1. Introduction
Online action detection [
1] plays an important role in computer vision for applications such as smart surveillance and human–computer interaction [
2,
3]. Unlike action recognition, which focuses solely on trimmed or pre-edited videos, online action detection involves the identification and localization of actions in real-time video streams as they unfold, enabling real-time decision-making even when the information is incomplete.
An online action detector architecture typically includes a feature extractor for processing input videos and a detection model that generates probabilities for
target action classes, along with an additional ‘background’ class, thereby constituting a (
K + 1) classification task. Note that the ‘background’ class is the key to localizing the actions within a video stream. Due to the significance of online action detection, several popular models have been extensively developed in recent years, such as TRN [
4], GateHUB [
5], and LSTR [
6].
Basically, there are two tasks closely related to online action detection: action recognition and temporal action localization. Action recognition [
7,
8] is the simplest task, where the goal is to classify a trimmed video segment into predefined target actions. Therefore, the entire video segment contains only one action and excludes other actions. However, when recognizing actions in unedited videos, where multiple actions may occur simultaneously or where there are moments without any action, action recognition alone may be insufficient. Temporal action localization [
9,
10], on the other hand, adds the additional challenge of identifying the time intervals of each action in untrimmed videos, which may involve different types of actions occurring simultaneously. This approach more accurately reflects real-world scenarios.
Unfortunately, both of the above-mentioned tasks share the drawback of typically being performed offline, meaning predictions are made only after the entire video has been viewed. This limitation hinders their practical applications in real-time scenarios. To tackle this problem, online action detection addresses this issue by making predictions based on past information at the current moment, unlike traditional methods that require processing information from all moments before making predictions for each time frame. In other words, online action detection tasks require the model to identify ongoing actions in a live video stream, even when only partial actions have been observed.
There are two well-known datasets for online action detection: Thumos14 [
11] and TVSeries [
1]. Many prominent online action detection models, which predominantly use image-based approaches, have been validated using these datasets. For this reason, this paper will not discuss skeleton-based methods. Among them, De Geest et al. [
1] were the first to introduce the task of online action detection and provided the TVSeries dataset. In the early stages of the online action detection field, 3D ConvNets [
7] were employed for spatio-temporal feature modeling across multiple frames, similar to their early use in action recognition. However, 3D ConvNets struggled to capture temporal correlations beyond their receptive fields. This led to the proposal of a two-stream feedback network with LSTM [
12] to model temporal dependencies [
13]. Inspired by human judgment, where current actions are often predicted based on anticipated future states, TRN [
4] used an LSTM model to predict future information and combined it with previously observed data for recognition. While these approaches rely on RNN models, they face challenges in effectively modeling long-term dependencies due to limited interaction between features. In recent years, significant breakthroughs have been achieved with Transformers in the fields of NLP and image recognition. Thus, OadTR [
14] was proposed, using Transformers instead of RNNs. Beyond enabling interactions between stored features, Transformers can also learn how past features influence current predictions.
Finally, building on these foundations, LSTR [
6] divided information into short-term memory and long-term memory and used Transformers to construct encoders and decoders, thus avoiding the limitations associated with RNNs [
12,
15,
16,
17].
While previous models have addressed many challenges in online action detection, this paper focuses on two under-explored issues in the field of online action detection, including the data imbalance caused by the background class and the similarity in features between the background class and the other target classes, both of which significantly hinder training effectiveness. The background class is unique compared to other target actions, but most prior methods, such as LSTR [
6], OadTR [
14], and TRN [
4], treated the background class as a regular class similar to the other target actions, directly undertaking a (
K + 1) classification task, where
denotes the number of target actions. However, in most real-world scenarios, the ‘background’ class occupies more frames than the target actions in video streams, leading to a data imbalance problem. Furthermore, the large number and diversity of frames cause the ‘background’ class to easily overlap with similar target actions in terms of features. As an attempt to solve the problem of data imbalance and feature similarity, this paper proposes a novel modeling approach based on the LSTR model to mitigate the training difficulties posed by these two issues.
In the video domain, addressing data imbalance remains a relatively unexplored topic. In contrast, the image domain benefits from data augmentation techniques that can effectively tackle this issue. However, traditional strategies from the image domain are not directly applicable to video data due to their temporal nature. CutMix [
18], a commonly used data augmentation technique in the image domain, overlays two different images and applies random erasing to enhance the dataset. VideoMix [
19] adapted the work of CutMix [
18] for the video domain. However, recent approaches to online action detection typically use the same dataset and feature extractor during training to ensure a fair comparison of model performance. At this stage, the data consist of offline-extracted features rather than raw images. Moreover, creating meaningful augmented action videos requires careful design of video process operations such as random erasing, cropping, translation, or overlay, which present limitations when adopting data augmentation techniques in the video domain.
Another approach relevant to our research is GateHub [
5], which employed focal loss to address the data imbalance issue, referred to as the “background suppression objective” in their work. Focal loss [
20] is commonly used to mitigate data imbalance by down-weighting the contribution of easy examples, thereby enabling the model to learn from harder examples. Inspired by this suppression mechanism, we developed our framework by incorporating an additional pathway to achieve a similar function. Unlike GateHub, which relies solely on training loss to tackle this problem, our proposed method strengthens predicted actions through an additional classifier, allowing the overall framework to make more stable predictions and achieve state-of-the-art performance on the dataset.
To the best of our knowledge, this work is the first to highlight these two challenges in the field of online action detection. The proposed framework for online action detection significantly addresses the training difficulties posed by these challenges. The contributions of this work include:
Identifying two specific challenges in online action detection: data imbalance caused by the background and the difficulty in classification due to the feature similarity between the background class and the target actions.
Proposing a framework for online action detection to mitigate the negative impacts of data imbalance and classification difficulty resulting from feature similarity between the background class and the target actions.
Developing a framework for online action detection where an additional action classifier is incorporated into the well-known model LSTR [
6].
Demonstrating through experimental results that the proposed framework for online action detection significantly improves performance on the Thumos14 dataset.
This paper is organized as follows.
Section 1 provides a brief introduction to online action detection.
Section 2 discusses the two challenges identified in this study.
Section 3 describes the proposed method.
Section 4 presents the experimental results, and
Section 5 concludes this paper.
2. Motivations
While the aforementioned methods address some challenges in online action detection to a certain extent, they share a common limitation of failing to explicitly distinguish the “background” class. Instead, a (
K )-class classifier is typically trained. Specifically, Equation (1) shows the output
y of a typical online action detection model:
where
is the number of target actions,
P(
i) is the probability of action
occurring, and
P(
background) denotes the union of probabilities of all non-target actions. The background is unique and can be represented as shown in Equation (2).
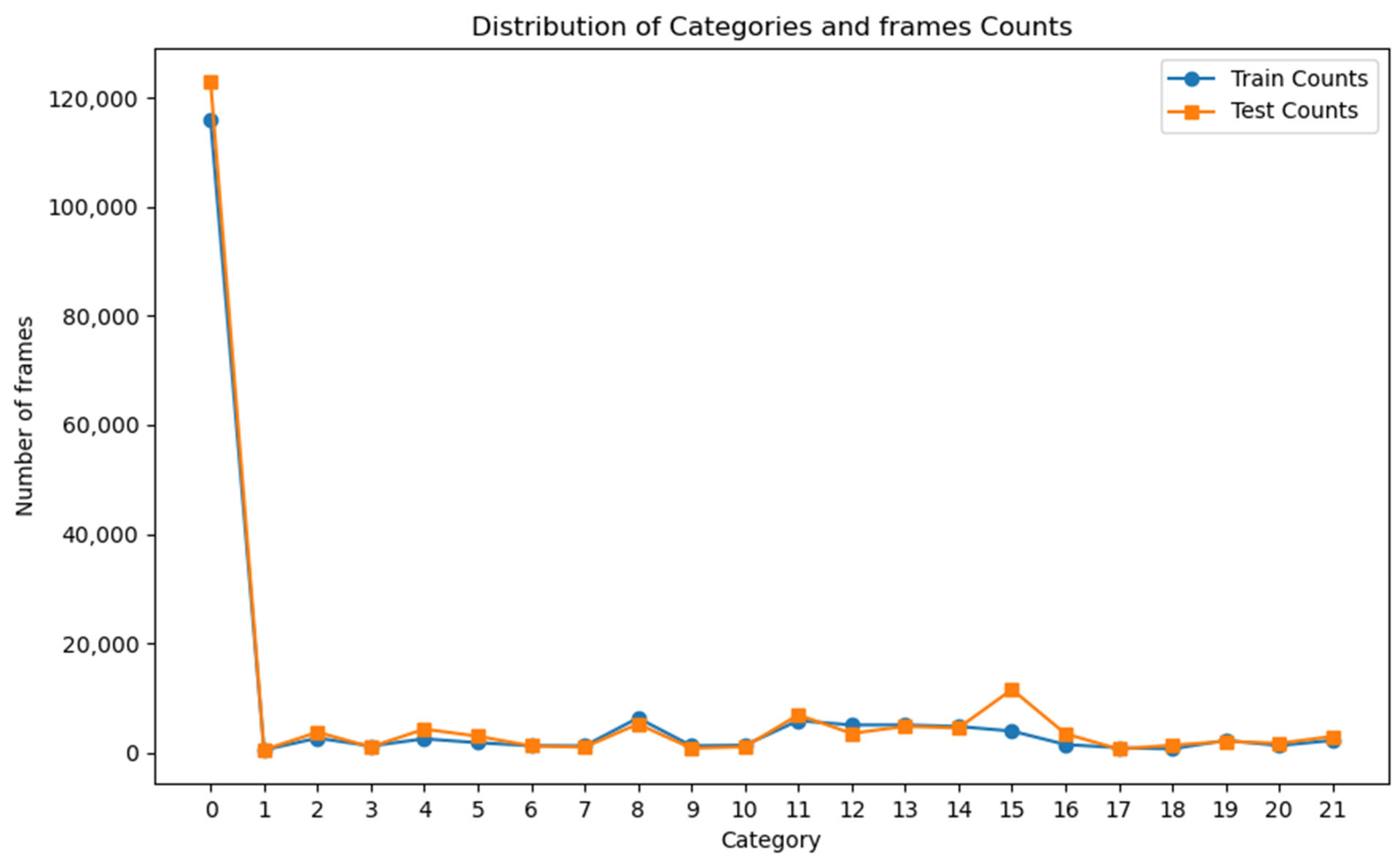
Based on the problem formation, two primary challenges emerge. The first challenge is data imbalance. In online action detection, labels are assigned at the frame level, with each frame having a label. The number of background labels far exceeds those of other classes, as demonstrated in
Figure 1, which shows the distribution of frames per category in the Thumos14 dataset, where category 0 represents the background class. We can see that the number of frames labeled as background is approximately 120,000, while all other categories have fewer than 20,000 frames. This indicates a severe data imbalance for the background category in comparison to other categories, making model training particularly challenging. Unfortunately, in real-world scenarios, the background class typically constitutes the majority of frame labels. Thus, data imbalance reflects potential training difficulties, even though it may accurately represent real-world data distributions. Common approaches to handling data imbalance, such as oversampling and undersampling, are difficult to implement in the context of online action detection, unlike in image classification tasks. In online action detection, each frame is temporally related, making it infeasible to arbitrarily add or remove frames. This interdependence adds to the complexity of the task.
The second challenge is that the feature differences between classes are sometimes marginal. In classification tasks, the difficulty of classification depends on the distinctiveness of features between classes. For example, the classification difficulty of category
can be represented by the intersection of the set of features of category
(denoted as
) with the set of features of other categories, which is represented as the union of the set of features of all other target actions except action
and the set of features of the background category, as shown in Equation (3)
where
is the set of features of action
, and
is the set of target action indices, and
is the set of background features. As previously defined in Equation (2), anything that is not a target action will be classified as background. Therefore, depending on the dataset, the background category may include any action other than the target actions. This means that the features of the background category encompass the features of all possible actions. Consequently, the challenge in online action detection lies not only in distinguishing between a target action and other target actions but also in differentiating between the target action and all possible actions. Therefore, Equation (3) can be rewritten as Equation (4),
where
represents the set of all possible action indices. The larger the intersection, the more difficult the classification. Note that the
includes features of all possible actions, and even frames with no actions are classified as background. Therefore, the feature differences between classes can be marginal for the model, making the classification task in online action detection particularly challenging.
Based on the two points mentioned above, we find that training a simple
K-class classifier to classify only target actions without including the background class can reduce classification difficulty compared to using a (
K + 1)-class classifier. The classification difficulty of the
K-classifier, without the background category, can be represented as shown in Equation (5).
Firstly, this approach avoids data imbalance issues. Secondly, its classification difficulty depends solely on the features associated with the selected target actions. Therefore, this paper suggests first training a K-class classifier and then fusing the information obtained with the original model to arrive at better predictions.
For illustrative purposes, this paper uses the LSTR model as the base and integrates a pre-trained K-class classifier to enhance detection accuracy. Experimental results demonstrate that for target actions without background, the K-class classifier outperforms the original model in making predictions. Furthermore, when applied to all classes, including the background, incorporating the information generated by the K-class classifier into the original model yields better accuracy than direct prediction using the original model alone.
3. Proposed Framework and Loss
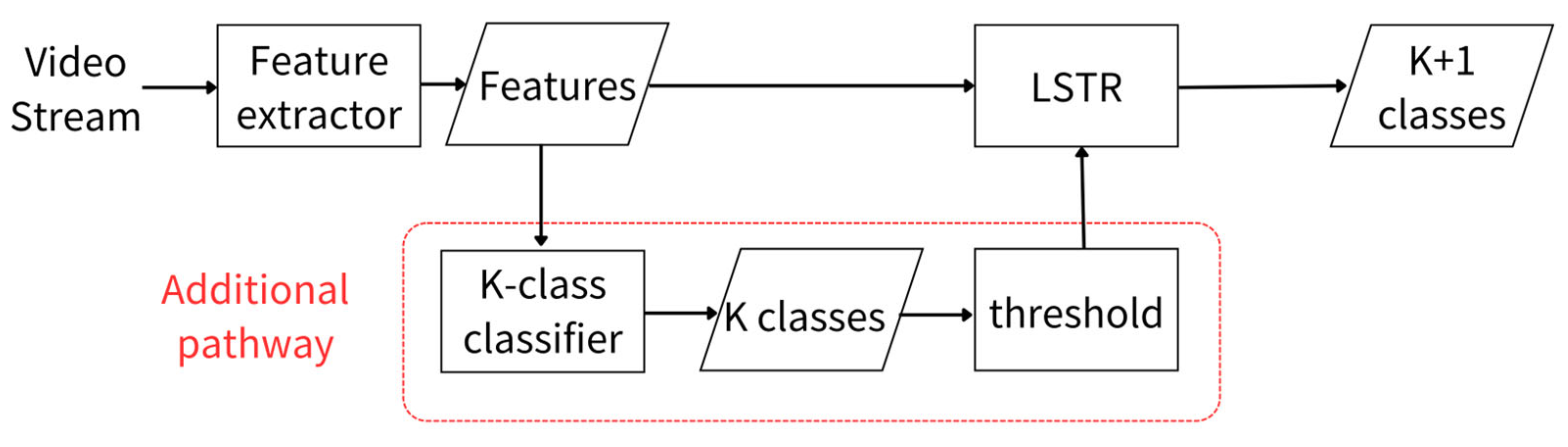
As an attempt to address the above-mentioned challenges, this paper proposes an innovative framework for online action detection, as shown in
Figure 2, which incorporates an additional pathway between the feature extractor and the LSTR. The advantage of using a
K-class classifier within this pathway is that it avoids the two aforementioned challenges by fusing the information obtained from the
K-class classifier with the original model, leading to improved predictions.
3.1. Model Architecture
When a video stream is fed into the feature extractor, the collected input features at time
t can be represented as Equation (6),
where
τ represents the number of input frames,
t represents the current time, and
represents the feature of the
i-th frame. According to the official settings in [
4], the original dimension of
is set to 2048 for the LSTR model. As shown in
Figure 2, we employ a
K-class action classifier within the additional pathway. The reason for using
K-class classification is that it provides more robust and accurate training compared to a (
K + 1)-class classifier, thereby alleviating the data imbalance issue. We then use this classifier as a secondary feature extractor to derive
K probabilities for the target actions. The output of the
K-class classifier can be represented as shown in Equation (7),
where
is the number of target actions, and
is the event where any target action occurs, and
is the predicted probability of a specific target action.
Next, we empirically determine a threshold: if the input is greater than 0.05, the output is 1; otherwise, the output is 0, as shown in Equation (8),
To determine the optimal threshold value, we initially tested a threshold of 0.5, then gradually decreased it in increments of 0.05, with the lowest value tested being 0.01. After several experiments, a threshold of 0.05 was selected as optimal.
In the context of neural networks, the output of the last layer in a fully connected network is often referred to as the logits. Therefore, we denote the output of the fully connected layer in the original model as
, as shown in Equation (9),
where
represents the logit of the original model for the
i-th class. Next, we use the output of the
K-class classifier,
as the input to the threshold function in Equation (8) to obtain a reference value
. We then perform element-wise multiplication between this reference value and the logits of the original model, to obtain the output of the proposed model as shown in Equation (10),
where * denotes element-wise multiplication. The missing dimension of the background is represented by 1, as the
K-class classifier cannot predict the probability of the background class. Finally, after passing through softmax, we obtain the predicted output, as shown in Equation (11)
The purpose of this approach is to exclude certain actions, which are assigned a reference value of 0 and judged as highly unlikely to occur by the K-class classifier, without disrupting the original logit values for other classes, which have a reference value of 1. The classification capability of the K-class classifier for target actions, by excluding frames with the background class, is superior to that of the (K + 1)-class classifier, as will be demonstrated in the experimental results. However, the probabilities generated by the K-class classifier are based on the assumption that the input contains only the target actions. As shown in Equation (7), since the K-class classifier was trained on data containing only target actions, the probabilities it outputs reflect these known target actions. In the context of online action detection, this assumption is impractical. Thus, the actual numerical values of the probabilities from the K-class classifier cannot be directly applied to the logit values of the original model. To address this, we use a threshold function to evaluate the relative magnitudes of the probabilities, disregarding their actual values. This approach avoids directly computing the probabilities from the -class classifier with the logit values of the ( + 1)-class classifier.
3.2. Loss Function
In the aforementioned architecture, when an update occurs and the threshold outputs a value of 0 for a certain action, the multiplication with the original logit O (as described in Equation (10)) results in 0, regardless of the logit’s original value. Consequently, the model’s final output will not be influenced by the original logit O. Since most updates in neural networks rely on gradient descent, it is essential to calculate gradients to perform these updates. From the perspective of backpropagation updates, as long as the threshold outputs a value of 0 for a certain action, the error term propagated to the preceding layers for that action will also be 0 during the update. This means that the weights related to that action will not be adjusted, as illustrated by the gradients in Equation (12).
Backpropagation allows us to compute gradients efficiently using the chain rule of calculus. The partial derivative of the logits layer
of the proposed model with respect to the original logit
O is given by Equation (12).
where
represents the prediction value of the
K-class classifier for the
i-th action. As long as the
is 0, the
i-th action will not be updated during the iteration. For example, suppose a certain frame does not contain the action of playing basketball. If the
K-class classifier determines that this frame does not depict the action of playing basketball, meaning
is 0, then even if the original model
predicts that the frame is definitely depicting playing basketball, the final output from the proposed model
will still indicate that it is not the action of playing basketball. Although the action in this frame is correctly identified, the original LSTR model is not penalized for this incorrect prediction. This could lead to the model becoming overly reliant on the
K-class classifier.
To address the issue of no updating when
outputs 0, introduce an additional loss component to the original Cross-Entropy (CE) loss. The purpose of this additional loss is to prevent the (
+ 1)-class classifier from overly reliant on the predictions of the
K-class classifier. The Cross-Entropy loss function is defined in Equation (13)
where
is the number of samples,
is the number of classes,
is the ground truth label for sample
and class
, and
is the predicted probability for sample
and class
. The original loss function can be calculated using Cross-Entropy to compute the error between the ground truth and our predicted values, as shown in Equation (14)
Additionally, we design an extra loss function based on Cross-Entropy to calculate the error between the ground truth and the probabilities obtained by passing
through the softmax, as shown in Equation (15):
Finally, we obtain the proposed loss function by adding the original loss in Equation (14) and the newly designed loss in Equation (15) together, and dividing the final combined loss by 2, as shown in Equation (16)
to maintain a learning rate similar to that of the original LSTR model.
To analyze the impact of this proposed loss, we examine its gradient, which determines the weight updates, similar to what we carried out earlier. The partial derivative of the proposed loss with respect to
O can be expressed as Equation (17) below:
When the previously mentioned situation occurs, that is, when outputs 0 for a certain action, the value of corresponding to that action will also be 0, as shown in Equation (12). If we use the original loss, this will result in the weights related to that action not being updated due to this discrepancy. However, with the proposed loss, even if is 0, can still update this discrepancy.
With the addition of the newly designed loss , even when the threshold output is 0, the gradient of with respect to the logits will still propagate back to update the earlier layers of the network. This helps to reduce instances where updating is not triggered when the predicted logits for a certain action significantly deviate from the true label.
The proposed extra loss function, , is a crucial component designed to address situations where the K-class classifier predicts a value of 0, indicating that no target action is detected. In such instances, using the original loss design would cause the overall outcome to be dominated by this zero value, regardless of the contribution from the (K + 1)-class classifier. This would lead to the model’s training process being overly dependent on the K-class classifier. In contrast, by applying the proposed loss function, this issue is mitigated, preventing the model from relying solely on the K-class classifier’s prediction. In summary, the purpose of the proposed additional loss element is to ensure that the model can still make stable predictions even when the K-class classifier predicts no action from within the K classes, as backpropagation remains valid through this extra loss element during training.






{kind=link}
{kind=link}