
A MobileFaceNet-Based Face Anti-Spoofing Algorithm for Low-Quality Images


Abstract
1. Introduction
- (1)
- We build a Low-Quality Face Anti-Spoofing Dataset (LQFA-D), which contains a large number of low-quality images by simulating surveillance scenarios.
- (2)
- (3)
- We implement the proposed model and train multi-scale models by using face images with multi-scales, and we obtained the final detection results by fusing the multi-scale models. The experimental results show that the proposed FAS method has advantages in terms of accuracy and efficiency for low-quality face images.
2. Related Work
2.1. Face Anti-Spoofing (FAS)
2.1.1. Handcrafted and Hybrid Methods
2.1.2. End-to-End Deep Learning-Based Methods
2.1.3. FAS Methods for Low-Quality Face Images
2.2. Face Anti-Spoofing Dataset
3. Face Anti-Spoofing Dataset of Low-Quality Images
3.1. Collection System
- (1)
- In order to simulate real application scenarios and obtain large numbers of low-quality face images, we configured the camera as follows. Set the width and height of the captured image to be 1.5 times and twice the width of the face, respectively.
- (2)
- Adjust the speed of target generation and detection sensitivity to the maximum.
- (3)
- Enable rapid image capturing, set the threshold of capturing to 40 images per second, set the maximum time of capturing a single image to 1 s, and set the number of capturing to be unlimited.
3.2. Collection Process
3.3. Statistics of LQFA-D
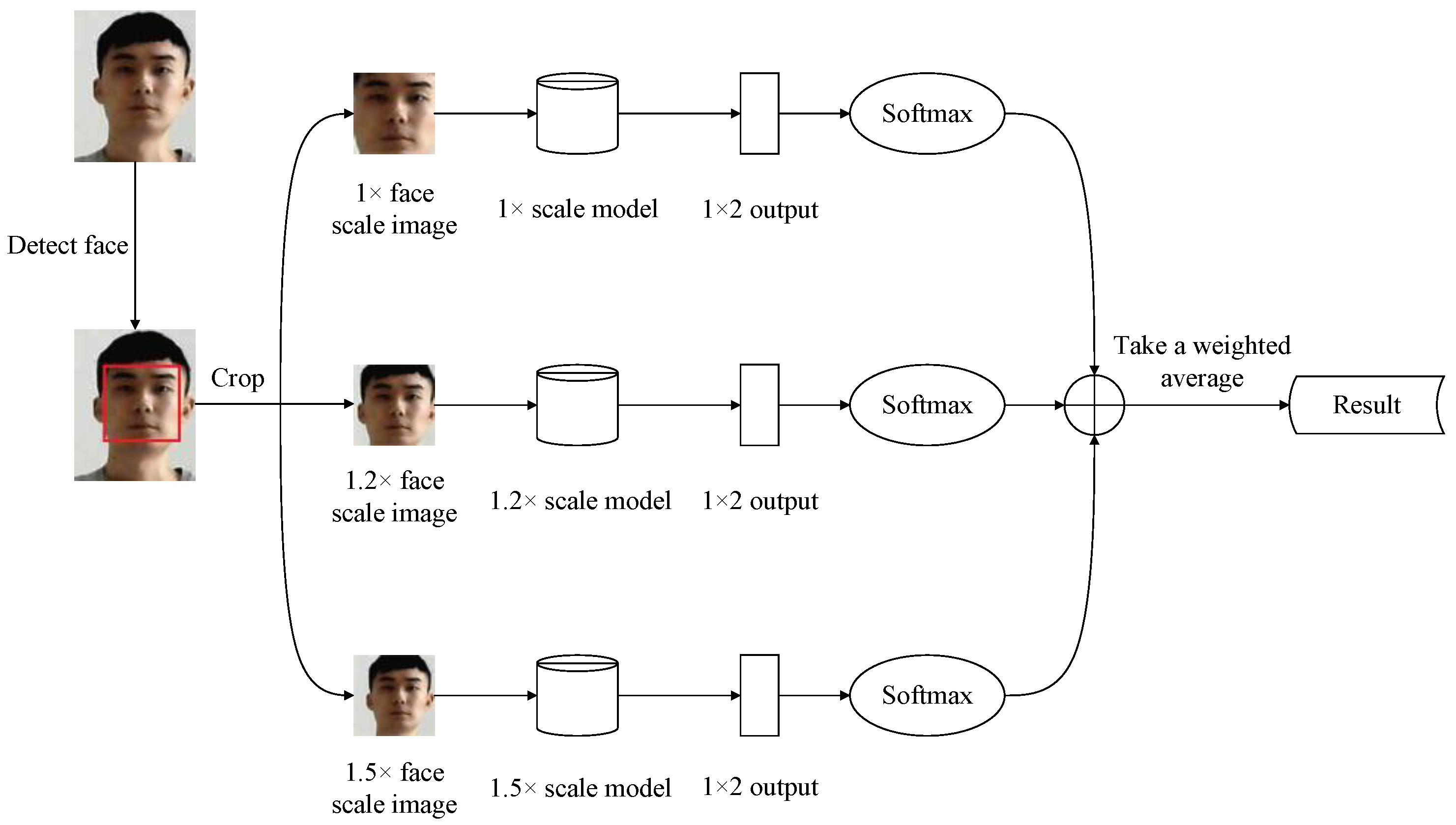
4. A Silent Face Anti-Spoofing Method for Low-Quality Images
4.1. Model Structure
4.2. Framework
5. Experimental Results and Analysis
5.1. Setup
5.2. Experimental Results
5.2.1. Evaluation of the Proposed Method
5.2.2. Complexity Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, M.; Zeng, K.; Wang, J. A survey on face anti-spoofing algorithms. J. Inf. Hiding Priv. Prot. 2020, 2, 21. [Google Scholar] [CrossRef]
- Yu, Z.; Qin, Y.; Li, X.; Zhao, C.; Lei, Z.; Zhao, G. Deep learning for face anti-spoofing: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5609–5631. [Google Scholar] [CrossRef] [PubMed]
- Ramachandra, R.; Busch, C. Presentation attack detection methods for face recognition systems: A comprehensive survey. ACM Comput. Surv. (CSUR) 2017, 50, 1–37. [Google Scholar] [CrossRef]
- Bao, W.; Li, H.; Li, N.; Jiang, W. A liveness detection method for face recognition based on optical flow field. In Proceedings of the 2009 International Conference on Image Analysis and Signal Processing, Linhai, China, 11–12 April 2009; pp. 233–236. [Google Scholar]
- Ali, A.; Deravi, F.; Hoque, S. Liveness detection using gaze collinearity. In Proceedings of the 2012 Third International Conference on Emerging Security Technologies, Lisbon, Portugal, 5–7 September 2012; pp. 62–65. [Google Scholar]
- Li, J.-W. Eye blink detection based on multiple Gabor response waves. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; pp. 2852–2856. [Google Scholar]
- Yu, Z.; Peng, W.; Li, X.; Hong, X.; Zhao, G. Remote heart rate measurement from highly compressed facial videos: An end-toend deep learning solution with video enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 151–160. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face anti-spoofing based on color texture analysis. In Proceedings of the 2015 IEEE International Conference on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 2636–2640. [Google Scholar]
- Patel, K.; Han, H.; Jain, A.K. Secure face unlock: Spoof detection on smartphones. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2268–2283. [Google Scholar] [CrossRef]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face antispoofing using speeded-up robust features and fisher vector encoding. IEEE Signal Process. Lett. 2017, 24, 141–145. [Google Scholar]
- Määttä, J.; Hadid, A.; Pietikäinen, M. Face spoofing detection from single images using micro-texture analysis. In Proceedings of the 2011 International Joint Conference on Biometrics (IJCB), Washington, DC, USA, 11–13 October 2011; pp. 1–7. [Google Scholar]
- De Freitas Pereira, T.; Komulainen, J.; Anjos, A.; De Martino, J.M.; Hadid, A.; Pietikäinen, M.; Marcel, S. Face liveness detection using dynamic texture. EURASIP J. Image Video Process. 2014, 2014, 2. [Google Scholar] [CrossRef]
- Boulkenafet, Z.; Komulainen, J.; Hadid, A. Face spoofing detection using colour texture analysis. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1818–1830. [Google Scholar] [CrossRef]
- Galbally, J.; Marcel, S.; Fierrez, J. Image quality assessment for fake biometric detection: Application to iris, fingerprint, and face recognition. IEEE Trans. Image Process. 2013, 23, 710–724. [Google Scholar] [CrossRef] [PubMed]
- Wen, D.; Han, H.; Jain, A.K. Face spoof detection with image distortion analysis. IEEE Trans. Inf. Forensics Secur. 2015, 10, 746–761. [Google Scholar] [CrossRef]
- Cai, R.; Chen, C. Learning deep forest with multi-scale local binary pattern features for face anti-spoofing. arXiv 2019, arXiv:1910.03850. [Google Scholar]
- Li, L.; Xia, Z.; Jiang, X.; Ma, Y.; Roli, F.; Feng, X. 3D face mask presentation attack detection based on intrinsic image analysis. IET Biom. 2020, 9, 100–108. [Google Scholar] [CrossRef]
- Shao, R.; Lan, X.; Yuen, P.C. Joint discriminative learning of deep dynamic textures for 3D mask face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2019, 14, 923–938. [Google Scholar] [CrossRef]
- Sharifi, O. Score-level-based face anti-spoofing system using handcrafted and deep learned characteristics. Int. J. Image Graph. Signal Process. 2019, 10, 15–20. [Google Scholar] [CrossRef]
- Li, L.; Xia, Z.; Hadid, A.; Jiang, X.; Zhang, H.; Feng, X. Replayed video attack detection based on motion blur analysis. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2246–2261. [Google Scholar] [CrossRef]
- Yang, J.; Lei, Z.; Li, S.Z. Learn convolutional neural network for face anti-spoofing. arXiv 2014, arXiv:1408.5601. [Google Scholar]
- Xu, Z.; Li, S.; Deng, W. Learning temporal features using LSTM-CNN architecture for face anti-spoofing. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 141–145. [Google Scholar]
- Tu, X.; Fang, Y. Ultra-deep neural network for face anti-spoofing. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; Springer: Cham, Switzerland, 2017; pp. 686–695. [Google Scholar]
- Yu, Z.; Zhao, C.; Wang, Z.; Qin, Y.; Su, Z.; Li, X.; Zhou, F.; Zhao, G. Searching central difference convolutional networks for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5295–5305. [Google Scholar]
- Alotaibi, A.; Mahmood, A. Deep face liveness detection based on nonlinear diffusion using convolution neural network. Signal Image Video Process. 2017, 11, 713–720. [Google Scholar] [CrossRef]
- Atoum, Y.; Liu, Y.; Jourabloo, A.; Liu, X. Face anti-spoofing using patch and depth-based CNNs. In Proceedings of the 2017 IEEE International Joint Conference on Biometrics (IJCB), Denver, CO, USA, 1–4 October 2017; pp. 319–328. [Google Scholar]
- Liu, Y.; Jourabloo, A.; Liu, X. Learning deep models for face anti-spoofing: Binary or auxiliary supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 389–398. [Google Scholar]
- Chen, X.; Xu, S.; Ji, Q.; Cao, S. A dataset and benchmark towards multi-modal face antispoofing under surveillance scenarios. IEEE Access 2021, 9, 28140–28155. [Google Scholar] [CrossRef]
- Fang, H.; Liu, A.; Wan, J.; Escalera, S.; Zhao, C.; Zhang, X.; Li, S.Z.; Lei, Z. Surveillance face anti-spoofing. arXiv 2023, arXiv:2301.00975. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; Yu, Z.; Deng, W.; Li, J.; Gao, T.; Wang, Z. Domain generalization via shuffled style assembly for face anti-spoofing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4123–4133. [Google Scholar]
- Chen, S.; Liu, Y.; Gao, X.; Han, Z. Mobilefacenets: Efficient cnns for accurate real-time face verification on mobile devices. In Proceedings of the Biometric Recognition: 13th Chinese Conference, CCBR 2018, Urumqi, China, 11–12 August 2018; Proceedings 13. Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 428–438. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Aravena, C.; Pasmino, D.; Tapia, J.E.; Busch, C. Impact of face image quality estimation on presentation attack detection. arXiv 2022, arXiv:2209.15489. [Google Scholar]
- Liu, Y.; Xu, Y.; Zou, Z.; Wang, Z.; Zhang, B.; Wu, L.; Guo, Z.; He, Z. Adversarial Domain Generalization for Surveillance Face Anti-Spoofing. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 6352–6360. [Google Scholar] [CrossRef]
- Wang, K.; Huang, M.; Zhang, G.; Yue, H.; Zhang, G.; Qiao, Y. Dynamic Feature Queue for Surveillance Face Anti-spoofing via Progressive Training. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 17–24 June 2023; pp. 6372–6379. [Google Scholar] [CrossRef]
- Tan, X.; Li, Y.; Liu, J.; Jiang, L. Face Liveness Detection from a Single Image with Sparse Low Rank Bilinear Discriminative Model. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Volume 6316, pp. 504–517. [Google Scholar]
- Zhang, Z.; Yan, J.; Liu, S.; Lei, Z.; Yi, D.; Li, S.Z. A face antispoofing database with diverse attacks. In Proceedings of the 2012 5th IAPR International Conference on Biometrics (ICB), New Delhi, India, 29 March–1 April 2012; pp. 26–31. [Google Scholar]
- Boulkenafet, Z.; Komulainen, J.; Li, L.; Feng, X.; Hadid, A. OULU-NPU: A mobile face presentation attack database with real-world variations. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 612–618. [Google Scholar]
- Zhang, Y.; Yin, Z.F.; Li, Y.; Yin, G.; Yan, J.; Shao, J.; Liu, Z. Celeba-spoof: Large-scale face anti-spoofing dataset with rich annotations. In Proceedings of the Computer Vision–ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 70–85. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural net-works. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5203–5212. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Number of Repetitions | Number of Output Channels | Step Size |
|---|---|---|---|---|
| 80 × 80 × 3 | Conv 3 × 3 | - | 64 | 2 |
| 40 × 40 × 64 | Conv 3 × 3 | - | 64 | 1 |
| 40 × 40 × 64 | bottleneck | - | 64 | 2 |
| 20 × 20 × 64 | bottleneck | 4 | 64 | 1 |
| 20 × 20 × 64 | bottleneck | - | 128 | 2 |
| 10 × 10 × 128 | bottleneck | 6 | 128 | 1 |
| 10 × 10 × 128 | bottleneck | - | 128 | 2 |
| 5 × 5 × 128 | bottleneck | 2 | 128 | 1 |
| 5 × 5 × 128 | Conv 1 × 1 | - | 512 | 1 |
| 5 × 5 × 512 | Linear GDC 5 × 5 | - | 512 | 1 |
| 1 × 1 × 512 | Linear Conv 1 × 1 | - | 2 | 1 |
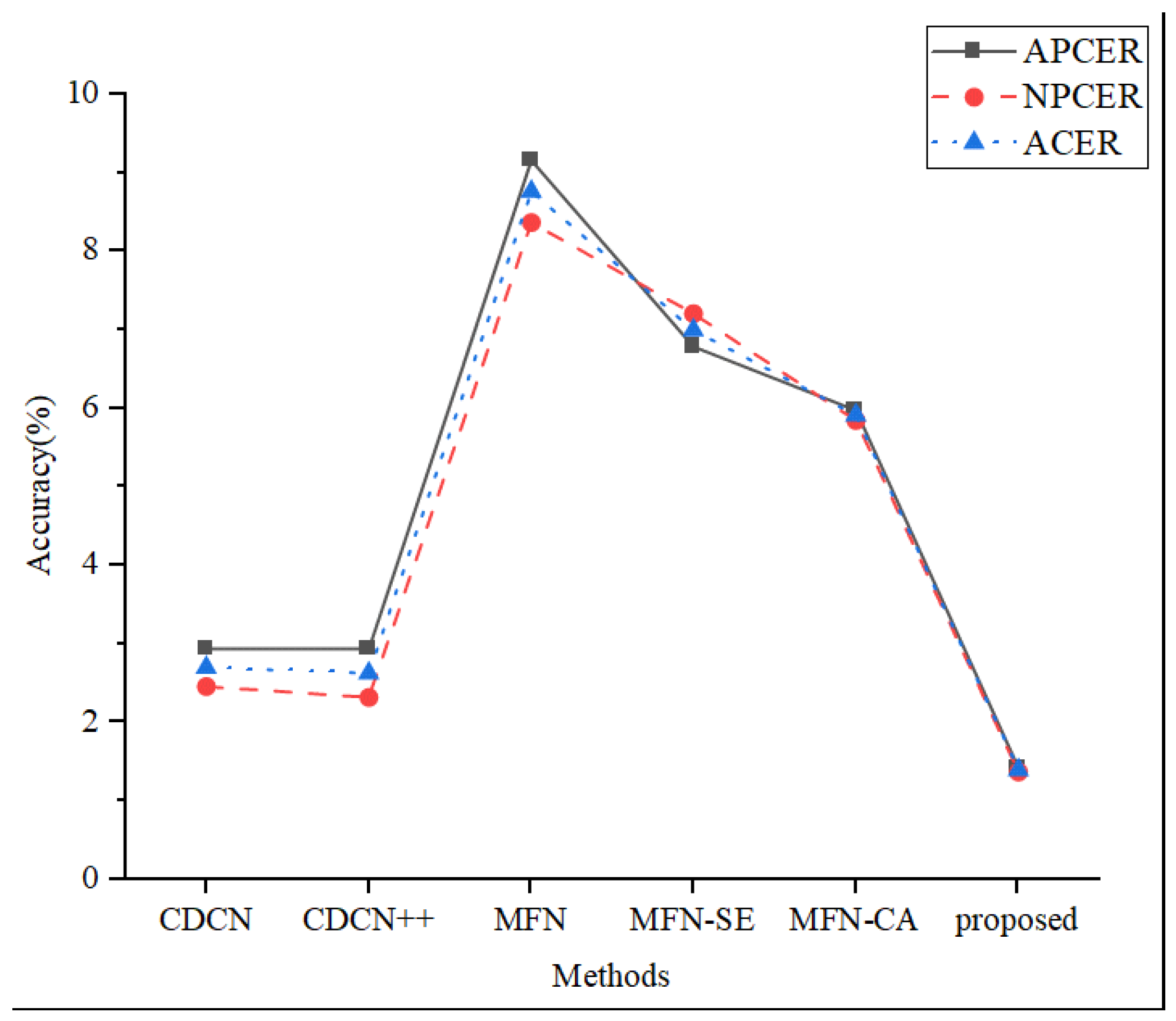
| Methods | APCER | NPCER | ACER |
|---|---|---|---|
| CDCN | 2.93% | 2.45% | 2.69% |
| CDCN++ | 2.93% | 2.31% | 2.62% |
| MobileFaceNet | 9.15% | 8.36% | 8.755% |
| MobileFaceNet+SE | 6.78% | 7.20% | 6.99% |
| MobileFaceNet+CA | 5.97% | 5.84% | 5.905% |
| The proposed method | 1.41% | 1.36% | 1.385% |
| Age | TOTAL | TP | FN | FP | TN | APCER | NPCER | ACER |
|---|---|---|---|---|---|---|---|---|
| [20, 30) | 600 | 280 | 0 | 8 | 312 | 2.5% | 0 | 1.25% |
| [30, 40) | 1328 | 408 | 8 | 12 | 900 | 1.32% | 1.92% | 1.62% |
| [40, 50) | 1620 | 456 | 8 | 12 | 1144 | 1.04% | 1.72% | 1.38% |
| ≥50 | 756 | 308 | 4 | 8 | 436 | 1.80% | 1.28% | 1.54% |
| Gender | TOTAL | TP | FN | FP | TN | APCER | NPCER | ACER |
|---|---|---|---|---|---|---|---|---|
| Male | 2800 | 896 | 12 | 28 | 1864 | 1.48% | 1.32% | 1.40% |
| Female | 1504 | 556 | 8 | 12 | 928 | 1.28% | 1.42% | 1.35% |
| People with or without Glasses | TOTAL | TP | FN | FP | TN | APCER | NPCER | ACER |
|---|---|---|---|---|---|---|---|---|
| With glasses | 2368 | 760 | 8 | 24 | 1576 | 1.50% | 1.04% | 1.27% |
| Without glasses | 1936 | 692 | 12 | 16 | 1216 | 1.30% | 1.70% | 1.50% |
| Different Lighting Conditions | TOTAL | TP | FN | FP | TN | APCER | NPCER | ACER |
|---|---|---|---|---|---|---|---|---|
| Normal | 1388 | 464 | 0 | 1 | 920 | 0.43% | 0 | 0.215% |
| Too bright | 1476 | 488 | 4 | 1 | 980 | 0.41% | 0.81% | 0.61% |
| Too dark | 1440 | 500 | 16 | 32 | 892 | 3.46% | 3.10% | 3.28% |
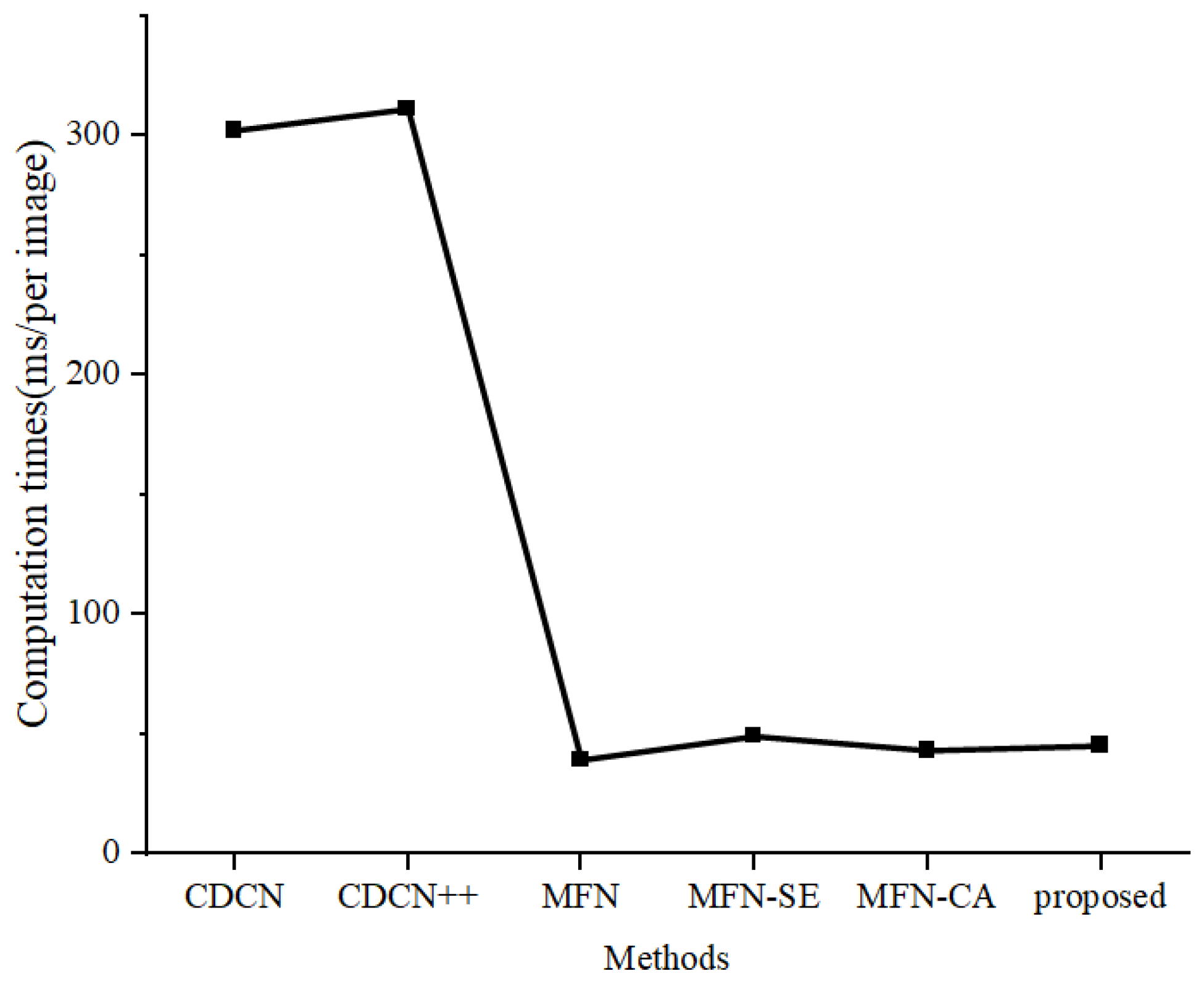
| Methods | FLOPs | The Number of Parameters | Computation Times (ms/per Image) |
|---|---|---|---|
| CDCN | 10.24 G | 2.245 M | 302 |
| CDCN++ | 10.78 G | 2.257 M | 311 |
| MobileFaceNet | 0.241 G | 0.991 M | 39 |
| MobileFaceNet+SE | 0.242 G | 1.014 M | 49 |
| MobileFaceNet+CA | 0.242 G | 0.999 M | 43 |
| The proposed method | 0.677 G | 2.997 M | 45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, J.; Wang, W.; Zhang, L.; Liu, H. A MobileFaceNet-Based Face Anti-Spoofing Algorithm for Low-Quality Images. Electronics 2024, 13, 2801. https://doi.org/10.3390/electronics13142801
Xiao J, Wang W, Zhang L, Liu H. A MobileFaceNet-Based Face Anti-Spoofing Algorithm for Low-Quality Images. Electronics. 2024; 13(14):2801. https://doi.org/10.3390/electronics13142801
Chicago/Turabian StyleXiao, Jianyu, Wei Wang, Lei Zhang, and Huanhua Liu. 2024. "A MobileFaceNet-Based Face Anti-Spoofing Algorithm for Low-Quality Images" Electronics 13, no. 14: 2801. https://doi.org/10.3390/electronics13142801
APA StyleXiao, J., Wang, W., Zhang, L., & Liu, H. (2024). A MobileFaceNet-Based Face Anti-Spoofing Algorithm for Low-Quality Images. Electronics, 13(14), 2801. https://doi.org/10.3390/electronics13142801