
Image Steganalysis of Low Embedding Rate Based on the Attention Mechanism and Transfer Learning


Abstract
1. Introduction
2. Related Work
2.1. Attention Mechanism
2.2. Transfer Learning
3. Proposed Method
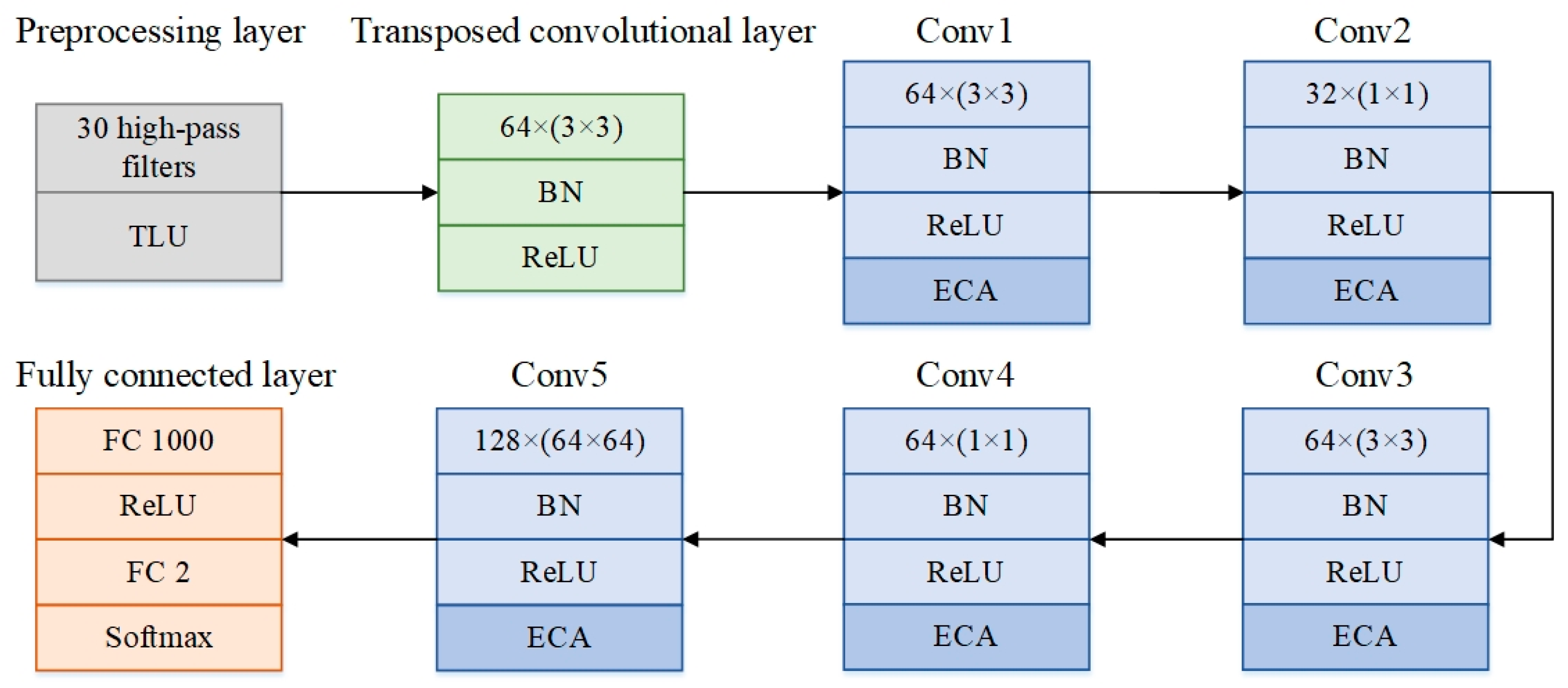
3.1. Model Structure
3.2. ECA Module
3.3. Model Migration
- Source domain training.
- 2.
- Feature migration.
- 3.
- Target domain training.
4. Experiments and Results Analysis
4.1. Software Platform and Dataset
4.2. Hyper-Parameters
4.3. Experimental Analysis
4.3.1. Effect of Attentional Mechanisms on Model Performance
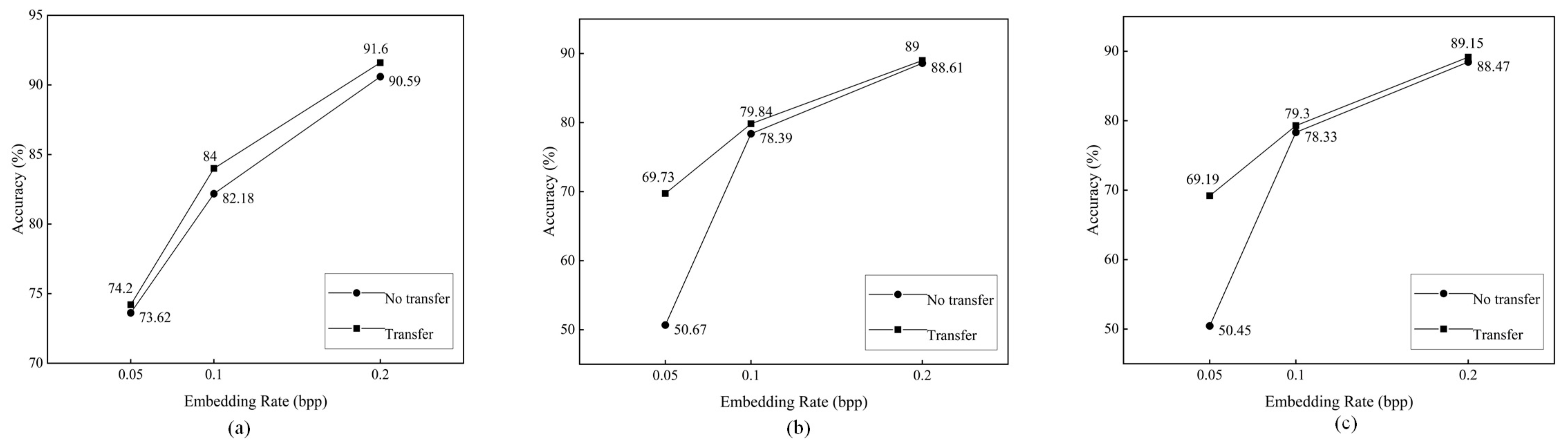
4.3.2. Role of Transfer Learning
4.3.3. Comparison with Other Models
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Han, C.; Ma, T.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A Novel Pavement Crack Image Segmentation Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22135–22144. [Google Scholar] [CrossRef]
- Ghaderizadeh, S.; Abbasi-Moghadam, D.; Sharifi, A.; Zhao, N.; Tariq, A. Hyperspectral Image Classification Using a Hybrid 3D-2D Convolutional Neural Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 7570–7588. [Google Scholar] [CrossRef]
- Ansari, S.U.; Javed, K.; Qaisar, S.M.; Jillani, R.; Haider, U. Multiple sclerosis lesion segmentation in brain MRI using inception modules embedded in a convolutional neural network. J. Healthc. Eng. 2021, 2021, 4138137. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Wu, H.; Shi, Y. Structural design of convolutional neural networks for steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Yedroudj, M.; Comby, F.; Chaumont, M. Yedroudj-net: An efficient CNN for spatial steganalysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2092–2096. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Shen, J.; Liao, X.; Qin, Z.; Liu, X.-C. Spatial Steganalysis of Low Embedding Rate Based on Convolutional Neural Network. J. Softw. 2021, 32, 2901–2915. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. J. Mach. Learn. Res. 2010, 9, 249–256. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines vinod nair. In Proceedings of the International Conference on Machine Learning, Madison, WI, USA, 21 June 2010; pp. 807–814. [Google Scholar]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 1, 1. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing Steganographic Distortion Using Directional Filters. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Costa Adeje, Spain, 2–5 December 2012. [Google Scholar]
- Pevný, T.; Filler, T.; Bas, P. Using high-dimensional image models to perform highly undetectable steganography. Int. Workshop Inf. Hiding 2010, 6387, 161–177. [Google Scholar]
- Niu, Z.Y.; Zhong, G.Q.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Huang, Z.L.; Wang, X.G.; Huang, L.C.; Huang, C.; Wei, Y.; Liu, W. CCNET: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Sperber, M.; Niehues, J.; Neubig, G.; Stüker, S.; Waibel, A. Self-attentional acoustic models. arXiv 2018, arXiv:1803.09519. [Google Scholar] [CrossRef]
- Letarte, G.; Paradis, F.; Giguère, P.; Laviolette, F. Importance of self-attention for sentiment analysis. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 267–275. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Pan, S.; Zhang, C. Disan: Directional self-attention network for rnn/cnn-free language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 4–6 February 2018. [Google Scholar] [CrossRef]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yan, C.; Tu, Y.; Wang, X.; Zhang, Y.; Hao, X.; Zhang, Y.; Dai, Q. STAT: Spatial-temporal attention mechanism for video captioning. IEEE Trans. Multimed. 2019, 22, 229–241. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using CNN with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Cai, W.; Wei, Z. Remote sensing image classification based on a cross-attention mechanism and graph convolution. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Niu, S.; Liu, Y.; Wang, J.; Song, H. A decade survey of transfer learning (2010–2020). IEEE Trans. Artif. Intell. 2020, 1, 151–166. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Bas, P.; Filler, T.; Pevný, T. “Break our steganographic system”: The ins and outs of organizing BOSS. Int. Workshop Inf. Hiding 2011, 6958, 59–70. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Number of HPF | Number of Convolutional Layers | Number of Average Pooling Layers | Number of Fully Connected Layers | With or without Transposed Convolution |
|---|---|---|---|---|---|
| Xu-Net [4] | 1 | 5 | 5 | 1 | No |
| Yedroudj-Net [6] | 30 | 5 | 4 | 3 | No |
| Shen-Net [9] | 30 | 3 | 0 | 2 | No |
| Whether or Not to Introduce ECA | Detection Accuracy (%) | ||||
|---|---|---|---|---|---|
| 0.05 bpp | 0.1 bpp | 0.2 bpp | 0.3 bpp | 0.4 bpp | |
| No ECA introduced | 72.82 | 81.77 | 88.65 | 94.65 | 96.91 |
| ECA introduced | 73.62 | 82.18 | 90.59 | 95.10 | 97.16 |
| Whether or Not to Introduce ECA | Detection Accuracy (%) | ||||
|---|---|---|---|---|---|
| 0.05 bpp | 0.1 bpp | 0.2 bpp | 0.3 bpp | 0.4 bpp | |
| No ECA introduced | 50.22 | 77.70 | 87.79 | 93.02 | 95.87 |
| ECA introduced | 50.67 | 78.39 | 88.61 | 93.65 | 96.20 |
| Network Models | Detection Accuracy (%) | ||
|---|---|---|---|
| 0.05 bpp | 0.1 bpp | 0.2 bpp | |
| Xu-Net [4] | 50.55 | 53.82 | 60.94 |
| Yedroudj-Net [6] | -- | -- | 56.01 |
| Shen-Net [9] | 69.17 | 78.90 | 88.17 |
| TCSI-ECA-Transfer | 74.20 | 84.00 | 91.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhang, C.; Wang, L.; Yang, P.; Hua, S.; Zhang, T. Image Steganalysis of Low Embedding Rate Based on the Attention Mechanism and Transfer Learning. Electronics 2023, 12, 969. https://doi.org/10.3390/electronics12040969
Liu S, Zhang C, Wang L, Yang P, Hua S, Zhang T. Image Steganalysis of Low Embedding Rate Based on the Attention Mechanism and Transfer Learning. Electronics. 2023; 12(4):969. https://doi.org/10.3390/electronics12040969
Chicago/Turabian StyleLiu, Shouyue, Chunying Zhang, Liya Wang, Pengchao Yang, Shaona Hua, and Tong Zhang. 2023. "Image Steganalysis of Low Embedding Rate Based on the Attention Mechanism and Transfer Learning" Electronics 12, no. 4: 969. https://doi.org/10.3390/electronics12040969
APA StyleLiu, S., Zhang, C., Wang, L., Yang, P., Hua, S., & Zhang, T. (2023). Image Steganalysis of Low Embedding Rate Based on the Attention Mechanism and Transfer Learning. Electronics, 12(4), 969. https://doi.org/10.3390/electronics12040969