Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction

 ,
,  , , , and
, , , and
Abstract
1. Introduction
- Development of novel rank-aggregation based multi-filter feature selection methods.
- Empirical evaluation and analysis of the performance of rank-aggregation based multi-filter feature selection methods in SDP.
2. Related Works
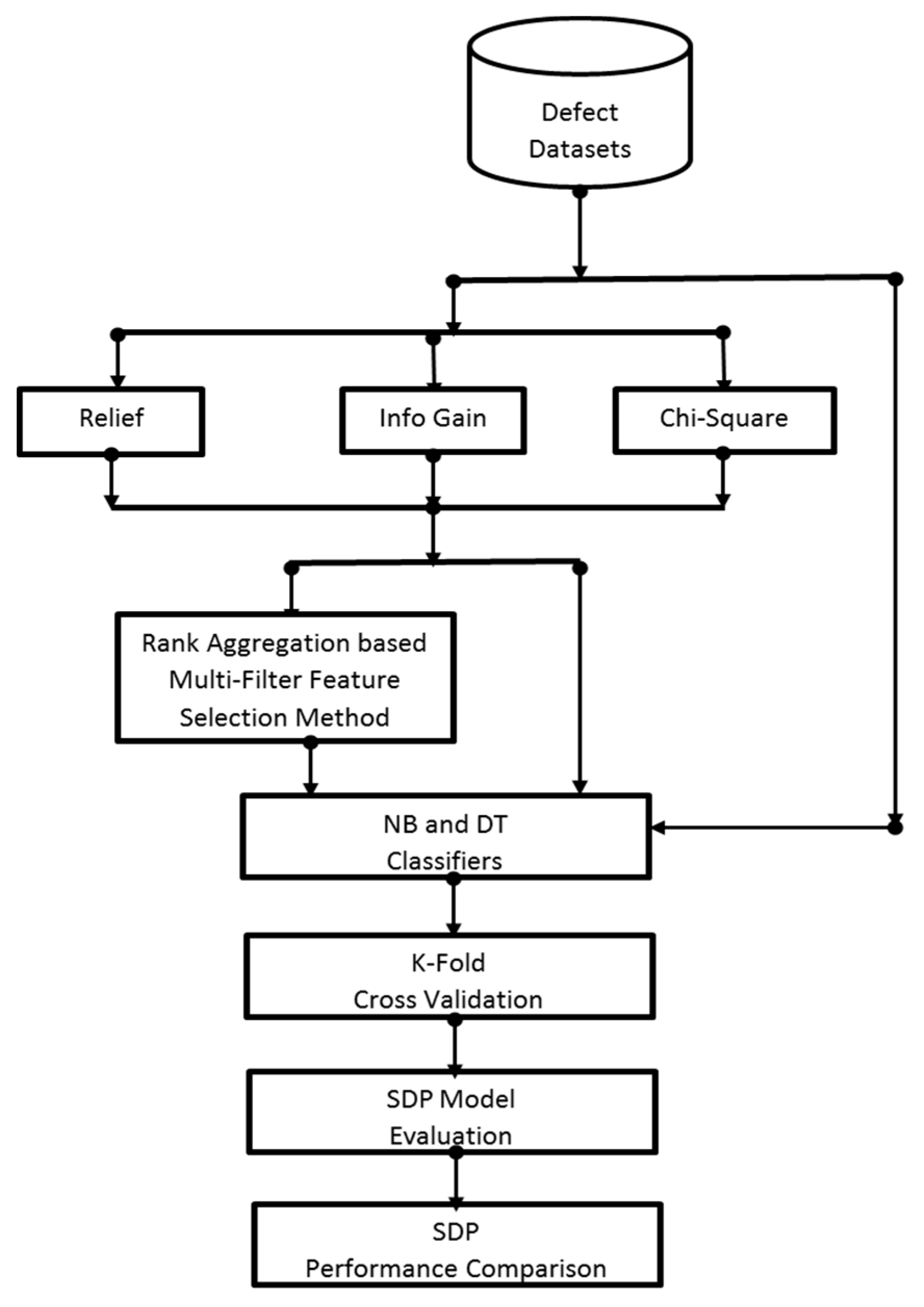
3. Methodology
3.1. Classification Algorithms
3.2. Filter Feature Selection
3.2.1. Chi-Square (CS)
3.2.2. ReliefF (REF)
3.2.3. Information Gain (IG)
3.3. Rank Aggregation-Based Multi-Filter Feature Selection (RMFFS) Method
| Algorithm 1 Rank Aggregation based Multi-Filter Feature Selection (RMFFS) Method |
| Input: N—Number of Filter Rank Method = {CS, REF, IG} T—Threshold value for optimal features selections = = A—Aggregators A = {min{}, max{}, range{mean{}, g.mean{}, h.mean{} P—Aggregated Features Output: —Optimal Features Selected From Aggregated Rank List based on T 1. for to N {do 2. Generate Rank list Rn for each filter rank method i 3. } 4. Generate Aggregated Rank list using Aggregator functions: for i = 1 to 5. 6. for i = 1 to { 7. if ( T) 8. //Select optimal features from based on T 9. } 10. = 11. return 12. } |
3.4. Software Defect Datasets
3.5. Performance Evaluation Metrics
- Accuracy is the number or percentage of correctly predicted data out of all total amount of data.
- F-Measure is defined as the weighted harmonic mean of the test’s precision and recall
- The Area under Curve (AUC) indicates the trade-off between TP and FP. It shows an aggregate measure of performance across all possible classification thresholds.
3.6. Experimental Framework
- Scenario 1 considered the application of the baseline classification algorithm (NB and DT) on the original defect datasets. In this case, NB and DT will be trained and tested with the original defect datasets. This is to determine the prediction performances of the baseline classifiers on the defect datasets.
- Scenario 2 is based on the application of each filter rank method (CS, REF, and IG) on the baseline classifiers. This is to determine and measure the individual effect of each filter rank methods on prediction performances of NB and DT over the selected defect datasets.
- Scenario 3 indicates the application of the proposed RMFFS method on the baseline classifiers. Just as in Scenario 2, this is to determine and measure the effectiveness of the proposed RMFFS method on prediction performances of NB and DT over the selected defect datasets.
- RQ1. How effective are the proposed RMFFS methods compared to individual filter FS methods?
- RQ2. Which of RMFFS methods had the highest positive impact on the prediction performance of SDP models?
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Afzal, W.; Torkar, R. Towards benchmarking feature subset selection methods for software fault prediction. In Computational Intelligence and Quantitative Software Engineering; Springer: Berlin/Heidelberg, Germany, 2016; pp. 33–58. [Google Scholar]
- Akintola, A.G.; Balogun, A.O.; Lafenwa-Balogun, F.; Mojeed, H.A. Comparative analysis of selected heterogeneous classifiers for software defects prediction using filter-based feature selection methods. FUOYE J. Eng. Technol. 2018, 3, 134–137. [Google Scholar] [CrossRef]
- Basri, S.; Almomani, M.A.; Imam, A.A.; Thangiah, M.; Gilal, A.R.; Balogun, A.O. The Organisational Factors of Software Process Improvement in Small Software Industry: Comparative Study. In Proceedings of the International Conference of Reliable Information and Communication Technology, Johor, Malaysia, 22–23 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1132–1143. [Google Scholar]
- Bajeh, A.O.; Oluwatosin, O.-J.; Basri, S.; Akintola, A.G.; Balogun, A.O. Object-Oriented Measures as Testability Indicators: An Empirical Study. J. Eng. Sci. Technol. 2020, 15, 1092–1108. [Google Scholar]
- Balogun, A.; Bajeh, A.; Mojeed, H.; Akintola, A. Software defect prediction: A multi-criteria decision-making approach. Niger. J. Technol. Res. 2020, 15, 35–42. [Google Scholar] [CrossRef]
- Chauhan, A.; Kumar, R. Bug Severity Classification Using Semantic Feature with Convolution Neural Network. In Computing in Engineering and Technology; Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–335. [Google Scholar]
- Jimoh, R.; Balogun, A.; Bajeh, A.; Ajayi, S. A PROMETHEE based evaluation of software defect predictors. J. Comput. Sci. Its Appl. 2018, 25, 106–119. [Google Scholar]
- Catal, C.; Diri, B. Investigating the effect of dataset size, metrics sets, and feature selection techniques on software fault prediction problem. Inf. Sci. 2009, 179, 1040–1058. [Google Scholar] [CrossRef]
- Li, L.; Leung, H. Mining static code metrics for a robust prediction of software defect-proneness. In Proceedings of the 2011 International Symposium on Empirical Software Engineering and Measurement, Washington, DC, USA, 22–23 September 2011; pp. 207–214. [Google Scholar]
- Mabayoje, M.A.; Balogun, A.O.; Bajeh, A.O.; Musa, B.A. Software Defect Prediction: Effect of feature selection and ensemble methods. FUW Trends Sci. Technol. J. 2018, 3, 518–522. [Google Scholar]
- Lessmann, S.; Baesens, B.; Mues, C.; Pietsch, S. Benchmarking classification models for software defect prediction: A proposed framework and novel findings. IEEE Trans. Softw. Eng. 2008, 34, 485–496. [Google Scholar] [CrossRef]
- Li, N.; Shepperd, M.; Guo, Y. A systematic review of unsupervised learning techniques for software defect prediction. Inf. Softw. Technol. 2020, 122, 106287. [Google Scholar] [CrossRef]
- Okutan, A.; Yıldız, O.T. Software defect prediction using Bayesian networks. Empir. Softw. Eng. 2014, 19, 154–181. [Google Scholar] [CrossRef]
- Rodriguez, D.; Herraiz, I.; Harrison, R.; Dolado, J.; Riquelme, J.C. Preliminary comparison of techniques for dealing with imbalance in software defect prediction. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; pp. 1–10. [Google Scholar]
- Usman-Hamza, F.; Atte, A.; Balogun, A.; Mojeed, H.; Bajeh, A.; Adeyemo, V. Impact of feature selection on classification via clustering techniques in software defect prediction. J. Comput. Sci. Its Appl. 2019, 26. [Google Scholar] [CrossRef]
- Balogun, A.; Oladele, R.; Mojeed, H.; Amin-Balogun, B.; Adeyemo, V.E.; Aro, T.O. Performance analysis of selected clustering techniques for software defects prediction. Afr. J. Comp. ICT 2019, 12, 30–42. [Google Scholar]
- Rodriguez, D.; Ruiz, R.; Cuadrado-Gallego, J.; Aguilar-Ruiz, J.; Garre, M. Attribute selection in software engineering datasets for detecting fault modules. In Proceedings of the 33rd EUROMICRO Conference on Software Engineering and Advanced Applications (EUROMICRO 2007), Lubeck, Germany, 28–31 August 2007; pp. 418–423. [Google Scholar]
- Wang, H.; Khoshgoftaar, T.M.; van Hulse, J.; Gao, K. Metric selection for software defect prediction. Int. J. Softw. Eng. Knowl. Eng. 2011, 21, 237–257. [Google Scholar] [CrossRef]
- Rathore, S.S.; Gupta, A. A comparative study of feature-ranking and feature-subset selection techniques for improved fault prediction. In Proceedings of the 7th India Software Engineering Conference, Chennai, India, 19–21 February 2014; pp. 1–10. [Google Scholar]
- Xu, Z.; Liu, J.; Yang, Z.; An, G.; Jia, X. The impact of feature selection on defect prediction performance: An empirical comparison. In Proceedings of the 2016 IEEE 27th International Symposium on Software Reliability Engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; pp. 309–320. [Google Scholar]
- Balogun, A.O.; Shuib, B.; Abdulkadir, S.J.; Sobri, A. A Hybrid Multi-Filter Wrapper Feature Selection Method for Software Defect Predictors. Int. J Sup. Chain. Manag. 2019, 8, 916. [Google Scholar]
- Balogun, A.O.; Basri, S.; Abdulkadir, S.J.; Hashim, A.S. Performance Analysis of Feature Selection Methods in Software Defect Prediction: A Search Method Approach. Appl. Sci. 2019, 9, 2764. [Google Scholar] [CrossRef]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Almomani, M.A.; Adeyemo, V.E.; Al-Tashi, Q.; Mojeed, H.A.; Imam, A.A.; Bajeh, A.O.; et al. Impact of Feature Selection Methods on the Predictive Performance of Software Defect Prediction Models: An Extensive Empirical Study. Symmetry 2020, 12, 1147. [Google Scholar] [CrossRef]
- Ghotra, B.; McIntosh, S.; Hassan, A.E. A large-scale study of the impact of feature selection techniques on defect classification models. In Proceedings of the 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), Piscataway, NJ, USA, 20–21 May 2017; pp. 146–157. [Google Scholar]
- Anbu, M.; Mala, G.A. Feature selection using firefly algorithm in software defect prediction. Clust. Comput. 2019, 22, 10925–10934. [Google Scholar] [CrossRef]
- Kakkar, M.; Jain, S. Feature selection in software defect prediction: A comparative study. In Proceedings of the 6th International Conference on Cloud System and Big Data Engineering, Noida, India, 14–15 January 2016; pp. 658–663. [Google Scholar]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Li, Y.; Li, T.; Liu, H. Recent advances in feature selection and its applications. Knowl. Inf. Syst. 2017, 53, 551–577. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Iqbal, A.; Aftab, S. A Classification Framework for Software Defect Prediction Using Multi-filter Feature Selection Technique and MLP. Int. J. Mod. Educ. Comput. Sci. 2020, 12, 18–25. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.-K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 130. [Google Scholar] [CrossRef]
- Cynthia, S.T.; Rasul, M.G.; Ripon, S. Effect of Feature Selection in Software Fault Detection. In Proceedings of the International Conference on Multi-disciplinary Trends in Artificial Intelligence, Kuala Lumpur, Malaysia, 17–19 November 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 52–63. [Google Scholar]
- Jia, L. A hybrid feature selection method for software defect prediction. IOP Conf. Ser. Mater. Sci. Eng. 2018, 394, 032035. [Google Scholar] [CrossRef]
- Jacquier, E.; Kane, A.; Marcus, A.J. Geometric or arithmetic mean: A reconsideration. Financ. Anal. J. 2003, 59, 46–53. [Google Scholar] [CrossRef]
- Wang, H.; Khoshgoftaar, T.M.; Napolitano, A. A comparative study of ensemble feature selection techniques for software defect prediction. In Proceedings of the 2010 Ninth International Conference on Machine Learning and Applications, Washington, DC, USA, 12–14 December 2010; IEEE: Washington, DC, USA, 2010; pp. 135–140. [Google Scholar]
- Xia, Y.; Yan, G.; Jiang, X.; Yang, Y. A new metrics selection method for software defect prediction. In Proceedings of the 2014 IEEE International Conference on Progress in Informatics and Computing, Shanghai, China, 16–18 May 2014; IEEE: Shanghai, China, 2014; pp. 433–436. [Google Scholar]
- Malik, M.R.; Yining, L.; Shaikh, S. The Role of Attribute Ranker using classification for Software Defect-Prone Data sets Model: An Empirical Comparative Study. In Proceedings of the 2020 IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24 August–20 September 2020; pp. 1–8. [Google Scholar]
- Yu, Q.; Jiang, S.; Zhang, Y. The performance stability of defect prediction models with class imbalance: An empirical study. IEICE TRANS. Inf. Syst. 2017, 100, 265–272. [Google Scholar] [CrossRef]
- Shepperd, M.; Song, Q.; Sun, Z.; Mair, C. Data quality: Some comments on the NASA software defect datasets. IEEE Trans. Softw. Eng. 2013, 39, 1208–1215. [Google Scholar] [CrossRef]
- Balogun, A.O.; Lafenwa-Balogun, F.B.; Mojeed, H.A.; Adeyemo, V.E.; Akande, O.N.; Akintola, A.G.; Bajeh, A.O.; Usman-Hamza, F.E. SMOTE-Based Homogeneous Ensemble Methods for Software Defect Prediction. In Proceedings of the International Conference on Computational Science and Its Applications, Cagliari, Italy, 1–4 July 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 615–631. [Google Scholar]
- Balogun, A.O.; Bajeh, A.O.; Orie, V.A.; Yusuf-Asaju, W.A. Software Defect Prediction Using Ensemble Learning: An ANP Based Evaluation Method. FUOYE J. Eng. Technol. 2018, 3, 50–55. [Google Scholar] [CrossRef]
- Imam, A.A.; Basri, S.; Ahmad, R.; Wahab, A.A.; González-Aparicio, M.T.; Capretz, L.F.; Alazzawi, A.K.; Balogun, A.O. DSP: Schema Design for Non-Relational Applications. Symmetry 2020, 12, 1799. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modelling; Springer: Berlin/Hedielberg, Germany, 2013. [Google Scholar]
- Alsariera, Y.A.; Adeyemo, V.E.; Balogun, A.O.; Alazzawi, A.K. Ai meta-learners and extra-trees algorithm for the detection of phishing websites. IEEE Access 2020, 8, 142532–142542. [Google Scholar] [CrossRef]
- Alsariera, Y.A.; Elijah, A.V.; Balogun, A.O. Phishing Website Detection: Forest by Penalizing Attributes Algorithm and Its Enhanced Variations. Arab. J. Sci. Eng. 2020, 45, 10459–10470. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Tantithamthavorn, C.; McIntosh, S.; Hassan, A.E.; Matsumoto, K. Comments on “Researcher Bias: The Use of Machine Learning in Software Defect Prediction”. IEEE Trans. Softw. Eng. 2016, 42, 1092–1094. [Google Scholar] [CrossRef]
- Tantithamthavorn, C.; McIntosh, S.; Hassan, A.E.; Matsumoto, K. The Impact of Automated Parameter Optimization on Defect Prediction Models. IEEE Trans. Softw. Eng. 2018, 45, 683–711. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Algorithms | Parameter Settings |
|---|---|
| Decision Tree (DT) | ConfidenceFactor = 0.25; MinObj = 2 |
| Naïve Bayes (NB) | NumDecimalPlaces = 2; NumAttrEval = Normal Dist. |
| Aggregators | Formula | Description |
|---|---|---|
| Min () | min{} | Selects the minimum of the relevance scores produced by the aggregated rank list |
| Max () | max{} | Selects the maximum of the relevance scores produced by the aggregated rank list |
| Range () | range{} | Selects the range of the relevance scores produced by the aggregated rank list |
| Mean () | mean{ | Selects the mean of the relevance scores produced by the aggregated rank list |
| Geometric Mean () | g.mean{} | Selects the geometric mean of the relevance scores produced by the aggregated rank list |
| Harmonic Mean () | h.mean{} | Selects the harmonic mean of the relevance scores produced by the aggregated rank list |
| Datasets | Number of Features | Number of Modules |
|---|---|---|
| CM1 | 38 | 327 |
| KC1 | 22 | 1162 |
| KC2 | 22 | 522 |
| KC3 | 40 | 194 |
| MW1 | 38 | 250 |
| PC1 | 38 | 679 |
| PC3 | 38 | 1077 |
| PC4 | 38 | 1287 |
| PC5 | 39 | 1711 |
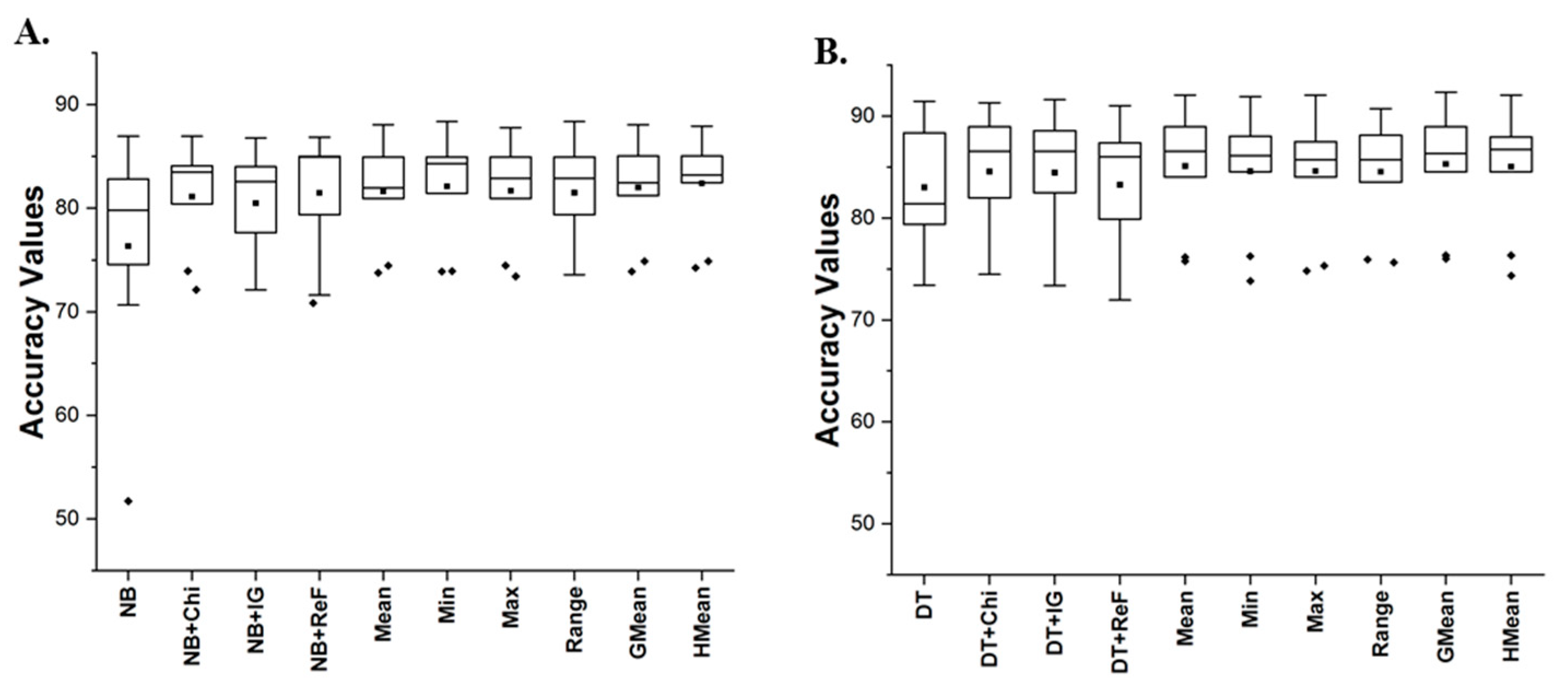
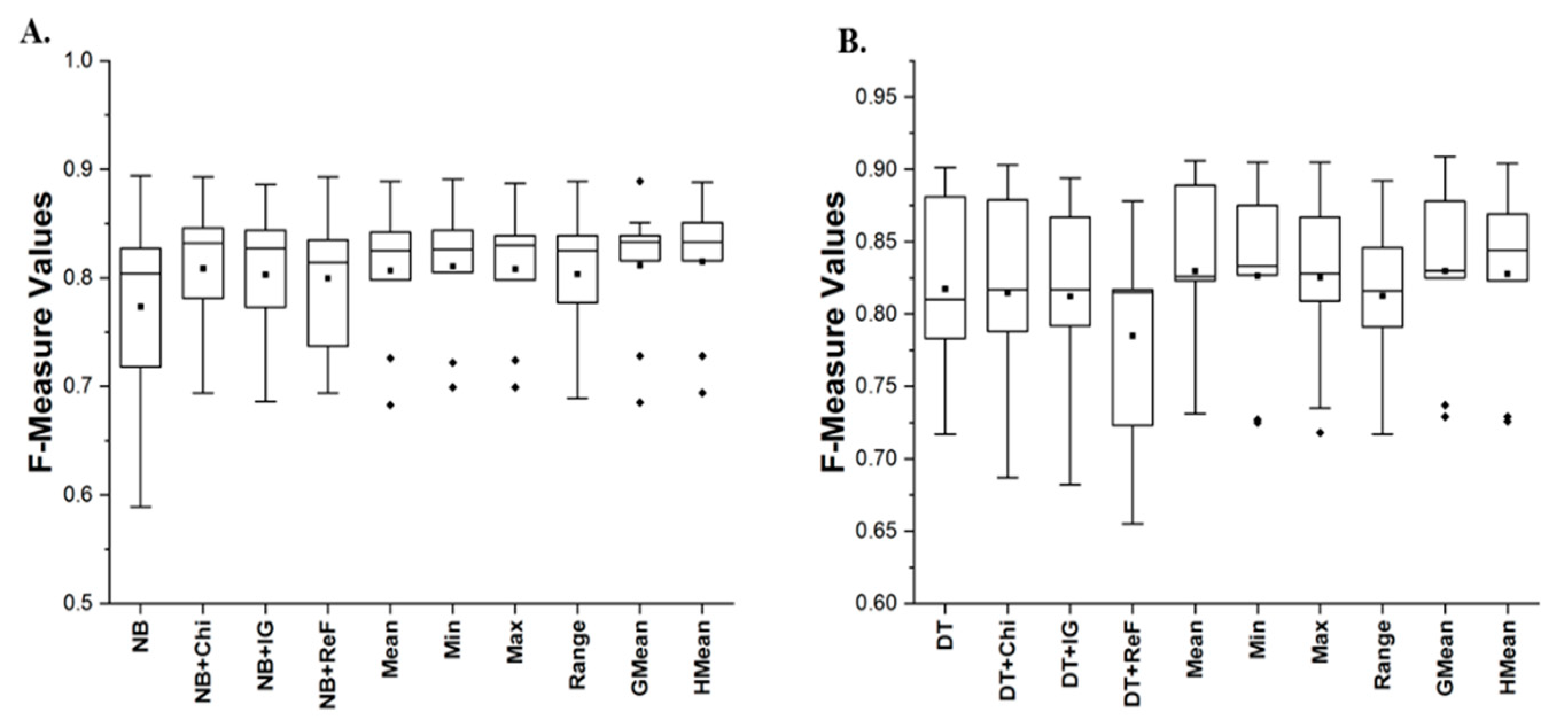
| Models | Average Accuracy | Average AUC | Average F-Measure |
|---|---|---|---|
| NB | 76.33 | 0.726 | 0.773 |
| NB + Chi | 81.12 | 0.746 | 0.809 |
| NB + IG | 80.48 | 0.748 | 0.803 |
| NB + ReF | 81.47 | 0.751 | 0.800 |
| Mean | 81.65 | 0.756 | 0.807 |
| Min | 82.11 | 0.764 | 0.811 |
| Max | 81.69 | 0.761 | 0.808 |
| Range | 81.50 | 0.741 | 0.803 |
| GMean | 82.01 | 0.761 | 0.812 |
| HMean | 82.40 | 0.764 | 0.815 |
| Models | Average Accuracy | Average AUC | Average F-Measure |
|---|---|---|---|
| DT | 83.01 | 0.625 | 0.816 |
| DT + Chi | 84.56 | 0.657 | 0.819 |
| DT + IG | 84.45 | 0.648 | 0.817 |
| DT + ReF | 83.26 | 0.630 | 0.807 |
| Mean | 85.10 | 0.680 | 0.830 |
| Min | 84.58 | 0.690 | 0.826 |
| Max | 84.62 | 0.686 | 0.825 |
| Range | 84.53 | 0.668 | 0.813 |
| G-Mean | 85.29 | 0.694 | 0.830 |
| H-Mean | 85.04 | 0.686 | 0.828 |
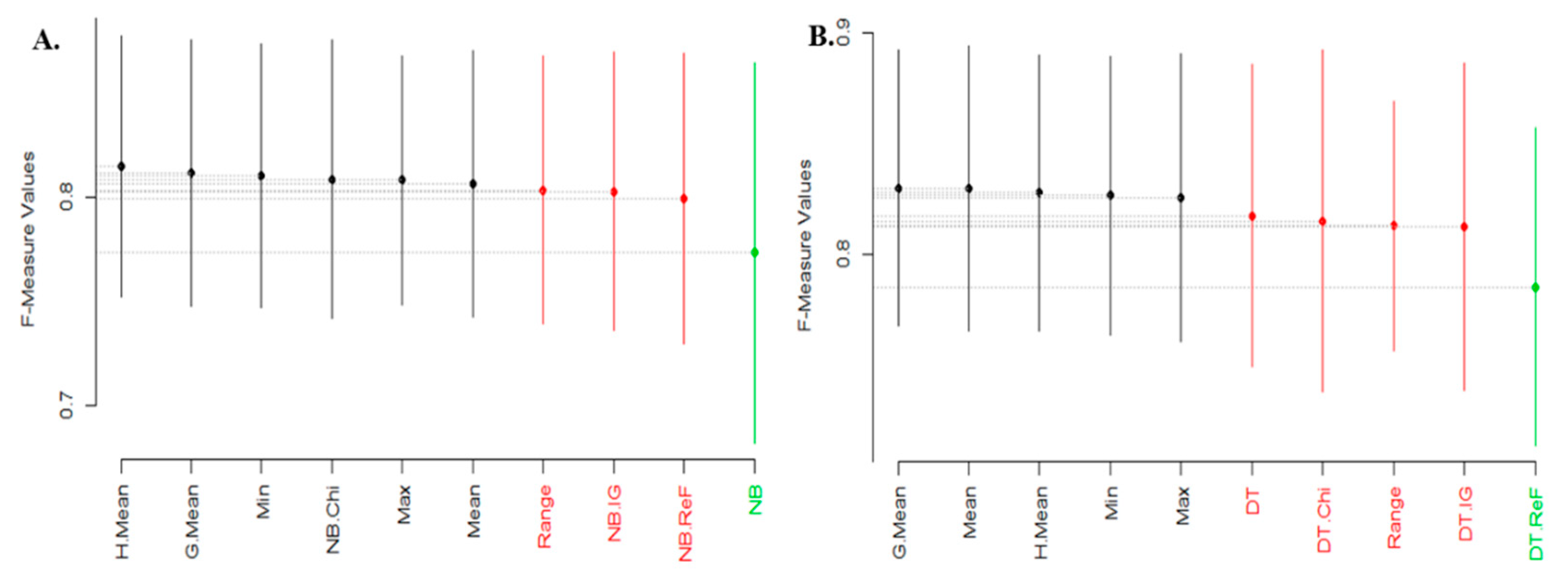
| Statistical Rank | Average Accuracy | Average AUC | Average F-Measure | |||
|---|---|---|---|---|---|---|
| NB | DT | NB | DT | NB | DT | |
| 1 | HMean, Min, GMean, Max, Mean, Range, NB + REF | GMean, Mean, HMean, Max, Min, DT + CS, Range, DT + IG | Min, HMean, GMean, Max, Mean | GMean, Min, Max, HMean, Mean | HMean, GMean, Min, NB + CS, Max, Mean | GMean, Mean, HMean, Min, Max |
| 2 | NB + CS, NB + IG | DT + REF, DT | NB + REF, NB + IG, NB + CS, Range | Range, DT + CS | Range, NB + IG, NB + REF | DT, DT + CS, Range, DT + IG |
| 3 | NB | - | NB | DT + IG | NB | DT + REF |
| 4 | - | - | - | DT | - | - |
| 5 | - | - | - | DT + REF | - | - |
| Research Questions | Answers |
|---|---|
| RQ1. How effective are the proposed RMFFS methods compared to individual filter FS methods? | The proposed RMFFS outperforms individual FFS methods with significant differences. |
| RQ2. Which of RMFFS methods had the highest positive impact on the prediction performance of SDP models? | GMean-based RMFFS method was superior to other RMFFS methods. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Capretz, L.F.; Imam, A.A.; Almomani, M.A.; Adeyemo, V.E.; Kumar, G. Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction. Electronics 2021, 10, 179. https://doi.org/10.3390/electronics10020179
Balogun AO, Basri S, Mahamad S, Abdulkadir SJ, Capretz LF, Imam AA, Almomani MA, Adeyemo VE, Kumar G. Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction. Electronics. 2021; 10(2):179. https://doi.org/10.3390/electronics10020179
Chicago/Turabian StyleBalogun, Abdullateef O., Shuib Basri, Saipunidzam Mahamad, Said Jadid Abdulkadir, Luiz Fernando Capretz, Abdullahi A. Imam, Malek A. Almomani, Victor E. Adeyemo, and Ganesh Kumar. 2021. "Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction" Electronics 10, no. 2: 179. https://doi.org/10.3390/electronics10020179
APA StyleBalogun, A. O., Basri, S., Mahamad, S., Abdulkadir, S. J., Capretz, L. F., Imam, A. A., Almomani, M. A., Adeyemo, V. E., & Kumar, G. (2021). Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction. Electronics, 10(2), 179. https://doi.org/10.3390/electronics10020179