


Video Detection Method Based on Temporal and Spatial Foundations for Accurate Verification of Authenticity



Abstract
1. Introduction
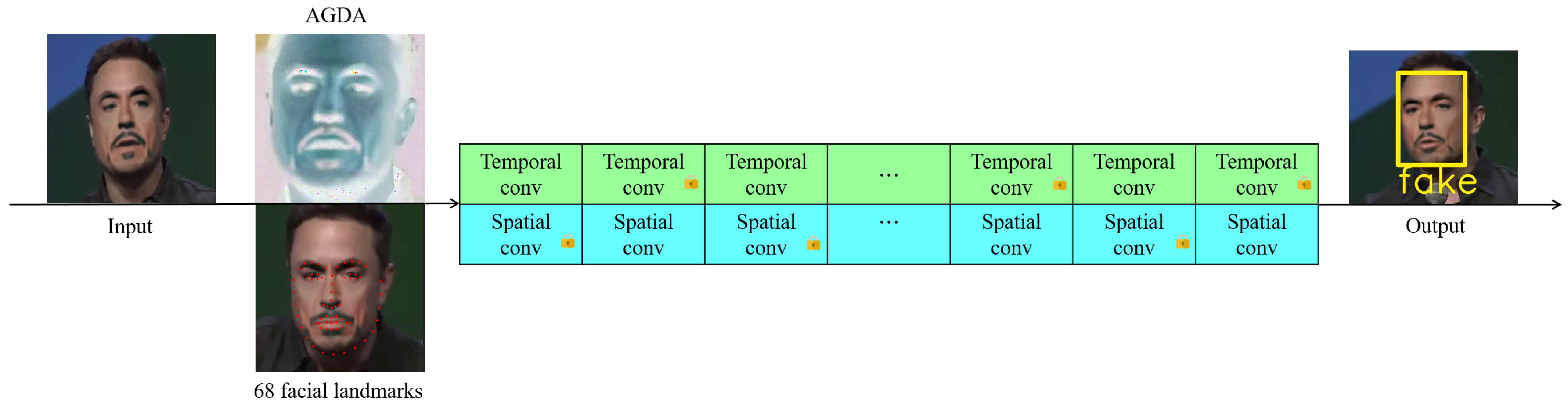
- Utilizing a cross-temporal and spatial detection method as the foundation, this study incorporates the attention-guided data augmentation (AGDA) mechanism to unearth more useful facial information. By employing the 68 facial landmarks method for facial marking and feature extraction, we have developed a deepfake video detection approach in this study.
- For the commonly used datasets, including UADFV, FaceForensics++, Celeb-DF, and DFDC, the detection outcomes of this research, when compared with binary classifier detection methods, such as “FakeVideoForensics”, “DeepFakes_FacialRegions”, “Improved Xception”, and the “AltFreezing” temporal and spatial detection approach, all demonstrate superior effectiveness.
- In detecting real videos and deepfake videos created using frameworks such as “DeepFaceLab” and “FakeApp”, our study’s detection results also show better performance compared to methods like “FakeVideoForensics”, “DeepFakes_FacialRegions”, “Improved Xception”, and “AltFreezing”. This confirms our method as a viable approach for accurately identifying the authenticity of videos.
2. Related Work
3. Proposed Method
3.1. Deepfake Video Detection Method
3.2. Deepfake Video Detection Process
- Configuration preparation: Specifies the paths for detection and output videos’ and processes’ video parameters, such as adjusting the video size (clip_size), batch size (batch_size), and image dimensions (imsize).
- Face positioning: Utilizes the 68 facial landmarks method to extract key facial points from every frame of the video.
- Alignment cutting: Performs size alignment and cropping as pre-processing for each frame’s facial image.
- Image processing: Enhances specific features in each frame’s facial image by amplifying attention through attention-guided data augmentation (AGDA).
- Input model: Inputs the pre-processed images into the network model, which is based on temporal and spatial dimensions.
- Make predictions: Utilizes the loaded model to predict the authenticity of each frame and calculates the overall authenticity of the test video.
- Result output: Compares and computes authenticity scores for each frame, producing the final detection outcome and exporting the detection result video.
4. Experimental Results and Analysis
4.1. Experimental Procedure
4.2. Deepfake Video Detection and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yadav, D.; Salmani, S. Deepfake: A Survey on Facial Forgery Technique Using Generative Adversarial Network. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 852–857. [Google Scholar]
- de Seta, G. Huanlian, or changing faces: Deepfakes on Chinese digital media platforms. Int. J. Res. New Media Technol. 2021, 27, 935–953. [Google Scholar] [CrossRef]
- Raja, K.; Ferrara, M.; Batskos, I.; Barrero, M.G.; Scherhag, U.; Venkatesh, S.K.; Singh, J.M.; Ramachandra, R.; Rathgeb, C.; Busch, C. Morphing Attack Detection-Database, Evaluation Platform, and Benchmarking. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4336–4351. [Google Scholar] [CrossRef]
- Tyagi, S.; Yadav, D. A detailed analysis of image and video forgery detection techniques. Vis. Comput. 2023, 39, 813–833. [Google Scholar] [CrossRef]
- Jain, R. Detection and Provenance: A Solution to Deepfakes? J. Stud. Res. 2023, 12. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The DeepFake Detection Challenge (DFDC) Dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-attentional Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 2185–2194. [Google Scholar]
- Wang, Z.; Bao, J.; Zhou, W.; Wang, W.; Li, H. AltFreezing for More General Video Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 4129–4138. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8107–8116. [Google Scholar]
- Jiang, L.; Li, R.; Wu, W.; Qian, C.; Loy, C.C. DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2889–2898. [Google Scholar]
- Neubert, T.; Makrushin, A.; Hildebrandt, M.; Kraetzer, C.; Dittmann, J. Extended StirTrace benchmarking of biometric and forensic qualities of morphed face images. IET Biom. 2018, 7, 325–332. [Google Scholar] [CrossRef]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A. On the Detection of Digital Face Manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5780–5789. [Google Scholar]
- Zakharov, E.; Shysheya, A.; Burkov, E.; Lempitsky, V. Few-Shot Adversarial Learning of Realistic Neural Talking Head Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9459–9468. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural Voice Puppetry: Audio-driven Facial Reenactment. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 716–731. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing Deep Fakes Using Inconsistent Head Poses. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Li, Y.; Chang, M.C.; Lyu, S. In ictu oculi: Exposing AI created fake videos by detecting eye blinking. In Proceedings of the IEEE International Workshop on Information Forensics and Security(WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips don’t lie: A Generalisable and Robust Approach to Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 5037–5047. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Rossler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1–11. [Google Scholar]
- Munoz, A.; Hernandez, M. FakeVideoForensics. Available online: https://github.com/afuentesf/fakeVideoForensics (accessed on 13 March 2022).
- Chen, B.; Ju, X.; Xiao, B.; Ding, W.; Zheng, Y.; de Albuquerque, V.H.C. Locally GAN-generated face detection based on an improved Xception. Inf. Sci. 2021, 572, 16–28. [Google Scholar] [CrossRef]
- Nguyen, H.; Yamagishi, J.; Echizen, I. Capsule-forensics: Using Capsule Networks to Detect Forged Images and Videos. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2307–2311. [Google Scholar]
- Li, Y.; Lyu, S. Exposing DeepFake Videos by Detecting Face Warping Artifacts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tolosana, R.; Romero-Tapiador, S.; Vera-Rodriguez, R.; Gonzalez-Sosa, E.; Fierrez, J. DeepFakes detection across generations: Analysis of facial regions, fusion, and performance evaluation. Eng. Appl. Artif. Intell. 2022, 110, 104673. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3207–3216. [Google Scholar]
- Trabelsi, A.; Pic, M.M.; Dugelay, J.L. Improving Deepfake Detection by Mixing Top Solutions of the DFDC. In Proceedings of the European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 643–647. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for More General Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5001–5010. [Google Scholar]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues. In Proceedings of the Computer Vision–ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 86–103. [Google Scholar]
- Shiohara, K.; Yamasaki, T. Detecting Deepfakes with Self-Blended Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18720–18729. [Google Scholar]
- Ju, Y.; Shi, B.; Chen, Y.; Zhou, H.; Dong, J.; Lam, K.-M. GR-PSN: Learning to Estimate Surface Normal and Reconstruct Photometric Stereo Images. IEEE Trans. Vis. Comput. Graph. 2023, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Bao, J.; Chen, D.; Zeng, M.; Wen, F. Exploring Temporal Coherence for More General Video Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 15044–15054. [Google Scholar]
- Kong, C.; Chen, B.; Li, H.; Wang, S.; Rocha, A.; Kwong, S. Detect and Locate: Exposing Face Manipulation by Semantic- and Noise-Level Telltales. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1741–1756. [Google Scholar] [CrossRef]
- Lou, A.; Kong, C.; Huang, J.; Hu, Y.; Kang, X.; Kot, A.C. Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection. IEEE Trans. Inf. Forensics Secur. 2023, 19, 1168–1182. [Google Scholar]
- Baltrušaitis, T.; Robinson, P.; Morency, L.-P. Openface: An open source facial behavior analysis toolkit. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Li, M.; Liu, B.; Hu, Y.; Zhang, L.; Wang, S. Deepfake Detection Using Robust Spatial and Temporal Features from Facial Landmarks. In Proceedings of the IEEE International Workshop on Biometrics and Forensics (IWBF), Rome, Italy, 6–7 May 2021; pp. 1–6. [Google Scholar]
- Xu, F.J.; Wang, R.; Huang, Y.; Guo, Q.; Ma, L.; Liu, Y. Countering Malicious DeepFakes: Survey, Battleground, and Horizon. Int. J. Comput. Vis. 2022, 130, 1678–1734. [Google Scholar]
- Faceswap. Available online: https://github.com/deepfakes/faceswap (accessed on 27 May 2023).
- Thies, J.; Zollhofer, M.; Nießner, M. Deferred Neural Rendering: Image Synthesis using Neural Textures. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Huang, D.; Torre, F.D.L. Facial Action Transfer with Personalized Bilinear Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 144–158. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. FSGAN: Subject Agnostic Face Swapping and Reenactment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4401–4410. [Google Scholar]
- Guera, D.; Delp, E.J. Deepfake Video Detection Using Recurrent Neural Networks. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | UADFV | FaceForensics++ | Celeb-DF | DFDC | Avg |
|---|---|---|---|---|---|
| FakeVideoForensics | 0.9546 | 0.8637 | 0.9559 | 0.9083 | 0.9206 |
| DeepFakes_FacialRegions | 0.2400 | 0.4000 | 0.2040 | 0.2000 | 0.2610 |
| Improved Xception | 0.5625 | 0.8605 | 0.6906 | 0.7755 | 0.7222 |
| AltFreezing | 0.9637 | 0.9494 | 0.7390 | 0.9029 | 0.8888 |
| Ours | 0.9813 | 0.9794 | 0.9787 | 0.9861 | 0.9814 |
| Methods | Real | DeepFaceLab | FakeApp |
|---|---|---|---|
| FakeVideoForensics | 0.8583 | 0.9654 | 0.9509 |
| DeepFakes_FacialRegions | 0.2105 | 0.2635 | 0.2278 |
| Improved Xception | 0.5839 | 0.4964 | 0.4599 |
| AltFreezing | 0.1188 | 0.9577 | 0.8966 |
| Ours | 0.0988 | 0.9727 | 0.9638 |
| Methods | Model Features | Comparison |
|---|---|---|
| FakeVideoForensics | Xception | Capable of detecting sequences in videos but struggles to identify images not present in datasets. |
| DeepFakes_FacialRegions | Xception, Capsule, DSP-FWA, 68 Facial Landmarks | Capable of detecting specific facial features but struggles to identify images not present in datasets. |
| Improved Xception | Improved Xception | The network model performs well but struggles to identify images not present in datasets. |
| AltFreezing | 3D ConvNet | Based on temporal and spatial dimensions, it can recognize images not present in datasets, yet it does not prioritize the detection results of real videos. |
| Ours | 3D ConvNet, 68 Facial Landmarks, AGDA | Based on temporal and spatial dimensions, incorporating the 68 facial landmarks and introducing the attention-guided data augmentation strategy (AGDA), it can recognize images not present in datasets and accurately identify authenticity. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-Y.; Lee, J.-C.; Wang, S.-J.; Chiang, C.-S.; Chou, C.-L. Video Detection Method Based on Temporal and Spatial Foundations for Accurate Verification of Authenticity. Electronics 2024, 13, 2132. https://doi.org/10.3390/electronics13112132
Lin C-Y, Lee J-C, Wang S-J, Chiang C-S, Chou C-L. Video Detection Method Based on Temporal and Spatial Foundations for Accurate Verification of Authenticity. Electronics. 2024; 13(11):2132. https://doi.org/10.3390/electronics13112132
Chicago/Turabian StyleLin, Chin-Yuan, Jen-Chun Lee, Shuenn-Jyi Wang, Chung-Shi Chiang, and Chao-Lung Chou. 2024. "Video Detection Method Based on Temporal and Spatial Foundations for Accurate Verification of Authenticity" Electronics 13, no. 11: 2132. https://doi.org/10.3390/electronics13112132
APA StyleLin, C.-Y., Lee, J.-C., Wang, S.-J., Chiang, C.-S., & Chou, C.-L. (2024). Video Detection Method Based on Temporal and Spatial Foundations for Accurate Verification of Authenticity. Electronics, 13(11), 2132. https://doi.org/10.3390/electronics13112132