
GaitMGL: Multi-Scale Temporal Dimension and Global–Local Feature Fusion for Gait Recognition


Abstract
1. Introduction
- We introduce the novel GaitMGL network model, designed to efficiently extract crucial global and local features from skeleton sequences.
- We propose a novel temporal extraction module called MTCN, which is suitable for temporal extraction at various scales, enhances the flexibility of extracting temporal information from model-based gait recognition networks, and improves the whole effect of temporal feature extraction.
- Our GaitMGL network is thoroughly assessed on publicly available datasets including CASIA-B, Gait3D, and GREW. The experimental data clearly indicate that GaitMGL outperforms state-of-the-art (SOTA) skeletal gait recognition models. In particular, on the GREW dataset, the accuracy of our model reaches an impressive 63.12%, nearly 30% higher than the best existing model-based gait recognition network. This performance improvement makes model-based gait recognition more competitive in the field.
2. Related Work
2.1. Silhouette-Based Gait Recognition Networks
2.2. Model-Based Gait Recognition Networks
3. Proposed Method
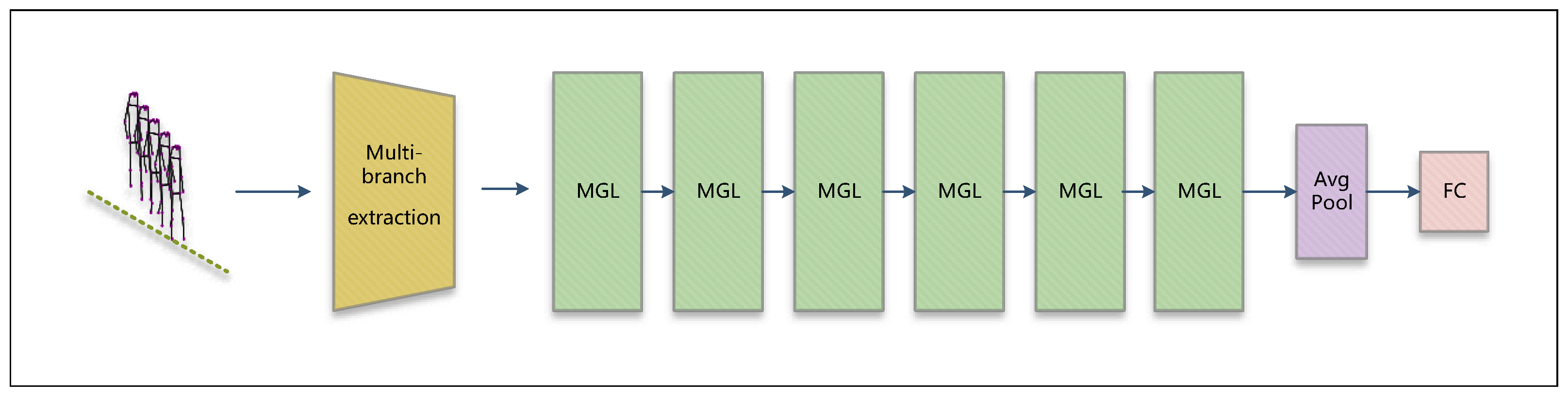
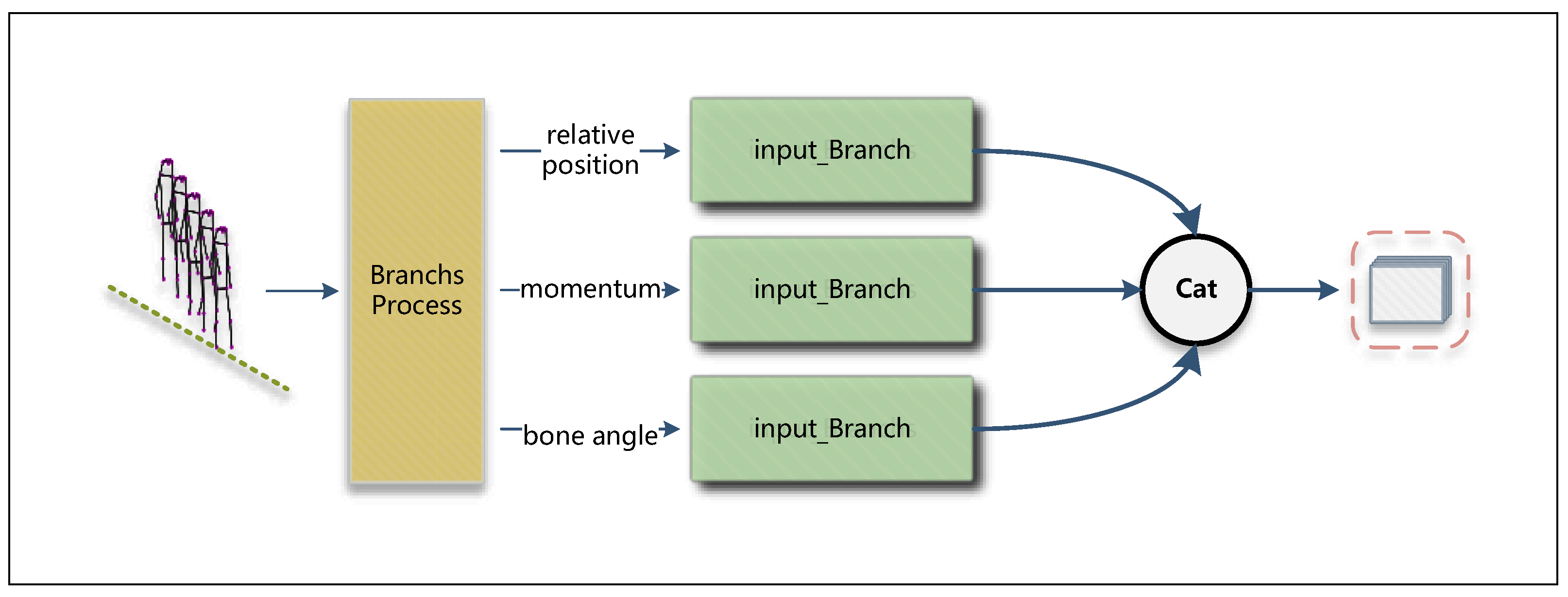
3.1. Overall Architecture
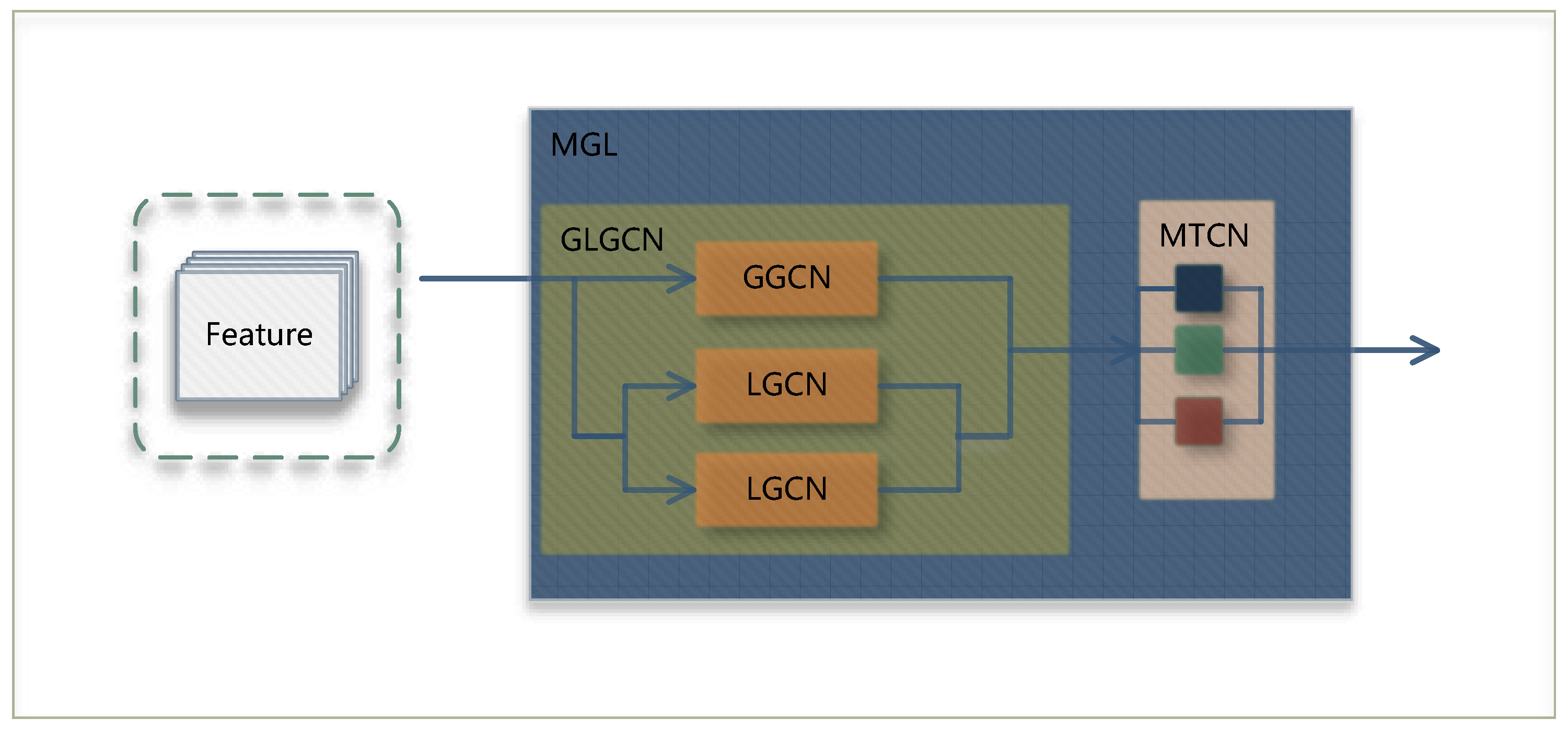
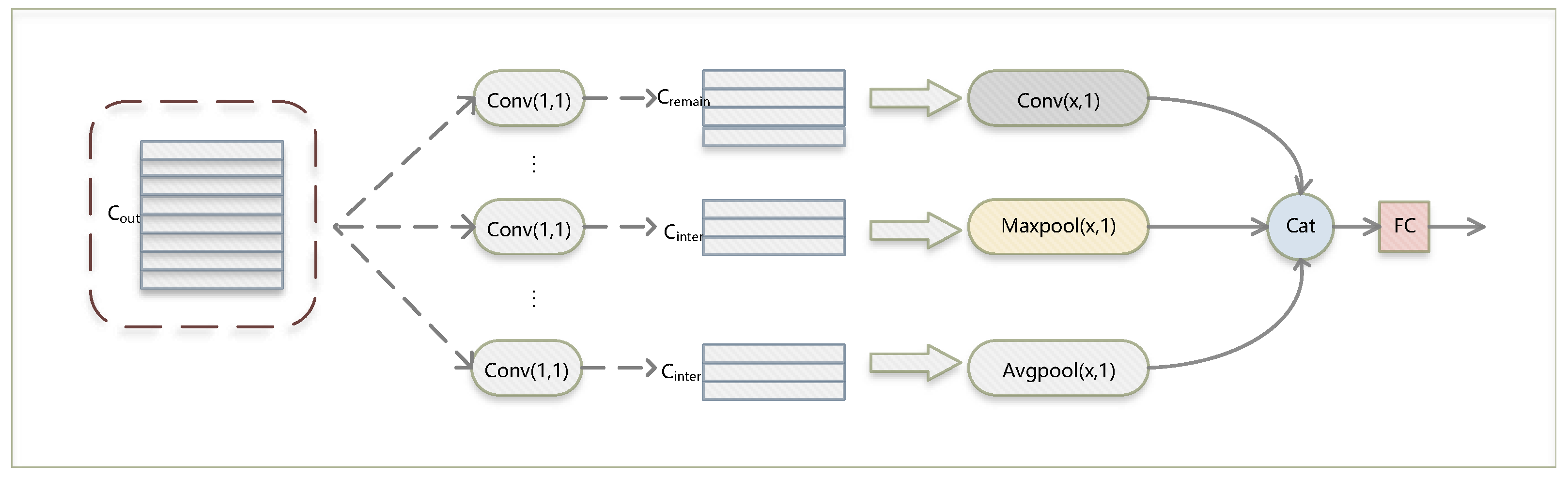
3.2. Global–Local Graph Convolutional Network
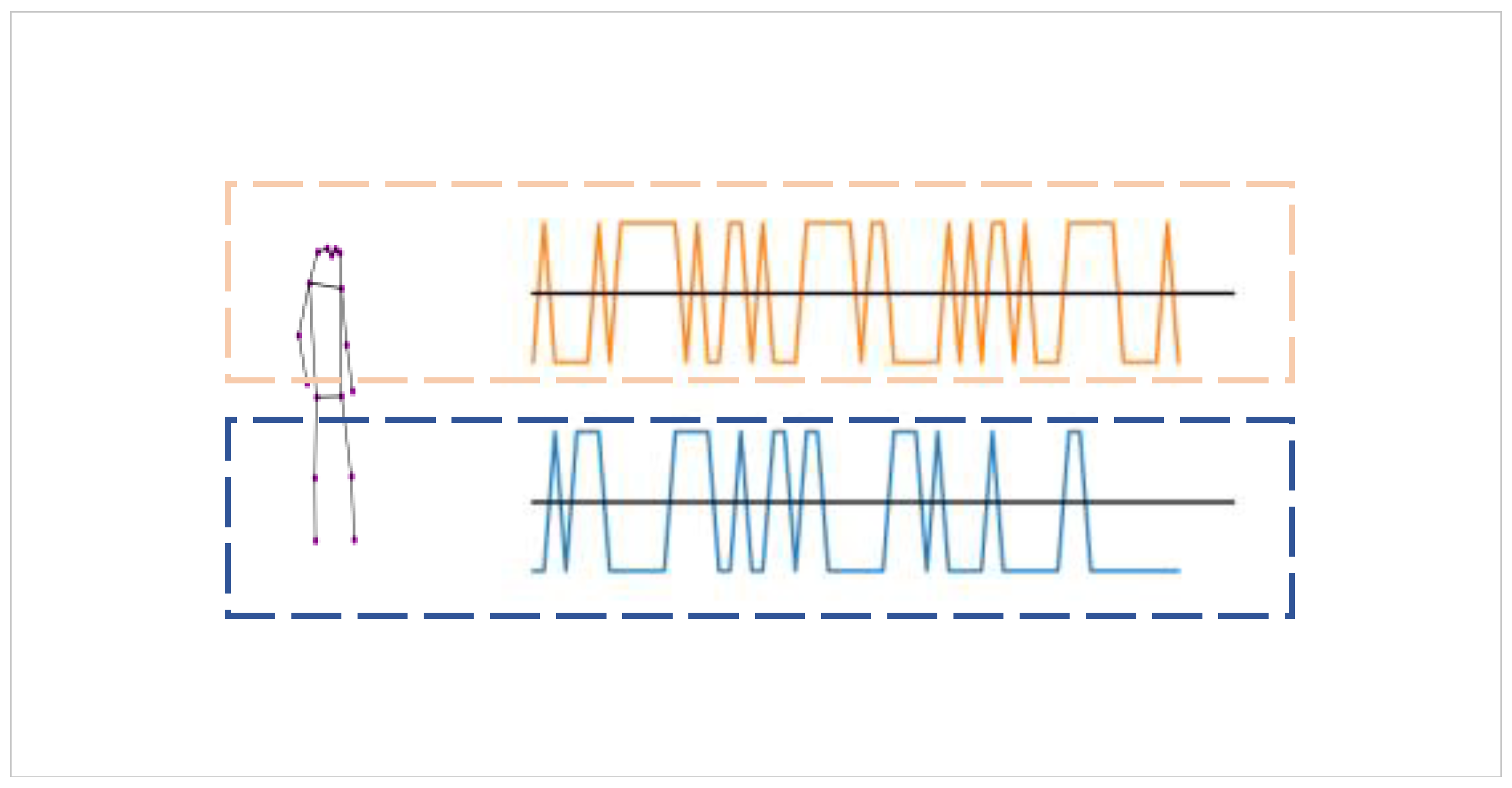
3.3. Multi-Scale Temporal Convolution Network
4. Experiments
4.1. Datasets
4.2. Implementation Details
- Training Batch Size. The training batch size is set as N × S, where N denotes the label number and S denotes the sequence number within every label. Specifically, the training batch size is set to 10 × 6 for the CASIA-B dataset and 48 × 10 for the GREW and Gait3D datasets.
- Optimizer. In the backpropagation process, we use the SGD optimizer and set 0.1 as the initial learning rate of the optimizer, 0.9 as the optimizer’s momentum, and set the weight decay to 0.0005. The scheduler settings are as follows. For the GREW dataset, the learning rate is to be reduced by a factor of 10 at steps of 30,000, 60,000, 90,000, and 120,000, for a total of 150,000 rounds of training. For the Gait3D and CASIA-B datasets, the decay is set at 30,000 and 18,000 batches, respectively, for a total of 32,000 and 20,000 rounds of training.
- Temporal scales. We tested different training timescales on the GREW and CASIA-B datasets (under normal walking conditions) to compare the accuracy of the models in order to determine the most suitable timescale for the datasets, and the experimental results are shown in Table 3 through experiments. We select the (3,1) and (9,1) convolution kernels as time scales for the GREW and Gait3D datasets. For the CASIA-B dataset, the (3,1) and (9,1) convolution kernels as well as the maximum pooling kernel of (3,1) are selected as time scales.
- Data augmentation. Considering real data and errors from pose estimation, we added joint noise with a variance of 0.25 to the coordinates of each joint.
- Other configurations. We set the loss function threshold to 0.1. The network fully connected mapping layer has an input dimension of 256 and an output dimension of 128.
4.3. Comparison with State-Of-The-Art Methods
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ding, W.; Abdel-Basset, M.; Hawash, H.; Moustafa, N. Interval type-2 fuzzy temporal convolutional autoencoder for gait-based human identification and authentication. Inf. Sci. 2022, 597, 144–165. [Google Scholar] [CrossRef]
- Yogarajah, P.; Chaurasia, P.; Condell, J.; Prasad, G. Enhancing gait based person identification using joint sparsity model and ℓ1-norm minimization. Inf. Sci. 2015, 308, 3–22. [Google Scholar] [CrossRef]
- Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Three-dimensional face recognition. Int. J. Comput. Vis. 2005, 64, 5–30. [Google Scholar] [CrossRef]
- Yang, J.; Xiong, N.; Vasilakos, A.V.; Fang, Z.; Park, D.; Xu, X.; Yoon, S.; Xie, S.; Yang, Y. A fingerprint recognition scheme based on assembling invariant moments for cloud computing communications. IEEE Syst. J. 2011, 5, 574–583. [Google Scholar] [CrossRef]
- Shu, L.; Zhang, Y.; Yu, Z.; Yang, L.T.; Hauswirth, M.; Xiong, N. Context-aware cross-layer optimized video streaming in wireless multimedia sensor networks. J. Supercomput. 2010, 54, 94–121. [Google Scholar] [CrossRef]
- Hu, W.J.; Fan, J.; Du, Y.X.; Li, B.S.; Xiong, N.; Bekkering, E. MDFC–ResNet: An agricultural IoT system to accurately recognize crop diseases. IEEE Access 2020, 8, 115287–115298. [Google Scholar] [CrossRef]
- Zhao, J.; Huang, J.; Xiong, N. An effective exponential-based trust and reputation evaluation system in wireless sensor networks. IEEE Access 2019, 7, 33859–33869. [Google Scholar] [CrossRef]
- Zeng, Y.; Sreenan, C.J.; Xiong, N.; Yang, L.T.; Park, J.H. Connectivity and coverage maintenance in wireless sensor networks. J. Supercomput. 2010, 52, 23–46. [Google Scholar] [CrossRef]
- Müller, R.; Kornblith, S.; Hinton, G.E. When does label smoothing help? Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Fang, W.; Li, Y.; Zhang, H.; Xiong, N.; Lai, J.; Vasilakos, A.V. On the throughput-energy tradeoff for data transmission between cloud and mobile devices. Inf. Sci. 2014, 283, 79–93. [Google Scholar] [CrossRef]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Bieliński, A.; Rojek, I.; Mikołajewski, D. Comparison of Selected Machine Learning Algorithms in the Analysis of Mental Health Indicators. Electronics 2023, 12, 4407. [Google Scholar] [CrossRef]
- Yao, B.; He, H.; Kang, S.; Chao, Y.; He, L. A Review for the Euler Number Computing Problem. Electronics 2023, 12, 4406. [Google Scholar] [CrossRef]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. Gaitset: Regarding gait as a set for cross-view gait recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8126–8133. [Google Scholar]
- Fan, C.; Peng, Y.; Cao, C.; Liu, X.; Hou, S.; Chi, J.; Huang, Y.; Li, Q.; He, Z. Gaitpart: Temporal part-based model for gait recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14225–14233. [Google Scholar]
- Lin, B.; Zhang, S.; Wang, M.; Li, L.; Yu, X. Gaitgl: Learning discriminative global-local feature representations for gait recognition. arXiv 2022, arXiv:2208.01380. [Google Scholar]
- Huang, Z.; Xue, D.; Shen, X.; Tian, X.; Li, H.; Huang, J.; Hua, X.S. 3D local convolutional neural networks for gait recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 14920–14929. [Google Scholar]
- Liang, J.; Fan, C.; Hou, S.; Shen, C.; Huang, Y.; Yu, S. Gaitedge: Beyond plain end-to-end gait recognition for better practicality. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 375–390. [Google Scholar]
- Fan, C.; Liang, J.; Shen, C.; Hou, S.; Huang, Y.; Yu, S. OpenGait: Revisiting Gait Recognition Towards Better Practicality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9707–9716. [Google Scholar]
- Dou, H.; Zhang, P.; Su, W.; Yu, Y.; Li, X. Metagait: Learning to learn an omni sample adaptive representation for gait recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23 August 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 357–374. [Google Scholar]
- Wang, M.; Guo, X.; Lin, B.; Yang, T.; Zhu, Z.; Li, L.; Zhang, S.; Yu, X. DyGait: Exploiting Dynamic Representations for High-performance Gait Recognition. arXiv 2023, arXiv:2303.14953. [Google Scholar]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Teepe, T.; Khan, A.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Gaitgraph: Graph convolutional network for skeleton-based gait recognition. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2314–2318. [Google Scholar]
- Teepe, T.; Gilg, J.; Herzog, F.; Hörmann, S.; Rigoll, G. Towards a deeper understanding of skeleton-based gait recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1569–1577. [Google Scholar]
- Lin, B.; Liu, Y.; Zhang, S. Gaitmask: Mask-based model for gait recognition. In Proceedings of the BMVC, Virtual, 22–25 November 2021; pp. 1–12. [Google Scholar]
- Xu, C.; Makihara, Y.; Li, X.; Yagi, Y. Occlusion-aware human mesh model-based gait recognition. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1309–1321. [Google Scholar] [CrossRef]
- Liao, R.; Cao, C.; Garcia, E.B.; Yu, S.; Huang, Y. Pose-based temporal-spatial network (PTSN) for gait recognition with carrying and clothing variations. In Proceedings of the Biometric Recognition: 12th Chinese Conference, CCBR 2017, Shenzhen, China, 28–29 October 2017; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2017; pp. 474–483. [Google Scholar]
- Wang, L.; Chen, J.; Chen, Z.; Liu, Y.; Yang, H. Multi-stream part-fused graph convolutional networks for skeleton-based gait recognition. Connect. Sci. 2022, 34, 652–669. [Google Scholar] [CrossRef]
- Sokolova, A.; Konushin, A. Pose-based deep gait recognition. IET Biom. 2019, 8, 134–143. [Google Scholar] [CrossRef]
- Pan, H.; Chen, Y.; Xu, T.; He, Y.; He, Z. Toward Complete-View and High-Level Pose-Based Gait Recognition. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2104–2118. [Google Scholar] [CrossRef]
- Santos, C.F.G.d.; Oliveira, D.D.S.; Passos, L.A.; Pires, R.G.; Santos, D.F.S.; Valem, L.P.; Moreira, T.P.; Santana, M.C.S.; Roder, M.; Papa, J.P.; et al. Gait recognition based on deep learning: A survey. arXiv 2022, arXiv:2201.03323. [Google Scholar]
- Shiraga, K.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Geinet: View-invariant gait recognition using a convolutional neural network. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. Pyskl: Towards good practices for skeleton action recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10 October 2022; pp. 7351–7354. [Google Scholar]
- Li, G.; Muller, M.; Thabet, A.; Ghanem, B. Deepgcns: Can gcns go as deep as cnns? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9267–9276. [Google Scholar]
- Song, Y.; Li, W.; Dai, G.; Shang, X. Advancements in Complex Knowledge Graph Question Answering: A Survey. Electronics 2023, 12, 4395. [Google Scholar] [CrossRef]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 183–192. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. DG-STGCN: Dynamic spatial-temporal modeling for skeleton-based action recognition. arXiv 2022, arXiv:2210.05895. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13359–13368. [Google Scholar]
- Hou, J.; Wang, G.; Chen, X.; Xue, J.H.; Zhu, R.; Yang, H. Spatial-temporal attention res-TCN for skeleton-based dynamic hand gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, S.; Tan, D.; Tan, T. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 4, pp. 441–444. [Google Scholar]
- Zhu, Z.; Guo, X.; Yang, T.; Huang, J.; Deng, J.; Huang, G.; Du, D.; Lu, J.; Zhou, J. Gait recognition in the wild: A benchmark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14789–14799. [Google Scholar]
- Zheng, J.; Liu, X.; Liu, W.; He, L.; Yan, C.; Mei, T. Gait recognition in the wild with dense 3d representations and a benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20228–20237. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Wang, Y.; Fang, W.; Ding, Y.; Xiong, N. Computation offloading optimization for UAV-assisted mobile edge computing: A deep deterministic policy gradient approach. Wirel. Netw. 2021, 27, 2991–3006. [Google Scholar] [CrossRef]
- Kang, L.; Chen, R.S.; Xiong, N.; Chen, Y.C.; Hu, Y.X.; Chen, C.M. Selecting hyper-parameters of Gaussian process regression based on non-inertial particle swarm optimization in Internet of Things. IEEE Access 2019, 7, 59504–59513. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Publication | Train Set | Test Set | Type | ||
|---|---|---|---|---|---|---|
| #ID | #Seq | #ID | #Seq | |||
| CASIA-B | ICPR2006 | 74 | 8140 | 50 | 5500 | NM, BG, CL |
| GREW | ICCV2021 | 20,000 | 102,887 | 6000 | 24,000 | Diverse |
| Gait3D | CVPR2022 | 3000 | 18,940 | 1000 | 6369 | Diverse |
| Dataset | Temporal Scale | Batch Size | MultiStep Scheduler | Steps |
|---|---|---|---|---|
| CASIA-B | (9,1), (3,1), (‘MAX’,3) | 10 × 6 | (18,000) | 20,000 |
| GREW | (9,1), (3,1) | 48 × 10 | (30,000, 60,000, 90,000) | 150,000 |
| Gait3D | (9,1), (3,1) | 48 × 10 | (30,000) | 32,000 |
| Dataset | Temporal Scale | Batch Size | Steps | Accuracy |
|---|---|---|---|---|
| GREW | (9,1), (5,1), (3,1), (‘MAX’,3) | 48 × 10 | 150,000 | 60.23 |
| (9,1), (3,1), (‘MAX’,3) | 48 × 10 | 150,000 | 62.71 | |
| (9,1), (3,1), (‘AVG’,3) | 48 × 10 | 150,000 | 62.12 | |
| (9,1), (3,1) | 48 × 10 | 150,000 | 63.12 | |
| CASIA-B | (9,1), (3,1) | 10 × 6 | 20,000 | 75.36 |
| (9,1), (3,1), (‘MAX’,3) | 10 × 6 | 20,000 | 63.12 |
| Gallery | 0°–180° | Mean | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Probe | 0° | 18° | 36° | 54° | 72° | 90° | 108° | 126° | 144° | 162° | 180° | ||
| NM | PoseGait | 55.3 | 69.6 | 73.9 | 75 | 68 | 68.2 | 71.1 | 72.9 | 76.1 | 70.4 | 55.4 | 68.7 |
| GaitGraph | 85.3 | 88.5 | 91 | 92.5 | 87.2 | 86.5 | 88.4 | 89.2 | 87.9 | 85.9 | 81.9 | 87.7 | |
| GaitGraph2 | 78.5 | 82.9 | 85.8 | 85.6 | 83.1 | 81.5 | 84.3 | 83.2 | 84.2 | 81.6 | 71.8 | 82 | |
| Ours | 79.9 | 87 | 85.6 | 85.4 | 86.9 | 87.6 | 87.1 | 88 | 85.8 | 86.4 | 84.2 | 85.8 | |
| BG | PoseGait | 35.3 | 47.2 | 52.4 | 46.9 | 45.5 | 43.9 | 46.1 | 48.1 | 49.4 | 43.6 | 31.1 | 44.5 |
| GaitGraph | 75.8 | 76.7 | 75.9 | 76.1 | 71.4 | 73.9 | 78 | 74.7 | 75.4 | 75.4 | 69.2 | 74.8 | |
| GaitGraph2 | 69.9 | 75.9 | 78.1 | 79.3 | 71.4 | 71.7 | 74.3 | 76.2 | 73.2 | 73.4 | 61.7 | 73.2 | |
| Ours | 70.9 | 75.6 | 77.9 | 78.9 | 77.4 | 76 | 76.6 | 76.1 | 77.9 | 79.6 | 67.4 | 75.9 | |
| CL | PoseGait | 24.3 | 29.7 | 41.3 | 38.8 | 38.2 | 38.5 | 41.6 | 44.9 | 42.2 | 33.4 | 22.5 | 36 |
| GaitGraph | 69.6 | 66.1 | 68.8 | 67.2 | 64.5 | 62 | 69.5 | 65.6 | 65.7 | 66.1 | 64.3 | 66.3 | |
| GaitGraph2 | 57.1 | 61.1 | 68.9 | 66 | 67.8 | 65.4 | 68.1 | 67.2 | 63.7 | 63.6 | 50.4 | 63.6 | |
| Ours | 68.5 | 71.4 | 73.1 | 70.5 | 71.8 | 68.2 | 71.9 | 69.5 | 70.4 | 73.4 | 68 | 70.6 | |
| Methods | Publication | Type | Mean | ||
|---|---|---|---|---|---|
| NM# | BG# | CL# | |||
| GaitSet [14] | AAAI 2019 | 95.8 | 90 | 75.4 | 87 |
| GaitPart [15] | CVPR 2020 | 96.1 | 90.7 | 78.7 | 88.5 |
| GaitGL [16] | ICCV 2021 | 97.4 | 94.5 | 83.8 | 91.9 |
| GaitBase [19] | CVPR 2023 | 97.6 | 94 | 77.4 | 89.6 |
| GaitMGL | Ours | 85.8 | 75.9 | 70.6 | 77.4 |
| Methods | Publication | Rank-1 | Rank-5 | Rank-10 | Rank-20 |
|---|---|---|---|---|---|
| PoseGait [22] | PR 2020 | 0.23 | 1.05 | 2.23 | 4.28 |
| GaitGraph1 [23] | ICIP 2021 | 1.31 | 3.46 | 5.08 | 7.51 |
| GaitGraph2 [24] | CVPR 2022 | 33.54 | 49.45 | 56.28 | 61.92 |
| GaitMGL | Ours | 63.12 | 79.75 | 84.87 | 88.60 |
| Methods | Publication | Rank-1 | Rank-5 | Rank-10 | Rank-20 |
|---|---|---|---|---|---|
| GaitSet [14] | AAAI 2019 | 46.28 | 63.58 | 70.26 | 76.82 |
| GaitPart [15] | CVPR 2020 | 44.01 | 60.68 | 67.25 | 73.47 |
| GaitGL [16] | ICCV 2022 | 47.28 | 63.56 | 69.32 | 74.18 |
| GaitBase [19] | CVPR 2023 | 60.10 | 75.40 | 80.38 | 84.16 |
| GaitMGL | Ours | 63.12 | 79.75 | 84.87 | 88.60 |
| Methods | Publication | Rank-1 | Rank-5 | mAP | mINP |
|---|---|---|---|---|---|
| PoseGait [22] | PR 2020 | 0.24 | 1.08 | 0.47 | 0.34 |
| GaitGraph1 [23] | ICIP 2021 | 6.25 | 16.23 | 5.18 | 2.42 |
| GaitGraph2 [24] | CVPR 2022 | 11.20 | 24.00 | - | - |
| GaitMGL | Ours | 22.70 | 42.70 | 18.65 | 9.48 |
| Methods | Rank-1 | Rank-5 | Rank-10 | Rank-20 |
|---|---|---|---|---|
| baseline | 57.74 | 75.87 | 81.43 | 85.93 |
| baseline + GLGCN | 62.10 | 79.00 | 84.20 | 88.30 |
| baseline + MTCN | 60.65 | 78.33 | 83.64 | 87.72 |
| ours (MTCN + GLGCN) | 63.12 | 79.75 | 84.87 | 88.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Wei, S.; Xi, L.; Wang, C. GaitMGL: Multi-Scale Temporal Dimension and Global–Local Feature Fusion for Gait Recognition. Electronics 2024, 13, 257. https://doi.org/10.3390/electronics13020257
Zhang Z, Wei S, Xi L, Wang C. GaitMGL: Multi-Scale Temporal Dimension and Global–Local Feature Fusion for Gait Recognition. Electronics. 2024; 13(2):257. https://doi.org/10.3390/electronics13020257
Chicago/Turabian StyleZhang, Zhipeng, Siwei Wei, Liya Xi, and Chunzhi Wang. 2024. "GaitMGL: Multi-Scale Temporal Dimension and Global–Local Feature Fusion for Gait Recognition" Electronics 13, no. 2: 257. https://doi.org/10.3390/electronics13020257
APA StyleZhang, Z., Wei, S., Xi, L., & Wang, C. (2024). GaitMGL: Multi-Scale Temporal Dimension and Global–Local Feature Fusion for Gait Recognition. Electronics, 13(2), 257. https://doi.org/10.3390/electronics13020257