Abstract
Researchers have, in recent times, achieved excellent compression efficiency by implementing a more complicated compression algorithm due to the rapid development of video compression. As a result, the next model of video compression, High-Efficiency Video Coding (HEVC), provides high-quality video output while requiring less bandwidth. However, implementing the intra-prediction technique in HEVC requires significant processing complexity. This research provides a completely pipelined hardware architecture solution capable of real-time compression to minimize computing complexity. All prediction unit sizes of , , , and , and all planar, angular, and DC modes are supported by the proposed solution. The synthesis results mapped to Xilinx Virtex 7 reveal that our solution can do real-time output with 210 frames per second (FPS) at resolution, called Full High Definition (FHD), or 52 FPS at resolution, called 4K, while operating at 232 Mhz maximum frequency.
1. Introduction
High-Efficiency Video Coding (H265/HEVC) is the next generation of Advanced Video Coding (H.264/AVC) compression technology, aimed at improving compression efficiency. Compared to earlier standards, H265/HEVC saves twice as much bandwidth. The desire for streaming digital video or video storing services is unavoidable as the Internet grows. H265/HEVC helps boost speed and capacity with its highly efficient coding efficiency. Moreover, H265/HEVC also outperforms high-resolution videos (4K, 8K).
Most video coding standards use intra-prediction to eliminate spatial redundancies by generating a predicted block based on nearby pixels. In H265/HEVC, the intra-prediction unit has been updated to achieve efficient coding; intra-prediction now has 35 prediction modes, nine more than H.264/AVC currently provides, and supports prediction unit (PU) sizes ranging from to (sample × sample) in comparison to the largest PU size of in H.264/AVC. H265/HEVC offers more complex intra-prediction, which has a substantial impact on coding efficiency because of the enormous computational complexity.
Intra-prediction consumes significant processing time, motivating researchers to employ various strategies to reduce algorithm complexity. Nevertheless, the output FPS of software solutions cannot meet the daily needs of the majority of consumers. Currently, streaming high-quality video in real time is common, yet, encoding these videos at high FPS is difficult with the present software solutions. As a result, we can bypass software constraints by employing hardware acceleration.
Many researchers investigated implementing the intra-prediction algorithm on hardware to achieve higher output framerates and more energy efficiency than the software version. Using the data reuse strategy for decreasing the number of computations, the proposed [1] solution helps to reduce 80% of the computation time to reach a framerate of 30 FPS for the FHD resolution. Nevertheless, it only supports PU sizes of and . Therefore, the authors deploy a completely pipelined solution constructed on the Field Programmable Gate Arrays (FPGA) in the architecture [2], which supports all intra-prediction modes with all PU sizes to reach the framerate at 24 FPS for the 4K resolution.
Hasan Azgin and their colleagues proposed a Computation and Energy Reduction Method for HEVC Intra Prediction [3] in 2017. It was demonstrated that using 24.63% less energy than the original H.265/HEVC intra-prediction equation, 40 FPS can be produced for the FHD resolution at 166MHz. In 2018, [4] developed an effective FPGA implementation for the approximate intra-prediction algorithm using digital signal processing (DSP) blocks instead of adders and shifters. This design can handle 55 FPS for the FHD resolution while consuming less energy. These proposals aim to reduce computational complexity while increasing energy efficiency. However, with the continued demand for high-quality streaming video, the ability to read-time encode at the 4K resolution and high FPS is necessary.
The contributions of this paper are as follows:
- (1)
- We propose a completely pipelined architecture for the intra-prediction module. By implementing DC, Planer, and Angular processing units in parallel, we effectively minimize execution time to increase the throughput. The predicted samples are generated for all PU sizes in one single clock cycle.
- (2)
- A flexible partitioning of cell predictions was introduced for the angular prediction modes, which enhances parallelism up to 16 PUs with sizes of or each time. Our solutions provide a processing speed of 210 FPS for the FHD resolution and 52 FPS for the 4K resolution and support all prediction modes and PU sizes.
The rest of the paper is organized as follows. Section 2 explains the H.265/HEVC coding structure and intra-prediction algorithm. Section 3 explains the proposed hardware architecture for intra-prediction. Next, Section 4 and Section 5 show the functional verification and synthesis results of the proposed design. Finally, Section 6 states our conclusions.
2. Intra Coding in H.265/HEVC
2.1. Overview of H.265/HEVC Structure
An image can be divided into coding tree units (CTU) in the H.265/HEVC coding standard. Compared to the previous H.264/AVC standard, CTU is the core of the coding layer. CTUs are L × L in size, with L being 64, 32, or 16; the greatest CTU size is , which is greater than a macroblock ( of luma samples). H.265/HEVC can improve the previous standard’s coding efficiency by adopting a larger CTU size. H.265/HEVC employs a quad-tree partitioning structure, as illustrated in Figure 1, in which the largest coding unit (LCU) can be recursively split into four smaller coding units (CU) [5].
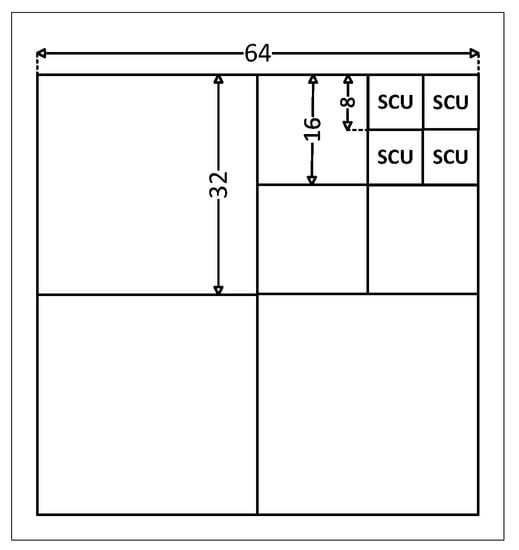
Figure 1.
Demonstration of CU partitioning, where SCU is the smallest CU.
As shown in Figure 2 [6], each CU has a PU and TU (Transform Unit). The PU determines whether to use intra-picture or inter-picture prediction to reduce spatial or temporal redundancy; after obtaining the prediction residual, it is processed by the Transform Unit, which then applies entropy coding to generate the output bitstream.
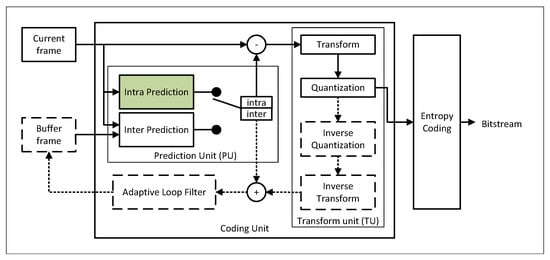
Figure 2.
H.265/HEVC coding unit structure.
Intra-prediction is used in H.265/HEVC to eliminate spatial redundancy; it generates predicted samples for the PU of the CU using already coded pixels and adjoining PUs as input references. The intra-prediction algorithm supports PU sizes of , , , and , with Planar, DC, and Angular prediction modes totaling 35, as shown in Table 1.

Table 1.
Intra mode number and its associated names.
2.2. H.265/HEVC Sample Substitution and Filter
As shown in Figure 3, H.265/HEVC employs a reference sample substitution process that enables the production of predicted samples without the full availability of reference samples, where an unknown reference can be substituted by the value of its nearest reference.
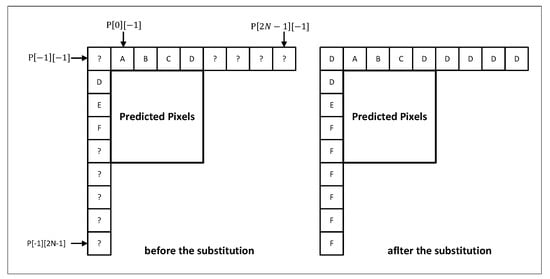
Figure 3.
Illustration of sample substitution process for prediction block .
Following sample substitution, input references will be conditionally filtered to avoid the appearance of undesirable directional edges on predicted samples. When the filter is applied, the three-tap filter is used as the default, and the output-filtered references are derived using the equations:
where x = [0:] and y = [0:], N is the size of predicted block.
2.3. H.265/HEVC Angular Prediction
H.265/HEVC [7] provides 33 different prediction directions in angular prediction modes, compared to only 8 in H.264/AVC [8]. Additional prediction directions allow H.265/HEVC to achieve more efficient coding with two main prediction directions: horizontal modes (modes 2–17) and vertical modes (the rest).
To perform prediction, we select positive references. The selection is followed by Equations (4) and (5):
For negative references, the A parameter is used for the selected mode, as shown in Table 2. If A is negative, indicating that both top and left references are required, the R needs to be extended with index by Equations (6) and (7). When input reference samples (R) are available, we can generate the predicted samples using the following equations:
Table 2.
Angular A and B parameters lock-up table.
Equation (8) is used for vertical modes (), and Equation (9) is for horizontal modes where , where the ranges of depend on the size of the prediction unit.
Discontinuities in the output result may occur during the generation of the predicted samples. These discontinuities can be removed using a boundary filter is used to smooth the predicted boundary values by replacing them with the reference samples; this step is optional for angular modes 10 and 26:
where is the mode 10 boundary after the filter and is the original boundary value, and are the top and left reference samples. In the case of an 8-bit pixel depth, the CLIP function takes the place of maintaining the predicted samples in the range .
2.4. H.265/HEVC Planar Prediction
Although the angular mode delivers a decent prediction when a prediction block contains edges, it may provide some noticeable discontinuities in the results. Therefore, the following equations are employed in H.265/HEVC planar prediction to generate smooth predicted samples with no discontinuities:
where P has planar predicted samples, N is the size of the prediction block, and p is references samples.
2.5. H.265/HEVC DC Prediction
DC prediction contributes to creating an absolutely smooth prediction block with no edges on the predicted output. The DC Prediction predicted samples are equal dcVal, which is derived by taking the average value of all left and top reference samples:
where N is the size of the PU, x,y = 0 … to determine the position of the predicted sample.
Similar to angular prediction, to avoid discontinuities, a three-tap filter is applied to replace the value of , and a two-tap filter is applied for all predicted samples and where x = y = 1 … :
2.6. Best Mode Decision
As explained in earlier sections, H.265/HEVC has introduced a series of new prediction modes that enhance the old prediction modes of H.264/AVC to eliminate duplications in prediction and improve compression efficiency and the efficient processing of PU with complicated structures. First, the mode selection runs all 35 modes for each PU before deciding on the optimum mode to use in that PU block.
Next, the RMD (Rough Mode Decision) and RDO (Rate Distortion Optimization) are processed. The RMD process can be regarded as a pre-processing phase that minimizes the complexity of RDO by lowering the number of modes to be predicted from 35 to less and putting them in a list. Then, the modes in the list are evaluated by RDO to discover the most optimal mode for prediction.
During RMD execution, the encoder calculates the cost function for each PU using the Lagrangian cost function:
where is the total cost required to encode a PU, and SAD (Sum of Absolute Transform Difference) is the total difference between the original and predicted PU blocks. is the Lagrangian coefficient, and is the bit rate needed to encrypt that PU block.
For RMD implementation, the decoder reduces the number of modes to perform from 35 modes to three modes (PU , , ) and eight modes (PU and ), with the lowest costing ones, after being calculated, added to the list of candidates. In addition, since the upper and left-adjacent PUs are related to the current PU, and these blocks have been encrypted, and the Intra mode of these blocks is also added to the list of candidates. These modes are called MPM (Most probable mode).
After completing the RMD step and adding MPM, the list of optimal modes is a total of 11 or 6 modes depending on the size of the PU. In the last step, the RDO process is performed to continue to calculate the costs of these modes and choose the lowest cost mode to apply to that PU using the following equation:
Similar to the calculation of RMD, is the RDO cost of each PU, is the Lagrangian coefficient, and is the bit rate required to encrypt that PU block. SSE is the sum of the squared error between the current and predicted PU blocks. After the calculation is completed, the processor chooses the mode with the lowest RDO cost as the mode of execution for the current PU. This process is shown in Figure 4.
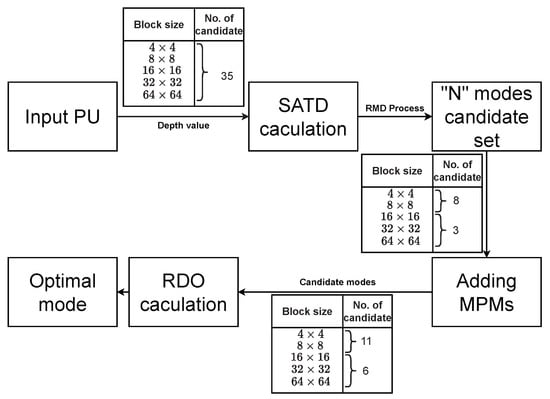
Figure 4.
Process of best mode decision [9].
3. Hardware Implementation of H.265/HEVC Intra-Prediction
The proposed hardware architecture supports all intra-prediction modes, and all PU block sizes (, , , ). According to Figure 5, the input reference samples are conditionally filtered and divided into three main datapaths for DC, planar, and angular prediction modules, as shown in Table 1, and the output predicted samples are fed to the SAD (Sum of Absolute Difference) module to calculate the cost for each prediction mode.
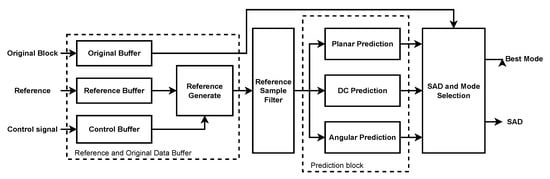
Figure 5.
The proposed hardware architecture for H.265/HEVC intra prediction.
3.1. Reference Sample Filtering
In the Reference Samples Filtering stage, a three-tap filter is applied according to Equations (1)–(3); Figure 6 depicts the hardware implementation of the three-tap filter. It has a pipeline behavior and requires three adders and two shifters.
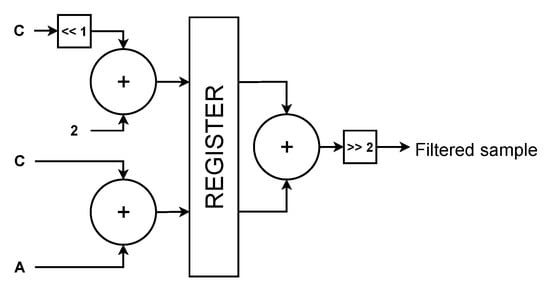
Figure 6.
Implementation of a TREE-TAP FILTER.
We used a tree-tap filtering cell for each reference sample and a multiplexer to select the output-filtered references based on the size of the prediction block to filter all of the input reference samples. The configuration of three-tap filtering cells is depicted in Figure 7. Depending on the size of the prediction block, a varied number of filtering cells is triggered to generate the output. All filtering cells are activated in the block; however, only cells 0 to 8 are activated in the block. It enables the Reference Samples Filter module to process reference samples of any size without duplicating hardware resources.
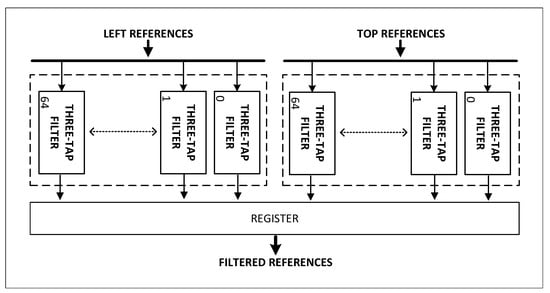
Figure 7.
Hardware architecture of Reference Samples Filter module.
3.2. Angular Prediction
The angular prediction Equations (8) and (9) require reference samples and i, f values for each prediction; before delivering the predicted samples, they can be flipped or post-filtered if necessary. Figure 8 depicts our proposed hardware architecture for the Angular prediction module.
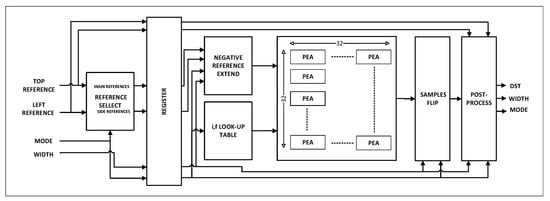
Figure 8.
The proposed hardware architecture for H.265/HEVC intra Angular mode.
The top and left references are chosen in our architecture to generate main and side reference samples for the next stage. The “REFERENCE SELECT” module processes the selection using multiplexers, as shown in Figure 9.
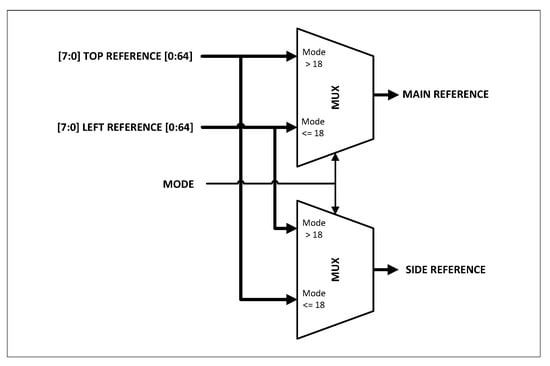
Figure 9.
The method to select main and side references.
The “NEGATIVE REFERENCE EXTEND” module processes the main and side references to generate the reference with the required negative index reference samples for prediction equations later. We have already calculated i and f for each mode and kept these values in memory as a look-up table to reduce the effort of finding i and f.
To implement Equations (8) and (9) without employing a multiplier, we use the PEA [2] (Processing Element for Angular) concept. Equation (9) can be rearranged as follows:
As shown in Figure 10, a group of five 2to1 multiplexers and six adders is employed, and a three-stage pipeline is used to reduce propagation time and increase throughput.
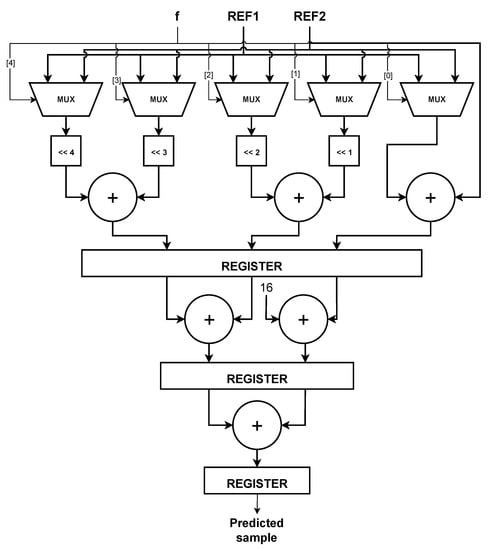
Figure 10.
The structure of Processing Element for Angular (PEA) [2].
Another technique to implement Equations (8) and (9) in FPGA is to use direct multiplication operations offered by the DSP block, as shown in Figure 11. The DSP blocks are particularly efficient regarding power consumption and may be customized. Moreover, they work well with binary multipliers and accumulators. Therefore, Equation (9) should be modified using the DSP as follows:
Then, Equation (26) matches to the custom implementation of DSP48 slice, where:
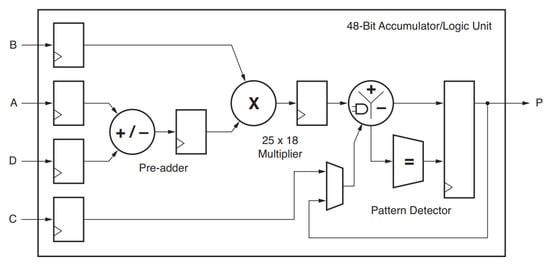
Figure 11.
Basic structure of DSP48E1 Slice [10].
The biggest PU size needs 1024 PEA units to predict 1024 samples for one mode in the angular prediction architecture. The PU size needs 64 PEA units to predict 64 samples for one mode. Thus, we split those 1024 PEA units into 16 groups (64 PEA units/group), then each group is used to predict 64 samples for one mode. Therefore, 16 modes can be predicted in parallel. The parallelism for PU size is achieved in the same manner. Using flexible PEAs, we can obtain a maximum throughput of 1024 predicted samples per clock cycle. The predicted block will be flipped at the “SAMPLES FLIP” module in the case of horizontal modes. The flip process is depicted in Figure 12.
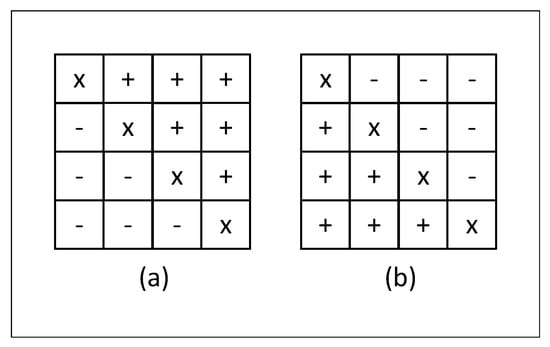
Figure 12.
Illustration of the input/output of “FLIP” module for prediction block of where: (a) input predicted block, (b) flipped block output.
3.3. Planar Prediction
Module Planar prediction in Intra Prediction helps solve the image’s areas with countering and blockiness inside a PU block. Similar to Angular Prediction, we also transfer multiplications in Equations (17) and (18) into the adders and shifters module to reduce the complexity of multiplications. For example, in the case of PU size is , with , Equations (17) and (18) are as follows:
In the case of and , then the formula is:
Two multiplications in (36) and (37) can be transformed into the shifter and adder modules according to the following formula:
Compared to employing multipliers, this transformation uses a set of shifters and adders instead of multipliers, as shown in Figure 13, which reduces the resources required to calculate the values of and .
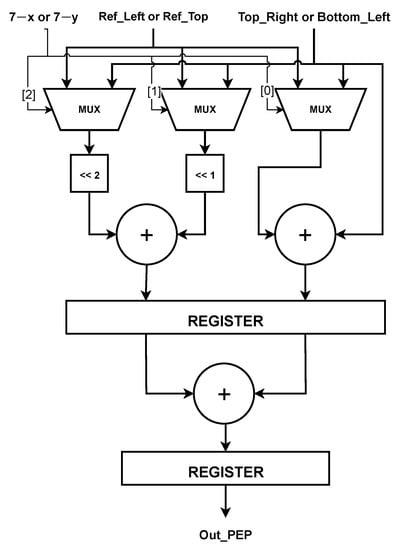
Figure 13.
The structure of Processing Element for Planar (PEP) [2].
The module’s input is determined by whether the calculated value is or . If is the calculating value, the input value will be , left reference samples, value, and reversed. These two numbers will be calculated in parallel simultaneously to increase throughput.
Figure 13 depicts a module with a two-stage pipeline to calculate in the situation of a PU size , in which the values of and shift from 0 (0 0 0) to 7 (1 1 1). As a result, it requires three bits to cover all cases, with these bits simultaneously acting as the input for three corresponding multiplexers. If , the selected values will be identical to the value of the reference sample. If , the input values will be either Top_Right () or Bottom_Left () depending on which value needs to be calculated. Then, these values are combined to produce the calculation-required value of and [2].
The number of multiplexers and shifters used to decode the relevant bits varies depending on the PU size. A maximum of five multiplexer sets for PU and a minimum of 2 multiplexer sets for PU .
These modules are used as the sub-modules to operate Equation (16), thus creating predicted samples for 8 × 8 size module, as shown in Figure 14. The same method is used for , , and PU sizes.
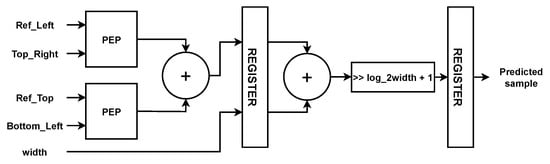
Figure 14.
Hardware architecture of Planar sample prediction.
The Planar Prediction module’s output is the predicted sample values at the location that has to be predicted after using the Planar Prediction algorithm. Then, depending on the processing PU size, these values are chosen by employing a multiplexer. The selection signal input of this multiplexer is controlled by the value of , as shown in Figure 15.
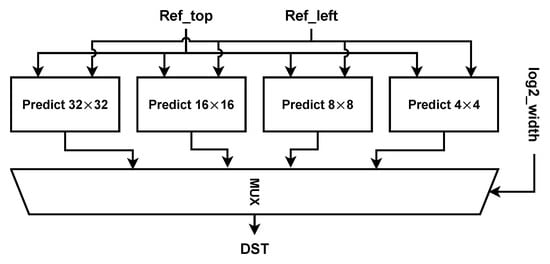
Figure 15.
Hardware architecture planar prediction.
3.4. DC Prediction
The architecture of the module DC prediction is relatively straightforward because the outcome of DC Prediction is simply a calculated dcVal value based on the sum of left and top reference samples, which are then attached to every single output sample location inside the PU block.
In this module, the values of the top and left reference samples are sequentially passed by the add module to be added. In the case of PU size , we employ a pipelined adder tree with 63 adder stages for adding at this step. It takes six clock cycles to add all of the left and top references.
The values of , , and in DC prediction must pass through post-processing procedures, as indicated in Section 3.4. Hence, after adding all of the left and top samples, the dcVal output is attached to a series of three parallel filter modules to determine the output value. Figure 16 depicts a complete DC prediction module with the filters that have been added.
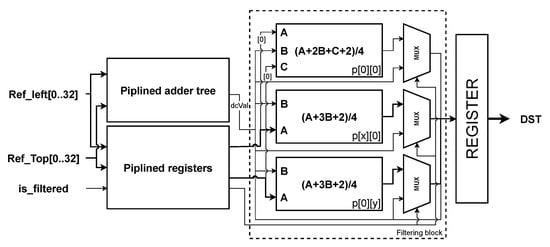
Figure 16.
Hardware architecture of DC Prediction.
In special cases with predicted samples at positions , , and , when the dcVal value is ready, it is put inside three-taps () or two-taps filter module ( and ), a multiplexer set is added to these values with control signal is a variable. In the case , the output value equals after processing through filters. Vice versa, if , the final value is . The first output requires seven clock cycles to complete all pipeline registers, and the next projected value is ready at each cycle.
4. Functional Verification
To validate our solution, we create a Universal Verification Methodology (UVM) environment, as illustrated in Figure 17. The Angular, DC, and Planar sequences are randomized and delivered to DUT via a virtual interface. The DUT output is gathered and monitored before being compared to the output of the H.265/HEVC intra-prediction software reference model and updated in the coverage report.
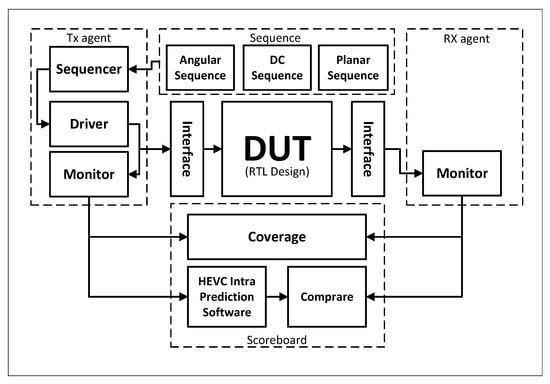
Figure 17.
The structure of the verification environment used for our DUT.
An open-source H.265/HEVC encoder [11] is used as a reference model for the intra-prediction module in this research. The model was created in the C programming language and supports all intra-prediction modes and PU sizes. By employing the SystemVerilog Direct Programming Interface [12] (DPI), which allows SystemVerilog to connect directly with functions written in C, we can eliminate errors in constructing our own software reference model because we reuse existing C functions from [11].
Questasim 10.7c is used to operate our test environment. A test case is considered “PASSED” when the same input reference sample is used, and the prediction output of the DUT with the software model is the same. We set coverage checkpoints for all prediction modes to ensure that our design was covered during the simulation phase. The simulation results indicate that our design function was successful.
5. Synthesis Results
The proposed hardware architecture is described in SystemVerilog, with a synthesis target of Xilinx Virtex-7 (xc7vx485tffg1761-3) and a speed grade = −2.
The latencies of the PU modules taken to perform in a CU module are described in Table 3. The parameters Latency of load reference samples, Latency of reconstruction loop, Latency of sample prediction, and Number PUs in 1 CU are labeled by (1), (2), (3), and (4). For the PU , PU 8 × 8, PU , and PU , the latencies of loading reference samples are 1, 1, 2, and 4, respectively. As shown in Figure 2, the latencies of the reconstruction loop of those PUs are the delay from the Sample Prediction unit, Subtraction, Transform, Quantization, Inverse Quantization, Inverse transform, and Summation modules. For the optimal pipelined design, the delay of the Subtraction, Transform, Quantization, Inverse Quantization, Inverse transform, and Summation modules can be estimated by 1, 2, 2, 2, 2, and 1 cycles, respectively. The latencies of the Sample Prediction unit are 3, 3, 36, and 36 clocks for the PU , PU 8 × 8, PU , and PU , respectively. Therefore, the latencies of the reconstruction loop of those PUs are 13, 13, 46, and 46, respectively. For the worst-case prediction for one CU module, 1 PU , 4 PUs , 16 PUs 8 × 8, and 64 PUs are performed. Then, the total latency to finish one CU module is 546 cycles. Therefore, as shown in Table 4, if we do the intra-prediction for the FHD frame, there are 2020 CU modules to be executed. Then, the frame rate is 210 FPS. If we do the intra-prediction for the 4K frame, there are 8100 CU modules to be executed. Then, the frame rate is 52 FPS.
Table 3.
Latency of PUs processing in a CU.
Table 4.
Frame Rate of the FHD and 4K Video.
The synthesis comparison results are shown in Table 5 and Table 6. The slide LUTS utilization costs 73%, and the slice registers utilization costs 41% of the FPGA resources. The memory utilization of our design is high because all reconstructed samples are stored in register buffers, including the original buffer, reference buffer, and control buffer, as shown in Figure 5.
Table 5.
Synthesis results and comparison with the other FPGA implementations.
Table 6.
Synthesis results and comparison with the other FPGA implementations (continue).
Compared to earlier works, the proposed design [13] accelerates the throughput of the most frequently used PU (PU ). This approach provides a frame rate of 4.38 FPS for the 4K resolution. To increase the throughput up to 7.5 FPS, the authors of [14,15] applied the pipelined TU coding and the paralleled intra-prediction architectures. By applying a fully parallel manner for the mode prediction, transformation, quantization, inverse quantization, inverse transformation, rate estimation, and reconstruction processes, [16,17] provided a frame rate of 11.25 FPS. To improve both throughput and hardware resources, ref. [18] proposed a four-stage pipeline architecture. This approach provides a frame rate of 15 FPS with a high bit rate/area (47 Kbps/LUT). To reach real-time 4K video processing of 24 FPS, [2] simplified the equations of all calculations for reference sample preparations and applied parallel computing. The authors of [19,22] investigated parallelization of Kvazaar-based intra-encoder on CPU and FPGA platforms to obtain the frame rate of 60 FPS for the 4K resolution with a bit rate/area of about 20 Kbps/LUT. The authors of [20] studied the impact of a high-level synthesis (HLS) design method on the HEVC intra-prediction block decoder. Although this work provides a high bit rate/area (45.82 Kbps/LUT), the frame rate is only 2 FPS. To increase the frame rate of 15 FPS, [21] proposed the computationally scalable algorithm and the architecture design for the H.265/HEVC intra-encoder. This design provides a bit rate/area of 32.04 Kbps/LUT. The designs in [23,24] provide a high frame rate of 30 FPS for the 4K resolution. However, the hardware resources of these works are not mentioned. To extremely reduce the hardware resources, some works applied approximation algorithms to simplify the designs [3,4,25,26]. The frame rates of those designs are 10, 13.75, 30, and 24 FPS, respectively. Although these approaches helped to increase the bit rate/area performance extremely, their peak signal-to-noise ratios (PSNRs) are affected. In addition to implementing on FPGA platforms, some works are designed and implemented on the ASIC platform [27,28] to provide the frame rate of 30 FPS for the 8K resolution. As shown in Table 5 and Table 6, our work provides a frame rate of 52 FPS with a high bit rate/area (48 Kbps/LUT). This throughput is high enough for the real-time processing of the 4K video frame.
6. Conclusions
This research uses both DSP and non-DSP versions of H.265/HEVC intra-prediction. PEA and PEP cells were employed to reduce the complexity of multiplications by developing a pipeline design with parallel processing for DC, Angular, and Planar predictions. The architecture creates multiple predictions for the angular mode with PU sizes of and with the flexible use of PEA cells. The design was synthesized and mapped to the Xilinx Virtex-7, which can handle 210 FPS for the FHD resolution and 52 FPS for the 4K resolution. The design is appropriate for high-resolution real-time coding. However, the hardware resources of our design still need to be improved. In future work, we will explore the approximation techniques to apply to our current design to optimize hardware resources and accuracy.
Author Contributions
Investigation, P.T.A.N. and T.A.T.; Methodology, D.K.L.; Project administration, D.K.L.; Supervision, D.K.L.; Writing—original draft, P.T.A.N. and T.A.T.; Writing—review and editing, D.K.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by The VNUHCM-University of Information Technology’s Scientific Research Support Fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kalali, E.; Adibelli, Y.; Hamzaoglu, I. A high performance and low energy intra prediction hardware for High Efficiency Video Coding. In Proceedings of the 22nd International Conference on Field Programmable Logic and Applications (FPL), Oslo, Norway, 29–31 August 2012; pp. 719–722. [Google Scholar] [CrossRef]
- Amish, F.; Bourennane, E.-B. Fully pipelined real time hardware solution for High Efficiency Video Coding (HEVC) intra prediction. J. Syst. Archit. 2016, 64, 133–147. [Google Scholar] [CrossRef]
- Azgin, H.; Kalali, E.; Hamzaoglu, I. A computation and energy reduction technique for HEVC intra prediction. IEEE Trans. Consum. Electron. 2017, 63, 36–43. [Google Scholar] [CrossRef]
- Azgin, H.; Mert, A.C.; Kalali, E.; Hamzaoglu, I. An efficient FPGA implementation of HEVC intra prediction. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Wang, C.; Kao, J.-Y. Fast Encoding Algorithm for H.265/HEVC Based on Tempo-spatial Correlation. Int. J. Comput. Consum. Control. (IJ3C) 2015, 4, 51–58. [Google Scholar]
- Lainema, J.; Bossen, F.; Han, W.J.; Min, J.; Ugur, K. Intra Coding of the HEVC Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1792–1801. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, S.; Lei, S. Intra mode coding in HEVC standard. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Nair, P.S.; Nair, M.S. On the analysis of HEVC Intra Prediction Mode Decision Variants. Procedia Comput. Sci. 2020, 171, 1887–1897. [Google Scholar] [CrossRef]
- Xilinx. 7 Series DSP48E1 Slice User Guide. UG479 (v1.10). 27 March 2018. Available online: https://docs.xilinx.com/v/u/en-US/ug479_7Series_DSP48E1 (accessed on 1 February 2023).
- Viitanen, M.; Koivula, A.; Lemmetti, A.; Ylä-Outinen, A.; Vanne, J.; Hämäläinen, T.D. Kvazaar: Open-Source HEVC/H.265 Encoder. In Proceedings of the 2016 ACM International Conference on Multimedia (MM’16), New York, NY, USA, 15–19 October 2016; pp. 1179–1182. [Google Scholar] [CrossRef]
- 1800-2017–IEEE Standard for SystemVerilog–Unified Hardware Design, Specification, and Verification Language; IEEE: Piscataway, NJ, USA, 2018. [CrossRef]
- Abramowski, A.; Pastuszak, G. A double-path intra prediction architecture for the hardware H.265/HEVC encoder. In Proceedings of the 17th International Symposium on Design and Diagnostics of Electronic Circuits & Systems, Warsaw, Poland, 23–25 April 2014; pp. 27–32. [Google Scholar] [CrossRef]
- Chen, W.; He, Q.; Li, S.; Xiao, B.; Chen, M.; Chai, Z. Parallel Implementation of H.265 Intra-Frame Coding Based on FPGA Heterogeneous Platform. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuvu, Fiji, 14–16 December 2020; pp. 736–743. [Google Scholar] [CrossRef]
- Atapattu, S.; Liyanage, N.; Menuka, N.; Perera, I.; Pasqual, A. Real time all intra HEVC HD encoder on FPGA. In Proceedings of the 2016 IEEE 27th International Conference on Application-specific Systems, Architectures and Processors (ASAP), London, UK, 6–8 July 2016; pp. 191–195. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, C. High-Performance Algorithm Adaptations and Hardware Architecture for HEVC Intra Encoders. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2138–2145. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, C. Efficient Algorithm Adaptations and Fully Parallel Hardware Architecture of H.265/HEVC Intra Encoder. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3415–3429. [Google Scholar] [CrossRef]
- Ding, D.; Wang, S.; Liu, Z.; Yuan, Q. Real-Time H.265/HEVC Intra Encoding with a Configurable Architecture on FPGA Platform. Chin. J. Electron. 2019, 28, 1008–1017. [Google Scholar] [CrossRef]
- Sjövall, P.; Viitamäki, V.; Vanne, J.; Hämäläinen, T.D.; Kulmala, A. FPGA-Powered 4K120p HEVC Intra Encoder. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Atitallah, A.B.; Kammoun, M. High-level design of HEVC intra prediction algorithm. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 2–5 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Pastuszak, G.; Abramowski, A. Algorithm and Architecture Design of the H.265/HEVC Intra Encoder. IEEE Trans. Circ. Syst. Video Tech. 2015, 26, 210–222. [Google Scholar] [CrossRef]
- Sjövall, P.; Viitamäki, V.; Oinonen, A.; Vanne, J.; Hämäläinen, T.D.; Kulmala, A. Kvazaar 4K HEVC intra encoder on FPGA accelerated airframe server. In Proceedings of the 2017 IEEE International Workshop on Signal Processing Systems (SiPS), Lorient, France, 3–5 October 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Aparna, P. Efficient Architectures for Planar and DC modes of Intra Prediction in HEVC. In Proceedings of the 2020 7th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 27–28 February 2020; pp. 148–153. [Google Scholar] [CrossRef]
- Shastri, S.; Lakshmi; Aparna, P. Complexity Analysis of Hardware Architectures for Intra Prediction unit of High Efficiency Video Coding (HEVC). In Proceedings of the 2020 International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 2–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Min, B.; Xu, Z.; Cheung, R.C. A Fully Pipelined Hardware Architecture for Intra Prediction of HEVC. IEEE Trans. Circ. Syst. Video Tech. 2016, 27, 2702–2713. [Google Scholar] [CrossRef]
- Kalali, E.; Hamzaoglu, I. An Approximate HEVC Intra Angular Prediction Hardware. IEEE Access 2019, 8, 599–2607. [Google Scholar] [CrossRef]
- Tang, G.; Jing, M.; Zeng, X.; Fan, Y. A 32-Pixel IDCT-Adapted HEVC Intra Prediction VLSI Architecture. In Proceedings of the 2019 IEEE International Symposium on Circuits and Systems (ISCAS), Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Fan, Y.; Tang, G.; Zeng, X. A Compact 32-Pixel TU-Oriented and SRAM-Free Intra Prediction VLSI Architecture for HEVC Decoder. IEEE Access 2019, 7, 149097–149104. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).