
ML-CLOCK: Efficient Page Cache Algorithm Based on Perceptron-Based Neural Network


Abstract
:1. Introduction
- Is it possible to discover a page, which will not be accessed in the future, on unexpected I/O patterns by taking the benefit of ML technology?
- Given a set of available information, such as the page’s recency and frequency, which one should we consider more important?
- Is it always useful to evict a page without considerations of asymmetric read and write costs on the underlying storage devices?
2. Background
2.1. Neural Network-Based Learning Algorithm
2.2. Perceptron-Based Algorithm
3. ML-CLOCK
- Requirement 1: It reduces the number of access to the underlying storage media.
- Requirement 2: It orchestrates functionalities of machine learning (ML) to enable the intelligent eviction policy.
3.1. Learning and Prediction Model
- For prediction, there are three of input values: reuse-distance for recency, reference count for frequency, and bias as mentioned earlier.
- Prediction operation is triggered either to find a victim page or to make decisions for the learning operation.
- Learning operation is responsible for calculating and updating weight values for the input values.
- Predicted value 0: It has a low possibility that access occurs in a short period of time.
- Predicted value 1: It provides a second chance because of an opportunity for access in the near future.
3.2. ML-CLOCK Algorithm
| Algorithm 1 ML-CLOCK |
|
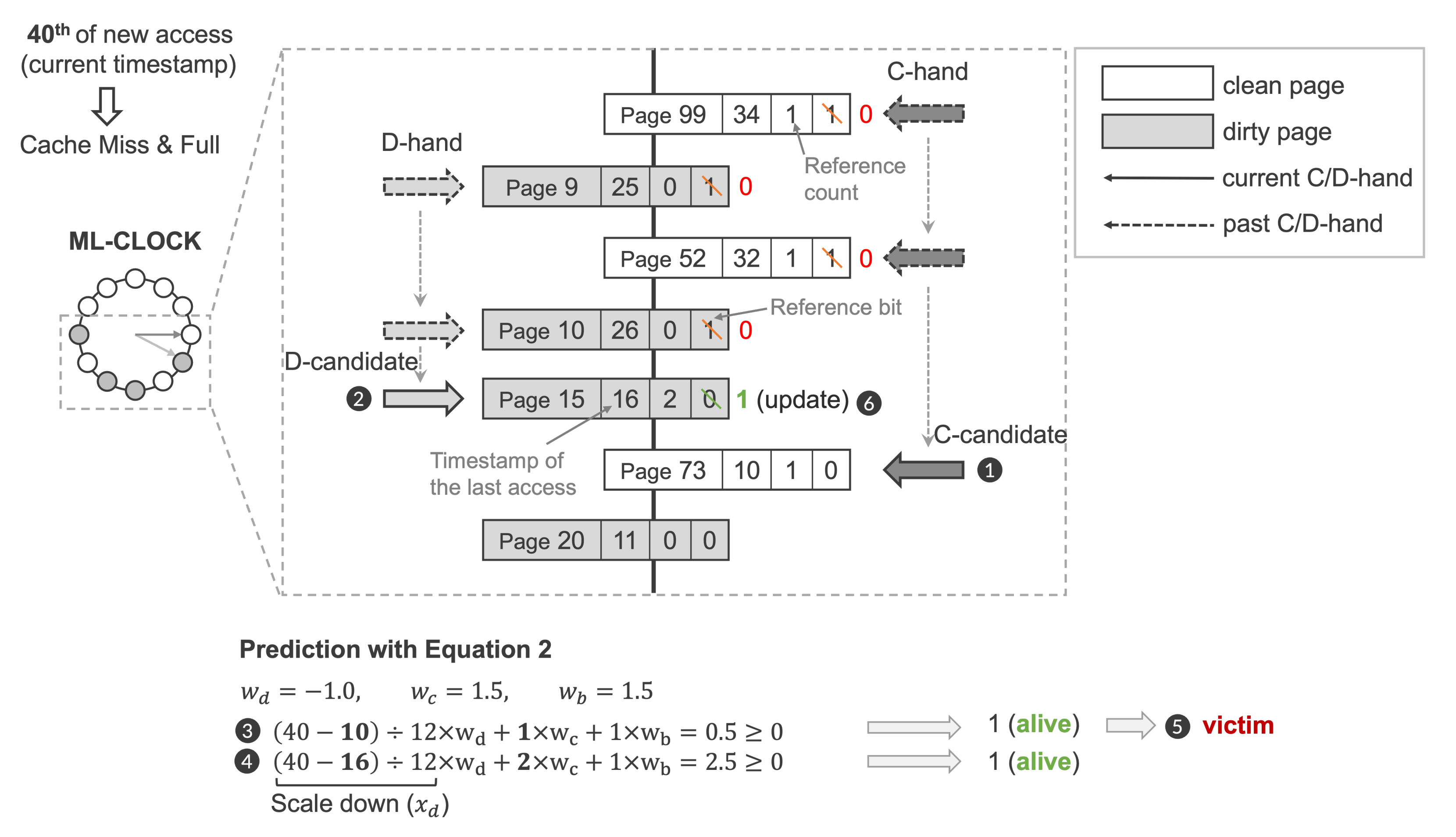
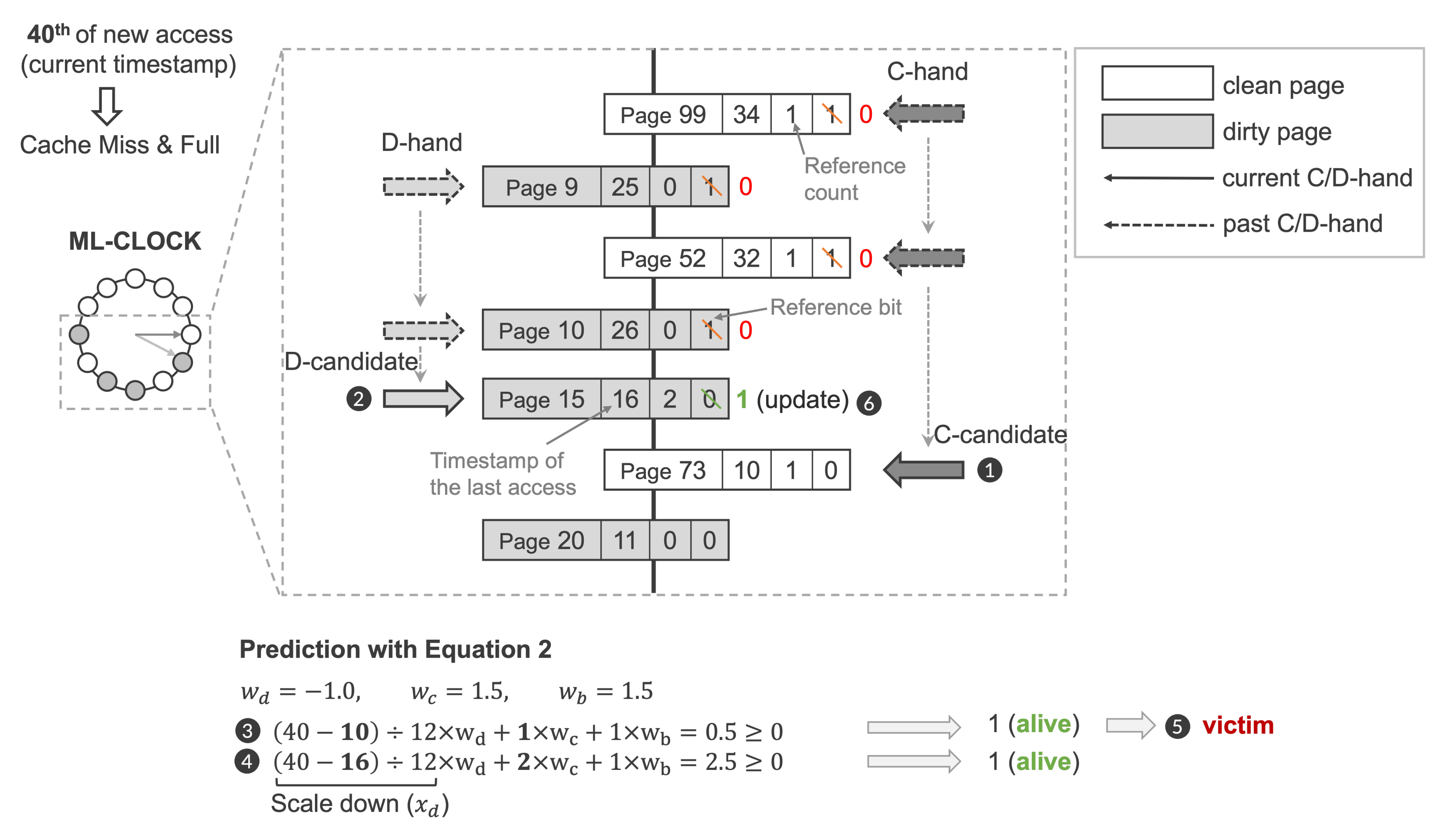
3.3. Example
4. Evaluation
- How much does ML-CLOCK improve the cache hit ratio under different workloads (Section 4.1)?
- How well does the prediction of ML-CLOCK apply corrections (Section 4.2)?
- How much does ML-CLOCK include performance overhead to apply the mechanism of machine learning (Section 4.3)?
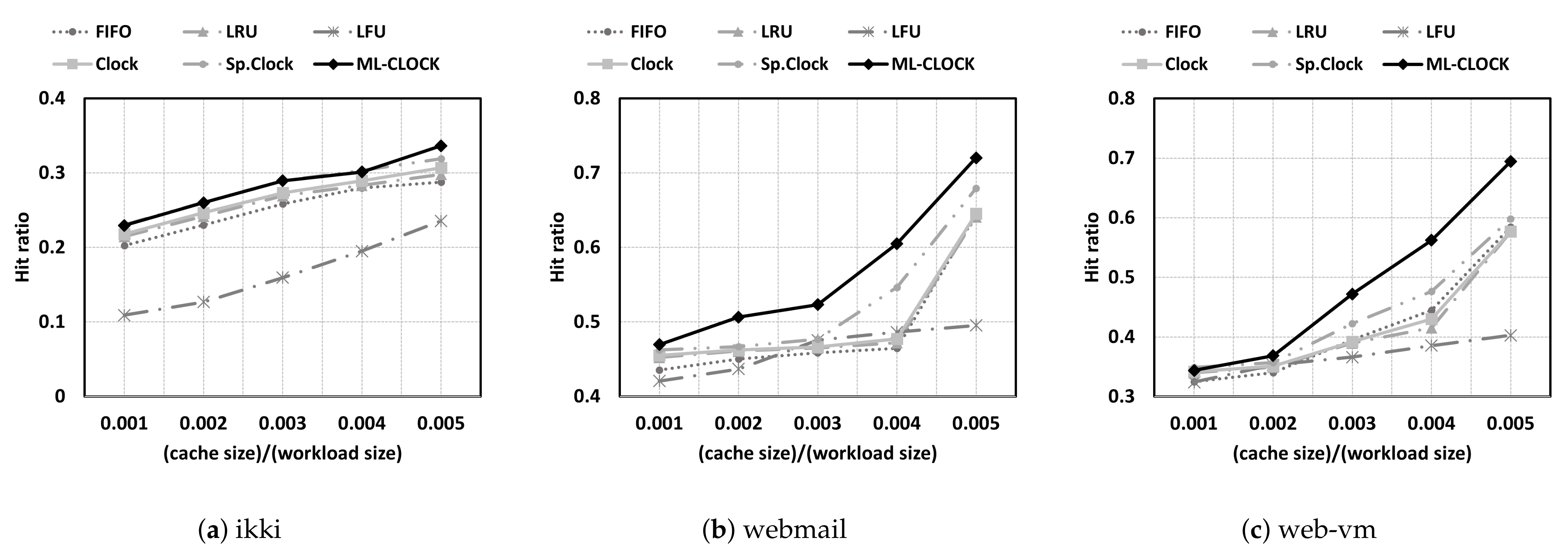
4.1. Cache Hit Ratio
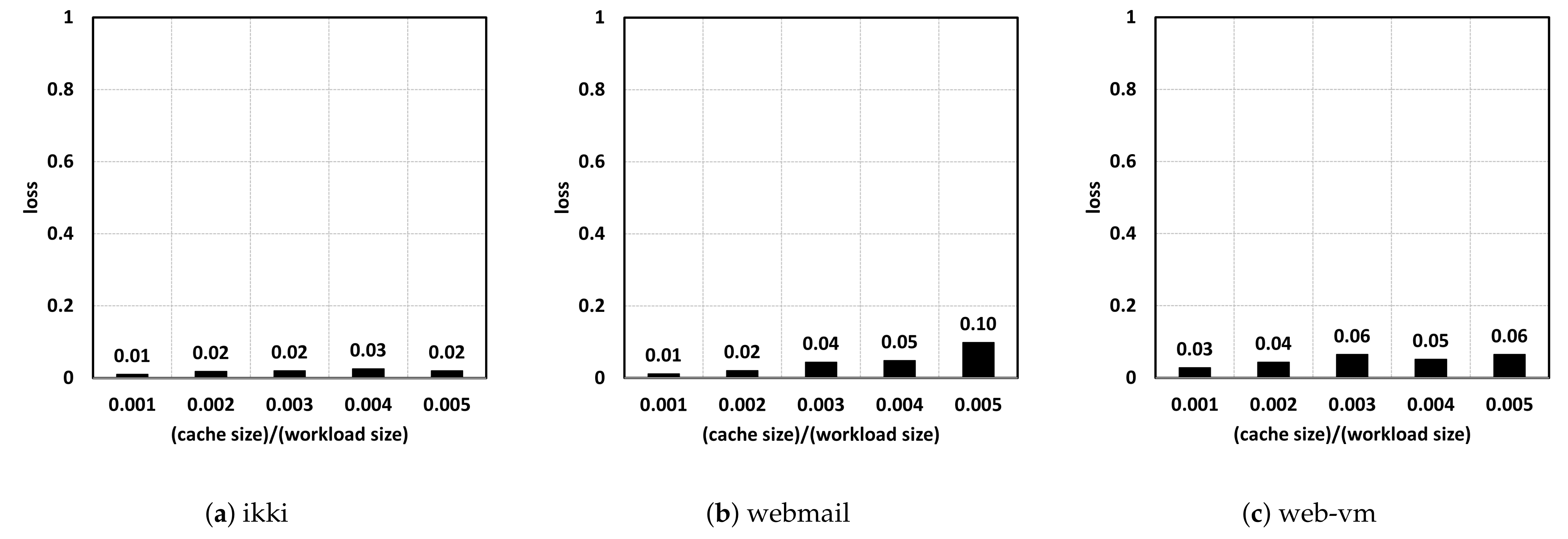
4.2. Loss of Accuracy
4.3. Simulated Performance
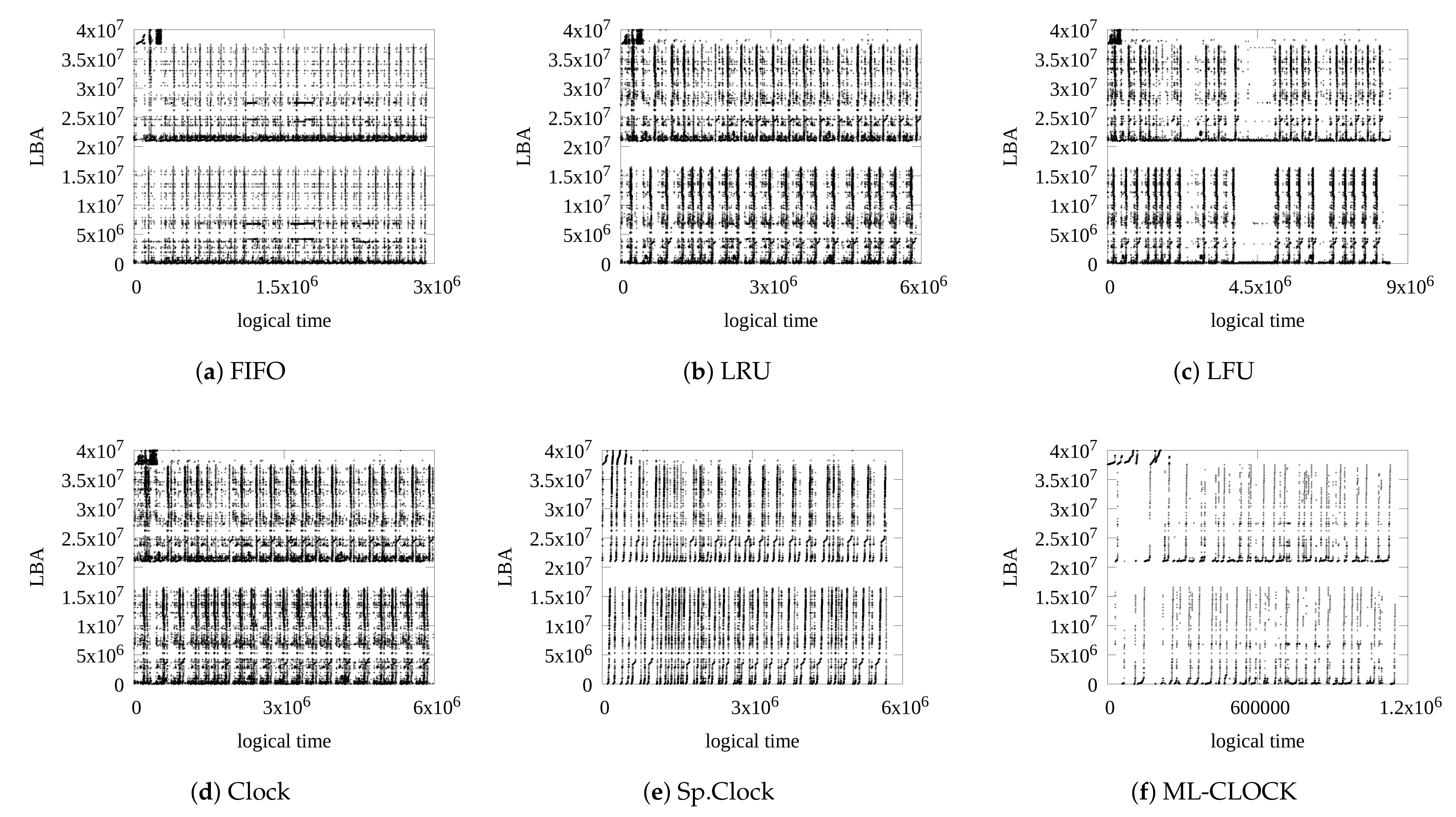
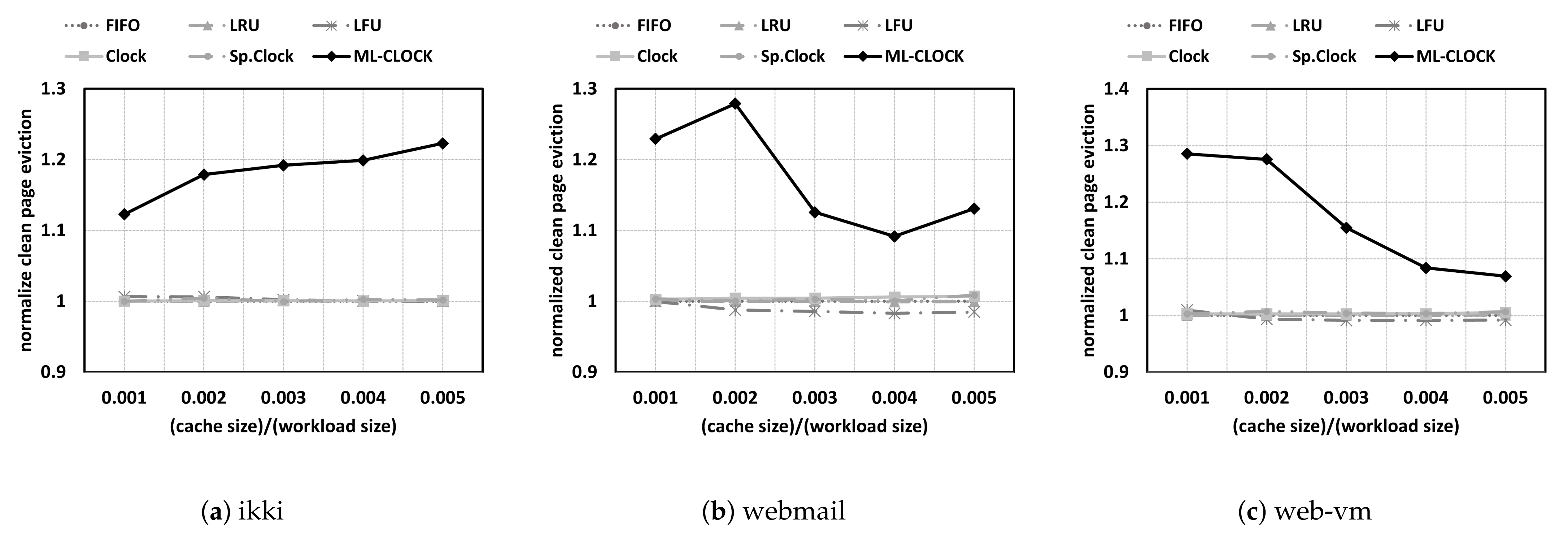
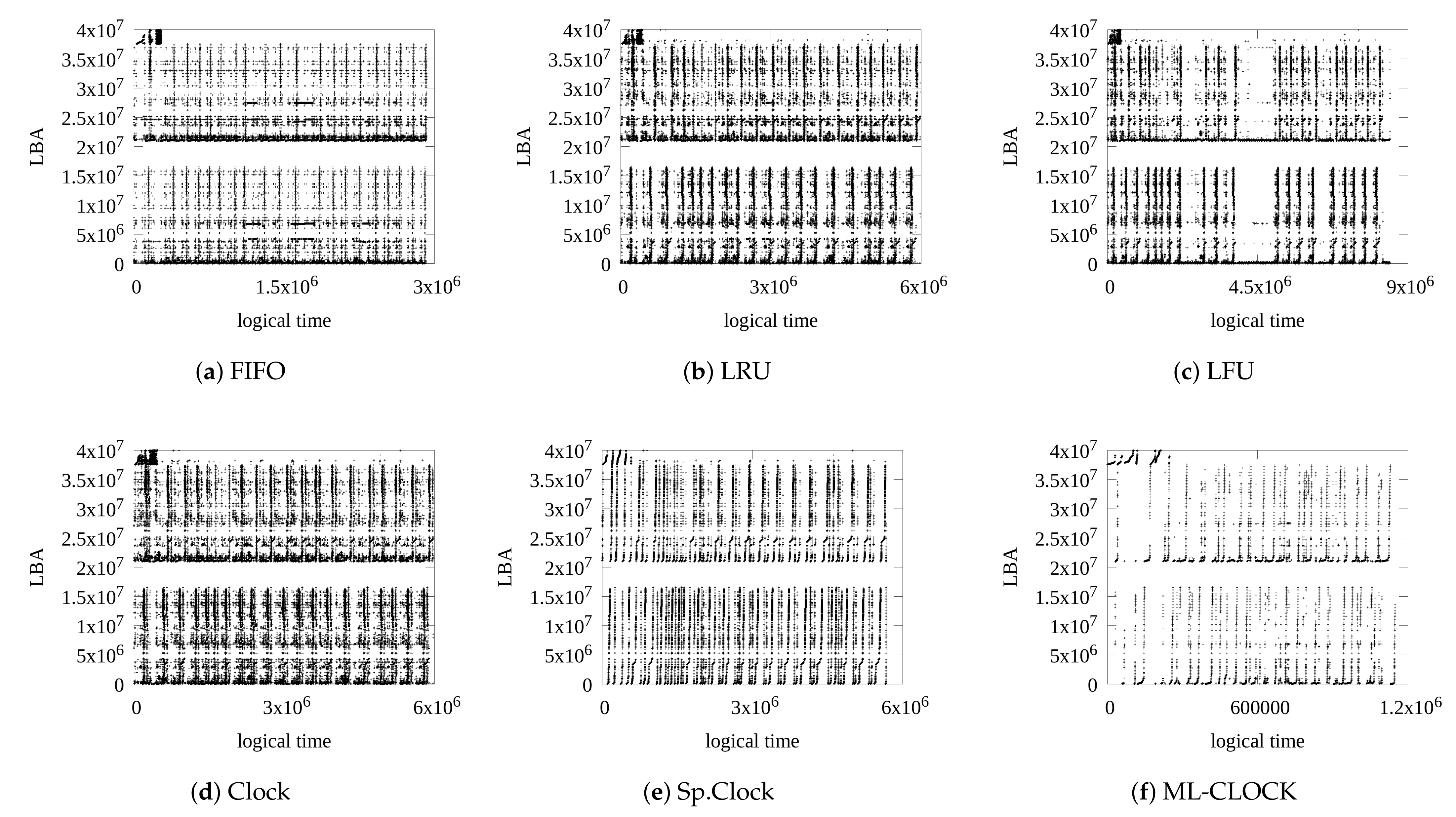
4.4. Analysis of Read and Write Patterns
5. Related Work
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence; |
| ML | Machine Learning; |
| SLP | Single-Layer Perceptron; |
| MLP | Multi-Layer Perceptron; |
| ANN | Artificial Neural Network |
| CNN | Convolutional Neural network; |
| LSTM | Long Short-Term Memory; |
| ML-CLOCK | Maching Learning based CLOCK algorithm; |
| C-hand | Clean-hand; |
| D-hand | Dirty-hand; |
| C-candidate | Clean-candidate; |
| D-candidate | Dirty-candidate. |
References
- Silberschatz, A.; Galvin, P.B.; Gagne, G. Operating System Concepts, 9th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2003; pp. 401–412. [Google Scholar]
- Corbato, F.J. A Paging Experiment with the Multics System; Technical Report, MIT Project MAC Report MAC-M-384; MIT: Cambridge, MA, USA, 1968. [Google Scholar]
- Jiang, S.; Chen, F.; Zhang, X. CLOCK-Pro: An Effective Improvement of the CLOCK Replacement. In Proceedings of the USENIX Annual Technical Conference, General Track, Anaheim, CA, USA, 10–15 April 2005. [Google Scholar]
- Jiang, S.; Zhang, X. LIRS: An efficient low inter-reference recency set replacement policy to improve buffer cache performance. ACM SIGMETRICS Perform. Eval. Rev. 2002, 30, 31–42. [Google Scholar] [CrossRef]
- Bansal, S.; Modha, D.S. CAR: Clock with Adaptive Replacement. In Proceedings of the USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 31 March–2 April 2004; pp. 187–200. [Google Scholar]
- Kim, H.; Ryu, M.; Ramachandran, U. What is a good buffer cache replacement scheme for mobile flash storage? ACM SIGMETRICS Perform. Eval. Rev. 2012, 20, 235–246. [Google Scholar] [CrossRef] [Green Version]
- Kang, D.H.; Min, C.; Eom, Y.I. An Efficient Buffer Replacement Algorithm for NAND Flash Storage Devices. In Proceedings of the International Symposium on Modelling, Analysis & Simulation of Computer and Telecommunication Systems, Paris, France, 9–11 September 2014. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Lee, S. Reducing tail latency of DNN-based recommender systems using in-storage processing. In Proceedings of the ACM SIGOPS Asia-Pacific Workshop on Systems, Tsukuba, Japan, 24–25 August 2020. [Google Scholar]
- Teran, E.; Wang, Z.; Jiménez, D.A. Perceptron learning for reuse prediction. In Proceedings of the Annual IEEE/ACM International Symposium on Microarchitecture, Taipei, Taiwan, 15–19 October 2016. [Google Scholar]
- Cao, Z.; Tarasov, V.; Tiwari, S.; Zadok, E. Towards better understanding of black-box auto-tuning: A comparative analysis for storage systems. In Proceedings of the USENIX Annual Technical Conference, Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Rodriguez, L.V.; Yusuf, F.; Lyons, S.; Paz, E.; Rangaswami, R.; Liu, J.; Zhao, M.; Narasimhan, G. Learning Cache Replacement with CACHEUS. In Proceedings of the USENIX Conference on File and Storage Technologies, Online, 23–25 February 2021. [Google Scholar]
- Liu, W.; Cui, J.; Liu, J.; Yang, L.T. MLCache: A space-efficient cache scheme based on reuse distance and machine learning for NVMe SSDs. In Proceedings of the IEEE/ACM International Conference On Computer Aided Design, San Diego, CA, USA, 2–5 November 2020. [Google Scholar]
- Schroeder, B.; Lagisetty, R.; Merchant, A. Flash reliability in production: The expected and the unexpected. In Proceedings of the USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 22–25 February 2016. [Google Scholar]
- Toshiba Makes Major Advances in NAND Flash Memory with 3-Bit-per-Cell 32nm Generation and with 4-Bit-per-Cell 43 nm Technology. Available online: https://www.global.toshiba/ww/news/corporate/2009/02/pr1102.html (accessed on 23 September 2021).
- Yoo, S.; Shin, D. Reinforcement Learning-Based SLC Cache Technique for Enhancing SSD Write Performance. In Proceedings of the USENIX Workshop on Hot Topics in Storage and File Systems, Online, 13–14 July 2020. [Google Scholar]
- Minsky, M.; Papert, S.A. Perceptrons: An Introduction to Computational Geometry; MIT Press: Cambridge, MA, USA, 2017; pp. 1–316. [Google Scholar]
- What Is Artificial Intelligence (AI)? Available online: https://www.ibm.com/cloud/learn/what-is-artificial-intelligence (accessed on 9 October 2021).
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Sahoo, D.; Pham, Q.; Lu, J.; Hoi, S.C. Online deep learning: Learning deep neural networks on the fly. arXiv 2017, arXiv:1711.03705. [Google Scholar]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online multi-object tracking using CNN-based single object tracker with spatial-temporal attention mechanism. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ergen, T.; Kozat, S.S. Efficient online learning algorithms based on LSTM neural networks. IEEE Trans. Neural Networks Learn. Syst. 2017, 29, 3772–3783. [Google Scholar]
- Hoi, S.C.; Sahoo, D.; Lu, J.; Zhao, P. Online learning: A comprehensive survey. arXiv 2018, arXiv:1802.02871. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Hu, W.S.; Li, H.C.; Pan, L.; Li, W.; Tao, R.; Du, Q. Spatial–Spectral Feature Extraction via Deep ConvLSTM Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 4237–4250. [Google Scholar] [CrossRef]
- Yin, J.; Qi, C.; Chen, Q.; Qu, J. Spatial-Spectral Network for Hyperspectral Image Classification: A 3-D CNN and Bi-LSTM Framework. Remote Sens. 2021, 13, 2353. [Google Scholar] [CrossRef]
- Verma, A.; Koller, R.; Useche, L.; Rangaswami, R. SRCMap: Energy Proportional Storage Using Dynamic Consolidation. In Proceedings of the USENIX Conference on File and Storage Technologies, San Jose, CA, USA, 23–26 February 2010. [Google Scholar]
- Sudan, K.; Badam, A.; Nellans, D. NAND-flash: Fast storage or slow memory? In Proceedings of the Non-Volatile Memory Workshop, La Jolla, CA, USA, 4–6 March 2012; pp. 1–2. [Google Scholar]
- Jo, H.; Kang, J.U.; Park, S.Y.; Kim, J.S.; Lee, J. FAB: Flash-aware buffer management policy for portable media players. IEEE Trans. Consum. Electron. 2006, 52, 485–493. [Google Scholar]
- Kim, H.; Ahn, S. BPLRU: A Buffer Management Scheme for Improving Random Writes in Flash Storage. In Proceedings of the USENIX Conference on File and Storage Technologies, San Jose, CA, USA, 26–29 February 2008. [Google Scholar]
- Debnath, B.; Subramanya, S.; Du, D.; Lilja, D.J. Large block CLOCK (LB-CLOCK): A write caching algorithm for solid state disks. In Proceedings of the IEEE International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems, London, UK, 21–23 September 2009. [Google Scholar]
- Sethumurugan, S.; Yin, J.; Sartori, J. Designing a Cost-Effective Cache Replacement Policy using Machine Learning. In Proceedings of the IEEE International Symposium on High-Performance Computer Architecture, 27 February–3 March 2021. [Google Scholar]
- Zhang, Y.; Zhou, K.; Huang, P.; Wang, H.; Hu, J.; Wang, Y.; Ji, Y.; Cheng, B. A machine learning based write policy for SSD cache in cloud block storage. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Grenoble, France, 9–13 March 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SLP [8] | MLP [9] | CNN [10] | LSTM [11] | |
|---|---|---|---|---|
| Time/Space Overhead | Low | High | High | High |
| Overfitting Probability | Low | High | High | High |
| Online Learning | ✓ | ✗ | ✗ | ✗ |
| Linear Binary Classification | ✓ | ✗ | ✗ | ✗ |
| Non-linear Classification/Regression | ✗ | ✓ | ✓ | ✓ |
| Image Classification/Regression | ✗ | ✗ | ✓ | ✗ |
| Sequence Classification/Regression | ✗ | ✗ | ✗ | ✓ |
| Predicted Value (C-Candidate) | Predicted Value (D-Candidate) | Victim Page |
|---|---|---|
| ✗ | ✗ | C-candidate |
| ✗ | ✓ | C-candidate |
| ✓ | ✗ | D-candidate |
| ✓ | ✓ | C-candidate |
| # of Lines | Read (%) | Write (%) | File Size (MB) | |
|---|---|---|---|---|
| ikki | 6337164 | 23 | 77 | 71.8 |
| webmail | 7795815 | 18 | 82 | 73.7 |
| web-vm | 14294158 | 22 | 78 | 146.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, M.; Kang, D. ML-CLOCK: Efficient Page Cache Algorithm Based on Perceptron-Based Neural Network. Electronics 2021, 10, 2503. https://doi.org/10.3390/electronics10202503
Cho M, Kang D. ML-CLOCK: Efficient Page Cache Algorithm Based on Perceptron-Based Neural Network. Electronics. 2021; 10(20):2503. https://doi.org/10.3390/electronics10202503
Chicago/Turabian StyleCho, Minseon, and Donghyun Kang. 2021. "ML-CLOCK: Efficient Page Cache Algorithm Based on Perceptron-Based Neural Network" Electronics 10, no. 20: 2503. https://doi.org/10.3390/electronics10202503
APA StyleCho, M., & Kang, D. (2021). ML-CLOCK: Efficient Page Cache Algorithm Based on Perceptron-Based Neural Network. Electronics, 10(20), 2503. https://doi.org/10.3390/electronics10202503