
Deep-Learning-Based Network for Lane Following in Autonomous Vehicles



Abstract
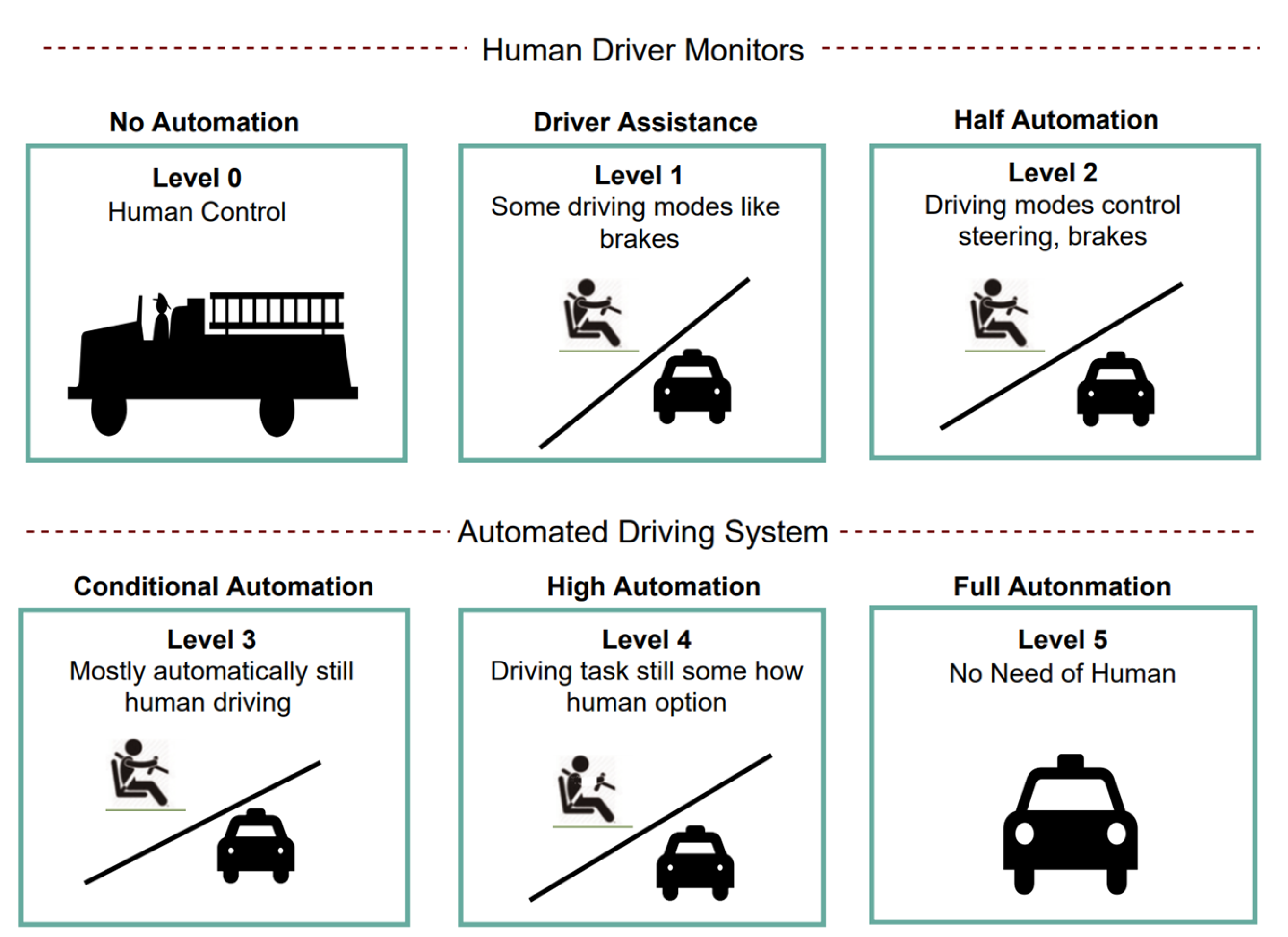
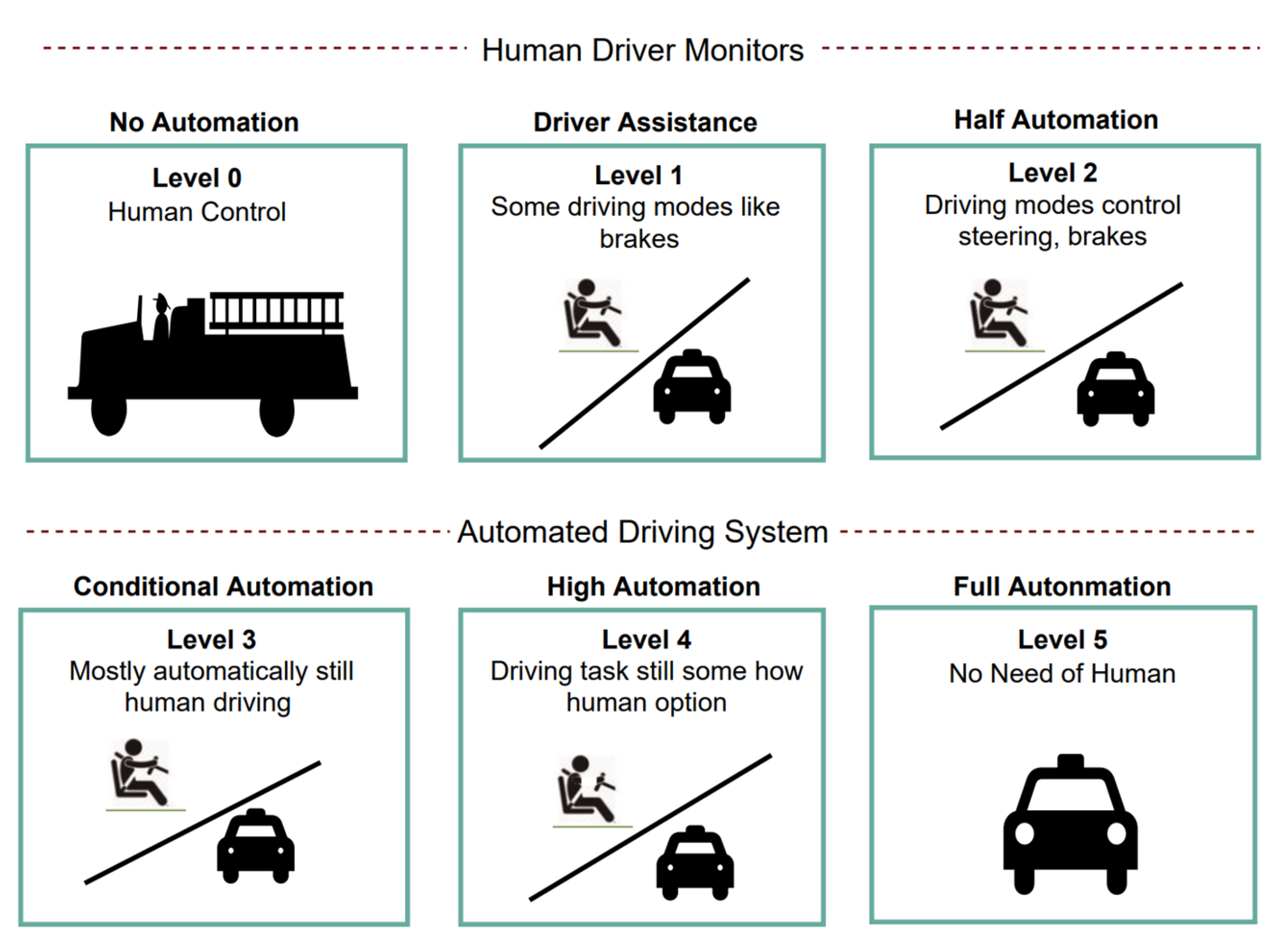
:1. Introduction
- A human-like decision-making motion planning approach (i.e., lane-following) that uses the VGG16-GRU algorithm was proposed. We used a simulated driving dataset and a real dataset to test our proposed method.
- An analysis of the result of the proposed VGG16-GRU model was carried out with two processing networks—an embedded system and a GPU—in order to analyze the power consumption.
- We compared the VGG16-GRU framework proposed herein with other proposed networks to demonstrate its better performance.
- A detailed analysis of the results is provided in terms of four performance measures: MSE, RMSE, time, and the number of parameters.
2. Related Work
3. Methodology
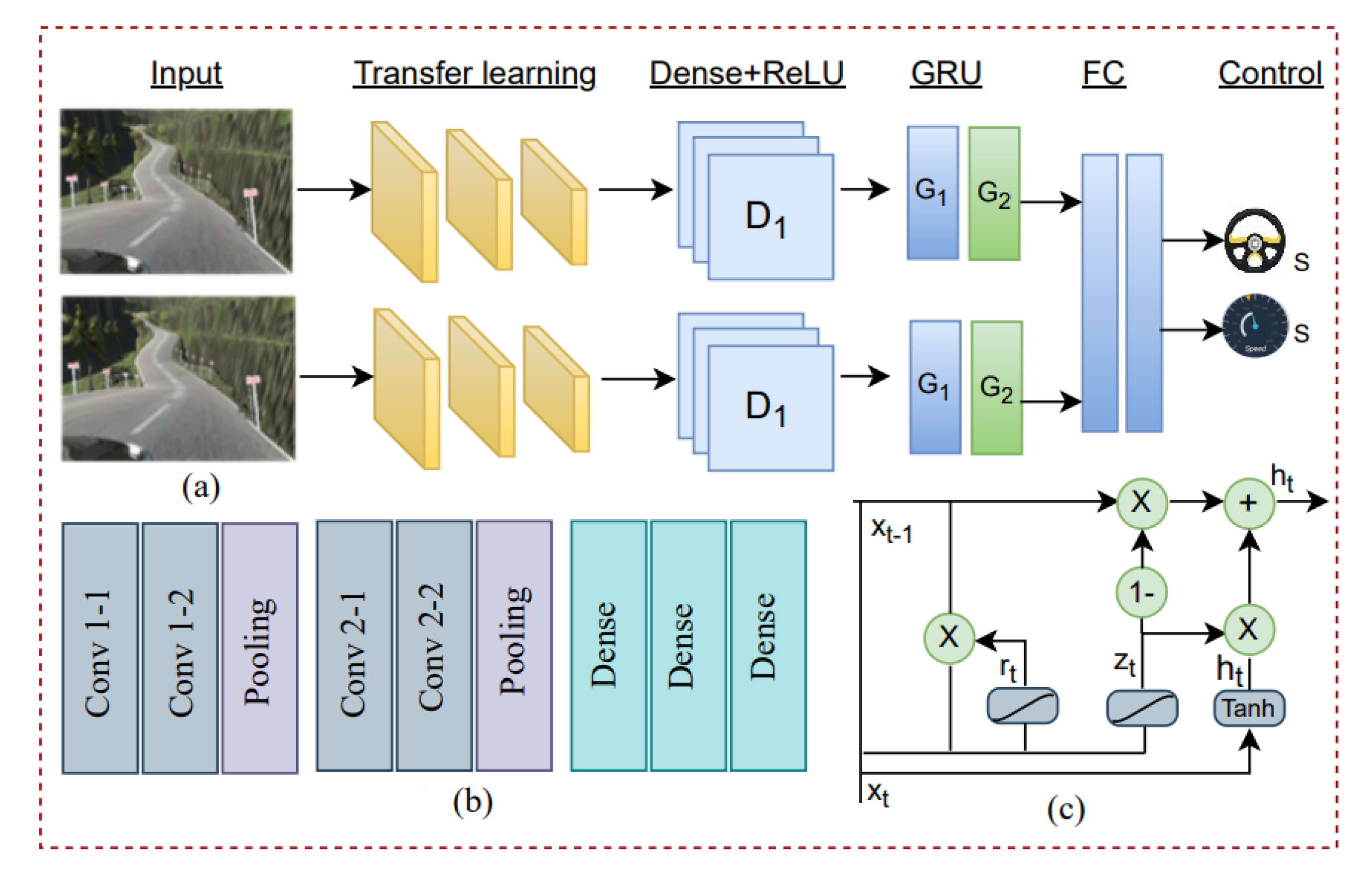
3.1. Overview of the Proposed System
3.1.1. Input Layer
3.1.2. Proposed System
3.1.3. Output
| Algorithm 1: Steering direction with speed control with VGG-GRU |
Input:
I = Output:
= Start () Define parameters of Vgg-GRU; Given direction and speed Spilt data into Training and Test For I in VGG-GRU with I Fit data into VGG-GRU network VGG-GRU (Load-framework) Execute compute the function ← VGG-GRU MAE ← VGG-GRU Runtime ← VGG-GRU Accuracy ← VGG-GRU End |
4. Results
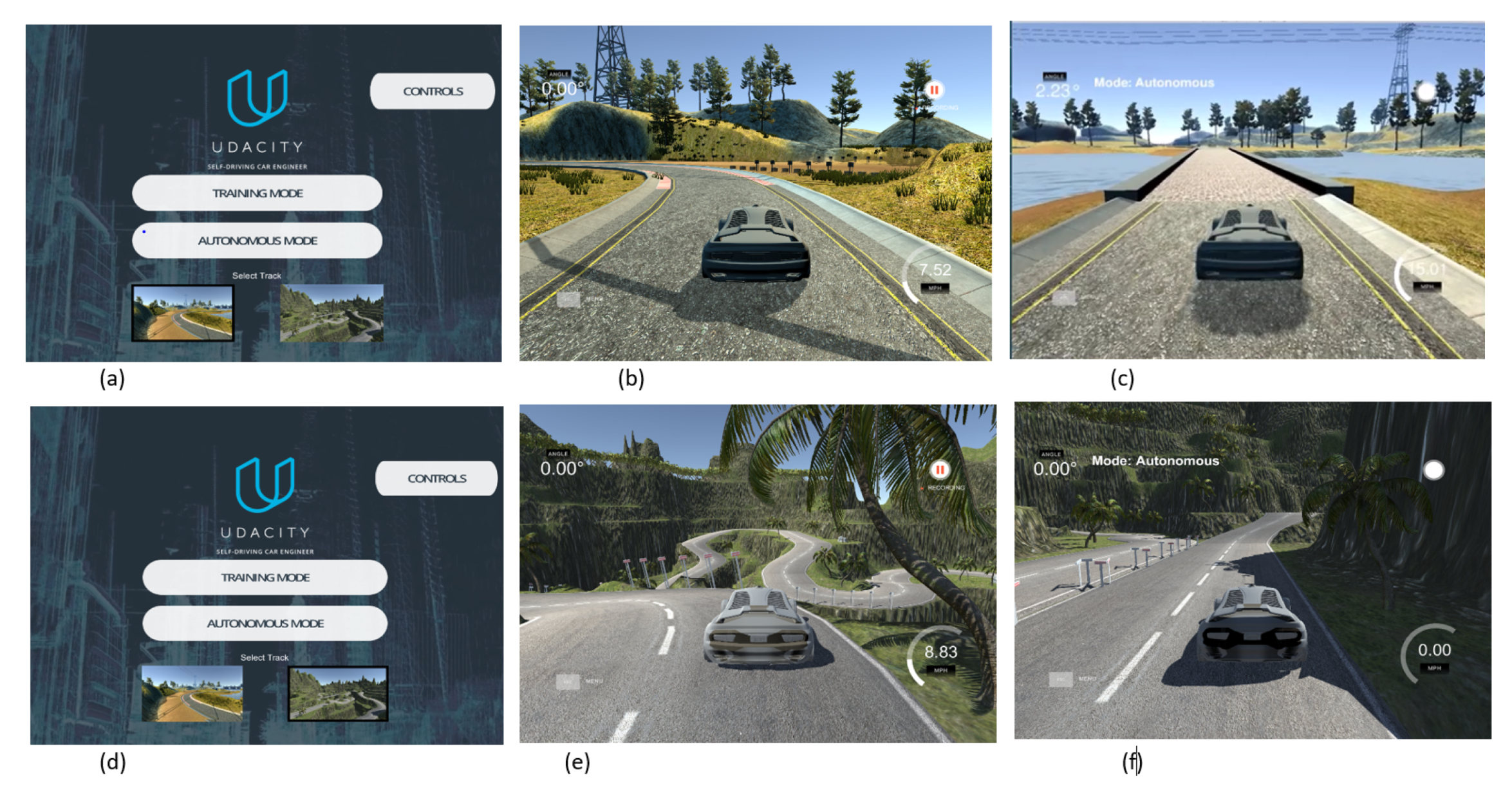
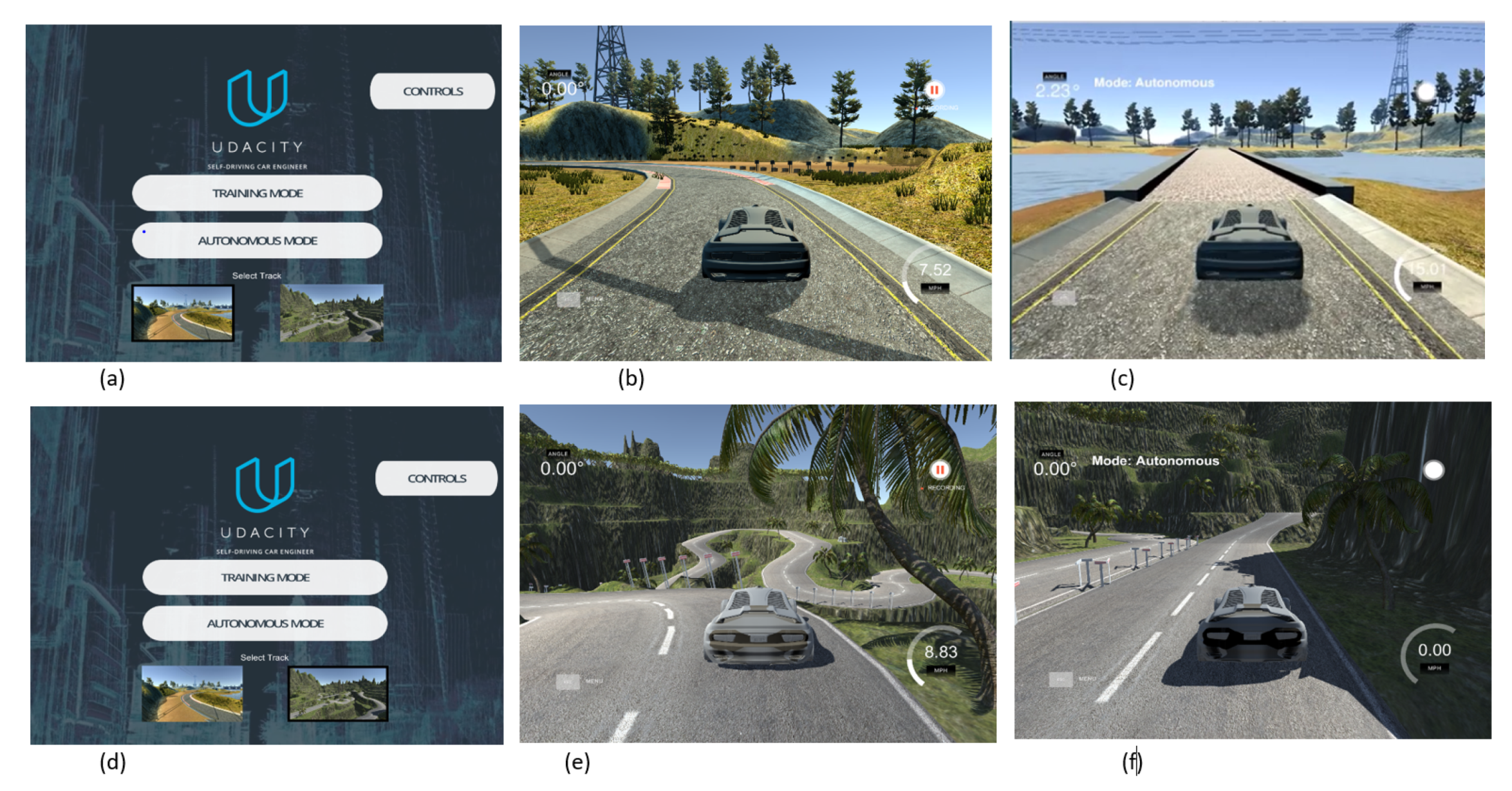
4.1. Simulation Framework
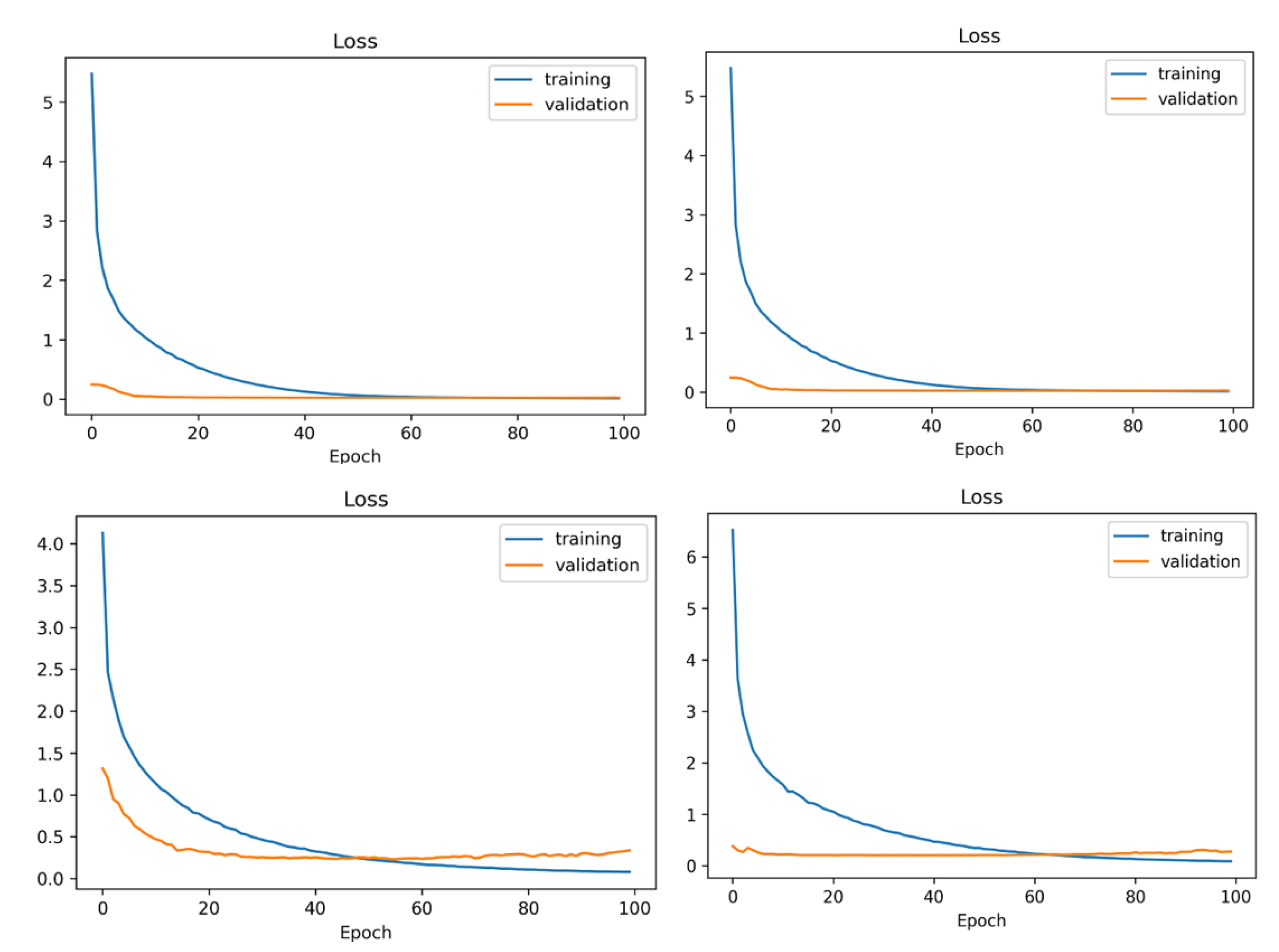
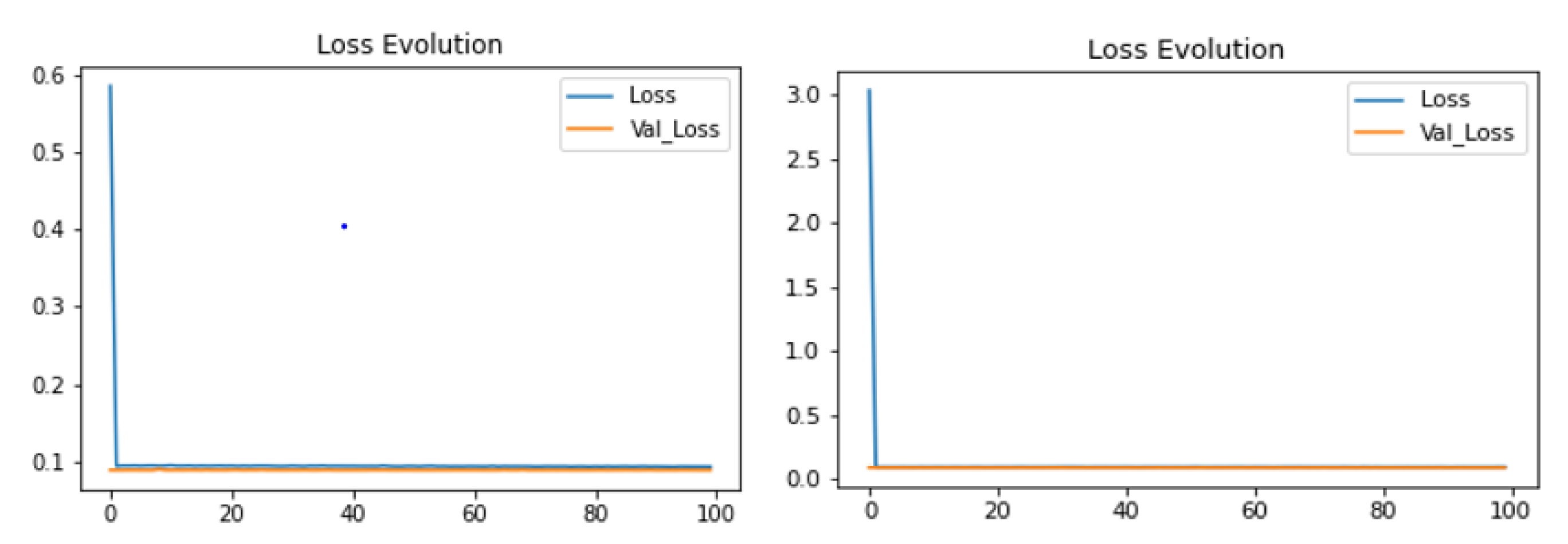
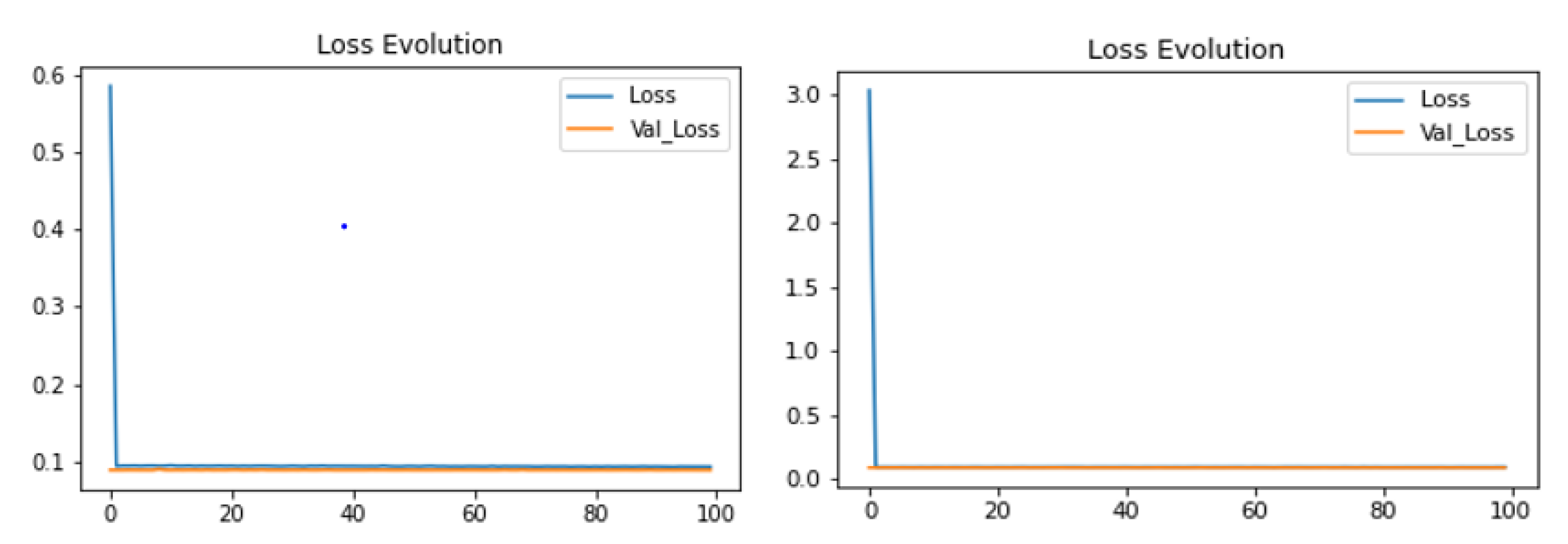
4.2. Analysis of the System
4.3. Embedded System
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| CNN | Convolutional neural network |
| GRU | Gated recurrent unit |
| AVs | Autonomous vehicle |
| LSTM | Long short-term memory |
| RNN | Recurrent neural network |
| FC | Fully connected |
| LT | Left turn |
| RT | Right turn |
| LK | Lane keeping |
| ReLU | Rectified linear unit |
| MSE | Mean square error |
| RMSE | Root mean square root |
| RNN | Recurrent neural network |
| DNN | Deep neural network |
| HLCIUM | Human-Like Lane-Changing Intention Understanding Model |
References
- Li, H.; Zhang, J.; Zhang, Z.; Huang, Z. Active lane management for intelligent connected vehicles in weaving areas of urban expressway. J. Intell. Connect. Veh. 2021, 4, 52–67. [Google Scholar] [CrossRef]
- Simmons, B.; Adwani, P.; Pham, H.; Alhuthaifi, Y.; Wolek, A. Training a remote-control car to autonomously lane-follow using end-to-end neural networks. In Proceedings of the 2019 53rd Annual Conference on Information Sciences and Systems (CISS), Munich, Germany, 15–18 December 2019; pp. 1–6. [Google Scholar]
- Deo, N.; Trivedi, M.M. Multi-modal trajectory prediction of surrounding vehicles with maneuver based lstms. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1179–1184. [Google Scholar]
- Xia, Y.; Qu, Z.; Sun, Z.; Li, Z. A human-like model to understand surrounding vehicles’ lane changing intentions for autonomous driving. IEEE Trans. Veh. Technol. 2021, 70, 4178–4189. [Google Scholar] [CrossRef]
- Larsson, J.; Keskin, M.F.; Peng, B.; Kulcsár, B.; Wymeersch, H. Pro-social control of connected automated vehicles in mixed-autonomy multi-lane highway traffic. Commun. Transp. Res. 2021, 1, 100019. [Google Scholar] [CrossRef]
- Wang, X.; Jiang, R.; Li, L.; Lin, Y.; Zheng, X.; Wang, F.Y. Capturing car-following behaviors by deep learning. IEEE Trans. Intell. Transp. Syst. 2017, 19, 910–920. [Google Scholar] [CrossRef]
- Valiente, R.; Zaman, M.; Ozer, S.; Fallah, Y.P. Controlling steering angle for cooperative self-driving vehicles utilizing CNN and LSTM-based deep networks. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2423–2428. [Google Scholar]
- Yuan, W.; Yang, M.; Li, H.; Wang, C.; Wang, B. End-to-end learning for high-precision lane keeping via multi-state model. CAAI Trans. Intell. Technol. 2018, 3, 185–190. [Google Scholar] [CrossRef]
- Jeong, Y.; Kim, S.; Yi, K. Surround vehicle motion prediction using LSTM-RNN for motion planning of autonomous vehicles at multi-lane turn intersections. IEEE Open J. Intell. Transp. Syst. 2020, 1, 2–14. [Google Scholar] [CrossRef]
- Zou, Q.; Jiang, H.; Dai, Q.; Yue, Y.; Chen, L.; Wang, Q. Robust lane detection from continuous driving scenes using deep neural networks. IEEE Trans. Veh. Technol. 2019, 69, 41–54. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, K.; Yu, J.; He, J. End-to-end control of autonomous vehicles based on deep learning with visual attention. In Proceedings of the 2020 4th CAA International Conference on Vehicular Control and Intelligence (CVCI), Hangzhou, China, 18–20 December 2020; pp. 584–589. [Google Scholar]
- Fayjie, A.R.; Hossain, S.; Oualid, D.; Lee, D.J. Driverless car: Autonomous driving using deep reinforcement learning in urban environment. In Proceedings of the 2018 15th International Conference on Ubiquitous Robots (ur), Honolulu, HI, USA, 26–30 June 2018; pp. 896–901. [Google Scholar]
- Wang, X.; Wu, J.; Gu, Y.; Sun, H.; Xu, L.; Kamijo, S.; Zheng, N. Human-like maneuver decision using LSTM-CRF model for on-road self-driving. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 210–216. [Google Scholar]
- Zhang, Y.; Li, Q.; Kang, Q.; Zhang, Y. Autonomous Car Motion Prediction Based On Hybrid Resnet Model. In Proceedings of the 2021 International Conference on Communications, Information System and Computer Engineering (CISCE), Beijing, China, 14–16 May 2021; pp. 649–652. [Google Scholar]
- Sokipriala, J. Prediction of Steering Angle for Autonomous Vehicles Using Pre-Trained Neural Network. Eur. J. Eng. Technol. Res. 2021, 6, 171–176. [Google Scholar] [CrossRef]
- Kortli, Y.; Gabsi, S.; Voon, L.F.L.Y.; Jridi, M.; Merzougui, M.; Atri, M. Deep embedded hybrid CNN–LSTM network for lane detection on NVIDIA Jetson Xavier NX. Knowl. Based Syst. 2022, 240, 107941. [Google Scholar] [CrossRef]
- Chen, L.; Hu, X.; Tang, B.; Cheng, Y. Conditional DQN-based motion planning with fuzzy logic for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 23, 2966–2977. [Google Scholar] [CrossRef]
- Hao, C.; Chen, D. Software/hardware co-design for multi-modal multi-task learning in autonomous systems. In Proceedings of the 2021 IEEE 3rd International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–5. [Google Scholar]
- Azam, S.; Munir, F.; Rafique, M.A.; Sheri, A.M.; Hussain, M.I.; Jeon, M. N 2 C: Neural network controller design using behavioral cloning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4744–4756. [Google Scholar] [CrossRef]
- Curiel-Ramirez, L.A.; Ramirez-Mendoza, R.A.; Bautista-Montesano, R.; Bustamante-Bello, M.R.; Gonzalez-Hernandez, H.G.; Reyes-Avedaño, J.A.; Gallardo-Medina, E.C. End-to-end automated guided modular vehicle. Appl. Sci. 2020, 10, 4400. [Google Scholar] [CrossRef]
- Sumanth, U.; Punn, N.S.; Sonbhadra, S.K.; Agarwal, S. Enhanced behavioral cloning-based self-driving car using transfer learning. In Data Management, Analytics and Innovation; Springer: Berlin/Heidelberg, Germany, 2022; pp. 185–198. [Google Scholar]
- Lee, D.H.; Liu, J.L. End-to-end deep learning of lane detection and path prediction for real-time autonomous driving. arXiv 2021, arXiv:2102.04738. [Google Scholar] [CrossRef]
- Li, L.; Zhao, W.; Xu, C.; Wang, C.; Chen, Q.; Dai, S. Lane-change intention inference based on rnn for autonomous driving on highways. IEEE Trans. Veh. Technol. 2021, 70, 5499–5510. [Google Scholar] [CrossRef]
- Zhou, S.; Xie, M.; Jin, Y.; Miao, F.; Ding, C. An end-to-end multi-task object detection using embedded gpu in autonomous driving. In Proceedings of the 2021 22nd International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 7 April 2021; pp. 122–128. [Google Scholar]
- Hu, X.; Tang, B.; Chen, L.; Song, S.; Tong, X. Learning a deep cascaded neural network for multiple motion commands prediction in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7585–7596. [Google Scholar] [CrossRef]
- Yadav, N.; Mody, R. Predict Steering Angles in Self-Driving Cars. 2017. Available online: https://rmmody.github.io/pdf/682Project.pdf (accessed on 22 September 2022).
- Jiang, H.; Chang, L.; Li, Q.; Chen, D. Deep transfer learning enable end-to-end steering angles prediction for self-driving car. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October 2020; pp. 405–412. [Google Scholar]
- Anwar, A.; Raychowdhury, A. Autonomous navigation via deep reinforcement learning for resource constraint edge nodes using transfer learning. IEEE Access 2020, 8, 26549–26560. [Google Scholar] [CrossRef]
- Zheng, J.; Lu, C.; Hao, C.; Chen, D.; Guo, D. Improving the generalization ability of deep neural networks for cross-domain visual recognition. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 607–620. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Udacity. An Open Source Self-Driving Car. 2. 2017. Available online: https://github.com/udacity/self-driving-car-sim (accessed on 22 September 2022).
- Khanum, A.; Lee, C.Y.; Yang, C.S. End-to-end deep learning model for steering angle control of autonomous vehicles. In Proceedings of the 2020 International Symposium on Computer, Consumer and Control (IS3C), Taichung City, Taiwan, 13–16 November 2020; pp. 189–192. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Dataset | Critical Idea | Method |
|---|---|---|---|
| [7] | Udacity | To improve control accuracy of the steering angle | CNN+LSTM+FC |
| [8] | TORCS | Multi-state model for performing higher-precision lane keeping | 3DCNN-LSTM |
| [9] | Real data | Motion prediction method for multilane turns at an intersection | LSTM-RNN |
| [10] | TuSimple | Lane detection by using multiple frames with a hybrid architecture | CNN-RNN |
| [11] | Comma.ai | AV control based on visual attention | CNN-RNN |
| [12] | Simulator | DRL method used for obstacle avoidance in an urban environment | DQN |
| [13] | NGSIM | Human-like decisions in lane change maneuvers | LSTM-CRF |
| [14] | Lyft | Deep-learning-based trajectory prediction for AVs | Resnet Model |
| Proposed | Simulator & Real | Deep-learning network for lane following with testing in an embedding system | VGG-GRU |
| Data | Samples | Training | Testing | Size |
|---|---|---|---|---|
| Lack | 25,162 | 20,129 | 5033 | 1.2 GB |
| Mountain | 18,366 | 14,692 | 3674 | 512.4 MB |
| Real | 10,011 | 8008 | 2003 | 7.8 GB |
| Spilt | 100 | 80 | 20 | - |
| Data | Direction | MSE | RMSE | Parameters |
|---|---|---|---|---|
| Simulator Lack | 0.0230 | 0.154 | 14,927,759 | |
| 0.0230 | 0.154 | 149,27,759 | ||
| Speed | 0.0233 | 0.0454 | 14,927,759 | |
| Simulator Mountain | 0.0520 | 0.300 | 15,183,909 | |
| 0.0525 | 0.331 | 15,183,909 | ||
| Speed | 0.0885 | 0.0400 | 15,183,909 | |
| Real data | 0.0936 | 0.3120 | 14,929,229 | |
| 0.0931 | 0.3038 | 14,929,229 | ||
| Speed | 0.0932 | 0.3039 | 14,929,229 |
| Data | Direction | Inference Times | Parameters |
|---|---|---|---|
| Lack | 3 ms | 14,927,759 | |
| 3 ms | 14,927,759 | ||
| Speed | 4 ms | 14,927,759 | |
| Mountain | 3 ms | 15,183,909 | |
| 4 ms | 15,183,909 | ||
| Speed | 3 ms | 15,183,909 | |
| Real-data | 3 ms | 14,929,229 | |
| 3 ms | 14,929,229 | ||
| Speed | 3 ms | 14,929,229 |
| Data | Model | MSE | RMSE | Parameters | Inference Time |
|---|---|---|---|---|---|
| Lack | VGG16 | 0.1068 | 0.8180 | 14,925,159 | 11 ms |
| Mountain | VGG16 | 0.1211 | 0.7356 | 14,925,159 | 11 ms |
| Real-data | VGG16 | 0.2479 | 0.6791 | 15,802,541 | 10 ms |
| Ref. | Data/Control | RMSE | Inference Time | MSE |
|---|---|---|---|---|
| [32] | Udacity | 0.4690 | 8ms | 0.01597 |
| [27] | Udacity | 0.3597 | 6 ms | 0.1113 |
| Our | 0.0154 | 3 ms | 0.0230 | |
| Our | Udacity Lack | 0.0154 | 3 ms | 0.0230 |
| Speed | 0.0454 | 4 ms | 0.0233 | |
| Our | 0.300 | 3 ms | 0.0520 | |
| Our | U-Mountain | 0.331 | 4 ms | 0.0520 |
| Speed | 0.0400 | 3 ms | 0.0520 | |
| Our | 0.3120 | 3 ms | 0.0936 | |
| Our | Real data | 0.3038 | 3 ms | 0.0931 |
| Speed | 0.3039 | 3 ms | 0.0932 |
| Simulator | Direction | Accuracy | GPU | Jetson Nano | Parameters |
|---|---|---|---|---|---|
| Lack | 90% | 25 s | 46 s | 14,927,759 | |
| 89% | 25 s | 46 s | 14,927,759 | ||
| Speed | 90% | 24 s | 46 s | 14,927,759 | |
| Mountain | 89% | 23 s | 45 s | 15,183,909 | |
| 89% | 23 s | 46 s | 15,183,909 | ||
| Speed | 88% | 23 s | 46 s | 15,183,909 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khanum, A.; Lee, C.-Y.; Yang, C.-S. Deep-Learning-Based Network for Lane Following in Autonomous Vehicles. Electronics 2022, 11, 3084. https://doi.org/10.3390/electronics11193084
Khanum A, Lee C-Y, Yang C-S. Deep-Learning-Based Network for Lane Following in Autonomous Vehicles. Electronics. 2022; 11(19):3084. https://doi.org/10.3390/electronics11193084
Chicago/Turabian StyleKhanum, Abida, Chao-Yang Lee, and Chu-Sing Yang. 2022. "Deep-Learning-Based Network for Lane Following in Autonomous Vehicles" Electronics 11, no. 19: 3084. https://doi.org/10.3390/electronics11193084
APA StyleKhanum, A., Lee, C.-Y., & Yang, C.-S. (2022). Deep-Learning-Based Network for Lane Following in Autonomous Vehicles. Electronics, 11(19), 3084. https://doi.org/10.3390/electronics11193084