
Design Framework for ReRAM-Based DNN Accelerators with Accuracy and Hardware Evaluation


Abstract
:1. Introduction
- We have integrated RRAM’s non-linear properties, including lognormal distribution, leakage current, IR drop, and sneak path into the proposed design framework. So far, there is no behavior simulator consider these non-linear properties at the same time.
- We use SystemC with TLM modeling method to build our virtual platform. Thus, our behavior simulator can efficiently simulate hardware performance with real hardware behavior. To our knowledge, the proposed design framework is the first behavior-level ReRAM-based DNN accelerator simulator that can simulate real hardware behavior.
- The proposed design framework can evaluate not only accuracy, but also hardware cost. Thus, the proposed design framework can be used for the behavior-level design space exploration (e.g., to explore the trade-off between accuracy and hardware cost between with respect to different XBar height/width, bandwidth, etc.)
2. Preliminaries
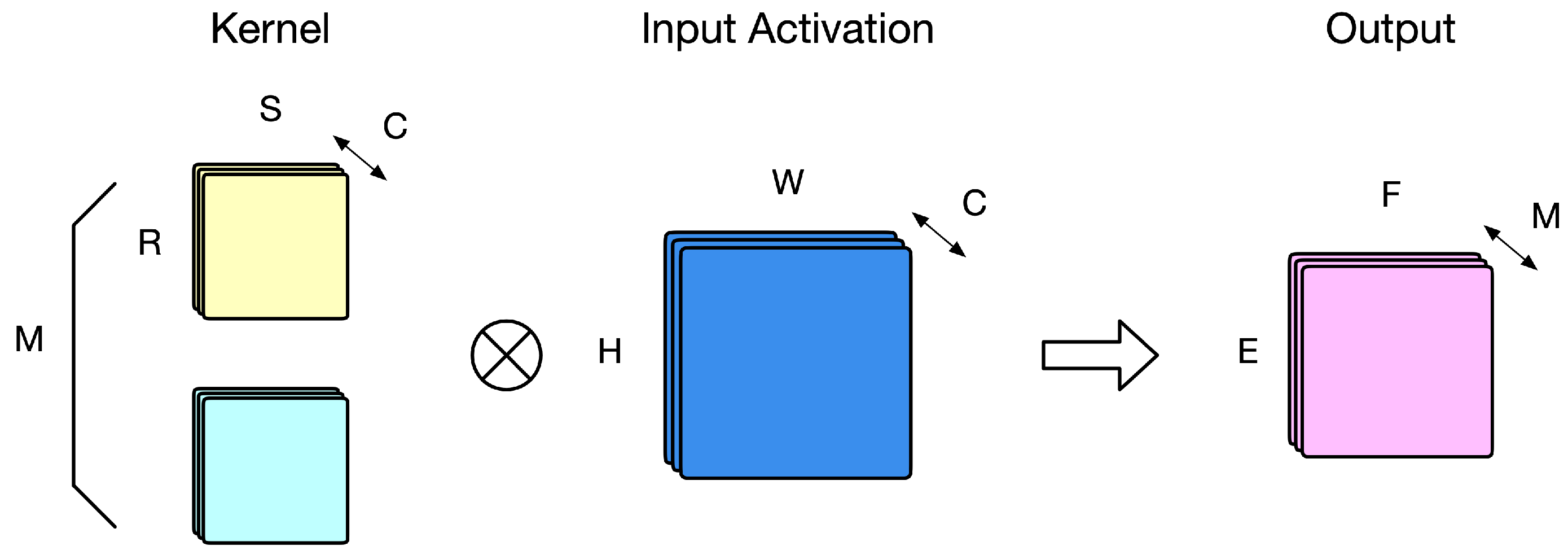
2.1. Convolution Neural Network
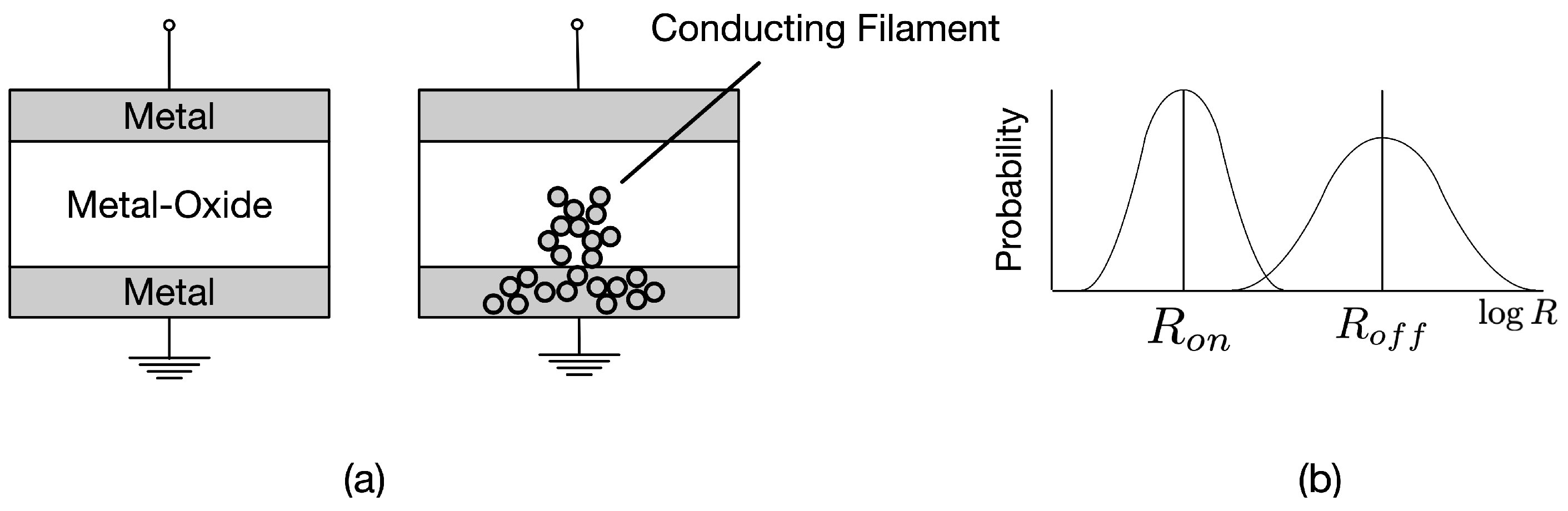
2.2. ReRAM and ReRAM Array
2.3. Dataflow of CIM
3. Noise Analysis
3.1. Lognormal Distribution
3.2. Leakage Current
3.3. Sneak Path
3.4. IR Drop
3.5. Peripherals
4. Virtual Platform Architectures
4.1. ReRAM Array
4.2. DAC/ADC
4.3. XBar
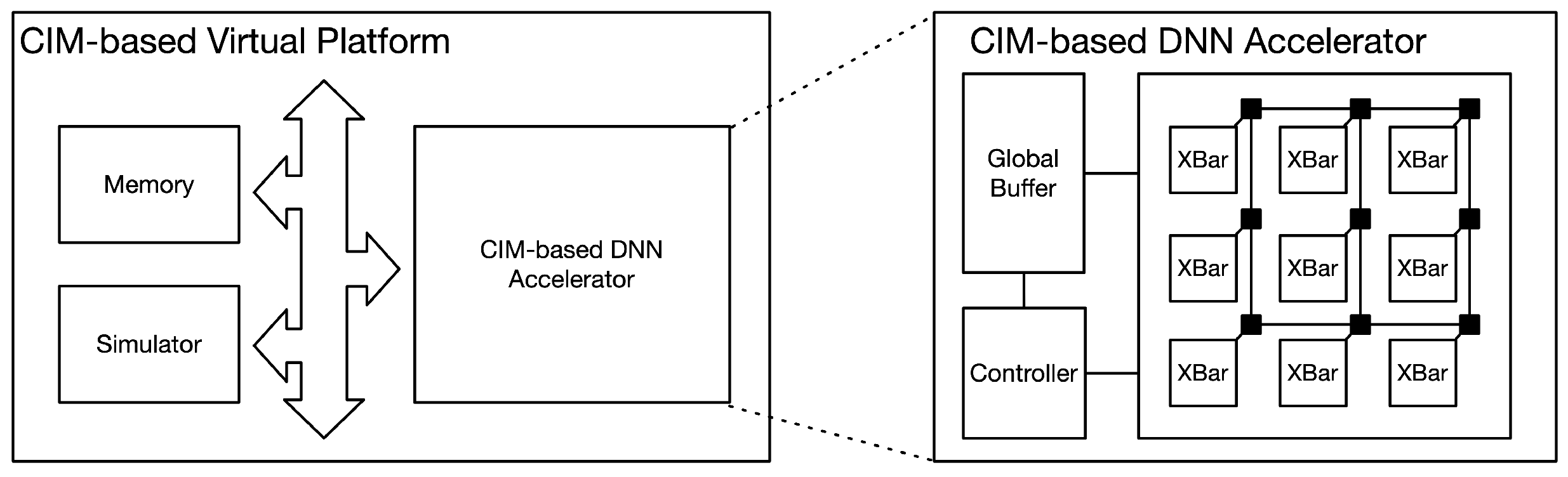
4.4. CIM-Based DNN Accelerator
4.5. CIM-Based Virtual Platform
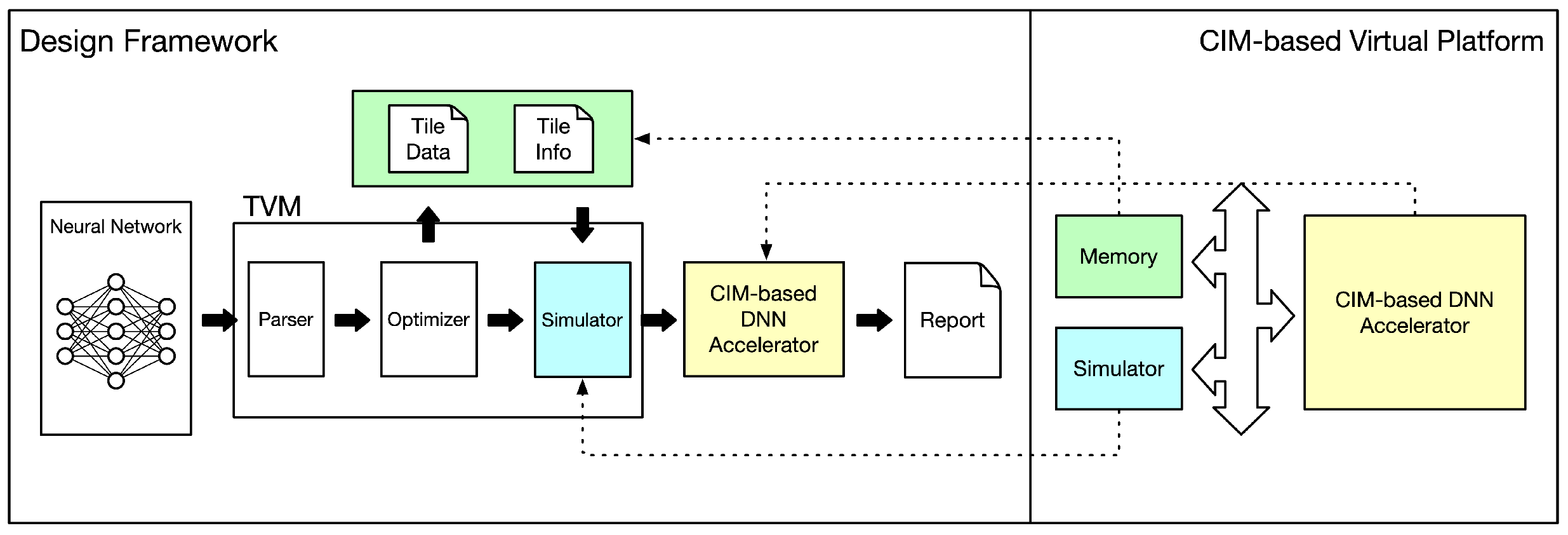
5. Design Framework
6. Experiment Results
6.1. Validation of ReRAM Model
6.2. Accuracy Evaluation
6.3. On/Off Ratio of ReRAM
6.4. Utilization Evaluation
6.5. Energy Delay Area Product
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Lu, W.; Yan, G.; Li, J.; Gong, S.; Han, Y.; Li, X. FlexFlow: A Flexible Dataflow Accelerator Architecture for Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), Austin, TX, USA, 4–8 February 2017; pp. 553–564. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Li, H.; Shi, C.; Li, X. Systolic Cube: A Spatial 3D CNN Accelerator Architecture for Low Power Video Analysis. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Du, Z.; Fasthuber, R.; Chen, T.; Ienne, P.; Li, L.; Luo, T.; Feng, X.; Chen, Y.; Temam, O. Shidiannao: Shifting Vision Processing Closer to the Sensor. In Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 13–17 June 2015; Volume 43, pp. 92–104. [Google Scholar] [CrossRef]
- Kwon, H.; Samajdar, A.; Krishna, T. MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects. ACM SIGPLAN Not. 2018, 53, 461–475. [Google Scholar] [CrossRef]
- Chen, Y.H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; Volume 44, pp. 367–379. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Yang, T.J.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE J. Emerg. Sel. Top. Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Chen, X.; Wang, Y.; Li, C.; You, H.; Fu, Y.; Xie, Y.; Wang, Z.; Lin, Y. SmartExchange: Trading Higher-cost Memory Storage/Access for Lower-cost Computation. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 954–967. [Google Scholar] [CrossRef]
- Chatarasi, P.; Kwon, H.; Raina, N.; Malik, S.; Haridas, V.; Parashar, A.; Pellauer, M.; Krishna, T.; Sarkar, V. Marvel: A Data-centric Compiler for DNN Operators on Spatial Accelerators. arXiv 2020, arXiv:2002.07752. [Google Scholar]
- Kwon, H.; Chatarasi, P.; Pellauer, M.; Parashar, A.; Sarkar, V.; Krishna, T. Understanding Reuse, Performance, and Hardware Cost of DNN Dataflows: A Data-Centric Approach Using MAESTRO. arXiv 2020, arXiv:1805.02566. [Google Scholar]
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Strachan, J.P.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A Convolutional Neural Network Accelerator with In-Situ Analog Arithmetic in Crossbars. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; Volume 44, pp. 14–26. [Google Scholar] [CrossRef]
- Chi, P.; Li, S.; Xu, C.; Zhang, T.; Zhao, J.; Liu, Y.; Wang, Y.; Xie, Y. PRIME: A Novel Processing-in-Memory Architecture for Neural Network Computation in ReRAM-Based Main Memory. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016; Volume 44, pp. 27–39. [Google Scholar] [CrossRef]
- Wong, H.S.P.; Lee, H.Y.; Yu, S.; Chen, Y.S.; Wu, Y.; Chen, P.S.; Lee, B.; Chen, F.T.; Tsai, M.J. Metal–Oxide RRAM. Proc. IEEE 2012, 100, 1951–1970. [Google Scholar] [CrossRef]
- Park, J. Neuromorphic Computing Using Emerging Synaptic Devices: A Retrospective Summary and an Outlook. Electronics 2020, 9, 1414. [Google Scholar] [CrossRef]
- Mittal, S. A Survey of ReRAM-Based Architectures for Processing-In-Memory and Neural Networks. Mach. Learn. Knowl. Extr. 2018, 1, 5. [Google Scholar] [CrossRef] [Green Version]
- Feinberg, B.; Wang, S.; Ipek, E. Making Memristive Neural Network Accelerators Reliable. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 52–65. [Google Scholar] [CrossRef]
- Wang, S.; Jin, S.; Bai, D.; Fan, Y.; Shi, H.; Fernandez, C. A critical review of improved deep learning methods for the remaining useful life prediction of lithium-ion batteries. Energy Rep. 2021, 7, 5562–5574. [Google Scholar] [CrossRef]
- Wang, S.; Takyi-Aninakwa, P.; Jin, S.; Yu, C.; Fernandez, C.; Stroe, D.I. An improved feedforward-long short-term memory modeling method for the whole-life-cycle state of charge prediction of lithium-ion batteries considering current-voltage-temperature variation. Energy 2022, 254, 124224. [Google Scholar] [CrossRef]
- Xia, L.; Li, B.; Tang, T.; Gu, P.; Chen, P.Y.; Yu, S.; Cao, Y.; Wang, Y.; Xie, Y.; Yang, H. MNSIM: Simulation Platform for Memristor-Based Neuromorphic Computing System. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 1009–1022. [Google Scholar] [CrossRef]
- Rasch, M.J.; Moreda, D.; Gokmen, T.; Gallo, M.L.; Carta, F.; Goldberg, C.; Maghraoui, K.E.; Sebastian, A.; Narayanan, V. A flexible and fast PyTorch toolkit for simulating training and inference on analog crossbar arrays. arXiv 2021, arXiv:2104.02184. [Google Scholar]
- Bahar, I.; Lin, M.Y.; Cheng, H.Y.; Lin, W.T.; Yang, T.H.; Tseng, I.C.; Yang, C.L.; Hu, H.W.; Chang, H.S.; Li, H.P.; et al. DL-RSIM: A simulation framework to enable reliable ReRAM-based accelerators for deep learning. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, P.Y.; Peng, X.; Yu, S. NeuroSim+: An Integrated Device-to-Algorithm Framework for Benchmarking Synaptic Devices and Array Architectures. In Proceedings of the 2017 IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 2–6 December 2017; pp. 6.1.1–6.1.4. [Google Scholar] [CrossRef]
- Mohsenin, T.; Zhao, W.; Chen, Y.; Mutlu, O.; Zhu, Z.; Sun, H.; Qiu, K.; Xia, L.; Krishnan, G.; Dai, G.; et al. MNSIM 2.0: A Behavior-Level Modeling Tool for Memristor-based Neuromorphic Computing Systems. In Proceedings of the 2020 on Great Lakes Symposium on VLSI, Online, 7–9 September 2020; pp. 83–88. [Google Scholar] [CrossRef]
- Chen, P.Y.; Peng, X.; Yu, S. NeuroSim: A Circuit-Level Macro Model for Benchmarking Neuro-Inspired Architectures in Online Learning. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 3067–3080. [Google Scholar] [CrossRef]
- Xia, L.; Li, B.; Tang, T.; Gu, P.; Yin, X.; Huangfu, W.; Chen, P.Y.; Yu, S.; Cao, Y.; Wang, Y.; et al. System Simulation of Memristor Based Computation In Memory Platforms. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 469–474. [Google Scholar] [CrossRef]
- BanaGozar, A.; Vadivel, K.; Stuijk, S.; Corporaal, H.; Wong, S.; Lebdeh, M.A.; Yu, J.; Hamdioui, S. CIM-SIM: Computation In Memory SIMuIator. In Proceedings of the 22nd International Workshop on Software and Compilers for Embedded Systems, Sankt Goar, Germany, 27–28 May 2019; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Galicia, M.; Merchant, F.; Leupers, R. A Parallel SystemC Virtual Platform for Neuromorphic Architectures. arXiv 2021, arXiv:2112.13157. [Google Scholar]
- Guan, X.; Yu, S.; Wong, H.S.P. A SPICE Compact Model of Metal Oxide Resistive Switching Memory with Variations. IEEE Electron Device Lett. 2012, 33, 1405–1407. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework | System Level | Virtual Platform | Lognormal Distribution | Non-Linear Properties Leakage Current | Sneak Path | IR Drop | HW Cost |
|---|---|---|---|---|---|---|---|
| [24] | ✓ | ✓ | ✓ | ||||
| [25] | ✓ | ✓ | ✓ | ✓ | |||
| [26] | ✓ | ✓ | ✓ | ||||
| [27] | ✓ | ✓ | ✓ | ||||
| [28] | ✓ | ✓ | ✓ | ||||
| [29] | ✓ | ✓ | ✓ | ✓ | |||
| [30] | ✓ | ✓ | ✓ | ||||
| [31] | ✓ | ✓ | ✓ | ||||
| [32] | ✓ | ✓ | ✓ | ||||
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Parameters | Value | Description |
|---|---|---|
| I-V fitting parameter | ||
| I-V fitting parameter | ||
| I-V fitting parameter | ||
| 293 K | Ambient temperature | |
| 100/0.33 S | ReRAM Max/Min conductance |
| Models | Input Shape | Number of Convolution Layers |
|---|---|---|
| LeNet | 3 | |
| AlexNet | 5 | |
| VGG-8 | 5 | |
| VGG-16 | 13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kao, H.-Y.; Huang, S.-H.; Cheng, W.-K. Design Framework for ReRAM-Based DNN Accelerators with Accuracy and Hardware Evaluation. Electronics 2022, 11, 2107. https://doi.org/10.3390/electronics11132107
Kao H-Y, Huang S-H, Cheng W-K. Design Framework for ReRAM-Based DNN Accelerators with Accuracy and Hardware Evaluation. Electronics. 2022; 11(13):2107. https://doi.org/10.3390/electronics11132107
Chicago/Turabian StyleKao, Hsu-Yu, Shih-Hsu Huang, and Wei-Kai Cheng. 2022. "Design Framework for ReRAM-Based DNN Accelerators with Accuracy and Hardware Evaluation" Electronics 11, no. 13: 2107. https://doi.org/10.3390/electronics11132107
APA StyleKao, H.-Y., Huang, S.-H., & Cheng, W.-K. (2022). Design Framework for ReRAM-Based DNN Accelerators with Accuracy and Hardware Evaluation. Electronics, 11(13), 2107. https://doi.org/10.3390/electronics11132107