4.1. Experimental Dataset
In this study, three publicly available datasets, namely, the Indian Pines dataset, the Salinas dataset, and the PaviaU dataset, are selected to evaluate the performance of each algorithm. The Indian Pines dataset contains a hyperspectral image acquired by Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) on 12 June 1992. This dataset covers an observed area located at the Indian Pines test site in northwestern Indiana. Similarly, the Salinas dataset, also obtained using the AVIRIS sensor, captured a hyperspectral image over the Salinas Valley region in southern California, USA, in 1992. Furthermore, the PaviaU dataset was collected over University of Pavia in northern Italy in 2003, utilizing Reflective Optics System Imaging Spectrometer (ROSIS). These datasets are widely recognized as standard datasets for researching feature extraction and classification methods in the field of hyperspectral images. They were acquired at different times and scenes, exhibiting variations in ground feature categories, resolution, coverage areas, and frequency bands. The utilization of these datasets enables us to assess algorithmic performance under diverse conditions and validate the effectiveness of different algorithms.
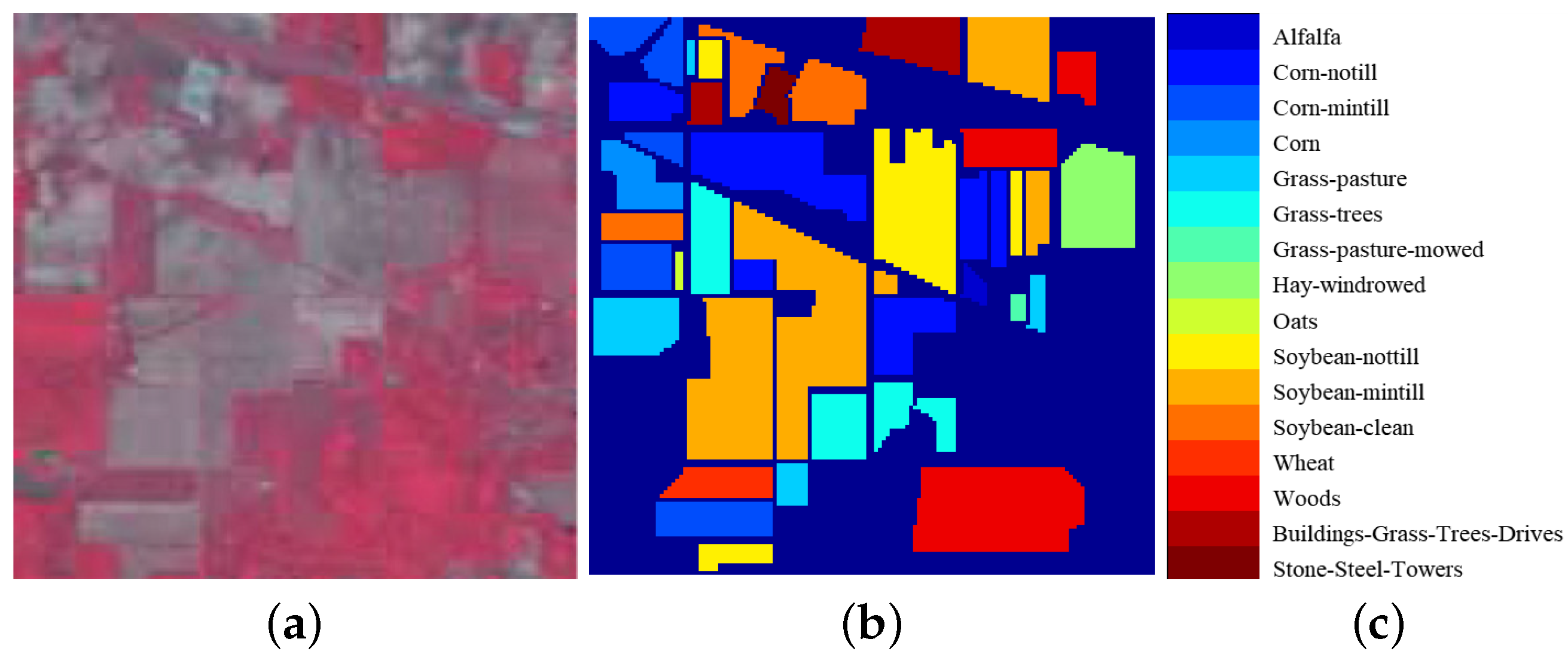
4.1.1. Indian Pines Dataset
The Indian Pines dataset employed in this study encompasses 16 distinct land feature classes and a total of 220 spectral bands. Typically, the number of bands is reduced to 200 by removing bands covering the region of water absorption; see, e.g., [104–108], [150–163], 220.
Figure 2 illustrates the pseudo-color map of the data, along with the class diagram representing the actual features and the corresponding category labels.
Table 1 provides detailed category information of the Indian Pines dataset.
4.1.2. Salinas Dataset
The Salinas dataset utilized in this research primarily encompasses land types such as vegetables and fallow land, and a total of 16 categories. For this study, 204 bands were employed for the experimental analysis, excluding the absorption bands.
Figure 3 visually presents the pseudo-color map of the data, the class diagram illustrating the actual features, and the corresponding category labels. Detailed category information of the Salinas dataset is provided in
Table 2.
4.1.3. PaviaU Dataset
The PaviaU dataset primarily consists of nine categories representing different land features, including asphalt and grassland.
Figure 4 provides a pseudo-color map of the data, along with the class diagram depicting the actual features and their corresponding category labels. Detailed category information of the PaviaU dataset is presented in
Table 3.
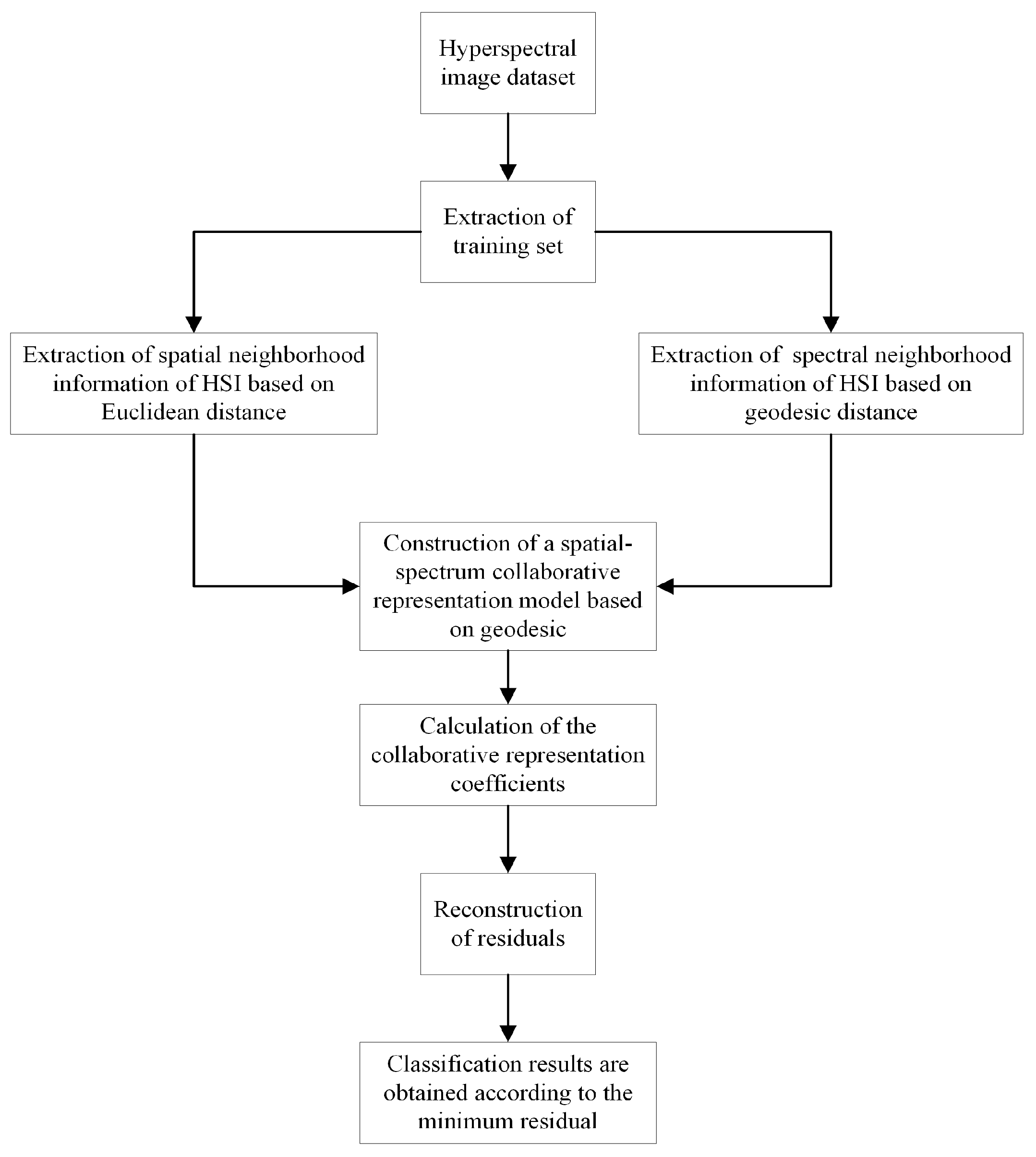
4.2. Experimental Results and Analysis
To validate the classification performance of the GSSCRC algorithm, several comparison algorithms, namely, Support Vector Machine (SVM), Sparse Representation Classification (SRC), Kernel Sparse Representation Classification (KSRC), and Joint Cooperative Representation Classification (JCR), are reported in this section. The evaluation criteria used to quantitatively assess the experimental results include average classification accuracy (AA), overall classification accuracy (OA), and kappa coefficient (Kappa).
In the experiments, the selection of the number of neighbors, denoted by k, was set to 7. Specific parameter settings were used for each dataset, where , for the Indian Pines dataset; for the Salinas dataset; and for the PaviaU dataset. For the Indian Pines dataset, 10% of the data were used for training, with the remaining data serving as the test samples. Similarly, for the Salinas dataset, 5% of the data were allocated for training, and for the PaviaU dataset, 10% of the data were used as the training samples. The chosen partitioning strategy was selected to directly reflect the scarcity of labeled hyperspectral data in a real scenario. For each dataset, we dedicated a significant portion to the testing set while allocating a comparatively smaller proportion for training. This deliberate division allows us to effectively assess and validate the performance of the proposed method, even when operating with a restricted number of training samples.
Once the necessary parameters were set, the GSSCRC algorithm could be compared and analyzed against the other algorithms to assess its overall performance. The experimental results are presented in the form of graphs.
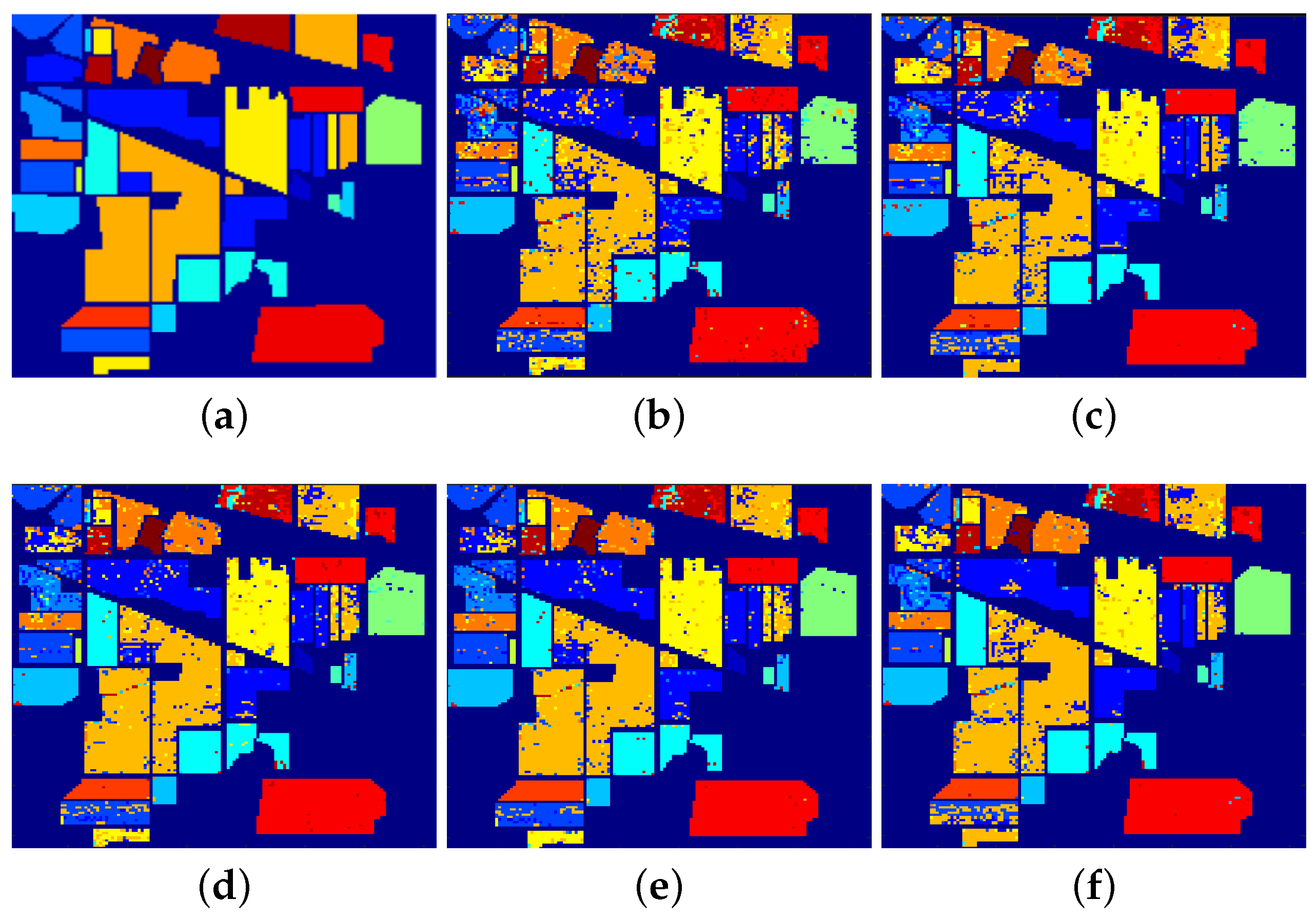
Table 4 and
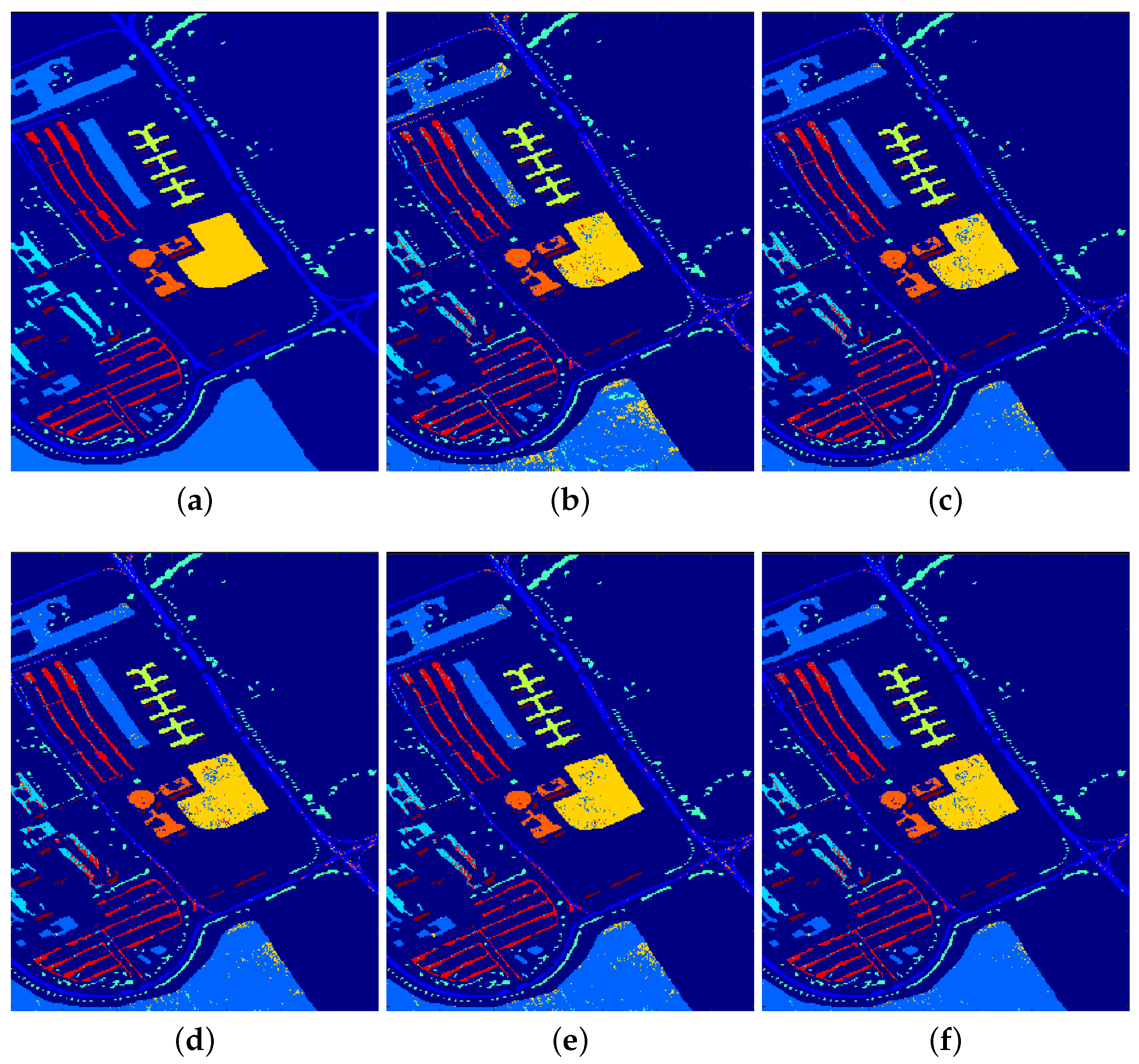
Figure 5 provide a detailed overview of the classification results and visualization of the effects achieved by the GSSCRC algorithm and the other algorithms for each feature within the Indian Pines dataset, respectively.
Based on the data presented in
Table 4, it is evident that the GSSCRC algorithm proposed in this study exhibits improved classification accuracy for most ground objects compared with other classification methods. In comparison to the SVM, SRC, and KSRC algorithms, which solely utilize spectral information, as well as the JCR algorithm, which incorporates both spatial and spectral information, the GSSCRC algorithm achieved higher OA, AA, and kappa coefficient. These results indicate that by employing geodesic-based spectral neighbor information selection, the GSSCRC algorithm effectively extracts spectral discrimination information. Additionally, the GSSCRC algorithm leverages the combination of spectral and spatial information, enabling it to extract a greater amount of information. Therefore, the GSSCRC algorithm proposed in this study demonstrates promising potential for improving the accurate classification of ground objects.
Figure 5 illustrates the classification results obtained using the GSSCRC algorithm and the comparison algorithms on the Indian Pines dataset. The graph highlights that the algorithm proposed in this study exhibits classification performance that closely resembles the actual terrain map of the Indian Pines dataset. It is observed that the misclassification of terrain pixels is relatively minimal, resulting in a smoother overall effect. Particularly, the algorithm demonstrates superior performance in the classification of the Hay Windrowed and Corn-notill features compared with the other algorithms.
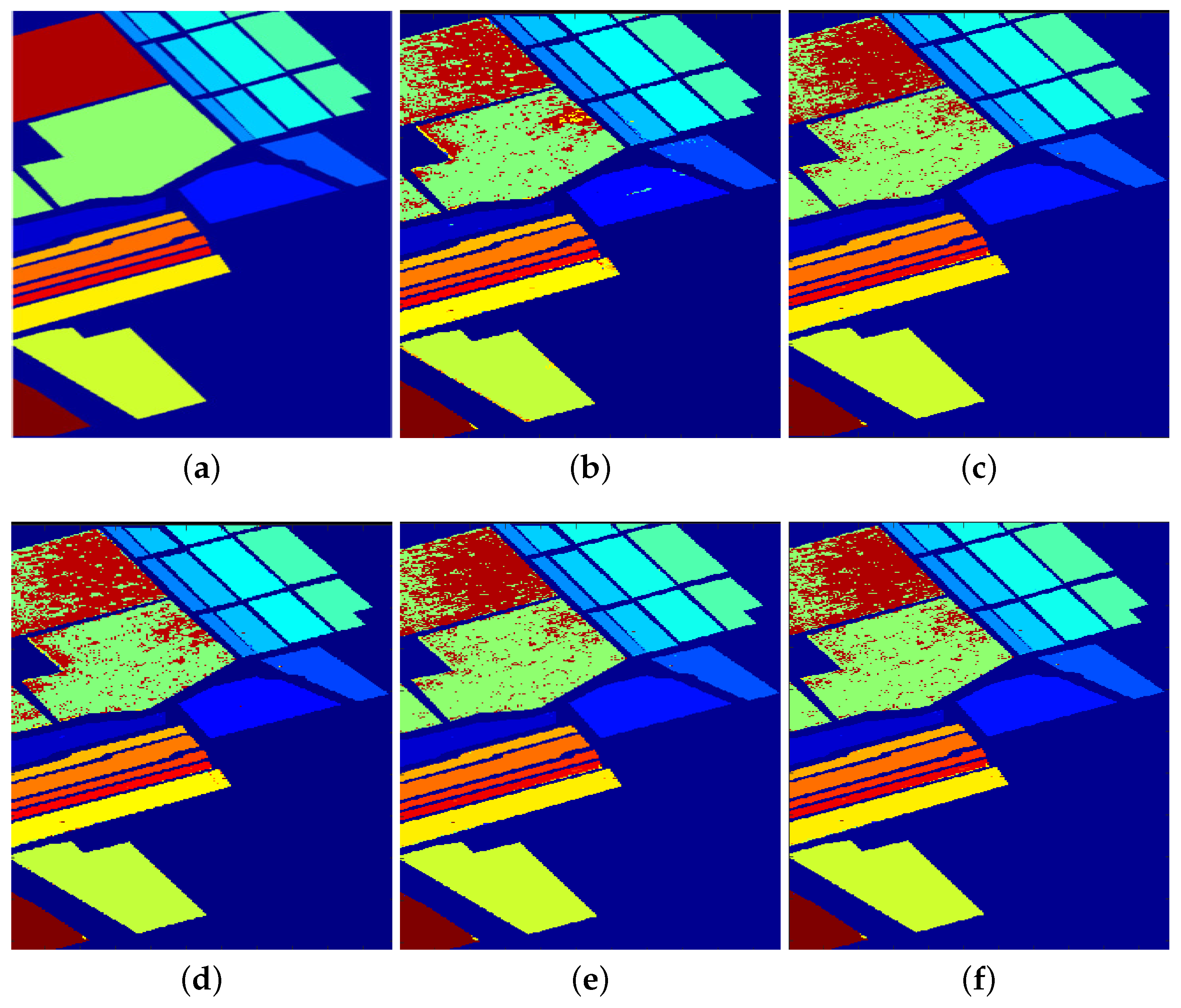
Moving forward, the experiment was conducted on the Salinas dataset. The detailed classification results and the classification effects of the GSSCRC algorithm and other algorithms for different features on the Salinas dataset are presented in
Table 5 and
Figure 6, respectively.
Based on the data presented in
Table 5, it is evident that the GSSCRC algorithm proposed in this paper significantly improved the classification accuracy compared with other classification methods. Furthermore, the GSSCRC algorithm exhibited slightly higher values for OA, AA, and Kappa coefficient when compared with other algorithms. Notably, the algorithm demonstrated correct classification of ground objects of class 1 and class 9, indicating the beneficial effect of geodesic distance on selecting spectral nearest-neighbor information and affirming the effectiveness of the algorithm.
Figure 6 provides a visual representation of the classification performance of the GSSCRC algorithm and the comparison algorithms on the Salinas dataset. Upon analyzing the classification performance of each algorithm, it can be concluded that the algorithm proposed in this study achieved classification results that closely resemble the real terrain map of the Salinas dataset. The algorithm exhibited fewer misclassifications in the dataset, resulting in a smoother overall effect. Particularly, in the classification of the weeds1 and Soil land features, the performance of the GSSCRC algorithm surpassed that of other algorithms. This observation highlights the capability of the GSSCRC algorithm of extracting spectral information more comprehensively with the usage of geodesic distance for selecting spectral nearest-neighbor information. By incorporating spatial information from hyperspectral images, the algorithm effectively captures the deep characteristics of hyperspectral image data.
To further validate the effectiveness of the GSSCRC algorithm, experiments were conducted on the PaviaU dataset. The detailed classification results and classification effects of the GSSCRC algorithm, along with those of other algorithms, are presented in
Table 6 and
Figure 7, respectively.
From the data in
Table 6, it is evident that the GSSCRC algorithm proposed in this paper significantly improved the classification accuracy compared with other classification methods. The OA, AA, and Kappa coefficient of the GSSCRC algorithm are slightly higher than those of other algorithms, indicating the effectiveness of using geodesic distance in the selection of spectral nearest-neighbor information.
Figure 7 presents the classification effect maps of the GSSCRC algorithm and the comparison algorithms on the PaviaU dataset. By observing the classification effect map of each algorithm, it can be concluded that in the Asphalt, Meadow, and Gravel regions, there are fewer misclassified pixels of ground features compared with the comparison algorithms, resulting in a smoother overall effect map. This demonstrates that the GSSCRC algorithm proposed in this paper can effectively reveal the intrinsic features hidden behind a hyperspectral image by combining the geodesic-based spectral information and spatial information.
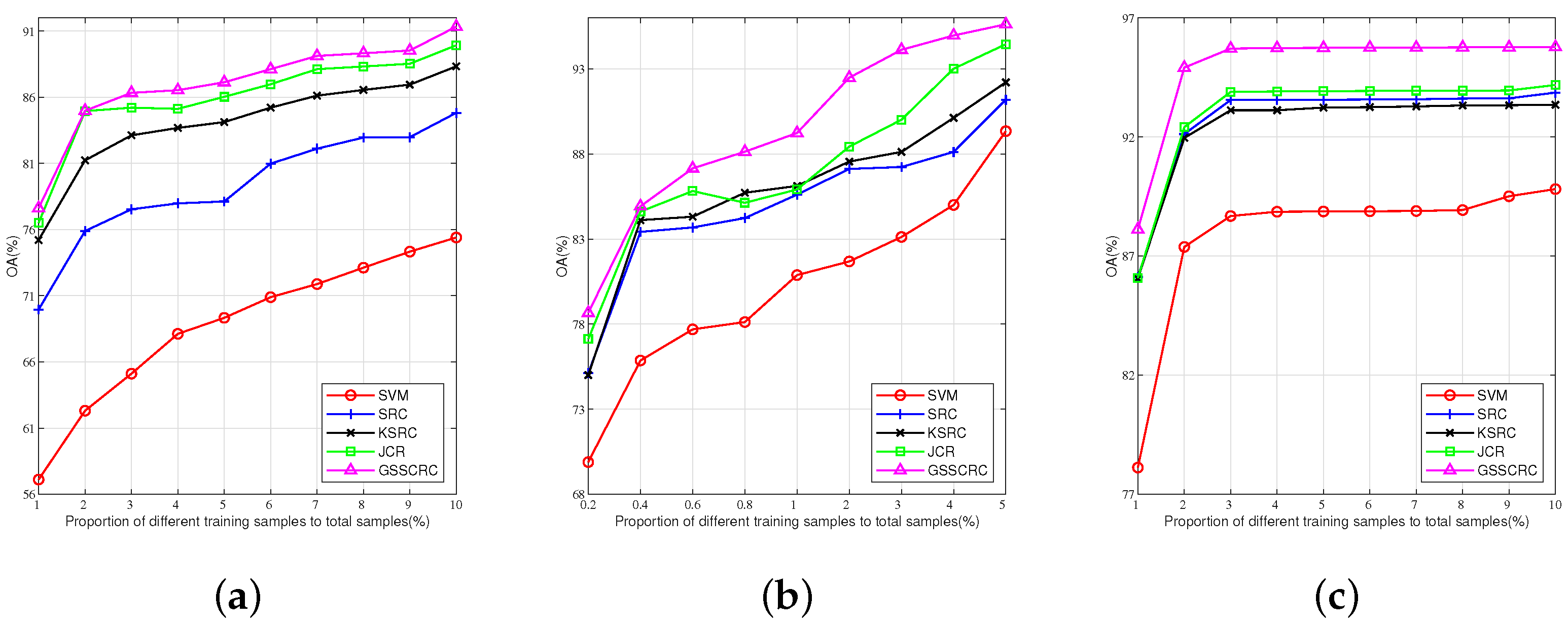
In order to examine the impact of the GSSCRC algorithm, as well as that of the SVM, SRC, KSRC, and JCR algorithms, on the overall classification results with varying numbers of training samples, this study conducts experiments on three datasets to assess the influence of different training sample sizes. For the Indian Pines dataset, the selected training sample proportions range from 1% to 10%, with the remaining samples being used as the test sample set. Similarly, for the Salinas dataset, the proportions range from 0.2% to 5%, and for the PaviaU dataset, the proportions range from 1% to 10%. The effect of different training sample sizes on the classification performance is depicted in
Figure 8.
Figure 8 illustrates the impact of different algorithms on the overall classification accuracy with varying training sample sizes across the three datasets. From
Figure 8a–c, it is evident that as the proportion of training datasets increases, the OA values of each algorithm also increase correspondingly.
To compare the running time of the GSSCRC algorithm with that of the SVM, SRC, KSRC, and JCR algorithms,
Table 7 presents the running time results of GSSCRC and the comparison algorithms on different datasets. It can be observed that SVM had the shortest running time, followed by the SRC, KSRC, and JCR algorithms. However, the GSSCRC algorithm in this paper had the longest running time due to the additional computational resources required for spectral information nearest-neighbor selection. Furthermore, the computation of the regularization term based on the competitive representation of spatial and spectral information also contributes to the increased computational cost. It is expected that the efficiency of the algorithm can be improved by combining some optimization methods [
48,
49]. Image processing combined with machine learning [
50,
51] may also bring some improvements. Despite the higher computational resource consumption, the GSSCRC algorithm demonstrates satisfactory classification performance, surpassing other similar algorithms in various aspects.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}