Abstract
Safety is the eternal theme of power systems. In view of problems such as time-consuming and poor real-time performance in the correct use of seat belt hooks by manual supervision operators in the process of power operation, this paper proposes an improved YOLOv7 seat belt hook suspension state recognition algorithm. Firstly, the feature extraction part of the YOLOv7 backbone network is improved, and the M-Spatial Pyramid Pooling Concurrent Spatial Pyramid Convolution (M-SPPCSPC) feature extraction module is constructed to replace the Spatial Pyramid Pooling Concurrent Spatial Pyramid Convolution (SPPCSPC) module of the backbone network, which reduces the amount of computation and improves the detection speed of the backbone network while keeping the sensory field of the backbone network unchanged. Second, a decoupled head, which realizes the confidence and regression frames separately, is introduced to alleviate the negative impact of the conflict between the classification and regression tasks, consequently improving the network detection accuracy and accelerating the network convergence. Ultimately, a dynamic non-monotonic focusing mechanism is introduced in the output layer, and the Wise Intersection over Union (WioU) loss function is used to reduce the competitiveness of high-quality anchor frames while reducing the harmful gradient generated by low-quality anchor frames, which ultimately improves the overall performance of the detection network. The experimental results show that the mean Average Precision (mAP@0.5) value of the improved network reaches 81.2%, which is 7.4% higher than that of the original YOLOv7, therefore achieving better detection results for multiple-state recognition of hooks.
1. Introduction
Due to the special, complex, and variable nature of power line architecture, electric work is very prone to injury, and falling is the most frequent accident in the electric power industry [1]. The normative use of safety belts plays a vital role in safeguarding operators’ lives and can effectively reduce the occurrence of safety accidents. In the “State Grid Electric Power Safety Regulations” [2], it is clearly stipulated that in the case of a fall height of more than 2 m, a safety belt must be used, while the hook or rope of the safety belt should be hung on a solid component or a special wire rope, and it is strictly prohibited to hang it on a movable or unfastened object. The overall use of the safety belt is a high-hanging and low-hanging method, which refers to the hook of the safety belt to be fixed above the operator. For operating personnel above, this way of operation is more secure and reasonable; when a fall occurs, the actual impact distance is shorter, reducing the harm caused to the operating personnel. Electric power operation specifications on the correct use of safety belt hooks also have requirements: hooks hanging on unstable sloping surfaces, sharp edges, thin lines, hooks not completely closed, etc., are prohibited behaviors [3].
Since the power system [4] of power generation, power supply, and infrastructure links need to work at height, the correct use of safety belts is decisive for the life safety of electric power workers working at height [5,6]. However, in the process of electric power operation, the operator needs to move frequently, and the working range and movement trajectory are difficult to control. Each time up and down, the the position of the safety belt needs to be re-fixed, that is, the safety belt hooks must be unlocked and then fastened. Some operators, for the sake of saving time, do not adhere to the provisions of the hanging hooks or even do not fasten the safety belt hooks.
For the problems of time-consuming and poor real-time performance in laborious manual supervision of the correct use of seat belt hooks by operators in the process of electric power inspection, a real-time detection algorithm for improving the suspension status of seat belt hooks with YOLOv7 is proposed in this work, and the main contributions are as follows:
- (1)
- In this study, the feature extraction part of the YOLOv7 backbone network is improved, and an M-Spatial Pyramid Pooling Concurrent Spatial Pyramid Convolution (M-SPPCSPC) feature extraction module is constructed to replace the Spatial Pyramid Pooling Concurrent Spatial Pyramid Convolution (SPPCSPC) module of the backbone network, reducing the amount of computation and improving the detection speed of the backbone network while keeping the sensory field of the backbone network unchanged.
- (2)
- The introduction of decoupled head, which implements confidence and regression frames separately, mitigates the negative impact of conflicts between classification and regression tasks, thus improving network detection accuracy and accelerating network convergence.
- (3)
- The Wise Intersection over Union (WioU) loss function is used to reduce the competitiveness of high-quality anchor frames while reducing the harmful gradient generated by low-quality anchor frames, which ultimately improves the overall performance of the detection network.
Next, in Section 2, this paper briefly introduces relevant background information on the identification of seat belt hook suspension status in the working environment at altitude and then focuses on analyzing the practical application of computer vision technology and Internet of Things technology in detecting the situation of seat belt suspension of workers at altitude. In Section 3, the specific framework of this paper’s improved real-time detection algorithm for the seat belt hook suspension state of YOLOv7 will be mainly introduced from four perspectives: the basic structure of YOLOv7, the decoupling head-based YOLOv7, the M-SPPCSPC module, and the WIoU loss function. Section 4 will also introduce the process, experimental environment, and model training parameters of the self-made dataset, verify the effectiveness of each single component of the proposed algorithm, and analyze and compare the detection performance of the proposed algorithm with other models. In addition, real-time performance analysis and error analysis are carried out to comprehensively evaluate the performance of the improved algorithm in actual high-altitude power operations. Finally, this paper is summarized in Section 5, affirming the advantages of the proposed algorithm and looking forward to the future improvement of the real-time detection algorithm for the suspension state of seat belt hooks in a high-altitude power operation environment.
2. Related Work
The current safety monitoring of operations primarily relies on video surveillance systems and manual on-site supervision to identify potential safety hazards. The video surveillance system lacks real-time recognition of abnormal conditions, while with manual supervision, it is challenging to sustain focused observation for extended periods. Therefore, it is imperative to adopt more effective measures for safety monitoring in order to mitigate operational accidents.
In recent years, there has been rapid development in computer vision technology [7], and the utilization of high-definition video surveillance technology with intelligent analysis based on computer vision has emerged as a prominent trend [8]. It is extensively applied in various construction scenarios, such as helmet detection [9], face detection [10], seat belt detection [11], and so on. Chen et al. [12] proposed a sophisticated algorithm for seat belt detection against complex road backgrounds by employing multi-scale feature extraction rooted in deep learning. The areas encompassing vehicles, windshields, and seat belts were subjected to multi-scale feature extraction, followed by training a convolutional neural network (CNN) model to identify preliminary candidates of vehicles, windshields, and seat belts within test images. A support vector machine (SVM) was employed to train the classification model that facilitated mapping and identification of seat belt regions within road surveillance camera footage. Consequently, this approach led to an improvement in the recognition rate of seat belts within intelligent transportation systems. Wang et al. take detection and recognition of stationary vehicles and seat belts as the key analysis object. When studying driver seat belt detection, Wang combines the YOLOv3 [13] target detection algorithm with a lightweight network structure to propose a driver-oriented positioning algorithm. With the increase in lightweight templates, the accuracy of the positioning algorithm was greatly improved.
However, the research on seat belt detection technology mainly focuses on the seat belt-wearing scene of motor vehicle drivers. In contrast, research on seat belt detection of electric power field workers is relatively limited. This phenomenon is mainly due to the complexity of the electric power work site environment, the variability of personnel posture, and the diversity of seat belt forms; the existence of these factors greatly increases the difficulty of determining whether the operator is correctly using the seat belt according to regulation.
For the study of wearing safety belts for power workers, Wei [14] adopted the YOLOv3 algorithm to build a digital and intelligent situation element extraction method for the feature extraction process of image data and built a high-altitude work recognition model for electric power construction to learn and train the judgment of high-altitude work, detect workers and safety belts as targets, and accurately send early warning signals. The research results provide a data basis for predicting the risk situation of electric power operation. Guo et al. [15] studied and established an action recognition method based on a three-dimensional (3D) skeleton and long short-term memory (LSTM), which was used to automatically monitor whether the seat belt was correctly fixed on site. Through laboratory experiments, the proposed method was tested for effectiveness and feasibility by comprehensively considering the characteristics of scaffolding work in common real building scenes. The method achieves acceptable accuracy and recall rates and can detect misuse of seat belts by combining multiple actions that will help prevent FFH in practice and help build a body of knowledge for building safety management. The two-stage algorithm Mask Region-based Convolutional Neural Network (Mask R-CNN) [16] can only identify whether the seat belt is high-hanging or low-use, cannot judge the suspension state of the seat belt hanger, and has slow image recognition speed, which makes it difficult to meet the actual requirements of power tower maintenance. Fang et al. [17] used two CNN models to work together to confirm whether workers were wearing seat belts when working at height. First, a Faster Region Convolutional Neural Network (R-CNN) model was used to detect the presence of workers, and then whether they were wearing seat belts. While this method has advantages over manually checking seat belts, it is still inaccurate and relies on large quantities of data and computing resources. Gomez-de-Gabriel et al. [18] proposed a method based on low-power Bluetooth zone demarcation to monitor the use of safety belts by operators. The specific steps of the method include zoning the construction area using a low-power Bluetooth beacon harness to exclude influences outside the work area. By verifying the connection of the safety harness to the corresponding anchor points, it can be determined whether the worker is within the designated area and wearing the safety harness correctly. This method has obvious advantages and performs well in the real construction environment, but the system operation steps are relatively complicated. With the aim of improving accuracy, Fang et al. [19] proposed a seat belt detection algorithm based on YOLOv5 and the Open Pose network. The dataset was created from a video stream of workers wearing seat belts, and the network was trained to detect seat belts. Li et al. [20] proposed a CME-YOLOv5 network to reduce environmental interference and mutual occlusion, and to facilitate detection of small targets. Wu et al. [21] enhanced the YOLOv5 network by adding an Attention Suggestion subnetwork (APN) and a new loss function (Complete Intersection over Union, CIoU) [22]. Xu et al. [7] proposed a lightweight target detection method (Efficient-YOLOv5) that is used to detect seat belt wearing in general construction operations, but it has certain limitations in electric power operation scenarios. In addition, the method only verifies whether workers wear seat belts and does not involve the assessment of the state of the hooks, so the condition of the seat belt hooks cannot be assessed.
In addition, the Internet of Things technology has also been widely used in high-altitude power operation safety belt detection, through the integration of various sensors, monitoring equipment, and data analysis systems, to achieve real-time monitoring of the safety status of operators. Zhang and Liu [23] studied a “safety monitoring system for aerial workers based on Internet of Things technology” that usually uses acceleration sensors and pressure sensors to monitor the attitude of the operator and the tensioner state of the seat belt to ensure their safety while working at altitude. Chen and Wang [24] use Radio Frequency Identification (RFID) tags to track and manage seat belts in real time and monitor the use status of seat belts through readers to ensure that operators use qualified seat belts. Li and Zhao [25] monitor high-altitude operation by fixed camera and combine a simple image processing algorithm to detect whether the seat belt is properly worn. However, compared with traditional IoT devices, the improved YOLOv7 real-time detection algorithm of seat belt hook suspension state in this paper has certain advantages. The improved YOLOv7 can carry out real-time image processing and adapt to dynamic environmental changes, while the traditional method may have delays. Through the training of a deep learning model, YOLOv7’s target recognition ability in complex scenes is better than that of rule-based sensor systems. In addition, the algorithm can be applied to a variety of state recognition tasks, while traditional devices are usually limited to a specific monitoring theory.
3. Methodology
3.1. Overview of YOLOv7 Model Structure
YOLOv7 is an advanced object detection model that was released in 2021. It adopts optimization techniques such as Anchor-Free, CSPDarknet53 feature extraction network, and Adaptive Thresholding to optimize the computational structure and detail design of the model, which improves the stability and overall performance of the model. With an Anchor-Free design, the predicted bounding box does not rely on predefined anchor points, enabling more accurate recognition of object position and size. This improves the capability to precisely detect object dimensions and locations.
YOLOv7 removes the Focus structure and introduces the Efficient Layer Aggregation Networks (ELANs) structure, which is located in the backbone part to enhance the network learning capability while maintaining the integrity of the original gradient path. In addition, YOLOv7 also introduces a Mixed-Precision (MP) structure, which integrates two subsampling methods, pooling and convolution, into the backbone to effectively increase the information content of subsampled feature maps and provide more abundant feature representation for target detection tasks. In the Neck part, YOLOv7 proposed the SPPCSPC structure, which divides the features into two parts, one for routine processing and the other for Spatial Pyramid Pooling (SPP) processing, to make full use of information of different scales. The introduction of this structure greatly improves the speed and accuracy of the model. YOLOv7 outputs three feature maps of different sizes (20 × 20, 40 × 40, and 80 × 80), providing more comprehensive support for multi-scale target detection. The YOLOv7 network structure, depicted in Figure 1.
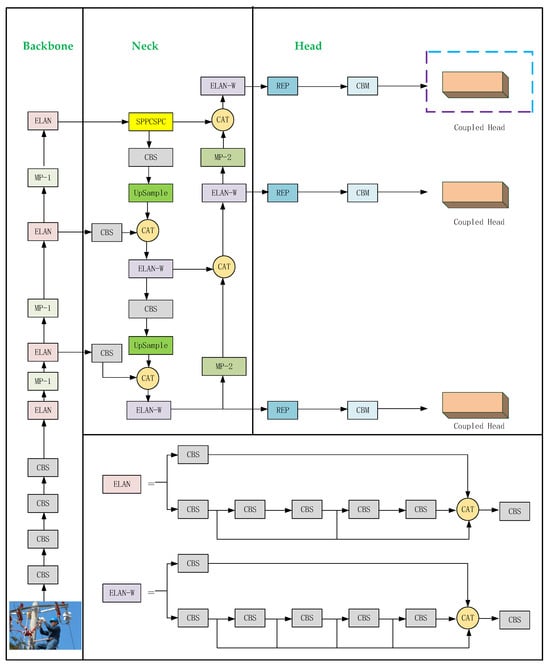
Figure 1.
YOLOv7 network structure.
The YOLO series of algorithms has been pivotal to the entire deep learning target detection field, from v1 to v7; with continuous innovation and improvement, the model generalization has been improved. What is more, the model generalization and robustness are getting better and better. Table 1 provides a qualitative comparison table of YOLOv7 in different safety-critical areas, showing a structured overview of its state-of-the-art (SOTA) performance, highlighting the key metrics and benefits that make it particularly suitable for each application. By observing this table, it can be seen that the versatility and effectiveness of YOLOv7 in various safety-critical application fields give full play to its excellent detection performance.

Table 1.
A qualitative comparison table of YOLOv7 in different safety-critical areas.
Since YOLOv7 takes into account both detection accuracy and detection speed, and the number of model parameters is small, the faster detection speed is more suitable for electric power operation sites, so this paper chooses YOLOv7 as the basic network model.
3.2. YOLOv7 Based on Decoupled Header
Considering the complex environment of the power operation scene and the existence of power facilities with different forms of interference and other problems, this paper applies a deep learning network to the recognition of safety belt hook state to realize the automatic recognition of hook state in complex power operation scenes. The network takes YOLOv7 as the base network, designs the M-SPPCSPC module to enhance the speed of the backbone network, and references the decoupling header [32]. Separate implementation of confidence and regression frames improves network detection accuracy and accelerates network convergence. Finally, the WIoU [33]-invoked loss function, based on an intelligent gradient gain allocation strategy, can focus on anchor frames of common quality and improve the overall performance of the detection network. Meanwhile, in an effort to evaluate the effect of the improved model, experimental validation is carried out on the Hook Dataset. The structure of the improved YOLOv7 network is shown in Figure 2.
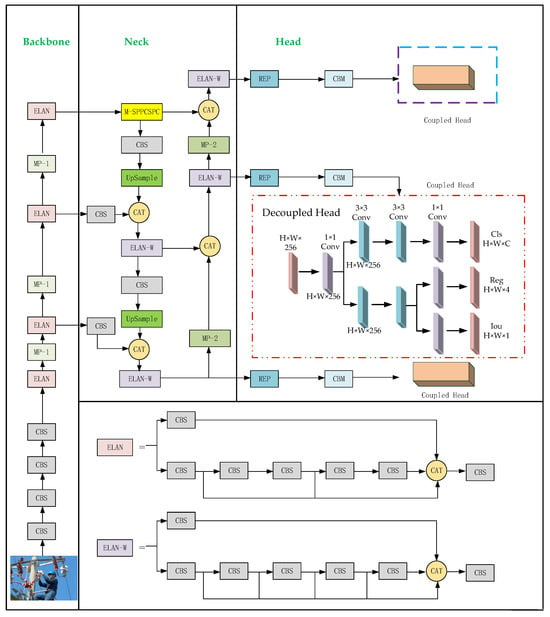
Figure 2.
Improved YOLOv7 network structure.
3.3. M-SPPCSPC Module
SPPCSPC is a feature extraction module in YOLOv7 that is composed of SPP and CSPNet structures. In other words, the SPP module is first used to extract features and then input them into CSPNet. Pooling of input feature maps of different sizes and scales can be carried out to further improve the accuracy and speed of the model. The structure of SPPCSPC is shown in Figure 3. In the first branch of Figure 3, there are four branches for parallel MaxPool processing. The MaxPool window sizes are 5, 9, 13, and 1. Nevertheless, the four MaxPools are processed in parallel, and the overall processing speed of the module is slow.
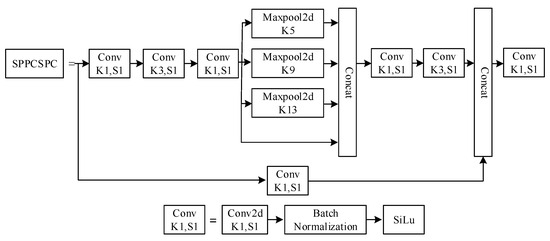
Figure 3.
SPPCSPC module (Note: K represents the size of the convolution kernel, which is used for convolution operations. It determines the range of receptive fields for each convolution operation, thus affecting the ability of feature extraction. s stands for stride, that is, the number of steps that the convolution operation moves on the input feature map. So, K1, K3, K5, K9, and K13 mean the MaxPool window sizes are 1, 3, 5, 9, and 13; S1 indicates that the step size of the convolution operation moving on the input feature graph is 1; Conv represents convolution; MaxPool2d indicates 2d max pooling; Concat means concatenation; SiLu stands sigmoid linear unit).
To improve the network speed even further and realize the purpose of real-time detection of seat belt hooks, this work proposes the M-SPPCSPC module based on the SPPCSPC module. The M-SPPCSPC module, as shown in Figure 4, is based on the original module, which reduces the computation volume by changing the four parallel MaxPool branches to serial processing. To keep the output size constant, the window sizes of the two middle MaxPool layers are changed. The result of the serial computation of two 5 × 5-sized MaxPool layers is equivalent to the result of the computation of a 9 × 9-sized MaxPool layer, and the serial computation of three 5 × 5 MaxPool layers is equivalent to the computation of a 13 × 13 MaxPool layer.
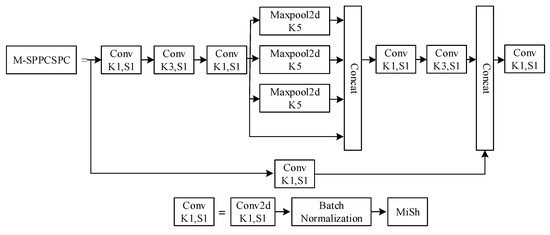
Figure 4.
M-SPPCSPC module (Note: K represents the size of the convolution kernel, which is used for convolution operations. It determines the range of receptive fields for each convolution operation, thus affecting the ability of feature extraction. s stands for stride, that is, the number of steps that the convolution operation moves on the input feature map. K1, K3, and K5 mean the MaxPool window sizes are 1, 3, and 5; S1 indicates that the step size of the convolution operation moving on the input feature graph is 1; Conv represents convolution; MaxPool2d indicates 2D max pooling; Concat means concatenation; MiSh represents Mish Activation Function).
The M-SPPCSPC module serially passes inputs through multiple 5 × 5-sized MaxPool layers, an operation that reduces the amount of computation and achieves the same outputs while maintaining the same sense field.
3.4. Decoupled Head
The backbone and feature pyramid of the YOLO series, such as Feature Pyramid Network (FPN) and Path Aggregation Network (PAN), have undergone much optimization and evolution, though the YOLO series detection head part still adopts a coupled design. Furthermore, YOLOv7 continues this feature, its detection head is still a coupled head, and the coupling head changes the position of the boundary box. The confidence and class probabilities are accomplished by a 1 × 1 convolution, as shown in Figure 5.
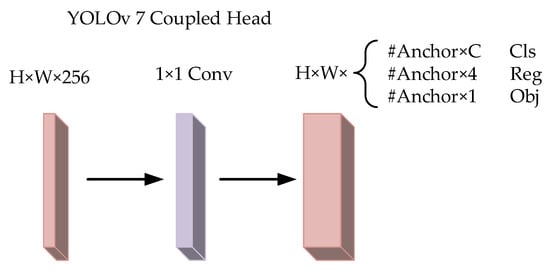
Figure 5.
YOLOv7 coupled head network structure.
In target detection tasks, it is often necessary to perform classification and regression tasks simultaneously to achieve higher accuracy and robustness. Nonetheless, classification and regression tasks focus on different information, and coupling heads cannot make them focus on the information they need, so decoupling heads are used to decompose each branch to improve detection accuracy. The structure of the decoupled head is shown in Figure 6.
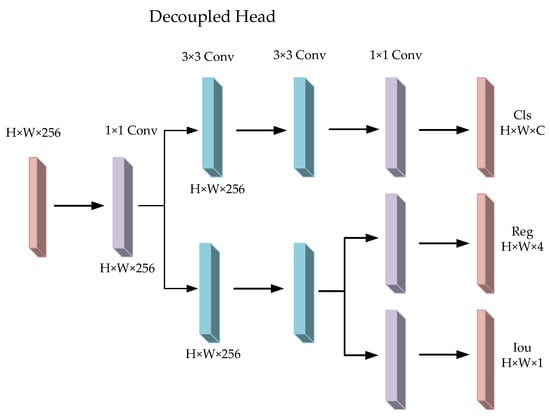
Figure 6.
Decoupled head network structure.
For the input feature layer, the decoupling head will use 1 × 1 convolution to downscale it to reduce the amount of computation and the number of parameters, then use two 3 × 3 convolutions in each of the two branches, classification and regression, to extract the features that help to identify the target category and the features that predict the bounding box coordinates. The decoupling network can obtain three outputs: classification (Cls), regression (Reg), and objectness (Obj), where Cls is the corresponding type of the target frame, Reg is the position information of the target frame, and Obj is whether each feature point contains an object. The three output values are fused to obtain the final prediction information. The decoupling operation implements the confidence and regression frames separately, which slightly increases the complexity of the process, but alleviates the negative impact of the conflict between the classification and regression tasks [34,35], thus achieving the goal of improving the network detection accuracy, as well as accelerating the convergence of network training.
3.5. Wise-IoU Loss Function
The loss function of YOLOv7 consists of three parts: localization loss , classification loss , and objectness loss . The overall loss function of YOLOv7 is the weighted sum of these three parts, and the weights can be adjusted to focus on the losses of the three parts by changing the values of the weights. The YOLOv7 loss function is shown in Equation (1), where a, b, and c are the weighting coefficients:
YOLOv7 uses CIoU loss to calculate coordinate loss; classification loss and target confidence loss are calculated using binary cross-entropy loss with log; and CIoU loss is calculated in Equation (2):
In Equation (2), is the distance between the centers of Box A and Box B, is the length of the diagonal of the smallest enclosing rectangle of Box A and Box B, is the similarity of the aspect ratio of Box A and Box B, and is the influence factor.
Although the CIoU loss function is able to solve the problem of gradient vanishing of the IoU loss function during the training process after taking into account the aspect ratio and other factors, there is still room for optimization. The WIoU loss function adopts a dynamic and non-monotonic focusing mechanism that utilizes the “outlier” to replace the IoU to assess the quality of the anchor frames and provides a judicious strategy for the allocation of gradient gains. This strategy reduces the competitiveness of high-quality anchor frames while reducing the harmful gradients generated by low-quality anchor frames. This allows for the WIoU to focus on average-quality anchor frames and improves the overall performance of the detector. The schematic of the WIoU structure is shown in Figure 7, and the formulas for the WIoU loss function are given in Equation (4):
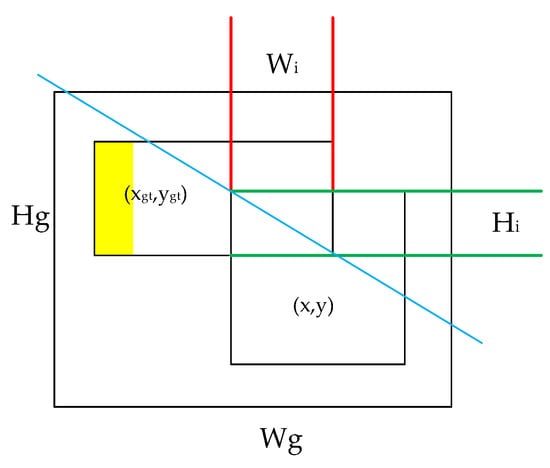
Figure 7.
Schematic diagram of the WIoU.
In Equations (4) and (5) above, * is the dimension of the minimum bounding box separated from the computational graph, is the outlier degree, and and are the hyperparameters, where we take = 1.9 and = 3. Compared with the CIoU loss function, the WIoU loss function uses the outlier degree to dynamically adjust the gradient gain of the anchor frames to improve the gradient gains of the anchor frames as much as possible during the training process to improve the detection accuracy.
4. Seat Belt Hook Dataset Construction
In deep learning, the quality of the dataset is critical to model performance and generalization ability. High-quality datasets not only help models learn more generalized features and improve their performance in real-world scenarios but also help prevent overfitting. In previous studies, there was a lack of ready-made datasets for seat belt wearing, so a lot of work was carried out in this paper to carefully build a dedicated dataset, the “Hook Dataset”, to ensure that the detection system had better detection performance when facing power operation scenarios.
4.1. Data Collection
The power operation safety belt dataset used in this study comes from the training materials of power companies, safety monitoring cameras, and field shots. Among them, the Hook Dataset is mainly composed of the power tower operation site photographed in the field and data collected by a web crawler, which both cover all kinds of electric power operation scenarios, including different working environments, lighting conditions, electric power equipment, etc., which show the use of safety belts in high and low hanging positions from various angles, covering the various suspension methods of the safety belt hooks, and the labels are categorized into five types: four types of violations (wrong place, wrong tie, too thin, and not closed) and one type of safety (safe). The sample images of the dataset are shown in Figure 8.

Figure 8.
Dataset sample images.
The diversity in sources and shooting conditions of the images leads to variable image quality. To ensure the high quality of the dataset, this work first carefully screens the samples, releases images that contain too much useless information or are heavily obscured, and removes blurred photos caused by acquisition and other reasons to ensure that the images in the dataset have good recognizability. Through organizing, the Hook Dataset has a total of 2250 photos. Some images of the dataset are shown in Figure 9.

Figure 9.
Some image samples from the dataset.
4.2. Data Enhancement
The small size of the original dataset may lead to overfitting of the algorithm, which in turn affects the detection effect of seat belts. To solve this problem, we use data enhancement methods to expand the initial dataset, including random masking, horizontal flipping, adjusting contrast and brightness, and other operations. Through random rectangular masking, horizontal flipping, contrast enhancement, and brightness adjustment, the number of images in the Hook Dataset expands to 9000, which effectively increases the diversity in the training set, and helps to prevent the overfitting phenomenon, ensuring that the final dataset has a better effect on the training and evaluation of the deep learning algorithm. The number of images in each category is 1800. An example of the enhanced effect is shown in Figure 10.

Figure 10.
Data augmentation: (a) original, (b) gaussian noise, (c) random matrix occlusion, (d) flip horizontal, (e) increase contrast.
4.3. Data Annotation
To make the dataset, the collected pictures need to be labeled, and only data marked with a target on the pictures can be sent into model training. The quality and accuracy of the annotation are very important for the performance of the training model. Good labeling can improve the generalization ability and prediction accuracy of the model. The higher the accuracy of the labeling target, the more accurate the labeling, and the better the model training effect; on the contrary, poor labeling may make it more difficult for the model to converge, result in model training fails, or output unreliable results. For the seat belt detection task involved in this study, the expanded datasets need to be labeled separately.
LabelImg [36] is an open-source software program for image annotation. The Hook Dataset is used for target detection tasks. LabelImg image annotation tool is used to annotate the real frame of the sample image. LabelImg tool is written in Python language and is open source. The label information can be saved as an XML file conforming to PASCAL VOC format or as a TXT file, as required by YOLO. Figure 11 shows the marking process.
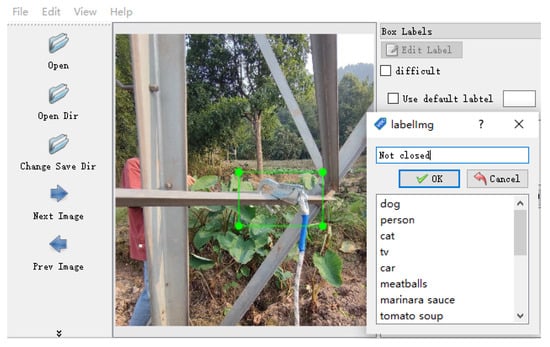
Figure 11.
LabelImg annotated data.
Through the above work, the Hook Dataset has a total of 9000 photos, and the labels are divided into 5 types: 4 types of violations (wrong place, wrong tie, too thin, not closed) and 1 type of security (safe). In our work, the ratio of training set, verification set, and test set is randomly divided into 8:1:1.
5. Experiment and Result Analysis
5.1. Experimental Environment and Model Training Parameters
5.1.1. Experimental Environment
The experiments and testing process of the seat belt hook detection algorithm proposed in this section were completed on a professional server equipped in the laboratory. The server system environment was Windows 10 Professional; the model construction, training, and testing of the results in the experiment were completed in the deep learning framework PyTorch; the programming software was PyCharm Community Edition (PyCharm); the CUDA computing platform and the supporting deep neural network library CUDNN were used for hardware acceleration; and the configuration required for the environment is specified in Table 2.
Table 2.
Experimental operating environment.
5.1.2. Model Training Parameters
The improved YOLOv7 model was trained with the following configuration: the adaptive size dimension of the input image was 640 × 640, epoch was set to 300, batch size was 32, initial learning rate was 0.01, and weight decay was 0.0005.
5.2. Evaluation Index
Precision [37] and recall [38] are commonly used evaluation indexes of target detection models. Accuracy rate refers to the proportion of samples in which the model predicts the correct example. It measures the accuracy of the model’s judgment of the positive category. The model with high accuracy has a low error rate when the prediction is positive. The recall rate refers to the proportion of samples successfully identified by the model as positive class samples to all actual positive class samples. The higher the recall rate, the less likely the model is to miss the real target and can better capture the real positive class samples. The calculation formulas of accuracy and recall rate are shown in Equations (6) and (7):
where true positive (TP) refers to the correct number of targets in the forecast, false positive (FP) refers to the wrong number of targets in the forecast, and false negative (FN) refers to the correct number of targets that are not predicted. The detection threshold set in this paper is 0.5. When the Intersection over Union (IoU) value between the detection frame and the real frame is greater than 0.5, the detection frame is considered to be correct. In the actual experiment, Average Precision (AP) [39] and mean Average Precision (mAP) [40] were used as comprehensive precision indexes. AP is calculated by calculating the area of the curve surrounded by different accuracy rates and recall rates. mAP is the average of all types of AP, and the mAP value ranges from 0 to 1. mAP calculation formula is shown in Equation (9):
For n samples of a certain classification in the dataset, suppose it has m positive examples, and each positive example corresponds to a recall rate R (1/m, 2/m, … 1); calculate the maximum accuracy p for each recall rate, and then calculate the average of m p-values to obtain AP. AP is targeted at a certain class, and a dataset often contains multiple categories. mAP is obtained by averaging the AP of all classes in the dataset.
mAP@0.5 when the IoU is set to 0.5, calculate the AP of all images in each category, and then average all categories. mAP@0.5:0.95 is defined as the IoU threshold from 0.5 to 0.95 in 0.05 steps and taking the mean of all maps. mAP can measure the comprehensive performance of the model under different IoU thresholds. The higher the value, the more accurately the predicted frame fits the real frame, and the better the model effect.
5.3. Ablation Experiments
5.3.1. Ablation Experiment 1
In order to verify the influence of each individual component of the algorithm on the final performance, the control variable principle is adopted in this paper. Decoupled head (YOLOv7 + M-SPPCSPC), YOLOv7 + WIoU (YOLOv7 + W), YOLOv7 + decoupled head (YOLOv7 + D), and our own model (YOLOv7 + M-SPPCSPC +) were designed. Five variant models of WIoU and decoupled head were used in the ablation experiment. The best training weight (best.pt) of each algorithm model was taken for testing. The results are shown in Table 3.
Table 3.
Results of ablation experiment 1.
As can be seen from Table 3, introduction of the M-SPPCSPC module increased mAP by 2.4%, while only losing 1 FPS, which indicates that M-SPPCSPC has little impact on speed while improving detection accuracy. The use of the WIoU loss function further improved the mAP by 2.3%, but also lost 1 FPS, indicating that WIoU contributed significantly to improving the inspection quality. The introduction of the decoupled head resulted in a 1.6% mAP boost and a small speed loss (0.5 FPS), indicating that the decoupled head performed well in terms of balance accuracy and speed. Finally, a single component is combined to form the algorithm in this paper, mAP is increased by 1.1% again, and the speed loss is only 0.5 FPS, which indicates that the algorithm in this paper has a certain contribution to the improvement of accuracy, while it has little impact on speed. The results of this ablation study show that each of the introduced components contributes positively to the final performance. M-SPPCSPC and WIoU contributed the most, increasing mAP by 2.4% and 2.3%, respectively. Although the decoupled head contributes relatively little, it also has the least impact on speed while improving accuracy. This result confirms the effectiveness of our improved algorithm, with each component playing an important role in the overall performance improvement.
5.3.2. Ablation Experiment 2
In order to verify the detection effect of the optimized YOLOv7 algorithm and the contribution of this structure to the overall performance of the model, we compared the performance of YOLOv7 (SPPCSPC + CIoU + coupled head), YOLOV7-1 (SPPCSPC + WIoU + coupled head), YOLOV7-2 (SPPCSPC + WIoU + decoupled head), YOLOv7-3 (M-SPPCSPC + WIoU + coupled head), YOLOv8, YoloV8-1 (meaning that WIoU loss function is used on the basis of YOLOv8 instead of CIoU loss function), YoloV8-2 (meaning that the decoupled head is used on the basis of YOLOv8), and the improved network (YOLOv7 + M-SPPCSPC + WIoU + decoupled head). The best training weight (best.pt) of each algorithm model was taken for testing. Table 4 lists the results.
Table 4.
Results of ablation experiment 2.
As can be seen from Table 4, for mAP@0.5, the improved algorithm proposed in this paper reaches 81.2%, which is 2% higher than that of YOLOv8-2 and 7.4% higher than that of the original YOLOv7, indicating that the improved algorithm significantly improved the overall detection performance, which proves that WIoU can improve the accuracy of reasoning. For all types of AP, the improved algorithm performs well in all categories, especially in the “Wrong place” and “Not closed” categories, reaching 82.0% and 82.5%, respectively, far exceeding other models. In addition, although YOLOv8 and its variants are improved compared to YOLOv7, the improved algorithm in this paper still performs better. For example, at mAP@0.5, the improved algorithm is 2% higher than YOLOv8-2 and 5.5% higher in the “Wrong place” category. The improved algorithm proposed in this paper is superior to YOLOv7, YOLOv8, and their variants in various indicators, which proves that the improved method based on YOLOv7 proposed in this paper makes a meaningful improvement in the detection effect of seat belt hooks, showing significant performance improvement and better generalization ability. In order to more intuitively display the test effect of the suspension mode of the seat belt hook before and after the improvement, the test results are visualized, as shown in Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9. For the purpose of more intuitively showing the detection effect of the seat belt hook suspension method before and after the improvement, the detection results are visualized, as shown in Figure 12.

Figure 12.
YOLO series model effect comparison.
5.4. Comparative Experiments
To verify the effectiveness of the algorithm proposed in our work on the seat belt hook suspension detection method, this paper conducted comparative experiments with mainstream target detection algorithms Single-Shot Multi-Box Detector (SSD), Faster R-CNN, YOLOv4, YOLOv7, etc. The metrics included mAP@0.5, mAP@0.5:0.95, FPS, and model size. The experimental results are shown in Table 5.
Table 5.
Comparison of the results of the improved YOLOv7 algorithm with other algorithms.
As shown in Table 5, in this study, compared to the mainstream SSD, and YOLOv4 models, the size of the model is drastically reduced, the model detection speed is drastically increased, and the accuracy of the model detection is the highest. Compared to the Faster R-CNN algorithm, the model size is drastically reduced while the detection speed is drastically increased. Compared with the original YOLOv7, in the improved YOLOv7 in our work, because of the addition of the decoupling head, the model size rises and the detection accuracy is greatly improved while the detection speed is slightly reduced. Figure 13 shows the partial detection results of YOLOv5, SSD, Faster R-CNN, and the improved algorithm of this paper for the seat belt hook suspension state.

Figure 13.
Comparison of the results of the improved YOLOv7 algorithm with other algorithms: (a) FASTER RCNN, (b) SSD, (c) YOLOV5, (d) ours.
As can be seen from Figure 13, all four detection algorithms can effectively detect the hook suspension state, and the confidence level of the other three models is low. Overall, the improved model in the study improves significantly in detecting the hook target and shows stronger and more stable detection performance. It outperforms the original YOLOv7 model in hook suspension state recognition, taking into account higher detection accuracy and detection speed.
5.5. Real-Time Performance and Error Analysis
5.5.1. Real-Time Performance Analysis
To evaluate whether the YOLOv7 algorithm optimized in this paper can meet the real-time operation requirements of power transmission environments, in this paper, YOLOv7, YOLOv8, and the improved network were compared to verify the real-time performance of the proposed algorithm from three perspectives: frames per second (FPS), processing time per frame, and required computing resources (GPU utilization rate). We took the best training weight (best-pt) of each algorithm model for testing, and the results are shown in Table 6.
Table 6.
Real-time performance results.
Analyzing the above data, it can be found that for FPS (frames per second), the improved algorithm in this paper reaches 42 FPS, which is slightly lower than YOLOv7 and YOLOv8, but still meets the needs of most real-time applications. In terms of processing time, the processing time per frame is 23.8 ms, which is slightly higher than YOLOv7 and YOLOv8, but the difference is not much. In terms of GPU utilization, the model used by the algorithm in this paper has a GPU utilization rate of 90%, which is slightly higher than the other two models, indicating that it makes more full use of computing resources. Overall, although our improved algorithm is slightly slower than YOLOv7 and YOLOv8 in speed, this slight speed loss is acceptable considering its significantly improved detection accuracy. The speed of 42 FPS is still enough to meet the real-time operation requirements in the power transmission environment, and the real-time performance of the algorithm in this paper is better.
5.5.2. Error Analysis
In order to further explore the performance of the improved YOLOv7 algorithm in this paper, we analyzed the hook state’s misclassified or missed detection by this model from four aspects: false positive, false negative, misclassification, and boundary box inaccuracy. The error analysis results are shown in Table 7.
Table 7.
Error analysis results.
Analysis of the table shows that 3.2% of false positives misidentify shadows as hooks, possibly due to changes in lighting conditions. For false negatives, 2.8% of errors were failures to detect partially occluded hooks, indicating that the model has room for improvement in handling occluded situations. In addition, in terms of misclassification: 4.5% of errors misclassified “too thin” hooks as “not closed”, which may be due to the visual similarity of the two states at certain angles. When it comes to bounding box inaccuracies, 5.1% of errors were the bounding boxes of large hooks that are outside the image range, which may require improvements in the model’s ability to handle large objects. Overall, despite the excellent overall performance of our model, there are still some areas for improvement, especially in dealing with occlusion, lighting variations, and large objects, for which future research can be optimized.
In this study, an algorithm based on an improved YOLOv7 model for detecting the suspension mode of seat belt hooks was proposed to address violation phenomena such as seat belt hooks mis-fastening and the non-fastening of electric power operators. The regression accuracy was improved, and the model prediction error was reduced by enhancing the feature extraction part of the backbone network, replacing the coupling head in the original network with a decoupling head, and replacing the original CIoU loss function with a WIoU loss function. The effectiveness of each single component of the proposed algorithm was verified on the self-made Hook Dataset. Meanwhile, experiments were carried out on the dataset. The results showed that the improved YOLOv7 detection algorithm increased the value of the original YOLOv7 mAP@0.5 by 7.4%, and model performance was significantly improved. The improved algorithm in this chapter is more advantageous. In addition, we also carried out real-time performance and error analysis on the algorithm proposed in this paper. Through these two analyses, we affirmed the advantages of the algorithm in this paper to meet the real-time operation requirements in an actual power transmission environment and determined the optimization of the algorithm in this paper.
6. Conclusions
Electric power safety production is crucial for the stable development of the power system. It is of great significance to apply deep learning technology in computer vision to power operation detection. Deep learning technology has excellent performance in target detection, semantic segmentation, etc., which can help to recognize the use of safety belts by operators at power operation sites. In our study, YOLOv7 was used for safety belt hook state recognition, and the safety belt hook suspension state recognition algorithm based on improved YOLOv7 was studied.
Aiming at the problem of time-consuming and laborious manual supervision of the correct use of seat belt hooks by operators in the process of electric power inspection and poor real-time performance, this paper put forward an algorithm for detecting the suspension status of seat belt hooks using YOLOv7. Firstly, the feature extraction section of the YOLOv7 backbone network was improved, and the feature extraction module of the M-SPPCSPC was used instead of SPPCSPC module. It can reduce the amount of computation and reduces the detection speed of the backbone network while maintaining the sensor field of the backbone network. Secondly, a decoupled head, which implements the confidence and regression frames separately, was introduced to alleviate the negative impact of the conflict between the classification and regression tasks so as to improve the network detection accuracy and accelerate the network convergence. Eventually, the WIoU loss function was used to reduce the harmful gradient generated by low-quality anchor frames, which improved the overall performance of the detection network. After several comparisons and ablation experiments, an improved version of the YOLOv7 algorithm model with better detection effect was successfully obtained, and the detection accuracy of the model in the process of electric power safety production was improved, which can enhance the efficiency of subsequent electric power operation scenarios for the correct use of seat belts by manual supervisors.
In future, we will further improve the performance of algorithmic networks. Considering the problem of model parameters and computational amount, we plan to refer to “A new lightweight deep neural network for surface scratch detection” proposed by Li et al. [41]. In the paper, the identification network of suspension state of safety belt hooks for high-altitude electric operation with smaller model parameters is studied from the perspective of light weight. In addition, considering the problems of the model’s interpretability and robustness, after in-depth study of the relevant work carried out by de Curto et al. [42] on semantic scene understanding of unmanned aerial vehicles (UAVs) based on a large language model and the open vocabulary object detection capability demonstrated by the YOLO-World model [43], we intend to integrate large language models (LLMs) and visual language models (VLMs) as additional layers of analysis to translate detection results into a more comprehensive context and human-understandable interpretation. By integrating these advanced language models, we propose a method that can both generate a detailed description of detected seat belt hook states and explain the reasoning behind the classification. A system that can also identify edge situations or anomalies that require human intervention, potentially improving the safety decision-making process, is expected to effectively process and describe complex visual information in high-altitude working environments in subsequent work.
Author Contributions
Conceptualization and methodology, X.X. and Z.C.; programming and testing, Z.L.; dataset creation, X.X., Z.C., Z.L. and X.Z; writing original draft, X.Z.; review and revision, M.C. and X.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Sichuan Province Science and Technology Plan Project, grant number 2024ZHCG0182, and the Opening Fund of Artificial Intelligence Key Laboratory of Sichuan Province, grant number 2023RZY02.
Data Availability Statement
The dataset used in this experiment was co-produced by the author and the power company and cannot be shared.
Conflicts of Interest
Author Zhengwei Chang is employed by Sate Grid Sichuan Electric Power Company. Author Zhongxiao Lan is employed by Si Chuan North Hong Guang Special Chemical Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- National Energy Administration, P.S.S.D. Compilation of National Power Accidents and Power Safety Incidents; China Electric Power Media Group: Beijing, China, 2022. [Google Scholar]
- China, S.G.C.o. Power Safety Regulations of State Grid Corporation: Substation Section; China Electric Power Press: Beijing, China, 2013. [Google Scholar]
- Chang, Z.; Deng, Y.; Wu, J.; Xiong, X.; Chen, M.; Wang, H.; Xie, X. Safety Risk Assessment of Electric Power Operation Site Based on Variable Precision Rough Set. J. Circuits Syst. Comput. 2022, 31, 2250254. [Google Scholar] [CrossRef]
- Xing, J. Research on Target Detection Algorithms for Site Safety Equipment. In Proceedings of the International Conference on Remote Sensing, Mapping, and Image Processing (RSMIP 2024), Xiamen, China, 19–21 January 2024. [Google Scholar]
- Lin, Z.; Chen, W.; Su, L.; Chen, Y.; Li, T. Hs-Yolo: Small Object Detection for Power Operation Scenarios. Appl. Sci. 2023, 13, 11114. [Google Scholar] [CrossRef]
- Chen, M.; Lan, Z.; Duan, Z.; Yi, S.; Su, Q. Hds-Yolov5: An Improved Safety Harness Hook Detection Algorithm Based on Yolov5s. Math. Biosci. Eng. MBE 2023, 20, 15476–15495. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, J.; Huang, K. A Novel Computer Vision-Based Approach for Monitoring Safety Harness Use in Construction. IET Image Process. 2023, 17, 1071–1085. [Google Scholar] [CrossRef]
- Zhou, Q.; Liu, D.; An, K. Ese-Yolov8: A Novel Object Detection Algorithm for Safety Belt Detection during Working at Heights. Entropy 2024, 26, 591. [Google Scholar] [CrossRef]
- He, C.; Tan, S.; Zhao, J.; Ergu, D.; Liu, F.; Ma, B.; Li, J. Efficient and Lightweight Neural Network for Hard Hat Detection. Electronics 2024, 13, 2507. [Google Scholar] [CrossRef]
- Gao, J.; Yang, T. Face Detection Algorithm Based on Improved Tinyyolov3 and Attention Mechanism. Comput. Commun. 2021, 181, 329–337. [Google Scholar] [CrossRef]
- Hosseini, S.; Fathi, A. Automatic Detection of Vehicle Occupancy and Driver’s Seat Belt Status Using Deep Learning. Signal Image Video Process. 2023, 17, 491–499. [Google Scholar] [CrossRef]
- Chen, Y.; Tao, G.; Ren, H.; Lin, X.; Zhang, L. Accurate Seat Belt Detection in Road Surveillance Images Based on Cnn and Svm. Neurocomputing 2018, 274, 80–87. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y. Detection and Recognition of Stationary Vehicles and Seat Belts in Intelligent Internet of Things Traffic Management System. Neural Comput. Appl. 2022, 34, 3513–3522. [Google Scholar] [CrossRef]
- Wei, C. Research on Electric Power Aerial Work Recognition Model Based on Deep Learning. In Proceedings of the International Conference on Computer Graphics, Artificial Intelligence, and Data Processing (ICCAID 2023), Qingdao, China, 1–3 December 2023. [Google Scholar]
- Guo, H.; Zhang, Z.; Yu, R.; Sun, Y.; Li, H. Action Recognition Based on 3d Skeleton and Lstm for the Monitoring of Construction Workers’ Safety Harness Usage. J. Constr. Eng. Manag. 2023, 149, 04023015. [Google Scholar] [CrossRef]
- Moccia, S.; Fiorentino, M.C.; Frontoni, E. Mask-R 2 Cnn: A Distance-Field Regression Version of Mask-Rcnn for Fetal-Head Delineation in Ultrasound Images. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 1711–1718. [Google Scholar] [CrossRef] [PubMed]
- Fang, W.; Ding, L.; Luo, H.; Love, P.E.D. Falls from Heights: A Computer Vision-Based Approach for Safety Harness Detection. Autom. Constr. 2018, 91, 53–61. [Google Scholar] [CrossRef]
- Gómez-De-Gabriel, J.M.; Fernández-Madrigal, J.A.; López-Arquillos, A.; Rubio-Romero, J.C. Monitoring Harness Use in Construction with Ble Beacons. Measurement 2019, 131, 329–340. [Google Scholar] [CrossRef]
- Fang, C.; Xiang, H.; Leng, C.; Chen, J.; Yu, Q. Research on Real-Time Detection of Safety Harness Wearing of Workshop Personnel Based on Yolov5 and Openpose. Sustainability 2022, 14, 5872. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Wu, L.; Cai, N.; Liu, Z.; Yuan, A.; Wang, H. A One-Stage Deep Learning Framework for Automatic Detection of Safety Harnesses in High-Altitude Operations. Signal Image Video Process. 2023, 17, 75–82. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y. Development of a Safety Monitoring System for High-altitude Workers Based on IoT Technology. IEEE Trans. Ind. Inform. 2018, 14, 1035–1044. [Google Scholar]
- Chen, X.; Wang, T. Application of RFID Technology in the Management of Safety Belts for Electric Power Maintenance. J. Electr. Eng. Technol. 2019, 14, 120–128. [Google Scholar]
- Li, J.; Zhao, Q. Visual Monitoring System for High-altitude Electrical Work Safety Based on Image Processing. Saf. Sci. 2020, 130, 104889. [Google Scholar]
- Zhang, L.; Liu, Y.; Chen, X. IoT-enabled smart safety harness system for enhanced worker safety in high-altitude environments. J. Constr. Eng. Manag. 2021, 147, 04021093. [Google Scholar]
- Wang, J.; Li, K.; Zhang, H. Integrated IoT approach for advanced fall protection systems: A focus on smart safety harnesses in construction. Saf. Sci. 2023, 158, 105966. [Google Scholar]
- Patel, S.; Johnson, M.; Brown, T. Data-driven insights from IoT-enhanced safety harness usage in high-altitude work: Implications for occupational safety policies. Int. J. Occup. Saf. Ergon. 2022, 28, 1532–1545. [Google Scholar]
- Li, S.; Tao, T.; Zhang, Y.; Li, M.; Qu, H. YOLO v7-CS: A YOLO v7-based model for lightweight bayberry target detection count. Agronomy 2023, 13, 2952. [Google Scholar] [CrossRef]
- Kaya, Ö.; Çodur, M.Y.; Mustafaraj, E. Automatic detection of pedestrian crosswalk with faster r-cnn and yolov7. Buildings 2023, 13, 1070. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, C.; Filaretov, V.F.; Yukhimets, D.A. Multi-scale ship detection algorithm based on YOLOv7 for complex scene SAR images. Remote Sens. 2023, 15, 2071. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-Iou: Bounding Box Regression Loss with Dynamic Focusing Mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking Classification and Localization for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 19 June 2020. [Google Scholar]
- Tzutalin, “LabelImg”, GitHub. 2021. Available online: https://github.com/tzutalin/labelImg (accessed on 1 October 2024).
- Yacouby, R.; Axman, D. Probabilistic extension of precision, recall, and f1 score for more thorough evaluation of classification models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Online, 20 November 2020; pp. 79–91. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of evaluation metrics for natural language processing tasks. In Proceedings of the Conference of the Canadian Society for Computational Studies of Intelligence, Kelowna, Canada, 25–27 May 2009; pp. 112–125. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- de Curtò, J.; de Zarzà, I.; Calafate, C.T. Semantic Scene Understanding with Large Language Models on Unmanned Aerial Vehicles. Drones 2023, 7, 114. [Google Scholar] [CrossRef]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16901–16911. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).