
Task Offloading Scheme for Survivability Guarantee Based on Traffic Prediction in 6G Edge Networks

 ,
, 
Abstract
:1. Introduction
- We deploy the accurate traffic prediction model on edge nodes by constructing a mapping between traffic prediction and future available resources to achieve resource visualization of the entire 6G edge network, so as to maximize the advantages of using edge resources while ensuring the survivability of the network.
- In response to the highly dynamic nature of networks, they may face the challenge of failing to adapt fixed algorithmic parameters to mutating network environments. We develop the PSO-PG algorithm for the design of node-overload protection schemes in dynamic networks. The key parameters of the PSO algorithm are adaptive adjustments by policy gradients (PGs) that interact with the actual network environment. The improved algorithm solves the problems of difficulty in manually configuring parameters and the inability to be updated in time according to the actual operating conditions.
- Under the constraints of the future available resources, utilizing the advantages of the PSO-PG algorithm, we propose an innovative survivability guarantee framework for 6G edge networks. It integrates the prediction of required processing power and the process of task offloading. The scheme effectively realizes the joint optimization of adjustment offloading decisions with routing and computing resources to match the network survivability guarantee, minimizing the increase in service delay due to insufficient or overallocation of resources while guaranteeing the performance of the whole network.
2. Related Work
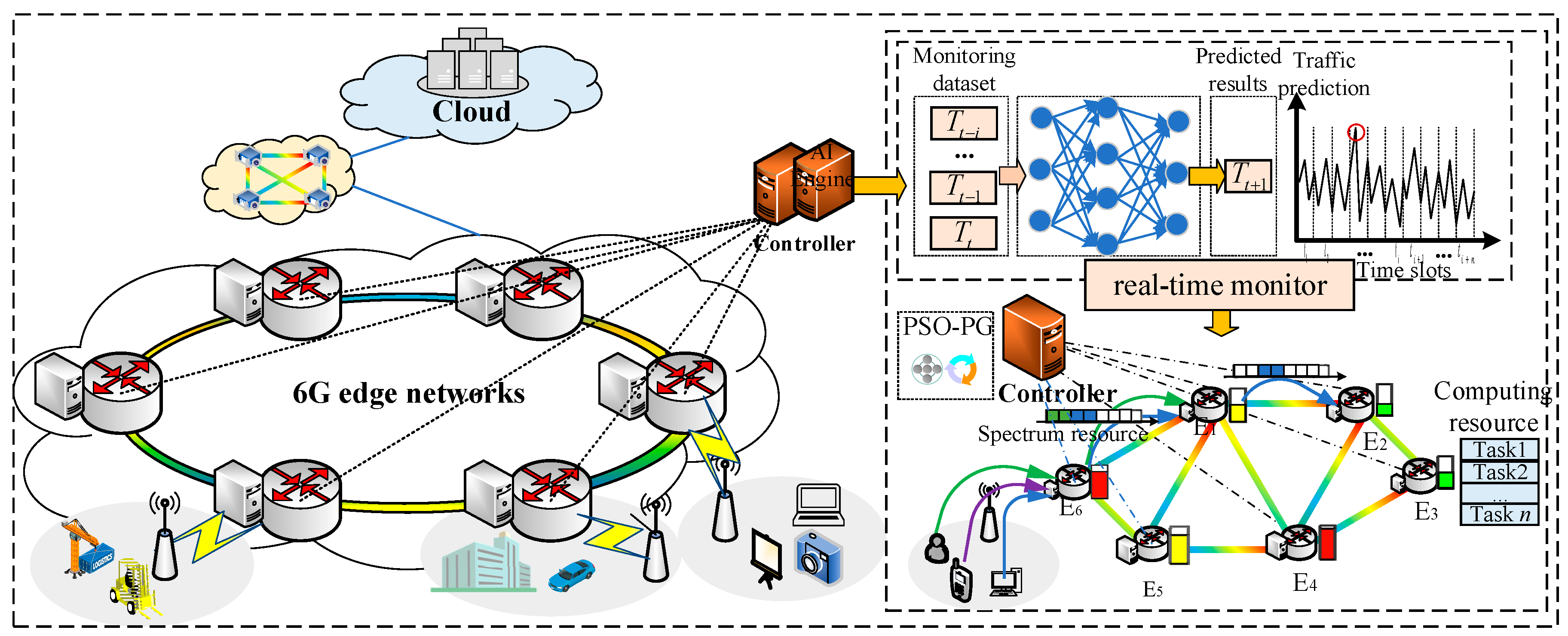
3. System Architecture
3.1. Description of Network Architecture
3.2. The Establishment of an Offloading Model
- indicates that the amount of tasks allocated to the edge server should be within the computing capacity of the server, and indicates the limit ratio of the maximum computing capacity of the server m.
- When , each task is allowed to be allocated to only one server for processing.
- represents that the frequency slot fs in the optical path occupied from the local MEC to the destination MEC.
- When , it is constrained that the number of frequency slots occupied by all tasks should be within the capacity of the frequency slot of the optical path.
- When , it is worth noting that the allocation of frequency slots follows the principle of proximity.
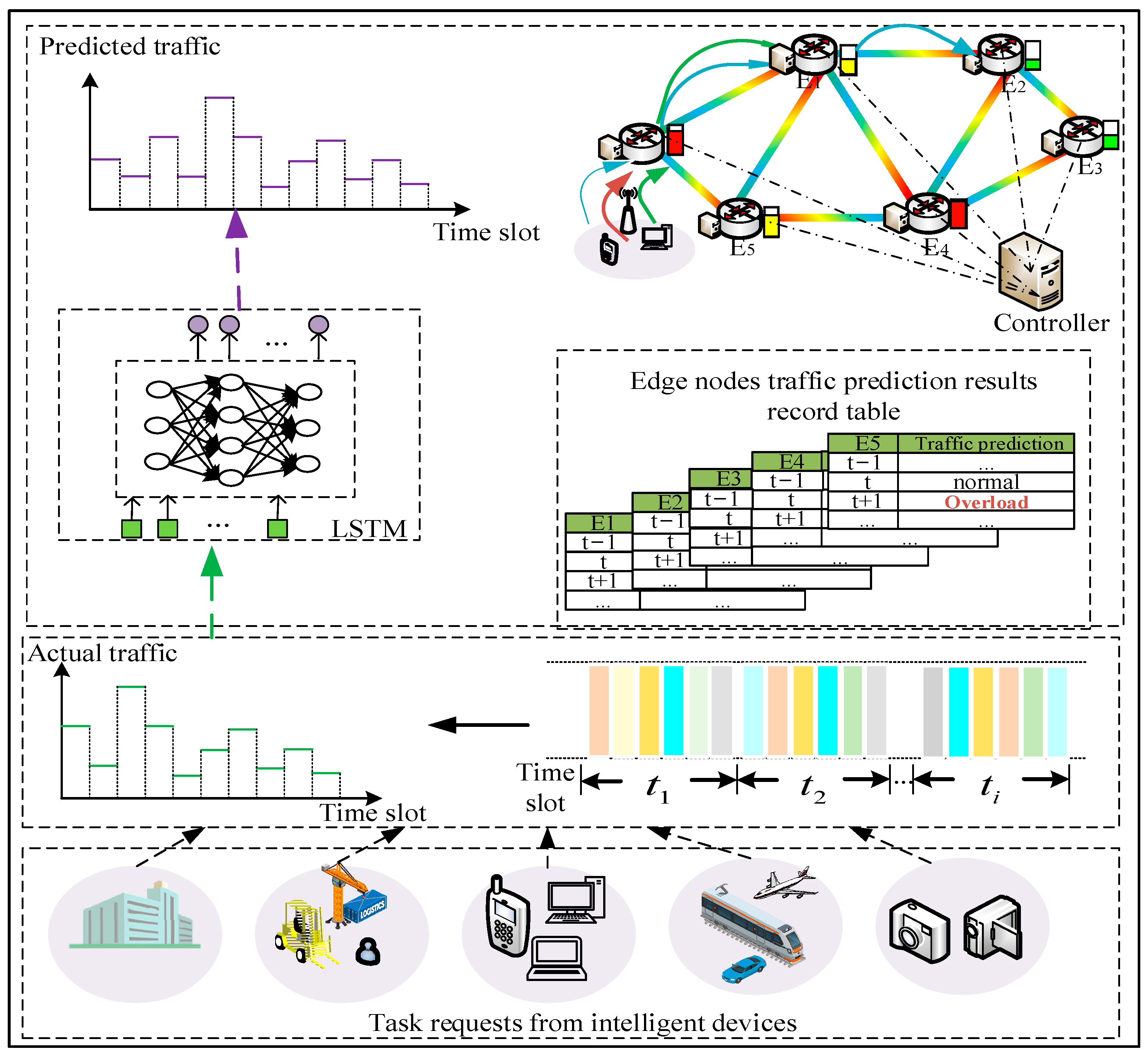
4. Task Offloading Scheme Based on Traffic Prediction for Node-Overload Protection
4.1. Traffic Prediction Based on LSTM
4.2. PSO-PG-Based Task Offloading Scheme under Multi-Edge Collaboration
| Algorithm 1: The algorithmic process of PSO-PG. |
| 1. Initialize the PG training parameters, learning rate and the loss function . 2. Initialize the size of particle swarm N, the maximum number of iterations , inertia weight and learning factors and . 3. Obtain the initialization fitness value according to the initial parameters. 4. For do 5. Input the individual optimal solution and the global optimal solution calculated by PSO into the PG. 6. Output action probability distribution through PG iterative operation. 7. The action selection function will select action according to and input to the PSO. 8. PSO receives the action according to the update rule for parameters to update , , and . 9. Update particle swarm velocity and position according to Formulas (20) and (21). 10. Update and , and calculate the new Fitness value according to Formula (24). 11. Return the new reward value by PG. 12. Store the obtained the state , action, and reward in intelligent agent. 13. Input the updated and into PG. 14. End For |
| Algorithm 2: Task offloading for node-overload protection based on PSO-PG. |
| 1. Obtain the predicted node overload. 2. Establish an ascending sort as a set of candidate offloading nodes; 3. Initialize particle position and particle velocity vector ;. 4. While the algorithm has not converged do 5. For each particle i do 6. Decode each particle swarm through (12) to obtain the offloading scheme. 7. Select the initial destination MEC server and allocation resource. 8. Calculate the Fitness () by Formula (21). 9. .10. if Fitness() < Fitness() then 11. 12. end if 13. if Fitness() < Fitness() then 14. 15. end if 16. End For 17. Choose the smallest Fitness value as the optimal scheme and update particle through the Formulas (19) and (20). 18. End While 19. Output the optical scheme . |
5. Evaluation
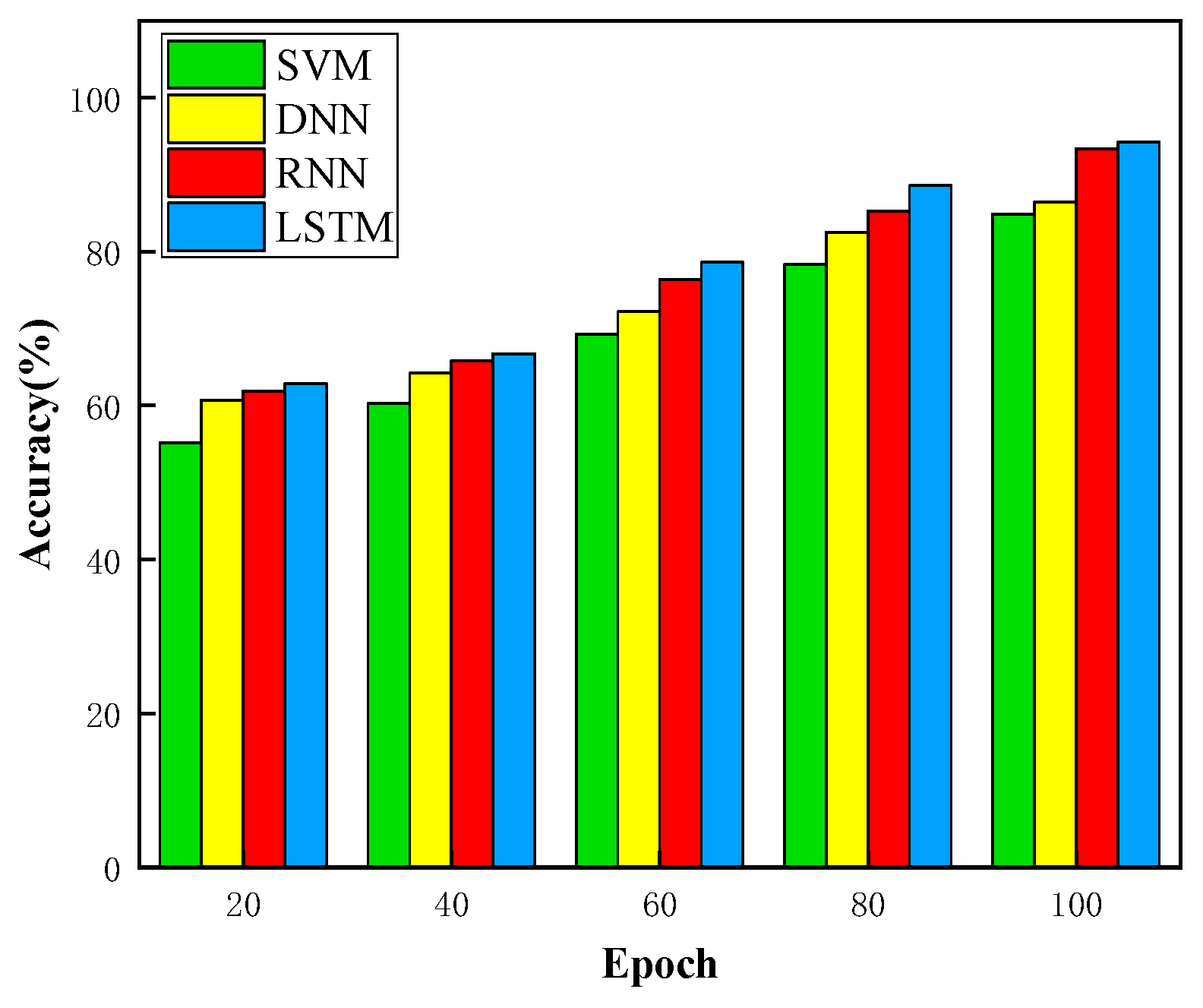
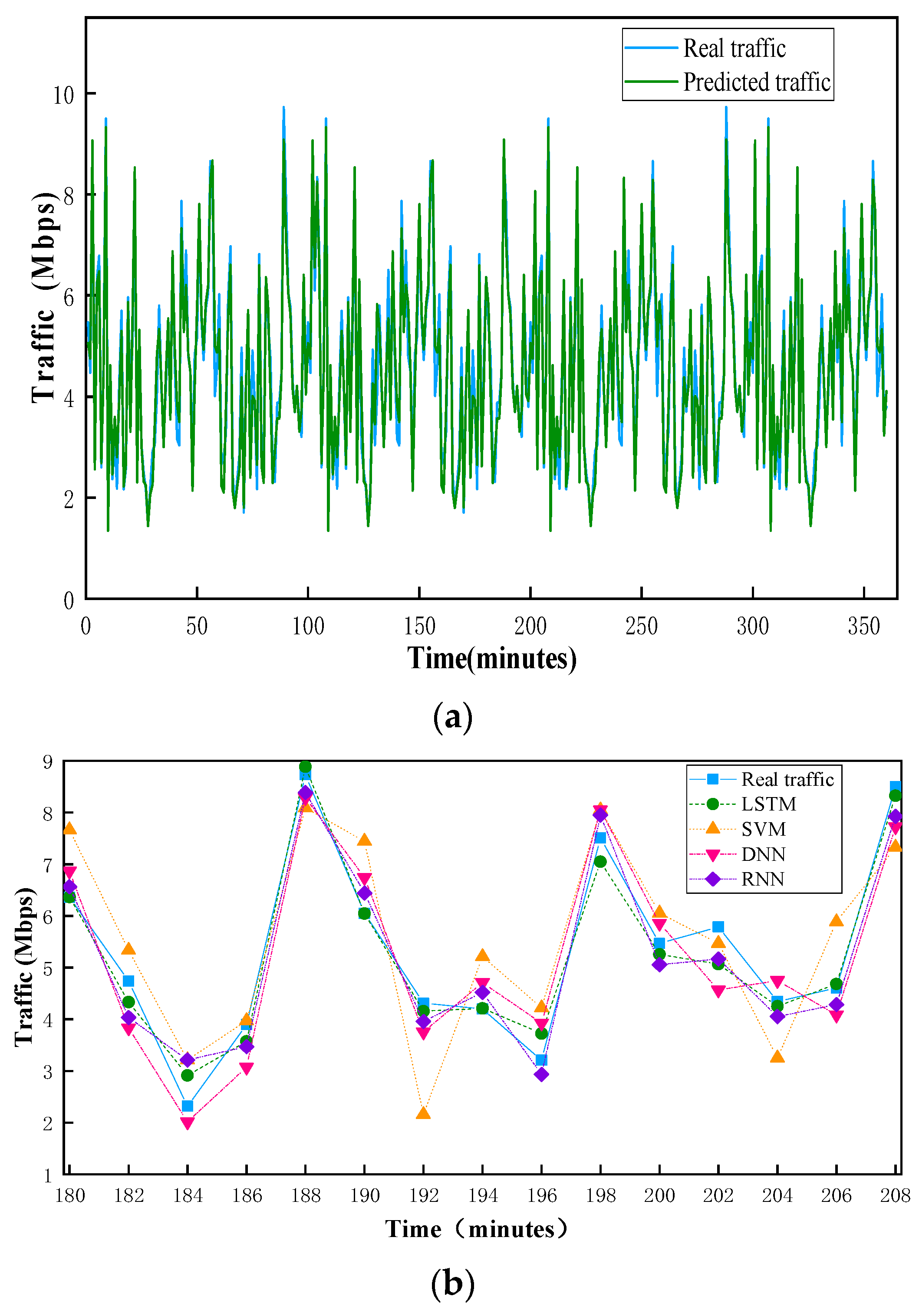
5.1. Simulation Setup and Results Analysis for Traffic Prediction Based on LSTM
5.2. Simulation Setup and Results Analysis for Task Offloading Based on PSO-PG
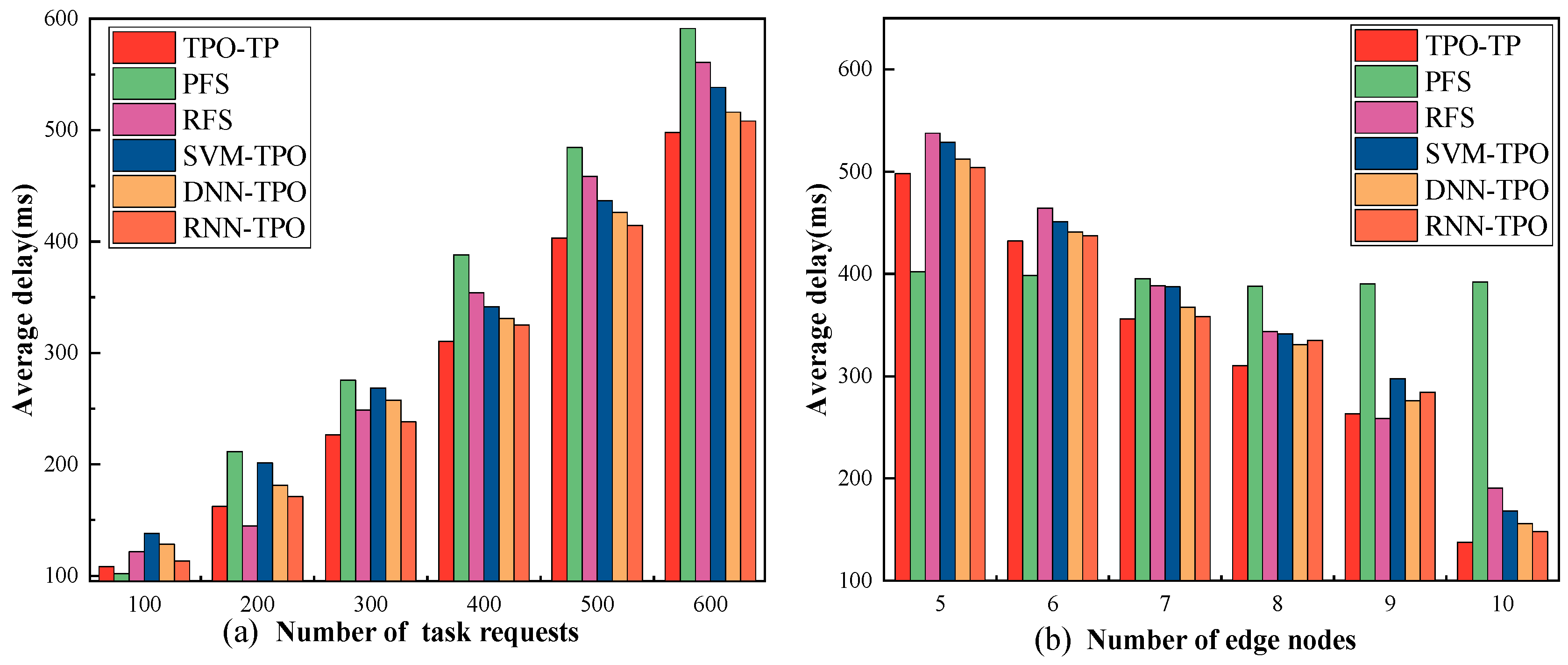
- Average delay
- Blocking probability
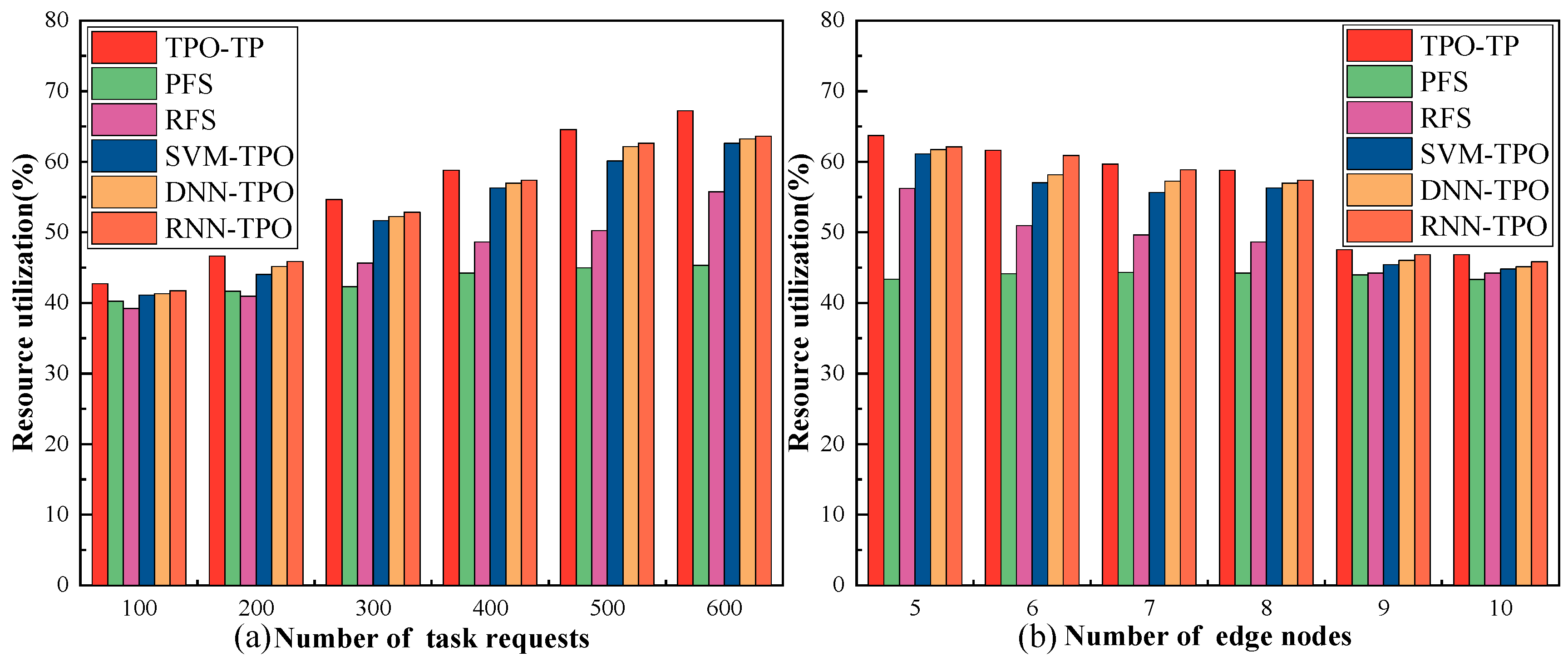
- Resource utilization
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Petrov, V.; Lema, M.A.; Gapeyenko, M.; Antonakoglou, K.; Moltchanov, D.; Sardis, F.; Samuylov, A.; Andreev, S.; Koucheryavy, Y.; Dohler, M. Achieving End-to-End Reliability of Mission-Critical Traffic in Softwarized 5G Networks. IEEE J. Sel. Areas Commun. 2018, 36, 485–501. [Google Scholar] [CrossRef]
- Spantideas, S.; Giannopoulos, A.; Cambeiro, M.A.; Trullols-Cruces, O.; Atxutegi, E.; Trakadas, P. Intelligent Mission Critical Services over Beyond 5G Networks: Control Loop and Proactive Overload Detection. In Proceedings of the 2023 International Conference on Smart Applications, Communications and Networking (SmartNets), Istanbul, Turkiye, 25–27 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Skarin, P.; Tärneberg, W.; Årzen, K.-E.; Kihl, M. Towards Mission-Critical Control at the Edge and Over 5G. In Proceedings of the 2018 IEEE International Conference on Edge Computing (EDGE), San Francisco, CA, USA, 2–7 July 2018; pp. 50–57. [Google Scholar] [CrossRef]
- Sun, Z.; Yang, H.; Li, C.; Yao, Q.; Wang, D.; Zhang, J.; Vasilakos, A.V. Cloud-Edge Collaboration in Industrial Internet of Things: A Joint Offloading Scheme Based on Resource Prediction. IEEE Internet Things J. 2022, 9, 17014–17025. [Google Scholar] [CrossRef]
- Wu, D.; Han, X.; Yang, Z.; Wang, R. Exploiting Transfer Learning for Emotion Recognition Under Cloud-Edge-Client Collaborations. IEEE J. Sel. Areas Commun. 2021, 39, 479–490. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Champagne, B.; Zhu, W.-P.; Al-Dhahir, N. Secrecy-Energy Efficient Hybrid Beamforming for Satellite-Terrestrial Integrated Networks. IEEE Trans. Commun. 2021, 69, 6345–6360. [Google Scholar] [CrossRef]
- Yang, H.; Yao, Q.; Bao, B.; Yu, A.; Zhang, J.; Vasilakos, A.V. Multi-associated parameters aggregation-based routing and resources allocation in multi-core elastic optical networks. IEEE/ACM Trans. Netw. 2022, 30, 2145–2157. [Google Scholar] [CrossRef]
- Yao, Q.; Yang, H.; Li, C.; Bao, B.; Zhang, J.; Cheriet, M. Federated Transfer Learning Framework for Heterogeneous Edge IoT Networks. China Commun. [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Hu, Y.; Li, D.; Wang, J.; Al-Dhahir, N. Pain Without Gain: Destructive Beamforming From a Malicious RIS Perspective in IoT Networks. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Yu, T.; Yang, H.; Yao, Q.; Yu, A.; Zhao, Y.; Liu, S.; Li, Y.; Zhang, J.; Cheriet, M. Multi visual GRU based survivable computing power scheduling in metro optical networks. IEEE Trans. Netw. Serv. Manag. 2023. [Google Scholar] [CrossRef]
- Wu, D.; Bao, R.; Li, Z.; Wang, H.; Zhang, H.; Wang, R. Edge-Cloud Collaboration Enabled Video Service Enhancement: A Hybrid Human-Artificial Intelligence Scheme. IEEE Trans. Multimed. 2021, 23, 2208–2221. [Google Scholar] [CrossRef]
- An, K.; Lin, M.; Ouyang, J.; Zhu, W.-P. Secure Transmission in Cognitive Satellite Terrestrial Networks. IEEE J. Sel. Areas Commun. 2016, 34, 3025–3037. [Google Scholar] [CrossRef]
- Ma, R.; Yang, W.; Shi, H.; Lu, X.; Liu, J. Covert communication with a spectrum sharing relay in the finite blocklength regime. China Commun. 2023, 20, 195–211. [Google Scholar] [CrossRef]
- Guo, C.; He, W.; Li, G.Y. Optimal Fairness-Aware Resource Supply and Demand Management for Mobile Edge Computing. IEEE Wirel. Commun. Lett. 2021, 10, 678–682. [Google Scholar] [CrossRef]
- Gunawardena, J. Learning Outside the Brain: Integrating Cognitive Science and Systems Biology. Proc. IEEE 2022, 110, 590–612. [Google Scholar] [CrossRef]
- Shi, C.; Ding, L.; Wang, F.; Salous, S.; Zhou, J. Joint Target Assignment and Resource Optimization Framework for Multitarget Tracking in Phased Array Radar Network. IEEE Syst. J. 2021, 15, 4379–4390. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, Q. Offloading schemes in mobile edge computing for ultra-reliable low latency communications. IEEE Access 2018, 6, 12825–12837. [Google Scholar] [CrossRef]
- Chen, L.; Xu, J.; Zhou, S. Computation peer offloading in mobile edge computing with energy budgets. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Sun, X.; Ansari, N. Latency aware workload offloading in the cloudlet network. IEEE Commun. Lett. 2017, 21, 1481–1484. [Google Scholar] [CrossRef]
- Li, J.; Luo, G.; Cheng, N.; Yuan, Q.; Wu, Z.; Gao, S.; Liu, Z. An end-to-end load balancer based on deep learning for vehicular network traffic control. IEEE Int. Things J. 2019, 6, 953–966. [Google Scholar] [CrossRef]
- Taleb, T.; Ksentini, A.; Frangoudis, P. Follow-me cloud: When cloud services follow mobile users. IEEE Trans. Mobile Comput. 2019, 7, 369–382. [Google Scholar] [CrossRef]
- Wang, S.; Urgaonkar, R.; Zafer, M.; He, T.; Chan, K.; Leung, K.K. Dynamic Service Migration in Mobile Edge Computing Based on Markov Decision Process. IEEE/ACM Trans. Netw. 2019, 27, 1272–1288. [Google Scholar] [CrossRef]
- He, Y.; Zhao, N.; Yin, H. Integrated networking, caching, and computing for connected vehicles: A deep reinforcement learning approach. IEEE Trans. Veh. Technol. 2018, 67, 44–55. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X. Decentralized computation offloading for multi-user mobile edge computing: A deep reinforcement learning approach. arXiv 2018, arXiv:1812.07394. [Google Scholar] [CrossRef]
- Jitani, A.; Mahajan, A.; Zhu, Z.; Abou-Zeid, H.; Fapi, E.T.; Purmehdi, H. Structure-Aware Reinforcement Learning for Node-Overload Protection in Mobile Edge Computing. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1881–1897. [Google Scholar] [CrossRef]
- Fang, Z.; Xu, X.; Dai, F.; Qi, L.; Zhang, X.; Dou, W. Computation Offloading and Content Caching with Traffic Flow Prediction for Internet of Vehicles in Edge Computing. In Proceedings of the 2020 IEEE International Conference on Web Services (ICWS), Beijing, China, 19–23 October 2020; pp. 380–388. [Google Scholar] [CrossRef]
- Tian, H.; Xu, X.; Qi, L.; Zhang, X.; Dou, W.; Yu, S.; Ni, Q. CoPace: Edge Computation Offloading and Caching for Self-Driving With Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 13281–13293. [Google Scholar] [CrossRef]
- Xu, X.; Jiang, Q.; Zhang, P.; Cao, X.; Khosravi, M.R.; Alex, L.T.; Qi, L.; Dou, W. Game Theory for Distributed IoV Task Offloading With Fuzzy Neural Network in Edge Computing. IEEE Trans. Fuzzy Syst. 2022, 30, 4593–4604. [Google Scholar] [CrossRef]
- Ferdosian, N.; Moazzeni, S.; Jaisudthi, P.; Ren, Y.; Agrawal, H.; Simeonidou, D.; Nejabat, R. Autonomous Intelligent VNF Profiling for Future Intelligent Network Orchestration. IEEE Trans. Mach. Learn. Commun. Netw. 2023, 1, 138–152. [Google Scholar] [CrossRef]
- Nagib, A.M.; Abou-zeid, H.; Hassanein, H.S. Toward Safe and Accelerated Deep Reinforcement Learning for Next-Generation Wireless Networks. IEEE Netw. 2023, 37, 182–189. [Google Scholar] [CrossRef]
- Prasanna Kumar, G.; Shankaraiah, N. An Efficient IoT-based Ubiquitous Networking Service for Smart Cities Using Machine Learning Based Regression Algorithm. Int. J. Inf. Technol. Comput. Sci. (IJITCS) 2023, 15, 15–25. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, X.; Yao, Q.; Yu, A.; Zhang, J.; Ji, Y. Accurate fault location using deep neural evolution network in cloud data center interconnection. IEEE Trans. Cloud Comput. 2022, 10, 1402–1412. [Google Scholar] [CrossRef]
- Li, C.; Yang, H.; Sun, Z.; Yao, Q.; Bao, B.; Zhang, J.; Vasilakos, A.V. Federated hierarchical trust-based interaction scheme for cross-domain industrial IoT. IEEE Internet Things J. 2023, 10, 447–457. [Google Scholar] [CrossRef]
- Yang, Z.; Yao, Y.; Gao, H.; Wang, J.; Mi, N.; Sheng, B. New YARN Non-Exclusive Resource Management Scheme through Opportunistic Idle Resource Assignment. IEEE Trans. Cloud Comput. 2021, 9, 696–709. [Google Scholar] [CrossRef]
- Eramo, V.; Lavacca, F.G.; Catena, T.; Perez Salazar, J.P. Application of a Long Short Term Memory neural predictor with asymmetric loss function for the resource allocation in NFV network architectures. Comput. Netw. 2021, 193, 108104–108116. [Google Scholar] [CrossRef]
- Feriani, A.; Hossain, E. Single and Multi-Agent Deep Reinforcement Learning for AI-Enabled Wireless Networks: A Tutorial. IEEE Commun. Surv. Tutor. 2021, 23, 1226–1252. [Google Scholar] [CrossRef]
- Giannopoulos, A.; Spantideas, S.; Tsinos, C.; Trakadas, P. Power Control in 5G Heterogeneous Cells Considering User Demands Using Deep Reinforcement Learning. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Crete, Greece, 25–27 June 2021; Springer: Cham, Switzerland, 2021; Volume 628. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Mur, D.C.; Gavras, A.; Ghoraishi, M.; Hrasnica, H.; Kaloxylos, A. (Eds.) AI and ML–Enablers for beyond 5G Networks; White Paper; 5G PPP Technology Board: Kista, Sweden, 2021. [Google Scholar]
- Yang, H.; Yao, Q.; Yu, A.; Lee, Y.; Zhang, J. Resource assignment based on dynamic fuzzy clustering in elastic optical networks with multi-core fibers. IEEE Trans. Commun. 2019, 67, 3457–3469. [Google Scholar] [CrossRef]
- Yu, A.; Yang, H.; Feng, C.; Li, Y.; Zhao, Y.; Cheriet, M.; Vasilakos, A.V. Socially-aware traffic scheduling for edge-assisted metaverse by deep reinforcement learning. IEEE Netw. 2023. [Google Scholar] [CrossRef]
- Li, C.; Yang, H.; Sun, Z.; Yao, Q.; Zhang, J.; Yu, A.; Vasilakos, A.V.; Liu, S.; Li, Y. High-Precision Cluster Federated Learning for Smart Home: An Edge-Cloud Collaboration Approach. IEEE Access 2023. [Google Scholar] [CrossRef]
- Eramo, V.; Catena, T. Application of an Innovative Convolutional/LSTM Neural Network for Computing Resource Allocation in NFV Network Architectures. IEEE Trans. Netw. Manag. 2022, 19, 2929–2943. [Google Scholar]

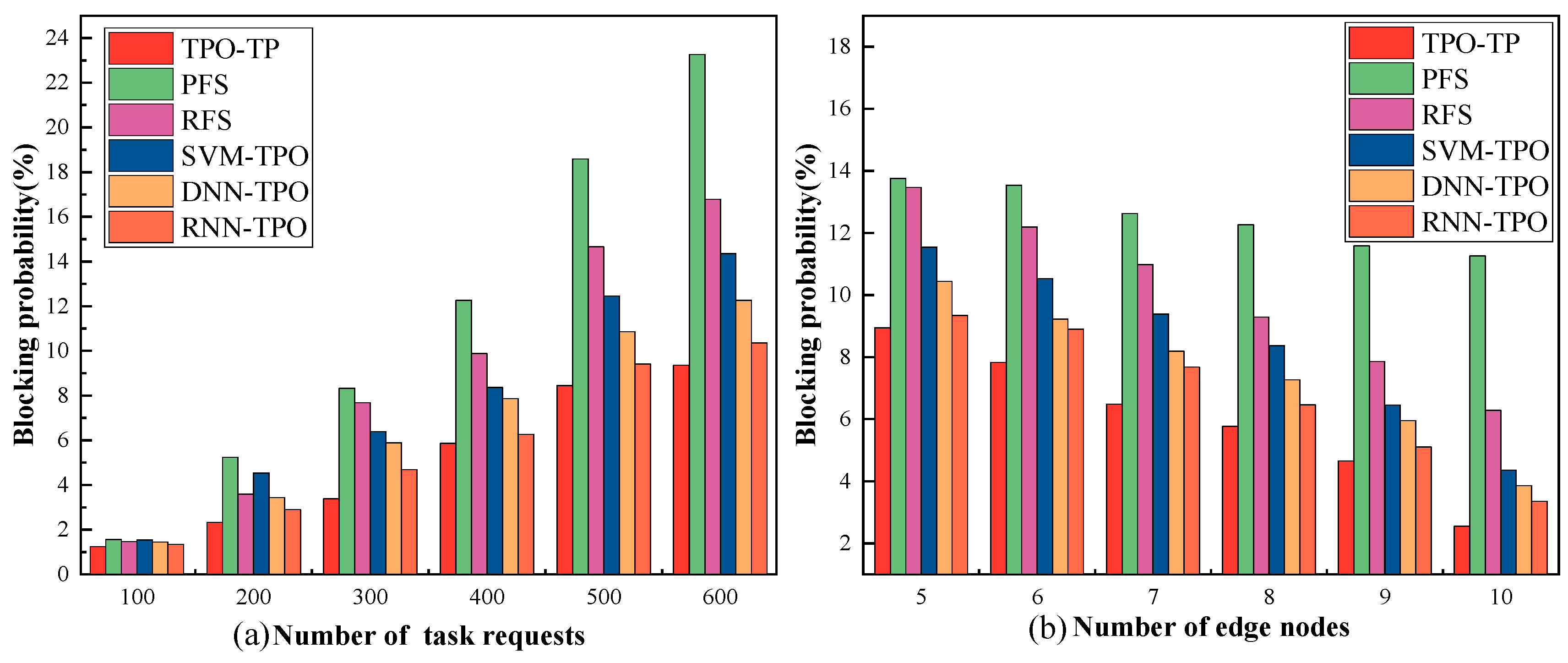

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| ML | The local MEC server |
| Pi | The taskset |
| Em | The candidate destination node set |
| Tri | The transmission delay |
| Tci | The processing delay |
| Ti | The total delay |
| R | The transmission rate |
| δm | The limit ratio of the maximum computing capacity |
| Ck | The computing capacity of the MEC server |
| λi,m | The task i is offloaded to the migrated server m |
| Ti,max | The delay threshold of task i |
| di | The data size of task i |
| Li(ao,ad) | The task i uses the link (ao,ad) |
| Di,m | The number of frequency slots allocated for transmitting task i |
| fsi(ao,ad) | The frequency slot fs in the optical path |
| Vi,m | The computing capacity allocated to task i by the server m |
| ci | The computing capacity required to process task i |
| DFS | The capacity of the frequency slot of the optical path |
| Algorithm | Accuracy (%) | MAE | MRE (%) | RMSE |
|---|---|---|---|---|
| LSTM | 94.2 | 0.21 | 3.24 | 0.27 |
| SVM | 84.9 | 0.46 | 6.83 | 0.59 |
| DNN | 86.4 | 0.35 | 4.35 | 0.42 |
| RNN | 93.4 | 0.26 | 3.96 | 0.31 |
| Algorithm | Computational Complexity |
|---|---|
| LSTM | O[4(nm + n2 + n)], n: hidden size, m: input size |
| SVM | O[Nsv3], Nsv: number of support vectors |
| DNN | O[8nd2], n: input size, d:vector dimension |
| RNN | O[nd2], n: input size, d:vector dimension |
| Schemes | Description of Scheme |
|---|---|
| PFS | Task offloading according to the principle of path priority without predicting before. |
| RFS | Task offloading according to the principle of resource priority without predicting before. |
| SVM-TPO | Task offloading based on SVM prediction results. |
| DNN-TPO | Task offloading based on DNN prediction results. |
| RNN-TPO | Task offloading based on RNN prediction results. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Yang, H.; Li, C.; Yao, Q.; Yu, A.; Zhang, J.; Zhao, Y.; Liu, S.; Li, Y. Task Offloading Scheme for Survivability Guarantee Based on Traffic Prediction in 6G Edge Networks. Electronics 2023, 12, 4497. https://doi.org/10.3390/electronics12214497
Sun Z, Yang H, Li C, Yao Q, Yu A, Zhang J, Zhao Y, Liu S, Li Y. Task Offloading Scheme for Survivability Guarantee Based on Traffic Prediction in 6G Edge Networks. Electronics. 2023; 12(21):4497. https://doi.org/10.3390/electronics12214497
Chicago/Turabian StyleSun, Zhengjie, Hui Yang, Chao Li, Qiuyan Yao, Ao Yu, Jie Zhang, Yang Zhao, Sheng Liu, and Yunbo Li. 2023. "Task Offloading Scheme for Survivability Guarantee Based on Traffic Prediction in 6G Edge Networks" Electronics 12, no. 21: 4497. https://doi.org/10.3390/electronics12214497
APA StyleSun, Z., Yang, H., Li, C., Yao, Q., Yu, A., Zhang, J., Zhao, Y., Liu, S., & Li, Y. (2023). Task Offloading Scheme for Survivability Guarantee Based on Traffic Prediction in 6G Edge Networks. Electronics, 12(21), 4497. https://doi.org/10.3390/electronics12214497