
ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence




Abstract
:1. Introduction
- An architecture based on existing blocks such as 3-dimension DenseNet, multi-head self-attention mechanism, and bidirectional convolutional LSTM, trained to detect violent actions in videos.
- An analysis of the input format (optical flow and adjacent frames subtraction) and their influence in the results.
- An experimentation with four datasets in which the state of the art for violence detection is improved.
- A cross-dataset analysis to check the generalization of the concept of violent actions.
2. Related Work
2.1. Non-Deep Learning Methods
2.2. Deep Learning Methods
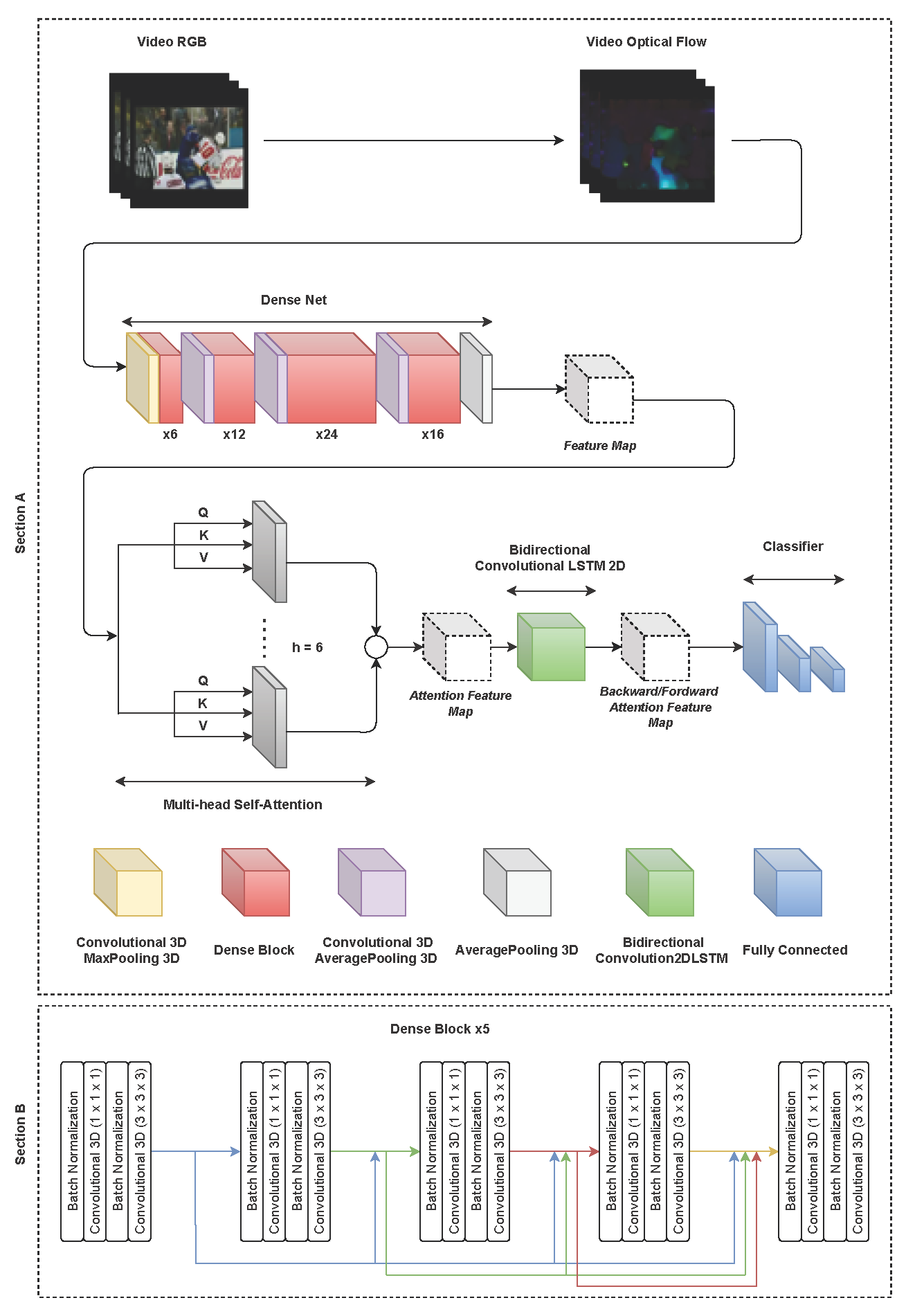
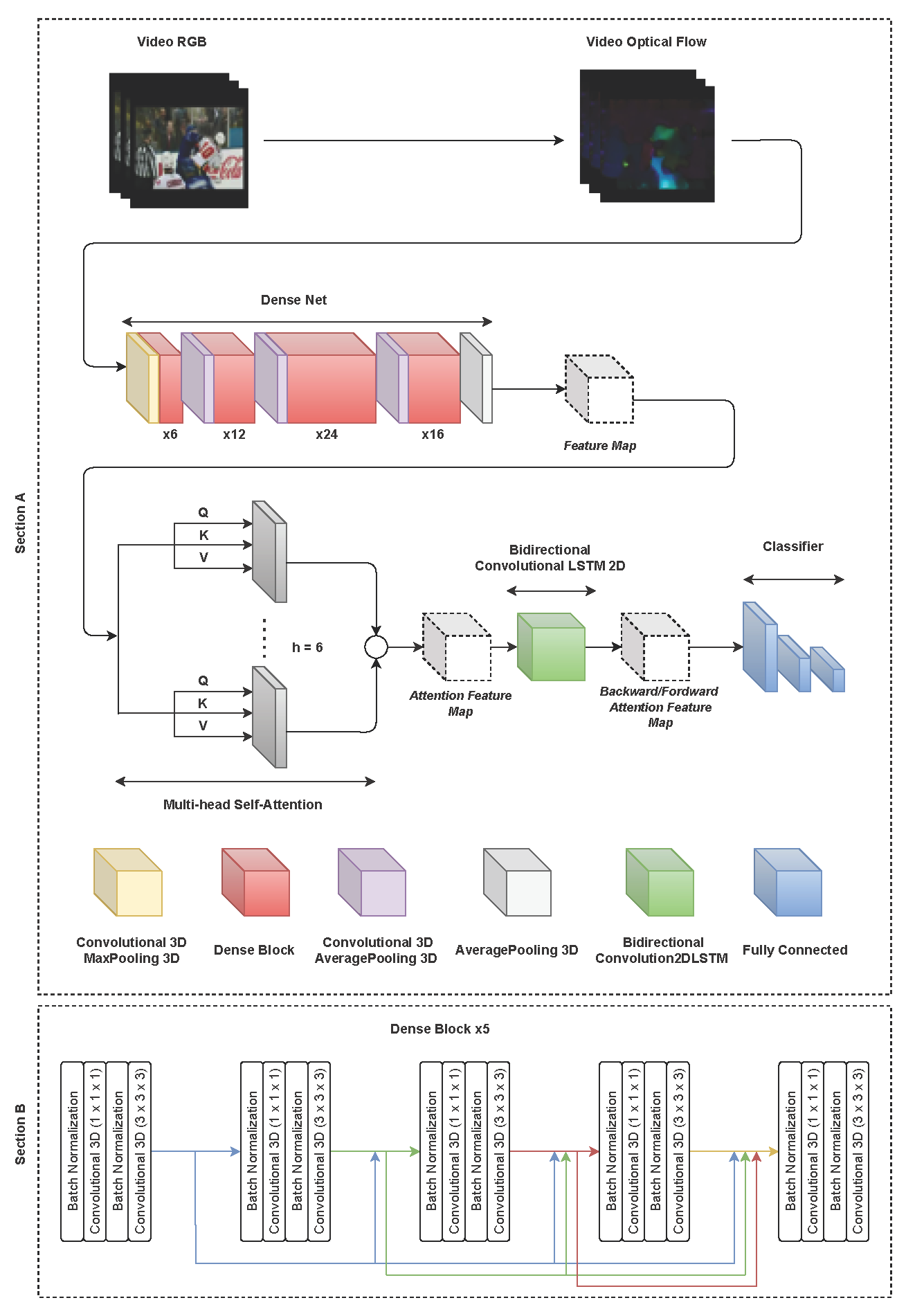
3. Model Architecture
3.1. Model Justification
3.2. Optical Flow
3.3. DenseNet Convolutional 3D
3.4. Multi-Head Self-Attention
3.5. Bidirectional Convolutional LSTM 2D
3.6. Classifier
4. Data
- Hockey Fights (HFs) [17] a collection of hockey games from the USA’s National Hockey League (NHL) that includes fights between players.
- Movies Fights (MFs) [17] a 200-clip collection of scenes from action movies that includes fight and non fight events.
- Violent Flows (VFs) [25] a collection of videos that include violence in crowds. It differs from the previous ones in that it is focused on crowds and not in person-to-person violence but it is interesting to check the versatility of the model.
- Real Life Violence Situations (RLVSs) [54] a collection of 1000 violence and 1000 non-violence videos collected from youtube, violence videos contain many real street fights situations in several environments and conditions. Additionally, non-violence videos are collected from many different human actions like sports, eating, walking, etc.
5. Experiments
5.1. Training Methodology
5.2. Metrics
- Train accuracy: The amount of correct classifications of the model on examples it was constructed on divided by the total amount of classifications.
- Test accuracy: The amount of correct classifications of the model on examples it has not seen divided by the total amount of classifications.
- Test inference time: The average latency time when making predictions atomically on the test dataset.
5.3. Ablation Study
5.4. Cross-Dataset Experimentation
6. Results
6.1. Ablation Study Results
6.2. State of the Art Comparison
6.3. Cross-Dataset Experimentation Results
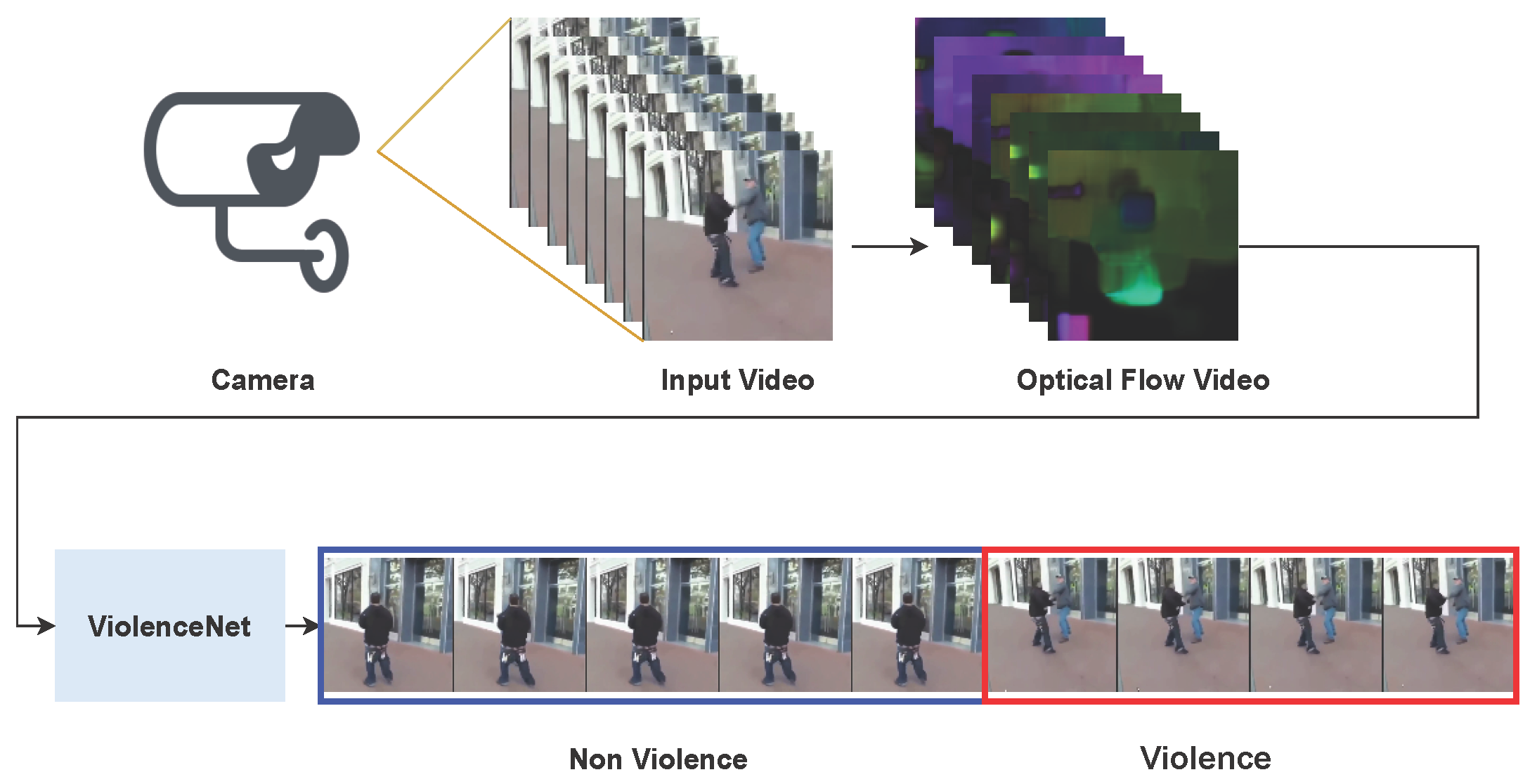
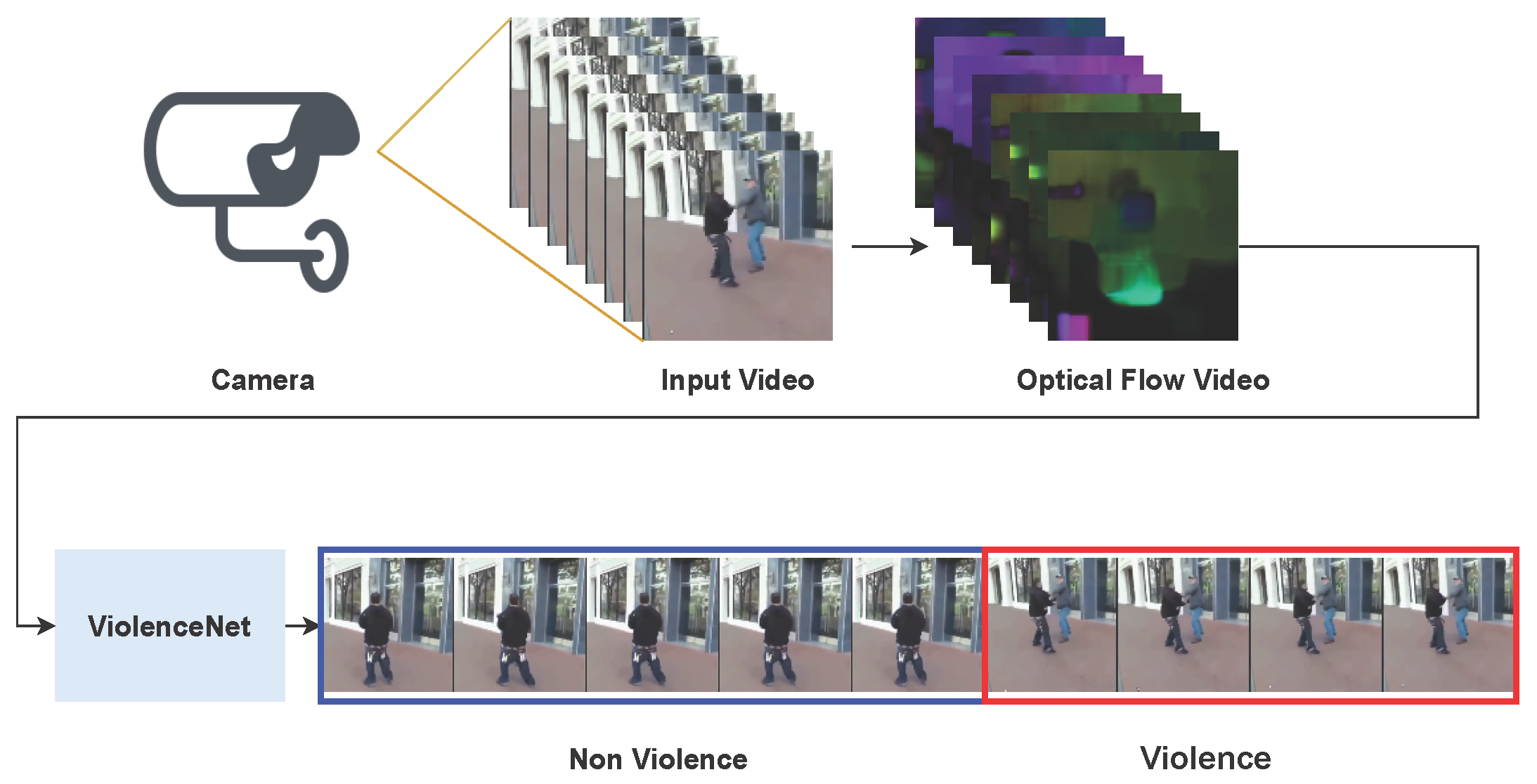
6.4. Detection Process in CCTV
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chaquet, J.M.; Carmona, E.J.; Fernández-Caballero, A. A survey of video datasets for human action and activity recognition. Comput. Vis. Image Underst. 2013, 117, 633–659. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Lai, A. A survey on still image based human action recognition. Pattern Recognit. 2014, 47, 3343–3361. [Google Scholar] [CrossRef]
- Carranza-García, M.; Torres-Mateo, J.; Lara-Benítez, P.; García-Gutiérrez, J. On the Performance of One-Stage and Two-Stage Object Detectors in Autonomous Vehicles Using Camera Data. Remote Sens. 2021, 13, 89. [Google Scholar] [CrossRef]
- Velastin, S.A.; Boghossian, B.A.; Vicencio-Silva, M.A. A motion-based image processing system for detecting potentially dangerous situations in underground railway stations. Transp. Res. Part Emerg. Technol. 2006, 14, 96–113. [Google Scholar] [CrossRef]
- Ainsworth, T. Buyer beware. Secur. Oz 2002, 19, 18–26. [Google Scholar]
- Cheng, G.; Wan, Y.; Saudagar, A.N.; Namuduri, K.; Buckles, B.P. Advances in human action recognition: A survey. arXiv 2015, arXiv:1501.05964. [Google Scholar]
- Kooij, J.; Liem, M.; Krijnders, J.; Andringa, T.; Gavrila, D. Multi-modal human aggression detection. Comput. Vis. Image Underst. 2016, 144, 106–120. [Google Scholar] [CrossRef]
- Nazare, A.C., Jr.; Schwartz, W.R. A scalable and flexible framework for smart video surveillance. Comput. Vis. Image Underst. 2016, 144, 258–275. [Google Scholar] [CrossRef]
- Salazar-González, J.L.; Zaccaro, C.; Álvarez-García, J.A.; Soria-Morillo, L.M.; Caparrini, F.S. Real-time gun detection in CCTV: An open problem. Neural Netw. 2020, 132, 297–308. [Google Scholar] [CrossRef]
- Vallez, N.; Velasco-Mata, A.; Deniz, O. Deep autoencoder for false positive reduction in handgun detection. Neural Comput. Appl. 2020, 1–11. [Google Scholar] [CrossRef]
- Ruiz-Santaquiteria, J.; Velasco-Mata, A.; Vallez, N.; Bueno, G.; Álvarez García, J.A.; Deniz, O. Handgun detection using combined human pose and weapon appearance. arXiv 2021, arXiv:2010.13753. [Google Scholar]
- United Nations Office on Drugs and Crime (UNODC) Global Study on Homicide 2019. Available online: https://www.unodc.org/documents/data-and-analysis/gsh/Booklet1.pdf (accessed on 2 July 2021).
- Clarin, C.; Dionisio, J.; Echavez, M.; Naval, P. DOVE: Detection of movie violence using motion intensity analysis on skin and blood. PCSC 2005, 6, 150–156. [Google Scholar]
- Chen, D.; Wactlar, H.; Chen, M.y.; Gao, C.; Bharucha, A.; Hauptmann, A. Recognition of aggressive human behavior using binary local motion descriptors. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 5238–5241. [Google Scholar]
- Xu, L.; Gong, C.; Yang, J.; Wu, Q.; Yao, L. Violent video detection based on MoSIFT feature and sparse coding. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3538–3542. [Google Scholar]
- Ribeiro, P.C.; Audigier, R.; Pham, Q.C. RIMOC, a feature to discriminate unstructured motions: Application to violence detection for video-surveillance. Comput. Vis. Image Underst. 2016, 144, 121–143. [Google Scholar] [CrossRef]
- Bermejo, E.; Deniz, O.; Bueno, G.; Sukthankar, R. Violence detection in video using computer vision techniques. In International Conference on Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar]
- Bilinski, P.; Bremond, F. Human violence recognition and detection in surveillance videos. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 30–36. [Google Scholar]
- Cai, H.; Jiang, H.; Huang, X.; Yang, J.; He, X. Violence detection based on spatio-temporal feature and fisher vector. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV); Springer: Berlin/Heidelberg, Germany, 2018; pp. 180–190. [Google Scholar]
- Senst, T.; Eiselein, V.; Kuhn, A.; Sikora, T. Crowd violence detection using global motion-compensated Lagrangian features and scale-sensitive video-level representation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2945–2956. [Google Scholar] [CrossRef]
- Zhang, T.; Jia, W.; Yang, B.; Yang, J.; He, X.; Zheng, Z. MoWLD: A robust motion image descriptor for violence detection. Multimed. Tools Appl. 2017, 76, 1419–1438. [Google Scholar] [CrossRef]
- Serrano, I.; Deniz, O.; Espinosa-Aranda, J.L.; Bueno, G. Fight recognition in video using Hough Forests and 2D convolutional neural network. IEEE Trans. Image Process. 2018, 27, 4787–4797. [Google Scholar] [CrossRef] [PubMed]
- Das, S.; Sarker, A.; Mahmud, T. Violence Detection from Videos using HOG Features. In Proceedings of the 2019 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, P.; Ding, Q.; Luo, H.; Hou, X. Violence detection in surveillance video using low-level features. PLoS ONE 2018, 13, e0203668. [Google Scholar] [CrossRef]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent Flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar]
- Zhang, T.; Yang, Z.; Jia, W.; Yang, B.; Yang, J.; He, X. A new method for violence detection in surveillance scenes. Multimed. Tools Appl. 2016, 75, 7327–7349. [Google Scholar] [CrossRef]
- Mahmoodi, J.; Salajeghe, A. A classification method based on optical flow for violence detection. Expert Syst. Appl. 2019, 127, 121–127. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems 27, Montréal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Meng, Z.; Yuan, J.; Li, Z. Trajectory-pooled deep convolutional networks for violence detection in videos. In International Conference on Computer Vision Systems; Springer: Berlin/Heidelberg, Germany, 2017; pp. 437–447. [Google Scholar]
- Dong, Z.; Qin, J.; Wang, Y. Multi-stream deep networks for person to person violence detection in videos. In Chinese Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2016; pp. 517–531. [Google Scholar]
- Sudhakaran, S.; Lanz, O. Learning to detect violent videos using Convolutional long short-term memory. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Hanson, A.; PNVR, K.; Krishnagopal, S.; Davis, L. Bidirectional Convolutional LSTM for the Detection of Violence in Videos. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, September 2018; pp. 280–295. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Aktı, Ş.; Tataroğlu, G.A.; Ekenel, H.K. Vision-based Fight Detection from Surveillance Cameras. In Proceedings of the 2019 Ninth International Conference on Image Processing Theory, Tools and Applications (IPTA), Istanbul, Turkey, 6–9 November 2019; pp. 1–6. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Zhou, P.; Ding, Q.; Luo, H.; Hou, X. Violent interaction detection in video based on deep learning. J. Phys. Conf. Ser. IOP Publ. 2017, 844, 012044. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Van Gool, L. Temporal 3d convnets: New architecture and transfer learning for video classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J. Pose-conditioned spatio-temporal attention for human action recognition. arXiv 2017, arXiv:1703.10106. [Google Scholar]
- Cho, S.; Maqbool, M.; Liu, F.; Foroosh, H. Self-attention network for skeleton-based human action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 635–644. [Google Scholar]
- Courtney, L.; Sreenivas, R. Using Deep Convolutional LSTM Networks for Learning Spatiotemporal Features. In Asian Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2019; pp. 307–320. [Google Scholar]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Scandinavian Conference on Image Analysis; Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–370. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liang, S.; Zhang, R.; Liang, D.; Song, T.; Ai, T.; Xia, C.; Xia, L.; Wang, Y. Multimodal 3D DenseNet for IDH genotype prediction in gliomas. Genes 2018, 9, 382. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Shen, Y.; Wang, S.; Xiao, T.; Deng, L.; Wang, X.; Zhao, X. Ensemble of 3D densely connected convolutional network for diagnosis of mild cognitive impairment and Alzheimer’s disease. Neurocomputing 2019, 333, 145–156. [Google Scholar] [CrossRef]
- Lin, Z.; Feng, M.; Santos, C.N.d.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. arXiv 2017, arXiv:1705.04304. [Google Scholar]
- Zhang, L.; Zhu, G.; Shen, P.; Song, J.; Afaq Shah, S.; Bennamoun, M. Learning spatiotemporal features using 3dcnn and convolutional lstm for gesture recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3120–3128. [Google Scholar]
- Liu, Q.; Zhou, F.; Hang, R.; Yuan, X. Bidirectional-convolutional LSTM based spectral-spatial feature learning for hyperspectral image classification. Remote Sens. 2017, 9, 1330. [Google Scholar]
- Soliman, M.M.; Kamal, M.H.; Nashed, M.A.E.M.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–10 December 2019; pp. 80–85. [Google Scholar]
- Varol, G.; Laptev, I.; Schmid, C. Long-term temporal convolutions for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1510–1517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sanchez-Caballero, A.; de López-Diz, S.; Fuentes-Jimenez, D.; Losada-Gutiérrez, C.; Marrón-Romera, M.; Casillas-Perez, D.; Sarker, M.I. 3DFCNN: Real-Time Action Recognition using 3D Deep Neural Networks with Raw Depth Information. arXiv 2020, arXiv:2006.07743. [Google Scholar]
- Sharma, M.; Baghel, R. Video Surveillance for Violence Detection Using Deep Learning. In Advances in Data Science and Management; Springer: Berlin/Heidelberg, Germany, 2020; pp. 411–420. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An Open Large Scale Video Database for Violence Detection. arXiv 2019, arXiv:1911.05913. [Google Scholar]
- Khan, S.U.; Haq, I.U.; Rho, S.; Baik, S.W.; Lee, M.Y. Cover the violence: A novel Deep-Learning-Based approach towards violence-detection in movies. Appl. Sci. 2019, 9, 4963. [Google Scholar] [CrossRef] [Green Version]
- Jiang, B.; Xu, F.; Tu, W.; Yang, C. Channel-wise attention in 3d convolutional networks for violence detection. In Proceedings of the 2019 International Conference on Intelligent Computing and its Emerging Applications (ICEA), Tainan, Taiwan, 30 August–1 September 2019; pp. 59–64. [Google Scholar]
- Moaaz, M.M.; Mohamed, E.H. Violence Detection In Surveillance Videos Using Deep Learning. Inform. Bull. Helwan Univ. 2020, 2, 1–6. [Google Scholar] [CrossRef]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only Look, but also Listen: Learning Multimodal Violence Detection under Weak Supervision. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 322–339. [Google Scholar]
- Degardin, B.; Proença, H. Iterative weak/self-supervised classification framework for abnormal events detection. Pattern Recognit. Lett. 2021, 145, 50–57. [Google Scholar] [CrossRef]
- Perez, M.; Kot, A.C.; Rocha, A. Detection of real-world fights in surveillance videos. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2662–2666. [Google Scholar]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 244–253. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Clips | Average Frames |
|---|---|---|
| Hockey Fights [17] | 1000 | 50 |
| Movies Fights [17] | 200 | 50 |
| Violent Flows [25] | 246 | 100 |
| Real Life Violence Situations [54] | 2000 | 100 |
| Dataset | Input | Test Accuracy (with Attention) | Test Accuracy (without Att.) | Test Inference Time (with Attention) | Test Inference Time (without Att.) |
|---|---|---|---|---|---|
| HF | Optical Flow | 99.20 ± 0.6% | 99.00 ± 1.0% | 0.1397 ± 0.0024 s | 0.1626 ± 0.0034 s |
| HF | Pseudo-Optical Flow | 97.50 ± 1.0% | 97.20 ± 1.0% | ||
| MF | Optical Flow | 100.00 ± 0.0% | 100.00 ± 0.0% | 0.1916 ± 0.0093 s | 0.2019 ± 0.0045 s |
| MF | Pseudo-Optical Flow | 100.00 ± 0.0% | 100.00 ± 0.0% | ||
| VF | Optical Flow | 96.90 ± 0.5% | 94.00 ± 1.0% | 0.2991 ± 0.0030 s | 0.3114 ± 0.0073 s |
| VF | Pseudo-Optical Flow | 94.80 ± 0.5% | 92.50 ± 0.5% | ||
| RLVS | Optical Flow | 95.60 ± 0.6% | 93.40 ± 1.0% | 0.2767 ± 0.020 s | 0.3019 ± 0.0059 s |
| RLVS | Pseudo-Optical Flow | 94.10 ± 0.8% | 92.20 ± 0.8% |
| Dataset | Input | Training Accuracy | Training Loss | Test Accuracy Violence | Test Accuracy Non-Violence | Test Accuracy |
|---|---|---|---|---|---|---|
| HF | Optical Flow | 100% | 99.00% | 100.00% | 99.50% | |
| HF | Pseudo-Optical Flow | 99% | 97.00% | 98.00% | 97.50% | |
| MF | Optical Flow | 100% | 100% | 100% | 100% | |
| MF | Pseudo-Optical Flow | 100% | 100% | 100% | 100% | |
| VF | Optical flow | 98% | 97.00% | 96.00% | 96.50% | |
| VF | Pseudo-Optical Flow | 97% | 95.00% | 94.00% | 94.50% | |
| RLVS | Optical Flow | 97% | 96.00% | 95.00% | 95.50% | |
| RLVS | Pseudo-Optical Flow | 95% | 94.00% | 93.00% | 93.50% |
| Model | HF test Accuracy | MF Test Accuracy | VF Test Accuracy | RLVS Test Accuracy | Train − Test | Validation | Params |
|---|---|---|---|---|---|---|---|
| VGG13-BiConvLSTM [34] | 100 ± 0% | − | 5 fold cross | − | |||
| Spatial Encoder VGG13 [34] | 100 ± 0% | − | 5 fold cross | − | |||
| FightNet [38] | 100 ± 0% | − | − | hold-out | − | ||
| Three streams + LSTM [31] | − | − | − | − | − | − | |
| AlexNet - ConvLSTM [32] | 100 ± 0% | % | − | 5 fold cross | 9.6 M | ||
| Hough Forest + CNN [22] | − | − | 5 fold cross | - | |||
| FlowGatedNetwork [59] | − | hold-out | 5.07 K | ||||
| Fine-Tuning Mobile-Net [60] | − | − | hold-out | − | |||
| Xception BiLSTM Attention 10 [36] | 100 ± 0% | − | − | hold-out | 9 M | ||
| Xception BiLSTM Attention 5 [36] | 100 ± 0% | − | − | hold-out | 9 M | ||
| SELayer-C3D [61] | − | − | − | hold-out | − | ||
| Conv2D LSTM [62] | − | − | hold-out | − | |||
| ViolenceNet Pseudo-OF | 100 ± 0% | 5 fold cross | 4.5 M | ||||
| ViolenceNet OF | 99.20 ± 0.6% | 100 ± 0% | 96.90 ± 0.5% | 95.60 ± 0.6% | 5 fold cross | 4.5 M |
| Dataset Training | Dataset Testing | Test Accuracy Optical Flow | Test Accuracy Pseudo-Optical Flow |
|---|---|---|---|
| HF | MF | 65.18 ± 0.34 | 64.86 ± 0.41 |
| HF | VF | 62.56 ± 0.33 | 61.22 ± 0.22 |
| HF | RLVS | 58.22 ± 0.24 | 57.36 ± 0.22 |
| MF | HF | 54.92 ± 0.33 | 53.50 ± 0.12 |
| MF | VF | 52.32 ± 0.34 | 51.77 ± 0.30 |
| MF | RLVS | 56.72 ± 0.19 | 55.80 ± 0.20 |
| VF | HF | 65.16 ± 0.59 | 64.76 ± 0.49 |
| VF | MF | 60.02 ± 0.24 | 59.48 ± 0.16 |
| VF | RLVS | 58.76 ± 0.49 | 58.32 ± 0.27 |
| RLVS | HF | 69.24 ± 0.27 | 68.86 ± 0.14 |
| RLVS | MF | 75.82 ± 0.17 | 74.64 ± 0.22 |
| RVLS | VF | 67.84 ± 0.32 | 66.68 ± 0.22 |
| HF + MF + VF | RLVS | 70.08 ± 0.19 | 69.84 ± 0.14 |
| HF + MF + RLVS | VF | 76.00 ± 0.20 | 75.68 ± 0.14 |
| HF + RLVS + VF | MF | 81.51 ± 0.09 | 80.49 ± 0.05 |
| RLVS + MF + VF | HF | 79.87 ± 0.33 | 78.63 ± 0.01 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rendón-Segador, F.J.; Álvarez-García, J.A.; Enríquez, F.; Deniz, O. ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics 2021, 10, 1601. https://doi.org/10.3390/electronics10131601
Rendón-Segador FJ, Álvarez-García JA, Enríquez F, Deniz O. ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics. 2021; 10(13):1601. https://doi.org/10.3390/electronics10131601
Chicago/Turabian StyleRendón-Segador, Fernando J., Juan A. Álvarez-García, Fernando Enríquez, and Oscar Deniz. 2021. "ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence" Electronics 10, no. 13: 1601. https://doi.org/10.3390/electronics10131601
APA StyleRendón-Segador, F. J., Álvarez-García, J. A., Enríquez, F., & Deniz, O. (2021). ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics, 10(13), 1601. https://doi.org/10.3390/electronics10131601