
Federated Split Learning Model for Industry 5.0: A Data Poisoning Defense for Edge Computing

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
1.1. Related Work
1.2. Problem Definition
1.3. Contribution
- A data poisoning defense mechanism for edge-computing-based FSL—DepoisoningFSL—is proposed;
- The optimal parameters are found for improving the performance of federated split learning;
- The performance of the proposed algorithm with several real-time datasets is evaluated.
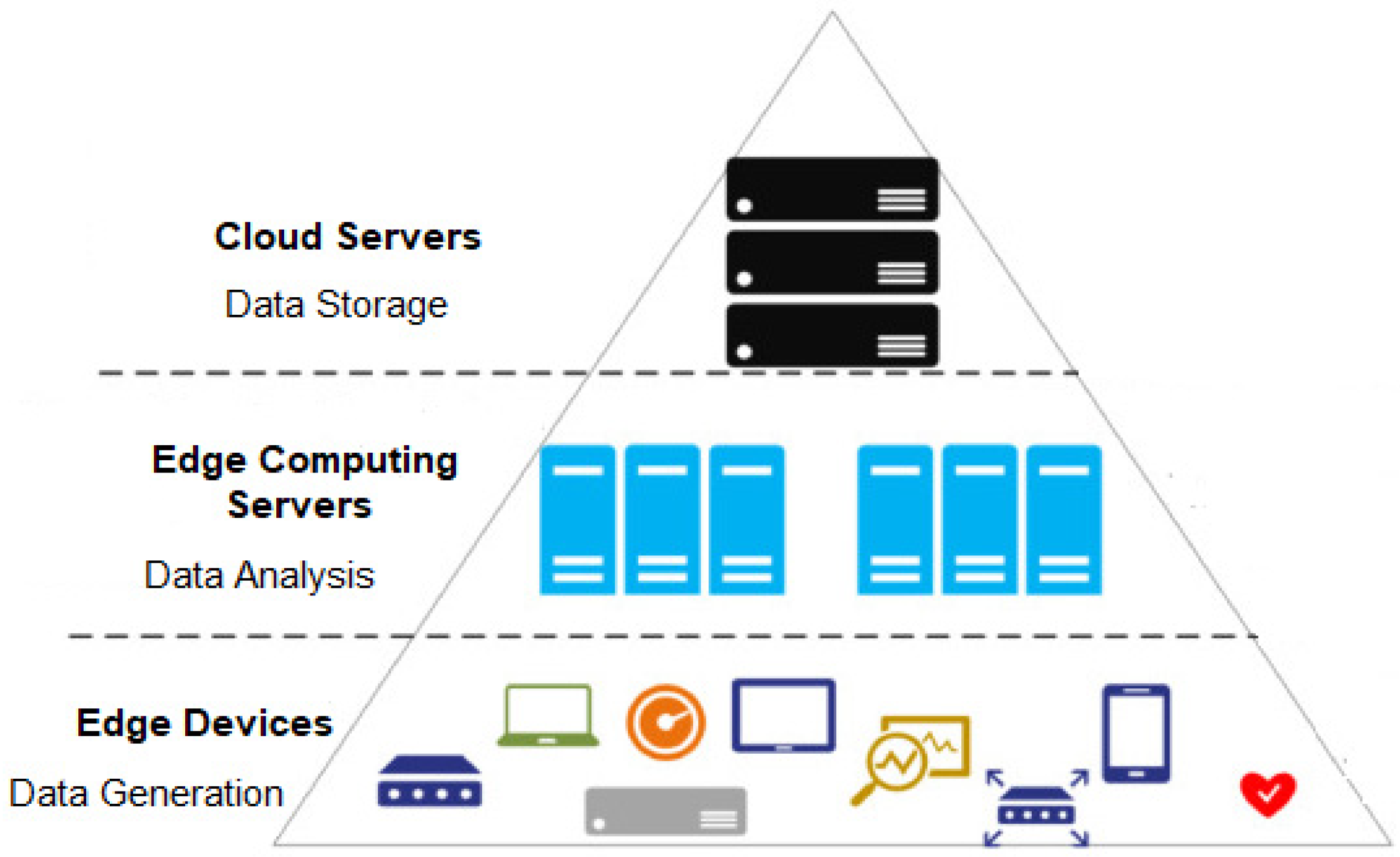
2. Preliminaries
2.1. Federated Learning
- The amount of time spent training has been lowered. In addition, multiple devices are employed simultaneously to compute gradients, resulting in considerable speedups.
- The time it takes to make a decision is cut in half. Each device has its local copy of the model, allowing exceptionally fast predictions without relying on slow cloud requests.
- Privacy is protected. Uploading sensitive data to the cloud poses a significant privacy risk for applications, such as healthcare devices. In these situations, privacy breaches could mean the difference between life and death. As a result, keeping data local protects end users’ privacy.
- It is less difficult to learn in a group setting. Instead of collecting a single large dataset to train a machine learning model, federated learning allows for a form of “crowdsourcing” that can make the data collection and labeling process considerably faster and easier.
2.2. Data Poisoning Attack
2.3. Threat and Adversary Model
3. Proposed Methodology
3.1. Defense against Data Poisoning
| Algorithm 1: Three Stage Learning Model |
| Input: Output: Dcorrect Step01: Mknn = Train(D) using K-Nearest Neighbor algorithm Step02: Pknn1 = Predict_Label(D)using Mknn Step03: UD1 = Update D based on Pknn1 Step04: Mlr1 = Train(D) using Linear regression algorithm Step05: Plr1 = Predict_Label (D) using Mlr Step06: Mlr2 = Train(UD1) using Linear regression algorithm Step07: Plr2 =Predict_Label (UD1) using Mlr2 Step08: UD2 = Update UD1 based on Plr2 Step09: Mrf1 = Train(D) using Random Forest algorithm Step10: Prf1 = Predict_Label (D) using Mrf1 Step11: Mrf2 = Train (UD2) using Random Forest algorithm Step12: Prf2 = Predict_Label(UD2) using Mrf2 Step13: UD3 = Update UD2 based on Prf2 Step14: Mknn2 = Train(UD3) using K-Nearest Neighbor algorithm Step15: Pknn2 = Predict_Label(UD3) using Mknn2 Step16: P1 = Voting (Pknn1,Plr1,Prf1) Step17: P2 = Voting(Pknn2, Plr2, Prf2) Step18: Dcorr = minLoss(P1,P2) |
3.2. Finding Optimized Parameters
| Algorithm 2: Parameter Optimization |
| Step01: GmL = 1; LmL = 1; LM = null; Step02: for each round r in R do Step03: for each edge node in EN do Step04: Collect Step05: apply three stage learning model Step06: Get LmL Step07: Update GmL based on LmL Step08: Add LmL into LM Step09: end for Step10: end for |
4. Performance Evaluation
4.1. Evaluation Metrics
4.2. Datasets
4.3. Result Comparison
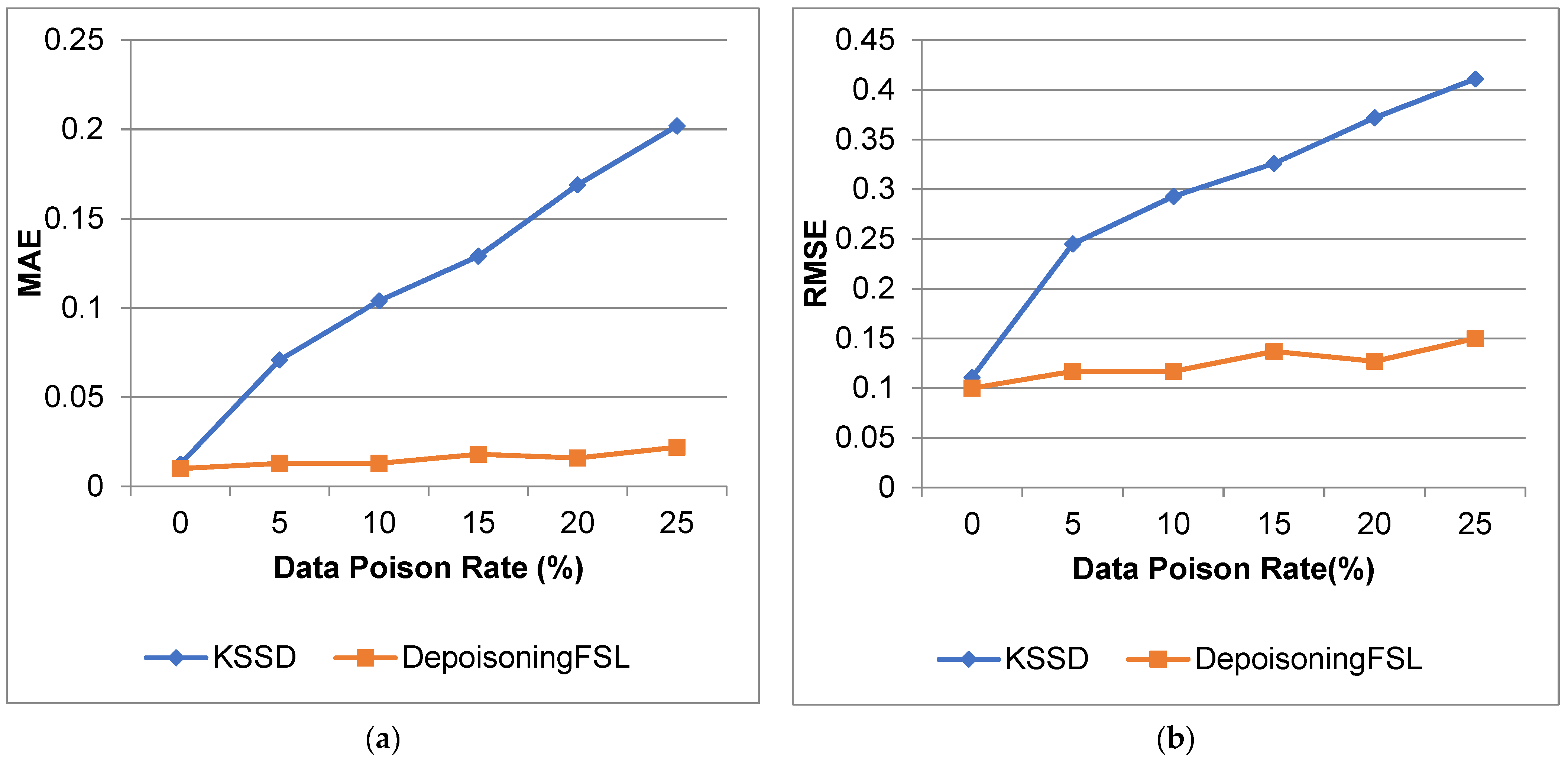
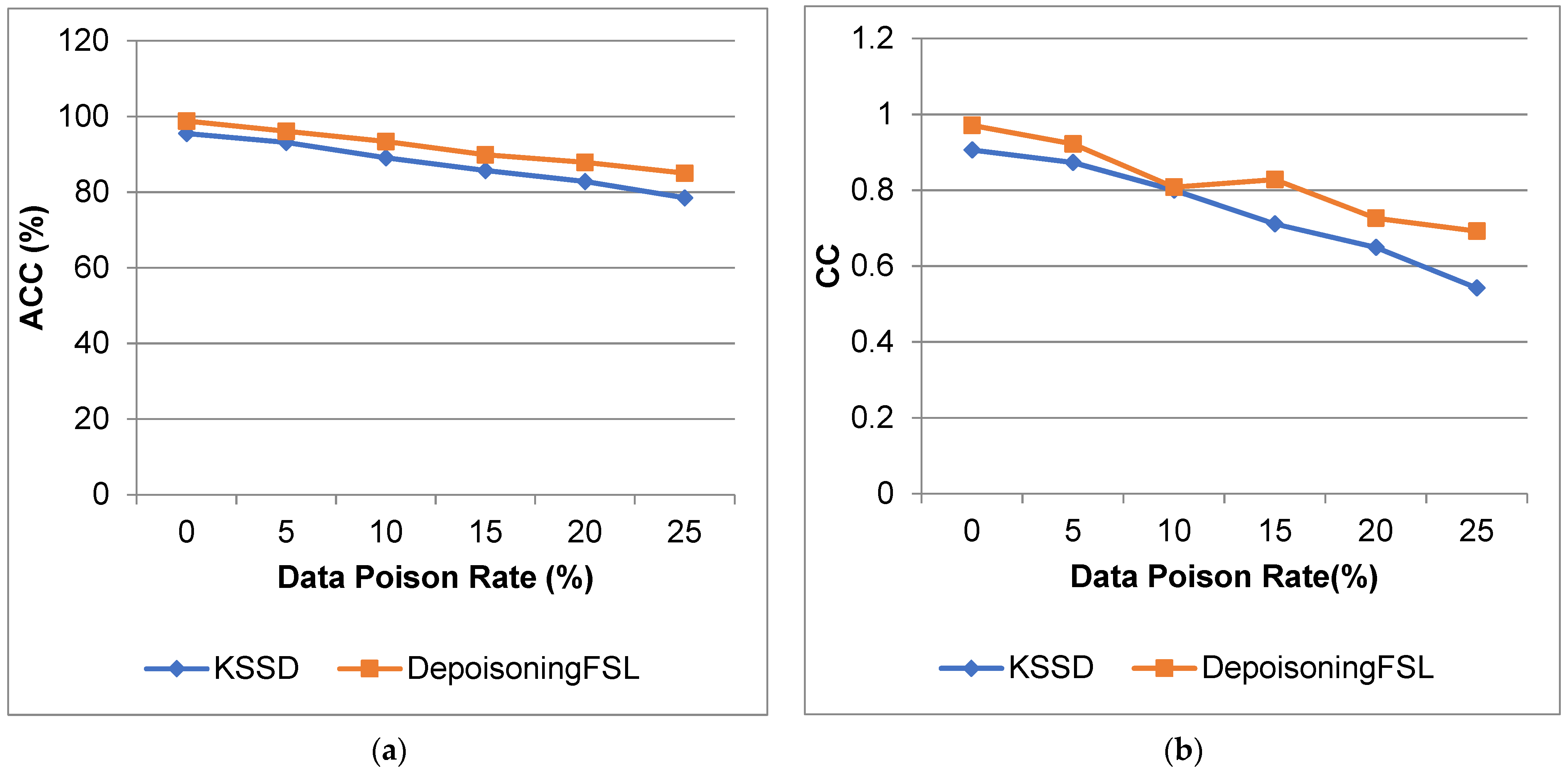
4.3.1. Results for Heart Dataset
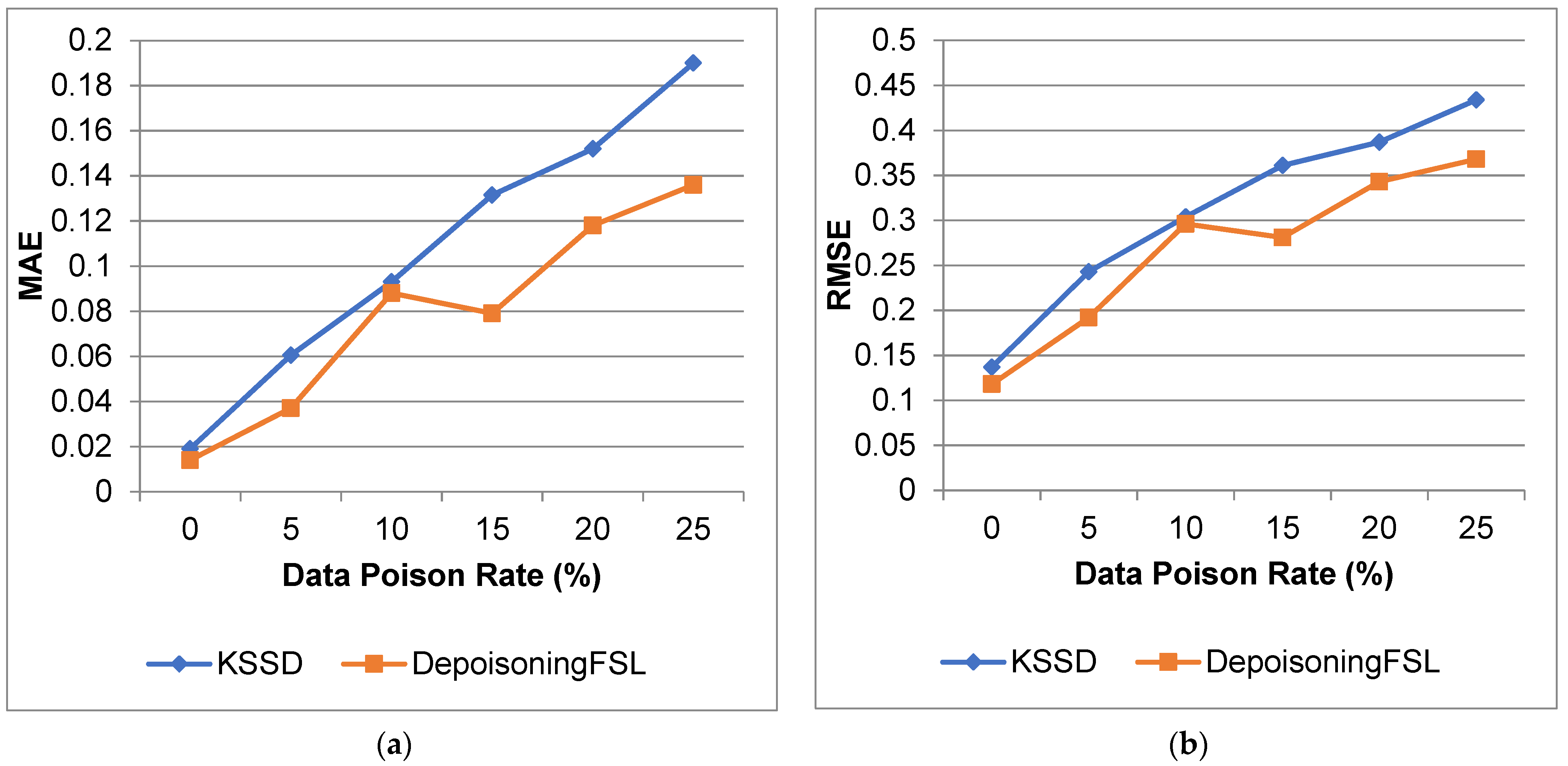
4.3.2. Results for Diabetes Dataset
4.3.3. Results for IoT_Weather Dataset
4.3.4. Results for IoT_GPS_Tracker Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nahavandi, S. Industry 5.0—A human-centric solution. Sustainability 2019, 11, 4371. [Google Scholar] [CrossRef] [Green Version]
- Abidi, M.H.; Alkhalefah, H.; Umer, U.; Mohammed, M.K. Blockchain-based secure information sharing for supply chain management: Optimization assisted data sanitization process. Int. J. Intell. Syst. 2020, 36, 260–290. [Google Scholar] [CrossRef]
- Abidi, M.H.; Umer, U.; Mohammed, M.K.; Aboudaif, M.K.; Alkhalefah, H. Automated Maintenance Data Classification Using Recurrent Neural Network: Enhancement by Spotted Hyena-Based Whale Optimization. Mathematics 2020, 8, 2008. [Google Scholar] [CrossRef]
- Ch, R.; Gadekallu, T.R.; Abidi, M.H.; Al-Ahmari, A. Computational System to Classify Cyber Crime Offenses using Machine Learning. Sustainability 2020, 12, 4087. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Pham, Q.-V.; Fang, F.; Ha, V.N.; Piran, J.; Le, M.; Le, L.B.; Hwang, W.-J.; Ding, Z. A Survey of Multi-Access Edge Computing in 5G and Beyond: Fundamentals, Technology Integration, and State-of-the-Art. IEEE Access 2020, 8, 116974–117017. [Google Scholar] [CrossRef]
- Abdirad, M.; Krishnan, K.; Gupta, D. A two-stage metaheuristic algorithm for the dynamic vehicle routing problem in Industry 4.0 approach. J. Manag. Anal. 2020, 8, 69–83. [Google Scholar] [CrossRef]
- Abidi, M.H.; Alkhalefah, H.; Umer, U. Fuzzy harmony search based optimal control strategy for wireless cyber physical system with industry 4.0. J. Intell. Manuf. 2021, 33, 1795–1812. [Google Scholar] [CrossRef]
- Abidi, M.H.; Mohammed, M.K.; Alkhalefah, H. Predictive Maintenance Planning for Industry 4.0 Using Machine Learning for Sustainable Manufacturing. Sustainability 2022, 14, 3387. [Google Scholar] [CrossRef]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified defenses for data poisoning attacks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3517–3529. [Google Scholar]
- Sidi, L.; Nadler, A.; Shabtai, A. Maskdga: An evasion attack against dga classifiers and adversarial defenses. IEEE Access 2020, 8, 161580–161592. [Google Scholar] [CrossRef]
- Sun, G.; Cong, Y.; Dong, J.; Wang, Q.; Lyu, L.; Liu, J. Data Poisoning Attacks on Federated Machine Learning. IEEE Internet Things J. 2021, 9, 11365–11375. [Google Scholar] [CrossRef]
- Chen, B.; Carvalho, W.; Baracaldo, N.; Ludwig, H.; Edwards, B.; Lee, T.; Molloy, I.; Srivastava, B. Detecting Backdoor Attacks on Deep Neural Networks by Activation Clustering. arXiv 2018, arXiv:1811.03728. [Google Scholar] [CrossRef]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the European Symposium on Research in Computer Security 2020, Darmstadt, Germany, 4–8 October 2020; pp. 480–501. [Google Scholar]
- Seetharaman, S.; Malaviya, S.; Vasu, R.; Shukla, M.; Lodha, S. Influence Based Defense Against Data Poisoning Attacks in Online Learning. arXiv 2021, arXiv:2104.13230. [Google Scholar] [CrossRef]
- Doku, R.; Rawat, D.B. Mitigating Data Poisoning Attacks On a Federated Learning-Edge Computing Network. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; pp. 1–6. [Google Scholar]
- Zhang, J.; Chen, B.; Cheng, X.; Binh, H.T.T.; Yu, S. PoisonGAN: Generative Poisoning Attacks Against Federated Learning in Edge Computing Systems. IEEE Internet Things J. 2020, 8, 3310–3322. [Google Scholar] [CrossRef]
- Chen, Y.; Mao, Y.; Liang, H.; Yu, S.; Wei, Y.; Leng, S. Data Poison Detection Schemes for Distributed Machine Learning. IEEE Access 2020, 8, 7442–7454. [Google Scholar] [CrossRef]
- Ye, Y.; Li, S.; Liu, F.; Tang, Y.; Hu, W. EdgeFed: Optimized Federated Learning Based on Edge Computing. IEEE Access 2020, 8, 209191–209198. [Google Scholar] [CrossRef]
- Lu, X.; Liao, Y.; Lio, P.; Hui, P. Privacy-Preserving Asynchronous Federated Learning Mechanism for Edge Network Computing. IEEE Access 2020, 8, 48970–48981. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, S.; Zhang, P.; Zhou, X.; Shao, X.; Pu, G.; Zhang, Y. Blockchain and Federated Learning for Collaborative Intrusion Detection in Vehicular Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 6073–6084. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Soman, K.P.; Poornachandran, P.; Al-Nemrat, A.; Venkatraman, S. Deep Learning Approach for Intelligent Intrusion Detection System. IEEE Access 2019, 7, 41525–41550. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Srinivasan, S.; Pham, Q.-V.; Padannayil, S.K.; Simran, K. A Visualized Botnet Detection System Based Deep Learning for the Internet of Things Networks of Smart Cities. IEEE Trans. Ind. Appl. 2020, 56, 4436–4456. [Google Scholar] [CrossRef]
- Ravi, V.; Alazab, M.; Srinivasan, S.; Arunachalam, A.; Soman, K.P. Adversarial Defense: DGA-Based Botnets and DNS Homographs Detection Through Integrated Deep Learning. IEEE Trans. Eng. Manag. 2021. early access. [Google Scholar] [CrossRef]
- Sriram, S.; Vinayakumar, R.; Alazab, M.; KP, S. Network Flow based IoT Botnet Attack Detection using Deep Learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 189–194. [Google Scholar]
- Murugesan, A.; Saminathan, B.; Al-Turjman, F.; Kumar, R.L. Analysis on homomorphic technique for data security in fog computing. Trans. Emerg. Telecommun. Technol. 2021, 32, e3990. [Google Scholar] [CrossRef]
- Vijayalakshmi, R.; Vasudevan, V.; Kadry, S.; Kumar, R.L. Optimization of makespan and resource utilization in the fog computing environment through task scheduling algorithm. Int. J. Wavelets Multiresolution Inf. Process. 2020, 18, 1941025. [Google Scholar] [CrossRef]
- Sankar, S.; Somula, R.; Kumar, R.L.; Srinivasan, P.; Jayanthi, M.A. Trust-aware routing framework for internet of things. Int. J. Knowl. Syst. Sci. (IJKSS) 2021, 12, 48–59. [Google Scholar] [CrossRef]
- Wang, Y.; Mianjy, P.; Arora, R. Robust Learning for Data Poisoning Attacks. In Proceedings of the Virtual Mode Only, Proceedings of Machine Learning Research 2021, Virtual, 13 December 2021; pp. 10859–10869. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 19–35. [Google Scholar]
- UCL Database. Machine Learning Databases. 2021. Available online: https://archive.ics.uci.edu/ml/datasets.phphttps://archive.ics.uci.edu/ml/datasets.php (accessed on 23 March 2022).
- UNSW Database. Machine Learning Datasets. 2021. Available online: https://research.unsw.edu.au/projects/toniot-datasetshttps://research.unsw.edu.au/projects/toniot-datasets (accessed on 24 March 2022).
- Paudice, A.; Muñoz-González, L.; Lupu, E.C. Label Sanitization Against Label Flipping Poisoning Attacks. In Proceedings of the ECML PKDD 2018 Workshops, Dublin, Ireland, 10–14 September 2018; pp. 5–15. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No of Instances | No of Attributes |
|---|---|---|
| Heart | 800 | 13 |
| Diabetes | 768 | 8 |
| IoT_Weather | 59,260 | 6 |
| IoT_GPS_Tracker | 58,960 | 5 |
| Poison Rate (%) | ACC | CC | MAE | RMSE | ||||
|---|---|---|---|---|---|---|---|---|
| KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | |
| 0 | 94.1 | 93.625 | 0.974 | 0.979 | 0.0125 | 0.01 | 0.111 | 0.1 |
| 5 | 90.04 | 91 | 0.875 | 0.971 | 0.0709 | 0.013 | 0.245 | 0.117 |
| 10 | 87.75 | 90.375 | 0.817 | 0.972 | 0.104 | 0.013 | 0.293 | 0.117 |
| 15 | 83.12 | 89.75 | 0.764 | 0.962 | 0.129 | 0.018 | 0.326 | 0.137 |
| 20 | 79.25 | 80.87 | 0.688 | 0.94 | 0.169 | 0.016 | 0.372 | 0.127 |
| 25 | 75.75 | 80 | 0.595 | 0.93 | 0.202 | 0.022 | 0.411 | 0.15 |
| Poison Rate (%) | ACC | CC | MAE | RMSE | ||||
|---|---|---|---|---|---|---|---|---|
| KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | |
| 0 | 73.82 | 84.11 | 0.554 | 0.596 | 0.136 | 0.119 | 0.369 | 0.346 |
| 5 | 69.14 | 82.03 | 0.548 | 0.587 | 0.132 | 0.126 | 0.364 | 0.355 |
| 10 | 65.75 | 79.82 | 0.53 | 0.475 | 0.152 | 0.146 | 0.39 | 0.382 |
| 15 | 63.93 | 77.21 | 0.488 | 0.494 | 0.128 | 0.133 | 0.359 | 0.364 |
| 20 | 61.19 | 75.91 | 0.342 | 0.364 | 0.205 | 0.128 | 0.453 | 0.357 |
| 25 | 60.54 | 84.11 | 0.311 | 0.596 | 0.21 | 0.119 | 0.459 | 0.346 |
| Poison Rate (%) | ACC | CC | MAE | RMSE | ||||
|---|---|---|---|---|---|---|---|---|
| KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | |
| 0 | 95.5 | 98.8 | 0.906 | 0.971 | 0.019 | 0.014 | 0.137 | 0.118 |
| 5 | 93.12 | 96.1 | 0.873 | 0.922 | 0.0605 | 0.037 | 0.243 | 0.192 |
| 10 | 89.1 | 93.4 | 0.8 | 0.808 | 0.093 | 0.088 | 0.304 | 0.296 |
| 15 | 85.7 | 89.9 | 0.711 | 0.828 | 0.1315 | 0.079 | 0.361 | 0.281 |
| 20 | 82.8 | 87.9 | 0.649 | 0.726 | 0.152 | 0.118 | 0.387 | 0.343 |
| 25 | 78.5 | 85.0 | 0.542 | 0.692 | 0.19 | 0.136 | 0.434 | 0.368 |
| Poison Rate (%) | ACC | CC | MAE | RMSE | ||||
|---|---|---|---|---|---|---|---|---|
| KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | KSSD | DFSL | |
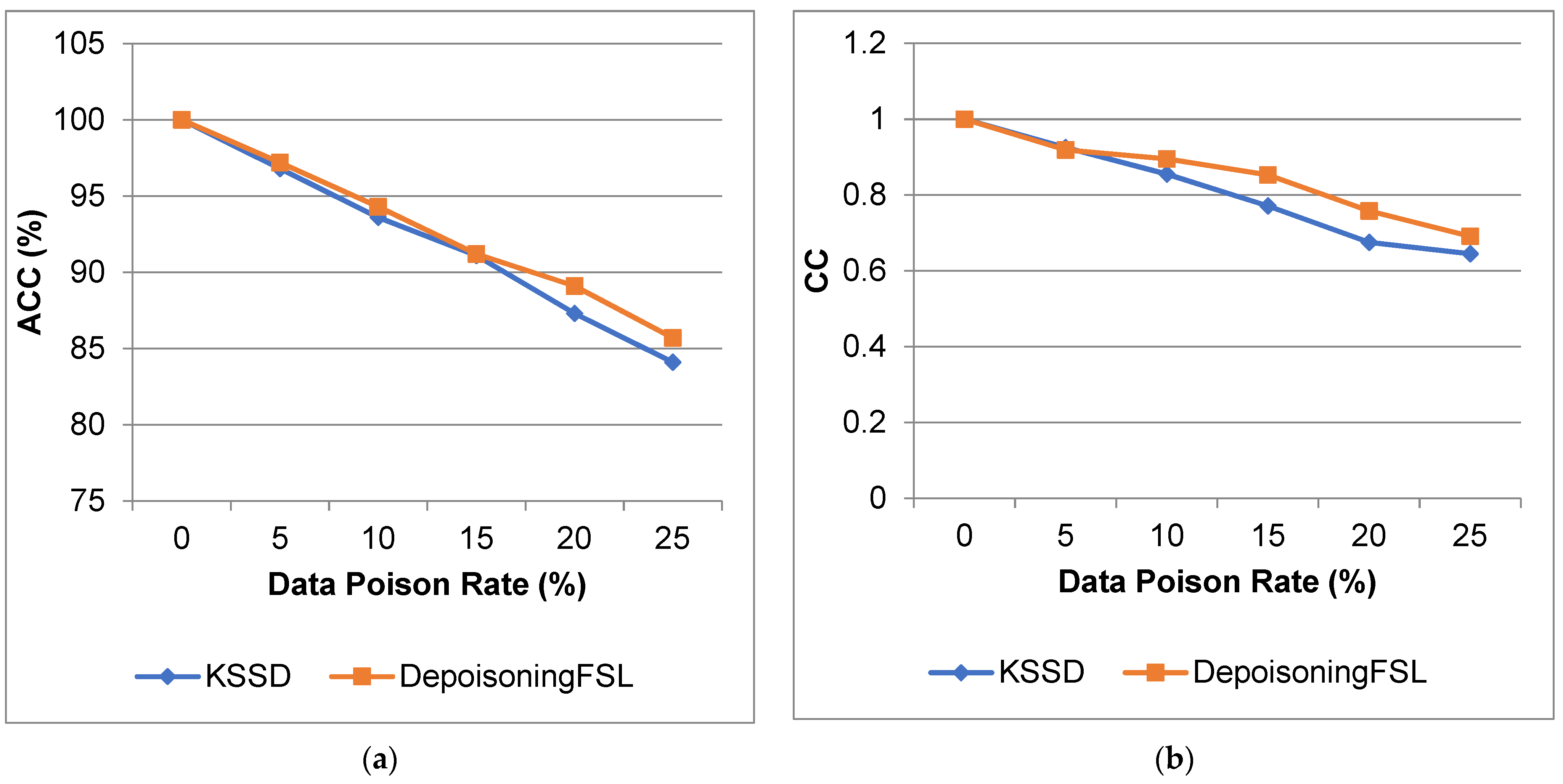
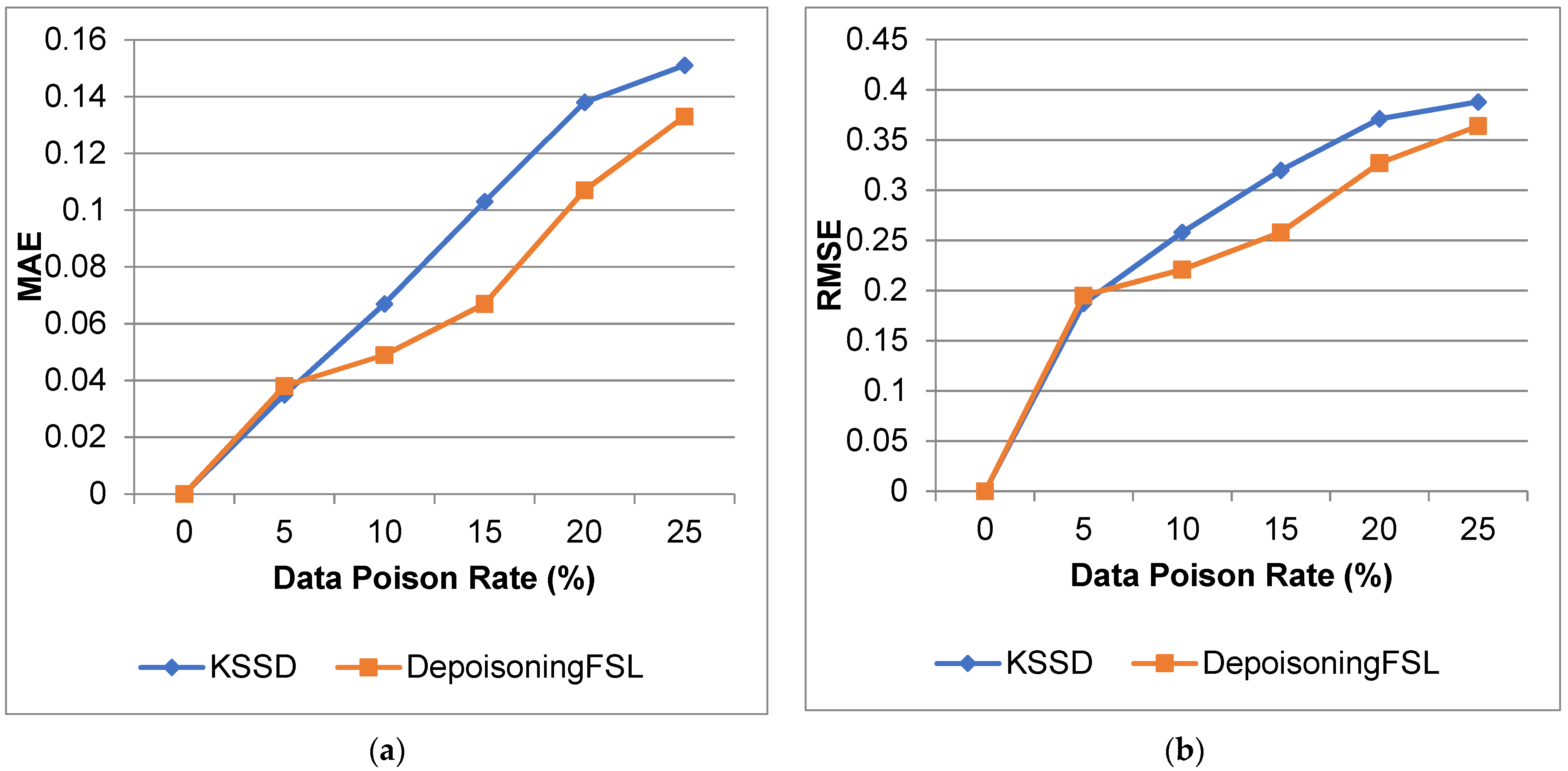
| 0 | 100 | 100 | 1 | 1.0 | 0 | 0 | 0 | 0 |
| 5 | 96.8 | 97.2 | 0.925 | 0.919 | 0.035 | 0.038 | 0.187 | 0.195 |
| 10 | 93.6 | 94.3 | 0.855 | 0.895 | 0.067 | 0.049 | 0.258 | 0.221 |
| 15 | 91.1 | 91.2 | 0.771 | 0.853 | 0.103 | 0.067 | 0.32 | 0.258 |
| 20 | 87.3 | 89.1 | 0.675 | 0.758 | 0.138 | 0.107 | 0.371 | 0.327 |
| 25 | 84.1 | 85.7 | 0.645 | 0.691 | 0.151 | 0.133 | 0.388 | 0.364 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, F.; Kumar, R.L.; Abidi, M.H.; Kadry, S.; Alkhalefah, H.; Aboudaif, M.K. Federated Split Learning Model for Industry 5.0: A Data Poisoning Defense for Edge Computing. Electronics 2022, 11, 2393. https://doi.org/10.3390/electronics11152393
Khan F, Kumar RL, Abidi MH, Kadry S, Alkhalefah H, Aboudaif MK. Federated Split Learning Model for Industry 5.0: A Data Poisoning Defense for Edge Computing. Electronics. 2022; 11(15):2393. https://doi.org/10.3390/electronics11152393
Chicago/Turabian StyleKhan, Firoz, R. Lakshmana Kumar, Mustufa Haider Abidi, Seifedine Kadry, Hisham Alkhalefah, and Mohamed K. Aboudaif. 2022. "Federated Split Learning Model for Industry 5.0: A Data Poisoning Defense for Edge Computing" Electronics 11, no. 15: 2393. https://doi.org/10.3390/electronics11152393
APA StyleKhan, F., Kumar, R. L., Abidi, M. H., Kadry, S., Alkhalefah, H., & Aboudaif, M. K. (2022). Federated Split Learning Model for Industry 5.0: A Data Poisoning Defense for Edge Computing. Electronics, 11(15), 2393. https://doi.org/10.3390/electronics11152393