1. Introduction
Data mining plays a significant role in data analysis and knowledge extraction [
1]; it has become an efficient tool for pattern discovery due to its applicability in a variety of circumstances such as association rule mining (ARM) [
2], clustering analysis [
3], and classification [
4]. Mining frequent patterns (FPs) [
2] are fundamental in ARM. The connection-based algorithm, called Apriori [
5], is a classical breadth-first iterative algorithm for mining FPs. Many algorithms have been developed to accelerate the mining of FP. Han et al. proposed a depth-first algorithm called FP-Growth [
6,
7], based on FP-tree. It uses a prefix tree structure without generating candidates and only scans the dataset twice. BitTableFI [
8], as proposed by Dong et al., employs an efficient bit structure to compress the dataset.
After the proposal of ARM, many new types of patterns have emerged, including high-utility patterns [
9], periodic itemset patterns (PIPs) [
10], subgraph patterns [
11], and sequential patterns [
12], etc. Among them, PIPs are one of the most well-studied types of patterns. For instance, the opportunity for online or offline retailers to recommend suitable products to their customers is very critical, because the right recommendation may satisfy the customers, while a completely wrong one may be a turnoff to the customers. Customers may buy a new product when the old one reaches its expected life or is consumed, therefore, it is safe to assume that there is a relationship between the lifespan or consumption cycle of a product and its purchase number and cycle. By tapping into the purchase frequency and period of a product in customers’ shopping records, retailers cannot only improve the shopping experience of customers but also allow themselves to better understand the buying habits of customers, raise the recommendation hit rates, promote similar products, increase user stickiness, and so on. Accordingly, when the criteria of frequency and period are considered together, the retailers can make advisable marketing strategies. Therefore, it is very necessary to utilize the periodic itemset patterns in the shopping records in the decision-making department of retailers.
PIPs can be used to predict the occurrence of periodic events [
13], deal with the seasonality information of products [
14], and serve in recommendation systems [
15]. PIPs consider both the frequency and periodicity of an itemset and are regarded as an expanded derivative of FPs. There are various periodicity measures for PIPs [
16], which lead to different definitions, including the maximum period [
17], variance of periods [
18], and so on. In 2021, Chen et al. adopted a measure based on the coefficient of variation to define PIPs [
19]. In their work, an itemset is a PIP if its coefficient of variation is less than or equal to the threshold of coefficient of variation, indicating that the fluctuation of the period of the itemset is below the average level. They proposed a probability model for predicting periodic patterns. The frequency and periodicity influence the prediction accuracy of the probability model. For an itemset, a higher frequency indicates a wider range of sample sizes of the periods, and a lower coefficient of variation means less fluctuation. The model is limited due to the redundancies originating from predicting items that are contained in different PIPs multiple times. The redundancies are proportional to the number of PIPs.
In 2023, Chen et al. proposed a special sort of PIP, named the Skyline Periodic Itemset Pattern (SPIP) [
20], aimed at making accurate pattern predictions. In SPIPs, PIPs with either higher frequency or lower coefficient of variation, or both, are preferred. They provided the definition of SPIP and proposed an effective algorithm named SPIM for mining SPIPs. Patterns that are not dominated by any other patterns in two dimensions constitute the skyline of a 2-dimensional dataset [
21]. A PIP is an SPIP if there are no other PIPs with both higher frequency and lower coefficient of variation. By mining SPIPs, we can significantly reduce the number of patterns while ensuring the accuracy of predictions. The aim of mining SPIPs is to avoid a vast number of PIPs and relieve users from an overload of patterns.
SPIM is divided into two steps. The first step is to mine all FPs in advance using FP-Growth, and then identify SPIPs from the FPs obtained in the first step. Using FP-Growth to mine FPs makes SPIM consist of two very independent steps. Additionally, the occurrence sets of an itemset are generated in the second step, even if the itemset has already been identified as an FP. Confined by these two complicated stages, SPIM consumes massive computational resources. The running time of SPIM is longer than that of FP-Growth, as FP-Growth essentially serves as part of SPIM. In terms of memory usage, constructing FP-trees in FP-Growth consumes significant memory resources. These disadvantages of SPIM motivate the development of a more efficient SPIP mining approach.
Instead of using separate steps, we found that the identification of SPIP can proceed as soon as an itemset is recognized as an FP. Additionally, efficient bitwise representations can accelerate set operations. We present a novel approach called Bitwise Skyline Periodic Itemset Pattern Mining (BitSPIM) for mining SPIPs. This method utilizes bitwise representations in an Apriori-like algorithm named BitTableFI [
8] to deal with FPs while incorporating a novel cutting mechanism. Once an itemset is recognized as an FP, the bitset for its occurrence set is directly used to derive its period list and coefficient of variation, which are then used to determine whether the itemset is an SPIP. Simulated experiments were conducted on ten transaction datasets with divergent characteristics to compare the performance of BitSPIM and SPIM. The experimental results demonstrate the effectiveness of the proposed method in terms of running time and memory usage. We believe that BitSPIM could be an influential alternative in mining SPIPs.
2. Related Works
In this section, we review related works and techniques concerning mining SPIPs. SPIP is a special type of PIP. In the field of PIP mining, different periodicity measures can lead to various types of PIPs. Maximum period [
17] can be used as the periodicity measure for PIPs, and such PIPs are mined by periodic frequent pattern growth, which utilizes a tree structure. Fournier-Viger et al. provided various kinds of periodic measures. Three measures named minimum periodicity, maximum periodicity, and average periodicity are proposed in [
22], and an algorithm named Periodic Frequent Pattern Miner mines PIPs with the aid of the monotonicity of these three types of periodicity. Additionally, they introduced the definitions of periodic standard deviation and sequence periodic ratio [
23] to mine PIPs common to multiple sequences. A regularity measure for PIPs is defined using the variance of periods [
18]. Based on the standard deviation, the coefficient of variation is adopted to measure PIPs in the works of Chen et al. [
19]. They then inherited the coefficient of variation measure to define SPIP in [
20].
Mining FPs is a fundamental procedure in mining SPIPs. Depth-first search and breadth-first search are two main methods for mining FPs, known as candidate generation and pattern growth, respectively [
24]. Depth-first algorithms search for FPs in a bottom-up manner. Starting from itemsets containing a single item, larger FPs with more items are recursively generated by appending items according to the total order. Han et al. proposed a depth-first algorithm called FP-Growth [
6,
7], based on the FP-tree, to compress database transactions. This method consumes a significant amount of running time in creating multiple subtrees. Additionally, the performance of the algorithm is affected by the storage consumption from recording a substantial number of FP-tree nodes.
As for breadth-first search, Apriori [
5] proposed by Agrawal et al., is a classical breadth-first FP mining algorithm. It is a fundamental iterative algorithm that uses a layer-by-layer search to find FPs, employing an iterative search pattern and a test-and-generate approach. Based on the Apriori algorithm, several algorithms have been developed to compress the database, allowing for the quick generation of candidate itemsets and the calculation of their support. T-Apriori [
25] uses an overlap strategy when counting support to ensure high efficiency. BitTableFI [
8], proposed by Dong et al., employs an efficient bit structure to compress the database.
Apart from approaches like BitTableFI for mining FPs, bitwise representations and operations are exploited in various works in mining metadata. Index-BitTableFI [
26] is an improved version of BitTableFI, which utilizes heuristic information provided by an index array. SPAM [
27], aimed at mining sequential patterns, employs a bitmap representation of the database. In IndiBits [
28], proposed by Breve et al., the binary representation of data similarities is used, and bitwise operations are employed to update the Binary Attribute Satisfiability (BAS) Distance Matrix. For mining frequent closed itemsets, algorithms for efficiently calculating the intersection between two dynamic bit vectors [
29] are proposed. CloFS-DBV [
30] also utilizes dynamic bit vectors to mine frequent closed itemsets. The computation of support is based on dynamic bit vectors when generating new patterns. These bit vectors can also be used in mining web access patterns [
31]. Trang et al. proposed two algorithms named MWAPC and EMWAPC, which are based on the prefix-web access pattern tree (PreWAP) structure for mining web access patterns with a super-pattern constraint. In DPMmine [
32], vector column intersection bitwise operations are used to aid the algorithm in mining colossal pattern sequences.
3. Background and Preliminaries
Let
denote a set of finite items,
is the number of items in
I. The items are discrete real numbers or symbols. As shown in
Figure 1, there are mapping relations that map these discrete numbers and symbols into a group of continuous items. In our paper, we assume that there exist mapping relations that map the real numbers or symbols into a series of continuous integers starting from 1. The relevant definitions of mining SPIPs are presented as follows:
Definition 1. A transaction is a set of items in I, i.e., . holds a unique index k called the transaction identifier.
A transaction dataset
=
comprises
n transactions.
is the number of transactions in
.
Table 1 shows an example transaction dataset
containing five transactions denoted by
to
, where
,
= 5. Example 1 shows the relationship between
and
I, where 1 ≤
k ≤ 5. Transactions represent a shopping list of products from the retailer that are purchased by a customer;
I can be used to represent the whole set of products on the shopping list. The transaction dataset can be extracted from the database of the retailer, which is served as the shopping record in a time interval.
Example 1. For the set of items = {1, 2, 3, 5} in Table 1, since , is a transaction. For another set of items {1, 2, 6, 8}, which is not a subset of I, it is not a transaction. Definition 2. An itemset, X, is a non-empty set, and X ⊆ I. An itemset, X, containing n items is called an n-itemset. n is the size of the itemset. Specifically, is a 1-itemset that contains a single item i.
Example 2. = {3} and = {2, 3} are two itemsets with sizes of 1 and 2. Thus, the two itemsets are also called a 1-itemset and a 2-itemset, respectively.
Definition 3. The occurrence set for an itemset X is a set of transaction identifiers, = .
Example 3. In Table 1, , , and incorporate X = {2, 3}, so = {1, 3, 5}. Definition 4. The frequency for an itemset X is the ratio of the size of to the number of transactions in the dataset, = . Given a frequency threshold θ, an itemset X is a frequent pattern if .
Example 4. For in Table 1 with a frequency threshold θ = 0.7, for = {2, 3} and = {3, 4}, = {1, 3, 5} and = {2, 3, 4, 5}. Thus, = 0.6 and = 0.8. Since , is a frequent pattern. Similarly, is not a frequent pattern since . Definition 5. The period list for an itemset X is the set of periods of X: = {{}}.
Definition 6. The coefficient of variation of an itemset X is the ratio of the standard deviation of to the mean of : = . and represent the standard deviation and mean, respectively.
Example 5. = {1, 2} and = {3, 6} in , as shown in Table 2, = {1, 4, 6, 8, 11}. Thus by Definition 5, = {3, 2, 2, 3}. The standard deviation and the mean of are 0.5 and 2.5, respectively, = = 0.2. Similarly, = {3, 4, 5, 12} and = {1, 1, 7}, = 0.943. The coefficient of variation is a suitable metric for measuring the periodicity of patterns [
19]. It reflects the fluctuation in the appearance of patterns in the transaction dataset. Patterns with a lower coefficient of variation exhibit better periodicity, while a higher coefficient of variation indicates irregularity in occurrence. We follow the approach of Chen et al. in introducing the coefficient of variation as a measure of periodicity [
19].
Definition 7. For a transaction dataset, a frequency threshold θ, and a coefficient of variation threshold δ, an itemset X is a periodic itemset pattern if X is a frequent pattern and . The set of PIPs is denoted by : Example 6. = {1, 2} and = {3, 6} in , as shown in Table 2, with a frequency threshold θ = 0.2 and a coefficient of variation threshold δ = 0.5. Both and are FPs, as their frequencies are beyond 0.2. As = 0.2 < 0.5, by Definition 7, is a PIP. Similarly, is not a PIP since = 0.943 > 0.5. Definition 8. For two itemsets (X and Y) in a transaction dataset, X is dominated by Y if and , or and . ‘X is dominated by Y’ is equivalent to ‘Y dominates X’.
Example 7. For = {1, 2}, = {3, 6}, and = {3} in , as shown in Table 2, the frequency and the coefficient of variation of , , and are listed in Table 3. By Definition 8, neither nor dominate , as < and < . Neither nor dominate as > and > . As < and > , is dominated by . Similarly, it is dominated by . Definition 9. For a transaction dataset, , a frequency threshold, θ, and a coefficient of variation threshold, δ, an itemset, X, is an SPIP if X is a periodic itemset pattern and X is not dominated by other itemsets in . The set of SPIPs is denoted by : By Definitions 8 and 9, the aim of mining SPIPs is to explore the patterns that are more frequent or have better periodicity or both.
4. BitSPIM: The Proposed Method
4.1. The Preliminaries of Bitwise Representation
In our approach, bitsets and efficient bitwise representations are introduced to deal with set operations.
Definition 10. The bitset for a set, X, is denoted by . is the ith bit of . If an item , then is assigned as 1. Otherwise, it is assigned as 0: The Set operation and Clear operation are used to assign 1 and 0 to the bits in the bitset, respectively.
and are the sizes of X and , respectively. equals the number of bits assigned, as 1 in . Obviously, = . By Definition 10, a mapping relation between the set and its bitwise representation is established. This relation enables the efficient use of bitwise operations when handling sets. For example, the intersection operation and union operation between sets are equivalent to performing “&” and “|” on their bitsets, respectively.
Definition 11. The value of a bitset denoted by is the binary number of .
As shown in Example 8, the bitsets can be regarded as binary numbers; thus, the value of bitsets can directly be compared.
Example 8. For = {2, 3, 5} and = {3, 4, 5} in , and are 01101 and 00111, respectively. as 01101 > 00111.
The transactions are also sets of items. If an item
i is in a transaction
,
is assigned as
1. Hereby, the bitset for a transaction is obtained. For a dataset
, the bitwise representation of
is derived by obtaining the bitsets for all transactions. The bitwise representation of
is shown in
Table 4.
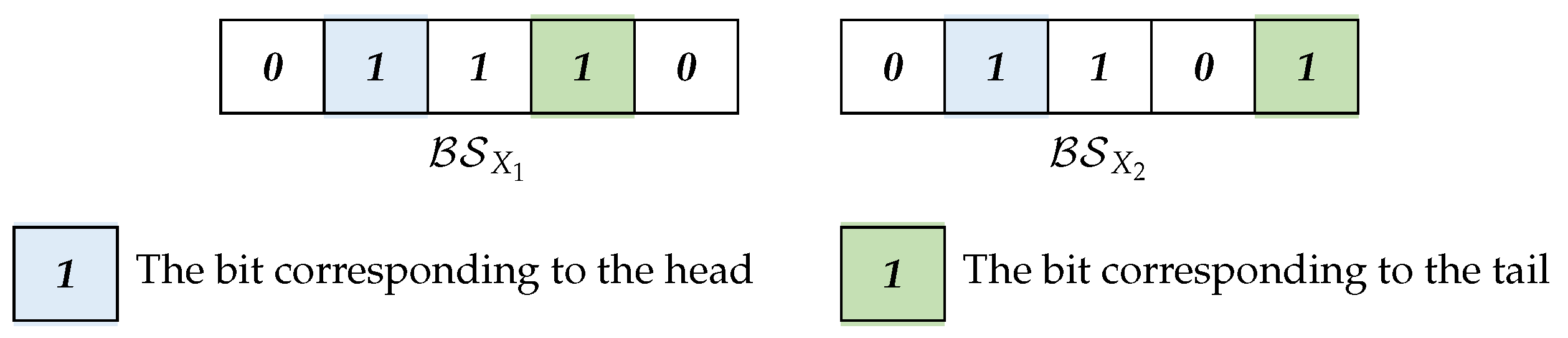
Definition 12. The head of an itemset X denoted by is the minimal item in X, it corresponds to the first 1 bit in . Accordingly, the tail of an itemset, X, denoted by , is the maximal item in X, and it corresponds to the last 1 bit in .
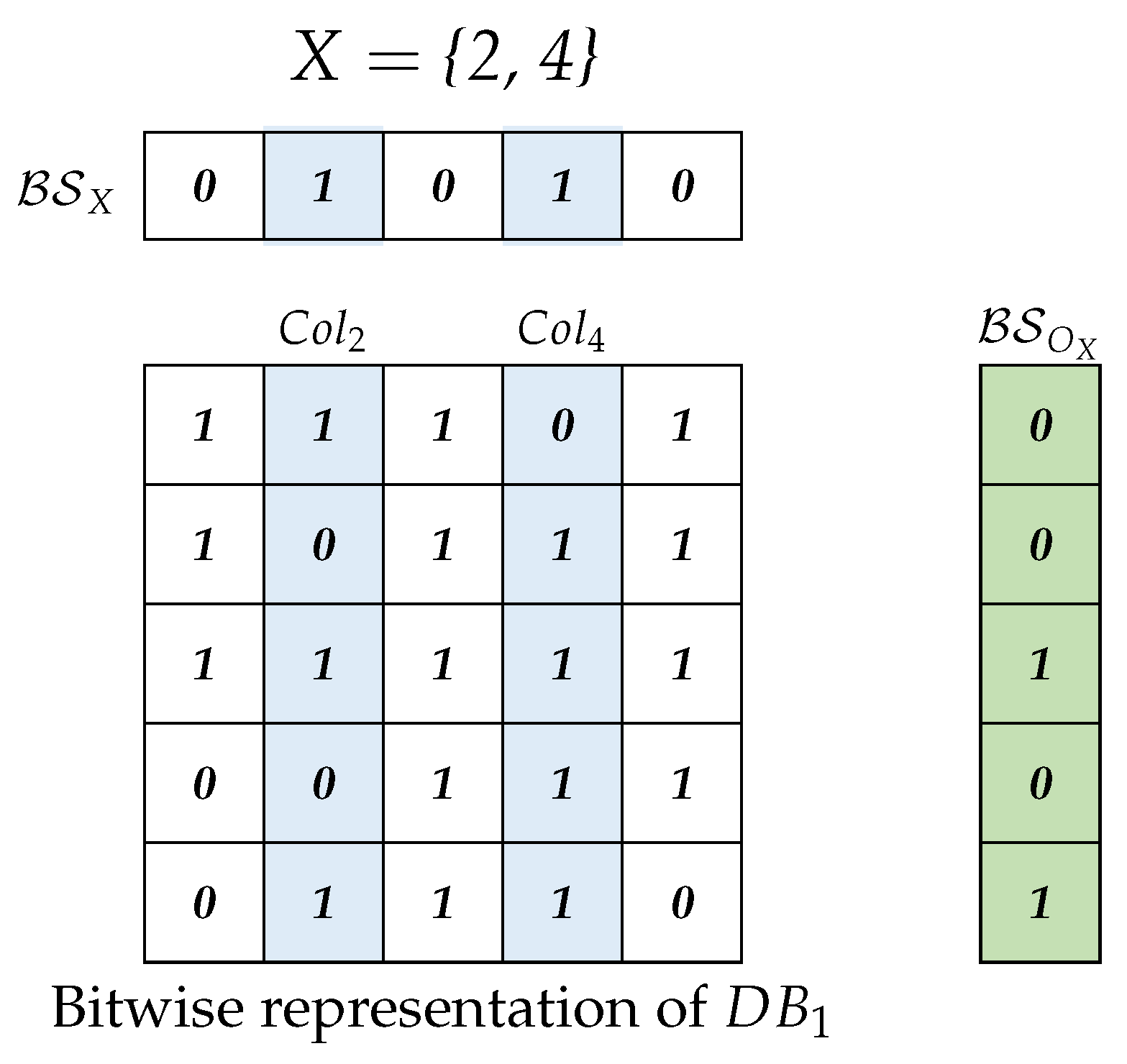
Example 9. As shown in Figure 2, for the 3-itemsets = {2, 3, 4} and = {2, 3, 5} in , = = 2, = 4 and = 5. Definition 13. Given a transaction dataset, , and its bitwise representation, I is the set of items in ; for an item , the column for i is the bitset for the occurrence set , where = .
By Definitions 3 and 10, with
, the frequency of
X can be calculated as
=
. For an itemset
X, Algorithm 1 shows the procedures to obtain the bitset for
. Initially,
equals
(line 4). Then,
is obtained by performing bitwise “&” operations on the columns for other items in
X (lines 5 to 9). The worst time complexity of Algorithm 1 is
(
/64), where
is the number of items in the dataset. Example 10 provides an illustration of acquiring
for an itemset
X in
Table 1.
| Algorithm 1 GetOccur |
- 1:
Input: : bitset - 2:
Output: : bitset - 3:
the head of X - 4:
- 5:
for each do - 6:
if then - 7:
- 8:
end if - 9:
end for - 10:
return
|
Example 10. By Table 4, for an itemset X = {2, 4} in Table 1, = 10101, =01111. As shown in Figure 3, by performing “&” on
and
,
is
00101.
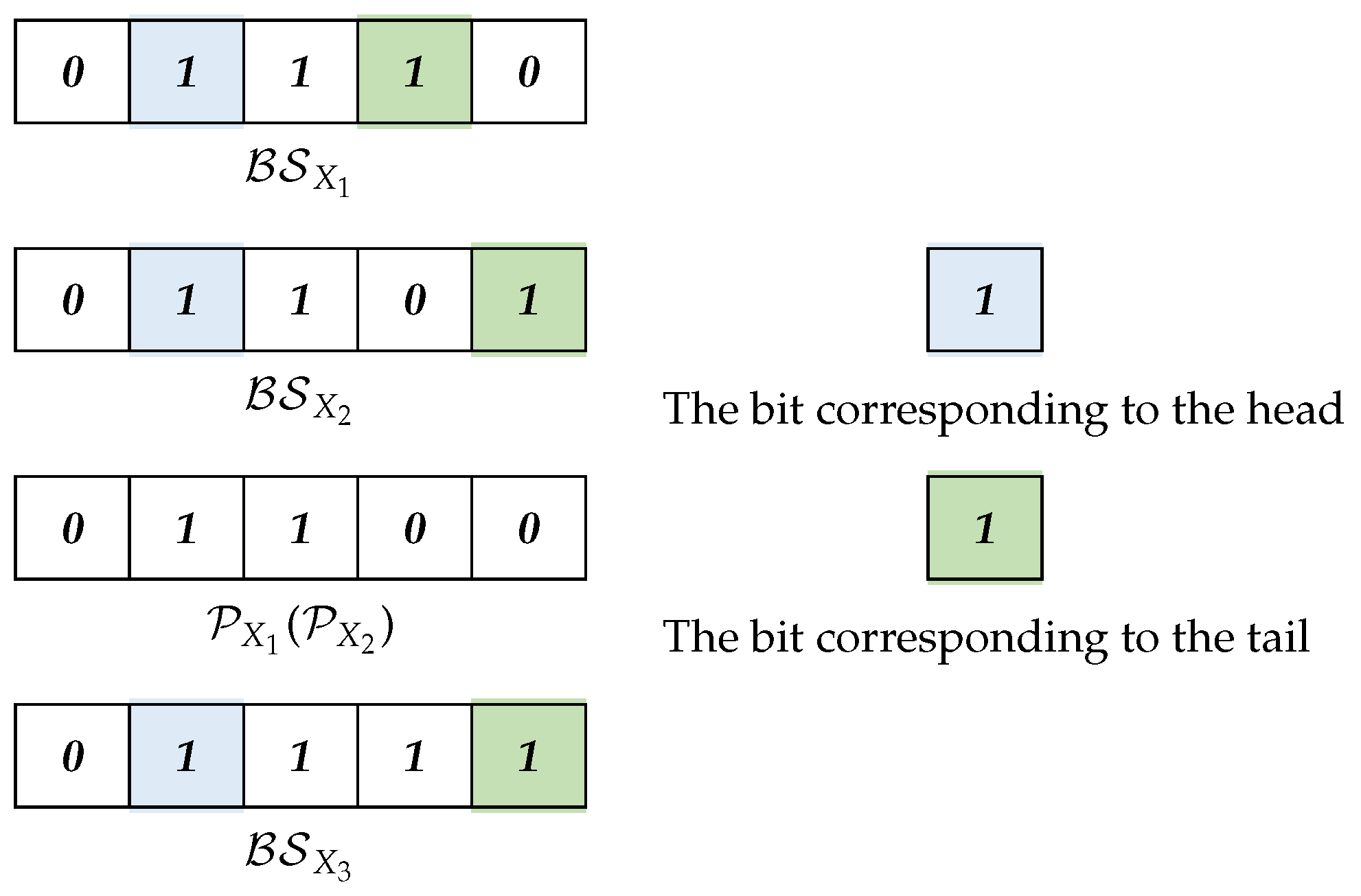
Definition 14. For an itemset, X, the prefix for X is denoted by . It is a bitset equal to while the last 1 bit is Cleared.
For two k-itemsets, X and Y, if X and Y have the same prefix, they have items in common and can be merged into a new -itemset Z. By Definition 12, the two k-itemsets, X and Y, and the new -itemset, Z, have an identical head, and the tail of Z is the larger one between and . Example 11 provides an illustration.
Example 11. As shown in Figure 4, for the 3-itemsets = {2, 3, 4} and = {2, 3, 5} in , since = = 01100, by merging and , a new 4-itemset is generated and = 01111, = = = 2. As , = = 5. In this paper, we specify that only itemsets with the same prefix can be merged.
4.2. Our Theories and Data Structure
Based on the aforementioned preliminary definitions and concepts, we introduce the critical knowledge and basic data structure to induce our proposed method. In BitSPIM, SPIPs are identified iteratively. We mark the iteration that generates the SPIPs of size k as kth iteration.
Definition 15. Given dataset , X and Y are two itemsets in , . If , then .
≻ reflects the relative position of the bitsets. If , is after . Obviously, the transitivity of ≻ between bitsets is satisfied. For three bitsets, , , and , if and , then .
Corollary 1. For two bitsets, and , if , then .
Proof. We denote as the value of the binary number for the bitset with the only 1 at the tail of X, , and accordingly, , . If , then and . If , then . If , assume , as and , , in other words, , which is contradictory with . The assumption is invalid and Corollary 1 is proved. □
Definition 16. The ItemsetList is an ordered list; its containing elements are unique bitsets with identical sizes. The ≻ relation holds between any two of the bitsets in .
PIPs and SPIPs are contained in the sets named
and
, respectively. The notations and functions of the ItemsetLists and sets in BitSPIM are shown in
Table 5:
Theorem 1. Suppose and are two bitsets in and . If ≠ , then there exists no , such that = and .
Proof. Since
,
by Corollary 1. As
≠
, there is
Suppose there exists
, such that
=
and
, then
and
, there is
Obviously, (
1) and (
2) contradict each other. Consequently, Theorem 1 is proved. □
Theorem 1 is the basic efficient cutting mechanism. An illustration of Theorem 1 is provided in Example 12.
Example 12. By Table 1, for five itemsets, = {1, 2, 3}, = {1, 2, 5}, = {1, 3, 4}, = {1, 3, 5}, and = {2, 4, 5} in , their bitsets and prefixes are shown in Figure 5. to are contained in and there is ≻≻≻≻. According to Theorem 1, since , neither the prefix for nor that of equals . As depicted in Figure 5, different types of bitsets are colored with different colors, respectively. and the bitsets that have the same prefix with are marked in blue; the first bitset that has a different prefix with is marked in green, and the bitsets that are not processed according to Theorem 1 are marked in gray. 4.3. Mining SPIPs Efficiently
In this section, a detailed illustration of BitSPIM is provided. We demonstrate our proposed method with an example of mining SPIPs in the
dataset, as shown in
Table 2, with a frequency threshold
= 0.4. For simplicity, the coefficient of variation threshold
is set to
∞, which implies that all FPs are also PIPs.
4.3.1. Identification of SPIPs with Bitset
We follow the key steps of the identification of SPIPs described in [
20] while several modifications are adopted. According to Chen et al., the identification of SPIPs does not proceed until all FPs are obtained, and at that moment, the occurrence set of each itemset is discovered.
Rather than acquiring all FPs in advance before the identification of SPIPs, in BitSPIM, once an itemset,
X, is recognized as an FP, the identification of whether
X is an SPIP is executed immediately. The bitset for
, denoted by
, can be directly utilized, which has already been obtained when calculating
. The steps of judging whether an FP is an SPIP are described in Algorithms 2 and 3. The function of Algorithm 2 is to remove all itemsets in
that are dominated by an itemset
X. Suppose
is the maximal number of itemsets in
; the worst time complexity of Algorithm 2 is
(
).
and
record the current maximal frequency and the minimal coefficient of variation of the itemsets in
, respectively. The steps of Algorithm 3 are as follows:
| Algorithm 2 ClearNonSPIP |
- 1:
Input: : Set, X: Itemset - 2:
Output: : Set - 3:
for each Y∈do - 4:
if Y is dominated by X then - 5:
← - 6:
end if - 7:
end for - 8:
return
|
| Algorithm 3 CheckSPIP |
- 1:
Input: : Bitset, : Bitset, : Double, : Set, : Set - 2:
Output: : List - 3:
the period list of X - 4:
the coefficient of variation of X - 5:
if then - 6:
return , - 7:
end if - 8:
- 9:
if then - 10:
, - 11:
← - 12:
else - 13:
if then - 14:
- 15:
else if then - 16:
- 17:
else if s.t. Y dominates X then - 18:
return , - 19:
end if - 20:
←call Algorithm 2 (, X) - 21:
← - 22:
end if - 23:
return ,
|
- (1)
With , by Definitions 5 and 6, and are acquired (lines 3 to 4), respectively.
- (2)
If , by Definition 7, X is not a PIP, and the algorithm terminates (line 6). Otherwise, X is added to (line 8).
- (3)
If and , by Definition 7, X dominates all itemsets in . Therefore, X is the only element in ; the value of and the value of are updated with and , respectively (lines 9 to 11).
- (4)
If and , or, and , X may dominate some itemsets in and none of the itemsets in can dominate X. contains X and the itemsets that are not dominated by X. Specifically, in the former case, the value of is updated with , and in the latter case, the value of is updated with (lines 13 to 16 and lines 20 to 21).
- (5)
If and , X may be dominated by some itemsets in . If any itemset dominates X (line 17), X is not an SPIP and the identification of X stops (line 18), X is not in . Otherwise, contains X and the itemsets that are not dominated by X (lines 20 to 21).
In Algorithm 3, as Algorithm 2 is invoked and is utilized, the worst-case time complexity of Algorithm 3 is (), where represents the maximal number of itemsets in .
4.3.2. First Iteration
The aim of first iteration is to generate bitsets for frequent 1-itemsets and identify SPIPs of size 1 (if any). Algorithm 4 illustrates the process of first iteration.
I is the set of items in the transaction dataset. To guarantee the ≻ relation between any two bitsets in the ItemsetLists, the items in
I are in ascending order. Initially, the values of
and
are set to 0 and
∞, respectively (line 3).
,
, and
are empty (line 4). For each item
i in
I, all bits in
are
Cleared except that the
ith bit is set to
1 (lines 6 to 7). Then, by Algorithm 1,
is formulated on line 8. As
contains one
1 bit, the process of lines 5 to 9 in Algorithm 1 is omitted.
is computed by Definition 4 (line 9). If
is not less than the frequency threshold
,
is an FP and
is added to the end of
(line 11). Algorithm 3 is then invoked to identify whether
is an SPIP, as discussed in
Section 4.3.1.
| Algorithm 4 First iteration |
- 1:
Input: I: Set, : Double, : Double - 2:
Output: - 3:
= 0, = ∞ - 4:
← an empty List, ←∅, ←∅ - 5:
for each i∈I do - 6:
an empty Bitset - 7:
Set - 8:
call Algorithm 1() - 9:
- 10:
if then - 11:
Add to the end of - 12:
call Algorithm 3 (, , , , ) - 13:
end if - 14:
end for - 15:
return
|
When Algorithm 4 stops, all infrequent 1-itemsets are eradicated and will not be involved in the subsequent iterations. becomes the input to the second iteration. In Algorithm 4, Algorithms 1 and 3 are invoked for each item i in I. Thus, the worst time complexity of Algorithm 4 is ( * ( + )).
An illustration of first iteration is provided for mining SPIPs in the
dataset, as shown in
Table 2, with a frequency threshold
= 0.4 and the coefficient of variation threshold
=
∞.
Table 6 shows the frequencies and the coefficients of variation for all eight 1-itemsets in
, denoted by
to
.
On line 5 of Algorithm 4, the items in I are in ascending order, the bitsets for all 1-itemsets, to , are sequentially processed by Algorithm 4. As the threshold of the coefficient of variation is set to ∞, the coefficients of variation for all 1-itemsets are not larger than ∞. Consequently, lines 5 to 7 of Algorithm 3 are skipped. Initially, for , as = 0 and = ∞, {1} is added to , = 0.583 and = 0.447. As = and = , lines 17 to 21 of Algorithm 3 are used to process {2}; {2} can also be added to as does not dominate . and remain invariant. As < and > , lines 9 to 11 of Algorithm 3 are used to process {3}; {3} dominates {1} and {2} and is added to while {1} and {2} are removed from . = 0.667 and = 0.351. As > and > , lines 15 to 16 and 20 to 21 of Algorithm 3 are used to process {4}; {3} stays in as it is not dominated by {4}. After {4} is processed, contains {3} and {4}, = 0.667 and = 0.2. As is less than the frequency threshold, {5} is not an SPIP as it is not an FP (line 10 of Algorithm 4). For itemsets {6} to {8}, their frequencies are less than . Moreover, they can be dominated by some itemsets in (line 17 of Algorithm 3). At the end of 1st iteration, {3} and {4} are two SPIPs. According to lines 10 to 11 of Algorithm 4, contains the bitsets for {1} to {8} except {5}, as the frequency of {5} is less than . is then used as the input to the second iteration.
4.3.3. kth Iteration (k > 1)
As shown in Algorithm 5, in kth iteration, SPIPs of size k are obtained, and frequent -itemsets are generated and used as the input to th iteration. kth iteration activates as covers the bitsets for all frequent -itemsets. The procedures of Algorithm 5 are as follows:
- (1)
When is not empty, Algorithm 5 runs iteratively (line 3).
- (2)
is set to empty (line 4).
- (3)
For each in , is preliminarily constructed (line 6). According to Definition 14, is equal to while the last 1 bit is substituted by 0 (lines 7 to 8).
- (4)
To generate new -itemsets, for each after in , if differentiates from , all bitsets after have a different prefix compared to that of , according to Theorem 1; thus, no bitset can be combined with . Therefore, none of the bitsets after will be further processed while determining which bitsets can be merged with (line 11). Otherwise, X and Y can be merged as they share an identical prefix. This approach of limiting the traversal of bitsets avoids extensive, pointless searches on itemsets that are inevitably unable to be merged.
- (5)
When processes an identical prefix, the last bit that indicates the tail is the only discrepancy between them. The combination of and focuses on the last 1-bit rather than trivially performing a bitwise “|” operation on and . A new bitset is constructed for the -itemset, which initially equals (line 13).
- (6)
The th bit in is set to 1 (line 14).
- (7)
Resembles 1st iteration, is calculated by Algorithm 1 and Definition 4 (lines 15 and 16).
- (8)
If is greater than or equal to the frequency threshold, is added to the end of (line 18).
- (9)
With and , Algorithm 3 is invoked to examine whether itemset N is an SPIP (line 19).
- (10)
While covers the bitsets for all -itemsets, the bitsets in are transferred to (line 23). This step declares both the end of kth iteration and the beginning of th iteration.
| Algorithm 5 kth iteration (k > 1) |
- 1:
Input: : List, : Double, : Double - 2:
Output: : List : Set, : Set - 3:
while is not an empty List do - 4:
← an Empty List - 5:
for each ∈ do - 6:
- 7:
← the tail of X - 8:
Clear - 9:
for each ∈ and do - 10:
if ≠ then - 11:
- 12:
end if - 13:
- 14:
Set - 15:
call Algorithm 1() - 16:
- 17:
if then - 18:
Add to the end of - 19:
call Algorithm 3 (, , , , ) - 20:
end if - 21:
end for - 22:
end for - 23:
- 24:
end while - 25:
return , ,
|
When is an empty list, no frequent -itemset is generated in kth iteration, th iteration will not proceed, and the algorithm terminates; all SPIPs are identified.
Suppose is the maximal number of bitsets in , the worst time complexity of an arbitrary kth iteration is ( * ( + )).
We provide an illustration of 2nd iteration for mining SPIPs in the
dataset, as shown in
Table 2 with a frequency threshold
= 0.4 and the coefficient of variation threshold
=
∞.
contains the bitset for
,
,
,
,
,
, and
. Algorithm 3 only checks if
=
and
=
are SPIPs, as among all the 2-itemsets, only
and
are FPs with a frequency beyond
. For simplicity,
Table 7 merely gives the frequency and the coefficient of variation of
and
in
Table 2.
At the beginning of 2nd iteration, = 0.667 and = 0.2. As < and = , lines 17 to 21 of Algorithm 3 are used to process . Neither nor dominates and cannot dominate or ; thus. , , and = are SPIPs. and remain invariant. Similarly, for = , as and > , is dominated by ; thus, it is not an SPIP. At the end of 2nd iteration, contains three SPIPs: {3}, {4}, and {1, 2}. contains two bitsets for and , which are used as the inputs of 3rd iteration.
In 3rd iteration, only a bitset for a 3-itemset
=
can be merged. As
is not an FP,
is an empty list at the end of 3rd iteration (line 4 and line 23 of Algorithm 5). 4th iteration starts with an empty
, the algorithm terminates as 4th iteration stops (line 3 of Algorithm 5), and the final SPIPs in
Table 2 with
= 40% and
=
∞ are
,
and
.
5. Empirical Evaluation
We conducted a series of experiments to compare the performances of BitSPIM and SPIM on a Windows 10 PC equipped with an AMD Ryzen 3950X processor, with 64 GB of memory. The CPU clock speed is locked to 3.5 GHz to avoid the adverse effects of CPU overclocking. The characteristics of the datasets involved in our experiments are presented in
Table 8, including four synthetic datasets and six real datasets. All datasets in the experiments are downloaded from the website SPMF (
http://www.philippe-fournier-viger.com/spmf, accessed on 1 September 2023).
As SPIM [
20] is the state-of-the-art and the only algorithm focusing on mining SPIPs, we primarily compare the running time and memory usage between our approach and SPIM. All datasets used in SPIM are included in our experiments. Additionally, as FP-Growth is a fundamental component of SPIM, the running time of FP-Growth is also considered to further explore the effectiveness of BitSPIM. For simplicity, all
in our experiment are set to
∞, which implies that all frequent patterns are also periodic itemset patterns. In the first experiment, the numbers of PIPs and SPIPs identified by both algorithms were recorded. The second experiment focuses on the running time of BitSPIM, SPIM, and FP-Growth. Finally, we compare the performance in terms of memory usage between BitSPIM and SPIM.
5.1. Number of Patterns
To verify that the SPIPs obtained by the proposed method are complete and correct, we counted the number of PIPs and SPIPs obtained by BitSPIM and SPIM. The results show that, on all datasets involved in the experiment, the PIP and SPIP numbers mined by BitSPIM are always consistent with those obtained by SPIM for various values , verifying the correctness of the proposed method.
5.2. Running Time
The running time of BitSPIM is compared with that of SPIM and FP-Growth. In SPIM, FPs are identified in advance using FP-Growth before the recognition of SPIPs; thus, the running time of FP-Growth can be recorded.
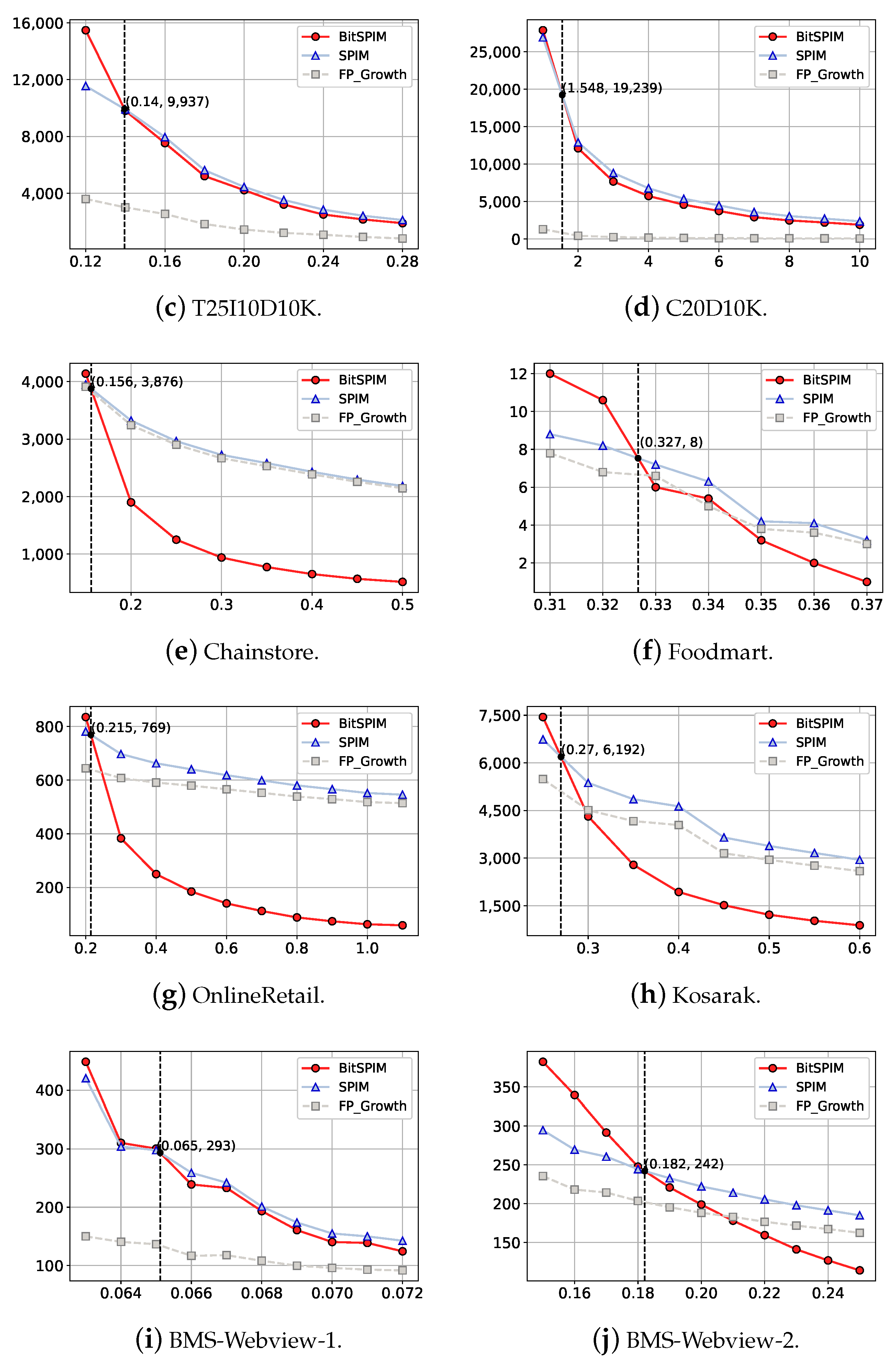
Figure 6 demonstrates the running times of BitSPIM, SPIM, and FP-Growth on different datasets with various frequency thresholds
when
=
∞. In each subfigure representing the running time on different datasets, the range of
includes the approximate frequency threshold value, where BitSPIM and SPIM have the same running times. The horizontal axis indicates the value of
, and the vertical axis represents the running time. The red curve, blue curve, and gray curve indicate the running times of BitSPIM, SPIM, and FP-Growth, respectively. The circles on the red curve, the triangles on the blue curve, and the squares on the gray curve represent the running times of our method and that of SPIM and FP-Growth on the specific
, respectively. The intersection points of the red and blue curves mean the running times of BitSPIM and SPIM are identical. This is projected on the horizontal axis by a dotted line parallel to the vertical axis. The horizontal coordinate of the intersection point indicates the frequency threshold at which the two algorithms have the same running time.
As shown in
Figure 6, except at the smaller thresholds, BitSPIM outpaces SPIM in terms of running time across most of the threshold ranges. The curve of the running time for BitSPIM is steeper than that of SPIM. Observing the gradient of the running time curve, as
increases, once
goes beyond the horizontal coordinate of the intersection point of BitSPIM’s curve and SPIM’s curve, the running time of BitSPIM is consistently less than that of SPIM. For example, as shown in
Figure 6g, the horizontal coordinate of the intersection point is 0.215% on the OnlineRetail dataset. It can be concluded that BitSPIM runs faster than SPIM at 99.785% of the threshold range.
The improvement achieved by BitSPIM over SPIM with respect to running time is significant on datasets T20I6D100K, Chainstore, OnlineRetail, and Kosarak. For example, on the T20I6D100K dataset, when the frequency threshold is 0.3%, BitSPIM is approximately 2 times faster than SPIM. For frequency thresholds beyond 0.6%, SPIM takes at least 4 times longer than BitSPIM. On datasets T25I10D10K, C20D10K, Foodmart, and BMS-Webview-1, although the improvement is not as pronounced, BitSPIM still shows an advantage over SPIM on the majority of frequency thresholds. Since BitSPIM utilizes the basic idea of Apriori, it is acknowledged that BitSPIM can be outpaced by SPIM at small frequency thresholds. In fact, the experimental results support the conclusion of [
33] that no algorithm is an absolute and clear winner, able to outperform all others across all datasets and the entire range of thresholds. Overall, BitSPIM is observed to require less running time compared with SPIM for the majority of frequency thresholds
Mining FPs is fundamental to the identification of SPIPs. SPIM identifies SPIPs from all FPs mined by FP-Growth, and as a result, SPIM naturally takes longer to run than FP-Growth. However, BitSPIM does not adopt separate steps to mine FPs and can demonstrate better performance compared with FP-Growth. On datasets like T20I6D100K, Chainstore, OnlineRetail, and Kosarak, BitSPIM runs faster than FP-Growth for the majority of frequency thresholds. Although on datasets such as T10I4D100K, Foodmart, and BMS-Webview-2, BitSPIM does not show much superiority over FP-Growth, it can still be observed that there is an intersection between the red curve and gray curve, representing the running times of BitSPIM and FP-Growth, respectively. This indicates that BitSPIM can outperform FP-Growth at some frequency thresholds. The comparison between the running times of BitSPIM and FP-Growth further demonstrates the superior performance of our approach over SPIM.
5.3. Memory Usage
The results comparing the average memory usage of BitSPIM and SPIM with different frequency thresholds
on empirical datasets are presented in
Table 9. The better results are highlighted in bold. The coefficient of variance threshold
is set to
∞ and the same range of frequency thresholds as in the running time experiment are adopted. As shown in
Table 9, except on datasets with a large number of transactions and items, such as Chainstore and Kosarak, BitSPIM outperforms SPIM in terms of average memory usage.
5.4. Discussion
From the results, the proposed method shows better performance, as it consumes less time compared with SPIM for the vast majority of frequency threshold values across different datasets. Regarding memory usage, BitSPIM generally consumes less memory than SPIM, except on datasets with an extensive number of transactions and items.
The advantages of the proposed method can be summarized as follows: (1) The bitset representation of the transaction dataset is more compact than the original dataset. (2) Bitwise operations are involved in mining SPIPs by mapping ordinary sets to bitsets. The generation of new itemsets and the calculation of their frequency can be realized by performing efficient bitwise operations. (3) A novel cutting technique avoids many unnecessary operations. When certain conditions are met, the loop stops without exploring the entire search space. (4) The off-the-shelf occurrence set of the itemset can be utilized directly when identifying whether an FP is an SPIP. (5) Space for constructing FP-trees is saved as FP-Growth is not used in identifying FPs.
However, due to the inherent drawbacks originating from Apriori, BitSPIM repeatedly scans the dataset to generate new bitsets and calculate the frequency of the itemsets. This leads to higher time consumption at smaller thresholds. On datasets with numerous transactions and items, a large number of bitsets need to be stored and operated in BitSPIM; thus, in such cases, it is outperformed by SPIM in terms of memory usage.




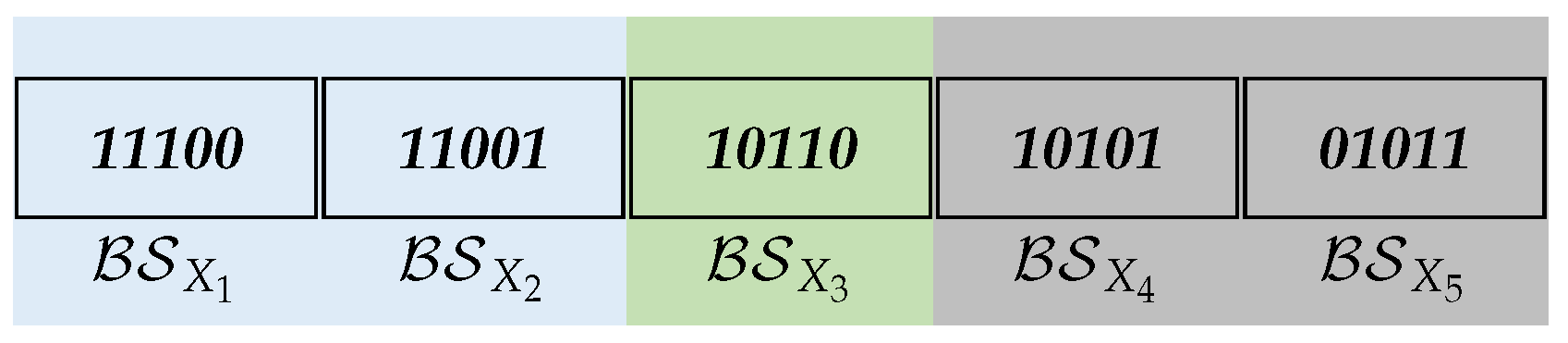


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}