
Optimal Allocation of IaaS Cloud Resources through Enhanced Moth Flame Optimization (EMFO) Algorithm


Abstract
:1. Introduction
- (i)
- Using suitable cost functions and operational limitations, implemented MFO for efficient resource allocation in an IaaS cloud environment.
- (ii)
- For improved search capabilities, migration and curvilinear properties are added into MFO.
- (iii)
- The quantitative performance of the EMFO is examined under a number of various conditions and settings.
- (iv)
- A comparative performance analysis of the various strategies described in the literature is also provided.
2. Related Works
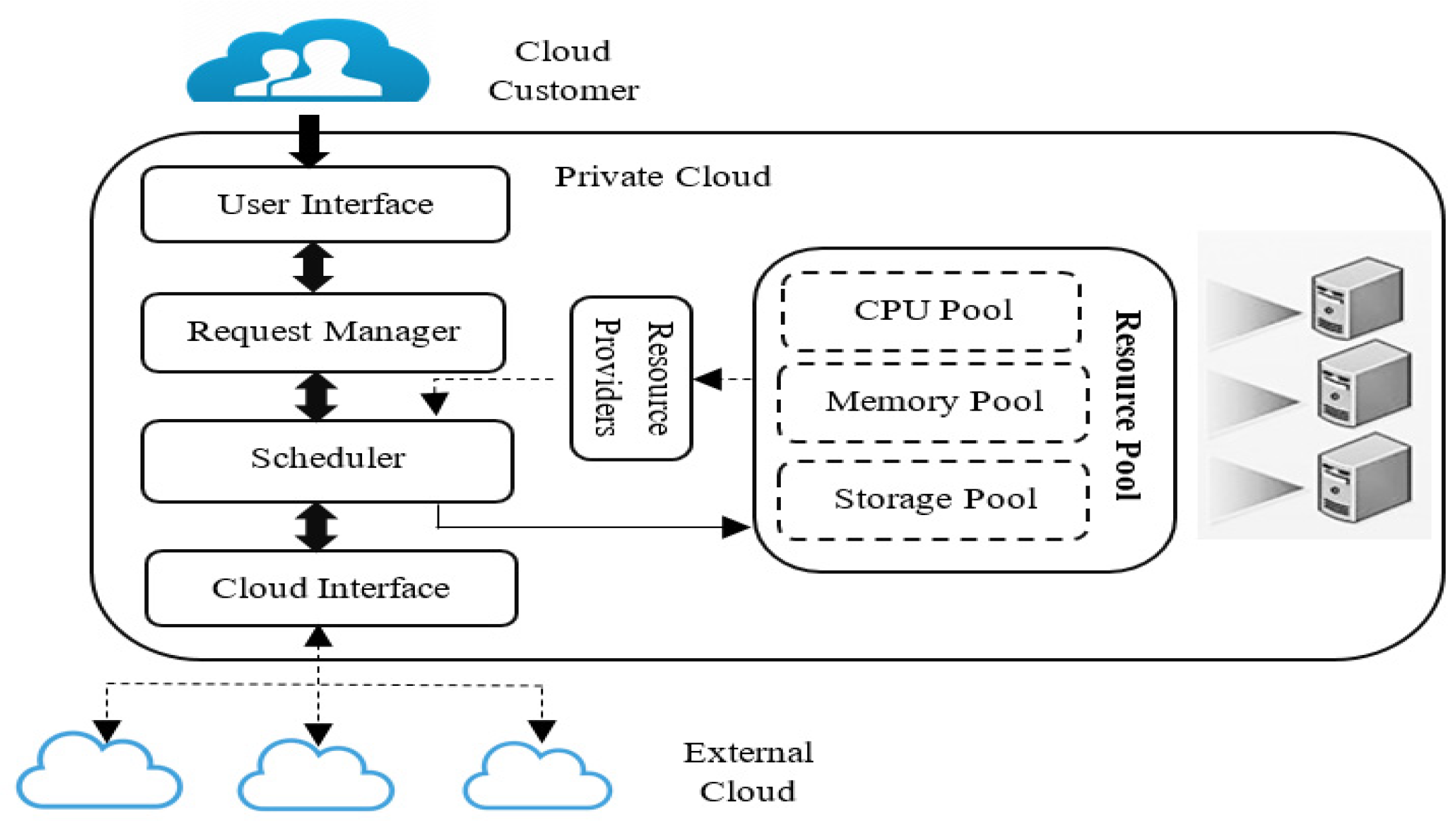
3. System Model
3.1. Application Model
3.2. Execution Model
4. Proposed Search Strategy
4.1. Standard MFO (SMFO)
4.2. Enhanced MFO (EMFO)
4.2.1. Migration Principle
4.2.2. Descending Curvilinear Principle
| Input:Maximal iteration number (MAXIT), Number of Control variables (d) Number of Moths (n), iterCount = 0 Output: OptimalSolution //Execute the following steps if (iterCount< MAXIT) { //Preparation phase of Moths M(n,d) = random() // Prepare the matrix for moths [M](n*d) (14) Obj(M(n)) // Find the fitness value for moths [OM](n*1) (15) //Preparation phase of Flames F(n,d) = random() // Prepare the matrix for flames [F](n*d) (16) Obj(F(n)) // Find fitness value for flames [OF](n*1) (17) // interaction phase of Moths and flames D = f(F,M) //Find distance of moths (20) // updation phase of Moths S = f(F,M) // Find logarithmic spiral for moths (19) M = f(S) //Update position of moths finalM = best(M) //Collect best Moths // Migration operation M = f(finalM) // Diverse moths using (22),(23) and (24) // limiting the flow of flames for further iterations F = f(n,l,T) // Curvilinear reduction of flames (25) iterCount = iterCount + 1 //Increment the generation count } Display finalM |
5. Results and Discussions
5.1. Technical Specifications of the Study
5.2. Performance Evaluation
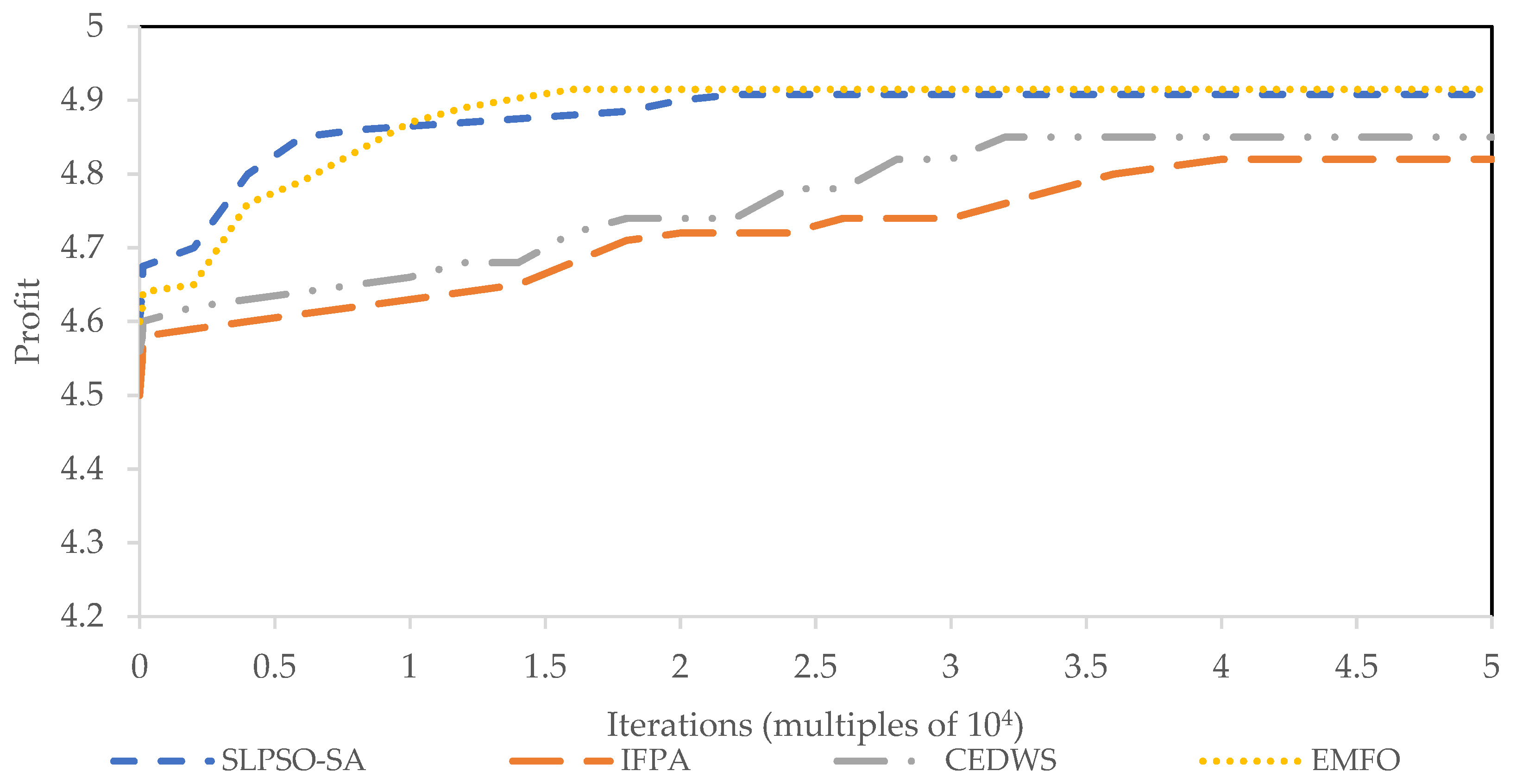
5.2.1. Instance Type 1
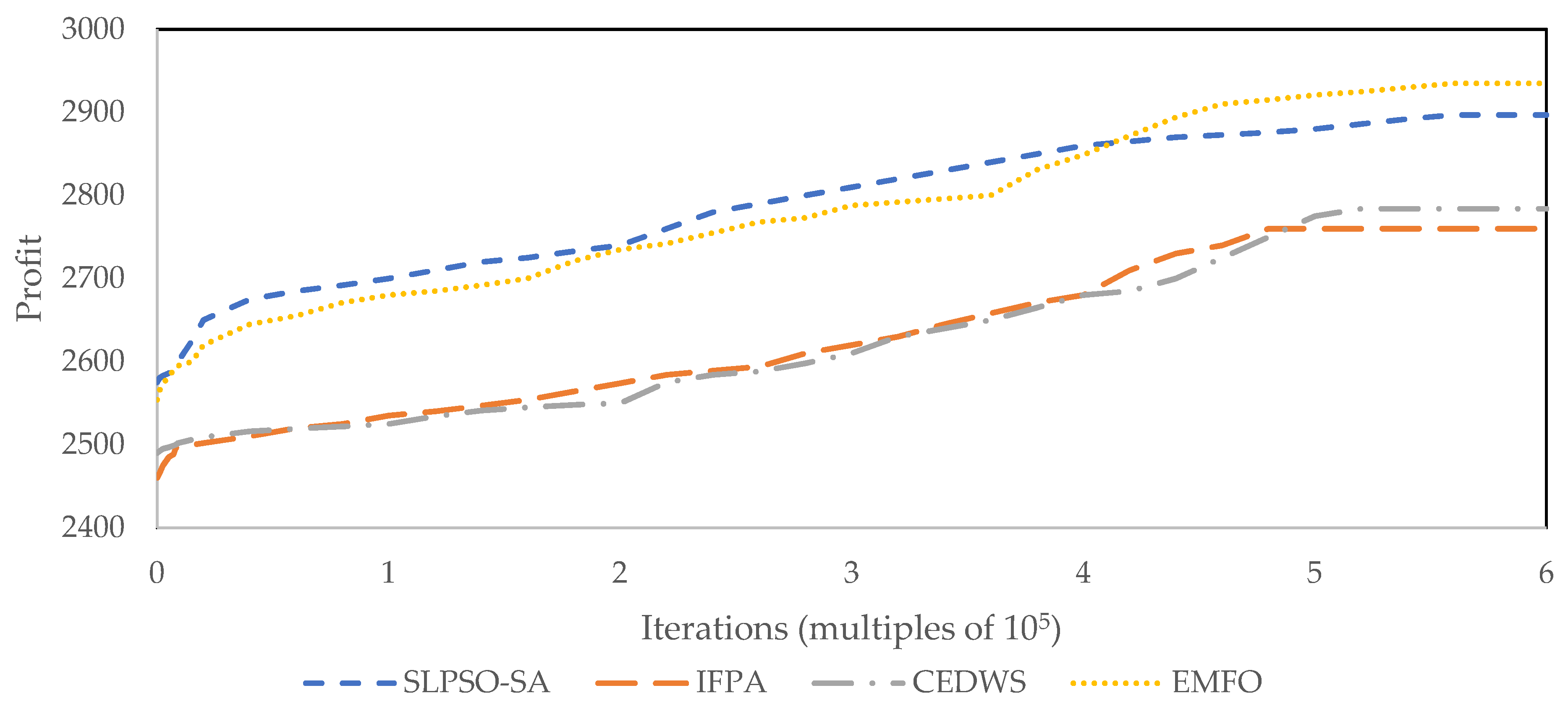
5.2.2. Instance Type 2 and 3
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Rajkumar, B.; Rajiv, R. Federated resource management in grid and cloud computing systems. J. Future Gener. Comput. Syst. 2011, 26, 1189–1191. [Google Scholar]
- Ghuman, S. Cloud Computing—A Study of Infrastructure as a Service. Comput. Sci. 2015. Available online: https://www.semanticscholar.org/paper/Cloud-Computing-A-Study-of-Infrastructure-as-a-Ghuman/1085618e1caf4b63ae53e772c6747a5f09207f68#citing-papers (accessed on 27 February 2022).
- Chase, J.S.; Darrell, C.A.; Prachi, N.T.; Amin, M.V. Managing energy and server resources in hosting centers. In Proceedings of the 11th IEEE/ACM International Conference on Grid Computing (GRID), Brussels, Belgium, 25–28 October 2010; Volume 12, pp. 50–52. [Google Scholar]
- Gupta, M.; Singh, S. Greening of the internet. In Proceedings of the ACM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Barcelona, Spain, 16–21 August 2009; pp. 19–26. [Google Scholar]
- Siddhisena, B.; Lakmal, W.; Mithila, M. Next generation mutitenant virtualization cloud computing platform. In Proceedings of the 13th International Conference on Advanced Communication Technology (ICACT), Seoul, Korea, 13–16 February 2011; Volume 12, pp. 405–410. [Google Scholar]
- Sunilkumar, S.M.; Gopal, K.S. Resource management for Infrastructure as a Service (IaaS) in cloud computing: A survey. J. Netw. Comput. Appl. 2014, 41, 424–440. [Google Scholar]
- Bhowmik, R.; Kochut, A.; Beaty, K. Managing responsiveness of virtual desk tops using passive monitoring. In Proceedings of the IEEE Integrated Network Management Symposium, Osaka, Japan, 19–23 April 2010; Volume 28, pp. 45–51. [Google Scholar]
- Zhang, Q.; Zhu, Q.; Boutaba, R. Dynamic resource allocation for spot markets in cloud computing environment. In Proceedings of the 4th IEEE International Conference on Utility and Cloud Computing, Melbourne, Australia, 5–8 December 2011; Volume 10, pp. 177–185. [Google Scholar]
- Batini, C.; Simone, G.; Andrea, M. Optimal enterprise data architecture. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, San Jose, CA, USA, 8–11 June 2011; Volume 8, pp. 541–547. [Google Scholar]
- Kuribayashi, S.I. Optimal joint multiple resource allocation method for cloud computing environments. J. Res. Rev. Comput. Sci. 2011, 2, 155–168. [Google Scholar]
- Mao, M.; Marty, H. Auto-scaling to minimize cost and meet application deadlines in cloud work flows. In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, Seattle, WA, USA, 12–18 November 2012; Volume 37, pp. 337–348. [Google Scholar]
- Alvarez, A.R.; Humphrey, M. A model and decision procedure for data storage in cloud computing. In Proceedings of the IEEE/ACM International Symposiumon Cluster, Cloud, and Grid Computing, Ottawa, ON, USA, 13–16 May 2012; Volume 12, pp. 50–52. [Google Scholar]
- Jeyarani, R.; Nagavent, N.; Ram, R.V. Design and implementation of adaptive power-aware virtual machine provisioner (APA-VMP) using swarm intelligence. Future Gener. Comput. Syst. 2012, 28, 811–821. [Google Scholar] [CrossRef]
- Zuo, X.; Zhang, G.; Tan, W. Self-Adaptive Learning PSO-Based Deadline Constrained Task Scheduling for Hybrid IaaS Cloud. IEEE Trans. Autom. Sci. Eng. 2014, 11, 351–359. [Google Scholar] [CrossRef]
- Wang, X.; Du, Z.; Chen, Y.; Yang, M. A green-aware virtual machine migration strategy for sustainable datacenter powered by renewable energy. Simul. Model. Pract. Theory 2015, 58, 3–14. [Google Scholar] [CrossRef]
- Mäsker, M.; Nagel, L.; Brinkmann, A.; Lotfifar, F.; Johnson, M. Smart grid-aware scheduling in data centres. In Proceedings of the 2015 Sustainable Internet and ICT for Sustainability (SustainIT), Funchal, Portugal, 6–7 December 2015; pp. 1–9. [Google Scholar]
- Khosravi, A.; Andrew, L.L.; Buyya, R. Dynamic VM placement method for minimizing energy and carbon cost in geographically distributed cloud data centers. IEEE Trans. Sustain. Comput. 2017, 2, 183–196. [Google Scholar] [CrossRef]
- Varasteh, A.; Tashtarian, F.; Goudarzi, M. On Reliability-Aware Server Consolidation in Cloud Datacenters. In Proceedings of the 2017 16th International Symposium on Parallel and Distributed Computing (ISPDC), Innsbruck, Austria, 3–6 July 2017; pp. 95–101. [Google Scholar]
- Kasture, H. A Hardware and Software Architecture for Efficient Datacenters. Ph.D. Thesis, Department of Electrical Engineering and Computer, MIT, Cambridge, MA, USA, February 2017. [Google Scholar]
- Arivudainambi, D.; Dhanya, D. Towards optimal allocation of resources incloud modified mapreduce using genetic algorithm. IOAB J. 2017, 8, 162–171. [Google Scholar]
- Li, H.; Li, W.; Wang, H.; Wang, J. An optimization of virtual machine selection and placement by using memory content similarity for server consolidation in cloud. Future Gener. Comput. Syst. 2018, 84, 98–107. [Google Scholar] [CrossRef]
- Grange, L.; Da Costa, G.; Stolf, P. Green IT scheduling for data center powered with renewable energy. Future Gener. Comput. Syst. 2018, 86, 99–120. [Google Scholar] [CrossRef] [Green Version]
- Mishra, S.K.; Puthal, D.; Sahoo, B.; Jayaraman, P.P.; Jun, S.; Zomaya, A.; Ranjan, R. Energy-efficient VM-placement in cloud data center. Sustain. Comput. Inform. Syst. 2018, 20, 48–55. [Google Scholar] [CrossRef]
- Shabeera, T.P.; Madhu Kumar, S.D.; Sameera, M.S.; Murali Krishnan, K. Optimizing VM allocation and data placement for data-intensive applications in cloud using ACO metaheuristic algorithm. Eng. Sci. Technol. Int. J. 2017, 20, 616–628. [Google Scholar] [CrossRef] [Green Version]
- Han, G.; Que, W.; Jia, G.; Zhang, W. Resource-utilization-aware energy efficient server consolidation algorithm for green computing in IIOT. J. Netw. Comput. Appl. 2018, 103, 205–214. [Google Scholar] [CrossRef]
- Tavana, M.; Shahdi-Pashaki, S.; Teymourian, E.; Arteaga, F.J.S.; Komaki, M. A discrete cuckoo optimization algorithm for consolidation in cloud computing. Comput. Ind. Eng. 2018, 115, 495–511. [Google Scholar] [CrossRef]
- Malekloo, M.H.; Kara, N.; El Barachi, M. An energy efficient and SLA compliant approach for resource allocation and consolidation in cloud computing environments. Sustain. Comput. Inform. Syst. 2018, 17, 9–24. [Google Scholar] [CrossRef]
- Guha Neogi, P.P. Cost-Effective Dynamic Workflow Scheduling in IaaS Cloud Environment. In Proceedings of the 2019 International Conference on Intelligent Computing and Remote Sensing (ICICRS), Bhubaneswar, India, 19–20 July 2019; pp. 1–6. [Google Scholar]
- Liaqat, M.; Naveed, A.; Ali, R.L.; Shuja, J.; Ko, K.M. Characterizing Dynamic Load Balancing in Cloud Environments Using Virtual Machine Deployment Models. IEEE Access 2019, 7, 145767–145776. [Google Scholar] [CrossRef]
- Mustafa, S.; Sattar, K.; Shuja, J.; Sarwar, S.; Maqsood, T.; Madani, S.A.; Guizani, S. SLA-Aware Best Fit Decreasing Techniques for Workload Consolidation in Clouds. IEEE Access 2019, 7, 135256–135267. [Google Scholar] [CrossRef]
- Alzhouri, F.; Melhem, S.B.; Agarwal, A.; Daraghmeh, M.; Liu, Y.; Younis, S. Dynamic Resource Management for Cloud Spot Markets. IEEE Access 2020, 8, 122838–122847. [Google Scholar] [CrossRef]
- Shen, H.; Chen, L. A Resource Usage Intensity Aware Load Balancing Method for Virtual Machine Migration in Cloud Datacenters. IEEE Trans. Cloud Comput. 2020, 8, 17–31. [Google Scholar] [CrossRef]
- Mishra, K.; Pati, J.; Majhi, S.K. A dynamic load scheduling in IaaS cloud using binary JAYA algorithm. J. King Saud Univ.-Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Zhang, X.; Huang, Z.; Wu, C.; Li, Z.; Lau, F.C.M. Dynamic VM Scaling: Provisioning and Pricing through an Online Auction. IEEE Trans. Cloud Comput. 2021, 9, 131–144. [Google Scholar] [CrossRef]
- Mishra, K.; Pradhan, R.; Majhi, S.K. Quantum-inspired binary chaotic salp swarm algorithm (QBCSSA)-based dynamic task scheduling for multiprocessor cloud computing systems. J. Supercomput. 2021, 77, 10377–10423. [Google Scholar] [CrossRef]
- Thiruvenkadam, S.; Chang, S.-M.; Ra, I.-H. Optimal Allocation of Virtual Machines (VMs) in IaaS cloud with improved Flower Pollination Algorithm. In Proceedings of the SMA 2021, Gunsan-si, Korea, 9–11 September 2021. [Google Scholar]
- Mirjalili, S. Moth-Flame Optimization Algorithm: A Novel Nature inspired Heuristic Paradigm. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Sathiskumar, M.; Nirmal Kumar, A.; Lakshminarasimman, L.; Thiruvenkadam, S. A self adaptive hybrid differential evolution algorithm for phase balancing of unbalanced distribution system. Int. J. Electr. Power Energy Syst. 2012, 42, 91–97. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Wang, H.J.; Dao, T.K.; Pan, J.S.; Ngo, T.G.; Yu, J. A Scheme of Color Image Multithreshold Segmentation Based on Improved Moth-Flame Algorithm. IEEE Access 2020, 8, 174142–174159. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Definitions | Expressions | Details |
|---|---|---|---|
| Private Clouds | PC | {PC1, PC2, …, PCn} | Cloud environment with ‘n’ private clouds |
| Virtual Machines | VM | {VM1, VM2, …, VMm} | Each physical machine has ‘m’ virtual machines |
| Price | p | pn | Price of nth private cloud |
| Cost | c | cn,m | Cost of mth virtual machine in nth private cloud |
| CPU | cpu | cpun,m | Number of CPU of mth virtual machine in nth private cloud |
| cputotal,n | Total number of CPUs in nth private cloud | ||
| Memory | mry | mryn,m | Memory size of mth virtual machine in nth private cloud |
| mrytotal,n | Total memory size of nth private cloud |
| Parameters | Definitions | Expressions | Details |
|---|---|---|---|
| Applications | A | {A1, A2, …, Al} | For any instance ‘l’ requested applications |
| Tasks | T | {Tl,1, Tl,2, …, Tl,p} | Application ‘l’ has ‘p’ number of tasks |
| Deadline | D | {D1, D2, …, Dl} | Deadline of applications {1, 2, …., l} |
| Runtime | r | {r1, r2, …, rl} | Runtime of each task of applications {1, 2, …, l} |
| Deadline Threshold | S | Maximum Deadline |
| Variables | Definitions |
|---|---|
| =1, if the ith application uses jth VM type, otherwise ‘0’ | |
| Start time slot of task tip | |
| = 1, if the task tip is allocated to kth PC, otherwise ‘0’ | |
| = 1, if the task tip is allocated to time slot ‘s’ of PC1, otherwise ‘0’ |
| VM Instance Types | Private Clouds | ECs Price (p) | |||||
|---|---|---|---|---|---|---|---|
| Name | CPU (cpu) | Memory in GB (mry) | Cost (c) | Price (p) | TypeA | TypeB | TypeC |
| VM_type1 | 1 | 1.7 | 0.03 | 0.08 | 0.085 | 0.07 | 0.10 |
| VM_type2 | 4 | 7.5 | 0.12 | 0.32 | 0.34 | 0.36 | 0.40 |
| VM_type3 | 8 | 15 | 0.24 | 0.64 | 0.68 | 0.70 | 0.72 |
| Instance Type 1 | Instance Type 2 and 3 | |||||
|---|---|---|---|---|---|---|
| Parameters | Values | Resources | Number | Values | Resources | Number |
| Tasks | U [1, 5] | CPU (cpu) | 20 | U [1, 50] | CPU (cpu) | 512 |
| VM type | U [1, 3] | Memory (mry) | 40 GB | U [1, 3] | Memory(mry) | 1024 GB |
| Deadline (hrs.) | U [1, 5] | U [1, 168] | ||||
| Runs | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Profit (PCprofit) | 4.9157 | 4.9030 | 4.8837 | 4.9196 | 4.8794 | 4.8800 | 4.9767 | 4.9553 | 4.9233 | 4.9115 |
| Runtime (s) | 12.20 | 11.35 | 11.80 | 15.20 | 10.71 | 15.79 | 12.55 | 11.18 | 11.34 | 9.71 |
| Algorithms | Average Profit | Average Runtime | Standard Error | Standard Deviation |
|---|---|---|---|---|
| SLPSO-SA | 4.9080 | 29.55 | 0.0020 | 0.0060 |
| CPLEX | 4.9100 | 0.98 | 0.0003 | 0.0008 |
| IFPA | 4.8240 | 0.86 | 0.0014 | 0.0372 |
| CEDWS | 4.8500 | 14.6 | 0.0025 | 0.0091 |
| EMFO | 4.9148 | 12.18 | 0.0009 | 0.0038 |
| Instance Type 2 | Instance Type 3 | |||||||
|---|---|---|---|---|---|---|---|---|
| Algorithms | Average Profit | Average Runtime | Standard Error | Standard Deviation | Average Profit | Average Runtime | Standard Error | Standard Deviation |
| SLPSO-SA | 3512.48 | 2874.27 | 0.0491 | 0.0620 | 2814.78 | 4265.80 | 0.0280 | 0.0513 |
| IFPA | 3281.25 | 4772.86 | 0.0352 | 0.0551 | 2760.17 | 6923.77 | 0.0215 | 0.0420 |
| CEDWS | 3354.62 | 3964.14 | 0.0567 | 0.0784 | 2784.30 | 7264.91 | 0.0530 | 0.0691 |
| EMFO | 3587.182 | 2368.49 | 0.0245 | 0.0537 | 2935.56 | 4327.64 | 0.0086 | 0.0347 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thiruvenkadam, S.; Kim, H.-J.; Ra, I.-H. Optimal Allocation of IaaS Cloud Resources through Enhanced Moth Flame Optimization (EMFO) Algorithm. Electronics 2022, 11, 1095. https://doi.org/10.3390/electronics11071095
Thiruvenkadam S, Kim H-J, Ra I-H. Optimal Allocation of IaaS Cloud Resources through Enhanced Moth Flame Optimization (EMFO) Algorithm. Electronics. 2022; 11(7):1095. https://doi.org/10.3390/electronics11071095
Chicago/Turabian StyleThiruvenkadam, Srinivasan, Hyung-Jin Kim, and In-Ho Ra. 2022. "Optimal Allocation of IaaS Cloud Resources through Enhanced Moth Flame Optimization (EMFO) Algorithm" Electronics 11, no. 7: 1095. https://doi.org/10.3390/electronics11071095
APA StyleThiruvenkadam, S., Kim, H.-J., & Ra, I.-H. (2022). Optimal Allocation of IaaS Cloud Resources through Enhanced Moth Flame Optimization (EMFO) Algorithm. Electronics, 11(7), 1095. https://doi.org/10.3390/electronics11071095