
Runtime Analysis of Area-Efficient Uniform RO-PUF for Uniqueness and Reliability Balancing

 , , and
, , and
Abstract
:1. Introduction
2. The Proposed RO-PUF
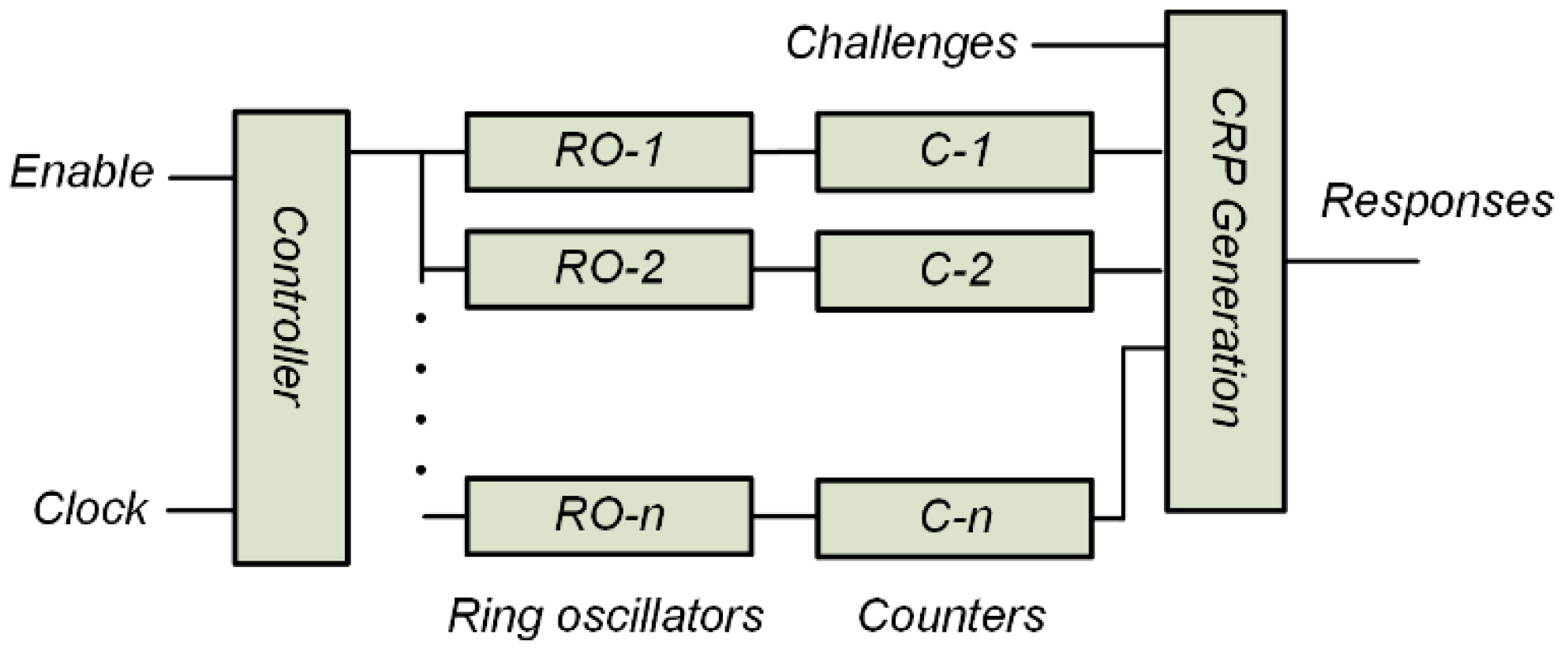
2.1. RO-PUF Circuit
- High RO utilization: a higher response bit can be achieved, as CRP generation is independent.
- Routing equality: the distance between each RO and the respective counter is equal. Hence, there will be no locking phenomena or jitter noise.
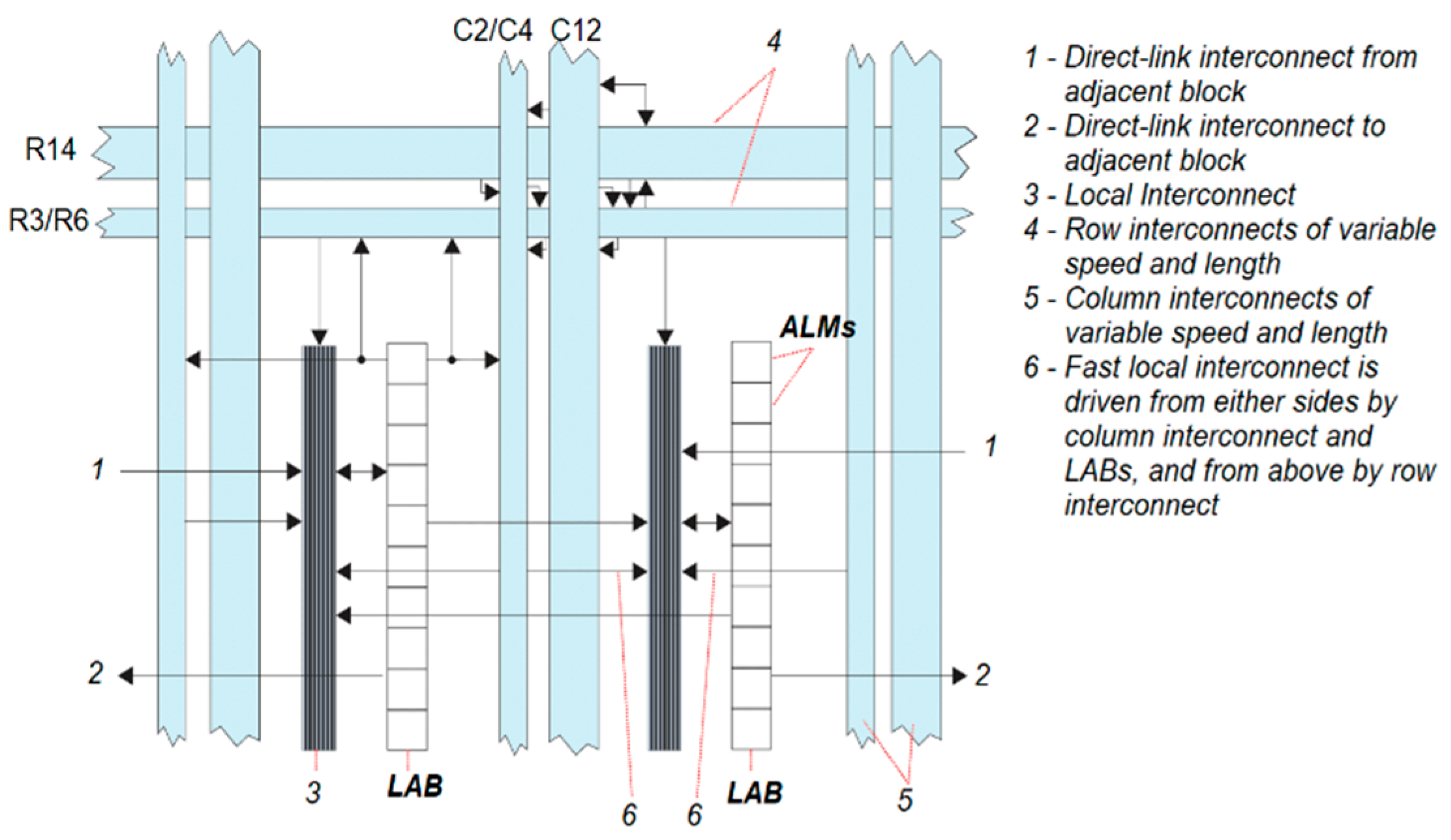
2.2. Ring Oscillator Realization
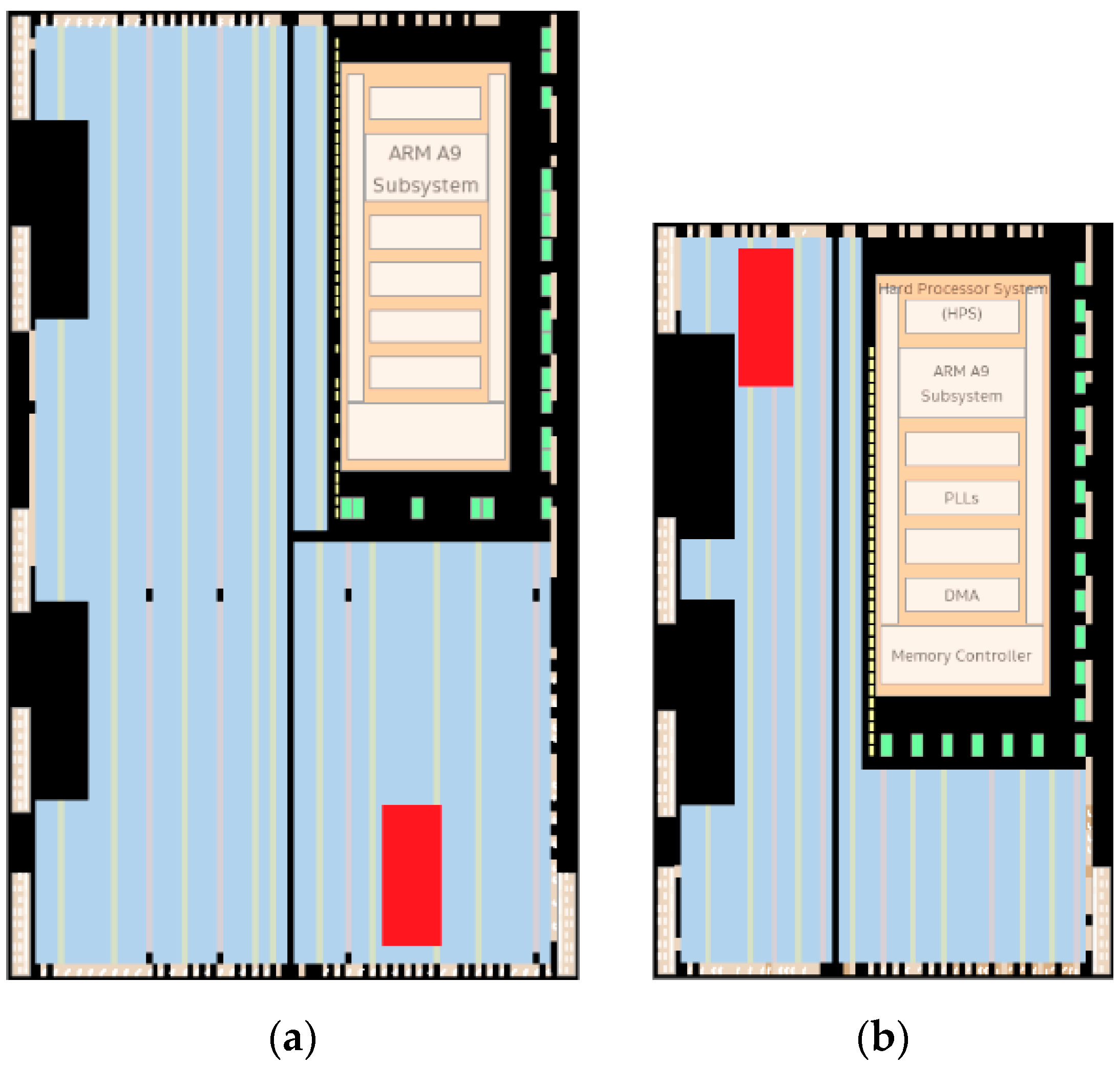
2.3. RO-PUF Placement
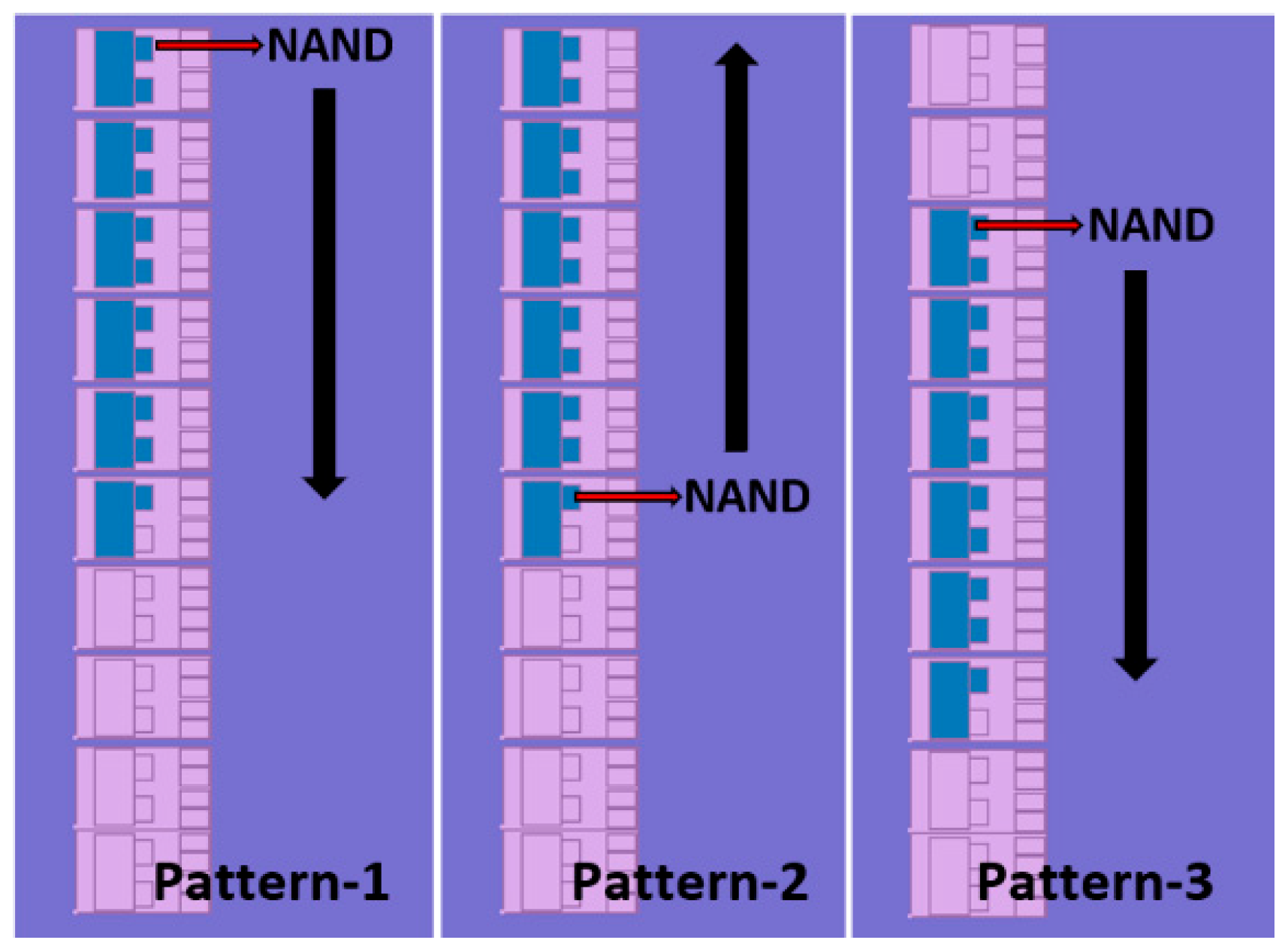
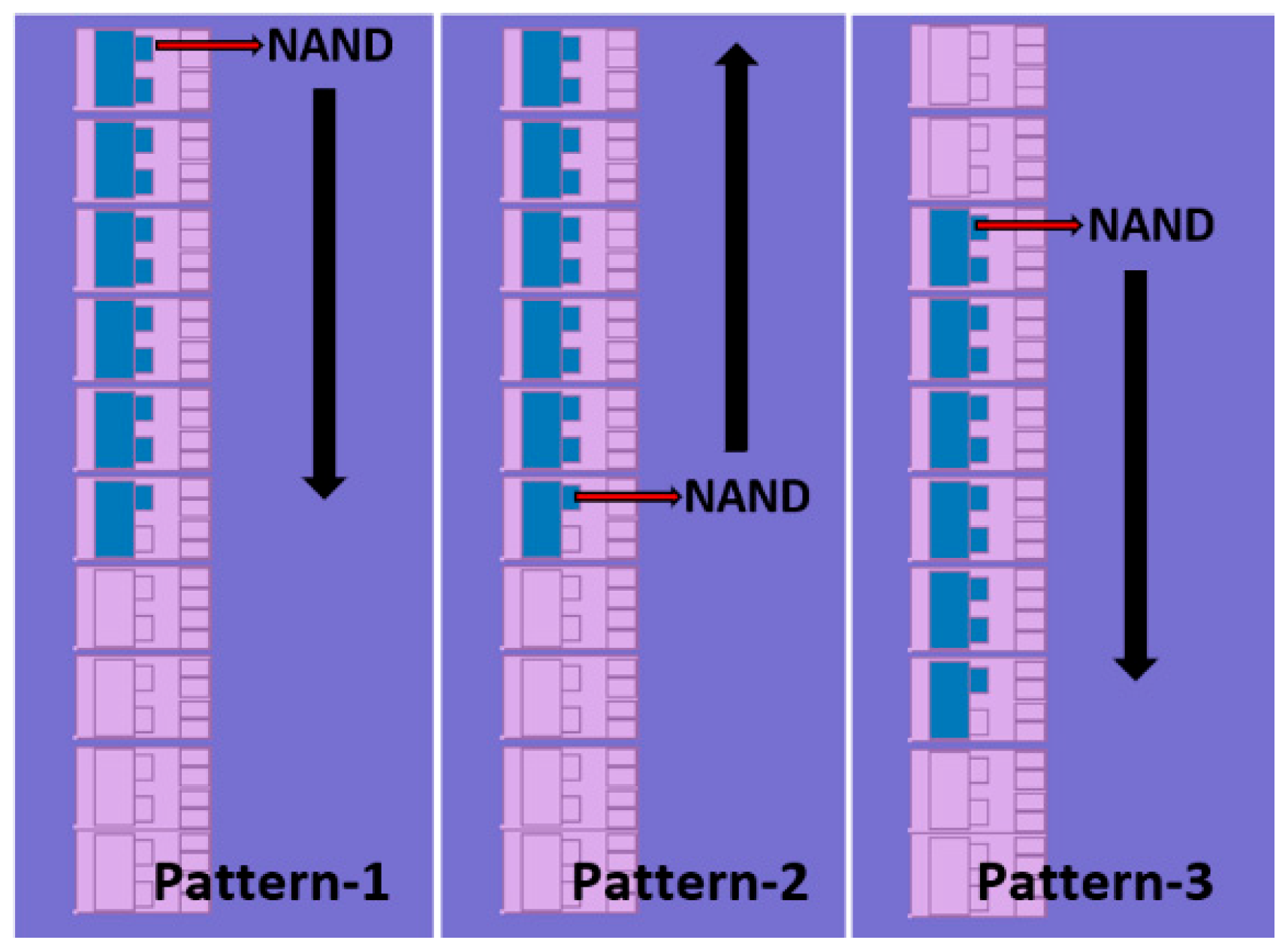
2.4. RO Patterns
2.5. Routing Density
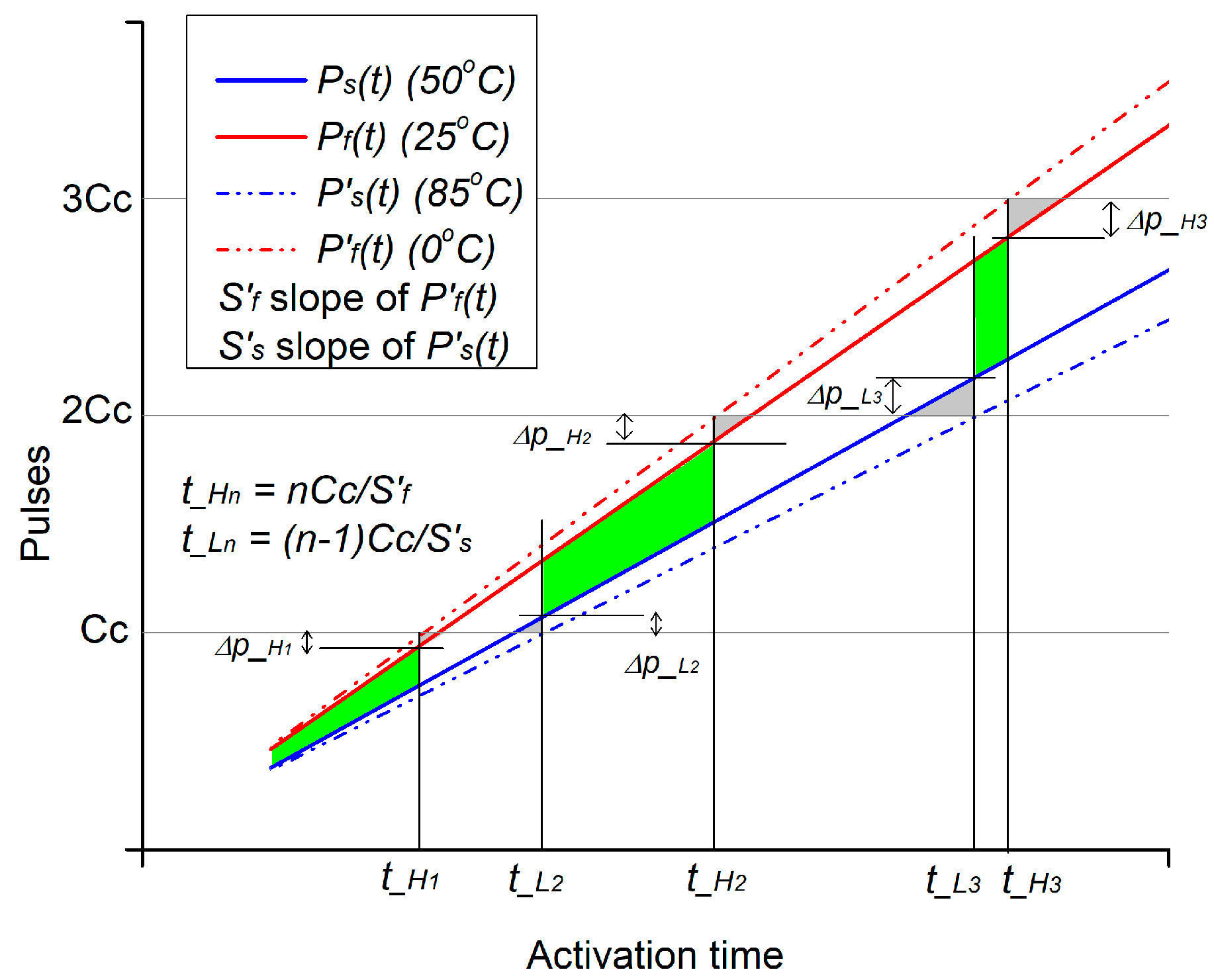
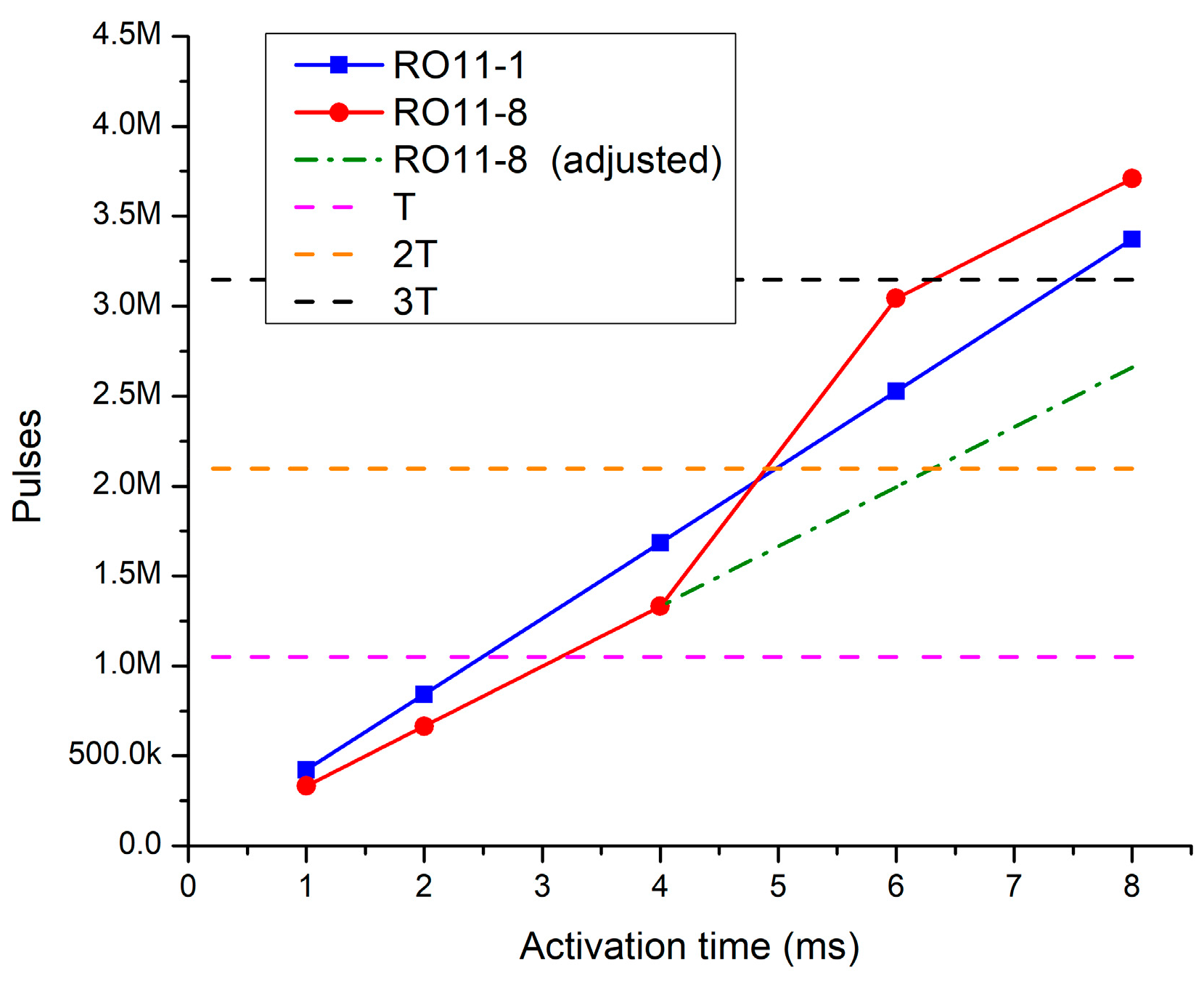
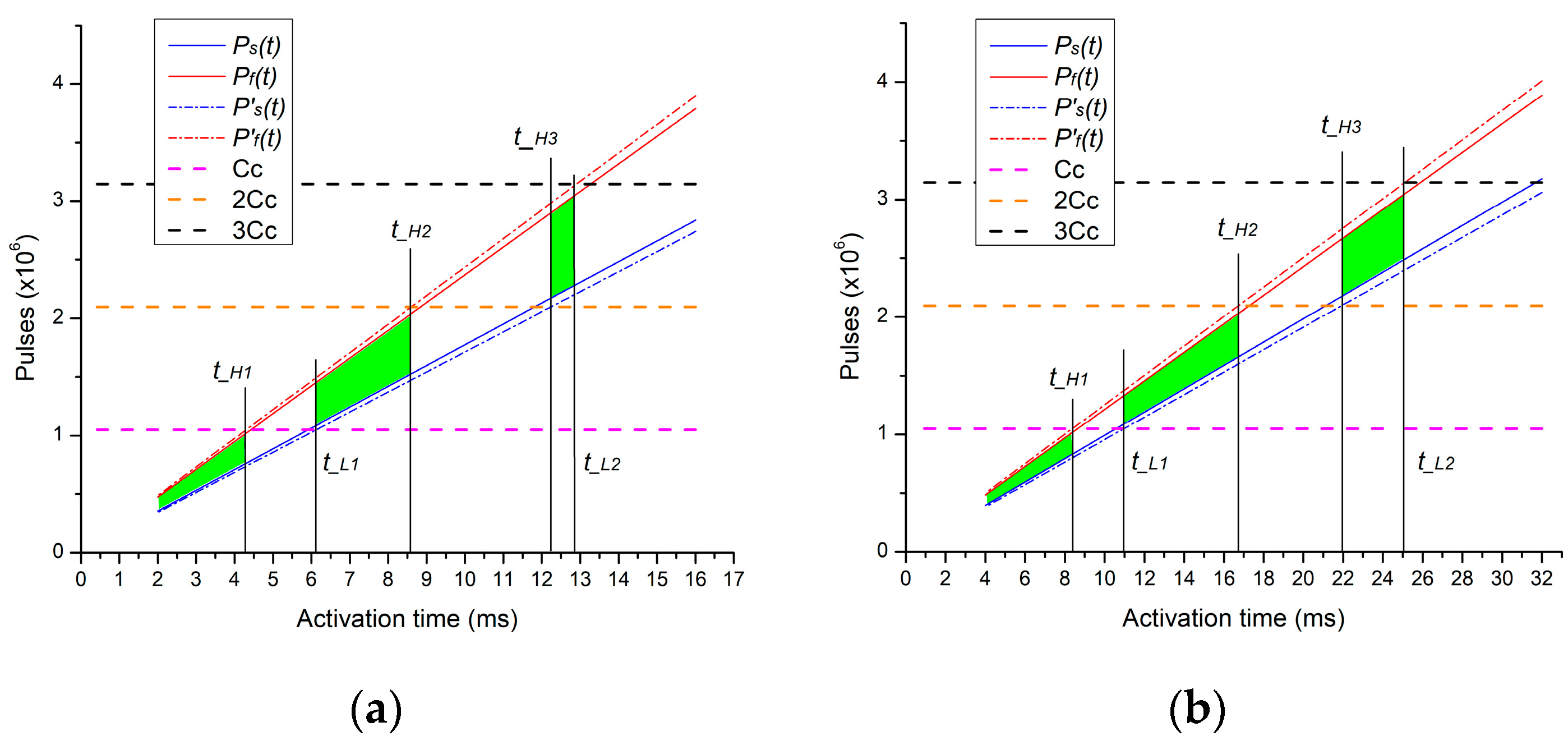
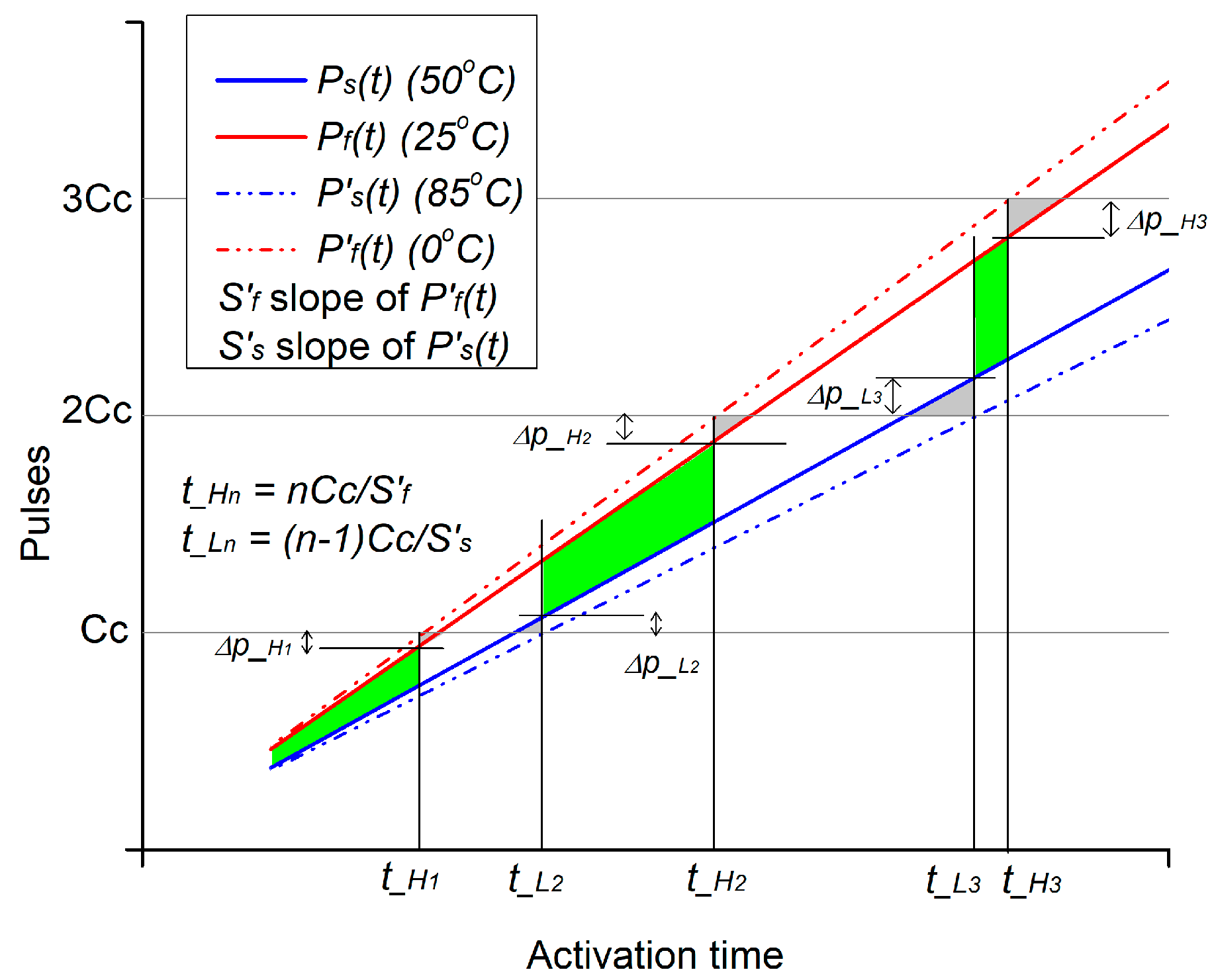
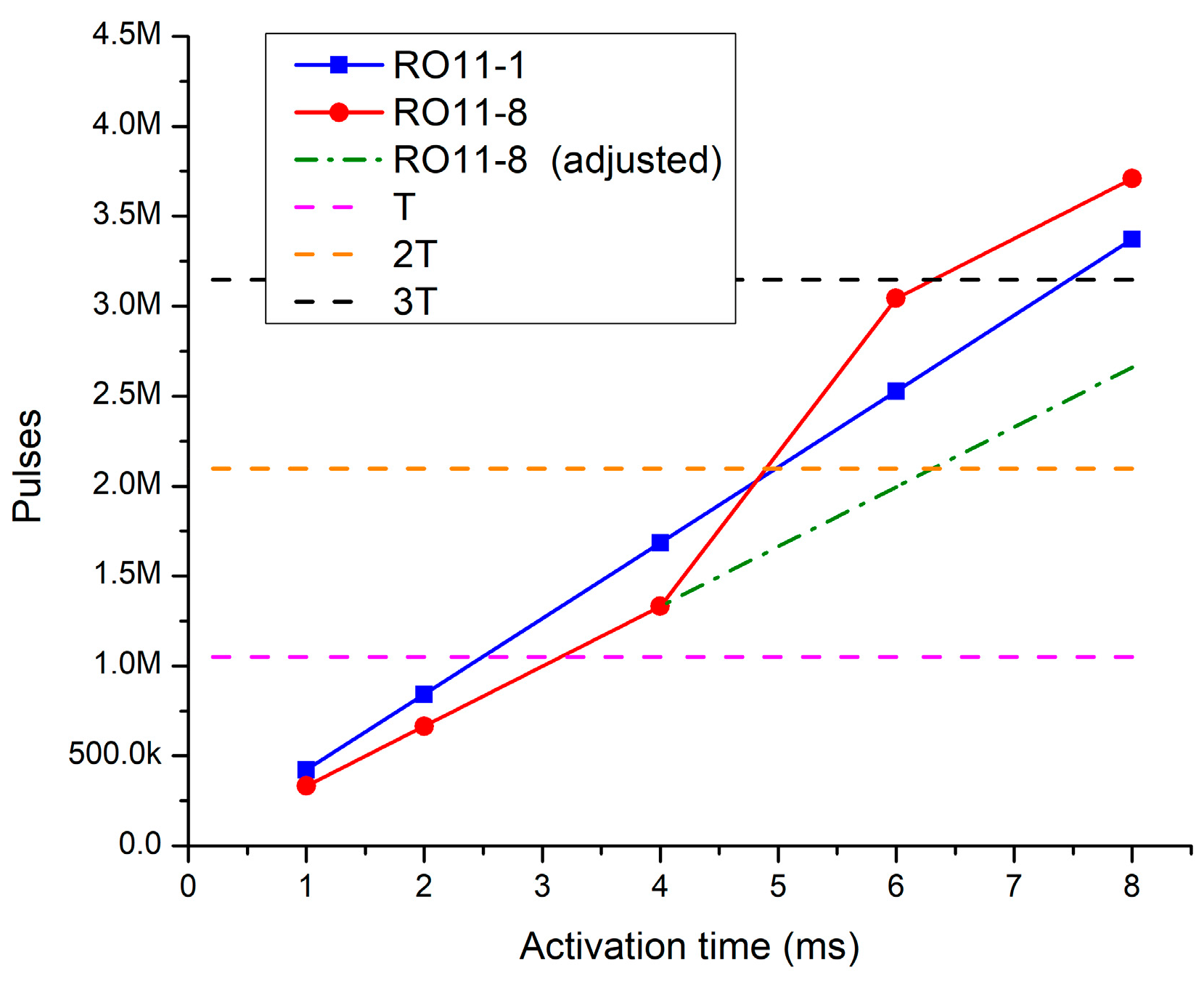
2.6. RO Runtimes
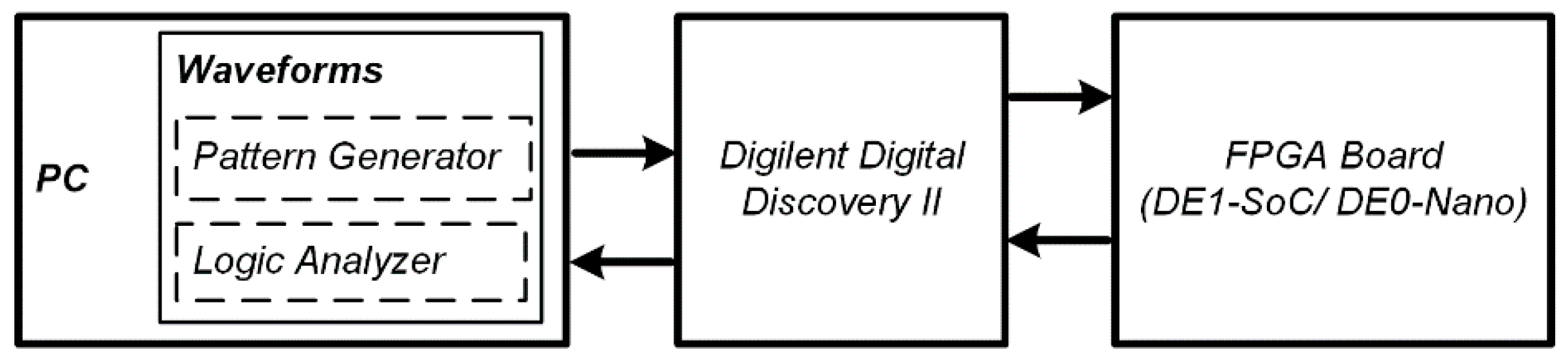
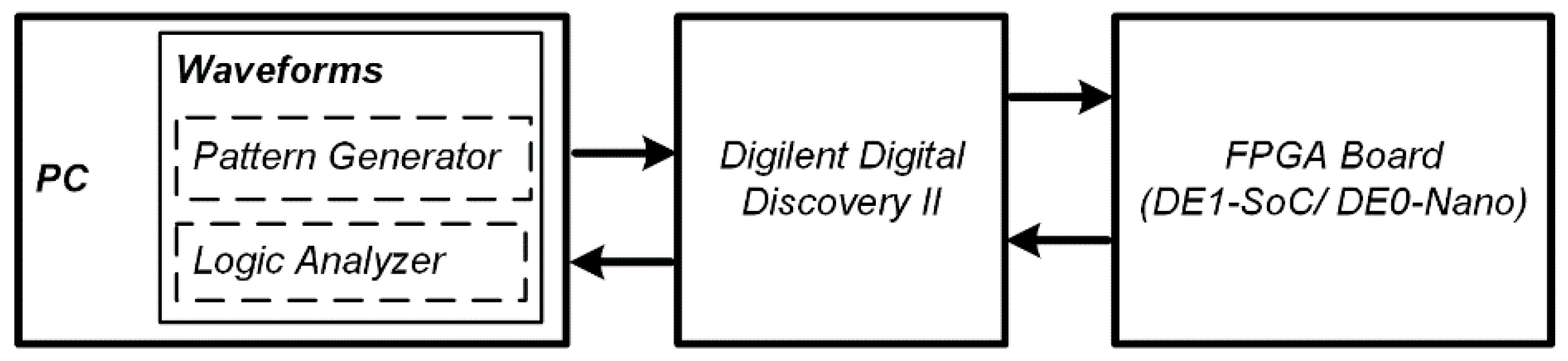
3. Experimental Setup
3.1. Uniformizing Routing Hotspots
- Rearrange the logic fan-out of input pins. Logic gates corresponding to the Clock and Enable inside the controller are rearranged.
- Rearrange the logic fan-in of output pins. Logic gates corresponding to display responses inside CRP Generation are rearranged.
- Distribute logic fan-in of ROs uniformly. All logic gates inside the Controller connected directly to ROs are distributed uniformly in the entire region.
- Distribute logic fan-out of counters uniformly. All logic gates in the CRP Generation region connected directly to counters are rearranged to be uniformly distributed in the entire region.
- Rearrange other logics in the CRP Generation region. Several logics inside this region do not have to be uniformly distributed. However, they are relocated based on the routing hotspots in the respective ROs.
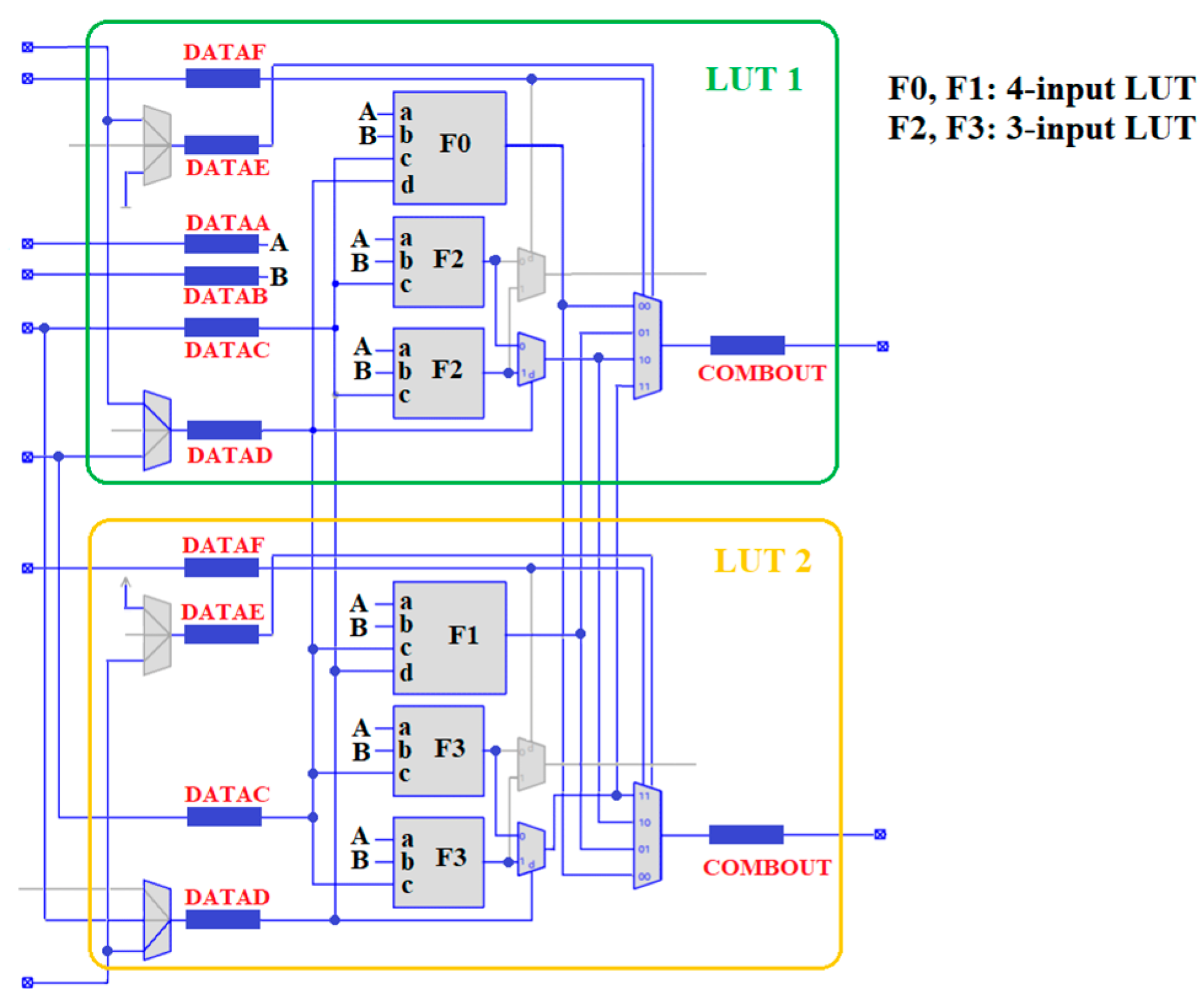
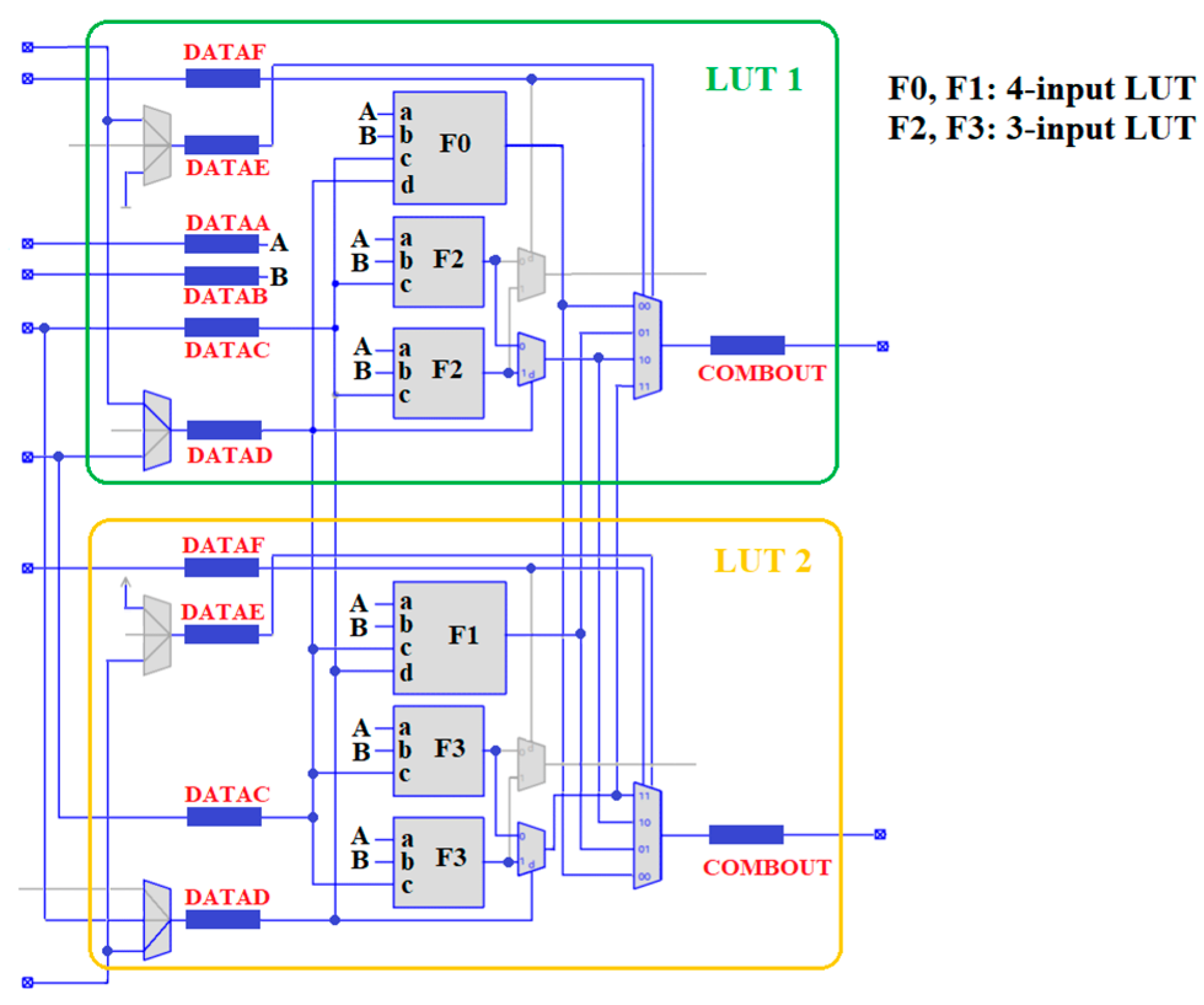
3.2. LUT Configuration
3.3. Data Acquisition
4. Performance Metrics
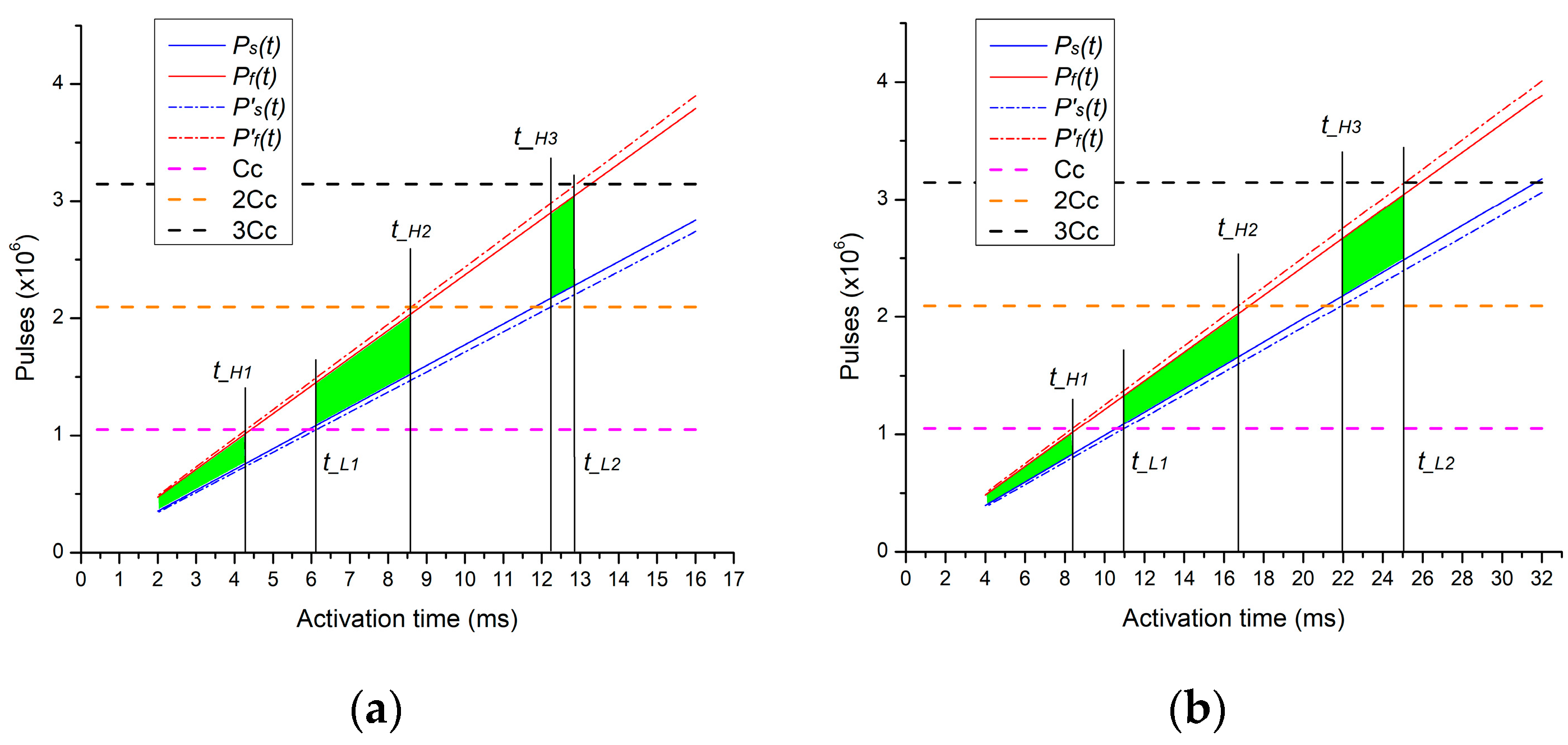
4.1. Estimating the Pulse Count
4.2. Uniqueness and Reliability
4.3. Uniformity and Bit Aliasing
5. Performance Analysis
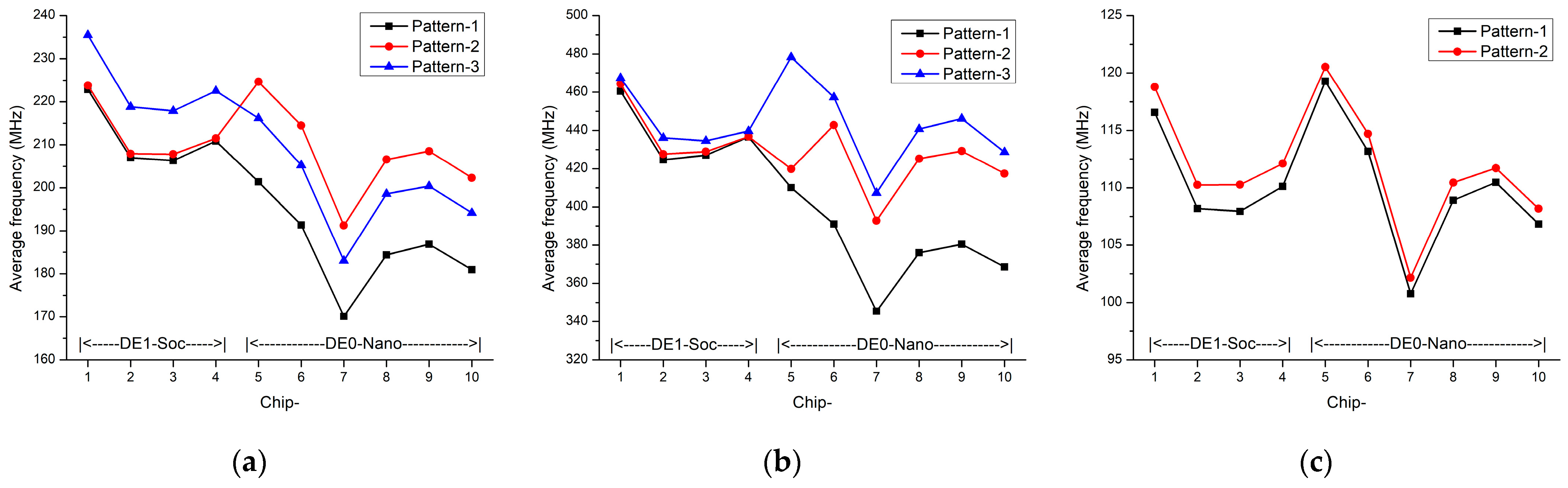
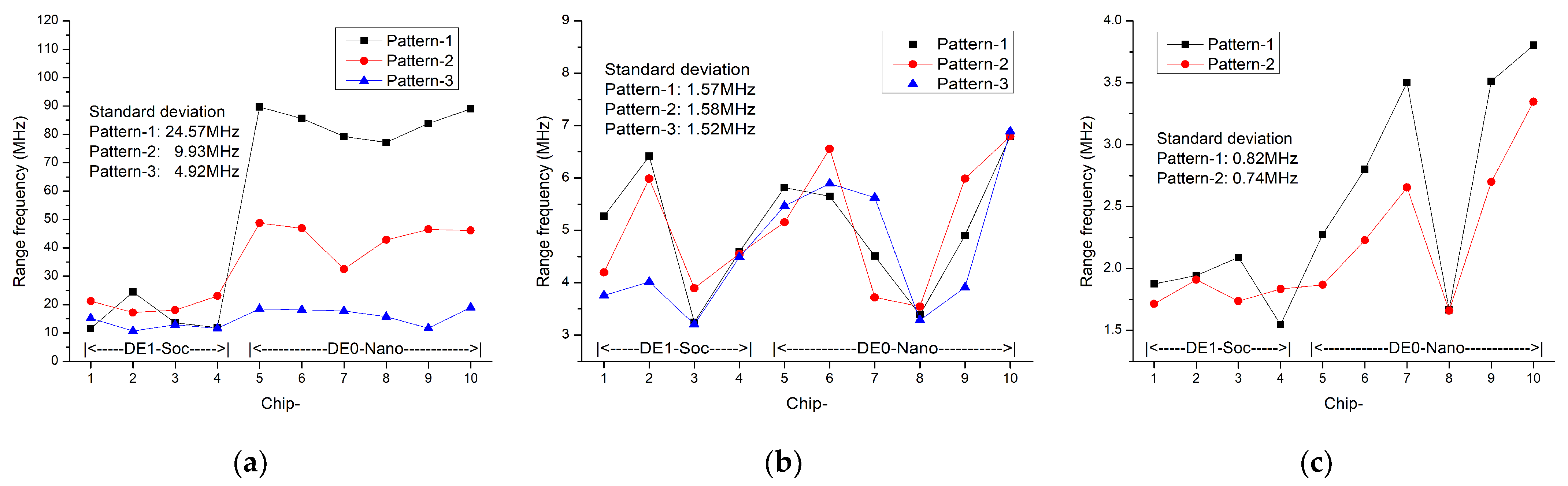
5.1. Statistical Properties
5.2. Runtimes Analysis
5.3. CRP and Metric Comparisons
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gassend, B.; Clarke, D.; Van Dijk, M.; Devadas, S. Silicon physical random functions. In Proceedings of the 9th ACM Conference on Computer and Communications Security, Washington, DC, USA, 18–22 November 2002; pp. 148–160. [Google Scholar]
- Gassend, B.L.P. Physical Random Functions; Massachusetts Institute of Technology: Cambridge, MA, USA, 2003. [Google Scholar]
- Suh, G.E.; Devadas, S. Physical unclonable functions for device authentication and secret key generation. In Proceedings of the 2007 44th ACM/IEEE Design Automation Conference, San Diego, CA, USA, 4–8 June 2007; pp. 9–14. [Google Scholar]
- Yin, C.-E.; Qu, G. Temperature-aware cooperative ring oscillator PUF. In Proceedings of the 2009 IEEE International Workshop on Hardware-Oriented Security and Trust, San Francisco, CA, USA, 27 July 2009; pp. 36–42. [Google Scholar]
- Merli, D.; Stumpf, F.; Eckert, C. Improving the quality of ring oscillator PUFs on FPGAs. In Proceedings of the 5th Workshop on Embedded Systems Security, Scottsdale, AZ, USA, 24 October 2010; pp. 1–9. [Google Scholar]
- Kodýtek, F.; Lórencz, R. A design of ring oscillator based PUF on FPGA. In Proceedings of the 2015 IEEE 18th International Symposium on Design and Diagnostics of Electronic Circuits & Systems, Belgrade, Serbia, 22–24 April 2015; pp. 37–42. [Google Scholar]
- Kodýtek, F.; Lórencz, R.; Buček, J. Improved ring oscillator PUF on FPGA and its properties. Microprocess. Microsyst. 2016, 47, 55–63. [Google Scholar] [CrossRef]
- Rahman, M.T.; Rahman, F.; Forte, D.; Tehranipoor, M. An aging-resistant RO-PUF for reliable key generation. IEEE Trans. Emerg. Top. Comput. 2016, 4, 335–348. [Google Scholar] [CrossRef]
- Gag, M.; Wegner, T.; Waschki, A.; Timmermann, D. Temperature and on-chip crosstalk measurement using ring oscillators in FPGA. In Proceedings of the 2012 IEEE 15th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), Tallinn, Estonia, 18–20 April 2012; pp. 201–204. [Google Scholar]
- Ikeda, M.; Kang, H.; Iwamura, K. Direct challenge ring oscillator PUF (DC-ROPUF) with novel response selection. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–2. [Google Scholar]
- Giechaskiel, I.; Rasmussen, K.B.; Eguro, K. Leaky Wires: Information Leakage and Covert Communication Between FPGA Long Wires. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Korea, 4–8 June 2018; pp. 15–27. [Google Scholar]
- Giechaskiel, I.; Eguro, K.; Rasmussen, K.B. Leakier wires: Exploiting FPGA long wires for covert-and side-channel attacks. ACM Trans. Reconfig. Technol. Syst. (TRETS) 2019, 12, 1–29. [Google Scholar] [CrossRef]
- Maiti, A.; Schaumont, P. Improved ring oscillator PUF: An FPGA-friendly secure primitive. J. Cryptol. 2011, 24, 375–397. [Google Scholar] [CrossRef]
- Feiten, L.; Spilla, A.; Sauer, M.; Schubert, T.; Becker, B. Implementation and analysis of ring oscillator PUFs on 60 nm Altera Cyclone FPGAs. Inf. Secur. J. Glob. Perspect. 2013, 22, 265–273. [Google Scholar] [CrossRef]
- Stanciu, A.; Cirstea, M.N.; Moldoveanu, F.D. Analysis and evaluation of PUF-based SoC designs for security applications. IEEE Trans. Ind. Electron. 2016, 63, 5699–5708. [Google Scholar] [CrossRef] [Green Version]
- Pang, Z.; Zhang, J.; Zhou, Q.; Gong, S.; Qian, X.; Tang, B. Crossover Ring Oscillator PUF. In Proceedings of the 2017 18th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 14–15 March 2017; pp. 237–243. [Google Scholar]
- Sahoo, S.R.; Kumar, K.S.; Mahapatra, K. A novel current controlled configurable RO PUF with improved security metrics. Integr. VLSI J. 2017, 58, 401–410. [Google Scholar] [CrossRef]
- Halak, B. Physically Unclonable Functions: From Basic Design Principles to Advanced Hardware Security Applications; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Roel, M. Physically Unclonable Functions: Constructions, Properties and Applications; Katholieke Universiteit: Leuven, Belgium, 2012. [Google Scholar]
- Bernard, F.; Fischer, V.; Costea, C.; Fouquet, R. Implementation of ring-oscillators-based physical unclonable functions with independent bits in the response. Int. J. Reconfig. Comput. 2012, 2012, 13. [Google Scholar] [CrossRef] [Green Version]
- Bochard, N.; Bernard, F.; Fischer, V.; Valtchanov, B. True-randomness and pseudo-randomness in ring oscillator-based true random number generators. Int. J. Reconfig. Comput. 2010, 2010, 879281. [Google Scholar] [CrossRef] [Green Version]
- Maiti, A.; Kim, I.; Schaumont, P. A robust physical unclonable function with enhanced challenge-response set. IEEE Trans. Inf. Forensics Secur. 2011, 7, 333–345. [Google Scholar] [CrossRef]
- Delavar, M.; Mirzakuchaki, S.; Mohajeri, J. A ring oscillator-based PUF with enhanced challenge-response pairs. Can. J. Electr. Comput. Eng. 2016, 39, 174–180. [Google Scholar] [CrossRef]
- Zulfikar, Z.; Soin, N.; Hatta, S.W.M.; Talip, M.S.A.; bin Jaafar, A. Uniformizing Routing Hotspots of Ring Oscillators on the Cyclone V FPGA for PUF Applications. In Proceedings of the 2019 IEEE Regional Symposium on Micro and Nanoelectronics (RSM), Pahang, Malaysia, 21–23 August 2019; pp. 176–179. [Google Scholar]
- Mustapa, M. PUF Based FPGAs for Hardware Security and Trust; University of Toledo: Toledo, OH, USA, 2015. [Google Scholar]
- Zulfikar, Z.; Soin, N.; Hatta, S.W.M. Capacitance Effects of Ring Oscillator’s Waveform Quality in Designing Physically Unclonable Functions. In Proceedings of the 2018 IEEE International Conference on Semiconductor Electronics (ICSE), Kuala Lumpur, Malaysia, 15–17 August 2018; pp. 113–116. [Google Scholar]
- Feiten, L.; Oesterle, J.; Martin, T.; Sauer, M.; Becker, B. Systemic frequency biases in ring oscillator pufs on fpgas. IEEE Trans. Multi-Scale Comput. Syst. 2016, 2, 174–185. [Google Scholar] [CrossRef]
- Marchand, C.; Bossuet, L.; Mureddu, U.; Bochard, N.; Cherkaoui, A.; Fischer, V. Implementation and characterization of a physical unclonable function for IoT: A case study with the TERO-PUF. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Feiten, L.; Sauer, M.; Becker, B. Implementation of Delay-Based PUFs on Altera FPGAs. In Hardware Security and Trust; Springer: Berlin/Heidelberg, Germany, 2017; pp. 211–235. [Google Scholar]
- Zulfikar, Z.; Soin, N.; Hatta, S.W.M.; Talip, M.S.A. FPGA ring oscillator comparisons between conventional and uniform routing hotspots. In Proceedings of the 2020 IEEE International Conference on Semiconductor Electronics (ICSE), Kuala Lumpur, Malaysia, 28–29 July 2020; pp. 176–179. [Google Scholar]
- Maiti, A.; Schaumont, P. Improving the quality of a physical unclonable function using configurable ring oscillators. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 703–707. [Google Scholar]
- Cyclone, V. Device Handbook Volume 1: Device Interfaces and Integration; Altera Corporation: San Jose, CA, USA, 2015. [Google Scholar]
- Report Routing Utilization Dialog Box. Available online: https://www.intel.com/content/www/us/en/programmable/quartushelp/17.1/index.htm#optimize/ace/acv_db_routing_congestion.htm (accessed on 10 June 2020).
- Maiti, A.; Gunreddy, V.; Schaumont, P. A systematic method to evaluate and compare the performance of physical unclonable functions. In Embedded Systems Design with FPGAs; Springer: Berlin/Heidelberg, Germany, 2013; pp. 245–267. [Google Scholar]
- Yu, H.; Leong, P.H.W.; Hinkelmann, H.; Moller, L.; Glesner, M.; Zipf, P. Towards a unique FPGA-based identification circuit using process variations. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 397–402. [Google Scholar]
- Hiller, M.; Kürzinger, L.; Sigl, G. Review of error correction for PUFs and evaluation on state-of-the-art FPGAs. J. Cryptogr. Eng. 2020, 10, 229–247. [Google Scholar] [CrossRef]
- Yu, M.-D.; Devadas, S. Secure and robust error correction for physical unclonable functions. IEEE Des. Test Comput. 2010, 27, 48–65. [Google Scholar] [CrossRef]
- Merli, D.; Schuster, D.; Stumpf, F.; Sigl, G. Semi-invasive EM attack on FPGA RO PUFs and countermeasures. In Proceedings of the Workshop on Embedded Systems Security, Taipei, Taiwan, 9–14 October 2011; pp. 1–9. [Google Scholar]
- Yin, C.-E.; Qu, G. Obtaining statistically random information from silicon physical unclonable functions. IEEE Trans. Emerg. Top. Comput. 2014, 2, 96–106. [Google Scholar] [CrossRef]
- Chauhan, A.S.; Sahula, V.; Mandal, A.S. Novel randomized placement for FPGA based robust ROPUF with improved uniqueness. J. Electron. Test. 2019, 35, 581–601. [Google Scholar] [CrossRef]
- Deng, D.; Hou, S.; Wang, Z.; Guo, Y. Configurable ring oscillator PUF using hybrid logic gates. IEEE Access 2020, 8, 161427–161437. [Google Scholar] [CrossRef]
- Hsieh, M.-H.; Huang, Y.-C.; Yew, T.-Y.; Wang, W.; Lee, Y.-H. The impact and implication of BTI/HCI decoupling on ring oscillator. In Proceedings of the 2015 IEEE International Reliability Physics Symposium, Monterey, CA, USA, 19–23 April 2015; pp. 6A.4.1–6A.4.5. [Google Scholar]
- Karimi, N.; Danger, J.-L.; Guilley, S. Impact of aging on the reliability of delay PUFs. J. Electron. Test. 2018, 34, 571–586. [Google Scholar] [CrossRef]
- Maiti, A.; Schaumont, P. The impact of aging on a physical unclonable function. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 22, 1854–1864. [Google Scholar] [CrossRef]
- Sahoo, D.P.; Mukhopadhyay, D.; Chakraborty, R.S. Design of low area-overhead ring oscillator PUF with large challenge space. In Proceedings of the 2013 International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 9–11 December 2013; pp. 1–6. [Google Scholar]
- Xin, X.; Kaps, J.-P.; Gaj, K. A configurable ring-oscillator-based PUF for Xilinx FPGAs. In Proceedings of the 2011 14th Euromicro conference on digital system design, Oulu, Finland, 31 August–2 September 2011; pp. 651–657. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FPGA Technology | Intel Cyclone V (28 nm) |
|---|---|
| Board Chip no. | Four DE1-SoC (5CSEMA5F31C6), six DE0-Nano (5CSEMA4U23C6) |
| RO stage | 5, 11, 20 (e.g., RO11-6 denote RO no. 6 of an 11-stage RO) |
| RO runtimes | 1–8 ms (RO5), 2–16 ms (RO11), 4–32 ms (RO20) |
| RO5 | RO11 | RO20 | ||||||
|---|---|---|---|---|---|---|---|---|
| Pattern-1 | Pattern-2 | Pattern-3 | Pattern-1 | Pattern-2 | Pattern-3 | Pattern-1 | Pattern-2 | |
| DE1-SoC | ||||||||
| Routing hotspots (%) | 21–42 | 35–57 | 28–50 | 35–50 | 42–64 | 35–57 | 42–64 | 35–57 |
| Average (%) | 30.6 | 45.4 | 36.5 | 46.2 | 51 | 43.7 | 52.6 | 44.6 |
| DE0-Nano | ||||||||
| Routing hotspots (%) | 7–22 | 8–28 | 11–21 | 21–35 | 21–35 | 25–37 | 19–42 | 19–42 |
| Average (%) | 16.4 | 18.7 | 15.1 | 27.3 | 25.1 | 29.3 | 26.6 | 28.7 |
| Pattern/Stage | Inputs Configuration | ||
|---|---|---|---|
| DE1-SoC | DE0-Nano | ||
| Pattern-1 | RO5 | DF-DDFF | FB-DCFF |
| RO11 | DF-DDFFFFFFFF | FB-DCFFFFFFFE | |
| RO20 | FD-DDFFFFFFFFFFDFFDFFD | FD-DCFFFFFFFFFFDFFDFFD | |
| Pattern-2 | RO5 | FE-FFFD | FE-FFFC |
| RO11 | FE-FFFFFFFFFD | FE-EFFFFFFFFC | |
| RO20 | FD-FDFFDFFDFFFFFFFFFFD | FD-FDFFDFFDFFFFFFFFFFC | |
| Pattern-3 | RO5 | FC-FFFF | FC-FFFF |
| RO11 | DF-FFFFFFFFDF | FB-FFFFFFFFDF | |
| Uniqueness (%) | Reliability (%) | Uniformity (%) | Bit aliasing (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RO5 | RO11 | RO20 | RO5 | RO11 | RO20 | RO5 | RO11 | RO20 | RO5 | RO11 | RO20 | |
| Pattern-1 | 40.52 | 46.51 | 47.31 | 99.20 | 97.96 | 98.80 | 60.04 | 63.78 | 61.24 | 59.78 | 63.69 | 61.16 |
| Pattern-2 | 44.46 | 47.33 | 47.48 | 97.96 | 98.09 | 99.16 | 59.69 | 60.62 | 62.89 | 59.65 | 60.71 | 62.98 |
| Pattern-3 | 50.98 | 47.69 | - | 98.18 | 98.27 | - | 56.49 | 58.40 | - | 59.44 | 58.80 | - |
| Author | No. of CRPs | CRP Enhance/Location |
|---|---|---|
| Suh et al. [3] | n/8 | no/inside chip |
| Maiti et.al. [31] | n − 1 | no/inside chip |
| Merli et.al. [38] | n/2 | no/inside chip |
| Yin et.al. [39] | log2 n! | no/inside chip |
| Our set-up | n! /2(n − 2)! | yes/inside or outside |
| Maiti et.al. [22] | 2n − n − 1 | yes/outside chip |
| Delavar et.al. [23] | 2n − 1 | yes/outside chip |
| Uniqueness (%) | Reliability (%) | Uniformity (%) | Bit-Aliasing (%) | Platform | |
|---|---|---|---|---|---|
| Suh et al. [3], 2007 | 46.15 | 99.52 | - | - | Xilinx (90 nm) |
| Maiti et al. [31], 2009 | 35.91–45.90 | - | - | - | Xilinx (90 nm) |
| Merli et al. [5], 2010 | 43.40–48.51 | 99.20, 98.28 | - | - | Xilinx (90 nm) |
| Xin et al. [46], 2011 | 32, 41 | 99.29 | - | - | Xilinx (90 nm) |
| Maiti et al. [22], 2012 | 49.99–50.07 | ±92 *, ±70 * (45 °C) | 50.02, 49.4 | 50.02, 49.4 | Xilinx (90 nm) |
| Feiten et al. [14], 2013 | 6.68 *–37.03 * | 99.41 *–82.5 * | 50.00 *, 62.07 * | - | Altera (65 nm) |
| Sahoo et al. [45], 2013 | 47.57 | 90.70 *** | 47 | 14.95 | Altera (65 nm) |
| Kodytek et al. [7], 2016 | 48.42–48.74 | 98.22, 97.55 | - | - | Xilinx (90 nm) |
| Delavar et al. [23], 2016 | 49.81 | 96.07 | - | - | Xilinx (90 nm) |
| Chauhan et al. [40], 2019 | 49.9 | 97.85–99.80 | - | - | Xilinx (28 nm) |
| Deng et al. [41], 2020 | 49.95 | 91.4–99.13 * | 49.61 | - | Xilinx (28 nm) |
| This work ** | 47.48 | 99.16 | 62.89 | 62.98 | Altera (28 nm) |
| Ideal value | 50% | 100% | 50% | 50% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zulfikar, Z.; Soin, N.; Wan Muhamad Hatta, S.F.; Abu Talip, M.S. Runtime Analysis of Area-Efficient Uniform RO-PUF for Uniqueness and Reliability Balancing. Electronics 2021, 10, 2504. https://doi.org/10.3390/electronics10202504
Zulfikar Z, Soin N, Wan Muhamad Hatta SF, Abu Talip MS. Runtime Analysis of Area-Efficient Uniform RO-PUF for Uniqueness and Reliability Balancing. Electronics. 2021; 10(20):2504. https://doi.org/10.3390/electronics10202504
Chicago/Turabian StyleZulfikar, Zulfikar, Norhayati Soin, Sharifah Fatmadiana Wan Muhamad Hatta, and Mohamad Sofian Abu Talip. 2021. "Runtime Analysis of Area-Efficient Uniform RO-PUF for Uniqueness and Reliability Balancing" Electronics 10, no. 20: 2504. https://doi.org/10.3390/electronics10202504
APA StyleZulfikar, Z., Soin, N., Wan Muhamad Hatta, S. F., & Abu Talip, M. S. (2021). Runtime Analysis of Area-Efficient Uniform RO-PUF for Uniqueness and Reliability Balancing. Electronics, 10(20), 2504. https://doi.org/10.3390/electronics10202504