Abstract
Current low-light image enhancement techniques prioritize increasing image luminance but fail to address issues including loss of intricate distortion of colors and image details. In order to address these issues that has been overlooked by all parties, this paper suggests a multi-module optimization network for enhancing low-light images by integrating deep learning with Retinex theory. First, we create a decomposition network to separate the lighting components and reflections from the low-light image. We incorporated an enhanced global spatial attention (GSA) module into the decomposition network to boost its flexibility and adaptability. This module enhances the extraction of comprehensive information from the image and safeguards against information loss. To increase the illumination component’s luminosity, we subsequently constructed an enhancement network. The Multiscale Guidance Block (MSGB) has been integrated into the improvement network, together with multilayer extended convolution to expand the sensing field and enhance the network’s capability for feature extraction. Our proposed method out-performs existing ways in both objective measures and personal evaluations, emphasizing the virtues of the procedure outlined in this paper.
1. Introduction
Digital image processing technology is becoming increasingly prevalent in electronic information devices, with applications ranging from traffic management to medical imaging, criminal investigation, remote sensing, and other extensive fields [1,2]. However, in some cases, the obtained image may not be ideal due to issues such as low brightness, resolution, contrast, and other problems. Nighttime photo recognition, real-time video surveillance, nighttime face recognition, and other applications require a solution for low image/video brightness. Improving the brightness and contrast of low-light images is of great research significance for enhancing the efficiency of computer vision work.
Enhancing low-light images can be classified into conventional techniques and deep learning methods. Conventional techniques include histogram equalization (HE) [3] and Retinex theory methods [4]. Many improved conventional techniques have been developed based on HE and Retinex theory. Improved methods based on HE includes local histogram equalization. This method processes the image locally using a sliding window to operate on the image in chunks, making image detail processing more obvious. Improved algorithms based on Retinex theory include Single Scale Retinex (SSR) [5], Multi Scale Retinex (MSR) [6], and Multi-Scale Retinex with Color Restoration (MSRCR) [7]. SSR and MSR are image processing methods that aim to retain the essential characteristics of an object by suppressing the influence of the incident image. MSR is an improvement on SSR, as it simultaneously preserves the image’s high fidelity and reduces its dynamic range. MSR can be used to enhance color, maintain color consistency, compress local dynamic range and compress global dynamic range. MSRCR is a method based on MSR that aims to eliminate color distortion in images caused by contrast enhancement in local areas. It brings out information in relatively dark areas while restoring the original colors of the image.
In 2017, Lore et al. proposed LLNet [8]. LLNet is trained using pairs of low light image datasets and can adaptively enhance image brightness by recognizing image features from the low illumination image. However, the use of Stacked Sparse Denoising Autoencoder (SSDA) as the core of LLNet may have limitations in processing high-resolution images or capturing image details. While this structure is effective at denoising and enhancing the brightness and contrast of images, it can lead to the loss of high-frequency data., which often contains detailed features of the image, during the coding phase of the network. Wei et al. [9] (2018) proposed RetinexNet. The method effectively demonstrates the Retinex decomposition effect, but the resulting images may contain noise. EnlightenGAN [10] is an image enhancement method that utilizes Generative Adversarial Networks (GANs) with U-Net structured generators and discriminators. The network is trained using adversarial loss, content loss, and illumination loss to produce images with more natural illumination. The method improves image detail retention but lacks in enhancing image brightness and removing shadowed portions. R2RNet [11] is an improved version of RetinexNet, proposing a specialized noise reduction network that is deeper and provides excellent results on the dataset used. Zhu et al. proposed RRDNet [12], a zero-sample learning method that does not rely on paired image datasets and achieves enhancement through iterative minimization of the loss function. However, the enhancement effect of RRDNet is limited by underexposure and requires a large amount of device hardware and long running time. Sci [13] introduces an auxiliary process during training, enhancing the capability of the basic unit model to better capture and process image features. Additionally, Sci [13] proposes a self-correcting weight sharing module that effectively reduces computation time and improves stability. However, the enhancement process may over-smooth or alter certain details of the image, which can negatively affect the final image quality. Existing low-light picture enhancing techniques can efficiently enhance image luminosity. However, some methods overlook image details, resulting in color distortion, noise, and other issues.
In order to address the aforementioned issues that have been overlooked by existing methodologies, this paper integrates deep learning with Retinex theory to propose a multimodular network for optimising low-light images. The network structure consists of two modules: Decom-Net and Enhance-Net. The Decom-Net module separates the low light image and normal light image into independent illumination components and smooth reflectance components. The reflectance components obtained from both should be the same, and the illumination components obtained should be free from noise interference. In the Decom-Net module, we have included the proposed global spatial attention (GSA) module to obtain more detailed global information during the Decom-Net process. Additionally, the Enhance-Net module is used to adjust the illumination component. We have employed multiscale connectivity to maintain regional consistency. In the Enhance-Net module, we have introduced the proposed Multi-Scale Guidance Block (MSGB) to better extract the multiscale feature components by expanding the receptive field. The proposed method was evaluated on a range of low-light image datasets using objective metrics and subjective visual comparisons. The study showed that the suggested technique surpasses previous methods for enhancing low-light images. Our main contributions are:
- (1)
- A multi-module low light image enhancement network is proposed, which is founded upon the Retinex theory. The network is divided into two main components: a Decom-Net module and an Enhance-Net module. Two networks are used to decompose the input image and to enhance the illumination component.
- (2)
- In the Decom-Net and augmentation modules, we added a global spatial attention (GSA) module and a Multi-Scale Guidance Block (MSGB). The global spatial attention module aims to obtain more detailed global information during the Decom-Net process. The MSGB aims to better preserve the detailed features of the illumination components.
- (3)
- Our suggested strategy outperforms existing methods in enhancing image characteristics and structure, as demonstrated by both subjective and objective evaluation metrics. Additionally, it is capable of improving image brightness and contrast while effectively reducing image noise, outperforming other methods.
2. Related Work
2.1. Total Network Structure
Low-light image enhancement methods often introduce more noise and severe color distortion. To tackle these issues, we propose a multi-module low-light image enhancement method based on Retinex. The network comprises two sub-networks: a Decom-Net module and an Enhance-Net module. During the training process, the paired image dataset is input into the Decom-Net module. The loss function constrains the output to obtain the same reflectance component of the low-light image and the normal light image, resulting in the illumination component of the low-light image. The Enhance-Net takes the illumination component and reflectance component of the low light image as inputs, with the primary objective of increasing the brightness of the illumination component. Figure 1 depicts the architecture of our proposed network.
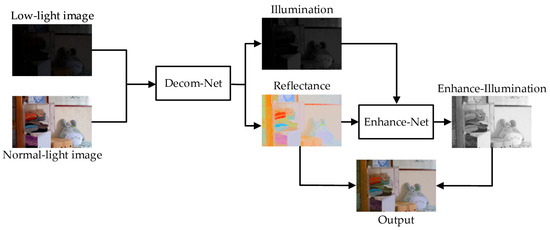
Figure 1.
Proposed general network model.
2.2. Decom-Net
To boost the brightness of dim images using Retinex theory, it is crucial to effectively distinguish the high-quality illumination part from the reflection component. The result of the decomposition will have a direct impact on the subsequent improvement of the network, the specific decomposition of the network structure is shown in Figure 2. Residual concatenation has demonstrated excellent performance in the field of image processing, which can reduce the model complexity, the risk of overfitting, and so on. We incorporate the proposed Global Spatial Attention Mechanism (GSA) module into the decomposition network. The GSA module enhances the ability of the decomposition network to focus on key regions in the image and improves the feature representation by combining the Global Spatial Attention Mechanism (GSA) and feature fusion techniques. The GSA network structure is shown in Figure 3. The main feature is the ability to adaptively adjust the importance of different spatial locations, while better preserving the original image feature information. The GSA module utilized in the decomposition network employs multiple steps to achieve enhanced decomposition outcomes. Initially, the GSA module conducts adaptive pooling to extract both maximum and average features from each channel. Subsequently, these features are merged and up-sampled to the original dimensions. Following this, a convolutional layer is applied to further process the features, introducing spatial attention to amplify key region information. Finally, the original features are fused with the attention-enhanced features to derive the final feature representation. This structured process ensures effective enhancement of feature representations within the network. The Decom-Net employs four GSA modules.
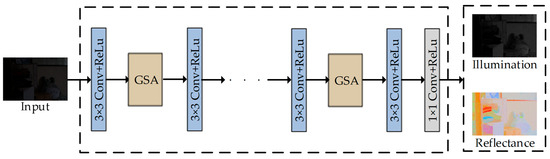
Figure 2.
Structural diagram of the Decom-Net module.
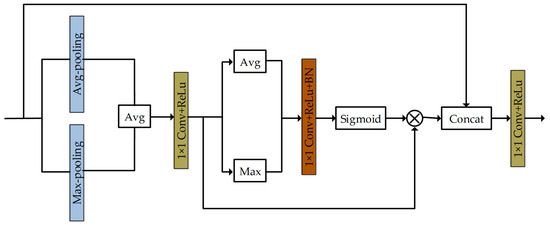
Figure 3.
Structural diagram of the GSA module.
The Decom-Net utilizes paired datasets of low illumination/normal luminance images to decompose low illumination images and normal luminance images based on obtaining the same reflectance component according to Retinex theory. Therefore, it is only necessary to work with appropriate loss functions such as reflectance consistency loss and illumination smoothing loss, and no additional normal reflectance components and illumination need to be provided in the training process.
2.3. Enhance-Net
After acquiring the illumination and reflectance components from the Decom-Net, the next step is to improve the visual effect of the enhancement results by adjusting the contrast of the illumination components. The U-Net has an excellent structural design, and a significant number of enhancement networks in the field of low-light image enhancement have adopted the U-Net as the main framework for their networks, achieving excellent results. Nevertheless, the utilization of multiple maximum pooling layers within the fundamental U-Net network has the potential to significantly impact the extraction of image features, which is contrary to the intended objective. In this paper, we utilize the improved U-Net network to construct the augmented network. Figure 4 shows the layout of the enhancement network. In this approach, the pooling layer of the original network is replaced by an adjustment to the convolutional step size. This operation increases the number of parameters, yet the resulting enhancement effect is optimal. The receptive field is the range of influence of neurons in a certain layer on the input data. The size of the receptive field is affected by the size of the convolution kernel. This directly impacts the network’s capacity to extract input information. Stacking multiple convolutional layers can be more effective in obtaining high-level information from the feature component. However, this operation may significantly increase the number of network parameters, leading to a higher risk of overfitting. To address this issue, DRNet [14] modifies the network structure connections, effectively resolving overfitting and training instability. Building on this approach, we propose a Multi-Scale Guidance Block (MSGB). The Guidance Block incorporates a dilation convolution with a variable dilation factor, illustrated in Figure 5. The Multi-Scale Guidance Block utilizes multilevel dilated convolutions, connected layer by layer. A self-guided approach is employed to utilize the dilation convolution with a larger dilation factor to guide the dilation convolution with a lower one. This approach has the potential to enhance the feature extraction ability. The enhancement network consists of 10 convolutional layers in which MSGB is inserted.
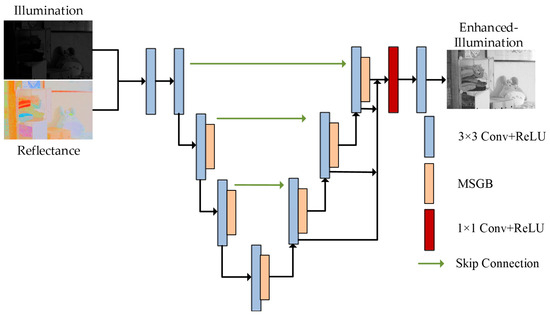
Figure 4.
Structural diagram of the Enhance-Net module.
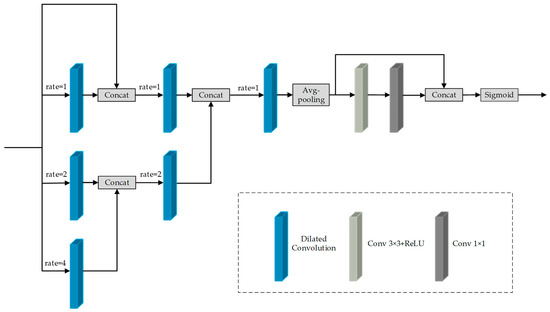
Figure 5.
Structural diagram of the MSGB module.
The network for Enhance utilizes the illumination component and reflectance component obtained from the Decom-Net to produce an improved illumination component. Finally, the reflectance component obtained from the Decom-Net and the illumination component () obtained from the Enhance-Net are multiplied element by element () to acquire the ultimate improved image (), which can be described as:
2.4. Loss Function
The loss function consists of two components: decomposition loss and illumination smoothing loss, defined below.
Decomposition loss is defined as the sum of image fidelity loss () and reflection component consistency loss ():
where is the image fidelity loss and is its corresponding coefficient. We set it to 1. is the reflection component consistency loss and is its corresponding coefficient, which we set to 0.001.
Image fidelity loss:
in the aforementioned equation, .
The Retinex theory posits that the reflection image of a low-light image and a normal-brightness image are essentially similar, yet the difference between the two illumination images is considerable. In order to facilitate the decomposition of the reflection component and the illumination component by the model, with the objective of reconstructing the corresponding original image as accurately as possible, we establish an image fidelity loss.
Reflected component consistency loss is defined as:
in the aforementioned equation, .
The Retinex theory states that the reflection component is independent of the original image and illumination components. Consequently, the reflection component, when decomposed from the low luminance image and the normal luminance image, should exhibit consistency. To achieve this, we set the reflection component consistency loss .
Illumination Smoothing Loss is composed of three terms:
The symbol denotes the enhanced illumination component. denotes the reconstruction loss in the augmentation-adjusted and vs. . represents the PSNR loss, and is its corresponding coefficient. We set it to 1.5. The smoothing loss is represented by , and is its corresponding coefficient. We set it to 0.001.
PSNR loss:
The PSNR loss, which is the value obtained during PSNR calculation, reflects the difference between the reconstructed image and the original image. The aim is to obtain a higher quality image.
Smoothing loss:
where denotes the total number of pixels. denotes the k-th pixel. denotes the neighboring pixels of the i-th pixel in its 5 × 5 window. The smoothing loss function draws upon the concept of a pixel neighborhood, wherein there are 24 neighboring pixels in addition to the center pixel k in a 5 × 5 window. The pixel difference around pixel k is calculated as the loss value.
The paper presents the total loss function of the proposed method:
3. Comparison of Experimental Results
3.1. Experimental Setup
This research uses the LOL dataset [9] and VE-LOL dataset [15] for training. The LOL dataset contains 500 pairs of low and normal brightness images. The image resolution is 400 × 600. The VE-LOL dataset is a large-scale dataset that contains 2500 pairs of low/normal brightness images, which is more diverse than the LOL scenarios. The methods proposed in our paper were tested and trained on an Intel i9 processor with 32G RAM and an NVIDIA GeForce RTX4070 GPU.
3.2. Comparison of Enhancement Effects
We use existing publicly available datasets, including LOL, VE-LOL, DICM [16] and LIME [17] datasets, to compare the method proposed with other existing low-light image enhancement methods (Retinex, MSRCR, RetinexNet, LightenNet [18], EnlightenGAN [10], DSLR [19], ExCNet [20], MBLLEN [21], ZeroDCE [22], R2RNet [11], RRDNet [12], Sci, RUAS [23]) are compared subjectively and objectively. To guarantee a fair comparison, we are using additional methods from pre-trained models provided by the authors for validation without making any modifications to the published code. For subjective comparison, we use the MOS scoring system in this paper and for objective comparison, we use commonly used image evaluation metrics (PSNR, SSIM, NIQE, Entropy, BRISQUE).
3.2.1. Subjective Evaluation
To demonstrate specific effects, we selected single images from the LOL, VE-LOL, and LIME datasets for subjective evaluation. We chose comparison methods from the 13 mentioned above, and their results are presented in Figure 6, Figure 7 and Figure 8.

Figure 6.
Enhancement effect of different algorithms on LOL dataset.

Figure 7.
Enhancement effect of different algorithms on VE-LOL dataset.

Figure 8.
Enhancement effect of different algorithms on LIME dataset.
Figure 6 illustrates the efficacy of the method proposed and other algorithms on the LOL dataset. It is evident that all the methods successfully enhance the brightness of the image. However, some methods are less effective than others in enhancing image brightness, such as LightenNet, DSLR, RRDNet, Sci, and RUAS. Among the remaining methods, R2RNet is known to cause noticeable color distortion. On the other hand, Retinex and MSRCR are effective in enhancing image brightness, but they tend to lose a significant amount of image detail in the process. The proposed method outperforms RetinexNet and EnlightenGAN in terms of image quality. The enhanced images are visually clearer and less noisy, resulting in a more natural and realistic feel. The preservation of details further contributes to the overall clarity of the image. In contrast, images generated by RetinexNet and EnlightenGAN may exhibit more noise or distortion, particularly at the edges or detailed parts of the image. The proposed method demonstrates superior performance and quality in the field of image enhancement.
Figure 7 demonstrates the enhancement achieved by the strategy suggested in this paper when compared to other methods on the VE-LOL dataset. Thereinto, the enhancement effect of Retinex can be seen as a distortion of the whole image color. Same as the LOL dataset, the luminance enhancement including LightenNet, DSLR, ExCNet, RRDNet, Sci and RUAS are not as effective as the method mentioned in this paper. The colors of the objects in R2RNet’s enhanced image appear to be less vibrant. This can be seen in the green hanger in the enhanced R2RNet image in Figure 7, where the color of the hanger in the enhanced image is bluish instead of the green it should be. The brightness of the enhancement effect produced by MSRCR and MBLLEN is more noticeable. However, upon closer inspection, it can be observed that dense white-dot noise is present in the improved images generated by these two methods. The experimental comparison shows that the proposed method in this research produces enhancement results that closely resemble the true brightness image. This is apparent not only in image brightness but also in image color consistency, detail retention, and noise reduction.
The improvement observed on the LIME dataset as a result of various algorithms is illustrated in Figure 8. It is pertinent to highlight that the LIME dataset is a reference-free image dataset and lacks a normal brightness image for reference. The results show that enhancement using classical methods such as Retinex and MSRCR results in overexposure and general distortion of the image colors. The RUAS method resulted in poor subjective visual improvement. LightenNet and RRDNet did not improve luminance as well as the other methods. The ExCNet method leads to a severe loss of detail in the enhanced image. On the contrary, the method proposed in this research improves the image’s brightness and contrast without compromising its detail and color constancy.
To ensure a fair comparison, we completed a user study. For the comparison of various validation methods, we randomly selected an image of a real scene. We invited 50 students to score each method using the MOS metrics approach. Our scores contain 5 points from 1–5, with higher scores indicating that the student had a better sensory visualization of the method. The invited students gave due consideration to image brightness, noise, color and detail features. The distribution of scores for all comparison methods is shown in Figure 9. Among the various methods, the approach was proposed and R2RNet did not achieve the lowest score of 1. In contrast, the method proposed achieved the highest number of scores, exceeding that of R2RNet. The sum of the number of scores of 5 and 4 obtained by the method of this paper is the highest, indicating that the method proposed is more suited to the visual effect of the human eye under the same environment. In order to provide a more accurate representation of the advantages of subjective vision, we compare the mean values of the ratings of all methods. The data indicates that the mean of the methods presented in this paper (3.82) is superior to that of the second-place R2RNet (3.76). The remaining methods are as follows: Retinex (1.86), MSRCP (3.56), RetinexNet (2.74), EnlighenGAN (3.24), LightenNet (2.24), DSLR (2.14), ExCNet (3.02), MBLLEN (3.52), Zero-DCE (3.06), R2RNet (3.76), RRDNet (2.4), Sci (3.12), RUAS (2.5).
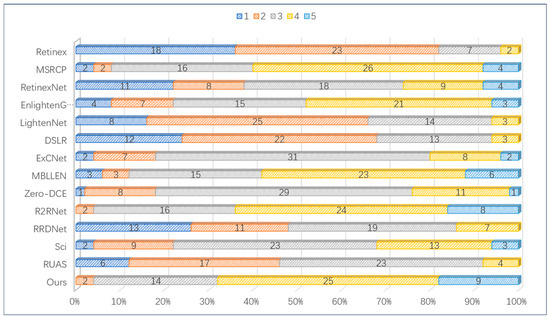
Figure 9.
Subjective evaluation bar chart of low-light image enhancement methods.
3.2.2. Objective Evaluation
The LOL dataset and VE-LOL dataset are paired image datasets with low illumination and normal brightness. Therefore, we use objective evaluation metrics such as PSNR and SSIM to evaluate reference images. Additionally, non-reference image evaluation metrics like NIQE can also be used for paired image dataset evaluation. The PSNR indicator is inversely proportional to the image distortion. The SSIM indicator varies between 0 and 1, with values nearing 1 suggesting improved images that closely resemble normal brightness. The NIQE value is indicative of better image quality when it is smaller. Please refer to Table 1 and Table 2 for further details.

Table 1.
The evaluation results of the LOL dataset and the VE-LOL dataset on PSNR, SSIM, and NIQE metrics are presented objectively. (The best results are shown in red, the second best in green and the third best in blue).
Table 2.
A Comparison of DICM Dataset Evaluations on NIQE, Entropy and BRISQUE Metrics. (The best results are shown in red, the second best in green and the third best in blue).
Table 1 shows that the proposed method outperforms most of the methods on the LOL dataset in terms of PSNR, SSIM, and NIQE metrics. which exceeded second place by 0.142 dB (18.345–18.203) in PSNR. While finishing second in the SSIM and NIQE metrics, the difference from first place was less than 0.1 in both cases, and the PSNR, SSIM and NIQE indicators on the VE-LOL dataset are in the leading position. The proposed method’s effectiveness is fully demonstrated in this study.
The DICM is an unreferenced dataset of 69 images. Table 2 shows the results of comparing various methods using NIQE, Entropy, BRISQUE, and LOE metrics for the DICM dataset. This method is the best on the DICM dataset for the NIQE and BRISQUE metrics. It obtains the second position in the Entropy metric, with a small difference from the first place.
3.2.3. Time Analysis
We selected images from three different sized image datasets and selected some of the deep learning methods for runtime comparison. The specific results are presented in Table 3. One of the fastest ways to run a speed test is RUAS. However, it is found that the running speed of the 640 480 image size still does not meet the requirements of 25 frames per second, while the requirements of general industrial cameras are 120 frames per second. Therefore, how to improve the running speed is currently one of the research hotspots. In contrast, the running time of the proposed method is not much different from that of other faster methods when obtaining the best objective indicators and the best subjective visual effects.
Table 3.
Runtime comparisons (in seconds).
4. Ablation Experiments
As a first step, we carry out a subjective visual comparison with the naked eye. Demonstrate the effectiveness of our proposed module, we selected an image from the LIME dataset for the ablation experiment comparison, as shown in Figure 10.

Figure 10.
Comparison of ablation experiments.
Figure 10 shows the effect of the missing GSA and MSGB modules and the improved effect of the method proposed. It is clear that the lack of two modules results in a noisier decomposition of the reflection component, while the illumination component loses more detail. The second and fourth rows, highlighted in green, demonstrate that our proposed method has richer detailed features compared to the method lacking the GSA module, and it effectively avoids image color distortion. The reflectance component obtained from the Decom-Net of the proposed method retains a more stereoscopic image in the red boxes of the third and fourth rows. Additionally, the comparison of the enhanced illuminated image shows that the method lacking MSGB appears to overexpose the local area and lacks image information. The proposed module is necessary and effective, as shown by subjective visual comparison.
We compared the ablation experiments of the approach without the module in Figure 10 with our suggested method using an objective image evaluation metric. We compare our complete method to networks that lack only the SGA module or only the MSGB module. The specific results are presented in Table 4.
Table 4.
Ablation Experiment Indicators Evaluation.
Table 4 demonstrates that networks lacking the GSA or MGDB module exhibit inferior performance compared to the technique introduced in this paper based on PSNR, SSIM, and NIQE metrics. This demonstrates the effectiveness of the network modules and loss functions introduced.
5. Discussion
Our study indicates that, when compared with other methods using objective evaluation metrics and subjective visual perception scores, our proposed method for low-light images demonstrates superior performance in objective metrics. Furthermore, it achieves the highest rankings subjective visual perception scores, which corroborates the efficiency of our proposed method. However, in practice, the use of low-light image enhancement methods is primarily employed for the purpose of facilitating higher visual tasks, such as nighttime task recognition, nighttime road monitoring, and so forth. Following experimental analysis, it was found that the method proposed in this paper is unable to meet the requirement of 25 frames per second for ordinary video when dealing with night-time video enhancement. Furthermore, it was observed that when dealing with part of the video obtained through video splicing techniques, some distortion occurs at the splicing place. It is our intention to conduct further research into the light weighting of our method, and to produce spliced image datasets with the intention of optimising the applicability of our proposed method.
6. Conclusions
This paper presents a deep learning-based multi-module network that employs Retinex theory to enhance low-light photos. The network comprises Decom-Net and Enhance-Net. Decom-Net decomposes images into illumination and reflectance using weight sharing, enhanced by a GSA module for global information capture. The Enhance-Net module enhances the illumination, with the assistance of an MSGB module that performs multi-stage convolution and improves feature extraction. This technique has been demonstrated to outperform other low-light enhancement algorithms in both subjective and objective evaluations.
Author Contributions
Conceptualization, J.W.; methodology, J.W.; software, Y.S.; validation, Y.S. and J.W.; investigation, J.W. and J.Y.; writing—original draft preparation, J.W.; writing—review and editing, J.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
This paper utilizes publicly available methods and datasets that can be downloaded from https://paperswithcode.com/task/low-light-image-enhancement accessed on 25 August 2023.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tang, H.; Zhu, H.; Fei, L.; Wang, T.; Cao, Y.; Xie, C. Low-illumination image enhancement based on deep learning techniques: A brief review. Photonics 2023, 10, 198. [Google Scholar] [CrossRef]
- Ye, J.; Qiu, C.; Zhang, Z. A survey on learning-based low-light image and video enhancement. Displays 2023, 81, 102614. [Google Scholar] [CrossRef]
- Patel, S.; Goswami, M. Comparative analysis of histogram equalization techniques. In Proceedings of the 2014 International Conference on Contemporary Computing and Informatics (IC3I), Mysore, Karnataka, India, 27–29 November 2014; pp. 167–168. [Google Scholar]
- Zhang, G.; Yan, P.; Zhao, H. A survey of image enhancement algorithms based on retinex theory. In Proceedings of the Third International Conference on Computer Science & Education, Wuhan, China, 12–14 December 2008. [Google Scholar]
- Jobson, D.J.; Rahman, Z.-u.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.J.; Rahman, Z.-u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed]
- Heng, B.; Xiao, D.; Zhang, X. Night color image mosaic algorithm combined with MSRCP. Comput. Eng. Des. 2019, 40, 3200–3204. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.T.; Zou, F.Z.; Lin, F.; Han, S.C. R2rnet: Low-light image enhancement via real-low to real-normal network. J. Vis. Commun. Image Represent. 2023, 90, 103712. [Google Scholar] [CrossRef]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Schwab, P.; Linhardt, L.; Bauer, S.; Buhmann, J.M.; Karlen, W. Learning counterfactual representations for estimating individual dose-response curves. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5612–5619. [Google Scholar]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. GLADNet: Low-light enhancement network with global awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018. [Google Scholar]
- Guo, X.J.; Li, Y.; Ling, H.B. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Li, C.Y.; Guo, J.C.; Porikli, F.; Pang, Y.W. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Li, M.; Yan, T.; Jing, H.; Liu, Y. Low-light enhancement method for light field images by fusing multi-scale features. J. Front. Comput. Sci. Technol. 2023, 17, 1904–1916. [Google Scholar]
- Zhang, L.; Zhang, L.J.; Liu, X.; Shen, Y.; Zhang, S.M.; Zhao, S.J.; Acm. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia (MM), Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light image/video enhancement using cnns. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 4. [Google Scholar]
- Guo, C.L.; Li, C.Y.; Guo, J.C.; Loy, C.C.; Hou, J.H.; Kwong, S.; Cong, R.M. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020; pp. 1777–1786. [Google Scholar]
- Liu, R.S.; Ma, L.; Zhang, J.A.; Fan, X.; Luo, Z.X. Retinex-inspired unrolling with cooperative prior architecture search for low-lightimage enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Nashville, TN, USA, 19–25 June 2021; pp. 10556–10565. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).