Abstract
Generative Artificial Intelligence (GenAI)-assisted Virtual Reality (VR) heritage serious game design constitutes a complex adaptive socio-technical system in which natural language prompts act as control levers shaping designers’ cognition and action. However, the systemic effects of prompt type on agency construction, decision boundaries, and process strategy remain unclear. Treating the design setting as adaptive, we captured real-time interactions by collecting think-aloud data from 48 novice designers. Nine prompt categories were extracted and their cognitive effects were systematically analyzed through the Repertory Grid Technique (RGT), principal component analysis (PCA), and Ward clustering. These analyses revealed three perception profiles: tool-based, collaborative, and mentor-like. Strategy coding of 321 prompt-aligned utterances showed cluster-specific differences in path length, first moves, looping, and branching. Tool-based prompts reinforced boundary control through short linear refinements; collaborative prompts sustained moderate iterative enquiry cycles; mentor-like prompts triggered divergent exploration via self-loops and frequent jumps. We therefore propose a stage-adaptive framework that deploys mentor-like prompts for ideation, collaborative prompts for mid-phase iteration, and tool-based prompts for final verification. This approach balances creativity with procedural efficiency and offers a reusable blueprint for integrating prompt-driven agency modelling into GenAI design workflows.
1. Introduction
Advances in generative AI (GenAI) have begun to reshape professional design practice. Empirical work shows that these systems can match the output quality of experienced designers and significantly increase novices’ creative efficiency [1]. Such progress, however, has been accompanied by concern that automated tools may displace human labor [2]. Other practitioners take the opposite view, regarding generative systems as valuable creative partners and integrating them into their workflows [3]. Moreover, several recent studies have systematically examined designers’ interaction patterns with AI during application development, identifying distinct usage styles, such as directive prompting, exploratory querying, and evaluative refinement, and documenting their effects on workflow efficiency and design ideation quality [4,5,6]. Recent studies describe a dual effect: while model assistance can raise overall idea quality, it can also foster solution convergence and reduce team-level diversity [7]. Designers therefore face a trade-off between the efficiency gained through automation and the potential loss of initiative and strategic variety [7].
Prompt design has emerged as a pivotal factor in this collaboration. Minor changes in wording or context can markedly alter system output [8]. Crafting effective prompts is not intuitive; it develops through trial and error and is shaped by user experience, interaction strategy, and shared knowledge [9]. In design settings, prompt type and usage strategy determine how the system participates in the creative process [10]. For example, without early guiding prompts, novices are prone to cognitive fixation and generate results with low diversity and originality [11]. However, systematic examinations of how prompt type influences both the creative process and designers’ cognition remain scarce, particularly in complex, constraint-rich tasks such as VR serious game development or cultural heritage interaction [11].
As GenAI systems increasingly influence design-stage decisions, designers must renegotiate who sets goals and who executes tasks. Scholars distinguish “designing for a system” from “designing with a system” and argue for a new perspective that emphasizes role perception and control rather than mere technical operation [12]. When a system assumes more operational duties, designers act as arbiters who critique and filter its proposals [13]. Excessive reliance on automated output, however, may erode creative initiative [7]. A symbiotic framework has thus been proposed, advocating clear decision boundaries for the technology while retaining human judgment [14]. Facilitating effective collaboration therefore requires designers to develop clear mental models of how different GenAI prompts construct their sense of agency, balancing perceived control and role attribution, thereby enabling calibrated trust and reducing user frustration [15]. Empirical evidence on how different prompt types trigger distinct perceptions of agency and influence strategic behavior is still limited, especially in immersive VR design where prompts also serve as psychological carriers of role definition and trust [16].
Against this background, the present study adopts agency construction as a central lens. It investigates how novice designers, through varied prompt types, form mental representations of the GenAI system as a tool, partner, or mentor and how these perceptions guide the entire chain from cognitive preset to behavioral strategy. Using an authentic cultural heritage VR task, we combine the think-aloud protocol (TAP) [17] with construct elicitation and rating experiment based on the Repertory Grid Technique (RGT) [18] to address three research questions:
- (1)
- Can the prompts produced by novices in the VR heritage serious game design task be classified into functionally distinct types?
- (2)
- Do these prompt types elicit divergent perceptions along the dual dimensions of perceived control and GenAI role?
- (3)
- How do different agency perceptions shape the strategic paths that designers follow?
Methodologically, prompt categories were derived from coded think-aloud transcripts. Repertory grid ratings were then analyzed with principal component analysis and hierarchical clustering to model agency perceptions. Finally, the strategy path analysis, which incorporated node coding, chain length calculation, identification of first moves, and analysis of frequent transitions, mapped how each perception profile steers design behavior.
The study makes three contributions. Theoretically, it positions prompts as triggers of mental models that influence the evolution of human–AI interaction, enriching cognitive accounts of GenAI-driven co-creation. Methodologically, it proposes a multi-layer framework that integrates repertory grid constructs with strategy chain analysis, offering a reusable approach for studying cognitive mechanisms in design. Practically, it provides stage-specific prompt guidelines and a strategy path model for novices working in cultural heritage VR, delivering actionable insights for education, platform design, and cross-disciplinary collaboration.
2. Related Work
Existing AI-assisted design research centers on two areas: how generative systems shape designers’ agency and how prompts drive workflows in VR heritage contexts. We first review agency construction and then examine prompt-driven strategies in cultural heritage VR.
2.1. Agency Construction and the Cognitive Role of GenAI in Design
In design collaborations with GenAI systems, designers’ sense of agency, defined as their perceived ownership and control over both actions and outcomes, has emerged as a key psychological variable influencing creative processes and role experience [12]. Prior research has shown that different GenAI approaches assume distinct cognitive roles within the design workflow. For example, ChatGPT series language models serve as creative writing assistants during concept generation and brainstorming, offering diverse textual suggestions, whereas diffusion models and generative adversarial networks act as visual prototyping aides during style exploration and sketch production [19,20]. This multimodal collaboration not only expands the designer’s information-processing and imaginative capacity but also shifts the paradigm from a purely designer-driven process toward a mixed intelligence team approach [21,22]. When GenAI systems display proactivity and yield partially unpredictable outputs, designers tend to regard them as equal partners rather than mere tools; in contrast, under tightly constrained conditions these systems remain framed as executors [23]. Such dynamic role attribution directly affects decision pathways and strategy choices: partnership-oriented prompts encourage iterative cycles, while tool-centered prompts support linear refinement [24].
This perspective aligns with cognitive and motivational theories that describe how perceived autonomy and locus of control shape the experience of agency. In cognitive psychology, sense of agency refers to the subjective feeling of being in control of one’s own actions and influencing events through them [25]. This construct aligns closely with perceived control and intrinsic motivation. For instance, Self-Determination Theory holds that autonomy (volitional control) is a basic psychological need for intrinsic motivation. If a designer feels that using GenAI undermines their autonomy, their self-motivation and engagement may suffer [26]. Empirical studies support this concern, for example, users interacting with highly automated AI systems (like chatbots) report significantly lower perceived autonomy compared to more manual interfaces [27]. In other words, an overly proactive AI partner could shift a designer’s perception toward an external locus of control, reducing their sense of ownership over design outcomes. On the other hand, cognitive theory such as the extended mind hypothesis argues that tools can become integrated into one’s cognitive processes rather than remaining external agents. From this perspective, a well-designed GenAI might function as a seamless extension of the designer’s mind [28]. In practice, this means the AI could augment the designers’ thinking without eroding their agency, potentially even preserving or enhancing the designers’ sense of agency within the human and AI creative partnership.
Prompt engineering is therefore pivotal to designers’ perceived control and satisfaction [29]. High-quality prompts serve as the creative code, requiring a vocabulary and syntax that map clearly to intended outcomes [29]. Structured interfaces, for example form-based templates, lower the learning barrier for novices and help preserve designer autonomy [10]. Nevertheless, prompt types differ in granularity, freedom, and feedback, shaping control perceptions and role attribution in distinct ways.
Although prior work recognizes the varied cognitive roles of GenAI systems and the influence of prompt design on agency [10,30], they remain largely confined to analyses of single models or isolated stages rather than examining how these usage patterns translate into downstream strategic behaviors in immersive tasks. Consequently, systematic frameworks linking prompt type, subjective agency, and process strategies remain scarce, particularly under authentic task conditions that combine behavioral logs with psychometric data [22].
2.2. Prompt-Driven Design Strategies and VR Applications for Cultural Heritage
With the maturation of immersive VR and MR, digital heritage research has moved beyond high-fidelity replication toward interactive, co-creative experiences [31]. GenAI accelerate this transition: designers can issue natural language prompts to diffusion networks, GANs, or large language models to create high-resolution images, three-dimensional meshes, and branching narratives, greatly enhancing efficiency and creative breadth [1]. Current studies highlight four prompt-driven strategies. First, visual realism and ambience are improved through style transfer, super-resolution, and semantic completion, enabling reconstructions that are both credible and culturally resonant [32]. By specifying period, material, and artistic lineage, prompts guide generation engines to produce scenes and artefact details that respect historical context [32]. Second, conversational prompts adapt narratives in real time to visitors’ actions and backgrounds, increasing engagement and dwell time without reducing exploratory freedom [33]. Third, semantically rich prompts let non-specialists assemble immersive environments, strengthening comprehension and memory for historical narratives [34]. Fourth, prompts can incorporate authoritative scholarship and ethical constraints to maintain factual consistency and cultural sensitivity [35].
Despite these advances, few studies have measured causal links among prompt vocabulary, syntax, contextual framing, and perceived agency [29], nor have they clarified how prompt-driven workflows influence designers’ cognitive load and sense of ownership [36]. These gaps offer important directions for future research.
3. Method
We employed a four-stage methodology: first, eliciting prompts through an AI augmented VR heritage design task; second, systematically classifying these prompts; third, modeling perceived agency via repertory grids; and fourth, tracing strategy paths from think-aloud transcripts.
3.1. Prompt Typing Through GenAI-Assisted Design Task
3.1.1. Participants and Design Task
This stage addressed RQ1 by examining how novice designers naturally deploy different types of generative AI prompts during a cultural heritage VR game design task. Forty-eight undergraduate product-design majors were recruited. All participants had completed courses on user experience, interaction design, and digital culture and thus possessed foundational knowledge of the design process. To ensure consistency in prior exposure to generative AI tools, all participants had only been briefly introduced to such tools during coursework. During the task, participants used ChatGPT 4o for all AI interactions. Valid data were collected from 48 participants (labeled U01 to U48).
Each participant worked alone in a quiet room for 90 min, using the think-aloud protocol to verbalize every thought. They were asked to develop a VR serious game prototype by defining nine core design elements (educational objectives, educational artifact content, overall game worldview, player role; story line, interactive mechanics, visual mood, a low-fidelity prototype interface, and a brief design presentation) and to capture all AI dialogue, audio reports, and concept sketches [37]. TAP captures contemporaneous cognitive activity without interrupting workflow and has been shown to reliably reveal designers’ internal reasoning and strategy shifts during idea generation, evaluation, and revision [37]. Primary data included screenshots or screen recordings of the AI dialogue, audio recordings of verbal reports, and hand-drawn or AI-assisted concept sketches. An overview of the experimental setup and data types collected is shown in Figure 1a.
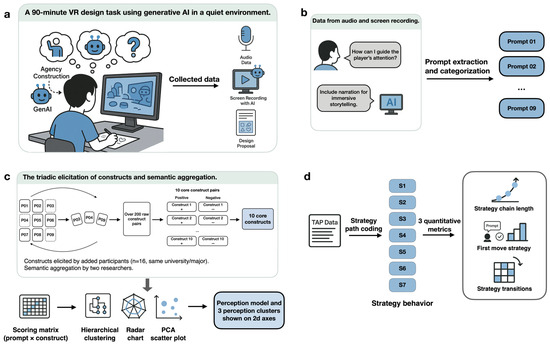
Figure 1.
Overview of the research design and analytical workflow. (a) Experimental context and data collection; (b) Prompt extraction and categorization; (c) RGT-based construct elicitation and perception modeling; (d) Strategy path coding and mapping.
3.1.2. Classification of Prompt Types and Their Cognitive Functions in Design
Two researchers (with backgrounds in design cognition or HCI and over three years of experience) extracted several hundred prompt instances from the forty-eight datasets. They then applied a three-step filtering process: (1) a two-round manual semantic screening, in which each researcher independently flagged obvious duplicates as well as generic or off-topic prompts, followed by a joint reconciliation session that merged overlapping items; (2) task-relevance checks, keeping only prompts that contained at least one domain-specific keyword such as “multisensory”, “interaction” or “role”; and (3) cross-validation, where a random 20% subsample was recoded independently and any remaining disagreements were resolved through discussion until full consensus was reached. Approximately 150 high-frequency prompts (appearing in five or more sessions) that exhibited distinct cognitive features were retained. Following grounded theory procedures (open, axial, and selective coding) [38], nine prompt categories were identified, each characterized by a distinct linguistic structure, cognitive trigger, and task function, forming the basic variables for subsequent construct analyses.
To ensure the reliability of the coding framework, a panel of seven experts (each with at least five years of experience in design thinking and cognitive research) conducted a review. The Content Validity Ratio (CVR) analysis produced a high S-CVI/Ave score of 0.94, demonstrating strong expert consensus and analytic robustness [39]. This expert panel was distinct from the later Delphi panel involved in construct validation to avoid any bias arising from overlapping reviewers. The prompt extraction and categorization workflow is shown in Figure 1b.
3.2. Constructing Perceived Agency
3.2.1. Experimental Procedure and Construct Elicitation
To address RQ2, the Repertory Grid Technique (RGT) [18] was employed to explore how different prompt types influence designers’ perceived control and GenAI role attribution. All sessions took place in a controlled lab setting. The experimental steps were as follows:
- (1)
- Element preparation
The nine prompt types identified in Stage 1 (P01 to P09) served as elicitation elements. Each prompt was printed on a separate card and arranged into randomized triads, ensuring that every prompt appeared in at least three unique combinations.
- (2)
- Triadic elicitation
Sixteen participants were newly recruited for this stage to provide fresh perspectives and avoid potential biases arising from prior exposure to the design task. All were first-year graduate students in product design at the same university, with comparable levels of VR design and GenAI experience to the initial cohort of 48 participants.
Using a participant-driven RGT approach, we facilitated the generation of 60 unique triads through dynamic participant assembly of prompt cards during sessions. Each participant created 3–5 triads from randomized prompt subsets, with algorithmic controls ensuring all prompts appeared in several triads for balanced representation while preventing duplicate combinations across participants. During 40 min sessions, participants completed their self-generated triads in random order, viewing three prompt cards per trial to select similar pairs and differing cards, then articulating bipolar constructs (e.g., “AI sets the direction” vs. “I set the direction”) through standardized prompts including the canonical RGT questions: “What makes these two similar?” and “How is the third different?” This ecologically valid process yielded 226 distinct construct pairs.
- (3)
- Coding and consolidation
All audio recordings and written responses were transcribed verbatim. Two researchers with expertise in design cognition independently performed open coding, applying the rule that each construct must represent a clearly defined cognitive contrast. They then conducted semantic clustering to merge synonymous constructs and removed duplicates. Interrater reliability was confirmed on a 20 percent subsample using Cohen’s kappa (kappa > 0.80). The final construct set comprised ten core agency related pairs, spanning two dimensions: perceived control (such as decision authority, information structuring, and pacing) and GenAI role attribution (such as tool or executor, partner, and mentor). The construct elicitation and modeling flow is shown in Figure 1c.
3.2.2. Construct Rating and Structural Analysis
All participants rated each prompt on the ten core constructs using a 7-point Likert scale (1 = strongly aligned with the negative pole, 7 = strongly aligned with the positive pole; e.g., 1 = “AI mainly directs creativity”, 7 = “I mainly direct creativity”). Mean ratings across the sixteen raters produced a Prompt × Construct matrix suitable for group-level analysis of latent perceptual patterns. These procedures are summarized in Figure 1c. Subsequent analyses comprised:
- (1)
- Principal Component Analysis (PCA) was conducted to reduce dimensionality and extract two primary dimensions of agency: perceived control and AI role construction;
- (2)
- Hierarchical clustering of the PCA scores was performed using Ward’s method and Euclidean distance to classify prompts into three perception profiles. Cluster stability was assessed by running k-means clustering with three clusters and examining average silhouette scores;
- (3)
- Radar charts were plotted for each profile, displaying average construct ratings on ten axes. These visualizations highlighted intra-profile variability and identified the constructs with the greatest discriminatory power between profiles;
- (4)
- Two-dimensional mapping of the first two principal components was used to visualize prompt positions and reinforce the interpretability of the clustering solution.
3.2.3. Strategy Path Coding and Analysis
- (1)
- Coding protocol
To examine how generative prompts guide designers’ strategy development under different agency perceptions, TAP transcripts were segmented into discrete episodes, each spanning from one prompt presentation to the next. First, each utterance was classified based on its primary intention, indicating whether the designer was setting constraints, accepting system suggestions or adjusting ideas, and on its orientation, grouped as leading, following or refining. Second, we distinguished whether the designer’s action targeted the GenAI output or their own thought process. Third, each strategy was anchored to a specific phase of the design workflow (context understanding, ideation, elaboration, verification) to maintain chronological coherence. Each utterance received a single strategy code reflecting its core function.
The coding proceeded in three iterative stages. In open coding, all transcriptions were reviewed to mark key semantic units related to shifts in strategy, control transfer, system interaction or thought interruption, ensuring we captured the full diversity of behaviors. Axial coding then grouped these units into preliminary categories based on shared cognitive features. Finally, selective coding abstracted the relationships among categories to establish seven distinct strategy types (S1 to S7). Two independent coders double-coded thirty percent of the data (twelve participants), yielding excellent agreement (Cohen’s kappa > 0.80). The lead coder then completed the remaining transcripts, with the second researcher auditing and refining the results, producing 321 validated strategy units in all. The coding and analysis process is visualized in Figure 1d.
- (2)
- Analytical indicators
Based on the coding results, we calculated three key quantitative metrics for each prompt cluster:
- Average path length was defined as the mean number of consecutive strategy steps within each prompt episode, reflecting the typical complexity of designers’ response chains.
- The first-move strategy was identified as the initial strategy code applied immediately after a prompt, capturing designers’ instant tactical choice.
- High-frequency bigrams were determined by counting the most common pairs of successive strategies (e.g., S1 to S4), thus highlighting which strategy shifts occur most often. To visualize these patterns across perception profiles, we constructed weighted strategy-transition matrices and displayed them as heat maps, enabling direct comparison of strategy evolution under tool-oriented, collaborative, and mentor-like conditions.
4. Results
Beginning with the classification of nine prompt types and their stage-specific patterns, we then explore how these types shape designers’ sense of control and AI role attribution, and finally reconstruct the distinct strategy paths each perception profile elicits.
4.1. Prompt Types and Stage-Specific Patterns
To address RQ1, we first classified novice designers’ prompts into functionally distinct types. Coding across all participants yielded nine representative prompt types (Table 1). These categories shape designers’ perceptions of control and their engagement with it throughout the interaction, revealing three recurrent agency patterns. The complete structural features and selected representative examples are provided in Supplementary Table S1. Additional representative prompts have been provided in Supplementary Table S2.

Table 1.
Prompt types and structural features.
Each prompt type has distinct linguistic structures and intended functions. P01 and P02 together comprised 61.5% of all prompt uses, indicating they dominate early phases. P05 and P06 accounted for 9.8% and peaked during concept elaboration, while P08 represented 17.7% and rose in the verification and iteration phase. Based on these usage patterns, three interaction modes emerge.
- (a)
- Active-control mode
Typical of the early phases, context comprehension and scene ideation, this mode is driven by P01 (information retrieval) and P02 (divergent ideation). Designers report a strong sense of self-direction when using these prompts. Participant U04 noted, “The prompt provides exactly the information I need without replacing my ideas; the design direction is entirely in my hands.” Similarly, U13 remarked, “AI offers many divergent ideas, but I decide what to keep or discard; the initiative always stays with me.” Such comments indicate that designers initially mobilize AI as a tool to reinforce self-efficacy and pacing control.
- (b)
- Passive-compliance mode
During concept elaboration, P05 (episodic narration) and P06 (role-driven synthesis) become dominant. Designers gradually cede initiative to the AI. U09 observed, “After several attempts to draft the storyline myself, I adopted the AI’s framework as my core plot.” U21 added, “The AI’s character design was more detailed than I expected, so I followed its suggestions for efficiency.” In complex tasks, designers thus transfer control to the AI, relying on its structured recommendations to advance the project.
- (c)
- Alternating co-creation mode
P08 (reflective co-creation) spans the entire workflow, including later verification–iteration stages, repeatedly prompting designers to reflect and revise. Control dynamically shifts: designers sometimes lead AI corrections, at other times accept AI suggestions. U17 stated, “The prompt raises critical questions that force me to pause and reflect, yet it never gives a direct answer, we move the design forward together.” U33 echoed, “The AI prompt frequently alters my thinking; sometimes I lead and ask AI to debug, sometimes I follow its advice. It feels like genuine co-creation.” This pattern highlights how prompts modulate designers’ agency in ongoing interaction.
4.2. Prompt-Related Agency Perceptions
4.2.1. Construct Elicitation and Consolidation
Building on RQ2, we then examined whether these prompt types elicit divergent perceptions of control and AI role. Triadic elicitation within the RGT produced 226 initial construct–contrast pairs. Using the semantic clustering and RGT’s bipolarity principle [18], two researchers merged semantically similar items. To ensure objectivity, a Delphi panel of three experts in GenAI-driven design, HCI, and design psychology (over five years’ experience each) conducted two independent review rounds, evaluating consistency, coverage, and representational accuracy. These experts did not overlap with the coding validation panel described earlier. Ten core constructs were retained (Table 2), with a mean expert approval rate of 92%.
Table 2.
Ten core constructs from RGT analysis describing control and AI role perceptions.
The final construct set comprehensively captured participants’ perceptions of human and AI leadership as well as AI role attribution during prompt use, forming the core variable framework for subsequent agency structure modelling. It reached semantic saturation with no new categories emerging, and demonstrated strong coverage and discriminant validity, ensuring a solid foundation for cognitive structure analysis.
4.2.2. Modelling Prompt Perception Structures from Construct Ratings
- (1)
- Principal component analysis
Sixteen participants rated nine representative prompts on the ten constructs using a 7-point scale (1 = negative pole, 7 = positive pole). PCA revealed that the first two components explained 81.78% of total variance (PC1 = 67.97%, PC2 = 13.81%), indicating strong explanatory power.
PC1 (Perceived Control) carried high positive loadings on C10 (creative leadership), C03 (pace sequencing), and C01 (information structuring), and high negative loadings on C08 (AI role recognition) and C09 (AI knowledge positioning), representing a continuum from designer-led to AI-led control. PC2 (AI role cognition) displayed strong negative loadings on C02 (AI proactivity), C08 (AI recognition), and C04 (sensory-interaction dominance), with modest positive loadings on C05 (idea filtering) and C07 (phase delineation), capturing the spectrum from AI-driven intervention to designer-controlled inspiration and staging.
- (2)
- Perceptual clustering of prompts
The Z-score-standardized rating matrix was projected into the PC1–PC2 space. Ward hierarchical clustering of PCA scores, validated by k-means (k = 3), yielded three stable clusters with an average silhouette score of 0.27 (>0.25 threshold), indicating acceptable separability (Figure 2).
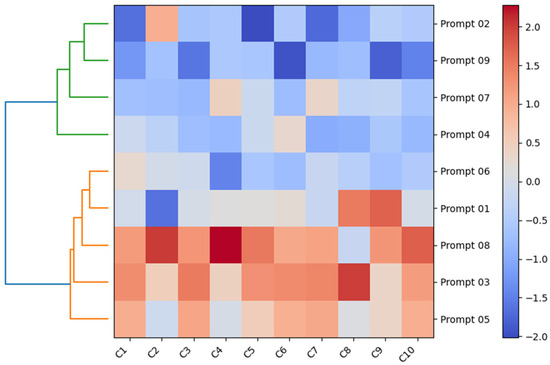
Figure 2.
Cluster heatmap showing construct ratings across 9 Prompts after z-score standardization.
Cluster C-A is tool-based, consisting solely of P01, which shows the warmest Z-scores on C1, C10, C6, and C3. This pattern reflects designers’ strong process ownership and their tendency to position AI as an auxiliary executor, ideal for early-stage divergence or detailed task refinement.
Cluster C-B represents a collaborative structure, including P02, P04, P06, P07, and P09, with the highest scores on C10 and C9, followed by C6 and C3. This indicates a partner-like interaction, where designers retain leadership while actively incorporating AI-generated suggestions, particularly suited to prototype development and mid-phase iteration.
Cluster C-C reflects a mentor-like structure, composed of P03, P05, and P08, and is characterized by the highest scores on C9, C8, and C10, with upper-mid values on C3. In this cluster, designers grant AI a high degree of proactivity, treating it as a cognitive scout that inspires new strategies, while still maintaining control over key pacing decisions. This approach is advantageous in exploratory and conceptual phases, though it may risk diminishing perceived agency if over-relied upon.
- (3)
- Construct-profile analysis and prompt-type differences
To complement the clustering results, a one-way ANOVA and within-cluster dispersion test were run on the ten construct ratings for the three clusters (radar chart summary in Figure 3).
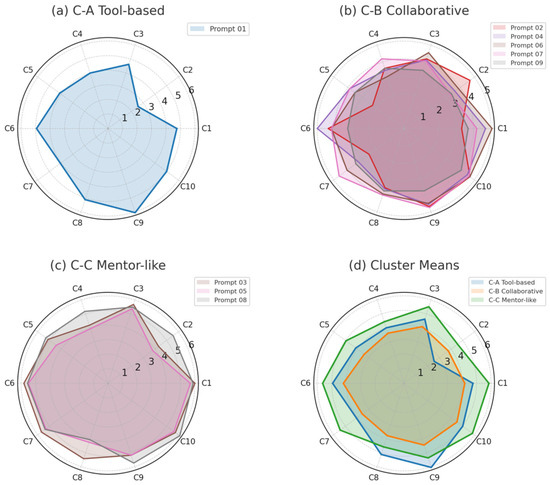
Figure 3.
Integrated radar plots comparing prompt perceptual structures across clusters.
Two constructs, C08 (AI role recognition) and C09 (AI knowledge anchoring), emerged as the principal discriminators of agency perception. ANOVA showed that these dimensions accounted for 41% and 36% of the total sum of squares, respectively, across prompt clusters. Box plots for C08 and C09 (Figure 4) further illustrate the distributional contrasts. On C08, the tool-based cluster (C-A) had a median of 6.0 (upper quartile 7.0); the collaborative cluster (C-B) a median of 4.0 (upper quartile 5.0); and the mentor-like cluster (C-C) a median of 4.5 (upper quartile 6.0). On C09, the tool-based cluster again centered at 6.0 (upper quartile 7.0), whereas both collaborative and mentor-like clusters centered at 5.0 (upper quartile 6.0), with collaborative prompts showing outliers at 2.0 and 4.0 and mentor-like prompts exhibiting greater scatter on C08.
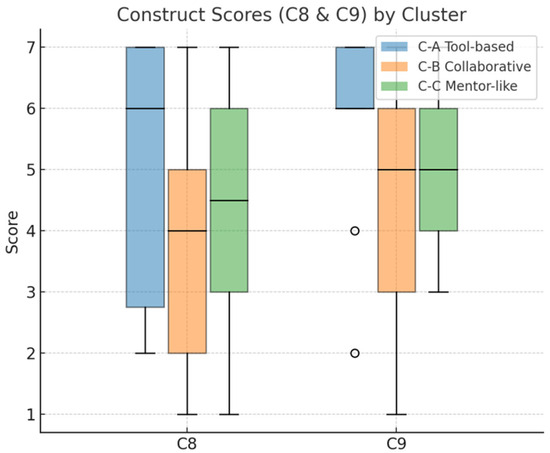
Figure 4.
Box plots of construct ratings (C08 and C09) across three prompt clusters.
Secondary variables C05 (control over idea filtering) and C07 (authority over narrative staging) highlighted the mentor-like cluster’s advantage in steering inspiration and process flow. Within-cluster variance was largest for collaborative prompts on C08 and C05 (≈0.18 and 0.14) and for mentor-like prompts on C02 (AI proactivity, ≈0.12), indicating residual disagreement among participants.
- (4)
- Perceptual mapping and cluster visualization
Using the combined results of PCA and k-means clustering, all nine prompts were plotted on the orthogonal axes of perceived control (PC1) and AI role cognition (PC2); average silhouette contours (mean 0.40) were overlaid to depict separability (Figure 5). Membership matched the hierarchical clustering heat map exactly, confirming stability.
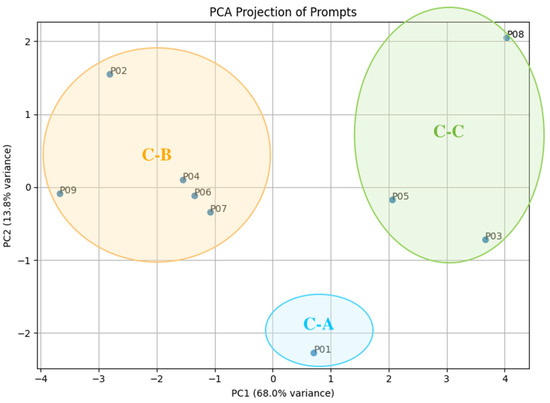
Figure 5.
Prompt distribution in PCA space defined by agency-related dimensions.
The tool-based prompt (cluster C-A, P01) lies in the upper-right quadrant (high PC1, slightly lower PC2), signaling high designer control and an “AI as executor” stance, ideal for early divergence and fine-grained refinement. The collaborative prompts (cluster C-B, P02, P04, P06, P07, P09) are located in the left-upper center of the plane (slightly negative PC1, neutral-to-positive PC2), where designers keep rhythm and content leadership yet welcome AI advice. This configuration is well suited to prototype development and mid-phase iteration. Mentor-like prompts (cluster C-C, P03, P05, P08) spread along the right side (positive PC1; PC2 descending). P03 sits highest on PC2, coupling enhanced control with strategic empowerment; P05 occupies the mid-range, reflecting weak guidance layered over designer leadership; P08 anchors the lower extreme, closest to a “designer leads, AI mentors” model.
4.3. Strategy Path Distributions Across Prompt Perception Clusters
In response to RQ3, we analyzed how different agency perceptions translate into strategic path differences. To determine whether the tripartite agency perception structure identified earlier produces measurable effects on design behavior, every TAP record was fully transcribed and systematically coded. Utterances reflecting task control, interaction with the GenAI system, and cognitive adjustment were extracted, yielding seven process strategy labels (Table 3). These labels were used to reconstruct prompt-specific strategy paths, showing how each agency profile steers designers toward distinct tactical choices. Aggregate frequencies and proportional distributions for the three prompt clusters appear in Figure 6. A weighted transition heat map (Figure 7) presents the flow frequencies among strategies for each prompt type. From 172 bigram transitions across all strategy nodes, three clusters emerged: C-A (N = 62), C-B (N = 78) and C-C (N = 32). A chi-square test confirmed significant differences in strategy distributions among prompt types (χ2 = 203.13, p < 0.001).
Table 3.
Strategy categories and definitions.
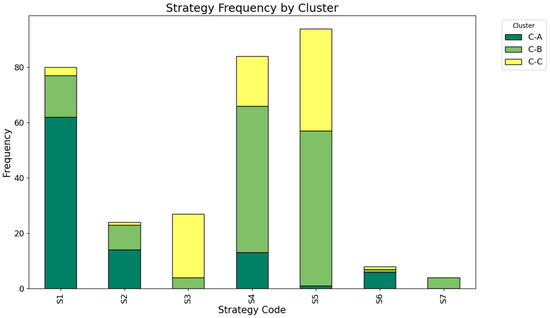
Figure 6.
Stacked bar chart of strategy frequencies by cluster.
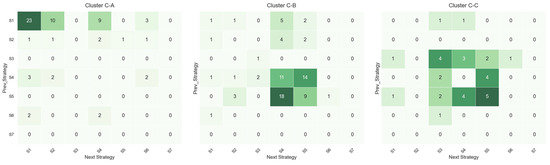
Figure 7.
Weighted strategy-transition matrices by prompt perception cluster.
- (1)
- C-A: Dominated by S1 (active control setting) self-loops and a linear constraint-to-refinement path
Paths in this cluster are compact (mean length ≈ 2.82). S1 is the first move in 97.1% of cases (S2, Accepting AI suggestions, in 2.9%). The most common transitions are S1→S1 (23) and S1→S2 (10), indicating that designers repeatedly impose explicit constraints and only occasionally adjust them locally. The prevailing agency stance is “I set, I refine”, trading exploratory breadth for efficiency and predictability.
- (2)
- C-B: Characterized by repeated S4 (wording and expression adjustment) ↔S5 (collaborative probing and dynamic tuning) cycles forming an inquiry-to-deepening loop
Average path length is 2.22, with S5 as the modal first move (nearly 50%), followed by S4, S1, and S2. The most frequent transitions, S5→S4 (18) and S4→S5 (14), depict an interactive deepening process. This cycling pattern serves as cognitive scaffolding: S4 refines language to elicit targeted outputs, while S5 probes for richer content. The moderate chain length and a higher branching index (≈15%) suggest designers balance control with openness to AI input, supporting iterative co-creation without overwhelming cognitive load.
- (3)
- C-C: Marked by frequent S5/S3 (reflection and reconstruction) self-loops, jumps, and multi-branch reconstruction
Paths here are the shortest (mean length ≈ 1.63), with S5 as the leading first move (>50%), followed by S3 and S4. High-frequency transitions include S5→S5 (5), S4→S5 (4) and S3→S3 (4). Designers oscillate rapidly between accepting suggestions (S5) and reflective reconstruction (S3), generating a diverge–leap–reflect dynamic. The high branching index (≈25%) and low mean path length point to a high-energy exploratory mode, but also reveal potential fragmentation of thought, indicating a trade-off between creative divergence and strategic coherence. For clarity and ease of comparison, Table 4 summarizes the main quantitative indicators of strategy path characteristics across the three prompt perception clusters.
Table 4.
Quantitative comparison of strategy path features across prompt perception clusters.
Ordered as tool oriented, collaborative, and mentor like, the clusters illustrate a developmental trajectory that begins with strict boundary control, progresses through reciprocal iterative engagement, and culminates in expansive divergent exploration.
5. Discussion
Interpreting these results in light of existing literature, we highlight key theoretical contributions, practical implications, and avenues for future study.
5.1. Key Findings
Drawing on novice designers’ cognitive traces, repertory grid ratings, and behavioral trajectories collected in an authentic VR heritage design task, the study yields four main findings. First, prompt types exhibit clear stage-specific distributions: tool-based prompts dominate the idea-generation phase and help maintain a sense of control; collaborative prompts span concept development and refinement, enabling iterative cycles of enquiry, response and reconstruction; mentor-like prompts emerge in evaluation and optimization, triggering divergent inspiration and solution diversity.
Second, prompts elicit a two-dimensional mental model composed of perceived control and AI role cognition. PCA and clustering show that tool-based prompts map onto a “designer-led, AI-executed” stance, collaborative prompts to “peer partnership”, and mentor-like prompts to “AI first, human filters”.
Third, the three prompt types steer designers toward distinct strategic patterns: tool-based prompts elicit dominant S1 (active control setting) self-loops with occasional S1→S2, accepting AI suggestions, local adjustments, reflecting a highly linear fine-tuning path; collaborative prompts revolve around reciprocal S4 (wording and expression adjustment) ↔ S5 (collaborative probing and dynamic tuning) cycles; and mentor-like prompts combine frequent S5/S3, reflection and reconstruction, loops with occasional jumps, supporting exploratory divergence.
Fourth, these patterns suggest a stage-wise prompt portfolio: tool-based prompts safeguard process control early on, collaborative prompts enhance mid-stage iteration, and mentor-like prompts activate late-stage creativity and variety, achieving a dynamic balance between efficiency and innovation.
5.2. Theoretical Implications
This study advances theory along four dimensions within a three-layer framework that connects prompt type, agency perception, and strategy path. First, earlier work often conceptualized intelligent tools through a binary lens of either instrument or agent [40]. By combining the repertory grid and the think-aloud protocol, the present research identifies three distinct mental models: controllable executor, peer collaborator, and scouting mentor. This typology enriches the existing taxonomy of human and machine roles in co-creation [22].
Second, while most prior studies focus on static prompt optimization [41], the current strategy path analysis proposes a dynamic schedule of upstream divergence, mid-stage collaboration, and downstream convergence. This demonstrates that prompt timing must shift in accordance with design phases to maintain a balance between efficiency and exploratory thinking, thereby contributing to the development of process-oriented prompt-engineering theory.
Third, although the field of design cognition has traditionally emphasized openness and closure in problem space navigation, it has paid limited attention to how designers experience control in technology-mediated environments [42,43]. By positioning perceived control and role attribution on orthogonal axes, this study reveals how these dimensions jointly shape design cognition. It further extends the coupling between self-efficacy and external agency and offers a quantitative framework for studying psychological empowerment in AI supported design contexts.
Finally, whereas conventional models typically describe design cognition as a linear process [44], the introduction of prompt-driven bigram paths highlights multiple cognitive trigger patterns enabled by generative systems. This provides a methodological foundation for examining how path structures relate to creative performance and design outcomes.
Cluster morphology analysis adds finer granularity to these theoretical contributions. Tool-based prompts form a compact grouping with minimal within-cluster variance, reflecting consensus in strong process control; collaborative prompts show moderate dispersion, indicating varied preferences for balancing leadership with AI input; mentor-like prompts stretch along the AI role cognition axis, revealing heterogeneous trust in the system’s proactivity as a mentor. Inter-centroid distances confirm clear separations, and their overall L-shaped layout, from collaborative through tool-based to mentor-like, suggests that designers typically adjust their sense of control before recalibrating role expectations.
Taken together, these developmental patterns validate the agency-construction framework: prompt-driven agency perceptions influence not only the selection of tactics but also the sequencing and intensity of cognitive operations. Designers move from strict boundary control, through reciprocal engagement, to expansive divergent exploration, underscoring the importance of stage-adaptive prompt deployment for optimizing cognitive engagement and creative outcomes.
It is worth noting that not all designers adhere strictly to this stage-wise progression; individual differences, prior experience, and task context may lead some to diverge early or maintain a linear approach throughout. This variability underscores the framework’s role as a flexible guide rather than a prescriptive sequence, and suggests that adaptive prompt scheduling should accommodate user-specific interaction patterns.
5.3. Practical Implications
Building on our construct and cluster insights, this study offers a tailored, phase-aligned roadmap specifically for VR heritage serious game development, which differs from general VR or AI-assisted design by emphasizing cultural storytelling, educational goals and multi-sensory engagement in heritage contexts. Unlike generic VR workflows, this roadmap integrates heritage-specific objectives such as artifact interpretation, narrative authenticity and cultural sensitivity into each prompt stage.
First, tool-based prompts are best paired with heritage-themed templates or modular combinations (for example, tile-production scenarios or period style narrations) so that designers can reinforce procedural control and ensure fidelity to historical context. Second, collaborative prompts call for clear ground rules on AI involvement, such as specifying when to request contextual explanations versus stylistic embellishments, together with transparent relevance checks that balance cultural accuracy and creative exploration. Third, a mentor-like prompting context benefits from calibrated AI proactivity thresholds (for example, limiting generative leaps to avoid anachronisms) and the insertion of interaction checkpoints, including expert review prompts, to prevent over-delegation and preserve the designer’ s sense of agency.
Beyond these cluster-based recommendations, design schools and professional programs can integrate this heritage focused prompt framework into curricula, using case studies drawn from museum collections or historic sites to train students in both technical and cultural competencies. Cultural experience producers and heritage institutions may embed these strategies in digital heritage toolkits, ensuring that VR heritage serious games deliver immersive learning while maintaining historical integrity. Finally, developers of generative AI platforms should provide heritage aware default settings, including period appropriate language models and sensory feedback presets, to accelerate adoption and safeguard against cultural misrepresentations.
5.4. Limitations and Future Work
This study has several limitations that suggest directions for future research. First, we recruited a homogeneous sample of 48 novice design students from a single university to reduce variability in prior training and strengthen internal validity; we also employed a uniform cultural heritage VR design task to isolate the effects of prompt type on design processes and avoid confounds from varied task contexts. However, this approach limits the generalizability of our findings. Future work should validate the proposed framework with expert practitioners, designers from diverse disciplines (e.g., industrial, graphic, service, interaction design), cross-cultural samples, and across multiple product and task types.
Second, data were collected via verbal think-aloud protocols in a single session. While these methods captured real-time cognitive strategies, they may overlook nonverbal and physiological signals; integrating eye tracking, neurophysiological measures (e.g., EEG, galvanic skin response), behavioral logs, and follow-up interviews, as well as conducting longitudinal studies across multiple real-world projects, would better capture nonverbal cognition and reveal how prompt strategies evolve over time.
Third, the analysis focused solely on text-based prompts delivered through one generative AI system. Exploring other modalities, including voice-activated, gesture-based, and image-driven prompts, and testing across multiple GenAI platforms (e.g., diffusion models, voice assistants) and device form factors (e.g., AR headsets, haptic feedback) could evaluate the robustness of our framework in richer, multisensory environments.
Lastly, while the study mapped cognitive rhythms and strategy patterns, it did not directly assess design outcomes or user experiences. Future research should link stage-specific prompts to objective design quality measures (e.g., expert ratings of creativity and usability), learning outcomes, and end-user experience metrics (e.g., immersion, satisfaction), to elucidate the practical value and optimize the prompt-engineering framework.
6. Conclusions
Within the context of VR serious games for cultural heritage, this study combines TAP trajectories and RGT ratings to demonstrate how prompt type shapes designers’ strategy paths via a dual axis perception structure of perceived control and AI role cognition, enabling dynamic shifts among linear, cyclic, and divergent mechanisms. Stage-specific prompt scheduling effectively balances efficiency and creativity across the design timeline. Our mixed methods approach highlights the value of integrating behavioral trace analysis with construct elicitation to uncover hidden cognitive patterns in human–AI co-creation, and underscores prompt engineering as a key lever for adaptive collaboration. The contributions are:
- (1)
- a triadic perception model comprising controllable executor, equal partner, and scouting mentor that links role attribution to process structure;
- (2)
- an empirically grounded prompt portfolio framework organized in stages that shifts engineering from static optimization to dynamic, process-oriented guidance;
- (3)
- practical implications for VR heritage design, generative AI platforms, and design education in enhancing collaborative efficiency and creative depth.
Beyond heritage applications, the framework provides a template for adaptive prompt design in diverse creative domains such as commercial product design, interactive media, and service innovation, guiding development of intelligent assistants that respond to users’ evolving agency needs. Future studies should evaluate the model with professional designers, incorporate multimodal interaction channels, and test across culturally varied projects, while measuring long term impacts on design performance and user satisfaction. Longitudinal field studies and real-time physiological measures could further elucidate how prompt-induced agency fluctuations influence cognitive load and creative outcomes.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/systems13070576/s1, Table S1: Prompt type, complete structural features and representative examples; Table S2: Additional representative prompt examples.
Author Contributions
Conceptualization, C.J.; Methodology, C.J.; Investigation, C.J. and S.H.; Writing—original draft preparation, C.J.; Writing-review and editing, C.J. and T.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Shanghai Art and Science Planning Research Project [Grant No. YB2024-G-069], and the Fundamental Research Funds for the Central Universities [Grant No. 2232023E-06 and 2232024D-42]. Additionally, as a phased result of the second phase of Beijing Palace Museum’s Open Research Project, this study received funding from the Longfor-Palace Museum Cultural Foundation and Beijing Palace Museum Cultural Protection Foundation.
Data Availability Statement
The data are not publicly available due to participant privacy.
Acknowledgments
The authors gratefully acknowledge all participants in the experiments and evaluations, whose time and insights were instrumental to this study.
Conflicts of Interest
No potential conflict of interest was reported by the authors.
References
- Lee, B.C.; Chung, J. An empirical investigation of the impact of ChatGPT on creativity. Nat. Hum. Behav. 2024, 8, 1906–1914. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Pang, H.; Wallace, M.P.; Wang, Q.; Chen, W. Learners’ perceived AI presences in AI-supported language learning: A study of AI as a humanized agent from community of inquiry. Comput. Assist. Lang. Learn. 2024, 37, 814–840. [Google Scholar] [CrossRef]
- Shi, M.; Seo, J.; Cha, S.H.; Xiao, B.; Chi, H.-L. Generative AI-powered architectural exterior conceptual design based on the design intent. J. Comput. Des. Eng. 2024, 11, 125–142. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Lei, S.; Wu, F.; Gao, X. The impact of metacognitive scaffolding on deep learning in a GenAI-supported learning environment. Interact. Learn. Environ. 2025, 1–18. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X.; Zhou, J.; Shou, Y.; Yin, Y.; Chai, C. Cognitive styles and design performances in conceptual design collaboration with GenAI. Int. J. Technol. Des. Educ. 2024, 35, 1169–1202. [Google Scholar] [CrossRef]
- Yan, L.; Greiff, S.; Teuber, Z.; Gašević, D. Promises and challenges of generative artificial intelligence for human learning. Nat. Hum. Behav. 2024, 8, 1839–1850. [Google Scholar] [CrossRef]
- Doshi, A.R.; Hauser, O.P. Generative AI enhances individual creativity but reduces the collective diversity of novel content. Sci. Adv. 2024, 10, eadn5290. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Cao, H.; Lin, L.; Hou, Y.; Zhu, R.; Ali, A.E. User Experience Design Professionals’ Perceptions of Generative Artificial Intelligence. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; Association for Computing Machinery: New York, NY, USA, 2024; p. 381. [Google Scholar]
- Wu, C.-H.; Chien, Y.-C.; Chou, M.-T.; Huang, Y.-M. Integrating computational thinking, game design, and design thinking: A scoping review on trends, applications, and implications for education. Humanit. Soc. Sci. Commun. 2025, 12, 163. [Google Scholar] [CrossRef]
- Mahdavi Goloujeh, A.; Sullivan, A.; Magerko, B. Is It AI or Is It Me? Understanding Users’ Prompt Journey with Text-to-Image Generative AI Tools. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; Association for Computing Machinery: New York, NY, USA, 2024; p. 183. [Google Scholar]
- Liu, Z.; Chen, D.; Zhang, C.; Yao, J. Design of a virtual reality serious game for experiencing the colors of Dunhuang frescoes. Herit. Sci. 2024, 12, 370. [Google Scholar] [CrossRef]
- Floridi, L. AI as Agency Without Intelligence: On ChatGPT, Large Language Models, and Other Generative Models. Philos. Technol. 2023, 36, 15. [Google Scholar] [CrossRef]
- Lee, S.-y.; Matthew, L.; Hoffman, G. When and How to Use AI in the Design Process? Implications for Human-AI Design Collaboration. Int. J. Hum.–Comput. Interact. 2025, 41, 1569–1584. [Google Scholar] [CrossRef]
- Shneiderman, B. Human-Centered Artificial Intelligence: Reliable, Safe & Trustworthy. Int. J. Hum.–Comput. Interact. 2020, 36, 495–504. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Park, S.; Yao, Y. Mental Models of Generative AI Chatbot Ecosystems. In Proceedings of the 30th International Conference on Intelligent User Interfaces, Cagliari, Italy, 24–27 March 2025; Association for Computing Machinery: New York, NY, USA, 2025; pp. 1016–1031. [Google Scholar]
- Oppenlaender, J. A taxonomy of prompt modifiers for text-to-image generation. Behav. Inf. Technol. 2024, 43, 3763–3776. [Google Scholar] [CrossRef]
- Noushad, B.; Van Gerven, P.W.; De Bruin, A.B. Twelve tips for applying the think-aloud method to capture cognitive processes. Med. Teach. 2024, 46, 892–897. [Google Scholar] [CrossRef] [PubMed]
- Prohl-Schwenke, K.; Kleinaltenkamp, M. How business customers judge customer success management. Ind. Mark. Manag. 2021, 96, 197–212. [Google Scholar] [CrossRef]
- Urban, M.; Děchtěrenko, F.; Lukavský, J.; Hrabalová, V.; Svacha, F.; Brom, C.; Urban, K. ChatGPT improves creative problem-solving performance in university students: An experimental study. Comput. Educ. 2024, 215, 105031. [Google Scholar] [CrossRef]
- Wang, H.; Wu, W.; Dou, Z.; He, L.; Yang, L. Performance and exploration of ChatGPT in medical examination, records and education in Chinese: Pave the way for medical AI. Int. J. Med. Inform. 2023, 177, 105173. [Google Scholar] [CrossRef] [PubMed]
- Saritepeci, M.; Yildiz Durak, H. Effectiveness of artificial intelligence integration in design-based learning on design thinking mindset, creative and reflective thinking skills: An experimental study. Educ. Inf. Technol. 2024, 29, 25175–25209. [Google Scholar] [CrossRef]
- Han, Y.; Qiu, Z.; Cheng, J.; LC, R. When Teams Embrace AI: Human Collaboration Strategies in Generative Prompting in a Creative Design Task. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; Association for Computing Machinery: New York, NY, USA, 2024; p. 176. [Google Scholar]
- Fui-Hoon Nah, F.; Zheng, R.; Cai, J.; Siau, K.; Chen, L. Generative AI and ChatGPT: Applications, challenges, and AI-human collaboration. J. Inf. Technol. Case Appl. Res. 2023, 25, 277–304. [Google Scholar] [CrossRef]
- Pataranutaporn, P.; Liu, R.; Finn, E.; Maes, P. Influencing human–AI interaction by priming beliefs about AI can increase perceived trustworthiness, empathy and effectiveness. Nat. Mach. Intell. 2023, 5, 1076–1086. [Google Scholar] [CrossRef]
- Wen, W.; Imamizu, H. The sense of agency in perception, behaviour and human–machine interactions. Nat. Rev. Psychol. 2022, 1, 211–222. [Google Scholar] [CrossRef]
- Wu, S.; Liu, Y.; Ruan, M.; Chen, S.; Xie, X.-Y. Human-generative AI collaboration enhances task performance but undermines human’s intrinsic motivation. Sci. Rep. 2025, 15, 15105. [Google Scholar] [CrossRef]
- Nguyen, Q.N.; Sidorova, A.; Torres, R. User interactions with chatbot interfaces vs. Menu-based interfaces: An empirical study. Comput. Hum. Behav. 2022, 128, 107093. [Google Scholar] [CrossRef]
- Clark, A. Extending Minds with Generative AI. Nat. Commun. 2025, 16, 4627. [Google Scholar] [CrossRef] [PubMed]
- Oppenlaender, J.; Linder, R.; Silvennoinen, J. Prompting AI art: An investigation into the creative skill of prompt engineering. Int. J. Hum.–Comput. Interact. 2024, 1–23. [Google Scholar] [CrossRef]
- Earle, S.; Parajuli, S.; Banburski-Fahey, A. DreamGarden: A Designer Assistant for Growing Games from a Single Prompt. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 26 April–1 May 2025; Association for Computing Machinery: New York, NY, USA, 2025; p. 57. [Google Scholar]
- Jiang, L.; Li, J.; Wider, W.; Tanucan, J.C.M.; Lobo, J.; Fauzi, M.A.; Hidayat, H.; Zou, R. A bibliometric insight into immersive technologies for cultural heritage preservation. NPJ Herit. Sci. 2025, 13, 126. [Google Scholar] [CrossRef]
- Zhao, F.; Ren, H.; Sun, K.; Zhu, X. GAN-based heterogeneous network for ancient mural restoration. Herit. Sci. 2024, 12, 418. [Google Scholar] [CrossRef]
- Yu, J.; Wang, Z.; Cao, Y.; Cui, H.; Zeng, W. Centennial Drama Reimagined: An Immersive Experience of Intangible Cultural Heritage through Contextual Storytelling in Virtual Reality. J. Comput. Cult. Herit. 2025, 18, 11. [Google Scholar] [CrossRef]
- Ribeiro, M.; Santos, J.; Lobo, J.; Araújo, S.; Magalhães, L.; Adão, T. VR, AR, gamification and AI towards the next generation of systems supporting cultural heritage: Addressing challenges of a museum context. In Proceedings of the 29th International ACM Conference on 3D Web Technology, Guimarães, Portugal, 25–27 September 2024; Association for Computing Machinery: New York, NY, USA, 2024; p. 9. [Google Scholar]
- Korzynski, P.; Mazurek, G.; Krzypkowska, P.; Kurasinski, A. Artificial intelligence prompt engineering as a new digital competence: Analysis of generative AI technologies such as ChatGPT. Entrep. Bus. Econ. Rev. 2023, 11, 25–37. [Google Scholar] [CrossRef]
- Yang, H.; Markauskaite, L. Fostering Language Student Teachers’ Transformative Agency for Embracing GenAI: A Formative Intervention. Teach. Teach. Educ. 2025, 159, 104980. [Google Scholar] [CrossRef]
- Wolcott, M.D.; Lobczowski, N.G. Using cognitive interviews and think-aloud protocols to understand thought processes. Curr. Pharm. Teach. Learn. 2021, 13, 181–188. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.-X.; Cheng, J.-W.; Philbin, S.P.; Ballesteros-Perez, P.; Skitmore, M.; Wang, G. Influencing factors of urban innovation and development: A grounded theory analysis. Environ. Dev. Sustain. 2023, 25, 2079–2104. [Google Scholar] [CrossRef]
- Ayre, C.; Scally, A.J. Critical values for Lawshe’s content validity ratio: Revisiting the original methods of calculation. Meas. Eval. Couns. Dev. 2014, 47, 79–86. [Google Scholar] [CrossRef]
- Krakowski, S. Human-AI agency in the age of generative AI. Inf. Organ. 2025, 35, 100560. [Google Scholar] [CrossRef]
- Knoth, N.; Tolzin, A.; Janson, A.; Leimeister, J.M. AI literacy and its implications for prompt engineering strategies. Comput. Educ. Artif. Intell. 2024, 6, 100225. [Google Scholar] [CrossRef]
- Sharples, M. Towards social generative AI for education: Theory, practices and ethics. Learn. Res. Pract. 2023, 9, 159–167. [Google Scholar] [CrossRef]
- Xie, X. The Cognitive Process of Creative Design: A Perspective of Divergent Thinking. Think. Skills Creat. 2023, 48, 101266. [Google Scholar] [CrossRef]
- Silk, E.M.; Rechkemmer, A.E.; Daly, S.R.; Jablokow, K.W.; McKilligan, S. Problem framing and cognitive style: Impacts on design ideation perceptions. Des. Stud. 2021, 74, 101015. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).