Abstract
With the rise of Large Language Models (LLMs), distinguishing between genuine and AI-generated content, particularly in finance, has become challenging. Previous studies have focused on binary identification of ChatGPT-generated content, overlooking other AI tools used for text regeneration. This study addresses this gap by examining various AI-regenerated content types in the finance domain. Objective: The study aims to differentiate between human-generated financial content and AI-regenerated content, specifically focusing on ChatGPT, QuillBot, and SpinBot. It constructs a dataset comprising real text and AI-regenerated text for this purpose. Contribution: This research contributes to the field by providing a dataset that includes various types of AI-regenerated financial content. It also evaluates the performance of different models, particularly highlighting the effectiveness of the Bidirectional Encoder Representations from the Transformers Base Cased model in distinguishing between these content types. Methods: The dataset is meticulously preprocessed to ensure quality and reliability. Various models, including Bidirectional Encoder Representations Base Cased, are fine-tuned and compared with traditional machine learning models using TFIDF and Word2Vec approaches. Results: The Bidirectional Encoder Representations Base Cased model outperforms other models, achieving an accuracy, precision, recall, and F1 score of 0.73, 0.73, 0.73, and 0.72 respectively, in distinguishing between real and AI-regenerated financial content. Conclusions: This study demonstrates the effectiveness of the Bidirectional Encoder Representations base model in differentiating between human-generated financial content and AI-regenerated content. It highlights the importance of considering various AI tools in identifying synthetic content, particularly in the finance domain in Pakistan.
1. Introduction
In recent years, natural language processing (NLP) has played an important role in improving computer systems’ performance for generating and understanding human content [1]. Due to the advancement of such a domain, a Large Language Model (LLM) was introduced recently for the generation of language that is relatively close to human tone, after the training of large text data [2]. The Generative Pretrained Transformer (GPT) model that was introduced by OpenAI has gained popularity in less time [3].
The founding of ChatGPT signifies a significant turning point in the development of complex computer systems, especially in the area of NLP [4]. After being trained on a large amount of textual information, ChatGPT produces quick logical and appropriate responses for the given context. Its influence can be observed in several areas, such as language acquisition, education, and communication, where its capacity to generate text like humans is constructive. The development of ChatGPT as a popular LLM signifies an important breakthrough in NLP. BERT, a massive language model developed by Google, is another noteworthy example that has significantly advanced the field of study. The increasing use of advanced AI-powered chatbots like ChatGPT underscores the importance of differentiating between text created by humans and artificial intelligence [5]. This distinction can have significant implications for various fields related to information security and digital forensics [6]. In the realm of information security, the ability to identify AI-generated language is crucial for detecting and mitigating the impact of harmful AI applications, such as deceptive social engineering or the dissemination of false and misleading information. Developing methods to distinguish AI-generated texts is essential for ensuring the integrity and accuracy of data [7], particularly in sensitive industries like banking and finance, political campaigns, and customer reviews of restaurants, movies, or products. ChatGPT can also be used for text regeneration, and the detection of ChatGPT is explored in many studies. There is a lack of identification text that is generated by tools like QuillBot, SpinBot, as well as ChatGPT. The main details about these tools are described below.
OpenAI’s GPT [8] series has sparked widespread interest in natural language processing (NLP) because of its novel technique and remarkable performance on linguistic challenges. GPT is a deep learning model that initially acquires knowledge from a large amount of text input, specifically from a transformer architecture. During this early learning stage, the model learns about the syntax, structure, and suggestions of the language. The transformer design in GPT has been recognized for properly managing complex linguistic problems. GPT produces coherent and contextually relevant writing by using a process known as “self-attention” to assess the significance of words inside a sentence. GPT can be fine-tuned using specific data for tasks like translation, summarization, question answering, and idea analysis. GPT and related models benefit people individually as well as society at large by enhancing communication, education, and healthcare services across a wide range of businesses.
In the development of NLP and text generation, Quillbot has emerged as a significant turning point [9]. AI researchers and engineers developed Quillbot as a language model to handle the difficulties of automatically paraphrasing text and growth. To improve the quality and accuracy of text, such tools currently need time. Quillbot provides superior-quality text extraction, academic scripting, creation of content, and skillful transmission by utilizing important NLP and ML strategies.
SpinBot [10] is a tool that is frequently used in marketing and content production to generate several versions of a blog post or article for search engine optimization. Nevertheless, because the automatic rewriting process does not always yield clear or comprehensible sentences, the deployment of SpinBot can result in low-quality or meaningless content. It is crucial to exercise caution while using these tools and to carefully check the results to make sure the content is still pertinent, accurate, and understandable.
2. Literature Review
Yu et al. [11] compiled a comprehensive conceptual dataset incorporated by ChatGPT users to develop identification techniques and investigate the potential negative impact of ChatGPT on academia. The conceptual dataset consists of 35,304 synthetic abstracts. Liao et al. [12] introduced the AIGC (Artificial Intelligence Generated Content) ethics framework in the healthcare sector. Their study mainly focused on comparing ChatGPT-generated texts with medical texts generated by human experts. In addition, they explored machine learning algorithms to gather and recognize medical texts created by ChatGPT. Initially, they accomplished a dataset containing both medical texts from ChatGPT and those from human specialists. Finally, they used and developed machine learning techniques to confirm the source of the generated medical text. ChatGPT has emerged as a potential tool in the medical industry, due to its advanced text analysis skills and user-friendly interface. However, ChatGPT is more concerned with understanding the meaning of text than with complicated data structures and real-time data analysis, which are normally necessary for the construction of an intelligent Clinical Decision Support System (CDSS) employing specialist AI algorithms. Although ChatGPT does not directly perform specific algorithms, it builds the framework for intelligent CDSS at the textual level.
Alamleh et al. [13] examined ChatGPT and other advanced artificial intelligence language models, highlighting concerns about distinguishing between human-written and AI-generated texts in academic and scientific contexts. The study aimed to assess the effectiveness of ML algorithms in discriminating between human-generated text and text generated by artificial intelligence. In their study, they interviewed computer science students about both paper-based and programming activities. They trained and tested a variety of ML models, including Logistic Regression (LR), Decision Tree (DT), support vector machines (SVMs), neural networks (NNs), and Random Forest (RF), using accuracy, computational efficiency, and confusion matrices. By comparing the performance of these models, they determined that the RF model is effective for such a task. Chen et al. [14] introduced a novel way of distinguishing between human-written texts and those generated by ChatGPT utilizing language-based methods. They collected and shared a preprocessed dataset called OpenGPT Text, which contained rewritten text created by ChatGPT. Then, they created, developed, and trained two distinct text classification models utilizing the highly improved pretraining method of BERT (Roberta) and the text-to-text transfer transformer (T5) in their study.
Katib et al. [15] proposed a Tunicate Swarm Algorithm with a Long Short-Term Memory Recurrent Neural Network (TSA-LSTMRNN) model to identify human and ChatGPT text in their study. Furthermore, the proposed TSA-LSTMRNN mainly focuses on word embedding, TF-IDF, and count vectorizer for the process of feature extraction. Hamed and Yu [16] demonstrated that the distributions generated by ChatGPT can be discriminated from those produced by human researchers. By developing a coordinated ML technique, they demonstrated how machine-generated articles may be distinguished from specialist-produced articles. They created an algorithmic mechanism for reliably identifying publications published by ChatGPT.
Perkins et al. [17] explored aspects of academic integrity among students utilizing artificial intelligence techniques, with a special emphasis on using ChatGPT in the LLM (Large Langue Model). They discussed the evolution of these tools and highlighted potential ways for an LLM to support students’ digital writing education, such as assisting with writing composition and instruction, facilitating AI–human collaboration, improving Automated Writing Assessment (AWA), and assisting EFL (English as a Foreign Language) students. Each institution’s academic integrity policy can determine if a student’s use of an LLM complies with academic integrity standards, which may need to be updated to reflect the changing use of these technologies in educational contexts.
Maddigan and Susnjak [18] introduced Chat2VIS, a revolutionary framework that uses Large Language Models (LLMs). This framework demonstrates how complicated language understanding challenges can be tackled, and it can guide critical and accurate final solutions more quickly than existing methods. Based on the arguments pointed out, Chat2VIS demonstrates that LLMs are a trustworthy method for visualizing natural language inquiries. Their study also demonstrates how LLM incentives may be set to protect data privacy and security over a wide range of information. To recognize machine-generated content on social media, Kumarage et al. [19] used BERT and ensemble-based techniques that used stylometric elements.
Pardos and Bhandari [20] carried out a fundamental study. They evaluated the efficiency of ChatGPT prompts to those provided by human instructors in two distinct algebra subjects: intermediate and arithmetic algebra. Their study introduces the Tunicate Multitude algorithm, which uses the TSA-LSTMRNN model to identify human-generated text and ChatGPT text. The suggested TSA-LSTMRNN method investigates the model’s decision-making and discovers any potential distinguishing patterns. Furthermore, the TSA-LSTMRNN method employs the TF-IDF (Term Frequency-Inverse Document Frequency) scheme, word embedding, and computer vectorization in the feature extraction process. The LSTMRNN model was used for both detection and classification tasks in their study. As compared to a multimodal ensemble, Dipta et al. [21] proposed a single base model with data augmentation and contrastive learning for the prediction of machine-generated text.
Research Gap
This study fills a major gap in the literature by proposing an extensive classification system that makes the distinctions between text written by QuillBot (v15.151.0), SpinBot (Basic Free Version), ChatGPT (v3.5), and real humans. Prior research has mostly concentrated on the distinction between text generated by ChatGPT and human writers, ignoring the subtleties added by other text-generation programs like QuillBot (v15.151.0), and SpinBot (Basic Free Version). This study’s incorporation of these extra classes offers a more sophisticated comprehension of text generation, facilitating more precise identification and classification of many forms of generated text. Our comprehension of the digital landscape is strengthened by this classification methodology, which improves our capacity to assess and address the spread of machine-generated information across several online platforms. The major challenges in finance AI text detection, such as domain-specific language and diverse data sources, have also been emphasized. The major contributions of this study are listed below:
- We meticulously compiled a substantial dataset of finance-related tweets sourced from Twitter, forming the cornerstone of our research.
- Utilizing this financial tweet dataset, we harnessed advanced language models, including ChatGPT, QuillBot, and SpinBot, to craft pertinent content, augmenting the depth and breadth of our collection for in-depth analysis.
- The prepared dataset of four classes was properly preprocessed before applying models.
- The different versions of Bidirectional Encoder Representations from Transformers (BERT) models, including BERT Base Cased, BERT Base Un-Cased, BERT Large Cased, BERT Large Un-Cased, Distilbert Base Cased, and Distilbert Base Un-Cased, are fine-tuned in this study.
- The performance of the “BERT Base Cased” model is also compared with various machine learning models, including Logistic Regression, Random Forest Classifier, Gradient Boosting Classifier, K Neighbors Classifier, Decision Tree Classifier, Multi-layer Perceptron (MLP) Classifier, AdaBoost Classifier, Bagging Classifier, Support Vector Classifier (SVC), and Quadratic Discriminant Analysis.
- The machine learning models are trained with TF-IDF and Word2Vec separately to properly show the robustness of the proposed fine-tuned “BERT Base Cased” model.
3. Materials and Methods
In this section, we explore the key aspects of our proposed study, including dataset preparation methods, preprocessing, and a thorough discussion of the models and techniques used in this study, see Figure 1 as an abstract diagram.
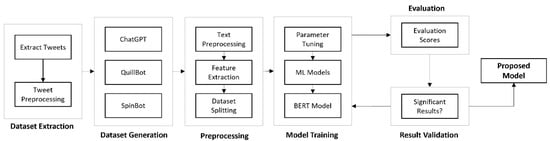
Figure 1.
Abstract diagram for proposed study.
3.1. Dataset
Using the search API on Twitter, we created a dataset of tweets for our study. We retrieved the tweets based on predefined financial terms, i.e., “debit” and “credit”, which helped us to select appropriate tweets for our study. Finally, to prepare the dataset, we regenerated the tweets with QuillBot, SpinBot, and ChatGPT-3.5. To reduce the overfitting chance, we prepared a balanced dataset, i.e., 1000 samples per class. Our prepared dataset consists of a total of 4000 samples from which 1000 belong to real financial texts, 10,000 are generated by ChatGPT-3.5, 1000 are generated by SpinBot, and 1000 are generated by QuillBot.
Preprocessing
Data preprocessing is a necessary step in the domains of machine learning and deep learning. To reduce the computation power and achieve effective accuracy, there is a need to remove unnecessary information from tweets before regenerating text from QuillBot, SpinBot, and ChatGPT. We used a well-known library, Tweets-Processor [22], to remove emojis, URLs, and hashtags from the tweets to remove the noise and irrelevant information, see Figure 2 for WordCloud.

Figure 2.
WordCloud of prepared and processed dataset.
Furthermore, the point that is noticeable here is that we have collated the English tweets only and applied lemmatization as text preprocessing for the time being to reduce the dimensionality of the dataset, see Figure 3 for the length of text in the prepared dataset. The final prepared samples can be seen in Table 1.
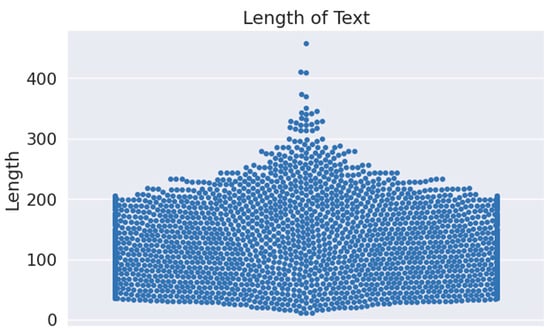
Figure 3.
Prepared dataset text length.

Table 1.
Prepared dataset samples after preprocessing.
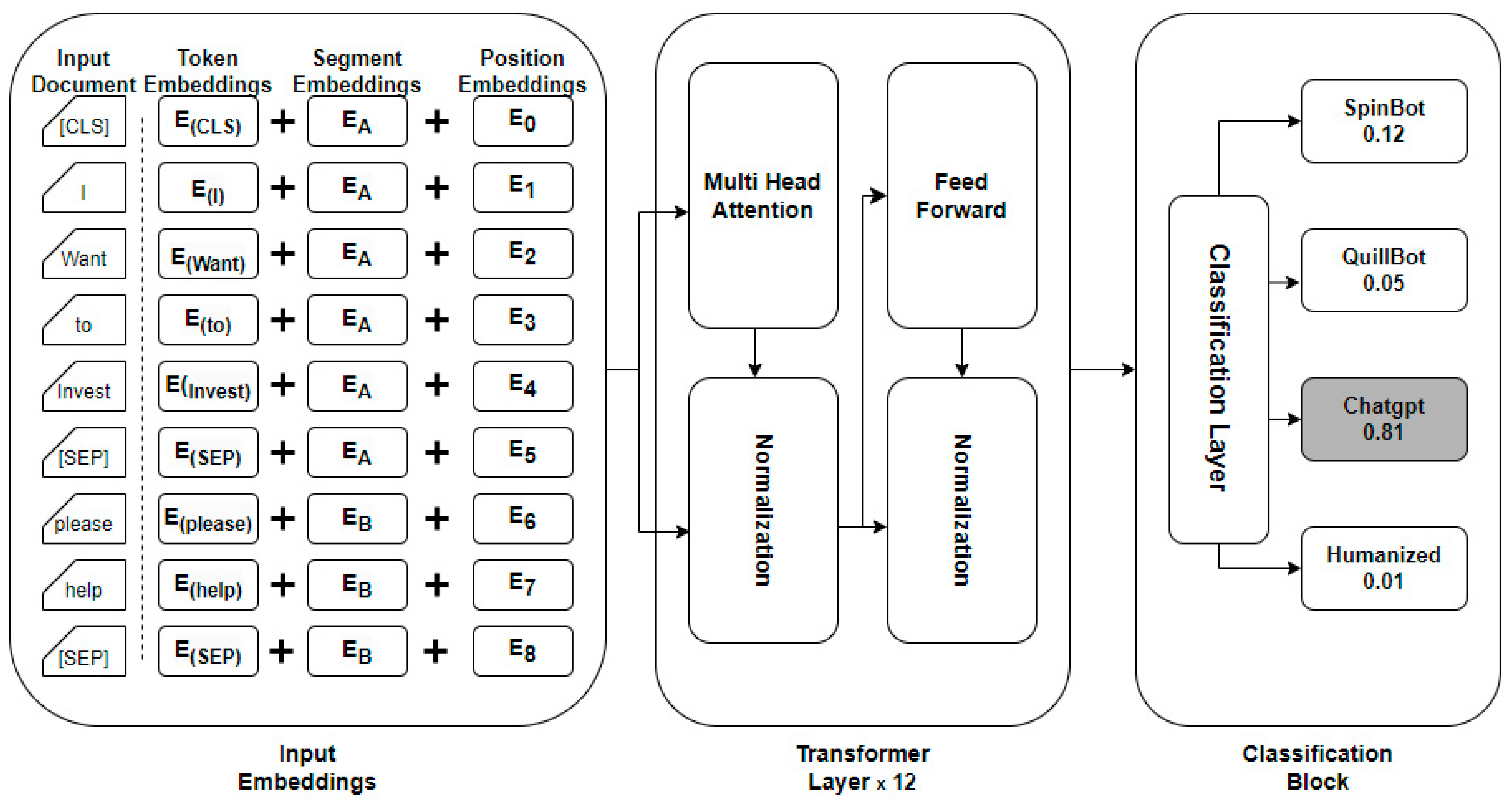
3.2. BERT Transformer Model
Development in recent years has focused on using the pretrained deep neural network as the language model and then optimizing the downstream tasks. The meaning of words and the structure of sentences must be accurately represented by these word vectors. These problems can be well solved by the BERT model. It employs a bidirectional transformer as the model’s training framework [23]. Three hyperparameters primarily decide the size of BERT: the quantity of transformer layers, the number of self-attention heads in every transformer, and the dimensionality of hidden state vectors. There are 12 transformer layers, 768 hidden state vectors, and 12 self-attention heads in the BERT base model. On the other hand, there are 24 transformer layers, 1024 hidden state vectors, and 16 self-attention heads in the BERT base model. Therefore, a huge computation power is required to train the BERT base as well as the BERT large model due to 110 M and 340 M parameters respectively. To mitigate this, large-scale unlabeled texts, such as those collected from Wikipedia, are used to pretrain BERT models in a self-supervised manner for two tasks: masked language modeling (MLM) and next sentence prediction (NSP). The base architecture of the model can be seen in Figure 4.

Figure 4.
Abstract diagram of model architecture.
Input Representation:
- BERT takes input sequences of tokens, which are the basic units of text (words or subwords).
- Each input sequence starts with a special token [CLS], which stands for classification, followed by the actual text tokens, and ends with a special token [SEP], which indicates the end of the sequence.
- BERT also uses WordPiece embeddings, which break down words into subword units to handle rare or out-of-vocabulary words.
Transformer Encoder:
- BERT utilizes the transformer architecture, which consists of multiple layers of self-attention mechanisms and feedforward neural networks.
- The self-attention mechanism allows the model to weigh the importance of different words in the input sequence when encoding each word representation.
- Each transformer layer processes the input sequence in parallel, allowing for efficient computation of contextual word embeddings.
Pre-training Objective:
- BERT is pretrained using two unsupervised learning tasks:
- Masked Language Model (MLM): BERT randomly masks some of the input tokens and then tries to predict the original words based on the context provided by the surrounding tokens.
- Next Sentence Prediction (NSP): BERT is trained to predict whether a pair of sentences appear consecutively in a document or not, helping the model learn relationships between sentences.
Fine-tuning for Text Classification:
- After pretraining, BERT can be fine-tuned on a specific text classification task [24].
- The [CLS] token representation from the final transformer layer is used as the aggregate sequence representation for the classification task.
- A simple classification layer (e.g., a SoftMax classifier) is added on top of the [CLS] representation to predict the class label for the input text.
Benefits of BERT for Text Classification:
- Bidirectional Context: BERT considers context from both directions, capturing richer semantic meaning compared to traditional models.
- Transfer Learning: Pretraining on a large corpus allows BERT to learn general language representations, which can be fine-tuned on smaller, task-specific datasets for improved performance.
- Attention Mechanism: The self-attention mechanism in BERT helps the model focus on relevant parts of the input sequence, enhancing its ability to understand complex relationships in text.
Pretraining and fine-tuning are the two phases of a BERT-based model’s training process. The trained model could be applied to predict the labels of test samples that have not been seen yet.
4. Experiments and Discussion
The evaluation metrics that were employed to ascertain the effectiveness of the proposed approach are thoroughly examined in this section [25]. It also looks at the hardware and software requirements needed for training and evaluating models. A thorough description of the various hyperparameters and the values that correlate with them is provided. This part also meticulously presents a thorough analysis of the results obtained with the proposed methodology.
4.1. Evaluation Metrics
Quantitative measurements known as assessment metrics are essential for assessing the effectiveness of a deep learning model. They are crucial for assessing how well various models or algorithms work on a certain task, figuring out how well a model or algorithm works to solve a certain problem, and pinpointing potential areas for development. This study used recall/sensitivity, ROC curve, accuracy, f1-score, precision, and confusion matrix as assessment metrics. These metrics provide a comprehensive assessment of the model’s effectiveness and provide illuminating details regarding its benefits and possible areas for development.
- Accuracy: To evaluate the overall accuracy of the model’s predictions, the accuracy metric computes the ratio of correctly classified cases to total samples, see Equation (1). However, when errors have varying degrees of importance or when datasets are uneven, relying solely on accuracy may not be adequate to provide a comprehensive evaluation.
- Precision: The ability of a model to correctly identify positive samples from the set of actual positives is referred to as its precision. This metric calculates the ratio of true positives to the sum of true positives and false positives, see Equation (2). In short, accuracy indicates how well the model performs when it generates a positive forecast.
- Recall: Recall measures how successfully the model separates positive samples from the actual positive pool. It is also frequently referred to as sensitivity or the true positive rate. This statistic is computed as the ratio of true positives to the sum of true positives and false negatives, see Equation (3). In essence, recall offers an assessment of the extent to which the model’s favorable predictions hold.
- F1-Score: Recall and precision are balanced in the F1-score, a comprehensive measure. It is calculated as these two measurements’ harmonic mean, see Equation (4). This is particularly helpful when there is an unequal distribution of errors between the classes or when there is no difference in the relative importance of the two error categories. The F1-score, which ranges from 0 to 1, is a combined assessment of the model’s recall and precision abilities. It operates most effectively at 1.
4.2. Experiments Setup
This experiment uses Python for programming. The deep learning framework used is Keras, which is built on top of TensorFlow. The experiment was developed using the Google Colab free version (https://colab.research.google.com/ (accessed on 1 February 2024)). The configuration used in the experiment is detailed in Table 2.
Table 2.
Hardware configuration.
4.3. Hyperparameter Tuning
To attain the best results in the training of the fake financial classification model, a thorough empirical testing approach was carried out to adjust several hyperparameters. Batch size, optimizer selection, learning rate, epochs, and the choice of a suitable loss function are some of these crucial variables. The goal was to determine which combination of hyperparameter values produced the best results in the classification of fake content. For the model to successfully identify between cases of real and machine-regenerated financial content with an adequate level of accuracy and resilience, an iterative optimization procedure is required. Table 3 provides the specifics of the parameters.
Table 3.
Hardware configuration.
4.4. Experimental Results and Discussion
In this study, we have considered the BERT models and their variations. Extensive experiments are performed for the prepared dataset. The different BERT variations, i.e., BERT base, BERT large, and Distilbert [26], are considered with fine-tuning in this study to propose an effective transformer model for fake text identification [27]. The BERT models are trained on BooksCorpus (800 M words) and English Wikipedia (2500 M words). The BERT base has 110 M parameters and the large has 340 parameters. The base model is light and the best for choosing such a classification task. The BERT Base Cascade model outperformed other variations, as can be seen in Table 4. The models were evaluated for 600 test samples. From Table 4, it is observable that the BERT base case model outperformed the variational models of BERT with an accuracy of 0.73, precision of 0.73, recall of 0.73, and f1 of 0.72.
Table 4.
Evaluation scores of BERT variations for fake financial text dataset.
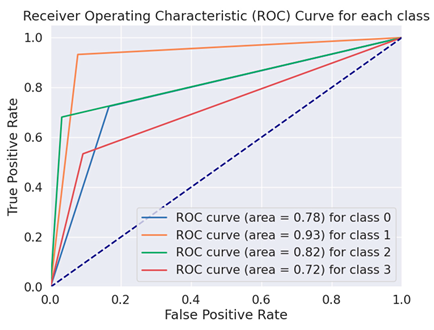
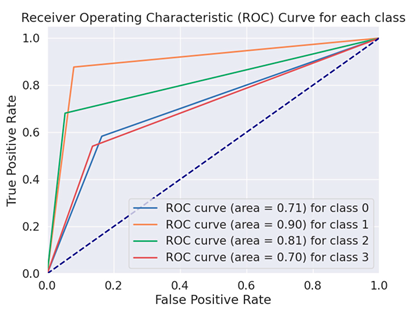
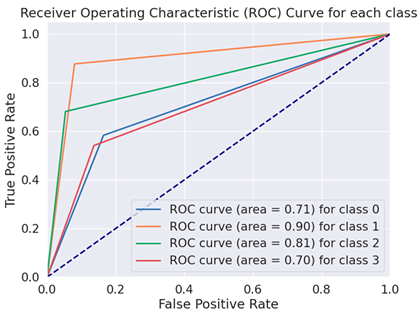
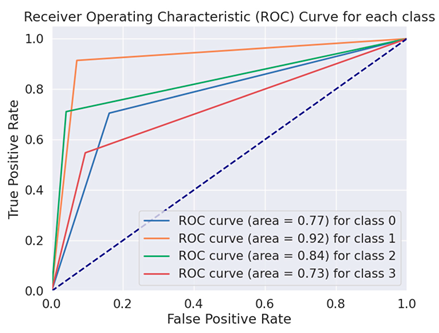
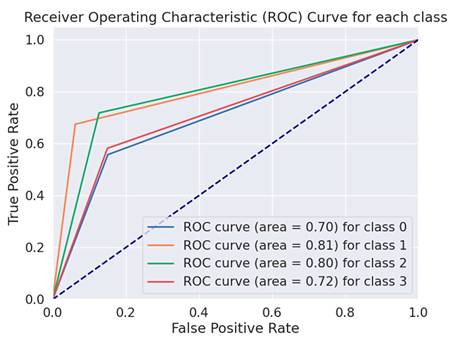
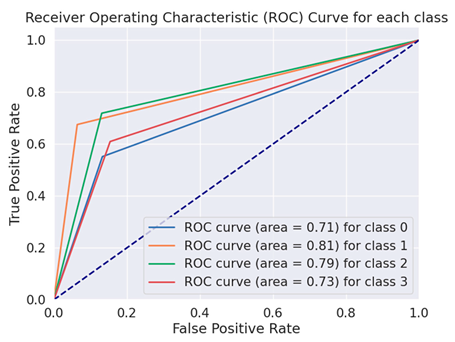
The Receiver Operating Characteristics curve (ROC) is a more crucial evaluation matrix used in the proposed study. An effective two-dimensional representation of the trade-off between true-positive and false-positive rates is an ROC curve. Every DL model was evaluated throughout the training process using a distinct set of test data that was not used in the training phase. To verify equal outcomes and assess the detectors’ generalization abilities, the data were constructed in this manner. The ROC curves of the BERT variation models are displayed in Table 5.
Table 5.
ROC curves of BERT variations for fake financial text dataset.
4.5. Robustness of the Proposed Model
For the robustness of the proposed fine-tuned BERT base model, we have also considered several machine learning models in this study. The TF-IDF (Term Frequency-Inverse Document Frequency) technique [28] has been examined in this study with machine learning models. This statistical measure assesses a word’s significance in a document about a corpus of documents. For tasks like text mining, text classification, and search engine optimization, it is frequently utilized in natural language processing and information retrieval. The results of well-known machine learning models with TF-IDF can be seen in Table 6.
Table 6.
Evaluation scores of machine learning models with TF-IDF vectorizer for fake financial text dataset.
The popular Word2Vec approach [39], which represents words as dense vectors in a continuous vector space, has also been taken into consideration in this study, see Table 7. Word2Vec is not usually used directly for the classification of texts; however, we have used it with machine learning models, and its embeddings can be quite helpful as features for classifiers.
Table 7.
Evaluation scores of machine learning models with Word2Vec for fake financial text dataset.
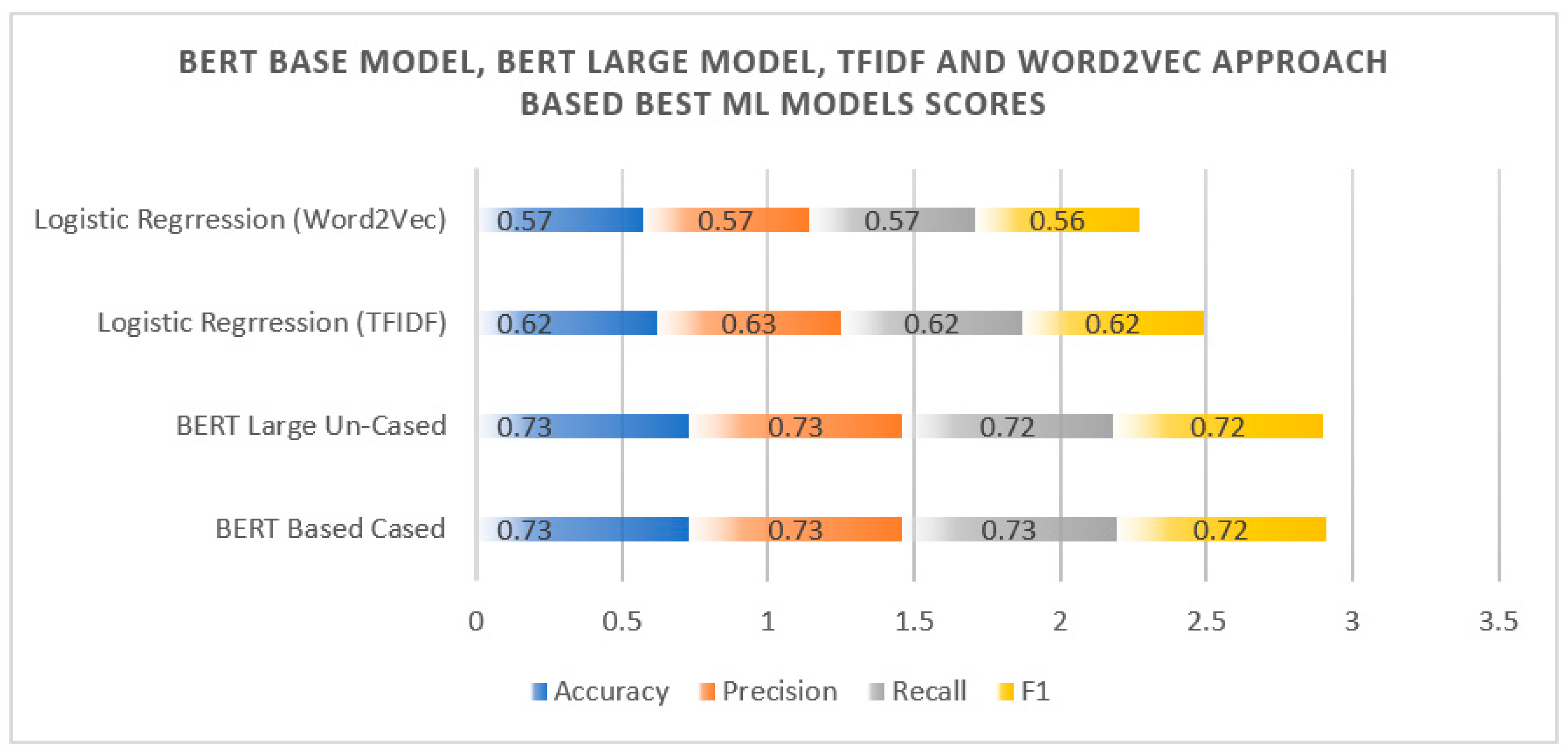
The BERT Base Cased model outperforms other models because of its ability to capture context through bidirectional training while maintaining case sensitivity, which is critical for identifying financial institutions. While BERT Large models contain more parameters, they are prone to overfitting and need more computational resources, making them unsuitable for our dataset. DistilBERT, while efficient, makes several tradeoffs in performance. Traditional models such as Logistic Regression, Random Forest, and others that use TF-IDF and Word2Vec embeddings lack the depth of contextual understanding that BERT has, resulting in lesser accuracy. This blend of complexity and generalization makes BERT Base Cased the best fit for our requirements. The extensive experiments conclude that the BERT Base Cased model outperformed not only BERT variations but also 10 machine learning models that were trained using TFIDF and Word2Vec separately. The BERT Base Cased model has superior performance with accuracy, precision, recall, and f1 of 0.73, 0.73, 0.73, and 0.72, respectively. Additionally, the BERT Large Un-Cased model is also effective due to accuracy, precision, recall, and f1 of 0.73, 0.73, 0.72, and 0.72. It is important to remember, nevertheless, that the 340 parameters in the BERT Large model make it computationally expensive. For the machine learning models trained with the TFIDF and Word2Vec approach, the logistic regression model with TFIDF outperformed the others with accuracy, precision, recall, and f1 of 0.62, 0.63, 0.62, and 0.62, respectively. The best models’ performance in terms of the BERT base model, BERT large model, TFIDF, and Word2Vec approach can be seen in Figure 5.
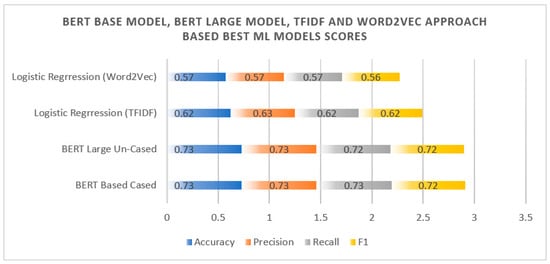
Figure 5.
BERT base model, BERT large model, and TFIDF and Word2Vec approach-based best ML models’ scores.
5. Conclusions
In this proposed study, we have covered a major gap in existing studies that are mainly based on binary fake content identification, i.e., ChatGPT and human text. We have considered the AI-based content regeneration online tools, i.e., QuillBot and SpinBot, with ChatGPT to save the financial markets from unfair content or reports. The original financial tweets retrieved from Twitter are based on financial keywords, i.e., debit, credit, and loan. Extensive preprocessing like removing emojis and URLs was performed on the prepared dataset. The different BERT variation models, i.e., BERT Base Cased, BERT Base Un-Cased, BERT Large Cased, BERT Large Un-Cased, Distilbert Base Cased, and Distilbert Base Un-Cased models, were fine-tuned for our four-class dataset: Real, ChatGPT, QuillBot, and SpinBot. The BERT Base Cased model outperformed others with accuracy, precision, recall, and f1 of 0.73, 0.73, 0.73, and 0.72, respectively. The proposed fine-tuned BERT Base Cased model is also effective due to the limited number of parameters as compared to BERT large models. For the robustness of the proposed model, different machine learning models were trained using the TFIDF and Word2VEC approach. From the machine learning perspective, the performance of Logistic Regression with TFIDF is effective with accuracy, precision, recall, and f1 of 0.62, 0.63, 0.62, and 0.62, respectively. This study is a pioneer study concerning four classes as per our knowledge. The limited dataset and four classes are the limitations of this study. The focus on specific AI tools and financial content within Pakistan may limit the study’s applicability. The keyword-based selection of real tweets may introduce noise into the dataset. In the future, extending the dataset size and improving the tweets’ collection process and classes will yield further improvements through additional refining and enhanced model performance.
Author Contributions
Conceptualization, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; methodology, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; validation, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; investigation, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; data curation, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; writing—original draft preparation, M.A.A., Ș.C.G., D.-E.-Z. and M.M.; writing—review and editing, M.A.A., Ș.C.G., D.-E.-Z. and M.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data will be available on request.
Acknowledgments
We acknowledge the use of ChatGPT (https://chat.openai.com/, accessed on 10 January 2024), Quillbot (https://quillbot.com/, accessed on 10 January 2024), and SpinBot (https://spinbot.com/, accessed on 10 January 2024), for fake dataset preparation.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gao, C.A.; Howard, F.M.; Markov, N.S.; Dyer, E.C.; Ramesh, S.; Luo, Y.; Pearson, A.T. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digit. Med. 2023, 6, 75. [Google Scholar] [CrossRef]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Akhtar, N.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2024, arXiv:2307.06435. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too; Elsevier: Amsterdam, The Netherlands, 2023; Available online: https://www.sciencedirect.com/science/article/pii/S2666651023000141 (accessed on 29 March 2024).
- Topal, M.O.; Bas, A.; van Heerden, I. Exploring transformers in natural language generation: Gpt, bert, and xlnet. arXiv 2021, arXiv:2102.08036. [Google Scholar]
- Mindner, L.; Schlippe, T.; Schaaff, K. Classification of human-and ai-generated texts: Investigating features for chatgpt. In International Conference on Artificial Intelligence in Education Technology; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Shahriar, S.; Hayawi, K. Let’s have a chat! A Conversation with ChatGPT: Technology, Applications, and Limitations. arXiv 2023, arXiv:2302.13817. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.L.; Tang, Y. A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Fitria, T.N. QuillBot as an online tool: Students’ alternative in paraphrasing and rewriting of English writing. Englisia J. Lang. Educ. Humanit. 2021, 9, 183–196. [Google Scholar] [CrossRef]
- SpinBot—Article Spinning, Text Rewriting, Content Creation Tool. Available online: https://spinbot.com/ (accessed on 29 March 2024).
- Yu, P.; Chen, J.; Feng, X.; Xia, Z. CHEAT: A Large-scale Dataset for Detecting ChatGPT-writtEn AbsTracts. arXiv 2023, arXiv:2304.12008v2. [Google Scholar]
- Liao, W.; Liu, Z.; Dai, H.; Xu, S.; Wu, Z.; Zhang, Y.; Huang, X.; Zhu, D.; Cai, H.; Liu, T.; et al. Differentiate ChatGPT-generated and Human-written Medical Texts. arXiv 2023, arXiv:2304.11567. [Google Scholar] [CrossRef]
- Alamleh, H.; AlQahtani, A.A.S.; ElSaid, A. Distinguishing Human-Written and ChatGPT-Generated Text Using Machine Learning. In Proceedings of the 2023 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27–28 April 2023; Available online: https://ieeexplore.ieee.org/abstract/document/10137767/?casa_token=BlKrjOFl998AAAAA:1b4KRytwxB1ynRxSVQFS15jLxeBtpntkB9UxP7y-uct08P-iKuys0-l736FwJNRDASbCDht7_ZuOs8s (accessed on 5 September 2023).
- Chen, Y.; Kang, H.; Zhai, V.; Li, L.; Singh, R.; Raj, B. GPT-Sentinel: Distinguishing Human and ChatGPT Generated Content. arXiv 2023, arXiv:2305.07969v2. [Google Scholar]
- Katib, I.; Assiri, F.Y.; Abdushkour, H.A.; Hamed, D.; Ragab, M. Differentiating Chat Generative Pretrained Transformer from Humans: Detecting ChatGPT-Generated Text and Human Text Using Machine Learning. Mathematics 2023, 11, 3400. [Google Scholar] [CrossRef]
- Hamed, A.A.; Wu, X. Improving Detection of ChatGPT-Generated Fake Science Using Real Publication Text: Introducing xFakeBibs a Supervised-Learning Network Algorithm. arXiv 2023, arXiv:2308.11767. [Google Scholar]
- Perkins, M. Academic Integrity considerations of AI Large Language Models in the post-pandemic era: ChatGPT and beyond. J. Univ. Teach. Learn. Pract. 2023, 20, 7. [Google Scholar] [CrossRef]
- Maddigan, P.; Susnjak, T. Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models. IEEE Access 2023, 11, 45181–45193. [Google Scholar] [CrossRef]
- Kumarage, T.; Garland, J.; Bhattacharjee, A.; Trapeznikov, K.; Ruston, S.; Liu, H. Stylometric Detection of AI-Generated Text in Twitter Timelines. arXiv 2023, arXiv:2303.03697. [Google Scholar]
- Pardos, Z.A.; Bhandari, S. Learning gain differences between ChatGPT and human tutor generated algebra hints. arXiv 2023, arXiv:2302.06871v1. [Google Scholar]
- Dipta, S.R.; Shahriar, S. HU at SemEval-2024 Task 8A: Can Contrastive Learning Learn Embeddings to Detect Machine-Generated Text? arXiv 2024, arXiv:2402.11815v2. [Google Scholar]
- Tweet-Preprocessor PyPI. Available online: https://pypi.org/project/tweet-preprocessor/ (accessed on 31 October 2023).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. Available online: https://arxiv.org/abs/1810.04805v2 (accessed on 28 March 2024).
- Arase, Y.; Tsujii, J. Transfer Fine-Tuning: A BERT Case Study. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Hong Kong, China, 3–7 November 2019; pp. 5393–5404. [Google Scholar] [CrossRef]
- Evaluation Metrics Machine Learning. Available online: https://www.analyticsvidhya.com/blog/2019/08/11-important-model-evaluation-error-metrics/ (accessed on 8 December 2020).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108v4. [Google Scholar]
- Alammary, A.S. BERT Models for Arabic Text Classification: A Systematic Review. Appl. Sci. 2022, 12, 5720. [Google Scholar] [CrossRef]
- Chawla, S.; Kaur, R.; Aggarwal, P. Text classification framework for short text based on TFIDF-FastText. Multimed. Tools Appl. 2023, 82, 40167–40180. [Google Scholar] [CrossRef]
- Li, Q.; Zhao, S.; Zhao, S.; Wen, J. Logistic Regression Matching Pursuit algorithm for text classification. Knowl. Based Syst. 2023, 277, 110761. Available online: https://www.sciencedirect.com/science/article/pii/S0950705123005117 (accessed on 29 March 2024). [CrossRef]
- Khan, T.A.; Sadiq, R.; Shahid, Z.; Alam, M.M.; Bin, M.; Su’ud, M. Sentiment Analysis using Support Vector Machine and Random Forest. J. Inform. Web Eng. 2024, 3, 67–75. [Google Scholar] [CrossRef]
- Kumar, P.; Wahid, A. Social Media Analysis for Sentiment Classification Using Gradient Boosting Machines. In Proceedings of the International Conference on Communication and Computational Technologies: ICCCT 2021, Chennai, India, 16–17 December 2021; pp. 923–934. [Google Scholar] [CrossRef]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 2020, 5, 12. [Google Scholar] [CrossRef]
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Saha, N.; Das, P.; Saha, H.N. Authorship attribution of short texts using multi-layer perceptron. Int. J. Appl. Pattern Recognit. 2018, 5, 251–259. [Google Scholar] [CrossRef]
- Zhang, X.; Xiong, G.; Hu, Y.; Zhu, F.; Dong, X.; Nyberg, T.R. A method of SMS spam filtering based on AdaBoost algorithm. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Mohammadimanesh, F.; Homayouni, S. Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation. Remote Sens. 2021, 13, 4405. [Google Scholar] [CrossRef]
- Han, T. Research on Chinese Patent Text Classification Based on SVM. In Proceedings of the 2nd International Conference on Mathematical Statistics and Economic Analysis, MSEA 2023, Nanjing, China, 26–28 May 2023. [Google Scholar] [CrossRef]
- Ghosh, A.; SahaRay, R.; Chakrabarty, S.; Bhadra, S. Robust generalised quadratic discriminant analysis. Pattern Recognit. 2021, 117, 107981. Available online: https://www.sciencedirect.com/science/article/pii/S0031320321001680 (accessed on 29 March 2024). [CrossRef]
- Cahyani, D.E.; Patasik, I. Performance comparison of tf-idf and word2vec models for emotion text classification. Bull. Electr. Eng. Inform. 2021, 10, 2780–2788. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).