Abstract
Human activity recognition (HAR) is crucial to infer the activities of human beings, and to provide support in various aspects such as monitoring, alerting, and security. Distinct activities may possess similar movements that need to be further distinguished using contextual information. In this paper, we extract features for context-aware HAR using a convolutional neural network (CNN). Instead of a traditional CNN, a combined 3D-CNN, 2D-CNN, and 1D-CNN was designed to enhance the effectiveness of the feature extraction. Regarding the classification model, a weighted twin support vector machine (WTSVM) was used, which had advantages in reducing the computational cost in a high-dimensional environment compared to a traditional support vector machine. A performance evaluation showed that the proposed algorithm achieves an average training accuracy of 98.3% using 5-fold cross-validation. Ablation studies analyzed the contributions of the individual components of the 3D-CNN, the 2D-CNN, the 1D-CNN, the weighted samples of the SVM, and the twin strategy of solving two hyperplanes. The corresponding improvements in the average training accuracy of these five components were 6.27%, 4.13%, 2.40%, 2.29%, and 3.26%, respectively.
1. Introduction
Human activity recognition (HAR) has played an important role in various applications such as sport performance [1], life logging [2], anti-crime security [3], fall detection [4], health monitoring [5], and elderly care [6]. Typically, three types of sensors are utilized to measure the human activities, namely environment-based sensors, object-based sensors, wearable sensors, and video-based sensors [7]. Examples of environment-based sensors are radar, sound, and pressure detectors, as well as thermocouples, and barometers. Examples of object-based sensors are Wi-Fi and RFID. For wearable sensors, examples are the global positioning system, magnetometers, gyroscopes, and accelerometers. The forms of human activities vary from static (e.g., sitting and lying) to dynamic (e.g., walking and running) to transitive postures (transitions between consecutive activities). Since some human activities may share similar characteristics, contextual information is included to support the inferring of actual activities [8]. This is related to the concept of context-awareness, which is the ability to capture information from the external environment. Common contextual information includes the task, process, role, user, time, activity, identity, and location [9]. In this paper, HAR using video-based sensors is not considered in the performance comparison because the data type (as videos/images) is different from other types. Readers could refer to the works [10,11] for more details on HAR using video-based sensors.
Various machine learning algorithms have been proposed for context-aware HAR. Generally, there are five types of algorithms, namely the fuzzy logic-based [12,13], probabilistic-based [14,15], rule-based [16,17], distance-based [18,19], and optimization-based approaches [20,21].
To begin the discussion with fuzzy logic-based algorithms, a fuzzy rule-based inference system using fuzzy logic (FL) was proposed for the HAR of six activities: exercising, laying, sitting down, standing up, walking, and sleeping [12]. An experimental analysis of the system with a one day case study showed an accuracy of 97%. Another fuzzy rule-based inference system was presented for HAR with first person video [13]. The selected activities in the kitchen for the analysis were cleaning, washing dishes, and cooking. Biased classification was observed based on the evaluation metrics of recall (54.7%), precision (58.4%), and accuracy (70%).
Regarding the probabilistic-based algorithms, naive Bayes (NB) was chosen to take in the features of the fundamental DC component of a fast Fourier transform, as well as the value and variances of the magnitude, pitch, and roll for HAR [14]. Five human activities were included: walking, standing up, standing, laying down, and sitting. An accuracy of 89.5% was reported. A hidden Markov model (HMM) [15] was used to analyze 22 activities for HAR. The activities were: two-leg jump, one-leg jump, shuffle-right, shuffle-left, V-cut-right-right-first, V-cut-right-left-first, V-cut-left-left-first, run, spin-right-right-first spin-right-left-first, spin-left-right-first, spin-left-left-first, walk-downstairs, walk-upstairs, walk-curve-right, walk-curve-left, walk, stand-to-sit, sit-to-stand, stand, and sit. Owing to the complexity of the recognition of many activities, the model achieved an accuracy of 84.5%. A recent dissertation reported an extensive analysis of an innovative proposal using a motion-unit-based hidden Markov model [22]. The results confirmed that the approach (with a recognition rate over 90%) outperformed many existing works using benchmark datasets, including CSL-SHARE, ENABL3S, and UniMiB SHAR. It also outperformed another newly proposed method using various deep learning-based approaches, including convolutional neural networks, long short-term memory, and ResNet [23]. Attention is also drawn to a novel approach for automatic speech recognition and kinesiology to construct an HAR model that ensures expandability, generalizability, interpretability, and effective model training [24].
One of the rule-based HAR models was built using a random forest (RF) [16]. The model considered six activities, namely walking upstairs, walking downstairs, walking, standing, sitting, and laying. Researchers collected samples from 30 volunteers for the experimental analysis. The results had a sensitivity of 98%, a precision of 98.5%, an accuracy of 98%, and F1-score of 98%. Another approach was built using a decision tree (DT) [17]. Ten activities, namely walking, standing, sitting, eating, drinking (standing), drinking (sitting), sitting (standing), smoking (sitting), smoking (standing), and smoking (walking) were defined for analysis. For static activities, the model achieved an accuracy of 72%, whereas, for dynamic activities, an accuracy of 78% was observed.
K-nearest neighbor (KNN) is one of the most common distance-based algorithms. In [18], the authors enhanced the KNN algorithm with random projection to recognize 13 human activities: pushing a wheelchair, jumping, jogging, going downstairs, going upstairs, turning right, turning left, walking right (circle), walking left (circle), walking forward, lying down, sitting, and standing. The HAR model achieved an accuracy of 92.6%. Another work [19] applied two variants of KNN, namely fuzzy KNN and evidence theoretic KNN for the HAR of twenty-nine activities using three benchmark datasets. The achieved accuracies were 77%, 93%, and 97% for datasets with 14, 10, and 5 activities, respectively.
For the optimization-based approach, a support vector machine (SVM) with a radial basis function was proposed [20]. Six human activities were considered, namely laying, standing, sitting, walking downstairs, walking upstairs, and walking. The experimental result showed that the model achieved an accuracy of 96.6%. In [21], an artificial neural network (ANN) model was built for the HAR of six human activities. The activities were laying, standing, sitting, walking, walking downstairs, and walking upstairs. An accuracy of 96.7% was observed.
A detailed pipeline was proposed for HAR research [25]. The key components involved are devices, sensors, software, data acquisition, segmentation, annotation, biosignal processing, feature extraction, feature study, activity modeling, training, recognition, evaluation, and application. Table 1 summarizes the key elements (sensors, feature extraction, method, context awareness, dataset, activities, cross-validation, and results) of the existing works [12,13,14,15,16,17,18,19,20,21]. The key research limitations of the existing works include the following:

Table 1.
Summary of the performance of existing works on HAR.
- There are two major types of feature extraction. Major works [12,13,14,15,16,17,19,20,21] utilized the traditional feature extraction process. There has been less discussion (e.g., [18]) of automatic feature extraction using a deep learning algorithm, which may extract more representative features and eliminate the domain knowledge of all human activities;
- The methodology in the existing works [12,13,14,15,16,17,18,19,20,21] utilized traditional classification algorithms that may not work well with the nature of a high-dimensional feature space;
- Context awareness was omitted in the design and formulation of most of the existing works [12,13,14,15,16,18,19,20,21];
- Experimental analyses used limited benchmark datasets (and, thus, limited types of activities), with one dataset in most of the works [12,13,14,15,16,17,18,20,21] and three in [19]; and
- Cross-validation was omitted in most works [12,13,14,16,17,18,20,21]. It is important to fine-tune the hyperparameters and to evaluate the issue of model overfitting.
1.1. Research Contributions
To address the limitations of the research works, we propose a combined 3D-CNN, 2D-CNN, and 1D-CNN algorithm (3D-2D-1D-CNN) for feature extraction and a weighted twin support vector machine (WTSVM) for the HAR model. The contributions of the algorithm are explained as follows:
- The 3D-2D-1D-CNN algorithm leverages the ability of automatic feature extraction. An ablation study confirms that the 3D-CNN, 2D-CNN, and 1D-CNN achieve accuracy improvements of 6.27%, 4.13%, and 2.40%, respectively;
- The WTSVM takes the advantage of high-dimensional feature space and outperforms the twin SVM by 3.26% in terms of accuracy;
- Context awareness is incorporated to enhance the formulation of the HAR model, with an accuracy improvement of 2.4%; and
- Compared to existing works, our proposed algorithm enhances the accuracy by 0.1–40.1% with an increase of the total number of activities by 230–3100%.
1.2. Paper Organization
This paper is structured with five sections. Section 2 presents the details of the methodology of the 3D-2D-1D-CNN and WTSVM. The experimental results of the algorithm and its comparison are presented in Section 3. To investigate the contributions of the individual elements of the algorithm, ablation studies are carried out. A conclusion is drawn, with directions of future work, in Section 4.
2. Methodology
The methodology of the proposed HAR model comprises a feature extraction module using the 3D-2D-1D-CNN and a classification module using the WTSVM. In the following two subsections, the design and formulations are shared.
2.1. Feature Extraction Module Using the 3D-2D-1D-CNN
The feature extraction module is indispensable in machine learning. Traditional statistical [34,35] and time–frequency approaches [36,37] are not employed, since these approaches may not be effective in fully extracting representative features for a complex context-aware HAR problem with many human activities. Therefore, automatic feature extraction via CNN was chosen. Feature extractions via the 3D-CNN [38], 2D-CNN [39], and 1D-CNN [40] have been used in different applications with satisfactory performances. The features extracted using these algorithms may differ from each other. Combing the algorithms and, thus, merging more representative features is expected to further enhance the performance of the context-aware HAR model.
Figure 1 shows the ensemble architecture of the proposed 3D-2D-1D-CNN algorithm for feature extraction, which supports the classification model using the WTSVM. Three input layers are required to handle the inputs for the 3D-CNN, 2D-CNN, and 1D-CNN, as in a sub-model of the 3D-2D-1D-CNN algorithm. The workflows of the 3D-CNN, 2D-CNN, and 1D-CNN share similarities, with convolution operations, max pooling operations, and flatten operations.
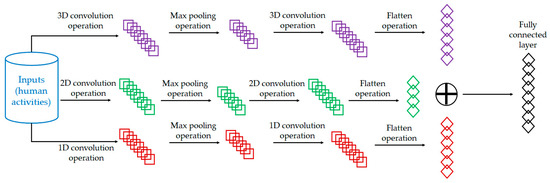
Figure 1.
The architecture of the 3D-2D-1D-CNN algorithm for feature extraction.
The convolution operation acts on two samples to generate outputs representing the pattern change between the samples. The concept of pooling aims to reduce the data size, the training complexity of the model, and model overfitting. The maximum pooling operation takes the maximum values in the blocks to extract significant features. The flatten operation converts the data into a 1D matrix that is then passed into the fully connected layer. The features obtained in each algorithm will be merged into a fully connected layer. The design takes advantage of the effective coordination of training individual 3D-CNN, 2D-CNN, and 1D-CNN. It also facilitates the extraction of more representative features to enhance the performance of the HAR model. Ablation studies will be carried out to verify the contributions of the proposed ensemble architecture.
2.2. Classification Module Using a WTSVM
The basis of a weighted support vector machine (WSVM) for an imbalanced binary classification problem [41]—the hyperplane (or decision function)—is defined as
with weighted vector and bias .
The constrained problem of a WSVM with a maximum margin hyperplane is given by:
where the regularization term represents the maximum margin of the two parallel hyperplanes; and are the penalty parameters to control the weights between terms for the negative class and positive class, respectively; and are the slack variables for the negative class and positive class, respectively; and are the training matrices for the negative class and positive class, respectively; and and are the vectors for the negative class and positive class, respectively. In general, larger Lagrange multipliers may be assigned to some support vectors that help reduce the negative impact of imbalanced classification in an imbalanced dataset (details are provided in Section 3.1).
On the other hand, the basic formulations for the twin support vector machine (TSVM) are illustrated as follows. Different from WSVM, TSVM considers two non-parallel hyperplanes, and :
with the weighted vectors and and the biases and . In these formulations, is close to and far away from , and is close to and far away from .
The constrained problems of the TSVM are defined as:
with the parameters and .
Regarding our proposed WTSVM, it features (i) weights to adjust the level of the sensitivity of the hyperplane to respond to the imbalance ratio and (ii) majority points for the hyperplanes. To be practical, we formulated the WTSVM with a non-linear kernel function (). The surfaces generated by the kernel function are given by
The optimization problems are defined as
The Lagrange function of (9) is defined as
with the Lagrange multiplier . Using Karush–Kuhn–Tucker conditions, we have
The Lagrange dual problem of (9) becomes
with . Likewise, the Lagrange dual problem of (10) becomes
with the Lagrange multiplier .
3. Performance Evaluation of the Proposed 3D-2D-1D-CNN-Based WTSVM for HAR
The proposed 3D-2D-1D-CNN-based WTSVM algorithm was evaluated using a benchmark dataset. This was followed by ablation studies to quantify the effectiveness of the individual components: 3D-CNN, 2D-CNN, 1D-CNN, weighted SVM, and twin SVM. We aimed to confirm that all components benefit the performance of the HAR model.
3.1. Dataset
To evaluate the performance of the proposed algorithm, a benchmark dataset, namely the ExtraSensory dataset, was chosen [42]. In this dataset, a mobile application was used to perform measurements of sixty volunteers for a one-minute recording with three twenty-second segments of various human activities. Motion-reactive sensors were used to collect data from the magnetometer, gyroscope, accelerometer, audio, compass, and location services. The dataset consisted of 308,306 labelled samples. Two types of labels were assigned to each record: (i) the primary activity (seven activities were included, namely bicycling, running, walking, standing and moving, standing in place, sitting, and lying down), and (ii) the secondary activity (a total of ninety-six specific contexts of various aspects, such as sleeping, eating, and cooking), which supplemented the primary activities. Each record could be linked with only one primary activity and multiple secondary activities. Figure 2 presents the number of samples of each of the primary activities. For activities defined as secondary activities, the number of samples is summarized in Table 2. As illustrative examples, Figure 3 shows the samples of the one-axis accelerometer readings with the phone-accelerometer (walking) and the watch-accelerometer, respectively.
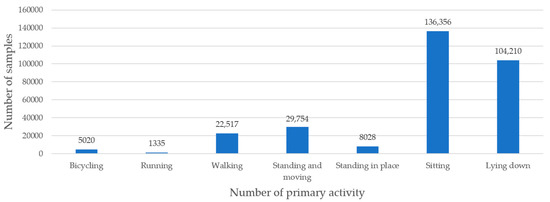
Figure 2.
The number of samples of each of the primary activities.
Table 2.
Summary of the number of samples of the secondary activities.
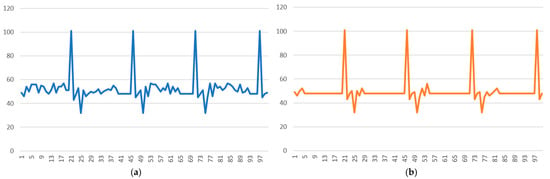
Figure 3.
Samples of accelerometer readings. (a) Phone accelerometer (walking). (b) Watch accelerometer (walking).
3.2. Results
Owing to a few samples of the secondary activities of wheelchair (9) and whistling (5), a subject-wise K-fold cross-validation with K = 5 (instead of 10) was employed, which was also confirmed to be a common setting in the training and testing of machine learning models [43,44,45]. Four typical kernel functions, linear, radial basis, sigmoid, and polynomial, were chosen for the WTSVM model. Figure 4 shows the training accuracy and testing accuracy of the proposed 3D-2D-1D-CNN-based WTSVM using four kernel functions on the ExtraSensory dataset. The average training accuracy and average testing accuracy were 98.3% and 98.1%, respectively. There was only a small deviation between the average training and testing accuracy.
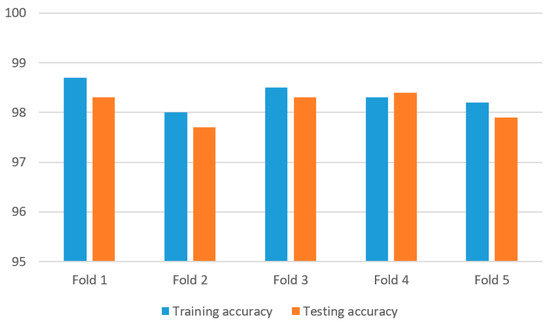
Figure 4.
Accuracy of the 3D-2D-1D-CNN-based WTSVM on the ExtraSensory dataset.
To analyze the effectiveness of the 3D-2D-1D-CNN algorithm for feature extraction, an ablation study was carried out to study the contributions of the 3D-CNN, 2D-CNN, and 1D-CNN. The training accuracy, testing accuracy, precision, recall, and F1 score are summarized in Table 3. The key findings of the results are detailed as follows:
Table 3.
Accuracy of the WTSVM using the 3D-2D-1D-CNN, 2D-1D-CNN, 3D-1D-CNN, and 3D-2D-CNN algorithms.
- The average training accuracy, average testing accuracy, average precision, average recall, and average F1 score were 98.3%, 98.1%, 98.4%, 98%, and 98.2%, respectively, for the 3D-2D-1D-CNN algorithm; 92.5%, 92.2%, 92.3%, 92.1%, and 92.2%, respectively, for the 2D-1D-CNN algorithm; 94.4%, 94.3%, 94.6%, 94.2%, and 94.3%, respectively, for the 3D-1D-CNN algorithm; and 96.0%, 95.9%, 96%, 95.8%, and 95.9%, respectively, for the 3D-2D-CNN algorithm. The results show that the average training accuracy was enhanced by 6.27%, 4.13%, and 2.40%, respectively;
- The ranking of the algorithms (from best to worst) based on the training accuracy and testing accuracy was 3D-2D-1D-CNN, 3D-2D-CNN, 3D-1D-CNN, and 2D-1D-CNN. This revealed the contributions of the individual components—the 3D-CNN, 2D-CNN, and 1D-CNN algorithms.
In addition, to analyze the effectiveness of the WTSVM, an ablation study was conducted to study the contributions of the weighting factors and the twin strategy. Table 4 summarizes the training accuracy and testing accuracy using the WTSVM, WSVM, and TSVM. The key observations are illustrated as follows:
Table 4.
Accuracy of the 3D-2D-1D-CNN-based WTSVM, WSVM, and TSVM algorithms.
- The average training accuracy, average testing accuracy, average precision, average recall, and average F1 score were 98.3%, 98.1%, 98.4%, 98%, and 98.2%, respectively, for the WTSVM algorithm; 95.2%, 95.1%, 95.2%, 95.0%, and 95.1%, respectively, for the WSVM algorithm; and 96.1%, 95.9%, 96.2%, 95.8%, and 95.9%, respectively, for the TSVM algorithm. The enhancement of the average training accuracy by the WTSVM algorithm was 2.29% and 3.26%, respectively;
- The ranking of the algorithms (from best to worst) based on the training accuracy and testing accuracy was WTSVM, TSVM, and WSVM. This revealed the contributions of the individual components, the WTSVM, WSVM, and TSVM algorithms.
To evaluate the hypotheses, if the proposed approach outperformed all/some of the other approaches, a non-parametric Wilcoxon signed-rank test [46,47] was carried out. Table 5 summarizes the results of the five hypotheses. The p-values of all hypotheses were less than 0.05, suggesting that the proposed approach significantly outperformed the other approaches in the ablation studies.
Table 5.
Results of hypothesis testing using the Wilcoxon signed-rank test.
The performance of the proposed 3D-2D-1D-CNN-based WTSVM was compared with existing works [42,48,49,50,51] using the benchmark ExtraSensory dataset [42], and our work was evaluated using the benchmark datasets Kyoto1, Kyoto7, and Kasteren [30,31]. Table 6 summarizes the details of the comparisons. The key observations are summarized as follows:
Table 6.
Comparisons between existing works and our work.
- For ExtraSensory, our work enhanced the accuracy by 12.8–20.2% [42,48,51] and enhanced the F score by 17.2–86.0% [49,50];
- For Kyoto1, our work enhanced the accuracy by 0.918–2.89% [18,19];
- For Kyoto7, our work enhanced the accuracy by 8.89–13.1% [18,19];
- For Kasteren, our work enhanced the accuracy by 2.74–6.09% [18,19].
The results suggest that the proposed algorithm can manage varying scales of HAR problems with different numbers of activities. Regarding the computational complexity, the proposed algorithm requires more training time due to the complexity of the feature extraction process (3D-2D-1D-CNN). Nevertheless, this will not significantly affect the applicability of low-latency decisions in practice, because the classifier is based on WTSVM, a traditional machine learning classifier.
4. Conclusions
It is desired for a context-aware HAR to be accurate and able to support the recognition of many activities. In this paper, we proposed 3D-CNN, 2D-CNN, and 1D-CNN algorithms (3D-2D-1D-CNN) for feature extraction and a weighted twin support vector machine (WTSVM) for an HAR model. A performance evaluation was carried out using four benchmark datasets. The proposed algorithm achieves an average training accuracy of 98.3% and an average testing accuracy of 98.1%. To investigate the contributions of the five individual components, namely the 3D-CNN, the 2D-CNN, the 1D-CNN, the weighted samples of the SVM, and the twin strategy of solving two hyperplanes, ablation studies were conducted. The results show the enhancement of the average training accuracy by 6.27%, 4.13%, 2.40%, 2.29%, and 3.26%, respectively, by the five individual components. In addition, we compared our work to 10 existing works. The comparison showed that our work enhanced the accuracy in four benchmark datasets.
The research team would like to suggest future research directions as follows: (i) generate more samples in the small classes, as in Table 1, using data generation algorithms such as the family of generative adversarial networks to reduce the issue of imbalanced recognition [53,54]; (ii) conduct online learning with new classes [55,56]; (iii) consider time-series image data [57,58] as inputs for the 3D-2D-1D-CNN algorithm; (iv) consider advanced feature extraction methods via high-level features [59], stacking, and feature space reduction [60,61]; and (v) investigate other non-training-based statistical methods of low-cost HAR algorithms [62,63].
Author Contributions
Formal analysis, K.T.C., B.B.G., M.T.-R., V.A., W.A. and I.F.Z.; investigation, K.T.C., B.B.G., M.T.-R., V.A., W.A. and I.F.Z.; methodology, K.T.C.; validation, K.T.C. and B.B.G.; visualization, K.T.C. and B.B.G.; writing—original draft, K.T.C., B.B.G., M.T.-R., V.A., W.A. and I.F.Z.; writing—review and editing, K.T.C., B.B.G., M.T.-R., V.A., W.A. and I.F.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research work was funded by Institutional Fund Projects under grant no. (IFPIP:1119-611-1443). The authors gratefully acknowledge technical and financial support provided by the Ministry of Education and King Abdulaziz University, DSR, Jeddah, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hendry, D.; Chai, K.; Campbell, A.; Hopper, L.; O’Sullivan, P.; Straker, L. Development of a human activity recognition system for ballet tasks. Sports Med.-Open 2020, 6, 10. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Quaid, M.A.K.; Tahir, S.B.U.D.; Kim, K. A study of accelerometer and gyroscope measurements in physical life-log activities detection systems. Sensors 2020, 20, 6670. [Google Scholar] [CrossRef] [PubMed]
- Ullah, F.U.M.; Muhammad, K.; Haq, I.U.; Khan, N.; Heidari, A.A.; Baik, S.W.; de Albuquerque, V.H.C. AI-Assisted Edge Vision for Violence Detection in IoT-Based Industrial Surveillance Networks. IEEE Trans. Ind. Inform. 2022, 18, 5359–5370. [Google Scholar] [CrossRef]
- Yadav, S.K.; Luthra, A.; Tiwari, K.; Pandey, H.M.; Akbar, S.A. ARFDNet: An efficient activity recognition & fall detection system using latent feature pooling. Knowl.-Based Syst. 2022, 239, 107948. [Google Scholar]
- Bhavanasi, G.; Werthen-Brabants, L.; Dhaene, T.; Couckuyt, I. Patient activity recognition using radar sensors and machine learning. Neural Comput. Appl. 2022, 34, 16033–16048. [Google Scholar] [CrossRef]
- Shu, X.; Yang, J.; Yan, R.; Song, Y. Expansion-squeeze-excitation fusion network for elderly activity recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5281–5292. [Google Scholar] [CrossRef]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Miranda, L.; Viterbo, J.; Bernardini, F. A survey on the use of machine learning methods in context-aware middlewares for human activity recognition. Artif. Intell. Rev. 2022, 55, 3369–3400. [Google Scholar] [CrossRef]
- Khowaja, S.A.; Yahya, B.N.; Lee, S.L. CAPHAR: Context-aware personalized human activity recognition using associative learning in smart environments. Hum.-Centric Comput. Inf. Sci. 2020, 10, 35. [Google Scholar] [CrossRef]
- Tsai, J.K.; Hsu, C.C.; Wang, W.Y.; Huang, S.K. Deep learning-based real-time multiple-person action recognition system. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef]
- da Costa, V.G.T.; Zara, G.; Rota, P.; Oliveira-Santos, T.; Sebe, N.; Murino, V.; Ricci, E. Dual-head contrastive domain adaptation for video action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022. [Google Scholar]
- Medjahed, H.; Istrate, D.; Boudy, J.; Dorizzi, B. Human activities of daily living recognition using fuzzy logic for elderly home monitoring. In Proceedings of the 2009 IEEE International Conference on Fuzzy Systems, Jeju, Republic of Korea, 20–24 August 2009. [Google Scholar]
- Schneider, B.; Banerjee, T. Bridging the Gap between Atomic and Complex Activities in First Person Video. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems, Luxembourg, 11–14 July 2021. [Google Scholar]
- Maswadi, K.; Ghani, N.A.; Hamid, S.; Rasheed, M.B. Human activity classification using Decision Tree and Naive Bayes classifiers. Multimed. Tools Appl. 2021, 80, 21709–21726. [Google Scholar] [CrossRef]
- Hartmann, Y.; Liu, H.; Schultz, T. Interactive and Interpretable Online Human Activity Recognition. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events, Pisa, Italy, 21–25 March 2022. [Google Scholar]
- Radhika, V.; Prasad, C.R.; Chakradhar, A. Smartphone-based human activities recognition system using random forest algorithm. In Proceedings of the 2022 International Conference for Advancement in Technology, Goa, India, 21–22 January 2022. [Google Scholar]
- Agac, S.; Shoaib, M.; Incel, O.D. Context-aware and dynamically adaptable activity recognition with smart watches: A case study on smoking. Comput. Electr. Eng. 2021, 90, 106949. [Google Scholar] [CrossRef]
- Fahad, L.G.; Tahir, S.F. Activity recognition in a smart home using local feature weighting and variants of nearest-neighbors classifiers. J. Ambient Intell. Humaniz. Comput. 2021, 12, 2355–2364. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, B.; Coelho, Y.; Bastos, T.; Krishnan, S. Trends in human activity recognition with focus on machine learning and power requirements. Mach. Learn. Appl. 2021, 5, 100072. [Google Scholar] [CrossRef]
- Muralidharan, K.; Ramesh, A.; Rithvik, G.; Prem, S.; Reghunaath, A.A.; Gopinath, M.P. 1D Convolution approach to human activity recognition using sensor data and comparison with machine learning algorithms. Int. J. Cogn. Comput. Eng. 2021, 2, 130–143. [Google Scholar]
- Myo, W.W.; Wettayaprasit, W.; Aiyarak, P. A cyclic attribution technique feature selection method for human activity recognition. Int. J. Intell. Syst. Appl. 2019, 11, 25–32. [Google Scholar] [CrossRef]
- Liu, H.; Schultz, I.T. Biosignal Processing and Activity Modeling for Multimodal Human Activity Recognition. Ph.D. Thesis, Universität Bremen, Bremen, Germany, 2021. [Google Scholar]
- Mekruksavanich, S.; Jantawong, P.; Jitpattanakul, A. A Deep Learning-based Model for Human Activity Recognition using Biosensors embedded into a Smart Knee Bandage. Procedia Comp. Sci. 2022, 214, 621–627. [Google Scholar] [CrossRef]
- Liu, H.; Hartmann, Y.; Schultz, T. Motion Units: Generalized sequence modeling of human activities for sensor-based activity recognition. In Proceedings of the 2021 29th European Signal Processing Conference, Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Liu, H.; Hartmann, Y.; Schultz, T. A Practical Wearable Sensor-based Human Activity Recognition Research Pipeline. In Proceedings of the 15th International Conference on Health Informatics, Online, 9–11 February 2022. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ugulino, W.; Cardador, D.; Vega, K.; Velloso, E.; Milidiú, R.; Fuks, H. Wearable computing: Accelerometers’ data classification of body postures and movements. In Proceedings of the Advances in Artificial Intelligence-SBIA 2012: 21th Brazilian Symposium on Artificial Intelligence, Curitiba, Brazil, 20–25 October 2012. [Google Scholar]
- Liu, H.; Hartmann, Y.; Schultz, T. CSL-SHARE: A multimodal wearable sensor-based human activity dataset. Front. Comput. Sci. 2021, 3, 759136. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J.; Incel, O.D. A hierarchical lazy smoking detection algorithm using smartwatch sensors. In Proceedings of the 2016 IEEE 18th International Conference on e-Health Networking, Applications and Services, Munich, Germany, 14–17 September 2016. [Google Scholar]
- Rashidi, P.; Cook, D.J.; Holder, L.B.; Schmitter-Edgecombe, M. Discovering activities to recognize and track in a smart environment. IEEE Trans. Knowl. Data Eng. 2010, 23, 527–539. [Google Scholar] [CrossRef]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Republic of Korea, 21–24 September 2008. [Google Scholar]
- Xu, L.; Yang, W.; Cao, Y.; Li, Q. Human activity recognition based on random forests. In Proceedings of the 2017 13th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery, Guilin, China, 29–31 July 2017. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN 2013 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Prathiba, S.B.; Raja, G.; Bashir, A.K.; AlZubi, A.A.; Gupta, B. SDN-assisted safety message dissemination framework for vehicular critical energy infrastructure. IEEE Trans. Ind. Inf. 2022, 18, 3510–3518. [Google Scholar] [CrossRef]
- Deveci, M.; Pamucar, D.; Gokasar, I.; Köppen, M.; Gupta, B.B. Personal mobility in metaverse with autonomous vehicles using Q-rung orthopair fuzzy sets based OPA-RAFSI model. IEEE Trans. Intell. Transport. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.Z.; He, H.; Gupta, B.B.; Abd El-Latif, A.A. Joint computation offloading and task caching for multi-user and multi-task MEC systems: Reinforcement learning-based algorithms. Wireless Netw. 2021, 27, 2023–2038. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Jiang, Y.; Wang, P.; Shen, Q.; Shen, C. Hyperspectral classification based on lightweight 3-D-CNN with transfer learning. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5813–5828. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Chi, H.R.; Arya, V.; Alhalabi, W.; Ruiz, M.T.; Shen, C.W. Transfer learning-based multi-scale denoising convolutional neural network for prostate cancer detection. Cancers 2022, 14, 3687. [Google Scholar] [CrossRef] [PubMed]
- Hakim, M.; Omran, A.A.B.; Inayat-Hussain, J.I.; Ahmed, A.N.; Abdellatef, H.; Abdellatif, A.; Gheni, H.M. Bearing Fault Diagnosis Using Lightweight and Robust One-Dimensional Convolution Neural Network in the Frequency Domain. Sensors 2022, 22, 5793. [Google Scholar] [CrossRef]
- Huang, Y.M.; Du, S.X. Weighted support vector machine for classification with uneven training class sizes. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005. [Google Scholar]
- Vaizman, Y.; Ellis, K.; Lanckriet, G. Recognizing detailed human context in the wild from smartphones and smartwatches. IEEE Pervasive Comput. 2017, 16, 62–74. [Google Scholar] [CrossRef]
- Tembhurne, J.V.; Almin, M.M.; Diwan, T. Mc-DNN: Fake news detection using multi-channel deep neural networks. Int. J. Semant. Web Inf. Syst. 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Lv, L.; Wu, Z.; Zhang, L.; Gupta, B.B.; Tian, Z. An edge-AI based forecasting approach for improving smart microgrid efficiency. IEEE Trans. Ind. Inf. 2022, 18, 7946–7954. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Liu, R.W.; Zhang, X.; Vasant, P.; Thomas, J.J. Extended-range prediction model using NSGA-III optimized RNN-GRU-LSTM for driver stress and drowsiness. Sensors 2021, 21, 6412. [Google Scholar] [CrossRef]
- Obulesu, O.; Kallam, S.; Dhiman, G.; Patan, R.; Kadiyala, R.; Raparthi, Y.; Kautish, S. Adaptive diagnosis of lung cancer by deep learning classification using wilcoxon gain and generator. J. Health. Eng. 2021, 2021, 5912051. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Asim, Y.; Azam, M.A.; Ehatisham-ul-Haq, M.; Naeem, U.; Khalid, A. Context-aware human activity recognition (CAHAR) in-the-Wild using smartphone accelerometer. IEEE Sensors J. 2020, 20, 4361–4371. [Google Scholar] [CrossRef]
- Cruciani, F.; Vafeiadis, A.; Nugent, C.; Cleland, I.; McCullagh, P.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Feature learning for human activity recognition using convolutional neural networks: A case study for inertial measurement unit and audio data. CCF Trans. Pervasive Comput. Interact. 2020, 2, 18–32. [Google Scholar] [CrossRef]
- Mohamed, A.; Lejarza, F.; Cahail, S.; Claudel, C.; Thomaz, E. HAR-GCNN: Deep Graph CNNs for Human Activity Recognition from Highly Unlabeled Mobile Sensor Data. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events, Pisa, Italy, 21–25 March 2022. [Google Scholar]
- Tarafdar, P.; Bose, I. Recognition of human activities for wellness management using a smartphone and a smartwatch: A boosting approach. Decis. Support Syst. 2021, 140, 113426. [Google Scholar] [CrossRef]
- Fahad, L.G.; Rajarajan, M. Integration of discriminative and generative models for activity recognition in smart homes. Appl. Soft Comput. 2015, 37, 992–1001. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative adversarial networks (GANs) for image augmentation in agriculture: A systematic review. Comput. Electron. Agric. 2022, 200, 107208. [Google Scholar] [CrossRef]
- Chui, K.T.; Gupta, B.B.; Jhaveri, R.H.; Chi, H.R.; Arya, V.; Almomani, A.; Nauman, A. Multiround Transfer Learning and Modified Generative Adversarial Network for Lung Cancer Detection. Int. J. Intell. Syst. 2023, 2023, 6376275. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, T.; Ng, W.W.; Pedrycz, W. KNNENS: A k-nearest neighbor ensemble-based method for incremental learning under data stream with emerging new classes. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Khosravi, K.; Golkarian, A.; Tiefenbacher, J.P. Using optimized deep learning to predict daily streamflow: A comparison to common machine learning algorithms. Water Resour. Manag. 2022, 36, 699–716. [Google Scholar] [CrossRef]
- Li, C.; Zhao, H.; Lu, W.; Leng, X.; Wang, L.; Lin, X.; Pan, Y.; Jiang, W.; Jiang, J.; Sun, Y.; et al. DeepECG: Image-based electrocardiogram interpretation with deep convolutional neural networks. Biomed. Signal Process. Control 2021, 69, 102824. [Google Scholar] [CrossRef]
- Makimoto, H.; Höckmann, M.; Lin, T.; Glöckner, D.; Gerguri, S.; Clasen, L.; Schmidt, J.; Assadi-Schmidt, A.; Bejinariu, A.; Müller, P.; et al. Performance of a convolutional neural network derived from an ECG database in recognizing myocardial infarction. Sci. Rep. 2020, 10, 8445. [Google Scholar] [CrossRef] [PubMed]
- Hartmann, Y.; Liu, H.; Lahrberg, S.; Schultz, T. Interpretable High-level Features for Human Activity Recognition. In Proceedings of the 15th International Conference on Bio-inspired Systems and Signal Processing, Online, 9–11 February 2022. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Feature Space Reduction for Human Activity Recognition based on Multi-channel Biosignals. In Proceedings of the 14th International Conference on Bio-inspired Systems and Signal Processing, Online, 11–13 February 2021. [Google Scholar]
- Hartmann, Y.; Liu, H.; Schultz, T. Feature Space Reduction for Multimodal Human Activity Recognition. In Proceedings of the 13th International Conference on Bio-inspired Systems and Signal Processing, Valletta, Malta, 24–26 February 2020. [Google Scholar]
- Folgado, D.; Barandas, M.; Antunes, M.; Nunes, M.L.; Liu, H.; Hartmann, Y.; Schultz, T.; Gamboa, H. Tssearch: Time series subsequence search library. SoftwareX 2022, 18, 101049. [Google Scholar] [CrossRef]
- Rodrigues, J.; Liu, H.; Folgado, D.; Belo, D.; Schultz, T.; Gamboa, H. Feature-Based Information Retrieval of Multimodal Biosignals with a Self-Similarity Matrix: Focus on Automatic Segmentation. Biosensors 2022, 12, 1182. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).