
An Efficient Object Navigation Strategy for Mobile Robots Based on Semantic Information



Abstract
:1. Introduction
2. Related Works
2.1. Robot Visual SLAM Systems
2.2. Robot Navigation Strategy
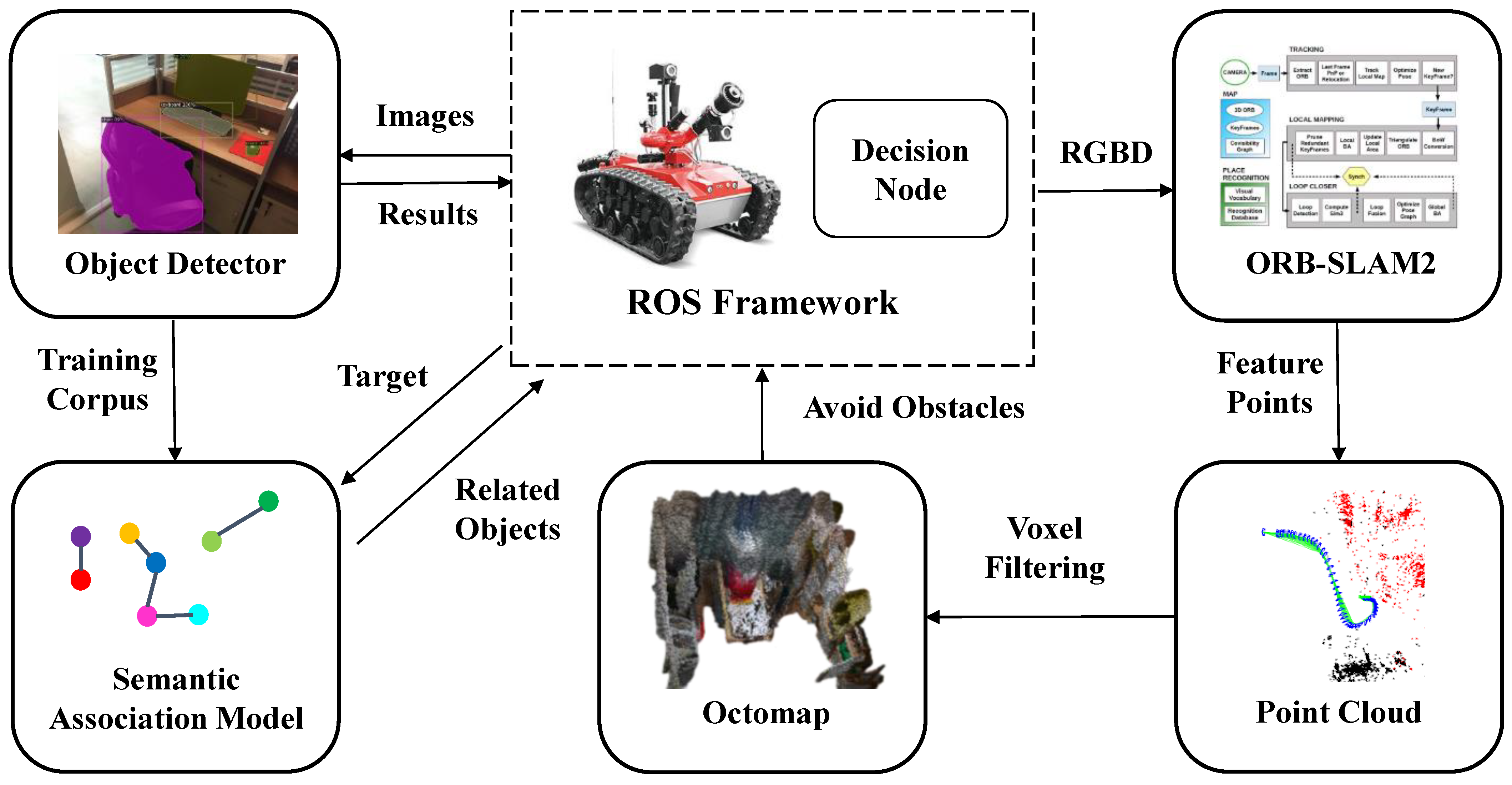
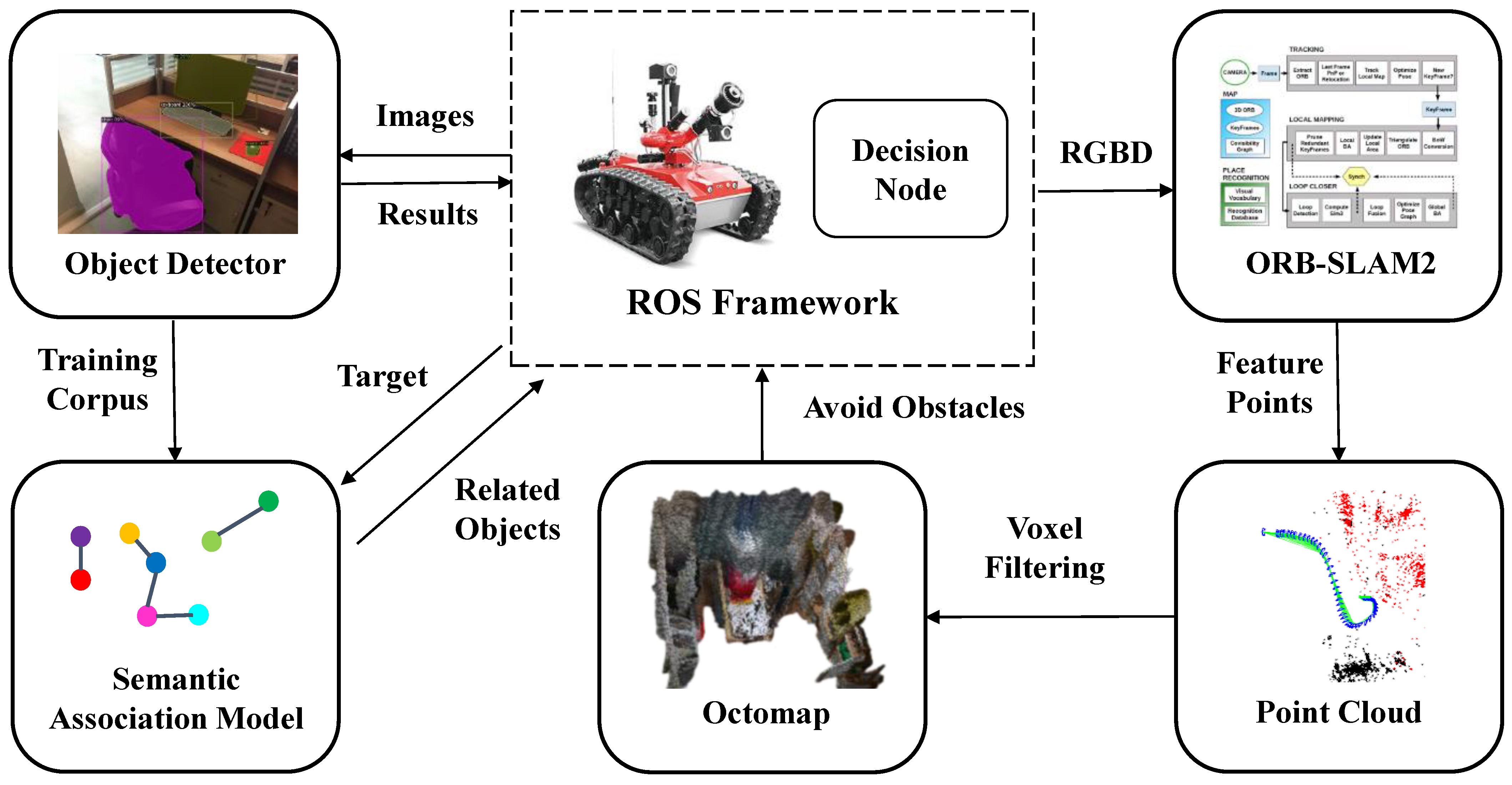
3. Autonomous Exploration and Object Navigation System
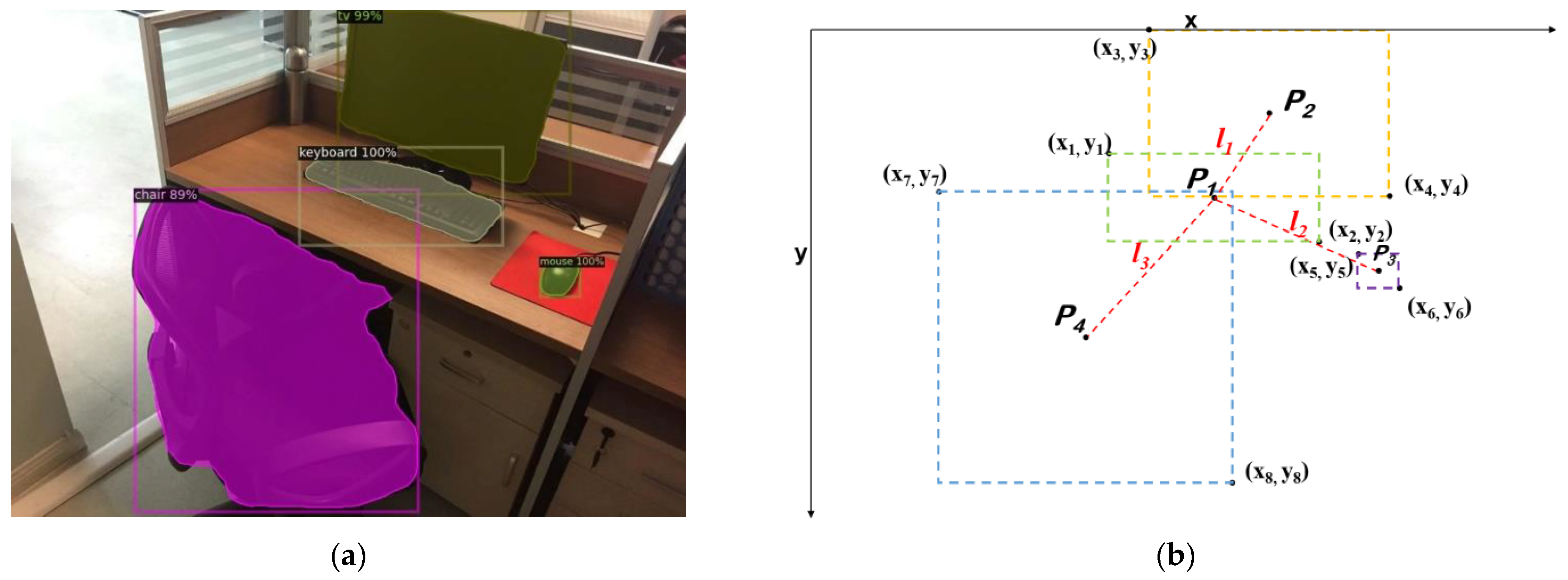
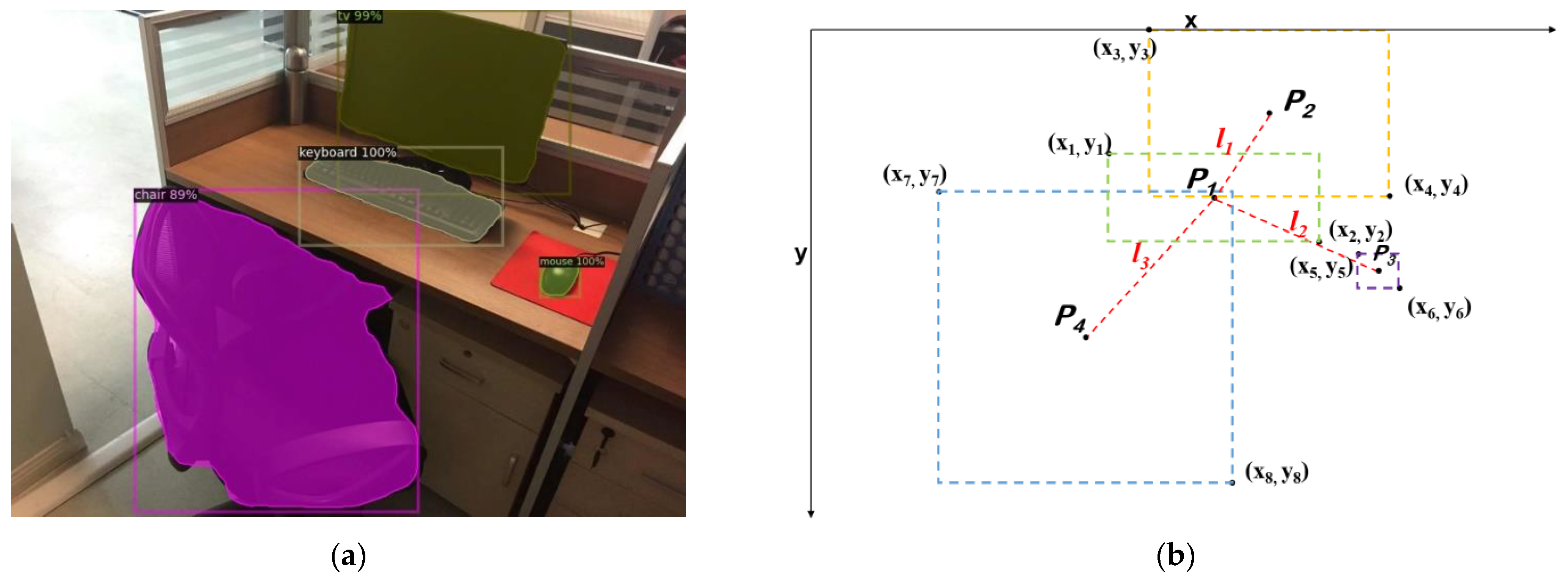
3.1. Objects Detection Using Mask R-CNN
3.2. Semantic Association Model Based on Co-Occurrence Probability
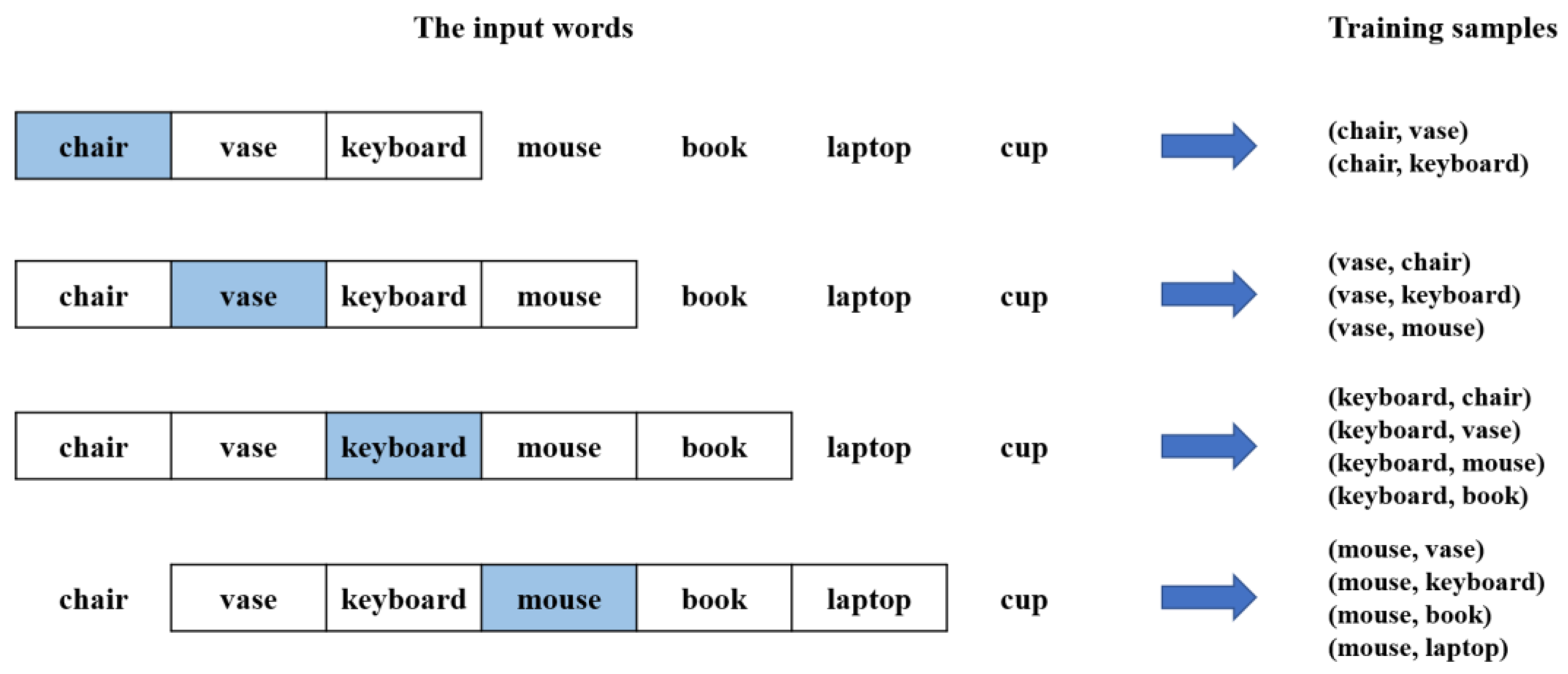
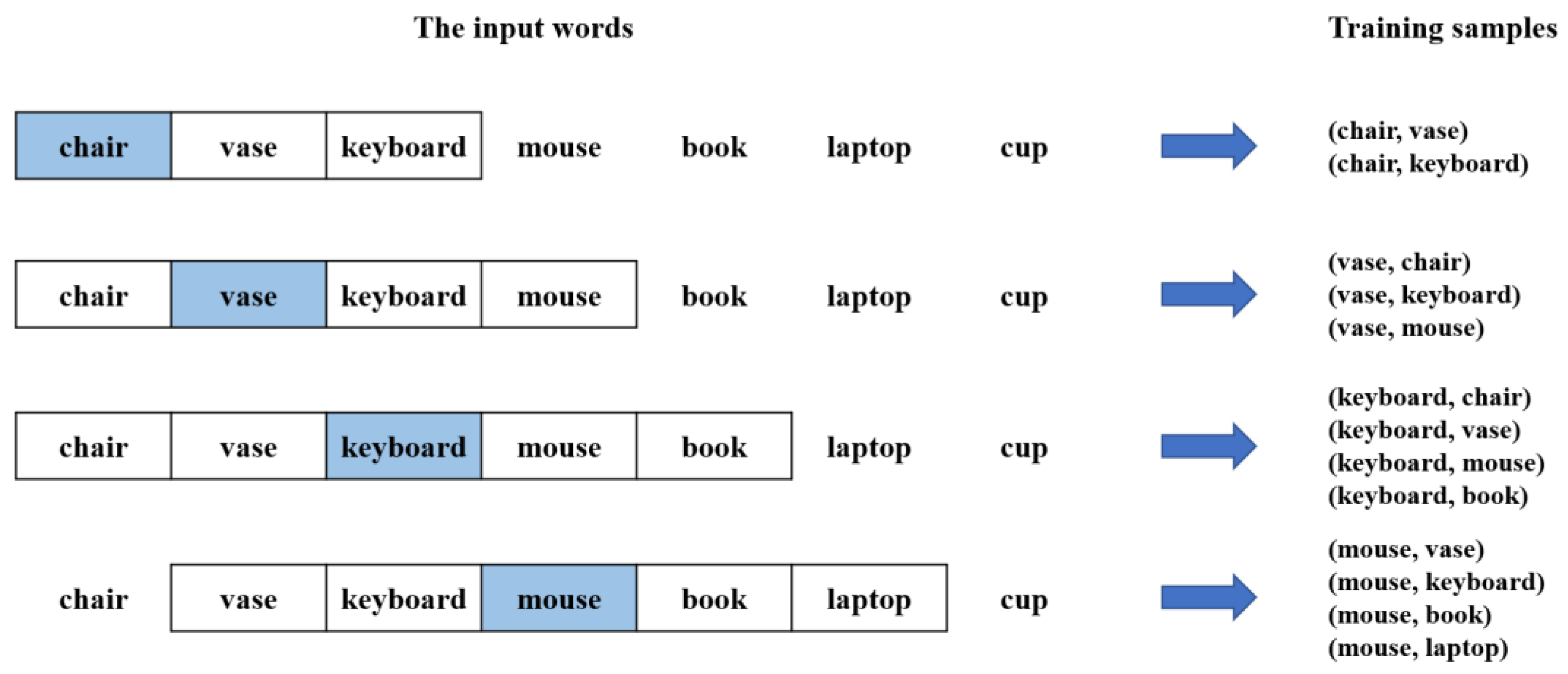
3.2.1. Corpus Processing
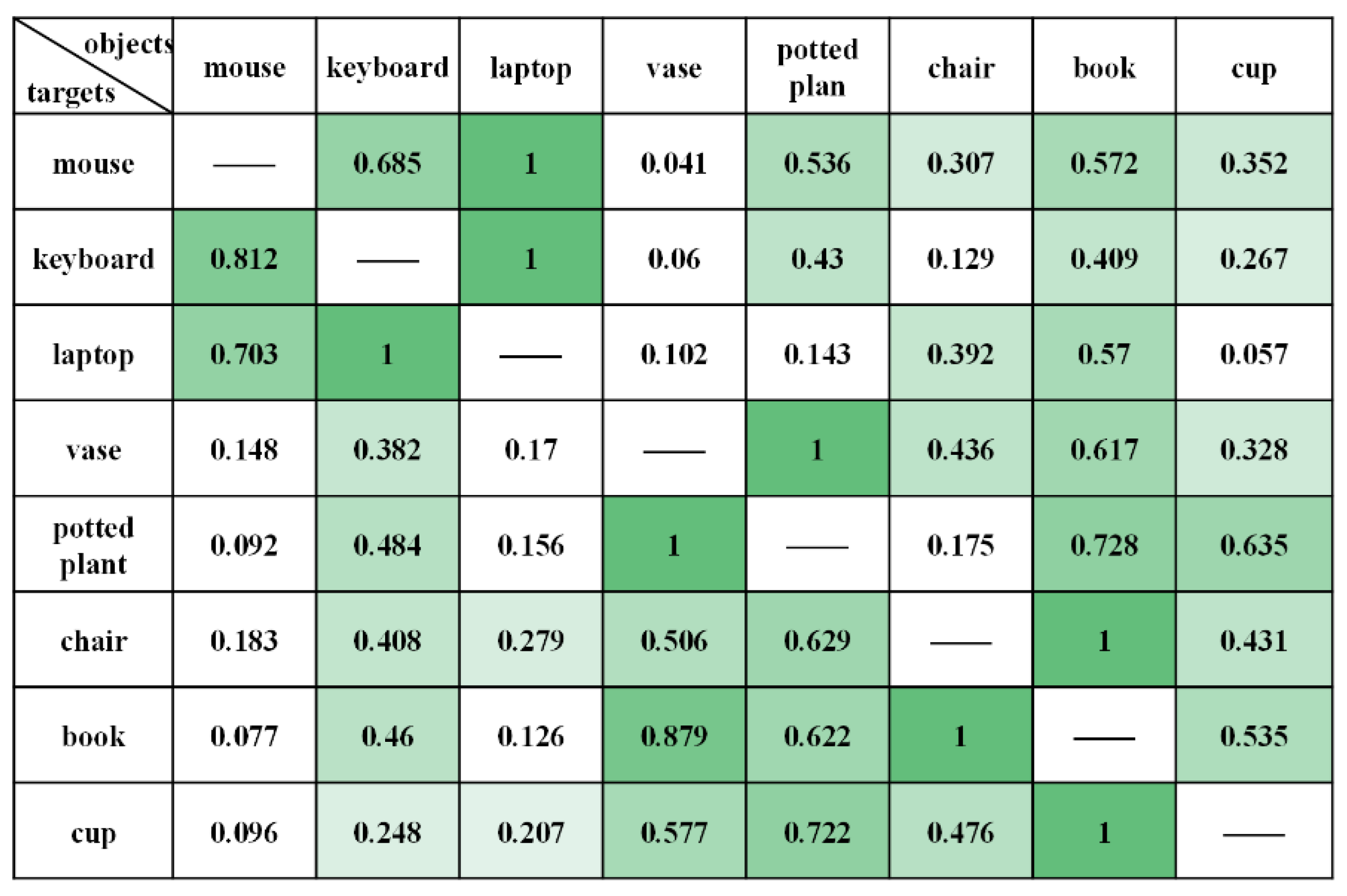
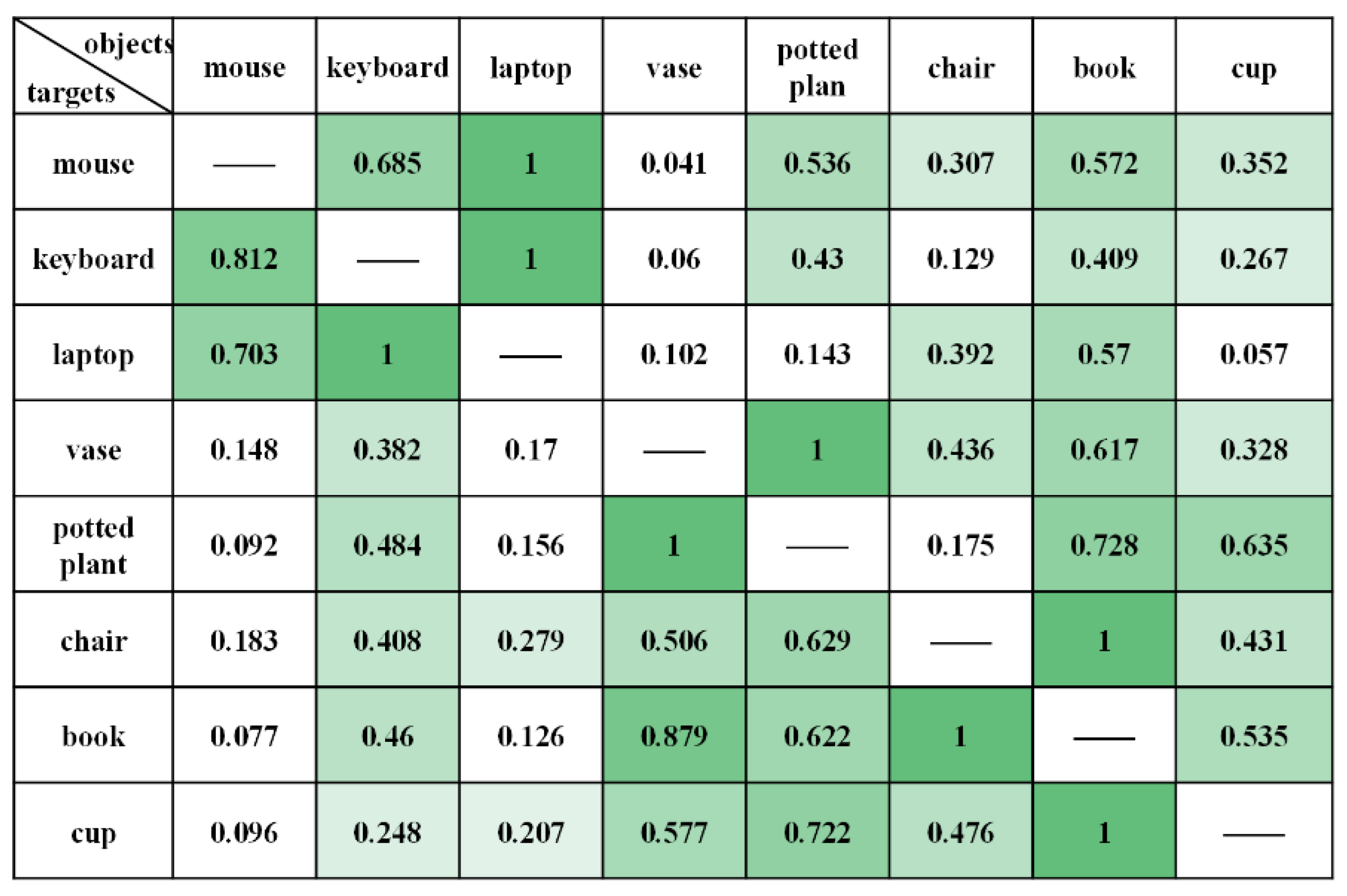
3.2.2. Semantic Relevance Extraction
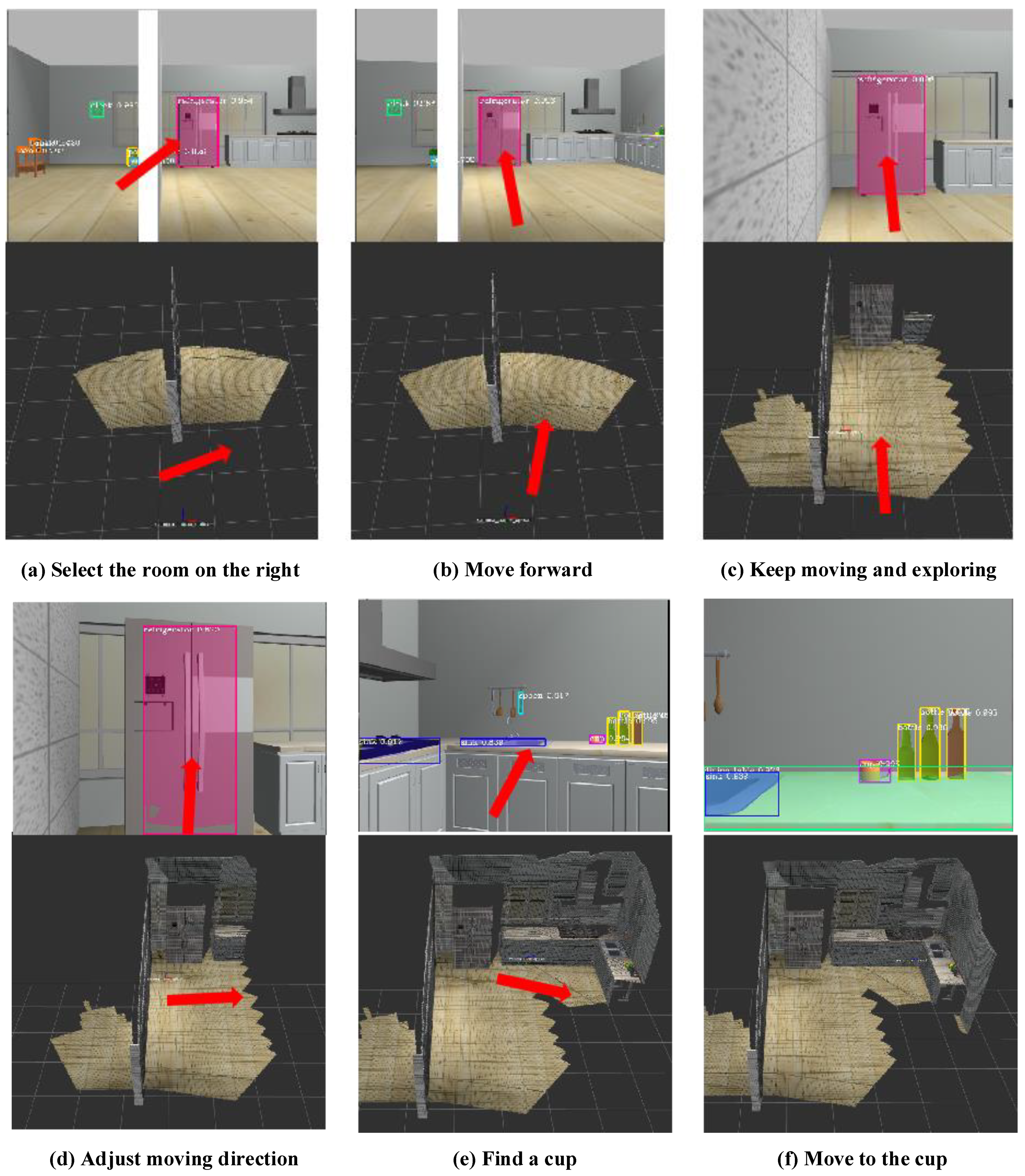
3.3. Goal-Driven Navigation Strategy
3.3.1. Basic Workflow of the Decision Node
3.3.2. Octomap Map Building
3.3.3. Local Navigation Policy
4. Experiments and Discussions
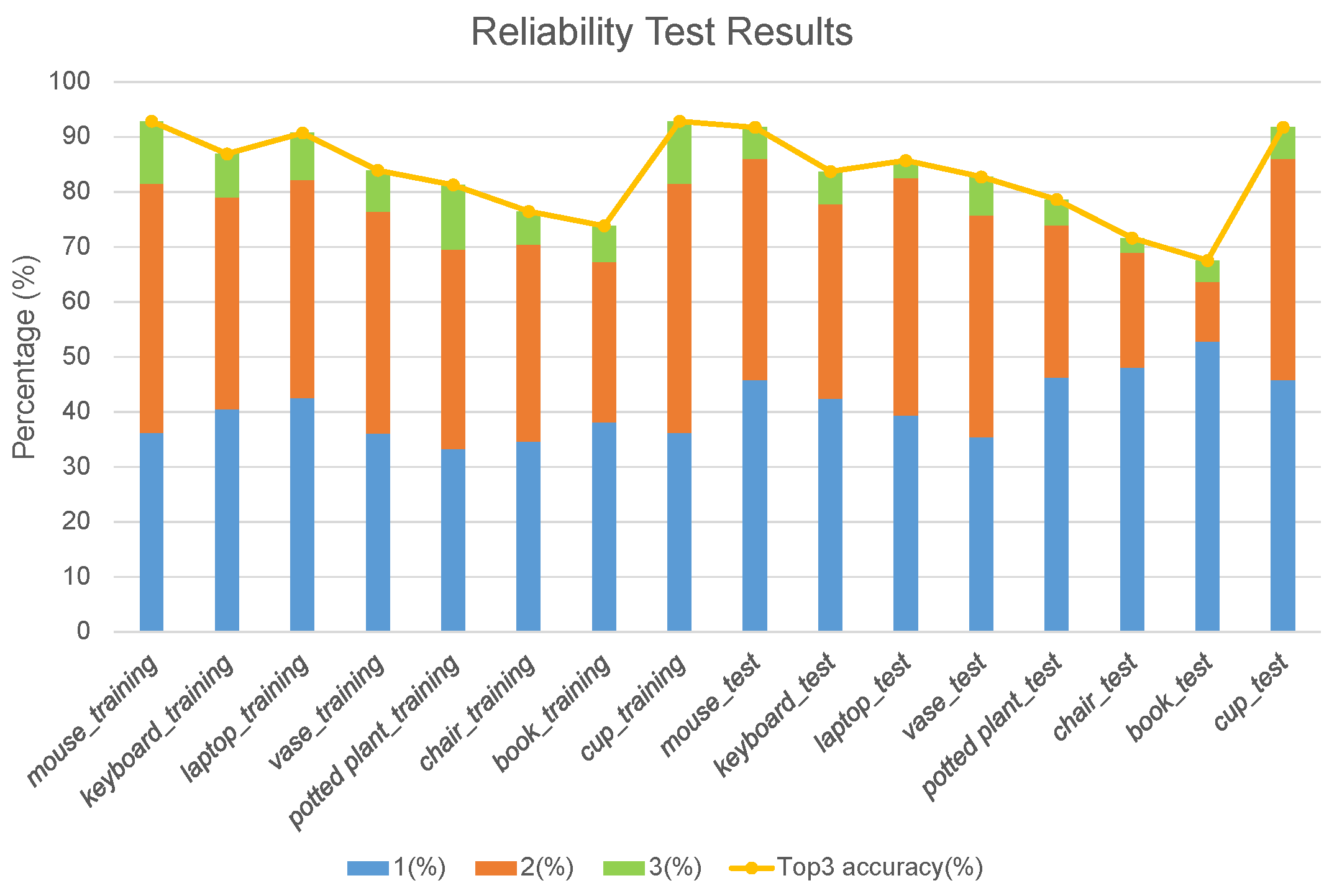
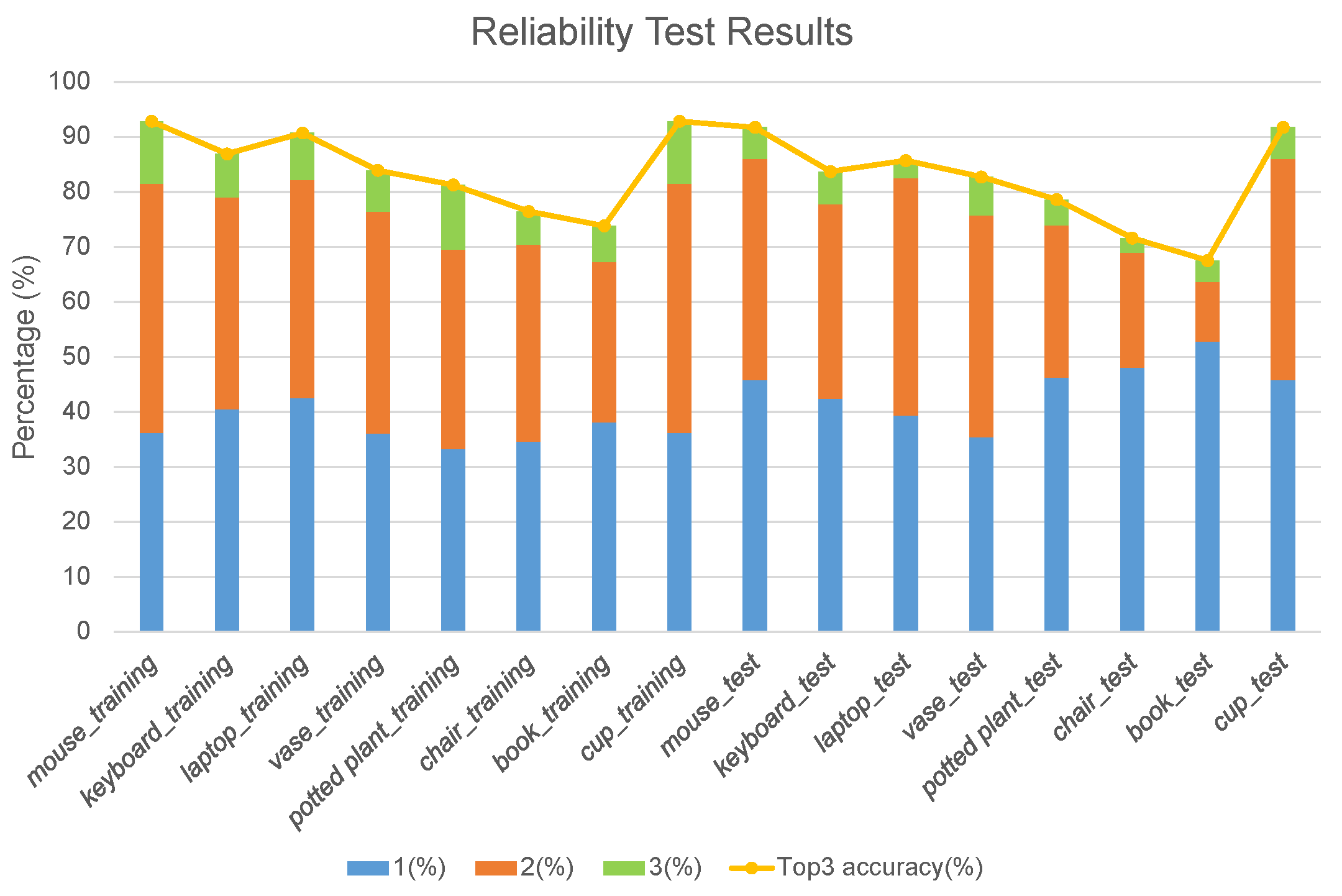
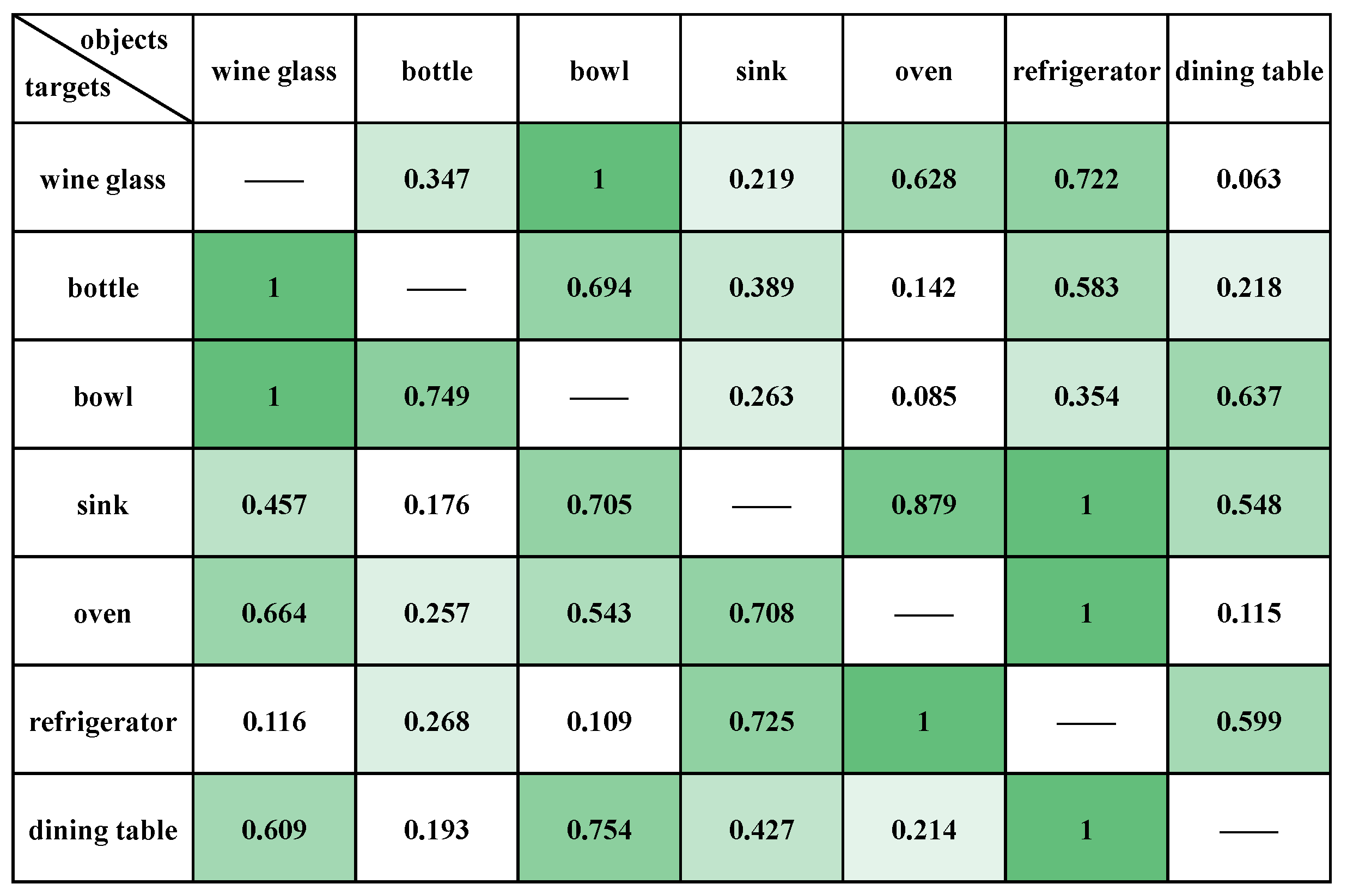
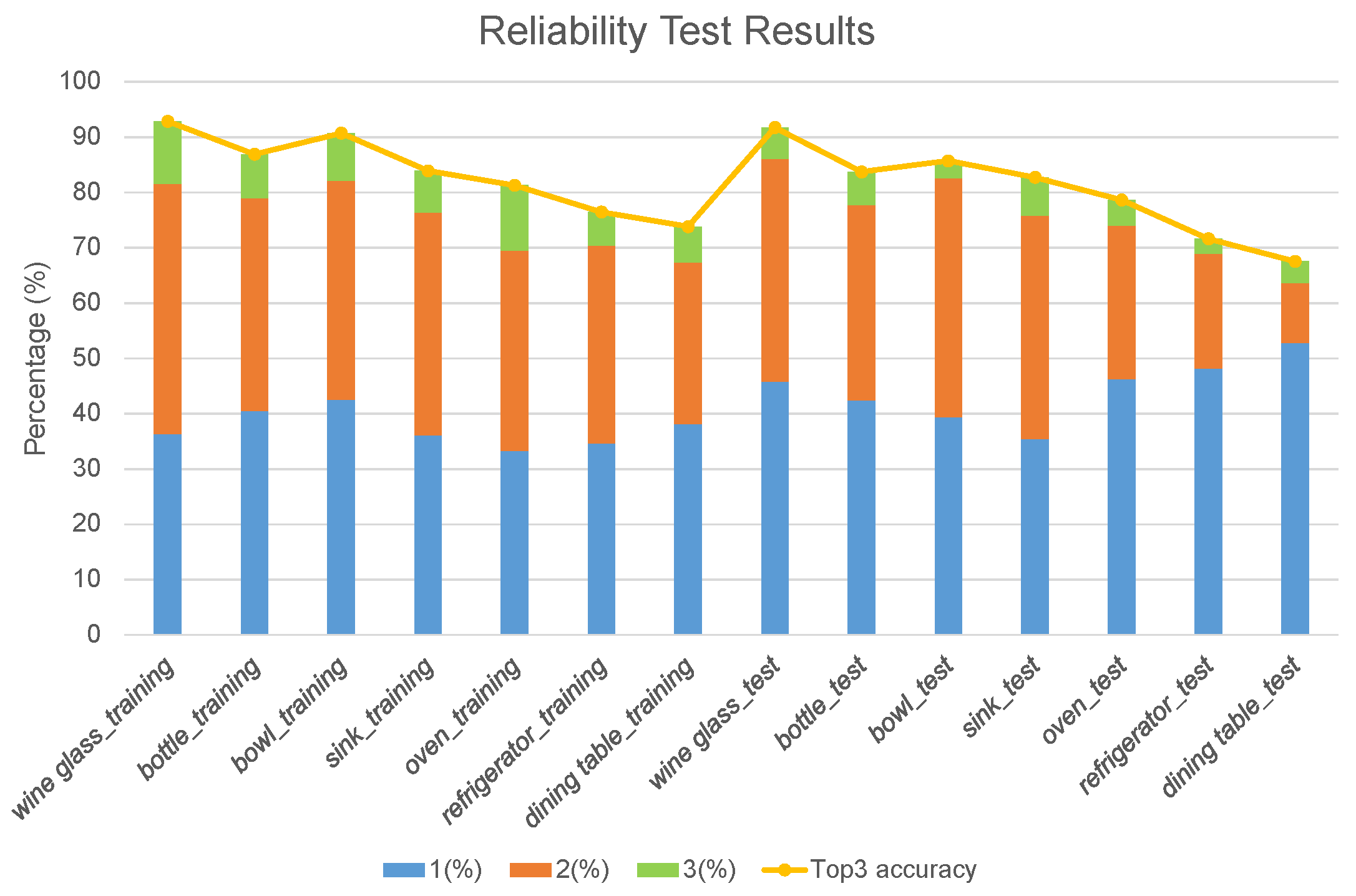
4.1. Verification of the Semantic Association Model
4.1.1. Office Places
4.1.2. Kitchen Places
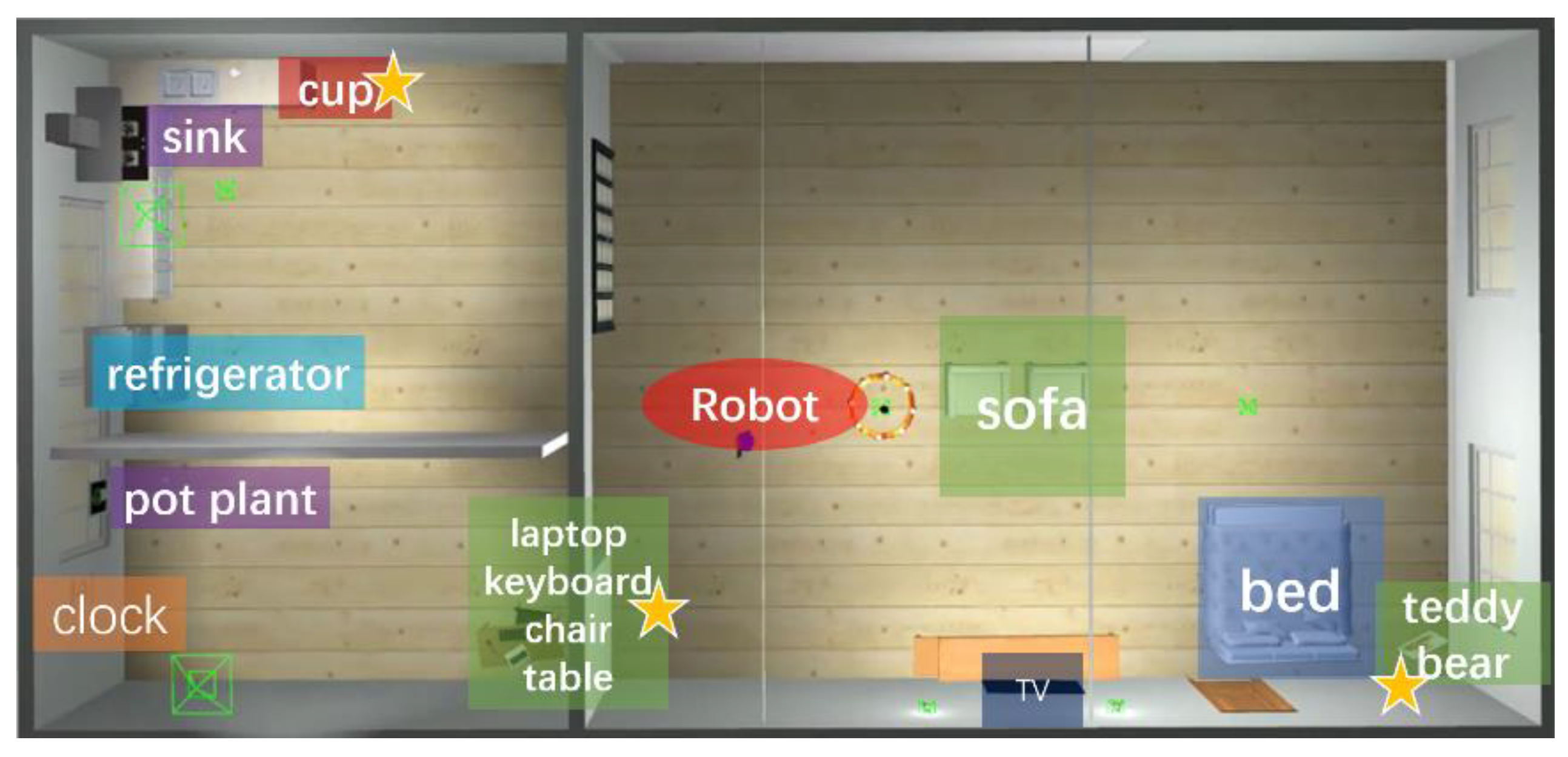
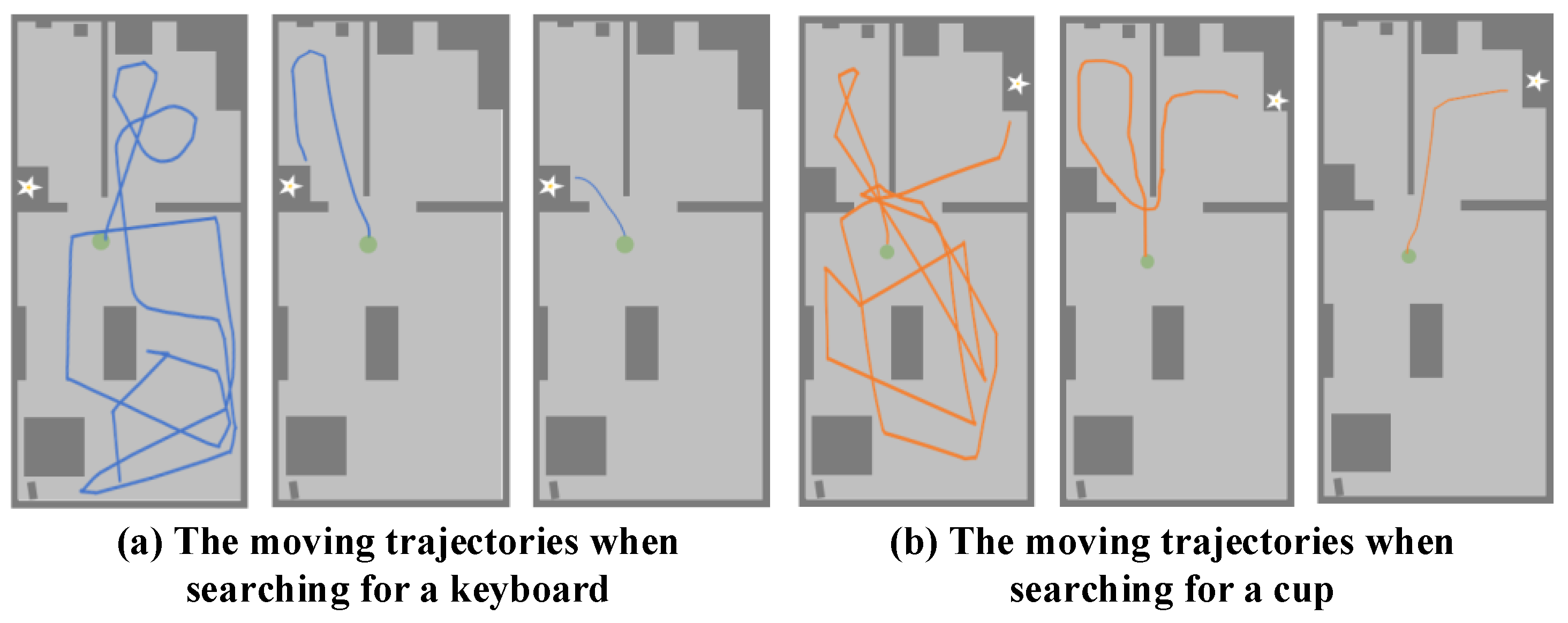
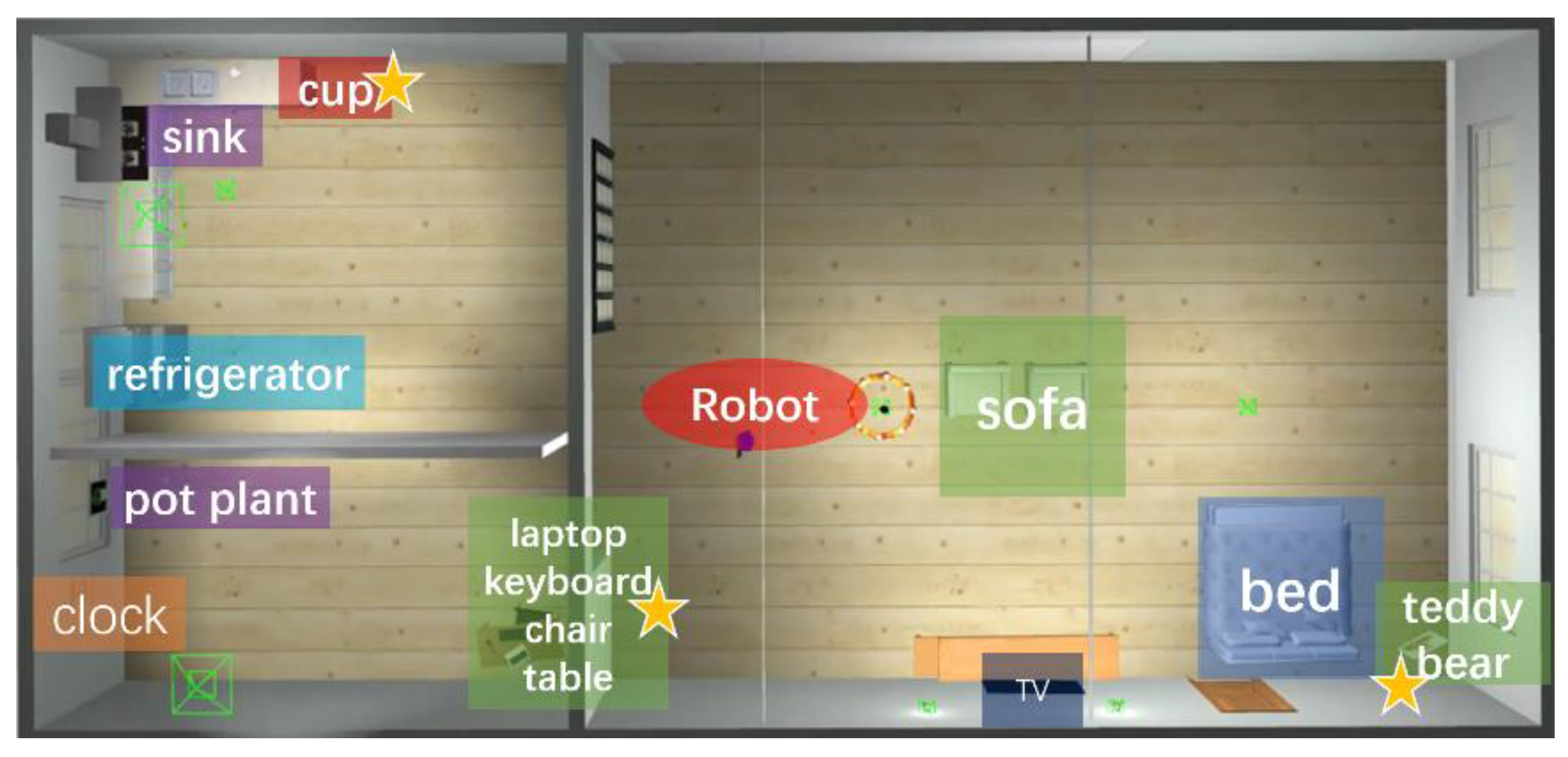
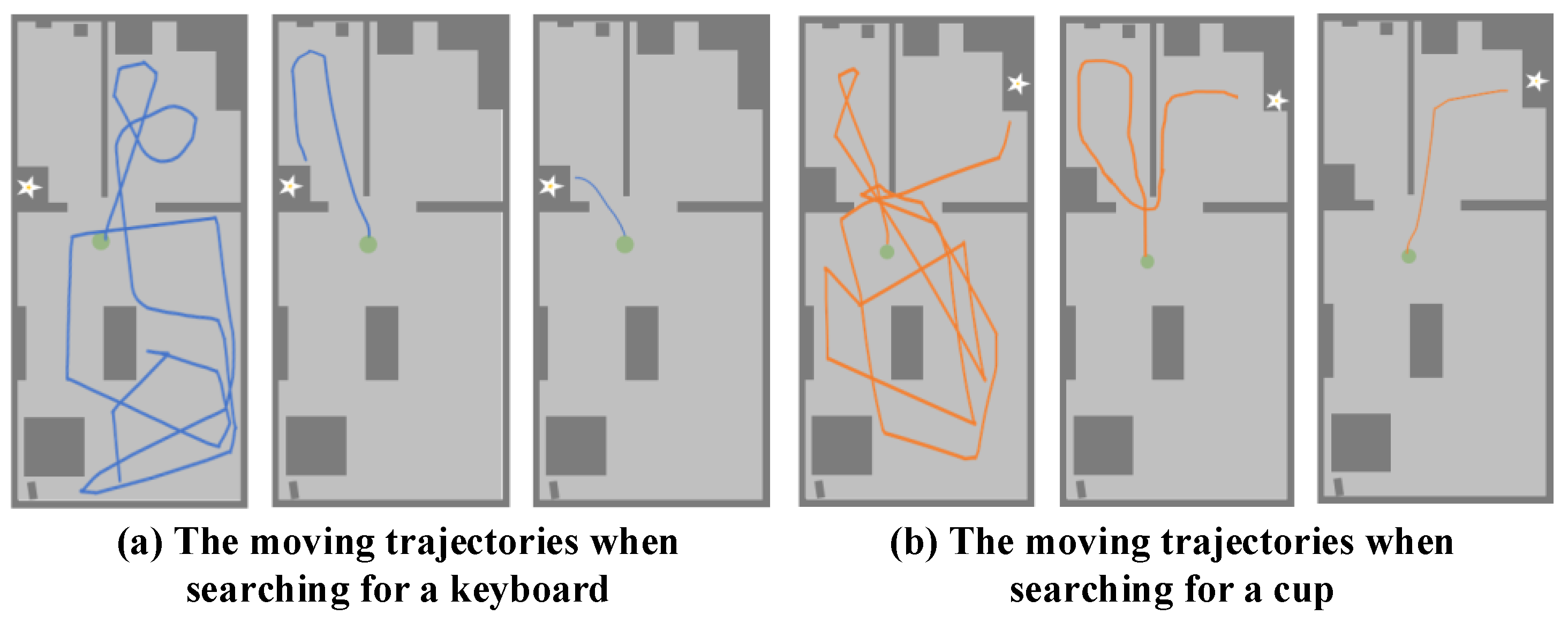
4.2. Verification of the Object Navigation System
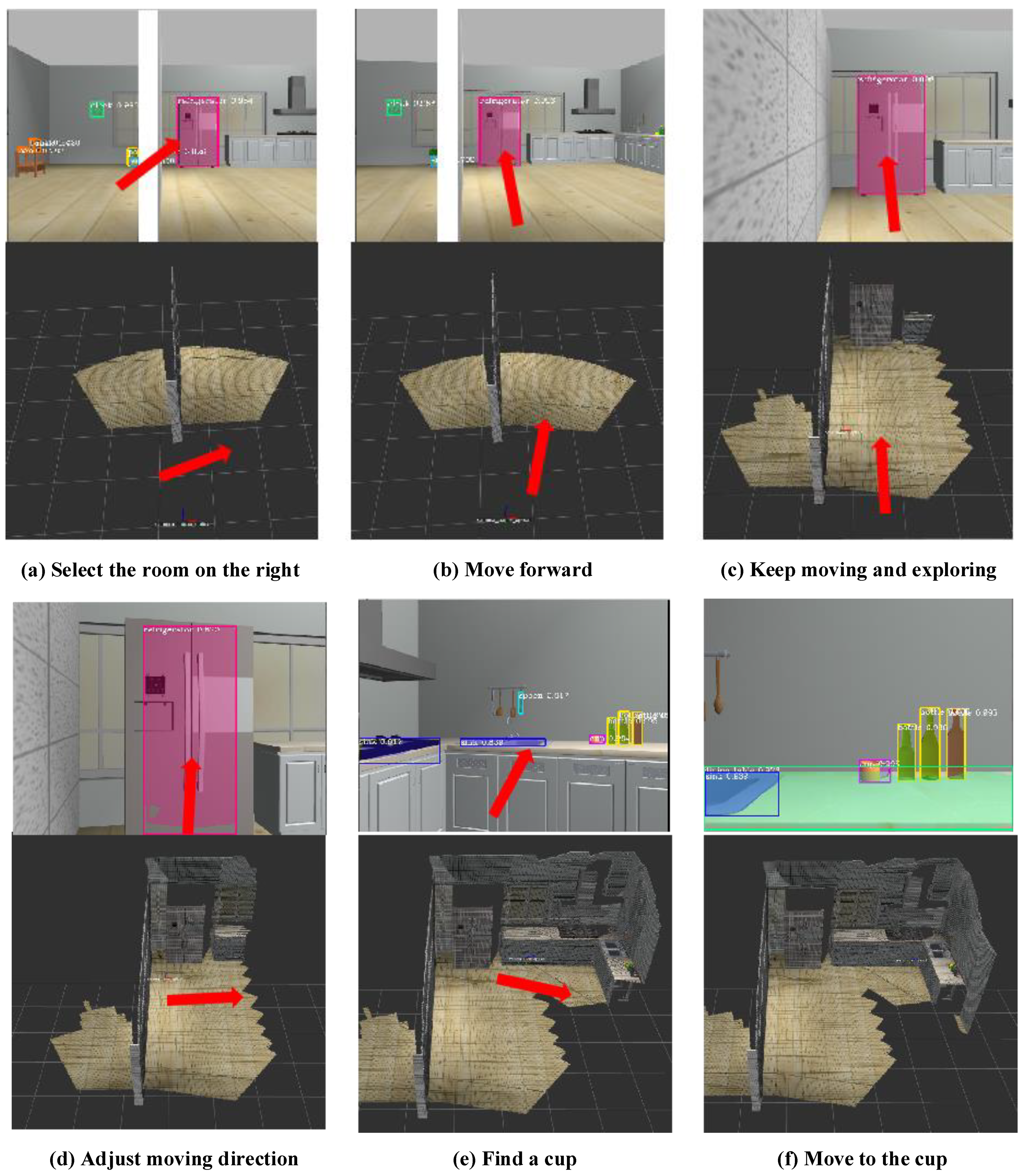
4.3. Verification on the Real Robot
5. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lera, F.J.R.; Rico, F.M.; Higueras, A.M.G.; Olivera, V.M. A context-awareness model for activity recognition in robot-assisted scenarios. Exp. Syst. 2020, 37, e12481. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Rob. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Smith, R.C.; Cheeseman, P. On the Representation and Estimation of Spatial Uncertainty. Int. J. Rob. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. Monoslam: Real-time single camera slam. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR), Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Whelan, T.; Mcdonald, J.; Kaess, M.; Fallon, M.; Johannsson, H.; Leonard, J. Robust real-time visual odometry for dense RGB-D mapping. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Sydney, Australia, 6–10 May 2012; pp. 5724–5731. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Rob. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodriguez, J.J.G.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial, and Multimap SLAM. IEEE Trans. Rob. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Abdelnasser, H.; Mohamed, R.; Elgohary, A.; Alzantot, M.F.; Wang, H.; Sen, S.; Choudhury, R.R.; Youssef, M. SemanticSLAM: Using Environment Landmarks for Unsupervised Indoor Localization. IEEE Trans. Mob. Comput. 2015, 15, 1770–1782. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar] [CrossRef] [Green Version]
- Narasimhan, M.; Wijmans, E.; Chen, X.; Darrell, T.; Batra, D.; Parikh, D.; Singh, A. Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation. In Proceedings of the 16th European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 513–529. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, Y.; Tamar, A.; Russell, S.; Gkioxari, G.; Tian, Y. Bayesian Relational Memory for Semantic Visual Navigation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2769–2779. [Google Scholar] [CrossRef] [Green Version]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A.; Davidson, J. Visual Representations for Semantic Target Driven Navigation. In Proceedings of the 2019 IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar] [CrossRef] [Green Version]
- ROS. Available online: http://wiki.ros.org/ (accessed on 14 September 2021).
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. Octomap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Rob. 2013, 34, 189–206. [Google Scholar] [CrossRef] [Green Version]
- Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Available online: https://github.com/matterport/Mask_RCNN (accessed on 23 June 2021).
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision, ECCV 2014, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Cosenza, C.; Nicolella, A.; Esposito, D.; Niola, V.; Savino, S. Mechanical System Control by RGB-D Device. Machines 2021, 9, 3. [Google Scholar] [CrossRef]
- YOLOv5 in Pytorch. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 March 2022).
- SSD: Single Shot MultiBox Detector. Available online: https://github.com/weiliu89/caffe/tree/ssd (accessed on 25 March 2022).
- Word2vec Tutorial-The Skip-Gram Model. Available online: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model (accessed on 28 November 2021).
- Yan, X.; Wang, S.; Ma, F.; Liu, Y.; Wang, J. A novel path planning approach for smart cargo ships based on anisotropic fast marching. Exp. Syst. Appl. 2020, 159, 113558. [Google Scholar] [CrossRef]
- SUN Database: Scene Categorization Benchmark. Available online: https://vision.cs.princeton.edu/projects/2010/SUN/ (accessed on 8 October 2021).
- Koenig, N.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar]
- Guo, Y.; Mi, Z.; Yang, Y.; Obaidat, M.S. An Energy Sensitive Computation Offloading Strategy in Cloud Robotic Network Based on GA. IEEE Syst. J. 2019, 13, 3513–3523. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar] [CrossRef]
- Liu, P.; Li, X.; Liu, H.; Fu, Z. Online Learned Siamese Network with Auto-Encoding Constraints for Robust Multi-Object Tracking. Electronics 2019, 8, 595. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Objects | Related Objects | Training Corpuses |
|---|---|---|
| keyboard | keyboard > tv > mouse > chair | keyboard tv mouse chair |
| tv | tv > keyboard > mouse > chair | tv keyboard mouse chair |
| mouse | mouse > keyboard > tv > chair | mouse keyboard tv chair |
| chair | chair > keyboard > mouse > tv | chair keyboard mouse tv |
| Strategy | Target | Average Searching Time (s) | Average Moving Distance (m) | Success Rate |
|---|---|---|---|---|
| Random Search | cup | timeout | 50.91 | 0.1 |
| keyboard | timeout | 51.39 | 0.2 | |
| teddy bear | timeout | 53.24 | 0 | |
| Traversal Search | cup | 125.72 | 26.93 | 0.9 |
| keyboard | 56.48 | 9.81 | 1 | |
| teddy bear | 188.53 | 41.28 | 0.7 | |
| Autonomous Search | cup | 51.34 | 12.13 | 1 |
| keyboard | 49.82 | 8.47 | 1 | |
| teddy bear | 89.18 | 19.26 | 1 |
| Target | Strategy | Average Searching Time (s) | Average Moving Distance (Estimated) (m) | Success Rate |
|---|---|---|---|---|
| mouse | Random | timeout | 13.42 | 0.2 |
| Traversal | 288.4 | 6.88 | 0.8 | |
| Autonomous | 179.3 | 5.34 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Xie, Y.; Chen, Y.; Ban, X.; Sadoun, B.; Obaidat, M.S. An Efficient Object Navigation Strategy for Mobile Robots Based on Semantic Information. Electronics 2022, 11, 1136. https://doi.org/10.3390/electronics11071136
Guo Y, Xie Y, Chen Y, Ban X, Sadoun B, Obaidat MS. An Efficient Object Navigation Strategy for Mobile Robots Based on Semantic Information. Electronics. 2022; 11(7):1136. https://doi.org/10.3390/electronics11071136
Chicago/Turabian StyleGuo, Yu, Yuanyan Xie, Yue Chen, Xiaojuan Ban, Balqies Sadoun, and Mohammad S. Obaidat. 2022. "An Efficient Object Navigation Strategy for Mobile Robots Based on Semantic Information" Electronics 11, no. 7: 1136. https://doi.org/10.3390/electronics11071136
APA StyleGuo, Y., Xie, Y., Chen, Y., Ban, X., Sadoun, B., & Obaidat, M. S. (2022). An Efficient Object Navigation Strategy for Mobile Robots Based on Semantic Information. Electronics, 11(7), 1136. https://doi.org/10.3390/electronics11071136