
PCNet: Leveraging Prototype Complementarity to Improve Prototype Affinity for Few-Shot Segmentation

Abstract
:1. Introduction
- We propose an adaptive self-distillation module (ASD) to solve the intra-class gap problem in the FSS task. The self-distillation method makes the support prototype and the query prototype supplement each other, and the base learner is introduced to suppress the base class in the query image.
- We propose a self-support background prototype module (SBP). The SBP is used to learn the feature comparison between the irrelevant class prototype and the query feature, which alleviates the adverse impact of the background features on the teacher prototypes generated by the adaptive self-distillation module.
- Combining an adaptive self-distillation module and a self-support background prototype module, we propose Prototype Complementarity Network (PCNet), which achieves new state-of-the-art results on the PASCAL- and COCO-.
2. Related Work
2.1. Semantic Segmentation
2.2. Few-Shot Learning
2.3. Few-Shot Semantic Segmentation
3. Method
3.1. Problem Setting
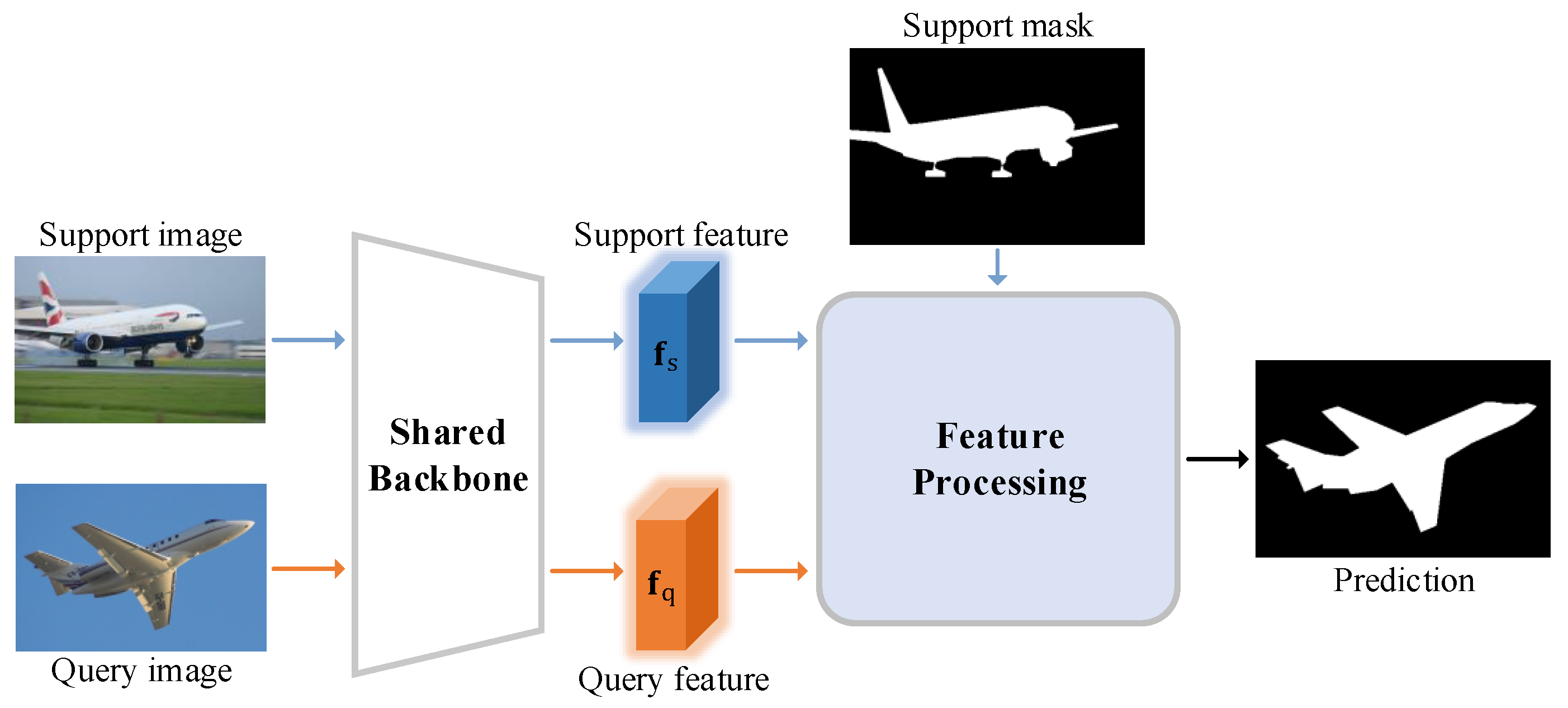
3.2. Motivation and Framework Overview
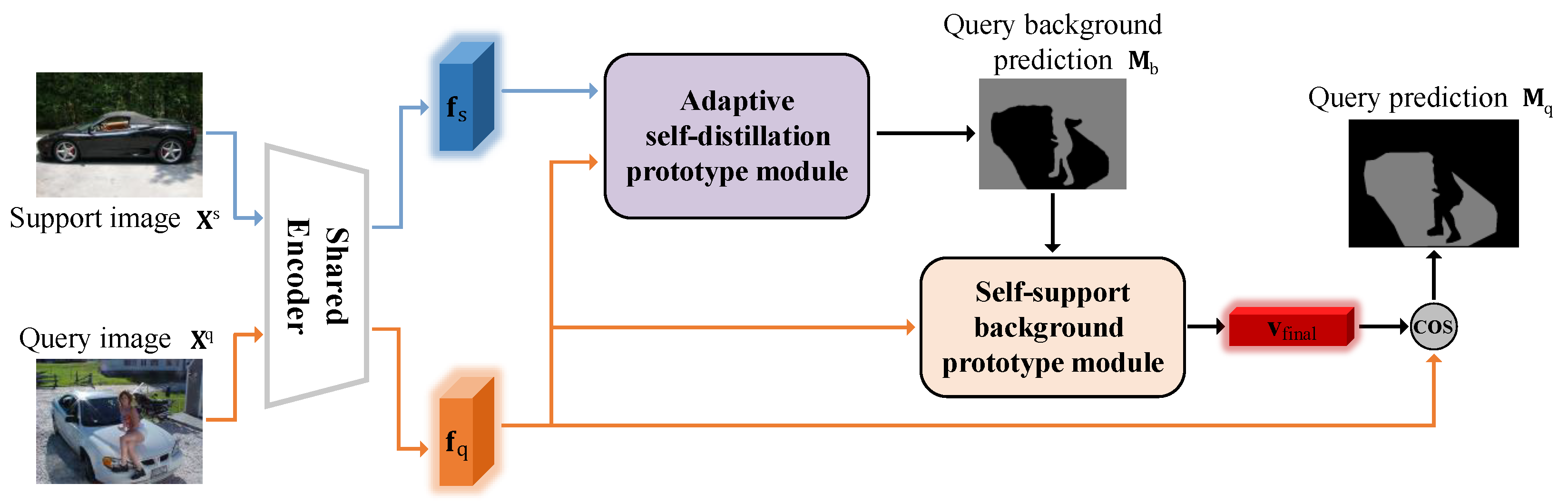
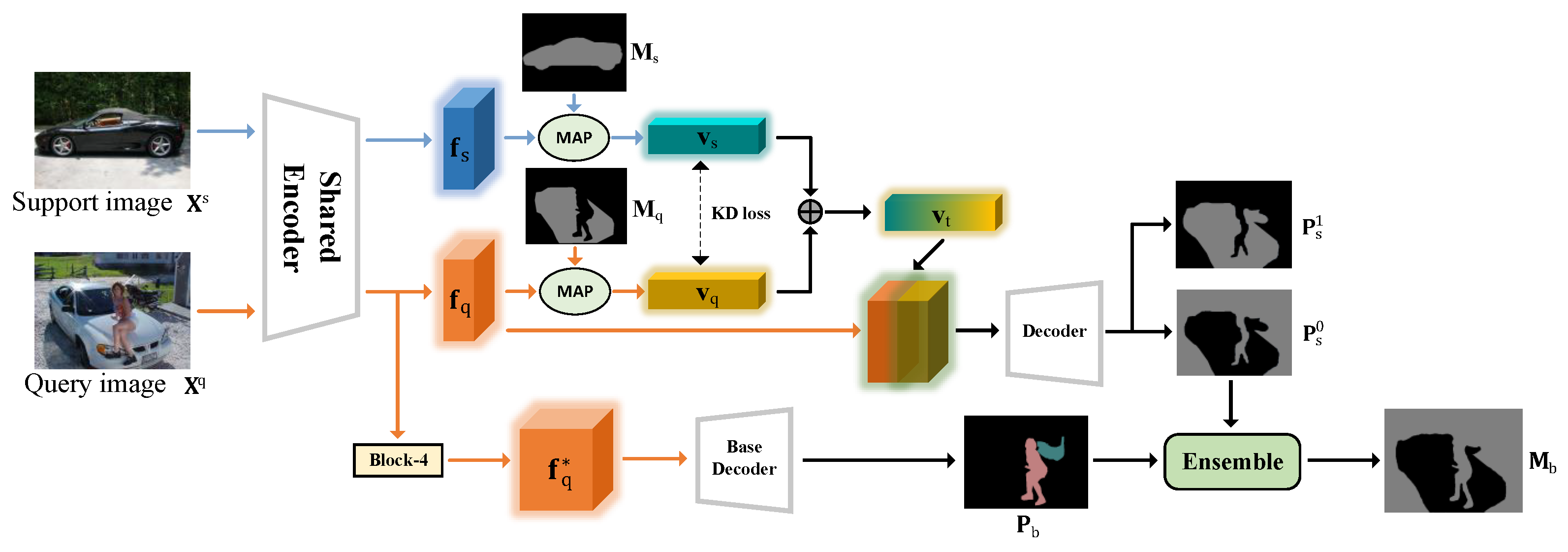
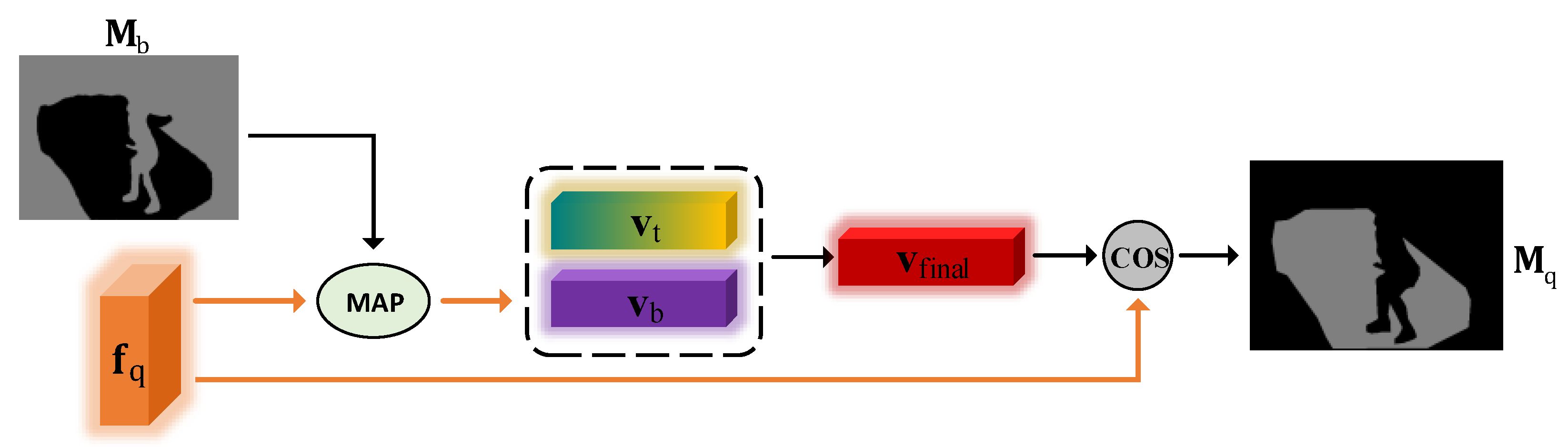
3.3. Adaptive Self-Distillation Prototype Module
3.4. Self-Support Background Prototype Module
3.5. Optimization
4. Experiments
4.1. Setup
4.2. Comparison with Previous Work
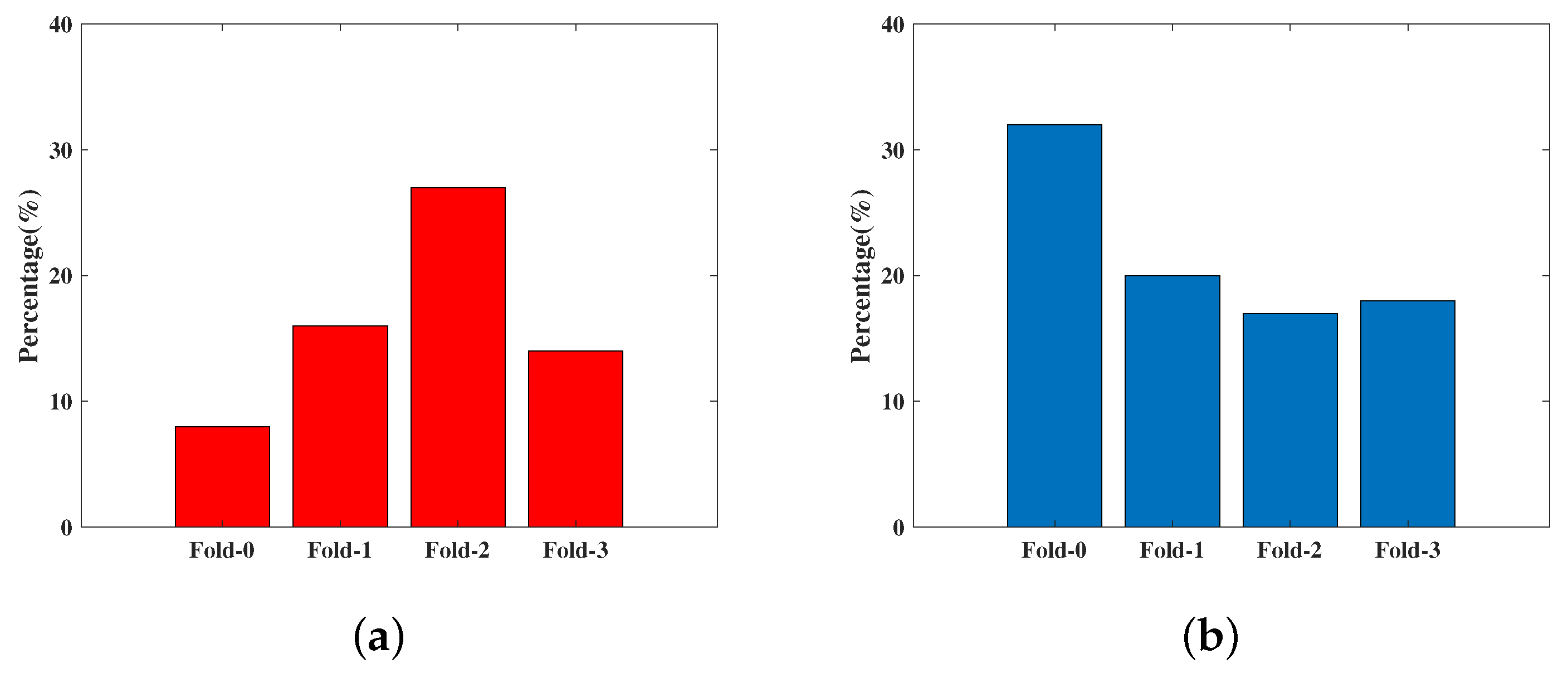
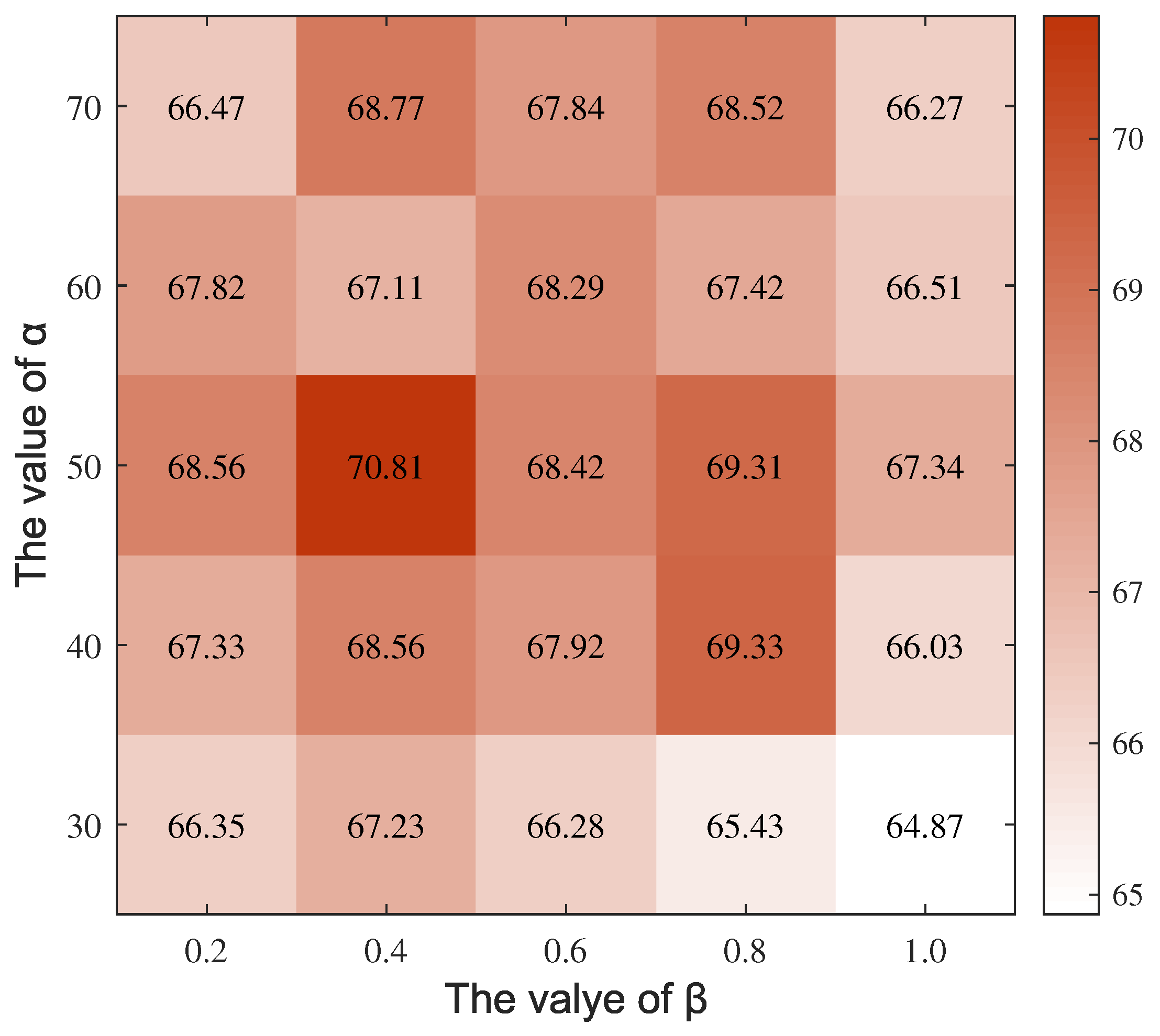
4.3. Ablation Studies
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pan, J.S.; Liang, Q.; Chu, S.C.; Tseng, K.K.; Watada, J. A multi-strategy surrogate-assisted competitive swarm optimizer for expensive optimization problems. Appl. Soft Comput. 2023, 147, 110733. [Google Scholar] [CrossRef]
- Yang, Q.; Chu, S.C.; Hu, C.C.; Kong, L.; Pan, J.S. A Task Offloading Method Based on User Satisfaction in C-RAN With Mobile Edge Computing. IEEE Trans. Mob. Comput. 2023, 1–15. [Google Scholar] [CrossRef]
- Liu, S.; Li, Y.; Chai, Q.w.; Zheng, W. Region-scalable fitting-assisted medical image segmentation with noisy labels. Expert Syst. Appl. 2024, 238, 121926. [Google Scholar] [CrossRef]
- Zhou, L.; Liu, S.; Zheng, W. Automatic Analysis of Transverse Musculoskeletal Ultrasound Images Based on the Multi-Task Learning Model. Entropy 2023, 25, 662. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Du, J.; Song, J.; Xue, Z. InfoMax Classification-Enhanced Learnable Network for Few-Shot Node Classification. Electronics 2023, 12, 239. [Google Scholar] [CrossRef]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Region-based semantic segmentation with end-to-end training. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 381–397. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Shen, X.; Cheng, M.M.; Feng, J.; Zhao, Y.; Yan, S. Stc: A simple to complex framework for weakly-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2314–2320. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Huang, Y.; Wang, Z. Collaborative Self-Supervised Transductive Few-Shot Learning for Remote Sensing Scene Classification. Electronics 2023, 12, 3846. [Google Scholar] [CrossRef]
- Guo, S.C.; Liu, S.K.; Wang, J.Y.; Zheng, W.M.; Jiang, C.Y. CLIP-Driven Prototype Network for Few-Shot Semantic Segmentation. Entropy 2023, 25, 1353. [Google Scholar] [CrossRef]
- Li, G.; Jampani, V.; Sevilla-Lara, L.; Sun, D.; Kim, J.; Kim, J. Adaptive prototype learning and allocation for few-shot segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8334–8343. [Google Scholar]
- Liu, B.; Ding, Y.; Jiao, J.; Ji, X.; Ye, Q. Anti-aliasing semantic reconstruction for few-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9747–9756. [Google Scholar]
- Siam, M.; Oreshkin, B.N.; Jagersand, M. Amp: Adaptive masked proxies for few-shot segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5249–5258. [Google Scholar]
- Chen, J.; Yuan, W.; Chen, S.; Hu, Z.; Li, P. Evo-MAML: Meta-Learning with Evolving Gradient. Electronics 2023, 12, 3865. [Google Scholar] [CrossRef]
- Kulis, B. Metric learning: A survey. Found. Trends® Mach. Learn. 2013, 5, 287–364. [Google Scholar] [CrossRef]
- Li, H.; Eigen, D.; Dodge, S.; Zeiler, M.; Wang, X. Finding task-relevant features for few-shot learning by category traversal. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1–10. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4080–4090. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, C.; Lin, G.; Liu, F.; Guo, J.; Wu, Q.; Yao, R. Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9587–9595. [Google Scholar]
- Shaban, A.; Bansal, S.; Liu, Z.; Essa, I.; Boots, B. One-shot learning for semantic segmentation. arXiv 2017, arXiv:1709.03410. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. Psanet: Point-wise spatial attention network for scene parsing. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 267–283. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. arXiv 2019, arXiv:1904.04232. [Google Scholar]
- Qi, H.; Brown, M.; Lowe, D.G. Low-shot learning with imprinted weights. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5822–5830. [Google Scholar]
- Lee, Y.; Choi, S. Gradient-based meta-learning with learned layerwise metric and subspace. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2927–2936. [Google Scholar]
- Gordon, J.; Bronskill, J.; Bauer, M.; Nowozin, S.; Turner, R.E. Meta-learning probabilistic inference for prediction. arXiv 2018, arXiv:1805.09921. [Google Scholar]
- Grant, E.; Finn, C.; Levine, S.; Darrell, T.; Griffiths, T. Recasting gradient-based meta-learning as hierarchical bayes. arXiv 2018, arXiv:1801.08930. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. Adv. Neural Inf. Process. Syst. 2019, 32, 4003–4014. [Google Scholar]
- Doersch, C.; Gupta, A.; Zisserman, A. Crosstransformers: Spatially-aware few-shot transfer. Adv. Neural Inf. Process. Syst. 2020, 33, 21981–21993. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Triantafillou, E.; Zhu, T.; Dumoulin, V.; Lamblin, P.; Evci, U.; Xu, K.; Goroshin, R.; Gelada, C.; Swersky, K.; Manzagol, P.A.; et al. Meta-dataset: A dataset of datasets for learning to learn from few examples. arXiv 2019, arXiv:1903.03096. [Google Scholar]
- Rakelly, K.; Shelhamer, E.; Darrell, T.; Efros, A.; Levine, S. Conditional networks for few-shot semantic segmentation. In Proceedings of the Workshop Track-ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, X.; Ye, Y.; Gupta, A. Zero-shot recognition via semantic embeddings and knowledge graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6857–6866. [Google Scholar]
- Tian, Z.; Zhao, H.; Shu, M.; Yang, Z.; Li, R.; Jia, J. Prior guided feature enrichment network for few-shot segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1050–1065. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Liu, C.; Li, B.; Jiao, J.; Ye, Q. Prototype mixture models for few-shot semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 763–778. [Google Scholar]
- Lang, C.; Cheng, G.; Tu, B.; Han, J. Learning what not to segment: A new perspective on few-shot segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8057–8067. [Google Scholar]
- Lu, Z.; He, S.; Zhu, X.; Zhang, L.; Song, Y.Z.; Xiang, T. Simpler is better: Few-shot semantic segmentation with classifier weight transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8741–8750. [Google Scholar]
- Fan, Q.; Pei, W.; Tai, Y.W.; Tang, C.K. Self-support few-shot semantic segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 701–719. [Google Scholar]
- Chen, J.; Gao, B.B.; Lu, Z.; Xue, J.H.; Wang, C.; Liao, Q. Apanet: Adaptive prototypes alignment network for few-shot semantic segmentation. IEEE Trans. Multimed. 2022, 25, 4361–4373. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Nguyen, K.; Todorovic, S. Feature weighting and boosting for few-shot segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 622–631. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Min, J.; Kang, D.; Cho, M. Hypercorrelation squeeze for few-shot segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6941–6952. [Google Scholar]
- Xie, G.S.; Liu, J.; Xiong, H.; Shao, L. Scale-aware graph neural network for few-shot semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5475–5484. [Google Scholar]
- Liu, Y.; Zhang, X.; Zhang, S.; He, X. Part-aware prototype network for few-shot semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 142–158. [Google Scholar]
- Liu, J.; Qin, Y. Prototype refinement network for few-shot segmentation. arXiv 2020, arXiv:2002.03579. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Model | mIoU(PASCAL-) | Limitations | |
|---|---|---|---|---|
| 1-Shot | 5-Shot | |||
| Siamese Neural Network-based method | OSLSM [42] | 40.80 | 44.00 | Double branch has more parameters, which is computationally expensive and prone to overfitting, and multiple samples are less efficient. |
| PFENet [44] | 60.80 | 61.90 | ||
| CANet [43] | 55.40 | 57.10 | ||
| BAM [46] | 64.41 | 68.76 | ||
| Prototype Learning-based method | PANet [20] | 48.10 | 55.70 | Some spatial information is lost, it is difficult to adapt to the appearance and shape of different images, and the effect of boundary segmentation is not good. |
| PMMs [45] | 56.30 | 57.30 | ||
| Attention Mechanism-based method | PGNet [21] | 56.00 | 58.50 | All input vectors participate in the training, which is computationally expensive and difficult to capture the position information of the image. |
| CWT [47] | 58.00 | 64.70 | ||
| FG Pixels | BG Pixels | ||
|---|---|---|---|
| cross-object | intra-object | cross-object | intra-object |
| 0.308 | 0.416 | 0.298 | 0.365 |
| Backbone | Method | 1-Shot | 5-Shot | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean | ||
| VGG16 | OSLSM [42] | 33.60 | 55.30 | 40.90 | 33.50 | 40.80 | 35.90 | 58.10 | 42.70 | 39.10 | 44.00 |
| PANet [20] | 42.30 | 58.00 | 51.10 | 41.20 | 48.10 | 51.80 | 64.60 | 59.80 | 46.50 | 55.70 | |
| FWB [51] | 47.00 | 59.60 | 52.60 | 48.30 | 51.90 | 50.90 | 62.90 | 56.50 | 50.10 | 55.10 | |
| PFENet [44] | 56.90 | 68.20 | 54.40 | 52.40 | 58.00 | 59.00 | 69.10 | 54.80 | 52.90 | 59.00 | |
| HSNet [57] | 59.60 | 65.70 | 59.60 | 54.00 | 59.70 | 64.90 | 69.00 | 64.10 | 58.60 | 64.10 | |
| APANet [49] | 58.00 | 68.90 | 57.00 | 52.20 | 59.00 | 59.80 | 70.00 | 62.70 | 57.70 | 62.60 | |
| BAM [46] | 63.18 | 70.77 | 66.14 | 57.57 | 64.41 | 67.36 | 73.05 | 70.61 | 64.00 | 68.76 | |
| Baseline | 59.54 | 68.36 | 65.55 | 54.73 | 62.04 | 64.12 | 70.41 | 69.74 | 63.62 | 66.97 | |
| PCNet (ours) | 64.93 | 72.21 | 66.81 | 59.29 | 65.81 | 69.97 | 74.68 | 72.01 | 67.75 | 71.10 | |
| ResNet50 | CANet [43] | 52.50 | 65.90 | 51.30 | 51.90 | 55.40 | 55.50 | 67.80 | 51.90 | 53.20 | 57.10 |
| PGNet [21] | 56.00 | 66.90 | 50.60 | 50.40 | 56.00 | 57.70 | 68.70 | 52.90 | 54.60 | 58.50 | |
| RPMM [45] | 55.20 | 66.90 | 52.60 | 50.70 | 56.30 | 56.30 | 67.30 | 54.50 | 51.00 | 57.30 | |
| PFENet [44] | 61.70 | 69.50 | 55.40 | 56.30 | 60.80 | 63.10 | 70.70 | 55.80 | 57.90 | 61.90 | |
| HSNet [57] | 64.30 | 70.70 | 60.30 | 60.50 | 64.00 | 70.30 | 73.20 | 67.40 | 67.10 | 69.50 | |
| SAGNN [58] | 64.70 | 69.60 | 57.00 | 57.20 | 62.10 | 64.90 | 70.00 | 57.90 | 59.30 | 62.80 | |
| APANet [49] | 62.20 | 70.50 | 61.10 | 58.10 | 63.00 | 63.30 | 72.00 | 68.40 | 60.20 | 66.00 | |
| BAM [46] | 68.97 | 73.59 | 67.55 | 61.13 | 67.81 | 70.59 | 75.05 | 70.79 | 67.20 | 70.91 | |
| Baseline | 64.52 | 71.88 | 66.01 | 58.31 | 65.18 | 67.55 | 72.92 | 70.23 | 66.74 | 69.36 | |
| PCNet (ours) | 67.84 | 74.32 | 67.70 | 63.11 | 68.24 | 70.81 | 75.46 | 71.35 | 67.47 | 71.27 | |
| Backbone | Method | FBIoU (%) | |
|---|---|---|---|
| 1-Shot | 5-Shot | ||
| ResNet50 | ASGNet [12] | 60.40 | 67.00 |
| PGNet [21] | 69.90 | 70.50 | |
| PPNet [59] | 69.19 | 75.76 | |
| PFENet [44] | 73.30 | 73.90 | |
| HSNet [57] | 76.70 | 80.60 | |
| BAM [46] | 79.71 | 82.18 | |
| PCNet (ours) | 80.36 | 82.60 | |
| Backbone | Method | 1-Shot | 5-Shot | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean | ||
| VGG16 | FWB [51] | 18.35 | 16.72 | 19.59 | 25.43 | 20.02 | 20.94 | 19.24 | 21.94 | 28.39 | 22.63 |
| PFENet [44] | 35.40 | 38.10 | 36.80 | 34.70 | 36.30 | 38.20 | 42.50 | 41.80 | 38.90 | 40.40 | |
| PRNet [60] | 27.46 | 32.99 | 26.70 | 28.98 | 29.03 | 31.18 | 36.54 | 31.54 | 32.00 | 32.82 | |
| SAGNN [58] | 35.00 | 40.50 | 37.60 | 36.00 | 37.30 | 37.20 | 45.20 | 40.40 | 40.00 | 40.70 | |
| PANet [20] | - | - | - | - | 20.90 | - | - | - | - | 29.70 | |
| APANet [49] | 35.60 | 40.00 | 36.00 | 37.10 | 37.20 | 40.10 | 48.70 | 43.30 | 40.70 | 43.20 | |
| BAM [46] | 38.96 | 47.04 | 46.41 | 41.57 | 43.50 | 47.02 | 52.62 | 48.59 | 49.11 | 49.34 | |
| Baseline | 38.34 | 46.32 | 43.62 | 39.75 | 41.96 | 44.21 | 48.57 | 44.26 | 47.32 | 46.09 | |
| PCNet(ours) | 39.11 | 49.16 | 46.90 | 42.51 | 44.24 | 46.74 | 54.19 | 52.72 | 49.79 | 50.86 | |
| ResNet50 | ASGNet [12] | - | - | - | - | 34.50 | - | - | - | - | 42.40 |
| HSNet [57] | 36.30 | 43.10 | 38.70 | 38.70 | 39.20 | 43.30 | 51.30 | 48.20 | 45.00 | 46.90 | |
| PPNet [59] | 34.50 | 25.40 | 24.30 | 18.60 | 25.70 | 48.30 | 30.90 | 35.70 | 30.20 | 36.20 | |
| RPMM [45] | 29.50 | 36.80 | 29.00 | 27.00 | 30.60 | 33.80 | 42.00 | 33.00 | 33.30 | 35.50 | |
| APANet [49] | 37.50 | 43.90 | 39.70 | 40.70 | 40.50 | 39.80 | 46.90 | 43.10 | 42.20 | 43.00 | |
| CWT [47] | 32.20 | 36.00 | 31.60 | 31.60 | 32.90 | 40.10 | 43.80 | 39.00 | 42.40 | 41.30 | |
| SSP [48] | 46.40 | 35.20 | 27.30 | 25.40 | 33.60 | 53.80 | 41.50 | 36.00 | 33.70 | 41.30 | |
| BAM [46] | 43.41 | 50.59 | 47.49 | 43.42 | 46.23 | 49.26 | 54.20 | 51.63 | 49.55 | 51.16 | |
| Baseline | 41.72 | 44.15 | 49.36 | 41.27 | 42.50 | 44.02 | 47.42 | 46.34 | 45.96 | 45.93 | |
| PCNet(ours) | 43.57 | 52.08 | 47.71 | 44.13 | 46.79 | 48.56 | 54.73 | 52.61 | 50.93 | 51.71 | |
| Methods | Fold-0 | Fold-1 | Fold-2 | Fold-3 | Mean |
|---|---|---|---|---|---|
| Baseline | 64.52 | 71.88 | 66.01 | 58.31 | 65.18 |
| Baseline + SBP | 65.73 | 72.82 | 66.34 | 60.48 | 66.34 |
| Baseline + ASD | 66.94 | 73.45 | 66.93 | 62.65 | 67.49 |
| PCNet | 67.84 | 74.32 | 67.70 | 63.11 | 68.24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.-Y.; Liu, S.-K.; Guo, S.-C.; Jiang, C.-Y.; Zheng, W.-M. PCNet: Leveraging Prototype Complementarity to Improve Prototype Affinity for Few-Shot Segmentation. Electronics 2024, 13, 142. https://doi.org/10.3390/electronics13010142
Wang J-Y, Liu S-K, Guo S-C, Jiang C-Y, Zheng W-M. PCNet: Leveraging Prototype Complementarity to Improve Prototype Affinity for Few-Shot Segmentation. Electronics. 2024; 13(1):142. https://doi.org/10.3390/electronics13010142
Chicago/Turabian StyleWang, Jing-Yu, Shang-Kun Liu, Shi-Cheng Guo, Cheng-Yu Jiang, and Wei-Min Zheng. 2024. "PCNet: Leveraging Prototype Complementarity to Improve Prototype Affinity for Few-Shot Segmentation" Electronics 13, no. 1: 142. https://doi.org/10.3390/electronics13010142
APA StyleWang, J.-Y., Liu, S.-K., Guo, S.-C., Jiang, C.-Y., & Zheng, W.-M. (2024). PCNet: Leveraging Prototype Complementarity to Improve Prototype Affinity for Few-Shot Segmentation. Electronics, 13(1), 142. https://doi.org/10.3390/electronics13010142