

FLIBD: A Federated Learning-Based IoT Big Data Management Approach for Privacy-Preserving over Apache Spark with FATE

 , ,
, ,  , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Work
2.1. Data Security Encryption in Federated Learning: Relevant Literature and Approaches
2.2. Privacy Threats in Federated Learning
2.3. Privacy and Security in Federated Learning Systems: State-of-the-Art Defensive Mechanisms
2.3.1. Limitations of Current Defensive Mechanisms in Federated Learning
Computational and Communication Overhead
Knowledge Preservation and Incremental Learning
Security and Privacy Concerns
2.4. Problem Statement
- Massive and rapid IoT data: IoT environments are characterised by the generation of immense volumes of data () at an astounding velocity, making effective and efficient data management imperative to prevent systemic bottlenecks and to ensure sustained operational performance.
- Preserving privacy with FL: Ensuring the data ( and ) remain localised and uncompromised during Global Model training in FL demands robust methodologies to prevent leakage or unintended disclosure of sensitive information through model updates ().
- Label-flipping attacks: These attacks, wherein labels of data instances are maliciously altered ( and ), present a pronounced threat to model integrity and efficacy in FL. Here, the design and implementation of defensive mechanisms that can detect, mitigate, or recover from such attacks is of paramount importance.where is the high-level function that seeks to minimise the loss function L given the perturbed data and weight matrix, ensuring the learned model is resilient against the attack.
- Ensuring scalability: Addressing the scale, by ensuring the developed FL model not only counters privacy and security threats, but also scales efficiently to manage and process expansive and diverse IoT Big Data.
- Technological integration and novelty: While FATE offers a promising federated learning framework and Apache Spark offers fast in-memory data processing, exploring and integrating these technologies in an innovative manner that cohesively addresses IoT Big Data management challenges within an FL paradigm becomes crucial.where is aimed at minimising the loss function L concerning the data, the weight matrix , and the model relationship matrix , ensuring a harmonised functionality between the integrated technologies and, also, enabling scalable and efficient data processing and model training across federated nodes.
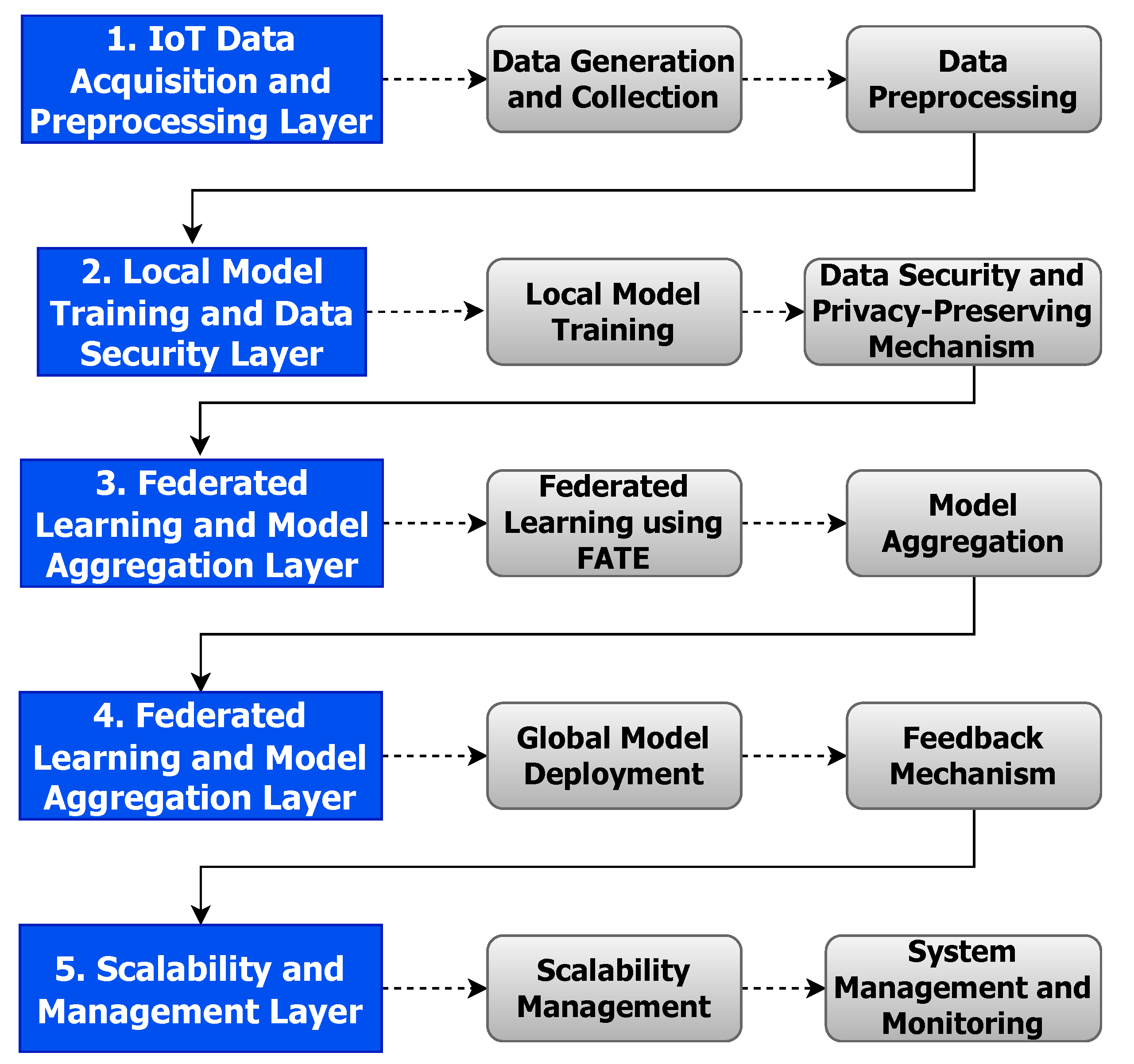
2.5. Proposed Architecture
- IoT data harvesting and initial processing layer:
- Dynamic data acquisition: implements a strategic approach to dynamically harvest, categorise, and preliminarily process extensive IoT data, utilising Apache Spark’s proficient in-memory computation to adeptly handle both streaming and batch data.
- In situ model training and data privacy layer:
- Intrinsic local model training: employs FATE to facilitate localised model training, reinforcing data privacy by ensuring data are processed in situ.
- Data and model security mechanism: integrate cryptographic and obfuscation techniques to safeguard data and model during communication, thus fortifying privacy and integrity.
- Federated learning and secure model consolidation layer:
- Privacy-aware federated learning: engages FATE to promote decentralised learning, which encourages local model training and securely amalgamates model updates without necessitating direct data exchange.
- Model aggregation and resilience: establishes a secure aggregation node that amalgamates model updates and validates them against potential adversarial actions and possible model poisoning.
- Global Model enhancement and feedback integration layer:
- Deploy, Enhance, and Evaluate: apply the Global Model to enhance local models, instigating a comprehensive evaluation and feedback mechanism that informs subsequent training cycles.
- Adaptive scalability and dynamic management layer:
- Dynamic scalability management: utilises Apache Spark to ensure adaptive scalability, which accommodates the continuous data and computational demands intrinsic to vast IoT setups.
- Proactive system management: implements AI-driven predictive management and maintenance mechanisms, aiming to anticipate potential system needs and iteratively optimise for both performance and reliability.
3. Methodology
Objectives of Federated Machine Learning
- Direct attack: . The attacker can directly inject data into all the target nodes, exploiting a vulnerability during data collection. For instance, in the case of mobile phone activity recognition, an attacker can provide counterfeit sensor data to directly attack the target mobile phones (nodes).
- Indirect attack: When no direct data injection is possible into the targeted nodes, symbolised by , the attacker can exert influence on these nodes indirectly. This is achieved by introducing tainted data into adjacent nodes, exploiting the communication protocol to subsequently impact the target nodes. Such an attack leverages the interconnected nature of the network, allowing for the propagation of the attack effects through the established data-sharing pathways.
- Hybrid attack: This form of attack represents a combination of both direct and indirect methods, wherein the aggressor has the capability to contaminate the data pools of both the target and source nodes at once. By employing this dual approach, the attacker enhances the potential to disrupt the network, manipulating data flows and learning processes by simultaneously injecting poisoned data into multiple nodes, thereby magnifying the scope and impact of the attack across the network.
- The aim, symbolised by , seeks to escalate the collective loss for all target nodes within the group , with representing the data manipulated by the attackers.
- The initial limitation strives to diminish the total loss for all learning tasks under the federation, depicted by . This includes both the original and tampered data, with denoting the loss for each task ℓ.
- To deter overfitting, which is fitting the model too closely to a limited set of data points, the model includes penalty terms and . These terms penalise the model’s complexity, balanced by the parameters and .
- A constraint ensures that the model’s parameters do not exceed a certain threshold C, maintaining the model’s general performance and stability.
4. Attacks on Federated Learning
4.1. Strategies for Attacking via Alternating Minimisation
| Algorithm 1 Federated Adversarial Attack for Multi-Task Learning (FAAMT). |
|
Further Analysis
5. Experimental Results
5.1. System Specifications of Experiments
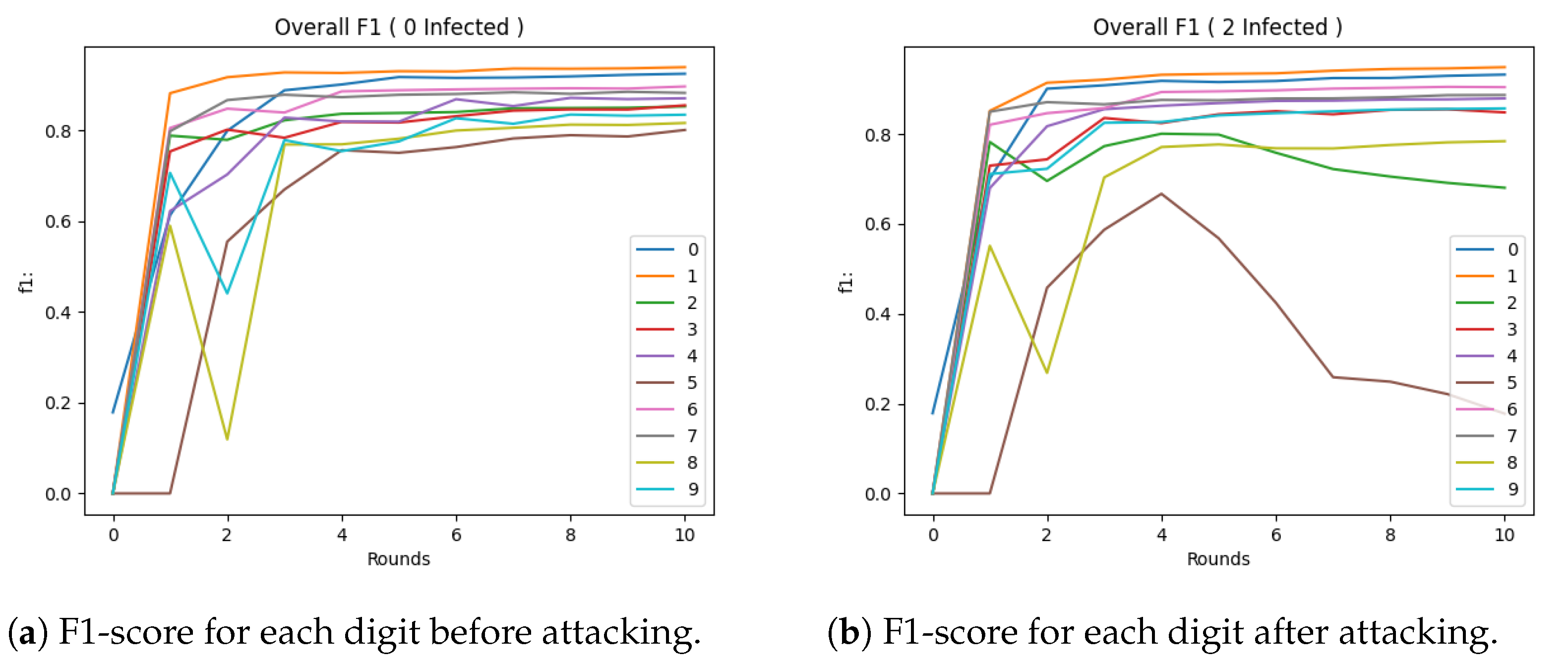
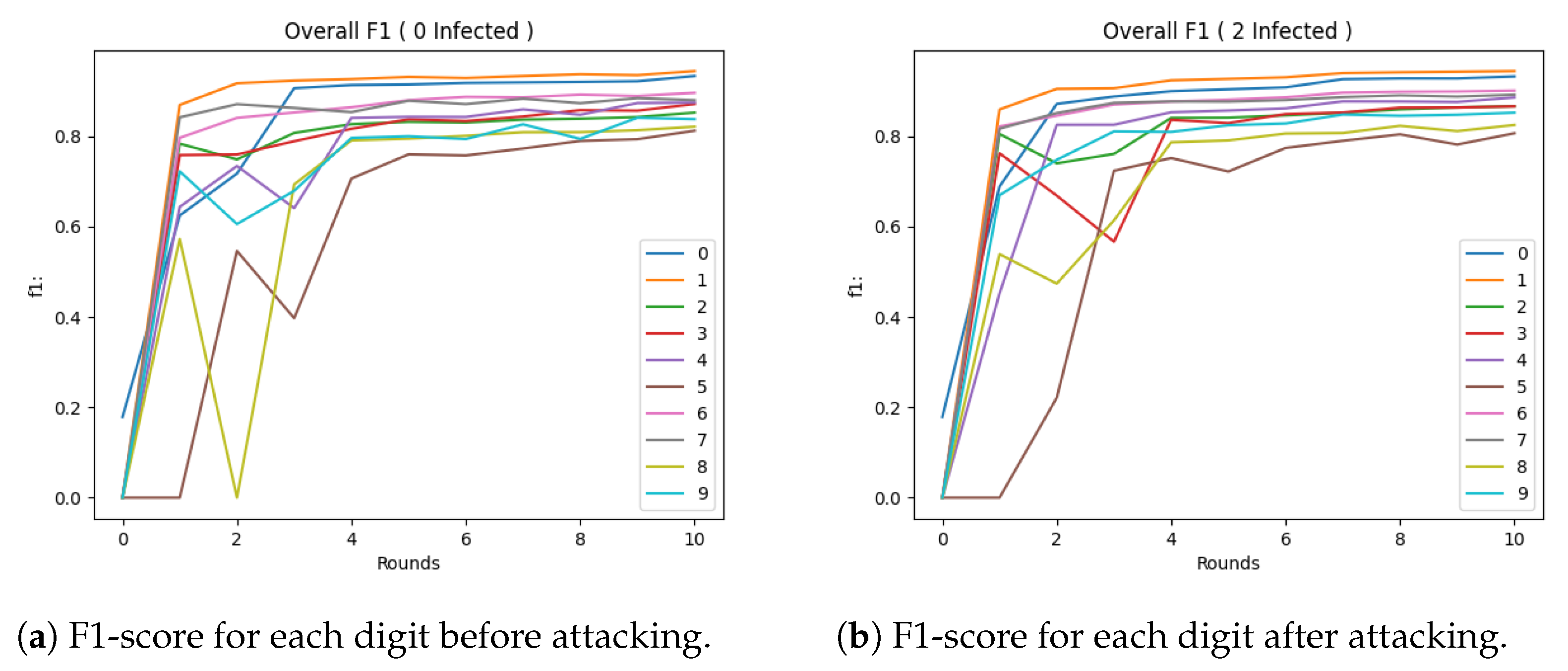
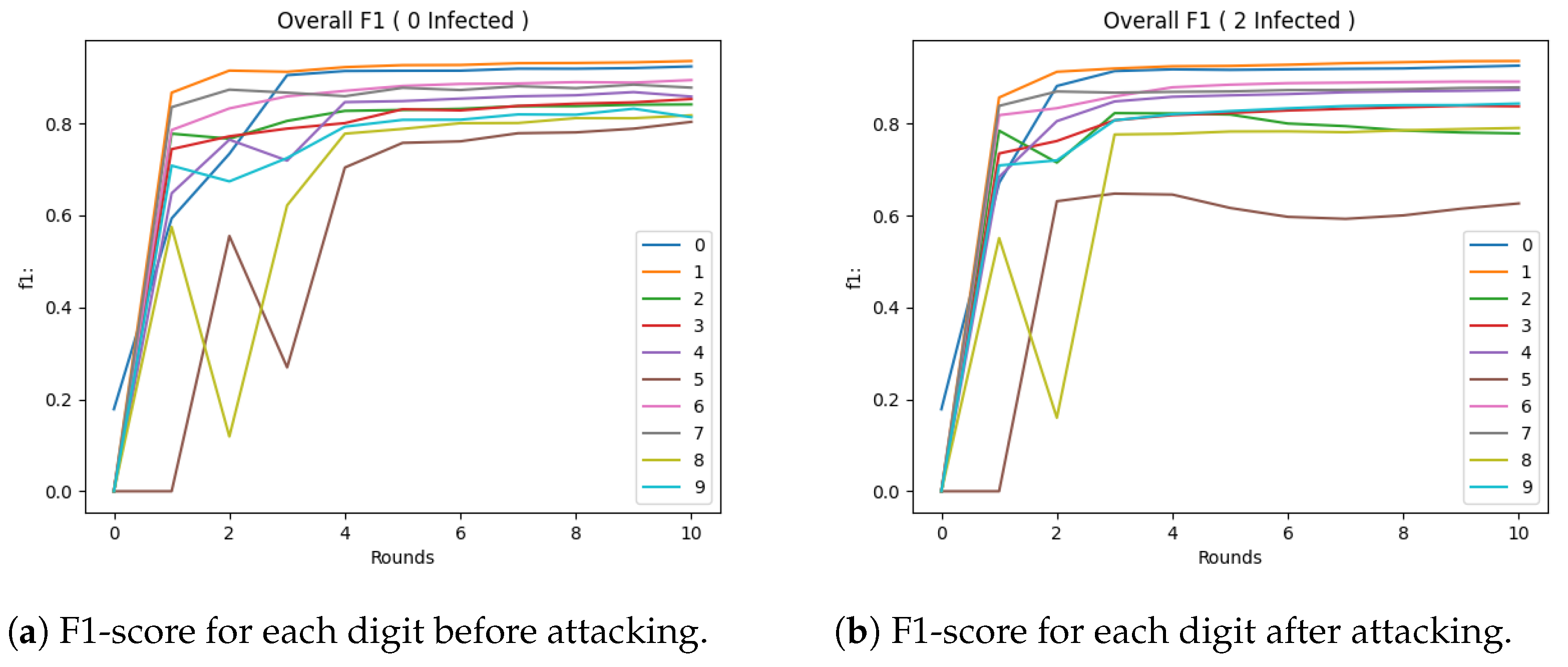
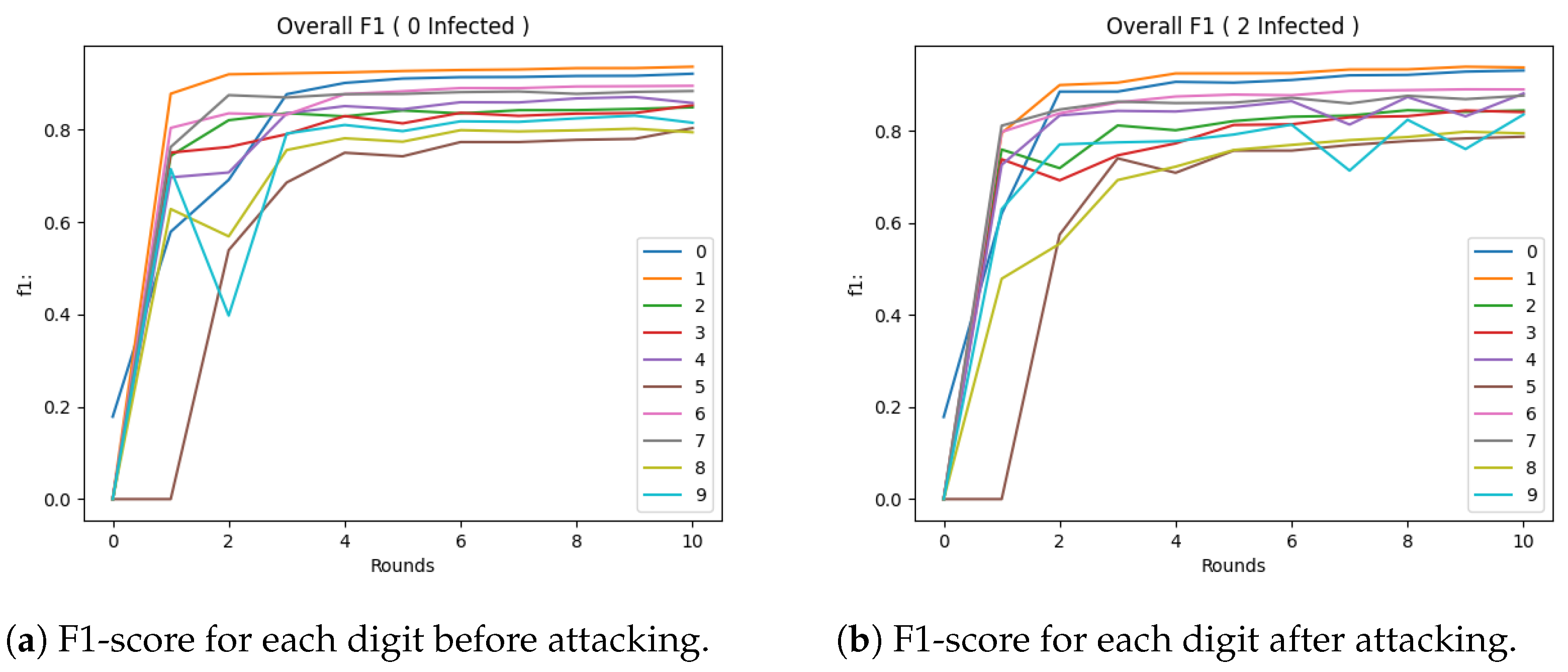
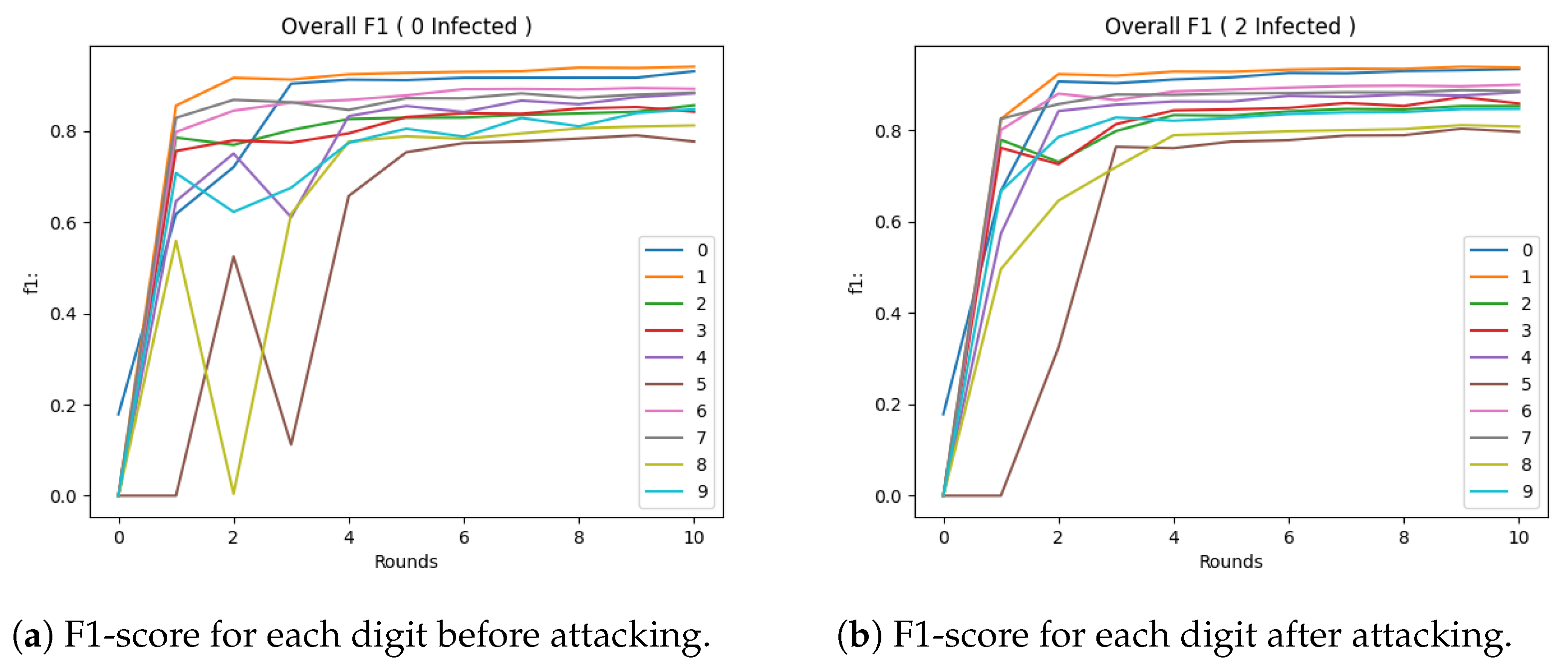
5.2. Experimental Evaluation of Attacking Mechanism
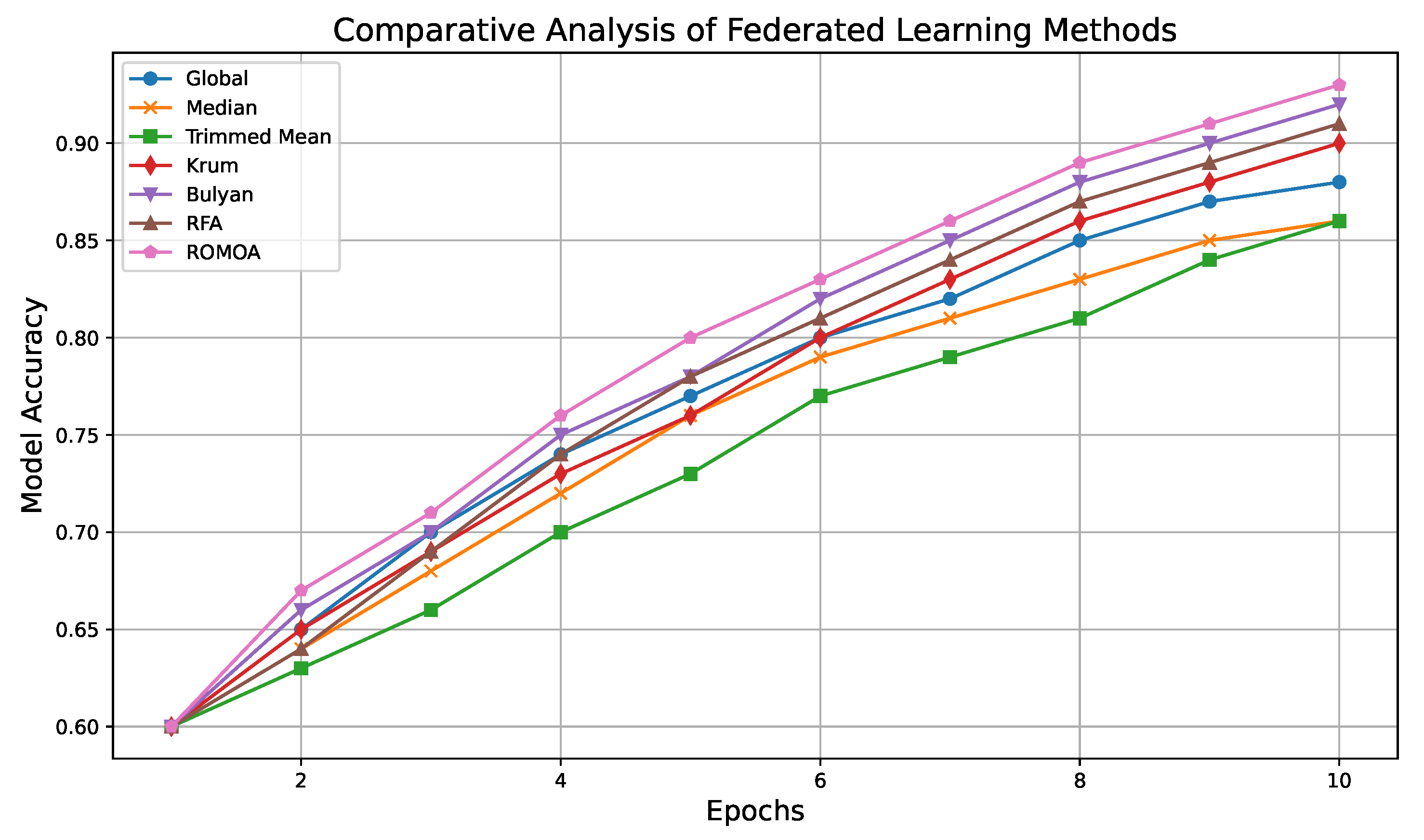
5.3. Experimental Evaluation of Defences
Evaluation Metrics:
6. Discussion
7. Conclusions
7.1. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Jebreel, N.M.; Domingo-Ferrer, J.; Sánchez, D.; Blanco-Justicia, A. Defending against the label-flipping attack in federated learning. arXiv 2022, arXiv:2207.01982. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, W.; Chen, Y. Data Quality Detection Mechanism Against Label Flipping Attacks in Federated Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1625–1637. [Google Scholar] [CrossRef]
- Li, D.; Wong, W.E.; Wang, W.; Yao, Y.; Chau, M. Detection and mitigation of label-flipping attacks in federated learning systems with KPCA and K-means. In Proceedings of the 2021 8th International Conference on Dependable Systems and Their Applications (DSA), Yinchuan, China, 5–6 August 2021; pp. 551–559. [Google Scholar]
- Cheng, Y.; Liu, Y.; Chen, T.; Yang, Q. Federated learning for privacy-preserving AI. Commun. ACM 2020, 63, 33–36. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security; 2019; pp. 1–11. Available online: https://arxiv.org/abs/1812.03224 (accessed on 18 October 2023).
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Pan, K.; Feng, K. Differential Privacy-Enabled Multi-Party Learning with Dynamic Privacy Budget Allocating Strategy. Electronics 2023, 12, 658. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Giotopoulos, K.C.; Tsolis, D.; Oikonomou, K.; Sioutas, S. Peer to Peer Federated Learning: Towards Decentralized Machine Learning on Edge Devices. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Abreha, H.G.; Hayajneh, M.; Serhani, M.A. Federated Learning in Edge Computing: A Systematic Survey. Sensors 2022, 22, 450. [Google Scholar] [CrossRef]
- Kaleem, S.; Sohail, A.; Tariq, M.U.; Asim, M. An Improved Big Data Analytics Architecture Using Federated Learning for IoT-Enabled Urban Intelligent Transportation Systems. Sustainability 2023, 15, 15333. [Google Scholar] [CrossRef]
- Javed, A.R.; Hassan, M.A.; Shahzad, F.; Ahmed, W.; Singh, S.; Baker, T.; Gadekallu, T.R. Integration of blockchain technology and federated learning in vehicular (iot) networks: A comprehensive survey. Sensors 2022, 22, 4394. [Google Scholar] [CrossRef]
- Kong, Q.; Yin, F.; Xiao, Y.; Li, B.; Yang, X.; Cui, S. Achieving Blockchain-based Privacy-Preserving Location Proofs under Federated Learning. In Proceedings of the ICC 2021—IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Math, S.; Tam, P.; Kim, S. Reliable Federated Learning Systems Based on Intelligent Resource Sharing Scheme for Big Data Internet of Things. IEEE Access 2021, 9, 108091–108100. [Google Scholar] [CrossRef]
- Nuding, F.; Mayer, R. Data poisoning in sequential and parallel federated learning. In Proceedings of the 2022 ACM on International Workshop on Security and Privacy Analytics; 2022; pp. 24–34. Available online: https://dl.acm.org/doi/abs/10.1145/3510548.3519372 (accessed on 18 October 2023).
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the Computer Security—ESORICS 2020: 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, 14–18 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 480–501. [Google Scholar]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data poisoning attacks on federated machine learning. IEEE Internet Things J. 2021, 9, 11365–11375. [Google Scholar] [CrossRef]
- Li, J.; Guo, W.; Han, X.; Cai, J.; Liu, X. Federated Learning based on Defending Against Data Poisoning Attacks in IoT. arXiv 2022, arXiv:2209.06397. [Google Scholar]
- Xu, W.; Fang, W.; Ding, Y.; Zou, M.; Xiong, N. Accelerating Federated Learning for IoT in Big Data Analytics with Pruning, Quantization and Selective Updating. IEEE Access 2021, 9, 38457–38466. [Google Scholar] [CrossRef]
- Fu, A.; Zhang, X.; Xiong, N.; Gao, Y.; Wang, H.; Zhang, J. VFL: A verifiable federated learning with privacy-preserving for big data in industrial IoT. IEEE Trans. Ind. Inform. 2020, 18, 3316–3326. [Google Scholar] [CrossRef]
- Can, Y.S.; Ersoy, C. Privacy-preserving federated deep learning for wearable IoT-based biomedical monitoring. ACM Trans. Internet Technol. (TOIT) 2021, 21, 1–17. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Y.; Zhang, Z.; Bai, H.; Zhong, T.; Song, M. Evaluation of data poisoning attacks on federated learning-based network intrusion detection system. In Proceedings of the 2022 IEEE 24th Int Conf on High Performance Computing & Communications; 8th Int Conf on Data Science & Systems; 20th Int Conf on Smart City; 8th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Hainan, China, 18–20 December 2022; pp. 2235–2242. [Google Scholar] [CrossRef]
- Singh, S.; Rathore, S.; Alfarraj, O.; Tolba, A.; Yoon, B. A framework for privacy preservation of IoT healthcare data using Federated Learning and blockchain technology. Future Gener. Comput. Syst. 2022, 129, 380–388. [Google Scholar] [CrossRef]
- Albelaihi, R.; Alasandagutti, A.; Yu, L.; Yao, J.; Sun, X. Deep-Reinforcement-Learning-Assisted Client Selection in Nonorthogonal-Multiple-Access-Based Federated Learning. IEEE Internet Things J. 2023, 10, 15515–15525. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Alam, T.; Gupta, R. Federated Learning and Its Role in the Privacy Preservation of IoT Devices. Future Internet 2022, 14, 246. [Google Scholar] [CrossRef]
- Dhiman, G.; Juneja, S.; Mohafez, H.; El-Bayoumy, I.; Sharma, L.K.; Hadizadeh, M.; Islam, M.A.; Viriyasitavat, W.; Khandaker, M.U. Federated Learning Approach to Protect Healthcare Data over Big Data Scenario. Sustainability 2022, 14, 2500. [Google Scholar] [CrossRef]
- Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. IEEE Trans. Inf. Forensics Secur. 2017, 13, 1333–1345. [Google Scholar]
- Chen, Y.R.; Rezapour, A.; Tzeng, W.G. Privacy-preserving ridge regression on distributed data. Inf. Sci. 2018, 451, 34–49. [Google Scholar] [CrossRef]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Park, J.; Lim, H. Privacy-Preserving Federated Learning Using Homomorphic Encryption. Appl. Sci. 2022, 12, 734. [Google Scholar] [CrossRef]
- Angulo, E.; Márquez, J.; Villanueva-Polanco, R. Training of Classification Models via Federated Learning and Homomorphic Encryption. Sensors 2023, 23, 1966. [Google Scholar] [CrossRef]
- Shen, X.; Jiang, H.; Chen, Y.; Wang, B.; Gao, L. PLDP-FL: Federated Learning with Personalized Local Differential Privacy. Entropy 2023, 25, 485. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Ma, X.; Wen, C. A Differential Privacy Strategy Based on Local Features of Non-Gaussian Noise in Federated Learning. Sensors 2022, 22, 2424. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, M.; Zhang, R.; Song, W.; Zheng, J.; Feng, J.; Matwin, S. Privacy-Enhanced Federated Learning: A Restrictively Self-Sampled and Data-Perturbed Local Differential Privacy Method. Electronics 2022, 11, 4007. [Google Scholar] [CrossRef]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning differentially private recurrent language models. arXiv 2017, arXiv:1710.06963. [Google Scholar]
- So, J.; Güler, B.; Avestimehr, A.S. Turbo-Aggregate: Breaking the Quadratic Aggregation Barrier in Secure Federated Learning. IEEE J. Sel. Areas Inf. Theory 2021, 2, 479–489. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Liu, S.; Yang, K.; Lin, X. VerifyNet: Secure and Verifiable Federated Learning. IEEE Trans. Inf. Forensics Secur. 2020, 15, 911–926. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained On-Device Federated Learning. IEEE Commun. Lett. 2020, 24, 1279–1283. [Google Scholar] [CrossRef]
- Mahmood, Z.; Jusas, V. Blockchain-Enabled: Multi-Layered Security Federated Learning Platform for Preserving Data Privacy. Electronics 2022, 11, 1624. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, H.; Chen, H.; Yan, Y.; Huang, J.; Xiong, A.; Yang, S.; Chen, J.; Guo, S. A Federated Learning Multi-Task Scheduling Mechanism Based on Trusted Computing Sandbox. Sensors 2023, 23, 2093. [Google Scholar] [CrossRef] [PubMed]
- Mortaheb, M.; Vahapoglu, C.; Ulukus, S. Personalized Federated Multi-Task Learning over Wireless Fading Channels. Algorithms 2022, 15, 421. [Google Scholar] [CrossRef]
- Du, W.; Atallah, M.J. Privacy-preserving cooperative statistical analysis. In Proceedings of the Seventeenth Annual Computer Security Applications Conference, New Orleans, LA, USA, 10–14 December 2001; pp. 102–110. [Google Scholar]
- Du, W.; Han, Y.S.; Chen, S. Privacy-preserving multivariate statistical analysis: Linear regression and classification. In Proceedings of the 2004 SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 222–233. [Google Scholar]
- Khan, A.; ten Thij, M.; Wilbik, A. Communication-Efficient Vertical Federated Learning. Algorithms 2022, 15, 273. [Google Scholar] [CrossRef]
- Hardy, S.; Henecka, W.; Ivey-Law, H.; Nock, R.; Patrini, G.; Smith, G.; Thorne, B. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv 2017, arXiv:1711.10677. [Google Scholar]
- Schoenmakers, B.; Tuyls, P. Efficient binary conversion for Paillier encrypted values. In Proceedings of the Advances in Cryptology-EUROCRYPT 2006: 24th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, 28 May–1 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 522–537. [Google Scholar]
- Zhong, Z.; Zhou, Y.; Wu, D.; Chen, X.; Chen, M.; Li, C.; Sheng, Q.Z. P-FedAvg: Parallelizing Federated Learning with Theoretical Guarantees. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can machine learning be secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J.D. Adversarial machine learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Chu, W.L.; Lin, C.J.; Chang, K.N. Detection and Classification of Advanced Persistent Threats and Attacks Using the Support Vector Machine. Appl. Sci. 2019, 9, 4579. [Google Scholar] [CrossRef]
- Chen, Y.; Hayawi, K.; Zhao, Q.; Mou, J.; Yang, L.; Tang, J.; Li, Q.; Wen, H. Vector Auto-Regression-Based False Data Injection Attack Detection Method in Edge Computing Environment. Sensors 2022, 22, 6789. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhou, Y.; Wu, D.; Li, C.; Wang, Y. On the Detection of Shilling Attacks in Federated Collaborative Filtering. In Proceedings of the 2020 International Symposium on Reliable Distributed Systems (SRDS), Shanghai, China, 21–24 September 2020; pp. 185–194. [Google Scholar] [CrossRef]
- Alfeld, S.; Zhu, X.; Barford, P. Data poisoning attacks against autoregressive models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Zügner, D.; Akbarnejad, A.; Günnemann, S. Adversarial attacks on neural networks for graph data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; 2018; pp. 2847–2856. Available online: https://arxiv.org/abs/1805.07984 (accessed on 18 October 2023).
- Zhao, M.; An, B.; Yu, Y.; Liu, S.; Pan, S. Data poisoning attacks on multi-task relationship learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Dhiman, S.; Nayak, S.; Mahato, G.K.; Ram, A.; Chakraborty, S.K. Homomorphic Encryption based Federated Learning for Financial Data Security. In Proceedings of the 2023 4th International Conference on Computing and Communication Systems (I3CS), Shillong, India, 16–18 March 2023; pp. 1–6. [Google Scholar]
- Jia, B.; Zhang, X.; Liu, J.; Zhang, Y.; Huang, K.; Liang, Y. Blockchain-Enabled Federated Learning Data Protection Aggregation Scheme With Differential Privacy and Homomorphic Encryption in IIoT. IEEE Trans. Ind. Inform. 2022, 18, 4049–4058. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Z.; Chen, Q.; Zheng, W.; Leng, J.; Guo, M. Dubhe: Towards data unbiasedness with homomorphic encryption in federated learning client selection. In Proceedings of the 50th International Conference on Parallel Processing, Lemont, IL, USA, 9–12 August 2021; pp. 1–10. [Google Scholar]
- Guo, X. Federated Learning for Data Security and Privacy Protection. In Proceedings of the 2021 12th International Symposium on Parallel Architectures, Algorithms and Programming (PAAP), Xi’an, China, 10–12 December 2021; pp. 194–197. [Google Scholar] [CrossRef]
- Fan, C.I.; Hsu, Y.W.; Shie, C.H.; Tseng, Y.F. ID-Based Multireceiver Homomorphic Proxy Re-Encryption in Federated Learning. ACM Trans. Sens. Netw. 2022, 18, 1–25. [Google Scholar] [CrossRef]
- Kou, L.; Wu, J.; Zhang, F.; Ji, P.; Ke, W.; Wan, J.; Liu, H.; Li, Y.; Yuan, Q. Image encryption for Offshore wind power based on 2D-LCLM and Zhou Yi Eight Trigrams. Int. J. Bio-Inspired Comput. 2023, 22, 53–64. [Google Scholar] [CrossRef]
- Li, L.; Li, T. Traceability model based on improved witness mechanism. CAAI Trans. Intell. Technol. 2022, 7, 331–339. [Google Scholar] [CrossRef]
- Lee, J.; Duong, P.N.; Lee, H. Configurable Encryption and Decryption Architectures for CKKS-Based Homomorphic Encryption. Sensors 2023, 23, 7389. [Google Scholar] [CrossRef]
- Ge, L.; Li, H.; Wang, X.; Wang, Z. A review of secure federated learning: Privacy leakage threats, protection technologies, challenges and future directions. Neurocomputing 2023, 561, 126897. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, H.; Wang, F.; Zhao, J.; Xu, Q.; Li, H. Security and privacy threats to federated learning: Issues, methods, and challenges. Secur. Commun. Netw. 2022, 2022, 2886795. [Google Scholar] [CrossRef]
- Zhang, J.; Li, M.; Zeng, S.; Xie, B.; Zhao, D. A survey on security and privacy threats to federated learning. In Proceedings of the 2021 International Conference on Networking and Network Applications (NaNA), Lijiang City, China, 29 October–1 November 2021; pp. 319–326. [Google Scholar] [CrossRef]
- Li, Y.; Bao, Y.; Xiang, L.; Liu, J.; Chen, C.; Wang, L.; Wang, X. Privacy threats analysis to secure federated learning. arXiv 2021, arXiv:2106.13076. [Google Scholar]
- Asad, M.; Moustafa, A.; Yu, C. A critical evaluation of privacy and security threats in federated learning. Sensors 2020, 20, 7182. [Google Scholar] [CrossRef]
- Manzoor, S.I.; Jain, S.; Singh, Y.; Singh, H. Federated Learning Based Privacy Ensured Sensor Communication in IoT Networks: A Taxonomy, Threats and Attacks. IEEE Access 2023, 11, 42248–42275. [Google Scholar] [CrossRef]
- Benmalek, M.; Benrekia, M.A.; Challal, Y. Security of federated learning: Attacks, defensive mechanisms, and challenges. Rev. Sci. Technol. L’Inform. Série RIA Rev. D’Intell. Artif. 2022, 36, 49–59. [Google Scholar] [CrossRef]
- Arbaoui, M.; Rahmoun, A. Towards secure and reliable aggregation for Federated Learning protocols in healthcare applications. In Proceedings of the 2022 Ninth International Conference on Software Defined Systems (SDS), Paris, France, 12–15 December 2022; pp. 1–3. [Google Scholar]
- Abdelli, K.; Cho, J.Y.; Pachnicke, S. Secure Collaborative Learning for Predictive Maintenance in Optical Networks. In Proceedings of the Secure IT Systems: 26th Nordic Conference, NordSec 2021, Virtual Event, 29–30 November 2021; Proceedings 26. Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 114–130. [Google Scholar]
- Jeong, H.; Son, H.; Lee, S.; Hyun, J.; Chung, T.M. FedCC: Robust Federated Learning against Model Poisoning Attacks. arXiv 2022, arXiv:2212.01976. [Google Scholar]
- Lyu, X.; Han, Y.; Wang, W.; Liu, J.; Wang, B.; Liu, J.; Zhang, X. Poisoning with cerberus: Stealthy and colluded backdoor attack against federated learning. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Jeon, Y.S.; Poor, H.V. Covert model poisoning against federated learning: Algorithm design and optimization. IEEE Trans. Dependable Secur. Comput. 2023. [Google Scholar] [CrossRef]
- Sun, J.; Li, A.; DiValentin, L.; Hassanzadeh, A.; Chen, Y.; Li, H. Fl-wbc: Enhancing robustness against model poisoning attacks in federated learning from a client perspective. Adv. Neural Inf. Process. Syst. 2021, 34, 12613–12624. [Google Scholar]
- Mao, Y.; Yuan, X.; Zhao, X.; Zhong, S. Romoa: Ro bust Mo del A ggregation for the Resistance of Federated Learning to Model Poisoning Attacks. In Proceedings of the Computer Security–ESORICS 2021: 26th European Symposium on Research in Computer Security, Darmstadt, Germany, 4–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 476–496. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust Aggregation for Federated Learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Wang, X.; Liang, Z.; Koe, A.S.V.; Wu, Q.; Zhang, X.; Li, H.; Yang, Q. Secure and efficient parameters aggregation protocol for federated incremental learning and its applications. Int. J. Intell. Syst. 2022, 37, 4471–4487. [Google Scholar] [CrossRef]
- Hao, M.; Li, H.; Xu, G.; Chen, H.; Zhang, T. Efficient, private and robust federated learning. In Proceedings of the Annual Computer Security Applications Conference, Virtual Event, 6–10 December 2021; pp. 45–60. [Google Scholar]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Shalev-Shwartz, S.; Zhang, T. Accelerated proximal stochastic dual coordinate ascent for regularized loss minimization. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 64–72. [Google Scholar]
- Wassan, S.; Suhail, B.; Mubeen, R.; Raj, B.; Agarwal, U.; Khatri, E.; Gopinathan, S.; Dhiman, G. Gradient Boosting for Health IoT Federated Learning. Sustainability 2022, 14, 16842. [Google Scholar] [CrossRef]
- Feng, J.; Yang, L.T.; Zhu, Q.; Choo, K.K.R. Privacy-preserving tensor decomposition over encrypted data in a federated cloud environment. IEEE Trans. Dependable Secur. Comput. 2018, 17, 857–868. [Google Scholar] [CrossRef]
- Feng, J.; Yang, L.T.; Ren, B.; Zou, D.; Dong, M.; Zhang, S. Tensor recurrent neural network with differential privacy. IEEE Trans. Comput. 2023. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Giotopoulos, K.C.; Tsolis, D.; Oikonomou, K.; Sioutas, S. Federated Edge Intelligence and Edge Caching Mechanisms. Information 2023, 14, 414. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Schizas, N.; Avlonitis, M.; Sioutas, S. AutoML with Bayesian Optimizations for Big Data Management. Information 2023, 14, 223. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanism | Description | Reference |
|---|---|---|
| FedCC | Employs a robust aggregation algorithm, mitigating both targeted and untargeted model poisoning or backdoor attacks, even in non-IID data scenarios. | [75] |
| Krum | Acts as a server-side defence via an aggregation mechanism, but may be susceptible to Covert Model Poisoning (CMP). | [77] |
| Trimmed Mean | Server-side aggregation similar to Krum, yet also potentially prone to CMP, aiming to resist model poisoning attacks. | [77] |
| MPC-Based Aggregation | Mitigates model inversion attacks by employing a trained autoencoder-based anomaly-detection model during aggregation. | [74] |
| FL-WBC | A client-based strategy that minimises attack impacts on the Global Model by perturbing the parameter space during local training. | [78] |
| Romoa | Utilises a logarithm-based normalisation to manage scaled gradients from malicious vehicles, resisting model poisoning attacks. | [79] |
| RFA | Utilises a weighted average of gradients to resist Byzantine attacks, aiming to establish a robust aggregation method. | [80] |
| Symbol | Interpretation |
|---|---|
| Uninfected data for node i | |
| Uninfected data for target node t | |
| Infected data for node i | |
| Infected data for attacking node s | |
| Set of target nodes | |
| Set of attacking nodes | |
| Upper level function | |
| Weight matrix | |
| Model relationship matrix |
| Component | Specification |
|---|---|
| CPU | AMD 5950X |
| RAM | 64GB DDR4 |
| Storage | 2TB NVMe |
| GPU | 3090Ti (24GB VRAM) |
| Operating System | Ubuntu 18.04 LTS |
| Network Interface | 1GBPS |
| Software Framework | Apache Spark with FATE |
| Method | Attack (A) | Defence (D) | Affected Clients (D) | ||
|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1 Score | out of 10 | |
| Global Model | 0.88 | 0.84 | 0.85 | 0.81 | 2 |
| Median Model | 0.86 | 0.82 | 0.87 | 0.83 | 2 |
| Trimmed Mean Model | 0.86 | 0.81 | 0.86 | 0.82 | 2 |
| Krum | 0.90 | 0.84 | 0.88 | 0.83 | 2 |
| Bulyan | 0.93 | 0.80 | 0.89 | 0.83 | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karras, A.; Giannaros, A.; Theodorakopoulos, L.; Krimpas, G.A.; Kalogeratos, G.; Karras, C.; Sioutas, S. FLIBD: A Federated Learning-Based IoT Big Data Management Approach for Privacy-Preserving over Apache Spark with FATE. Electronics 2023, 12, 4633. https://doi.org/10.3390/electronics12224633
Karras A, Giannaros A, Theodorakopoulos L, Krimpas GA, Kalogeratos G, Karras C, Sioutas S. FLIBD: A Federated Learning-Based IoT Big Data Management Approach for Privacy-Preserving over Apache Spark with FATE. Electronics. 2023; 12(22):4633. https://doi.org/10.3390/electronics12224633
Chicago/Turabian StyleKarras, Aristeidis, Anastasios Giannaros, Leonidas Theodorakopoulos, George A. Krimpas, Gerasimos Kalogeratos, Christos Karras, and Spyros Sioutas. 2023. "FLIBD: A Federated Learning-Based IoT Big Data Management Approach for Privacy-Preserving over Apache Spark with FATE" Electronics 12, no. 22: 4633. https://doi.org/10.3390/electronics12224633
APA StyleKarras, A., Giannaros, A., Theodorakopoulos, L., Krimpas, G. A., Kalogeratos, G., Karras, C., & Sioutas, S. (2023). FLIBD: A Federated Learning-Based IoT Big Data Management Approach for Privacy-Preserving over Apache Spark with FATE. Electronics, 12(22), 4633. https://doi.org/10.3390/electronics12224633