Abstract
The transferability of adversarial examples has been proven to be a potent tool for successful attacks on target models, even in challenging black-box environments. However, the majority of current research focuses on non-targeted attacks, making it arduous to enhance the transferability of targeted attacks using traditional methods. This paper identifies a crucial issue in existing gradient iteration algorithms that generate adversarial perturbations in a fixed manner. These perturbations have a detrimental impact on subsequent gradient computations, resulting in instability of the update direction after momentum accumulation. Consequently, the transferability of adversarial examples is negatively affected. To overcome this issue, we propose an approach called Adversarial Perturbation Transform (APT) that introduces a transformation to the perturbations at each iteration. APT randomly samples clean patches from the original image and replaces the corresponding patches in the iterative output image. This transformed image is then used to compute the next momentum. In addition, APT could seamlessly integrate with other iterative gradient-based algorithms, incurring minimal additional computational overhead. Experimental results demonstrate that APT significantly enhances the transferability of targeted attacks when combined with traditional methods. Our approach achieves this improvement while maintaining computational efficiency.
1. Introduction
In recent years, deep learning has rapidly developed and found applications in various fields, such as autonomous driving [1,2] and face recognition [3,4]. However, deep neural networks (DNNs) face the threat of adversarial examples [5,6]. Attackers can fool DNNs by adding some imperceptible disturbances to the input images. Given the susceptibility of neural networks to adversarial examples, DNNs encounter significant challenges in real-world applications. Several defenses [7,8,9,10,11] have been proposed to defend against adversarial examples. Additionally, numerous adversarial attack methods [6,7,12,13] have been developed to evaluate the robustness of DNNs.
However, in the real world, it is difficult for attackers to access all the information of the target model. So, white-box attack methods [6,7,12,13] are hard to apply in realistic scenarios. With decision-based black-box attacks [14,15], attackers do not need to grasp the internal structure of the model and have a certain viability, but it will take a large number of queries and time consumption. This will trigger the security system’s vigilance. If the defender limits the number of queries, the black-box attack will not succeed. The transferability of adversarial examples enables real-world attacks in black-box scenarios, where attackers lack knowledge of the model’s structure and parameters and are not required to query the target model.
In general, attack methods can be divided into two categories: targeted and non-targeted attacks. Targeted attacks aim to misidentify adversarial examples as a specific class, while non-targeted attacks focus on decreasing the accuracy of the victim model. Recent studies have proposed methods to enhance the transferability of non-targeted attacks [16,17,18,19,20], with the objective of reducing the accuracy of the target model. However, the success rate of transferable targeted attacks, where the attackers must deceive the victim model to produce a predetermined specific outcome, still remains lower than that of non-targeted attacks.
Overfitting to the source model is a primary factor contributing to the limited transferability of adversarial examples. To address this issue, several techniques have been proposed to enhance the transferability of adversarial examples. These techniques include input transformations [21], translation invariant attacks [22], advanced gradient computation [17,22,23], and advanced loss functions [24,25]. Among these, input transformation stands out as one of the most effective methods, drawing inspiration from data augmentation techniques used in model training [26]. By applying diverse transformations to input images, this approach aims to prevent adversarial examples from overfitting to the proxy model. However, most existing methods focus solely on diversifying individual input images, and these fixed transformations may still overfit to the internal environment of the source model, rendering them unsuitable for unknown black-box models.
Existing gradient iteration algorithms, such as MI-FGSM [17], have limitations in terms of generating adversarial perturbations with high transferability. These limitations arise due to the excessive consistency and redundancy in the perturbations generated during the iterative attack process, which is constrained by a perturbation budget. This consistency leads to a high degree of redundancy between successive perturbations, resulting in momentum accumulation in a fixed direction. As a result, the update direction becomes unstable, negatively impacting the transferability of adversarial examples.
The proposed Adversarial Perturbation Transform (APT) method aims to overcome these limitations and enhance the transferability of targeted attacks. APT randomly selects perturbed patches from the input image at each iteration and restores them to their original state, creating an admixed image. Then, this admixed image is included in the gradient calculation process. This approach effectively prevents excessive consistency and redundancy between successive perturbations, leading to a more stable update direction.
In summary, our main contributions are as follows:
- We identify the redundancy and consistency of adversarial perturbations generated during iterative attacks. They have a negative impact on the stability of the update direction.
- We introduce the inclusion of clean patches from the original input image to bootstrap the computation of gradients, presenting an effective method for enhancing the transferability of targeted attacks.
- Our method is compatible with most algorithms based on MI-FGSM and incurs minimal additional computational overhead. Empirical evaluations demonstrate that APT significantly improves the transferability of targeted attacks.
2. Related Work
The vulnerability of deep neural networks (DNNs) to adversarial examples was first mentioned by [5]. These adversarial images can exploit the vulnerability of the models to fool them, inducing the model to classify the samples into the wrong classes with high probability.
Szegedy et al. [5] initially used the LBFGS to generate adversarial examples. Due to the high computational cost, Goodfellow et al. [6] proposed the fast gradient sign method (FGSM), which effectively generates adversarial examples by performing a single gradient step. Kurakin et al. [27] used an iterative method ( I-FGSM ) to extend FGSM. To avoid local minima to improve transferability, ref. [17] incorporated the momentum iterative gradient method to boost the transferability effect of the generated adversarial examples.
Several techniques have been proposed to improve transferability by helping the image avoid falling into local minima and prevent overfitting to the specific source model. DI (Diverse Input) [21] randomly resizes and fills the image for each input. Zou et al. [28] introduced a three-stage pipeline, resizing diverse input, diversity ensemble, and region fitting, which work together to enhance the transferability. TI (Translation Invariant) [29] generates several translated versions of the current image and uses a convolution to approximate the gradient fusion. SI (Scale Invariant) [22] exploits the scale-invariant property of CNNs and uses multiple scale copies from each input image. Admix [30] randomly samples a set of images from other classes and computes the gradient of the original image mixed with a small portion of additional images while using the original labels of the input to make more transferable examples. Reference [31] trains a CNN as an adversarial transformation network, which neutralizes the adversarial perturbations and thus constructs more powerful adversarial examples. ODI (object-based diverse input) [32] renders images onto different 3D target objects and classifies the rendered objects into target classes, including different lighting and viewpoints, while it also requires additional computational overhead.
Lin et al. [22] incorporated the Nesterov accelerated gradient method into an iterative gradient-based attack to mitigate the issue of local optima in the optimization process. Wang et al. [23] addressed the instability of the update direction by considering the gradient variance from the previous iteration. They adjusted the current gradient based on this variance, which helped stabilize the update direction and improved the performance of the attack. The choice of loss function also plays a significant role in the effectiveness of targeted attacks. Li et al. [24] observed that using cross-entropy loss (CE) can lead to gradient vanishing during an attack. To increase targeted transferability, they proposed using Poincare distance as the loss function. However, Zhao et al. [25] argued that using Poincare distance can result in a large step size and a coarse loss function surface, leading to worse results compared to cross-entropy loss in different architecture models. They suggested using a simple logit loss for targeted attacks and emphasized the importance of conducting a sufficient number of iterations to generate effective adversarial examples.
3. Methodology
This paper focuses on the transferability of targeted attacks. It firstly describes the attack target and notation, then introduces details of the APT method and the motivation.
3.1. Preliminary
The attack method for generating adversarial examples can be considered an optimization problem. Let x be the input image with the ground-truth label y. indicates the neural network classifier, J be the loss function, and generated adversarial examples with target label . And the perturbation is constrained by the -norm which can be formulated as . Then, the targeted attack aims to solve the following optimization problem, presented by Equation (1).
Here, we use the logit loss as the loss function [25]. The formulation is Equation (2).
where denotes the logit output with respect to the target class.
3.2. Adversarial Perturbation Transform
Adversarial Perturbation Transform (APT) is a data enhancement technique that involves the following steps: Firstly, the input image x is divided into several patches denoted as , where m represents the total amount of patches in the image and with n being the dimensions of each patch. Secondly, during each iteration, a proportion p of clean patches is randomly sampled from the input image to obtain . This process results in an image with clean patches, where t denotes the t-th iteration. Mathematically, this can be represented as
In Equation (3), the Hadamard product is denoted by the symbol ⊙. We use a binary matrix in our algorithm, which consists of tiny matrices with a randomly distributed pattern of 0 and 1. The proportion of 1 s in is represented by p. In the next step, we remove the patches from the perturbed images that correspond to the 0 elements in . This results in an image with only perturbed patches. Mathematically, we achieve this using the following equation:
In Equation (4), I denotes the matrix with all elements equal to 1. In the final step, we combine and into a composite image, which consists of clean patches and perturbed patches. This fusion process can be achieved using the following equation, Equation (5):
Finally, is fed into the proxy model to participate in the gradient calculation, and we show the APT method involved in the MI-FGSM [17] attack process as an example in Algorithm 1.
| Algorithm 1:APT-MI-FGSM |
|
3.3. Motivations
Most existing gradient optimization methods [21,28,29,32] utilize MI-FGSM [17] as the baseline, which introduces momentum in the iterative attack process. This momentum helps to stabilize the update direction and prevents the convergence to poorer local maxima. However, generating more robust target adversarial examples requires a sufficient number of iterations [25]. The fixed perturbation input leads to redundancy during momentum accumulation, limiting the effectiveness within the perturbation budget. Figure 1 presents the gradient and momentum cosine similarity between iterative attacks. Figure 1a illustrates cases where the cosine similarity between two successive gradients is less than 0 when using MI-FGSM, indicating opposite directions. Consequently, the momentum after gradient accumulation does not converge sufficiently, resulting in an unstable update direction (Figure 1b).
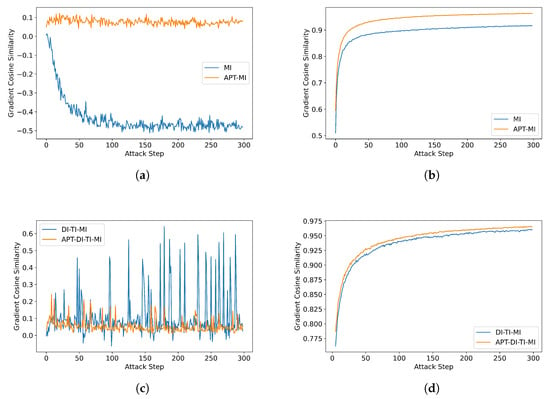
Figure 1.
Analysis of gradient and momentum cosine similarity between iterative attacks: (a) Cosine similarity between two successive gradients. (b) Cosine similarity between two successive momentums. (c) Cosine similarity between two successive gradients. (d) Cosine similarity between two successive momentums.
Data augmentation is an effective technique for enhancing the transferability of adversarial examples [21,22,28,29,30,32]. However, most existing input transformation methods focus on a single perturbed input image with relatively fixed transformations. While these methods alleviate over-fitting to some extent, the issue of gradient redundancy persists. DI-TI [21,29] transformation partially addresses the gradient direction problem (Figure 1c). However, part of the gradients in consecutive calculations remain highly similar, and the accumulated momentum is still insufficient for convergence (Figure 1d). The algorithm improved by APT makes the two continuous gradients maintain a low similarity, which ensures the momentum’s direction is more stable.
The transferability of adversarial examples can be seen as analogous to generalization in model training. While the latter trains a robust model for classification, the former aims to train a robust sample capable of successfully attacking various models. To simulate different unknown black-box environments, we introduce perturbation distortion by eliminating some perturbations and require the generated adversarial examples to resist this distortion.
We address the issue of gradient redundancy by randomly selecting reduced adversarial patches, making adjacent iterations of the input perturbation completely different. Calculating gradients for mixed patches has the potential to enhance the transferability of targeted attacks. It is important to note that APT differs from SI and Admix methods in that APT only changes part of the image, while SI and Admix change the whole image and generate multiple copies to calculate so that APT is more efficient.
4. Experiment
4.1. Experimental Settings
Dataset. We used a dataset compatible with ImageNet from the NIPS2017 Adversarial Attack and Defense Competition [33]. The dataset consists of 1000 images with dimensions and labels corresponding to ImageNet’s target class tasks for targeted attacks.
Models. We evaluated both undefended models (trained normally) and defended models as target models. For the undefended models, we selected Resnet50 (Res50) [34], DenseNet121 (Den121) [35], VGG16 [36], Inception-v3 (Inc-v3) [37], MobileNet-v2 (Mob-v2) [38], and Inception-Resnet-v2 (IR-v2) with different architectures. As for the defended models, we chose three adversarially trained models [39]: ens3-adv-Inception-v3 (Inc-v3-ens3), ens4-adv-Inception-v3 (Inc-v3-ens4), and ens-adv-Inception-Resnet-v2 (IR-v2-ens4).
Baselines. Since a simple transformation alone does not yield satisfactory results in terms of targeted transferability, we employed a composite method that combines several classical algorithms, namely MI [17], DI [21], RDI [28], ODI [32], and TI [29], as baselines for comparison.
Implementation details. We set the transformation probability to in DI and randomly enlarged the image size within the range of . The kernel convolution size in TI was set to 5. Regarding the hyperparameters used in the iterative process, we set the decay factor to 1, the step size to , the number of iterations to 300, and the perturbation size to . In the experiment evaluating APT attacks, we set the patch size n to 10 and the hyperparameter p to .
Evaluation Metrics. We measured the success rate of targeted attacks (suc), which indicates the percentage of instances where the black-box model was fooled into predicting the specified category.
4.2. Attacking Naturally Trained Models
In reality, attackers have no access to grasp all the information of the target model. Therefore, we set up experiments between different architectural models. This assumption aligns more with the real-world scenario.
The results of the APT with baseline attacks are shown in Table 1. From the results, APT is very effective in enhancing the transferability in targeted attacks. Taking ResNet50 as source model for example, the average performance improvements induced by APT are (DI-TI), (RDI-TI), and (ODI-TI), respectively. Comparing to the ResNet50 and DenseNet121, all attacks generally achieve lower transferability when using VGG-16 or Inception-v3 as the source models. This may be explained by the fact that skip connections in ResNet50 and DenseNet121 improve the transferability [40]. APT’s improvement of the effectiveness of adversarial attacks using weak transferability models is more obvious. For example, when Inception-3 was the source model, APT improved the average performance with (DI-TI), (RDI-TI), and (ODI-TI). However, for DenseNet121 and VGG16 as the source models, APT also consistently boosted the transferability under all cases.

Table 1.
Targeted fooling rates (%) of different attacks against various architectural models. The best results are highlighted in blue. * Indicates white-box attacks.
In Figure 2, we present visual comparisons of the adversarial examples generated by the DI-TI and APT-DI-TI attacks, using ResNet50 as the proxy model. The results demonstrate that there is little difference in the degree of perturbations between the adversarial examples generated by the two methods.

Figure 2.
Visualization of adversarial images generated on ResNet50.
4.3. Attacking Adversarially Trained Models
Adversarial training, proposed by Tramer et al. [39], is widely recognized as an effective defense method against adversarial attacks, especially targeted attacks. Fooling adversarially trained models into predicting the target class successfully is a challenging task. In this study, we employed an ensemble of white-box models, including Resnet50, DenseNet121, VGG16, and Inception-v3, which were trained naturally. The results presented in Table 2 illustrate the success rates of attacks on the adversarially trained models. Our findings demonstrate that the adversarially trained models effectively resisted the adversarial examples. However, APT increased the average success rate of the state-of-the-art (SOTA) method from 1.13% to 5.56%, indicating that adversarially trained defense models may still be vulnerable to adversarial attacks.
Table 2.
Targeted fooling rates (%) of black-box attacks against three defense models under multi-model setting. Best results are highlighted in blue.
4.4. Ablation Study
In this section, we conduct ablation experiments to study the influence of the hyperparameter p on the performance of three algorithms and different proxy models. These experiments enable an investigation into the sensitivity of our proposed method to the hyperparameter p and offer insights into the optimal value of p for achieving the highest performance.
Figure 3 demonstrates the average success rates of the three distinct methods across various hyperparameter values of p. Notably, APT-DI-TI, APT-RDI-TI, and APT-ODI-TI correspond to DI-TI, RDI-TI, and ODI-TI when , respectively. Upon observation, it becomes apparent that discarding a small portion of adversarial patches leads to a noteworthy improvement in transferability. Nevertheless, an excessive discarding of patches results in a substantial loss of gradient information, consequently leading to a reduction in transferability. The findings indicate that the optimal value of p depends on the specific baseline algorithm employed. Specifically, APT-DI-TI achieved the highest performance at , APT-RDI-TI exhibited the best performance at , and APT-ODI-TI performed optimally at . The results show that the value of p is very critical when using different baseline algorithms.
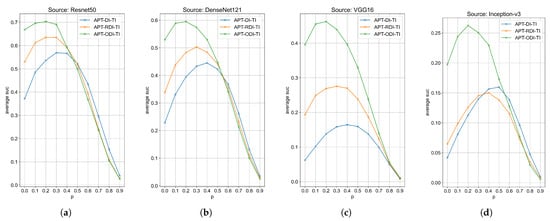
Figure 3.
Impact of p on targeted transferability between different architectural models. (a) Targeted attack success rates under different hyperparameters p against the source model Resnet50. (b) Targeted attack success rates under different hyperparameters p against the source model DenseNet121. (c) Targeted attack success rates under different hyperparameters p against the source model VGG16. (d) Targeted attack success rates under different hyperparameters p against the source model Inception-v3.
In addition, we observed variations in the selection of the optimal p value for different proxy models. Considering APT-DI-TI as the study object, it achieved the highest performance with when Resnet 50 was the source model. For Densenet21 or VGG16 as the proxy model, the optimal p value increased to . Furthermore, if Inception-v3 was the proxy model, APT-DI-TI performed best with . These results highlight the close relationship between proxy model selection and adjusting p, offering valuable guidance for further performance optimization.
5. Conclusions
In this paper, we identify the limitations of current gradient iteration algorithms for targeted attacks. We introduce a novel approach by considering the gradient information of clean patches in the image and proposing an improved method to enhance the transferability of adversarial examples. Our extensive experiments on ImageNet demonstrate that our proposed method, APT, achieves significantly higher success rates against black-box models compared to traditional attack methods. As a result, our method can serve as an effective benchmark for evaluating future defense mechanisms. For future work, we intend to consider other transforms and to investigate theoretical explanations for the high transferability of targeted attacks of perturbations.
Author Contributions
Formal analysis, project administration, writing—review and editing, and supervision, Z.D.; methodology, validation, formal analysis, writing—original draft preparation, and investigation, W.X.; validation and writing—review and editing, X.L.; data curation and supervision, S.H.; writing—review and editing, Y.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by Natural Science Foundation of Hainan Province (No. 620RC604, No. 623QN236), Hainan Province Higher Education Teaching Reform Research Funding Project (No. Hnjg2023-49, Hnjg2021-37, Hnjg2020ZD-14), the Science and Technology Project of Haikou (No. 2022-007), the Open Funds from Guilin University of Electronic Technology, Guangxi Key Laboratory of Image and Graphic Intelligent Processing (No. GIIP2012), 2022 Hainan Normal University’s Graduate Innovation Research Project (No. hsyx2022-91), the Hainan Province Key R&D Program Project (No. ZDYF2021GXJS010), the Major Science and Technology Project of Haikou City (No.2020006).
Data Availability Statement
Image data can be obtained at https://github.com/cleverhans-lab/
cleverhans/ tree/master/cleverhans_v3.1.0/examples/nips17_ adversarial_competition/dataset (accessed on 10 June 2023).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Sun, Z.; Balakrishnan, S.; Su, L.; Bhuyan, A.; Wang, P.; Qiao, C. Who is in control? Practical physical layer attack and defense for mmWave-based sensing in autonomous vehicles. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3199–3214. [Google Scholar] [CrossRef]
- Milz, S.; Arbeiter, G.; Witt, C.; Abdallah, B.; Yogamani, S. Visual slam for automated driving: Exploring the applications of deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 247–257. [Google Scholar]
- Raghavendra, R.; Raja, K.B.; Busch, C. Presentation attack detection for face recognition using light field camera. IEEE Trans. Image Process. 2015, 24, 1060–1075. [Google Scholar] [CrossRef] [PubMed]
- Arashloo, S.R. Matrix-regularized one-class multiple kernel learning for unseen face presentation attack detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4635–4647. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, C.; Rana, M.; Cissé, M.; van der Maaten, L. Countering Adversarial Images using Input Transformations. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A.L. Mitigating Adversarial Effects Through Randomization. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against adversarial attacks using high-level representation guided denoiser. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1778–1787. [Google Scholar]
- Song, Z.; Deng, Z. An Adversarial Examples Defense Method Based on Image Low-Frequency Information. In Proceedings of the Advances in Artificial Intelligence and Security, Dublin, Ireland, 19–23 July 2021; Sun, X., Zhang, X., Xia, Z., Bertino, E., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 204–213. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 25 May 2017. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cheng, M.; Le, T.; Chen, P.; Zhang, H.; Yi, J.; Hsieh, C. Query-Efficient Hard-label Black-box Attack: An Optimization-based Approach. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Li, Y.; Bai, S.; Zhou, Y.; Xie, C.; Zhang, Z.; Yuille, A. Learning transferable adversarial examples via ghost networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11458–11465. [Google Scholar]
- Zhou, W.; Hou, X.; Chen, Y.; Tang, M.; Huang, X.; Gan, X.; Yang, Y. Transferable adversarial perturbations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 452–467. [Google Scholar]
- Gao, L.; Zhang, Q.; Song, J.; Liu, X.; Shen, H.T. Patch-wise attack for fooling deep neural network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 307–322. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving transferability of adversarial examples with input diversity. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2730–2739. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, X.; He, K. Enhancing the transferability of adversarial attacks through variance tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 1924–1933. [Google Scholar]
- Li, M.; Deng, C.; Li, T.; Yan, J.; Gao, X.; Huang, H. Towards transferable targeted attack. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 641–649. [Google Scholar]
- Zhao, Z.; Liu, Z.; Larson, M. On success and simplicity: A second look at transferable targeted attacks. Adv. Neural Inf. Process. Syst. 2021, 34, 6115–6128. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Artificial Intelligence Safety and Security; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; pp. 99–112. [Google Scholar]
- Zou, J.; Pan, Z.; Qiu, J.; Liu, X.; Rui, T.; Li, W. Improving the transferability of adversarial examples with resized-diverse-inputs, diversity-ensemble and region fitting. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 563–579. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4312–4321. [Google Scholar]
- Wang, X.; He, X.; Wang, J.; He, K. Admix: Enhancing the transferability of adversarial attacks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 16158–16167. [Google Scholar]
- Wu, W.; Su, Y.; Lyu, M.R.; King, I. Improving the transferability of adversarial samples with adversarial transformations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9024–9033. [Google Scholar]
- Byun, J.; Cho, S.; Kwon, M.J.; Kim, H.S.; Kim, C. Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15244–15253. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S.; Dong, Y.; Liao, F.; Liang, M.; Pang, T.; Zhu, J.; Hu, X.; Xie, C.; et al. Adversarial Attacks and Defences Competition. arXiv 2018, arXiv:abs/1804.00097. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Wu, D.; Wang, Y.; Xia, S.; Bailey, J.; Ma, X. Skip Connections Matter: On the Transferability of Adversarial Examples Generated with ResNets. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).