
Application of a 3D Talking Head as Part of Telecommunication AR, VR, MR System: Systematic Review




Abstract
:1. Introduction
1.1. Research Motivations
1.2. Research Contribution
- We prepare a deep and extensive analysis of current research approaches for audio-driven 3D head generation. We show that some of these techniques can be used in the proposed architecture;
- We propose general evaluation criteria for 3D talking head algorithms in terms of their Shared Virtual Environment application.
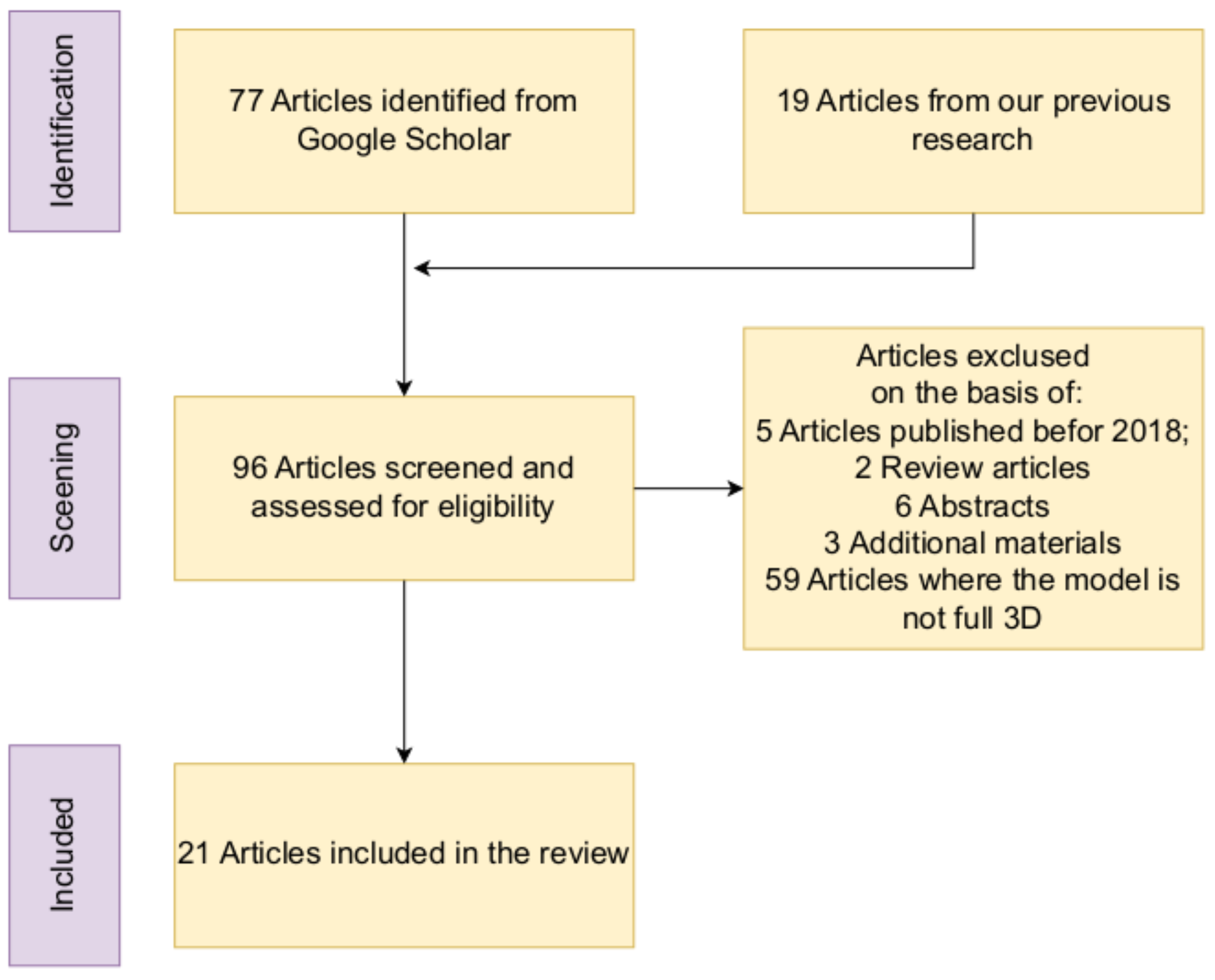
1.3. Literature Review and Survey Methodology
1.4. Paper Structure
2. Talking Head Animation in Shared Virtual Environments
2.1. An Overview of Talking Head Animation
2.2. Conceptualization of Shared Virtual Environments and Their Applications
- Characteristics of Virtual, Augmented and Mixed Realities
- Introduction in Shared Virtual Environments
- Shared Virtual Environments in VR, AR, and MR Applications
2.3. Aspects on Usability of Talking Head Animation in SVE
- Scenario 1:
- Implies the real-time 3D model of the talking head and the audio information are simultaneously generated and processed. This approach enables dynamic and coordinated communication, improving the user experience.
- Scenario 2:
- Involves the real-time generation of the 3D model of the talking head while the audio information is processed offline. While the visual component benefits from the dynamics, there can be potential challenges in synchronizing with the audio.
- Scenario 3:
- The 3D model of the talking head is generated offline, followed by real-time processing of the audio input. This scenario ensures synchronization in the audio, although the visual representation may lack real-time dynamics.
- Scenario 4:
- Involves offline generation of the 3D model and audio information. While real-time dynamics may be limited, it allows for the combination of pre-designed elements. This scenario has been implemented by multiple authors.
2.4. Criteria for Usability of 3D Talking Head Animation in Shared Virtual Environments
2.4.1. Aspects Related to Talking Head Evaluation
2.4.2. 3D Talking Head Algorithm Criteria for VR/AR/MR/Telepresence Application
- Key Considerations as a Justification of the Criteria
- Effective Implementation Under Different SVEs: User-centered Evaluation
3. Assessment at 3D Talking Head Algorithms in SVE
3.1. Realism Implementation
3.2. Covered Criteria for Talking Head Implementation
3.3. Seamless Integration within SVE
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three-dimensional |
| AI | Artificial Intelligence |
| AR | Augmented Reality |
| AV | Augmented Virtuality |
| CAVE | Cave Automated Virtual Environment |
| CNN | Convolutional Neural Network |
| Com. res | Computational resource |
| CVEs | Collaborative Virtual Environments |
| DLNN | Deep Learning Neural Network |
| DVEs | Digital Virtual Environments |
| GAN | Generative Adversarial Network |
| LSTM | Long-Short Term Memory |
| MLP | Multi-layer Perceptron |
| MR | Mixed Reality |
| NeRF | Neural Radiance Fields |
| NN | Neural Network |
| Oper. eff. within the actual PoNC | Operates effectively within the actual physical or natural context |
| PRISMA | Preferred Reporting Items for Systematic Reviews |
| and Meta-Analyses | |
| SVEs | Shared Virtual Environments |
| SVSs | Shared Virtual Spaces |
| VE | Virtual Environment |
| VR | Virtual Reality |
| XR | Extended Reality |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | AR | MR | VR | Telepresence |
|---|---|---|---|---|
| Karras et al. [106], 2018 | 70 | 70 | 20 | 50 |
| Zhou et al. [101], 2018 | 30 | 30 | 30 | 75 |
| Cudeiro et al. [59], 2019 | 30 | 46.7 | 30 | 75 |
| Tzirakis et al. [107], 2019 | 50 | 66.7 | 50 | 100 |
| Liu et al. [103], 2020 | 20 | 20 | 20 | 50 |
| Zhang et al. [57], 2021 | 75 | 66.7 | 50 | 100 |
| Wang et al. [108], 2021 | 40 | 56.7 | 40 | 100 |
| Richard et al. [63], 2021 | 40 | 56.7 | 40 | 100 |
| Fan et al. [58], 2022 | 50 | 66.7 | 50 | 100 |
| Li et al. [60], 2022 | 40 | 56.7 | 40 | 100 |
| Yang et al. [109], 2022 | 50 | 66.7 | 50 | 100 |
| Fan et al. [61], 2022 | 20 | 36.7 | 20 | 50 |
| Peng et al. [102], 2023 | 40 | 40 | 40 | 75 |
| Xing et al. [110], 2023 | 30 | 30 | 30 | 75 |
| Haque and Yumak [62], 2023 | 30 | 46.7 | 30 | 100 |
| Yi et al. [111], 2023 | 50 | 66,7 | 50 | 100 |
| Bao et al. [112], 2023 | 40 | 40 | 40 | 100 |
| Nocentini et al. [113], 2023 | 30 | 30 | 30 | 75 |
| Wu et al. [114], 2023 | 50 | 50 | 50 | 100 |
| Ma et al. [115], 2023 | 50 | 50 | 50 | 100 |
| Liu et al. [116], 2023 | 40 | 56.7 | 40 | 100 |
References
- Ratcliffe, J.; Soave, F.; Bryan-Kinns, N.; Tokarchuk, L.; Farkhatdinov, I. Extended reality (XR) remote research: A survey of drawbacks and opportunities. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online, 8–13 May 2021; pp. 1–13. [Google Scholar]
- Maloney, D.; Freeman, G.; Wohn, D.Y. “Talking without a Voice” Understanding Non-verbal Communication in Social Virtual Reality. Proc. ACM Hum.-Comput. Interact. 2020, 4, 175. [Google Scholar] [CrossRef]
- Reiners, D.; Davahli, M.R.; Karwowski, W.; Cruz-Neira, C. The combination of artificial intelligence and extended reality: A systematic review. Front. Virtual Real. 2021, 2, 721933. [Google Scholar] [CrossRef]
- Zhang, Z.; Wen, F.; Sun, Z.; Guo, X.; He, T.; Lee, C. Artificial intelligence-enabled sensing technologies in the 5G/internet of things era: From virtual reality/augmented reality to the digital twin. Adv. Intell. Syst. 2022, 4, 2100228. [Google Scholar] [CrossRef]
- Chamola, V.; Bansal, G.; Das, T.K.; Hassija, V.; Reddy, N.S.S.; Wang, J.; Zeadally, S.; Hussain, A.; Yu, F.R.; Guizani, M.; et al. Beyond Reality: The Pivotal Role of Generative AI in the Metaverse. arXiv 2023, arXiv:2308.06272. [Google Scholar]
- Wiles, O.; Koepke, A.; Zisserman, A. X2face: A network for controlling face generation using images, audio, and pose codes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 670–686. [Google Scholar]
- Yu, L.; Yu, J.; Ling, Q. Mining audio, text and visual information for talking face generation. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 787–795. [Google Scholar]
- Vougioukas, K.; Petridis, S.; Pantic, M. Realistic speech-driven facial animation with GANs. Int. J. Comput. Vis. 2020, 128, 1398–1413. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9299–9306. [Google Scholar]
- Jamaludin, A.; Chung, J.S.; Zisserman, A. You said that?: Synthesising talking faces from audio. Int. J. Comput. Vis. 2019, 127, 1767–1779. [Google Scholar] [CrossRef]
- Yi, R.; Ye, Z.; Zhang, J.; Bao, H.; Liu, Y.-J. Audio-driven talking face video generation with learning-based personalized head pose. arXiv 2020, arXiv:2002.10137. [Google Scholar]
- Wang, K.; Wu, Q.; Song, L.; Yang, Z.; Wu, W.; Qian, C.; He, R.; Qiao, Y.; Loy, C.C. Mead: A large-scale audio-visual dataset for emotional talking-face generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 700–717. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Cham, Switzerland; pp. 716–731. [Google Scholar]
- Guo, Y.; Chen, K.; Liang, S.; Liu, Y.; Bao, H.; Zhang, J. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5784–5794. [Google Scholar]
- Zhou, H.; Sun, Y.; Wu, W.; Loy, C.C.; Wang, X.; Liu, Z. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4176–4186. [Google Scholar]
- Ji, X.; Zhou, H.; Wang, K.; Wu, Q.; Wu, W.; Xu, F.; Cao, X. Eamm: One-shot emotional talking face via audio-based emotion-aware motion model. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; ACM: New York, NY, USA, 2022; pp. 1–10. [Google Scholar]
- Liang, B.; Pan, Y.; Guo, Z.; Zhou, H.; Hong, Z.; Han, X.; Han, J.; Liu, J.; Ding, E.; Wang, J. Expressive talking head generation with granular audio-visual control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3387–3396. [Google Scholar]
- Zeng, B.; Liu, B.; Li, H.; Liu, X.; Liu, J.; Chen, D.; Peng, W.; Zhang, B. FNeVR: Neural volume rendering for face animation. Adv. Neural Inf. Process. Syst. 2022, 35, 22451–22462. [Google Scholar]
- Zheng, Y.; Abrevaya, V.F.; Bühler, M.C.; Chen, X.; Black, M.J.; Hilliges, O. Im avatar: Implicit morphable head avatars from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13545–13555. [Google Scholar]
- Tang, A.; He, T.; Tan, X.; Ling, J.; Li, R.; Zhao, S.; Song, L.; Bian, J. Memories are one-to-many mapping alleviators in talking face generation. arXiv 2022, arXiv:2212.05005. [Google Scholar]
- Yin, Y.; Ghasedi, K.; Wu, H.; Yang, J.; Tong, X.; Fu, Y. NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 8539–8548. [Google Scholar]
- Alghamdi, M.M.; Wang, H.; Bulpitt, A.J.; Hogg, D.C. Talking Head from Speech Audio using a Pre-trained Image Generator. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; ACM: New York, NY, USA, 2022; pp. 5228–5236. [Google Scholar]
- Du, C.; Chen, Q.; He, T.; Tan, X.; Chen, X.; Yu, K.; Zhao, S.; Bian, J. DAE-Talker: High Fidelity Speech-Driven Talking Face Generation with Diffusion Autoencoder. arXiv 2023, arXiv:2303.17550. [Google Scholar]
- Shen, S.; Zhao, W.; Meng, Z.; Li, W.; Zhu, Z.; Zhou, J.; Lu, J. DiffTalk: Crafting Diffusion Models for Generalized Audio-Driven Portraits Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 1982–1991. [Google Scholar]
- Ye, Z.; Jiang, Z.; Ren, Y.; Liu, J.; He, J.; Zhao, Z. Geneface: Generalized and high-fidelity audio-driven 3D talking face synthesis. arXiv 2023, arXiv:2301.13430. [Google Scholar]
- Ye, Z.; He, J.; Jiang, Z.; Huang, R.; Huang, J.; Liu, J.; Ren, Y.; Yin, X.; Ma, Z.; Zhao, Z. GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation. arXiv 2023, arXiv:2305.00787. [Google Scholar]
- Xu, C.; Zhu, J.; Zhang, J.; Han, Y.; Chu, W.; Tai, Y.; Wang, C.; Xie, Z.; Liu, Y. High-fidelity generalized emotional talking face generation with multi-modal emotion space learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 6609–6619. [Google Scholar]
- Zhong, W.; Fang, C.; Cai, Y.; Wei, P.; Zhao, G.; Lin, L.; Li, G. Identity-Preserving Talking Face Generation with Landmark and Appearance Priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 9729–9738. [Google Scholar]
- Liu, P.; Deng, W.; Li, H.; Wang, J.; Zheng, Y.; Ding, Y.; Guo, X.; Zeng, M. MusicFace: Music-driven Expressive Singing Face Synthesis. arXiv 2023, arXiv:2303.14044. [Google Scholar]
- Wang, D.; Deng, Y.; Yin, Z.; Shum, H.-Y.; Wang, B. Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17979–17989. [Google Scholar]
- Zhang, W.; Cun, X.; Wang, X.; Zhang, Y.; Shen, X.; Guo, Y.; Shan, Y.; Wang, F. SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; IEEE: New York, NY, USA, 2023; pp. 8652–8661. [Google Scholar]
- Tang, J.; Wang, K.; Zhou, H.; Chen, X.; He, D.; Hu, T.; Liu, J.; Zeng, G.; Wang, J. Real-time neural radiance talking portrait synthesis via audio-spatial decomposition. arXiv 2022, arXiv:2211.12368. [Google Scholar]
- Suwajanakorn, S.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Synthesizing Obama: Learning lip sync from audio. ACM Trans. Graph. (ToG) 2017, 36, 95. [Google Scholar] [CrossRef]
- Fried, O.; Tewari, A.; Zollhöfer, M.; Finkelstein, A.; Shechtman, E.; Goldman, D.B.; Genova, K.; Jin, Z.; Theobalt, C.; Agrawala, M. Text-based editing of talking-head video. ACM Trans. Graph. (TOG) 2019, 38, 68. [Google Scholar] [CrossRef]
- Gafni, G.; Thies, J.; Zollhofer, M.; Nießner, M. Dynamic neural radiance fields for monocular 4D facial avatar reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8649–8658. [Google Scholar]
- Zhang, Z.; Li, L.; Ding, Y.; Fan, C. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3661–3670. [Google Scholar]
- Wu, H.; Jia, J.; Wang, H.; Dou, Y.; Duan, C.; Deng, Q. Imitating arbitrary talking style for realistic audio-driven talking face synthesis. In Proceedings of the 29th ACM International Conference on Multimedia, Online, 20–24 October 2021; pp. 1478–1486. [Google Scholar]
- Habibie, I.; Xu, W.; Mehta, D.; Liu, L.; Seidel, H.-P.; Pons-Moll, G.; Elgharib, M.; Theobalt, C. Learning speech-driven 3D conversational gestures from video. In Proceedings of the 21st ACM International Conference on Intelligent Virtual Agents, Online, 14–17 September 2021; pp. 101–108. [Google Scholar]
- Lahiri, A.; Kwatra, V.; Frueh, C.; Lewis, J.; Bregler, C. Lipsync3d: Data-efficient learning of personalized 3D talking faces from video using pose and lighting normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2755–2764. [Google Scholar]
- Tang, J.; Zhang, B.; Yang, B.; Zhang, T.; Chen, D.; Ma, L.; Wen, F. Explicitly controllable 3D-aware portrait generation. arXiv 2022, arXiv:2209.05434. [Google Scholar] [CrossRef] [PubMed]
- Khakhulin, T.; Sklyarova, V.; Lempitsky, V.; Zakharov, E. Realistic one-shot mesh-based head avatars. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 345–362. [Google Scholar]
- Liu, X.; Xu, Y.; Wu, Q.; Zhou, H.; Wu, W.; Zhou, B. Semantic-aware implicit neural audio-driven video portrait generation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23-27 October 2022; Springer: Cham, Switzerland, 2022; pp. 106–125. [Google Scholar]
- Chatziagapi, A.; Samaras, D. AVFace: Towards Detailed Audio-Visual 4D Face Reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16878–16889. [Google Scholar]
- Wang, J.; Zhao, K.; Zhang, S.; Zhang, Y.; Shen, Y.; Zhao, D.; Zhou, J. LipFormer: High-Fidelity and Generalizable Talking Face Generation With a Pre-Learned Facial Codebook. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13844–13853. [Google Scholar]
- Xu, C.; Zhu, S.; Zhu, J.; Huang, T.; Zhang, J.; Tai, Y.; Liu, Y. Multimodal-driven Talking Face Generation via a Unified Diffusion-based Generator. CoRR 2023, 2023, 1–4. [Google Scholar]
- Li, W.; Zhang, L.; Wang, D.; Zhao, B.; Wang, Z.; Chen, M.; Zhang, B.; Wang, Z.; Bo, L.; Li, X. One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 17969–17978. [Google Scholar]
- Huang, R.; Lai, P.; Qin, Y.; Li, G. Parametric implicit face representation for audio-driven facial reenactment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12759–12768. [Google Scholar]
- Saunders, J.; Namboodiri, V. READ Avatars: Realistic Emotion-controllable Audio Driven Avatars. arXiv 2023, arXiv:2303.00744. [Google Scholar]
- Ma, Y.; Wang, S.; Hu, Z.; Fan, C.; Lv, T.; Ding, Y.; Deng, Z.; Yu, X. Styletalk: One-shot talking head generation with controllable speaking styles. arXiv 2023, arXiv:2301.01081. [Google Scholar] [CrossRef]
- Jang, Y.; Rho, K.; Woo, J.; Lee, H.; Park, J.; Lim, Y.; Kim, B.; Chung, J. That’s What I Said: Fully-Controllable Talking Face Generation. arXiv 2023, arXiv:2304.03275. [Google Scholar]
- Song, L.; Wu, W.; Qian, C.; He, R.; Loy, C.C. Everybody’s talkin’: Let me talk as you want. IEEE Trans. Inf. Forensics Secur. 2022, 17, 585–598. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, J.; Zhang, W.Q. Expressive Speech-driven Facial Animation with Controllable Emotions. arXiv 2023, arXiv:2301.02008. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering–a systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Burden, D.; Savin-Baden, M. Virtual Humans: Today and Tomorrow; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Christoff, N.; Tonchev, K.; Neshov, N.; Manolova, A.; Poulkov, V. Audio-Driven 3D Talking Face for Realistic Holographic Mixed-Reality Telepresence. In Proceedings of the 2023 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Istanbul, Turkey, 4–7 July 2023; pp. 220–225. [Google Scholar]
- Zhang, C.; Ni, S.; Fan, Z.; Li, H.; Zeng, M.; Budagavi, M.; Guo, X. 3D talking face with personalized pose dynamics. IEEE Trans. Vis. Comput. Graph. 2021, 29, 1438–1449. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Lin, Z.; Saito, J.; Wang, W.; Komura, T. Joint audio-text model for expressive speech-driven 3D facial animation. Proc. ACM Comput. Graph. Interact. Tech. 2022, 5, 16. [Google Scholar] [CrossRef]
- Cudeiro, D.; Bolkart, T.; Laidlaw, C.; Ranjan, A.; Black, M.J. Capture, learning, and synthesis of 3D speaking styles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10101–10111. [Google Scholar]
- Li, X.; Wang, X.; Wang, K.; Lian, S. A novel speech-driven lip-sync model with CNN and LSTM. In Proceedings of the IEEE 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Taizhou, China, 28–30 October 2021; pp. 1–6. [Google Scholar]
- Fan, Y.; Lin, Z.; Saito, J.; Wang, W.; Komura, T. Faceformer: Speech-driven 3D facial animation with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18770–18780. [Google Scholar]
- Haque, K.I.; Yumak, Z. FaceXHuBERT: Text-less Speech-driven E (X) pressive 3D Facial Animation Synthesis Using Self-Supervised Speech Representation Learning. arXiv 2023, arXiv:2303.05416. [Google Scholar]
- Richard, A.; Zollhöfer, M.; Wen, Y.; De la Torre, F.; Sheikh, Y. Meshtalk: 3D face animation from speech using cross-modality disentanglement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1173–1182. [Google Scholar]
- Junior, W.C.R.; Pereira, L.T.; Moreno, M.F.; Silva, R.L. Photorealism in low-cost virtual reality devices. In Proceedings of the IEEE 2020 22nd Symposium on Virtual and Augmented Reality (SVR), Porto de Galinhas, Brazil, 7–10 November 2020; pp. 406–412. [Google Scholar]
- Lins, C.; Arruda, E.; Neto, E.; Roberto, R.; Teichrieb, V.; Freitas, D.; Teixeira, J.M. Animar: Augmenting the reality of storyboards and animations. In Proceedings of the IEEE 2014 XVI Symposium on Virtual and Augmented Reality (SVR), Salvador, Brazil, 12–15 May 2014; pp. 106–109. [Google Scholar]
- Sutherland, I.E. Sketchpad: A man-machine graphical communication system. In Proceedings of the Spring Joint Computer Conference, Detroit, MI, USA, 21–23 May 1963; ACM: New York, NY, USA, 1963; pp. 329–346. [Google Scholar]
- Sutherland, I.E. A head-mounted three dimensional display. In Proceedings of the Fall Joint Computer Conference, San Francisco, CA, USA, 9–11 December 1968; Part I. ACM: New York, NY, USA, 1968; pp. 757–764. [Google Scholar]
- Caudell, T. AR at Boeing. 1990; Retrieved 10 July 2002. Available online: http://www.idemployee.id.tue.nl/gwm.rauterberg/presentations/hci-history/sld096.htm (accessed on 2 November 2014).
- Krueger, M.W.; Gionfriddo, T.; Hinrichsen, K. VIDEOPLACE—An artificial reality. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Francisco, CA, USA, 22–27 April 1985; Association for Computing Machinery: New York, NY, USA, 1985; pp. 35–40. [Google Scholar]
- Milgram, P.; Kishino, F. A taxonomy of mixed reality visual displays. IEICE Trans. Inf. Syst. 1994, 77, 1321–1329. [Google Scholar]
- Waters, R.C.; Barrus, J.W. The rise of shared virtual environments. IEEE Spectr. 1997, 34, 20–25. [Google Scholar] [CrossRef]
- Chen, C.; Thomas, L.; Cole, J.; Chennawasin, C. Representing the semantics of virtual spaces. IEEE Multimed. 1999, 6, 54–63. [Google Scholar] [CrossRef]
- Craig, D.L.; Zimring, C. Support for collaborative design reasoning in shared virtual spaces. Autom. Constr. 2002, 11, 249–259. [Google Scholar] [CrossRef]
- Steed, A.; Slater, M.; Sadagic, A.; Bullock, A.; Tromp, J. Leadership and collaboration in shared virtual environments. In Proceedings of the IEEE Virtual Reality (Cat. No. 99CB36316), Houston, TX, USA, 13–17 March 1999; pp. 112–115. [Google Scholar]
- Durlach, N.; Slater, M. Presence in shared virtual environments and virtual togetherness. Presence Teleoperators Virtual Environ. 2000, 9, 214–217. [Google Scholar] [CrossRef]
- Kraut, R.E.; Gergle, D.; Fussell, S.R. The use of visual information in shared visual spaces: Informing the development of virtual co-presence. In Proceedings of the 2002 ACM Conference on Computer Supported Cooperative Work, New Orleans, LA, USA, 16–20 November 2002; pp. 31–40. [Google Scholar]
- Schroeder, R.; Heldal, I.; Tromp, J. The usability of collaborative virtual environments and methods for the analysis of interaction. Presence 2006, 15, 655–667. [Google Scholar] [CrossRef]
- Sedlák, M.; Šašinka, Č.; Stachoň, Z.; Chmelík, J.; Doležal, M. Collaborative and individual learning of geography in immersive virtual reality: An effectiveness study. PLoS ONE 2022, 17 10, e0276267. [Google Scholar] [CrossRef]
- Santos-Torres, A.; Zarraonandia, T.; Díaz, P.; Aedo, I. Comparing visual representations of collaborative map interfaces for immersive virtual environments. IEEE Access 2022, 10, 55136–55150. [Google Scholar] [CrossRef]
- Ens, B.; Bach, B.; Cordeil, M.; Engelke, U.; Serrano, M.; Willett, W.; Prouzeau, A.; Anthes, C.; Büschel, W.; Dunne, C.; et al. Grand challenges in immersive analytics. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; ACM: New York, NY, USA, 2021; pp. 1–17. [Google Scholar]
- Aamir, K.; Samad, S.; Tingting, L.; Ran, Y. Integration of BIM and immersive technologies for AEC: A scientometric-SWOT analysis and critical content review. Buildings 2021, 11, 126. [Google Scholar]
- West, A.; Hubbold, R. System challenges for collaborative virtual environments. In Collaborative Virtual Environments: Digital Places and Spaces for Interaction; Springer: London, UK, 2001; pp. 43–54. [Google Scholar]
- Eswaran, M.; Bahubalendruni, M.R. Challenges and opportunities on AR/VR technologies for manufacturing systems in the context of industry 4.0: A state of the art review. J. Manuf. Syst. 2022, 65, 260–278. [Google Scholar] [CrossRef]
- Koller, A.; Striegnitz, K.; Byron, D.; Cassell, J.; Dale, R.; Moore, J.; Oberlander, J. The first challenge on generating instructions in virtual environments. In Conference of the European Association for Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 328–352. [Google Scholar]
- Uddin, M.; Manickam, S.; Ullah, H.; Obaidat, M.; Dandoush, A. Unveiling the Metaverse: Exploring Emerging Trends, Multifaceted Perspectives, and Future Challenges. IEEE Access 2023, 11, 87087–87103. [Google Scholar] [CrossRef]
- Thalmann, D. Challenges for the research in virtual humans. In Proceedings of the AGENTS 2000 (No. CONF), Barcelona, Spain, 3–7 June 2000. [Google Scholar]
- Malik, A.A.; Brem, A. Digital twins for collaborative robots: A case study in human-robot interaction. Robot. Comput. Integr. Manuf. 2021, 68, 102092. [Google Scholar] [CrossRef]
- Slater, M. Grand challenges in virtual environments. Front. Robot. AI 2014, 1, 3. [Google Scholar] [CrossRef]
- Price, S.; Jewitt, C.; Yiannoutsou, N. Conceptualising touch in VR. Virtual Real. 2021, 25, 863–877. [Google Scholar] [CrossRef]
- Muhanna, M.A. Virtual reality and the CAVE: Taxonomy, interaction challenges and research directions. J. King Saud-Univ.-Comput. Inf. Sci. 2015, 27, 344–361. [Google Scholar] [CrossRef]
- González, M.A.; Santos, B.S.N.; Vargas, A.R.; Martín-Gutiérrez, J.; Orihuela, A.R. Virtual worlds. Opportunities and challenges in the 21st century. Procedia Comput. Sci. 2013, 25, 330–337. [Google Scholar] [CrossRef]
- Çöltekin, A.; Lochhead, I.; Madden, M.; Christophe, S.; Devaux, A.; Pettit, C.; Lock, O.; Shukla, S.; Herman, L.; Stachoň, Z.; et al. Extended reality in spatial sciences: A review of research challenges and future directions. ISPRS Int. J. Geo-Inf. 2020, 9, 439. [Google Scholar] [CrossRef]
- Lea, R.; Honda, Y.; Matsuda, K.; Hagsand, O.; Stenius, M. Issues in the design of a scalable shared virtual environment for the internet. In Proceedings of the IEEE Thirtieth Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 1997; Volume 1, pp. 653–662. [Google Scholar]
- Santhosh, S.; De Crescenzio, F.; Vitolo, B. Defining the potential of extended reality tools for implementing co-creation of user oriented products and systems. In Proceedings of the Design Tools and Methods in Industrial Engineering II: Proceedings of the Second International Conference on Design Tools and Methods in Industrial Engineering (ADM 2021), Rome, Italy, 9–10 September 2021; Springer International Publishing: Cham, Switzerland, 2022; pp. 165–174. [Google Scholar]
- Galambos, P.; Weidig, C.; Baranyi, P.; Aurich, J.C.; Hamann, B.; Kreylos, O. Virca net: A case study for collaboration in shared virtual space. In Proceedings of the 2012 IEEE 3rd International Conference on Cognitive Infocommunications (CogInfoCom), Kosice, Slovakia, 2–5 December 2012; pp. 273–277. [Google Scholar]
- Mystakidis, S. Metaverse. Encyclopedia 2022, 2, 486–497. [Google Scholar] [CrossRef]
- Damar, M. Metaverse shape of your life for future: A bibliometric snapshot. J. Metaverse 2021, 1, 1–8. [Google Scholar]
- Tai, T.Y.; Chen, H.H.J. The impact of immersive virtual reality on EFL learners’ listening comprehension. J. Educ. Comput. Res. 2021, 59, 1272–1293. [Google Scholar] [CrossRef]
- Roth, D.; Bente, G.; Kullmann, P.; Mal, D.; Purps, C.F.; Vogeley, K.; Latoschik, M.E. Technologies for social augmentations in user-embodied virtual reality. In Proceedings of the 25th ACM Symposium on Virtual Reality Software and Technology, Parramatta, NSW, Australia, 12–15 November 2019; pp. 1–12. [Google Scholar]
- Yalçın, Ö.N. Empathy framework for embodied conversational agents. Cogn. Syst. Res. 2020, 59, 123–132. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, Z.; Landreth, C.; Kalogerakis, E.; Maji, S.; Singh, K. VisemeNet: Audio-driven animator-centric speech animation. ACM Trans. Graph. (TOG) 2018, 37, 161. [Google Scholar] [CrossRef]
- Peng, Z.; Wu, H.; Song, Z.; Xu, H.; Zhu, X.; Liu, H.; He, J.; Fan, Z. EmoTalk: Speech-driven emotional disentanglement for 3D face animation. arXiv 2023, arXiv:2303.11089. [Google Scholar]
- Liu, J.; Hui, B.; Li, K.; Liu, Y.; Lai, Y.-K.; Zhang, Y.; Liu, Y.; Yang, J. Geometry-guided dense perspective network for speech-driven facial animation. IEEE Trans. Vis. Comput. Graph. 2021, 28, 4873–4886. [Google Scholar] [CrossRef] [PubMed]
- Poulkov, V.; Manolova, A.; Tonchev, K.; Neshov, N.; Christoff, N.; Petkova, R.; Bozhilov, I.; Nedelchev, M.; Tsankova, Y. The HOLOTWIN project: Holographic telepresence combining 3D imaging, haptics, and AI. In Proceedings of the IEEE 2023 Joint International Conference on Digital Arts, Media and Technology with ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (ECTI DAMT & NCON), Phuket, Thailand, 22–25 March 2023; pp. 537–541. [Google Scholar]
- Pan, Y.; Zhang, R.; Cheng, S.; Tan, S.; Ding, Y.; Mitchell, K.; Yang, X. Emotional Voice Puppetry. IEEE Trans. Vis. Comput. Graph. 2023, 29, 2527–2535. [Google Scholar] [CrossRef] [PubMed]
- Karras, T.; Aila, T.; Laine, S.; Herva, A.; Lehtinen, J. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. (TOG) 2018, 36, 94. [Google Scholar] [CrossRef]
- Tzirakis, P.; Papaioannou, A.; Lattas, A.; Tarasiou, M.; Schuller, B.; Zafeiriou, S. Synthesising 3D facial motion from “in-the-wild” speech. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Online, 16–20 November 2020; pp. 265–272. [Google Scholar]
- Wang, Q.; Fan, Z.; Xia, S. 3D-talkemo: Learning to synthesize 3D emotional talking head. arXiv 2021, arXiv:2104.12051. [Google Scholar]
- Yang, D.; Li, R.; Peng, Y.; Huang, X.; Zou, J. 3D head-talk: Speech synthesis 3D head movement face animation. Soft Comput. 2023. [Google Scholar] [CrossRef]
- Xing, J.; Xia, M.; Zhang, Y.; Cun, X.; Wang, J.; Wong, T.-T. Codetalker: Speech-driven 3D Facial Animation with Discrete Motion Prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 12780–12790. [Google Scholar]
- Yi, H.; Liang, H.; Liu, Y.; Cao, Q.; Wen, Y.; Bolkart, T.; Tao, D.; Black, M.J. Generating holistic 3D human motion from speech. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 469–480. [Google Scholar]
- Bao, L.; Zhang, H.; Qian, Y.; Xue, T.; Chen, C.; Zhe, X.; Kang, D. Learning Audio-Driven Viseme Dynamics for 3D Face Animation. arXiv 2023, arXiv:2301.06059. [Google Scholar]
- Nocentini, F.; Ferrari, C.; Berretti, S. Learning Landmarks Motion from Speech for Speaker-Agnostic 3D Talking Heads Generation. arXiv 2023, arXiv:2306.01415. [Google Scholar]
- Wu, H.; Jia, J.; Xing, J.; Xu, H.; Wang, X.; Wang, J. MMFace4D: A Large-Scale Multi-Modal 4D Face Dataset for Audio-Driven 3D Face Animation. arXiv 2023, arXiv:2303.09797. [Google Scholar]
- Ma, Z.; Zhu, X.; Qi, G.; Lei, Z.; Zhang, L. OTAvatar: One-shot Talking Face Avatar with Controllable Tri-plane Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16901–16910. [Google Scholar]
- Liu, B.; Wei, X.; Li, B.; Cao, J.; Lai, Y.K. Pose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention. arXiv 2023, arXiv:2302.12532. [Google Scholar]


| Features | Shared Virtual Environment | Shared Virtual Space |
|---|---|---|
| Focus | Interactive, collaborative environment + user interactions | SVE + Digital representation of the environment |
| Interaction | Real-time interactions between users through avatars and objects | The level of interaction may be restricted or given less attention |
| Realism | Emphasis on realistic avatars, physics, and interactions | Focus on realistic graphics and environmental details |
| Applications | Multiplayer games, collaborative workspaces | 3D art galleries, 360 degree walks |
| Scenario | 3D Model | Audio Information |
|---|---|---|
| 1 | real-time | real-time |
| 2 | real-time | offline |
| 3 | offline | real-time |
| 4 | offline | offline |
| Criteria | AR Applications | MR Applications | VR Applications | Telepresence | |
|---|---|---|---|---|---|
| 1 | Animation flexibility | ✓ | ✓ | ✓ | ✓ |
| 2 | Depth of immersion | ✓ | ✓ | ✓ | ✓ |
| 3 | Enhancement of reality | ✓ | ✓ | ✓ | ✓ |
| 4 | Haptic capabilities | ✓ | |||
| 5 | Interaction with virtual objects | ✓ | ✓ | ✓ | |
| 6 | Integrating digital technologies with physical objects | ✓ | ✓ | ||
| 7 | Navigation process | ✓ | ✓ | ||
| 8 | Operates effectively within the actual physical or natural context | ✓ | |||
| 9 | User presence | ✓ | ✓ | ✓ | ✓ |
| Architecture | Covered Criteria | System-Related Factors | Realism |
|---|---|---|---|
| Karras et al. [106], 2018 | Depth of immersion Integr. digital tech. with PO Navigation process Oper. eff. within the actual PoNC User presence | Com. res.: Theano and Lasagne, and cuDNN for GPU acceleration Feasibility: N/A Latency: N/A | In the context of facial animation. |
| Zhou et al. [101], 2018 | Animation flexibility Depth of immersion Enhancement of reality | Com. res.: TitanX GPU for training Feasibility: N/A Latency: N/A | N/A |
| Cudeiro et al. [59], 2019 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC | Com. res.: N/A Feasibility: N/A Latency: N/A | Realistic audio quality, Correct representation of facial emotions and movements, Realistic 3D models, Spatially suitable positioning of virtual items. |
| Tzirakis et al. [107], 2019 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In the context of synthesizing 3D facial motion from speech. |
| Liu et al. [103], 2020 | Animation flexibility Enhancement of reality | Com. res.: N/A Feasibility: N/A Latency: N/A | By more accurate and reasonable animation results. |
| Zhang et al. [57], 2021 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects Integr. digital tech. with PO User presence | Com. res.: Nvidia GTX 1080 Ti Feasibility: N/A Latency: N/A | Focuses on improving the realism of generated head poses, facial expressions, and overall visual appearance. |
| Wang et al. [108], 2021 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC User presence | Com. res.: a single GPU (GTX2080) Feasibility: N/A Latency: N/A | In terms of emotion transfer, reconstruction accuracy, and user perception. |
| Richard et al. [63], 2021 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In terms of generating highly realistic motion synthesis for the entire face, accurate lip motion, plausible animations of uncorrelated face parts (eye blinks, eyebrow motion). |
| Fan et al. [58], 2022 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In terms of generating expressive facial animations, maintaining lip synchronization with audio, and producing realistic facial muscle movements. |
| Li et al. [60], 2022 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | Including realistic audio quality, correct representation of facial emotions and movements, realistic 3D models, and spatially suitable positioning of virtual items. The true-to-life and natural authenticity of the virtual representation. |
| Yang et al. [109], 2022 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In terms of generating realistic audio-visual content. |
| Fan et al. [61], 2022 | Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC | Com. res.: N/A Feasibility: N/A Latency: N/A | Emphasizing accurate lip synchronization, realistic facial expressions, and natural behavior corresponding to the audio input. |
| Peng et al. [102], 2023 | Animation flexibility Depth of immersion Enhancement of reality User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In terms of generating rich emotional facial expressions and enhancing emotional information. |
| Xing et al. [110], 2023 | Animation flexibility Enhancement of reality User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | N/A |
| Haque and Yumak [62], 2023 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC | Com. res.: N/A Feasibility: N/A Latency: N/A | Expressiveness. |
| Yi et al. [111], 2023 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | In terms of generating realistic facial expressions, coherent poses, and motions that match the speech. |
| Bao et al. [112], 2023 | Animation flexibility Depth of immersion Enhancement of reality User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | N/A |
| Nocentini et al. [113], 2023 | Depth of immersion Enhancement of reality User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | Facial animations that can accurately replicate human speech and facial expressions. |
| Wu et al. [114], 2023 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | Be addressed through the use of synchronized audio and high-resolution 3D mesh sequences. |
| Ma et al. [115], 2023 | Animation flexibility Depth of immersion Enhancement of reality Interaction with virtual objects User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | N/A |
| Liu et al. [116], 2023 | Animation flexibility Depth of immersion Enhancement of reality Oper. eff. within the actual PoNC User presence | Com. res.: N/A Feasibility: N/A Latency: N/A | By realistic facial expressions and head poses consistent with the input audio. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christoff, N.; Neshov, N.N.; Tonchev, K.; Manolova, A. Application of a 3D Talking Head as Part of Telecommunication AR, VR, MR System: Systematic Review. Electronics 2023, 12, 4788. https://doi.org/10.3390/electronics12234788
Christoff N, Neshov NN, Tonchev K, Manolova A. Application of a 3D Talking Head as Part of Telecommunication AR, VR, MR System: Systematic Review. Electronics. 2023; 12(23):4788. https://doi.org/10.3390/electronics12234788
Chicago/Turabian StyleChristoff, Nicole, Nikolay N. Neshov, Krasimir Tonchev, and Agata Manolova. 2023. "Application of a 3D Talking Head as Part of Telecommunication AR, VR, MR System: Systematic Review" Electronics 12, no. 23: 4788. https://doi.org/10.3390/electronics12234788
APA StyleChristoff, N., Neshov, N. N., Tonchev, K., & Manolova, A. (2023). Application of a 3D Talking Head as Part of Telecommunication AR, VR, MR System: Systematic Review. Electronics, 12(23), 4788. https://doi.org/10.3390/electronics12234788