventional neural networks, the issue of vanishing gradients appeared during training. The threshold mechanism introduced by LSTM effectively mitigates the vanishing gradient problem inherent in RNNs to a considerable degree. Nevertheless, information can only be propagated from front to back in LSTM, implying that the information at time t is solely reliant on the preceding information up to time t. To capture contextual features comprehensively at every temporal point, BiLSTM is employed to learn sentence representations. Forward and backward LSTMs are included in BiLSTM, enabling it to comprehend the semantic content of vocabulary to the fullest extent possible.
Ultimately, the softmax function is employed to forecast the label of , as shown in Figure 2. “BIESO” (Begin, Inside, End, Single, Other) is adopted to designate the positional status of words within an entity and to mark the entity span in a sentence. “B” and “E” express the “Begin” and “End” positions in the entity, respectively. “I” stands for the set of positions other than “Begin” and “End” in the entity, and “S” stands for the entity consisting of a single word. The label “O” stands for the “other” label, which represents that the word is not an entity in the sentence.
3.2. Calculation of Relation Weight
Next, edges are constructed between entity span nodes to indicate the strength of the correlation between entity span pairs. The input sentence is a sequence, and the relation extraction models based on the sequence only work on the word sequence, ignoring the non-local syntactic relation between words. Dependency-based relation extraction models use a syntactic dependency graph to construct tree-structure sentences, ignoring the relation information between entities. In view of the defects of the existing models, the attention mechanism is adopted to learn the connection relation between entity spans, construct an entity relation weighted graph, and finally form an adjacency matrix A of the entity spans. The attention mechanism is utilized to capture the interaction between two words in arbitrary positions of a sequence. The key idea is to use attention to deduce the relations between nodes, especially for those nodes that are indirectly connected by multi-hop paths. Multi-Head Attention [17] is adopted in this paper to compute the relation weight between entities. The structure of Multi-Head Attention is shown in Figure 3.
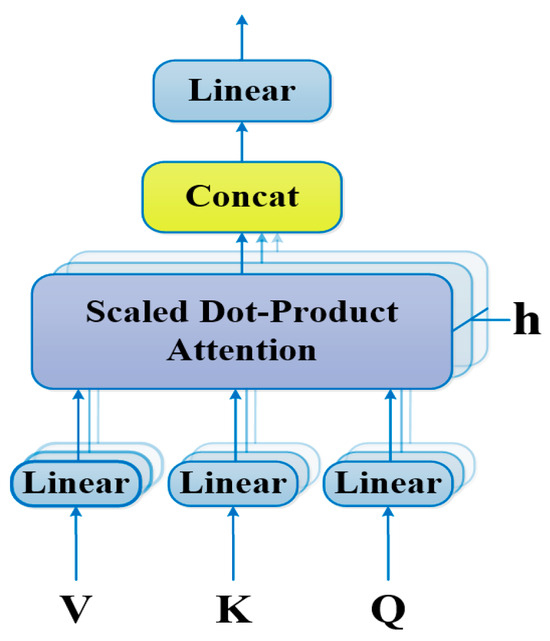
Figure 3.
Structure of the Multi-Head Attention.
The calculation formula of Multi-Head Attention is:
represents the i-th attention head, is a -dimensional query vector, is a -dimensional key vector, and is a -dimensional value vector. express the dimensionality of query, key, and value vectors. Initially, , and are the input word embeddings. , , and are the corresponding learnable parameters.
The most important part of Multi-Head Attention is Scaled Dot-Product Attention, whose framework is shown in Figure 4.
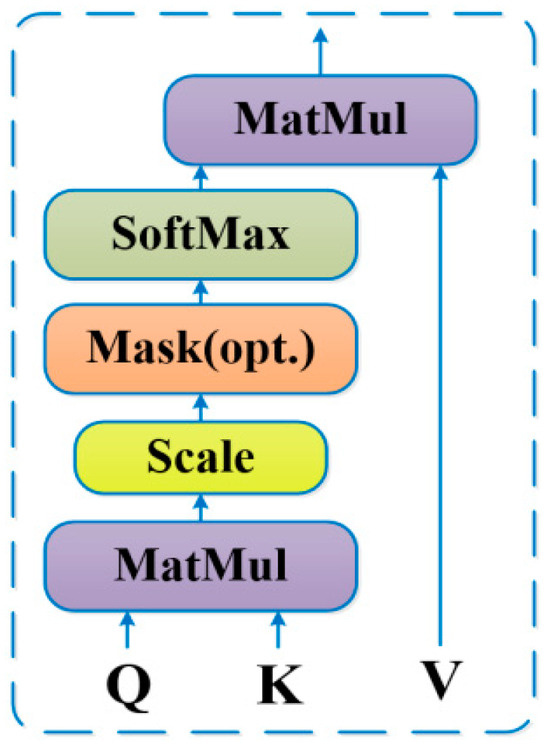
Figure 4.
Structure of the Scaled Dot-Product Attention.
The calculation formula of Scaled Dot-Product Attention is:
In order to use the Scaled Dot-Product Attention, and must have the same dimension. So in the model, and are mapped into dimension, and is mapped into dimension respectively by h = 8 different linear transformations. Then the above matrix is substituted into the attention mechanism to produce a total of -dimensional output. Then the encoded information from h subspaces is fused and the final output is obtained by a linear transformation.
The superiority of Multi-Head Attention is that it can acquire the global connection in one step and addresses the challenge of long-distance dependencies. Since parallel computing is performed directly in the matrix, it significantly reduces computational overhead and enhances overall efficiency.
To fully consider the relation information between two connected entities, Multi-Head Attention is used in this paper to construct a fully connected edge-weighted graph. The process is shown in Figure 5.
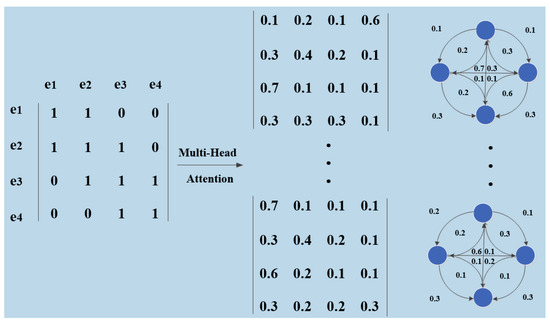
Figure 5.
Construction of relation weight graph.
3.3. Joint Type Inference
Considering the interactions between entities and relations, we devised a joint model based on GCN. The entity span matrix and relationship adjacency matrix obtained in the previous stages are used as inputs, and the entities and relations are jointly inferred to obtain the final entity relations. The architecture of GCN is displayed in Figure 6.
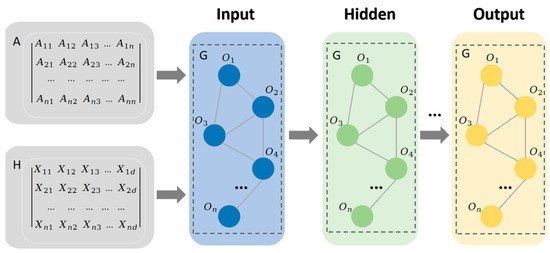
Figure 6.
The architecture of the GCN.
Given a graph with nodes, the nodes in the graph are denoted as to . The input part is the input node embedding matrix and adjacency matrix . represents the number of nodes and represents the embedding dimension of input nodes. Each row of represents the feature vector of the node, and denotes the connection relation between the nodes. means two nodes are connected. In an L-layer GCN, each layer is expressed as a nonlinear function:
Among them, , is the weight matrix of the L-th layer neural network, is a bias vector of the L-th layer, and is the nonlinear activation function of the network in the layer, such as ReLU, sigmoid.
By stacking multiple GCN layers, GCN can extract the local features of each node. Considering the different degrees and aggregation of different relations, two layers of GCN are used in this paper. First, matrix is obtained through preprocessing with . Then ReLU is utilized as the first layer activation function, and Softmax is adopted as the second layer activation function. Then the entire GCN is expressed as:
The traditional GCN only considered undirected graphs when designing. In order to consider the dependency between entities and relations, as well as the features of both incoming and outgoing, bi-GCN is used in this paper.
Specifically, based on the entity span extraction of the first part, the entity span matrix is obtained. Based on the relation weight calculation in the second part, the relation adjacency matrix is obtained. Then bi-GCN is applied to each graph to integrate entity relation information.
During the process of training, cross-entropy is adopted as the classification loss function. To comprehensively account for the interaction between the entities and the relations, the total loss function is defined as the sum of the entity loss and the relation loss :
In Formula (10), n means the number of entities in the sentence s. means the predicted label of the entity ei. y means the true label of the entity. means the probability that the model predicts the entity label as y given entity ei and s.
In Formula (11), ei, ej is a pair of entities within s. r means the relation label between entities ei and ej. P(r│ei, ej, s) means the probability that the model predicts the relation between ei and ei as given s.
4. Experiments
4.1. Dataset and Setting
To validate the performance of the devised methodology, the public dataset NYT (https://github.com/shanzhenren/CoType (accessed on 26 May 2020)) generated by the distant supervision method [26] is used. NYT includes training data 353 k triplets, test set 3880 triplets, and the size of the relation set is 24. To guarantee the accuracy of the experimental results, the average values of five randomly initialized experiments are utilized as the evaluation results.
The results are evaluated with Precision (P), Recall (R), and F1 scores. Specifically, if the output entity spans correctly encompass both e1 and e2, and the relation l is accurately identified, then the final result is deemed correct.
The pre-trained word vector Glove [32], which is 300-dimensional, is utilized as word embedding in this paper. Stanford CoreNLP is used to get part-of-speech tagging and dependency parsing of all data sets. The dimensionality of the distributed word vectors is 300, while that of the Part-of-Speech (POS) tagging and dependency parsing is 50, respectively. Other parameter settings are presented in Table 1.

Table 1.
The experiment parameter setting.
4.2. Experiment
4.2.1. Comparison with Existing Models
Firstly, to demonstrate the efficacy of the entity relation extraction model proposed in this paper, a comparative analysis is conducted between the proposed method and several existing models, utilizing a common corpus as the benchmark for evaluation. The compared approaches are as follows:
Pipeline models:
DS-logistic [33] is a sophisticated method that leverages both distant supervision and feature-based approaches, integrating supervised and unsupervised information for enhanced performance.
LINE [34] is a network embedding method capable of any type of information network.
FCM [35] is a combined model of linguistic vocabulary and word vector representation.
Joint models:
MultiR [36] is a distant supervision method based on a multi-instance learning algorithm, used to combat noisy training data.
CopyR [23] is an end-to-end model that employs a replication mechanism, proficiently addressing the issue of overlapping in a seamless manner.
Novel Tagging [3] introduces an innovative labeling scheme that transforms the complex joint extraction task into a more manageable sequence labeling problem.
The comparative experimental results of the various methods, including the proposed approach, are presented in Table 2. The best-performing results on each dataset are highlighted in bold for clarity.
Table 2.
The results of extraction of entity relation.
According to the data in Table 2, a comparison of various entity relation extraction experiments is illustrated in Figure 7, Figure 8 and Figure 9.
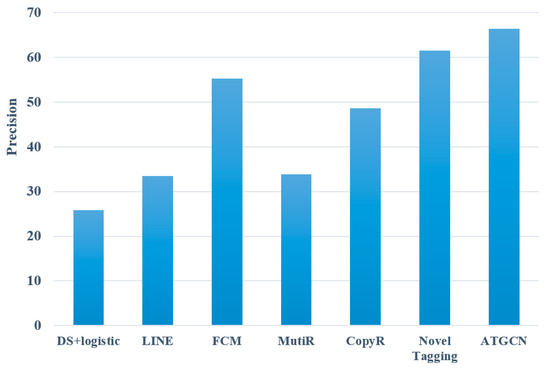
Figure 7.
Precision of different entity relation extraction models.
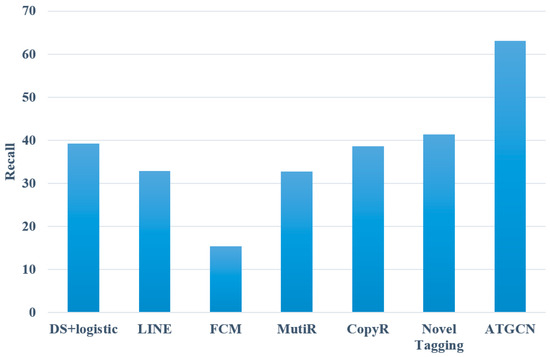
Figure 8.
Recall of various entity relation extraction models.
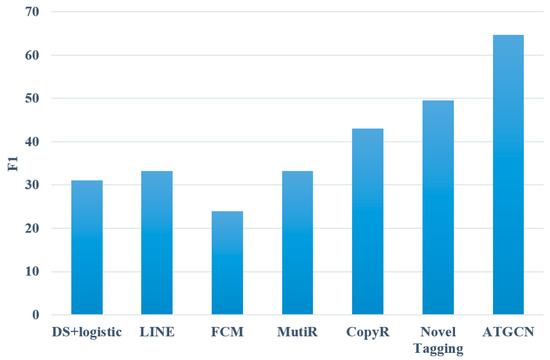
Figure 9.
F1 of different entity relation extraction models.
As evident from the above figures, the model introduced in this paper outperforms all baseline models in terms of precision, recall, and F1, reaching 66.4%, 63.1%, and 64.7%, respectively. This illustrates that the proposed method can effectively deal with the task of entity relation extraction. Compared with the pipeline methods, the model proposed in this paper improves the F1 value by 33.6%, 31.5%, and 40.7%, respectively, with an average increase of 35.3%. The reason may be that such methods ignore the relation between the two subtasks. At the same time, errors may occur in two independent subtasks, resulting in cumulative propagation, which ultimately affects the performance of the models. Compared with the joint extraction models, the model proposed in this paper improves the F1 value by 31.4%, 21.7%, and 15.2%, respectively, with an average increase of 22.8%. The reason may be that most of the joint extraction methods are feature-based models, which leads to unsatisfactory experimental results.
At the same time, it can be found from Figure 10 and Table 3 that the average precision, recall, and F1 values of the pipeline methods reach 38.2%, 29.2%, and 29.4% while the average precision, recall, and F1 values of the joint extraction methods are 48.0%, 37.6% and 41.9%. In contrast, the results of the proposed model are obviously better than these two methods, which is also as expected. Firstly, we used word vectors with different features to empower the learning capabilities of the model. Secondly, Multi-Head Attention is adapted to achieve the entity–relation connection graph to better measure the interaction between entities and relations. Finally, the entity information and relation information are trained by GCN, which can fully learn the entity relation information.
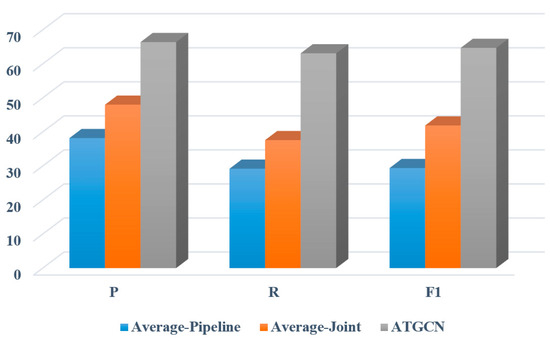
Figure 10.
Comparison of different entity relation extraction models.
Table 3.
Comparison of various entity relation extraction models.
4.2.2. Verification of Effectiveness
To validate the impact of each individual component within the proposed model, comparative experiments are performed with different settings to verify the contribution of each part.
- ① Influence of word vector
The deep learning method can effectively consider the syntactic structure information of sentences, so it is widely utilized in entity relation extraction tasks. However, the lexical features and semantic information of the two entities in the sentence cannot be well considered simultaneously in the method. Therefore, the part-of-speech features and dependency parsing features are placed into word embedding in this paper. The experimental outcomes are displayed in Table 4 and Figure 11.
Table 4.
Comparison of various word embedding.
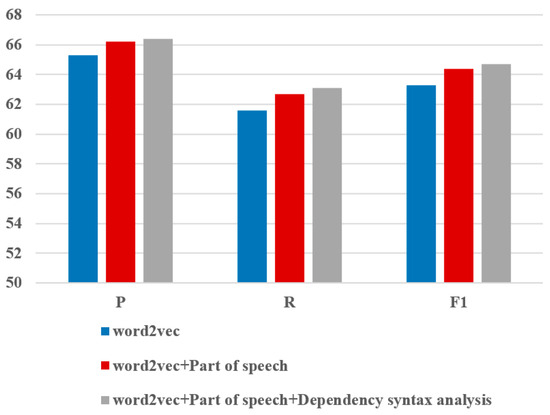
Figure 11.
Comparison of various word embedding.
The experimental outcomes demonstrate that compared with the word vector trained only with Word2vec, the multi-feature fusion word vector representation method proposed in this paper has obtained good results, increasing the precision, recall, and F1 values by 1.1%, 1.5%, and 1.4%, respectively. It can be seen from the experimental results that each feature has improved the performance, but the improvement contribution is not the same. Relatively speaking, the addition of part-of-speech features improved the experimental results significantly. Compared with the baseline experiment, precision, recall, and F1 values of “word2+ part of speech” method were improved by 0.9%, 1.1%, and 1.1%, respectively. The addition of dependency syntax analysis has limited improvement in recognition effects. Compared with “word2+ part of speech” experiment, precision, recall, and F1 values of muti-feature fusion method were improved by 0.2%, 0.4%, and 0.3%, respectively. In summary, the various features introduced in the word vector representation have been proven effective in this paper. The part-of-speech and the dependency syntax analysis of words in sentences significantly contribute to entity relation extraction.
- ② Influence of attention
Traditionally, sequence-based and dependency tree-based methods are usually used in entity relation extraction. Sun et al. [29] proposed to use the structure of entity relation bipartite graph in entity relation extraction. Considering the interaction between entities and relations, the original dependency tree is replaced with Self-Attention in this paper to generate a fully connected entity connection weighted graph. The experimental results of different methods are shown in Table 5 and Figure 12.
Table 5.
Comparison of different extraction models.
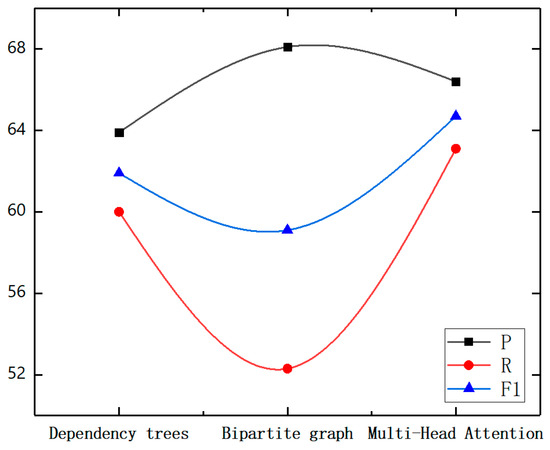
Figure 12.
Comparison of different extraction models.
It is evident from the experimental outcomes that compared with the method based on the dependency tree, the Self-Attention method proposed in this paper achieved better results, increasing the precision, recall, and F1 values by 2.5%, 3.1%, and 2.8%, respectively. The Self-Attention mechanism employed in the paper could attain the sequential information and non-local dependent words simultaneously.
Then GCN is used to consider the dependency between entities and relations, which can extract more abundant features to improve the performance of the relation extraction task. At the same time, it shows that the performance of entity relation extraction could be improved without any external syntactic tools, which saves unnecessary generation and propagation of some errors. Compared with the model based on the bipartite graph structure, the proposed Multi-Head Attention method in this paper improves recall and F1 by 10.8% and 5.6%, respectively, which are significant improvements. However, it has a poor performance in precision. The reason may be that the bipartite graph-based method can better represent the relation between two entities by using binary classification. On the whole, our model can obtain a higher F1 score, which is superior to the other two methods in overall performance.
- ③ Influence of GCN layer
The number of layers in GCN represents the reasoning ability of the model. Shallow GCN may not capture non-local interactions in the graph, while deep GCN can capture more information. However, according to experience, the two-layer GCN exhibits optimal experimental performance. To substantiate the impact of varying layer counts, comparative experiments are carried out with the different numbers of layers.
From Table 6 and Figure 13, we can see that when GCN has two layers, the experimental results reach the best. When the number of layers increases from one to two, the result is improved, which illustrates that the deeper GCN model can obtain abundant information and bring better performance. However, when the number of layers increases from two to three, the result of the experiment decreases. This may be due to the overfitting of the model. It also shows that a deeper GCN layer may not necessarily bring better experimental results.
Table 6.
Comparison of various GCN layers.
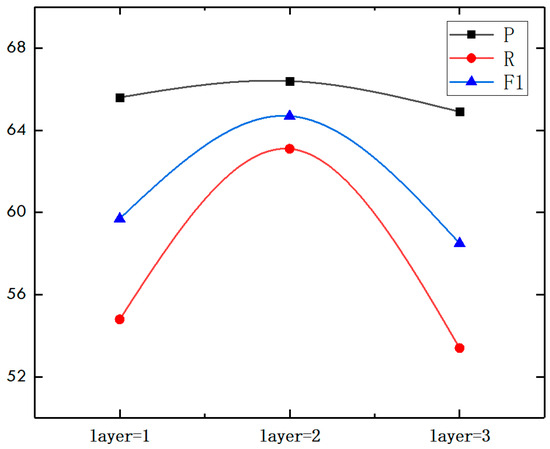
Figure 13.
Comparison of various GCN layers.
5. Conclusions
An end-to-end relation extraction model is presented that innovatively integrates GCN with an attention mechanism to facilitate the concurrent learning of entities and their relations. We introduce a novel multi-feature fusion technique for word vector representation, alongside a Multi-Head Attention model, which meticulously computes entity spans and relation weights across sentences. These computations culminate in the construction of an entity span matrix and a relation adjacency matrix, respectively. Subsequently, a joint model based on GCN is proposed, where entities and relations are seamlessly inferred based on these two matrices, ultimately yielding the definitive entity relations. The empirical evaluation of the NYT dataset demonstrates the model’s superiority in extracting entity relations, attributed to its nuanced consideration of the interaction between entities and relations, facilitated by the attention mechanism and GCN. Specifically, in the domain of information security, entity relation extraction plays a pivotal role in identifying potential threats, vulnerabilities, and actors involved in cyber attacks. Notably, while this work represents a significant step forward, it does not delve into the challenge of overlapping relation extraction. In future research, it is imperative to focus on analyzing and addressing this complex aspect, which holds immense potential for promoting the model’s applicability, particularly in the context of information security.
Author Contributions
Conceptualization, C.G. and Y.M.; methodology, Y.M., G.X. and C.G.; software, Y.M.; validation, Y.M. and G.X.; writing—original draft preparation, Y.M. and G.X.; writing—review and editing, C.G. and G.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Beijing Social Science Foundation Project, grant number 20YYB011.
Data Availability Statement
The data presented in this study are available in the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tang, X.; Shen, M.; Li, Q.; Zhu, L.; Xue, T.; Qu, Q. Pile: Robust privacy-preserving federated learning via verifiable perturbations. IEEE Trans. Dependable Secur. Comput. 2023, 20, 5005–5023. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. arXiv 2016, arXiv:1603.01360. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 1227–1236. [Google Scholar]
- Meng, Z.; Tian, S.; Yu, L.; Lv, Y. Joint extraction of entities and relations based on character graph convolutional network and multi-head self-attention mechanism. J. Exp. Theor. Artif. Intell. 2021, 33, 349–362. [Google Scholar] [CrossRef]
- Bastings, J.; Titov, I.; Aziz, W.; Marcheggiani, D.; Sima’An, K. Graph convolutional encoders for syntax-aware neural machine translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1957–1967. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Marcheggiani, D.; Titov, I. Encoding Sentences with Graph Convolutional Networks for Semantic Role Labeling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1506–1515. [Google Scholar]
- Fu, T.J.; Ma, W.Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1409–1418. [Google Scholar]
- Gilmer, J.; Schoenholz, S.; Riley, P.; Vinyals, O.; Dahl, G. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dhingra, B.; Yang, Z.; Cohen, W.; Salakhutdinov, R. Linguistic knowledge as memory for recurrent neural networks. arXiv 2017, arXiv:1703.02620. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Liu, B.; Zhang, T.; Niu, D.; Lin, J.; Lai, K.; Xu, Y. Matching long text documents via graph convolutional networks. arXiv 2018, arXiv:1802.07459. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Berg, R.V.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Semantic Web: 15th International Conference, Extended Semantic Web Conference (ESWC) 2018, Heraklion, Crete, Greece, 3–7 June 2018. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- De Cao, N.; Aziz, W.; Titov, I. Question answering by reasoning across documents with graph convolutional networks. arXiv 2018, arXiv:1808.09920. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zheng, Y.; Gao, Z.; Shen, J.; Zhai, X. Optimizing Automatic Text Classification Approach in Adaptive Online Collaborative Discussion–A Perspective of Attention Mechanism-Based Bi-LSTM. IEEE Trans. Learn. Technol. 2023, 16, 591–602. [Google Scholar] [CrossRef]
- Liu, Y.; He, M.; Yang, Q.; Jeon, G. An Unsupervised Framework With Attention Mechanism and Embedding Perturbed Encoder for Non-Parallel Text Sentiment Style Transfer. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2134–2144. [Google Scholar] [CrossRef]
- Rink, B.; Harabagiu, S. Utd: Classifying semantic relations by combining lexical and semantic resources. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 256–259. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using LSTMs on sequences and tree structures. In Proceedings of the 54rd Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint Extraction of Entity Mentions and Relations without Dependency Trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 917–928. [Google Scholar]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an End-to-End neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 506–514. [Google Scholar]
- Wang, S.; Zhang, Y.; Che, W.; Liu, T. Joint extraction of entities and relations based on a novel graph scheme. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4461–4467. [Google Scholar]
- Zhou, Y.; Huang, L.; Guo, T.; Hu, S.; Han, J. An attention-based model for joint extraction of entities and relations with implicit entity features. In Proceedings of the Companion Proceedings of The 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 729–737.
- Ren, X.; Wu, Z.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Abdelzaher, T.F.; Han, J. Cotype: Joint extraction of typed entities and relations with knowledge bases. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1015–1024. [Google Scholar]
- Xiao, Y.; Chen, G.; Du, C.; Li, L.; Yuan, Y.; Zou, J.; Liu, J. A Study on Double-Headed Entities and Relations Prediction Framework for Joint Triple Extraction. Mathematics 2023, 11, 4583. [Google Scholar] [CrossRef]
- Pang, Y.; Qin, X.; Zhang, Z. Specific Relation Attention-Guided Graph Neural Networks for Joint Entity and Relation Extraction in Chinese EMR. Appl. Sci. 2022, 12, 8493. [Google Scholar] [CrossRef]
- Sun, C.; Gong, Y.; Wu, Y.; Gong, M.; Duan, N. Joint Type Inference on Entities and Relations via Graph Convolutional Networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1361–1370. [Google Scholar]
- Wang, J.; Chen, X.; Zhang, Y.; Zhang, Y.; Wen, J.; Lin, H.; Yang, Z.; Wang, X. Document-level biomedical relation extraction using graph convolutional network and multihead attention: Algorithm development and validation. JMIR Med. Inform. 2020, 8, e17638. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wan, W.; Hu, J.; Wang, Y.; Huang, B. Complex Causal Extraction of Fusion of Entity Location Sensing and Graph Attention Networks. Information 2022, 13, 364. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Gormley, M.; Yu, M.; Dredze, M. Improved relation extraction with feature-rich compositional embedding models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–22 September 2015. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D. Knowledge based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, OR, USA, 19–24 June 2011; pp. 541–550. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).