


Spatiotemporal Hybrid Air Pollution Early Warning System of Urban Agglomeration Based on Adaptive Feature Extraction and Hesitant Fuzzy Cognitive Maps

Abstract
1. Introduction
- (1)
- Although the hybrid model can serve the purpose of the problem well by combining specific methods, there are still some disadvantages. Most of the current hybrid models only focus on extracting data features through the decomposition of time series, which greatly improves the fitting effect of data but ignores the potential risk of information leakage in the decomposition process [28]. Therefore, the data preprocessing method needs to be further improved.
- (2)
- In the past, the study of air pollution was based on the division of administrative regions, and the effects of meteorology and time were analyzed separately. However, air pollution is a cross-regional environmental pollution problem, and the spatial spillover effect between urban agglomerations cannot be ignored [29].
- (3)
- Traditional single models cannot achieve high accuracy requirements, while hybrid models can improve forecasting accuracy.
- (4)
- The study of time series data only focuses on the order of time and ignores the particularities of the air quality data itself, such as the ambiguity and uncertainty of the data.
- Spatial spillover effects are considered the main factors affecting the air quality index (AQI) of different cities. It verifies that the spatiotemporal correlation of the extracted data is necessary to improve the accuracy of air pollution forecasting.
- The Hampel filter algorithm optimized by the squirrel search algorithm is innovatively introduced into the air quality forecasting model to process and correct the data outliers to improve the forecasting accuracy of the hybrid model.
- Hesitant fuzzy cognitive maps are first proposed to forecast air pollution. It can effectively solve the gray information of air quality or fuzzy relationships and uncertainties, thus further improving the accuracy of forecasting.
- The proposed model was comprehensively evaluated with the actual AQI dataset, five model evaluation criteria, and thirteen comparative models collected from the Beijing-Tianjin-Hebei region. The empirical results show that the proposed hybrid method has superior forecasting performance compared with the comparison models and can provide a theoretical basis for air pollution forecasting and early warning.
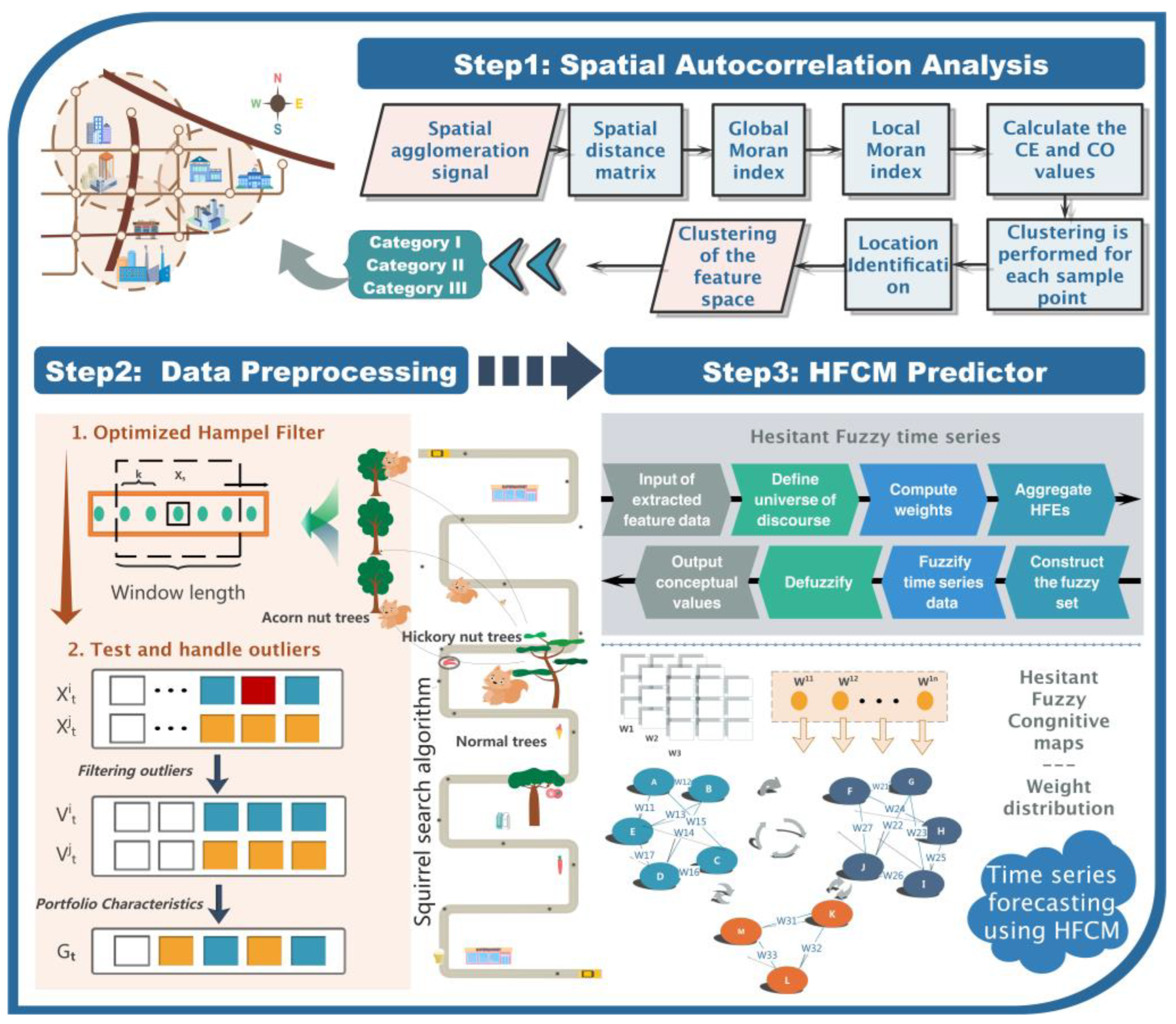
2. Design of Spatiotemporal Hybrid Air Pollution Early Warning System
2.1. Spatial Correlation Analysis Module
2.1.1. Moran Index
2.1.2. Local Gravitational Clustering
2.2. Data Preprocessing Module
2.2.1. Squirrel Search Algorithm
2.2.2. Hampel Filter
2.3. Fuzzy Information Forecasting Module
2.3.1. The Basic Definition of Hesitant Fuzzy Theory
2.3.2. The FCM Framework
2.3.3. Hesitant Fuzzy Processing Time Series
- Step 1: Define the universe of discourse and divide the interval.
- Step 2: Calculate membership degree.
- Step 3: Build fuzzy relationship matrix.
- Step 4: Defuzzify
| Algorithm 1: HFCM | ||||
| Objective function: min (MAPE) = | ||||
| Input: —a sequence of sample data. —a sequence of FCM output Output: | ||||
| Parameters: ip: number of the intervals i: i-th sample j: : the left endpoint of the adaptive division interval : the right endpoint of the adaptive division interval : the left endpoint of the equal frequency division interval : the right endpoint of the equal frequency division interval : the membership degree of the adaptive division interval : the membership degree of the equal frequency division interval nn: min number of the intervals mm: max number of the intervals | ||||
| 1: | /* Initialize the data and convert it into growth rate */ | |||
| 2: | /* Define the universe of discourse */ | |||
| 3: | FOR ip = nn: mm (number of the intervals); N = ip; | |||
| 4: | /* Calculate by cumulative distribution function. (Equation (26)) */ | |||
| 5: | /* Calculate by fuzzy c-means clustering (Equation (27)) */ | |||
| 6: | /* Calculate the weights of different intervals */ | |||
| 7: | ; | |||
| 8: | ||||
| 9: | /* Calculate */ | |||
| 10: | Calculate: Membership grades ; | |||
| 11: | /* Judgment fuzzy sets */ | |||
| 12: | IF is fuzzy set corresponding to | |||
| 13: | Assign fuzzy set to | |||
| 14: | END | |||
| 15: | IF is fuzzy production of day n, and is fuzzy production of day n + 1 | |||
| 16: | ||||
| 17: | END | |||
| 18: | /* Determine the fuzzy logic relation group */ | |||
| 19: | /* Count the frequency of each logical relationship */ | |||
| 20: | /* Calculate the percentage rate of each occurrence logic */ | |||
| 21: | /* Calculate the weight matrix and normalize the weight. */ | |||
| 22: | Calculate: ; | |||
| 23: | /* The maximum membership principle determines the fuzzy set to which it belongs. */ | |||
| 24: | Calculate: ; | |||
| 25: | /* Defuzzification to obtain the predicted value */ | |||
| 26: | /* Turning growth rates into data */ | |||
| 27: | END | |||
| 28: | ||||
| 29: | Returned: r (The location of the optimal concept) | |||
2.4. Error Evaluation Module
2.4.1. Error Test
2.4.2. Hypothesis Testing
3. Results
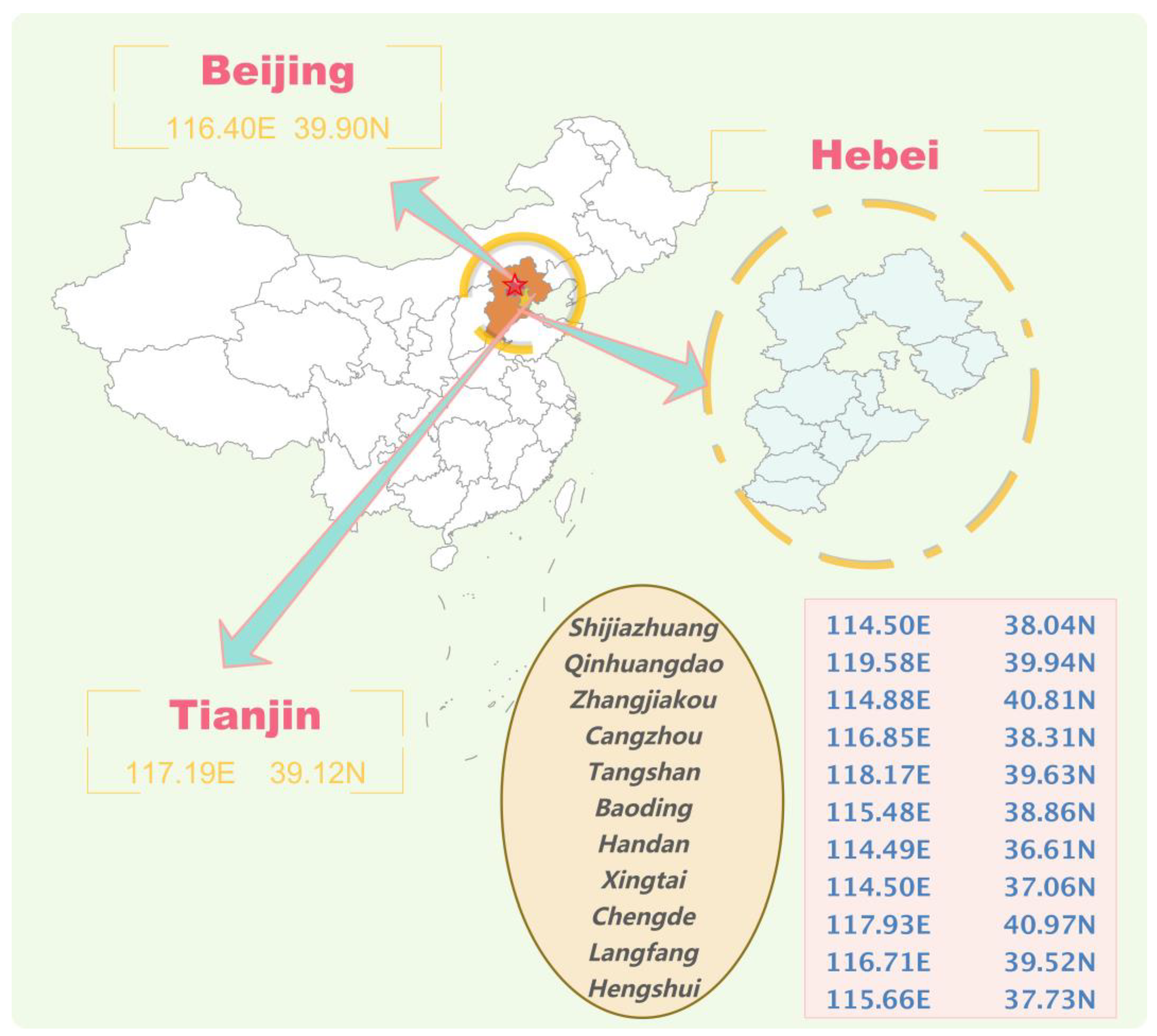
3.1. Study Area and Data Description
3.2. Spatial Feature Extraction Results
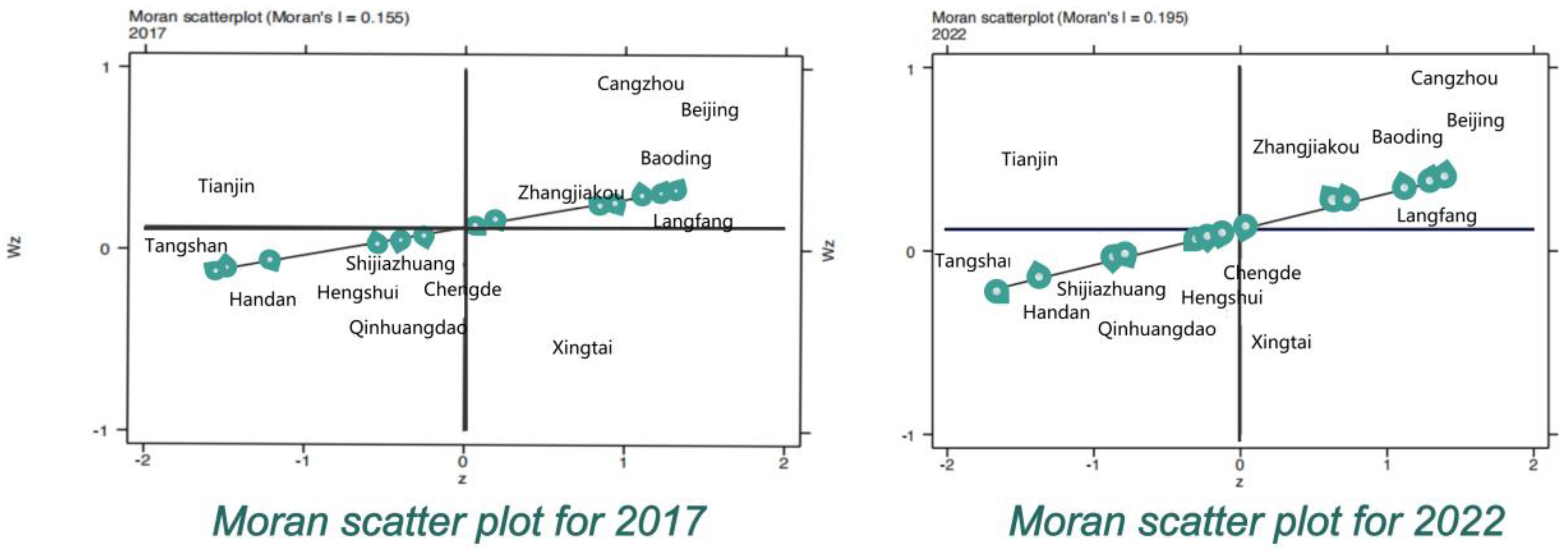
3.2.1. Spatial Autocorrelation
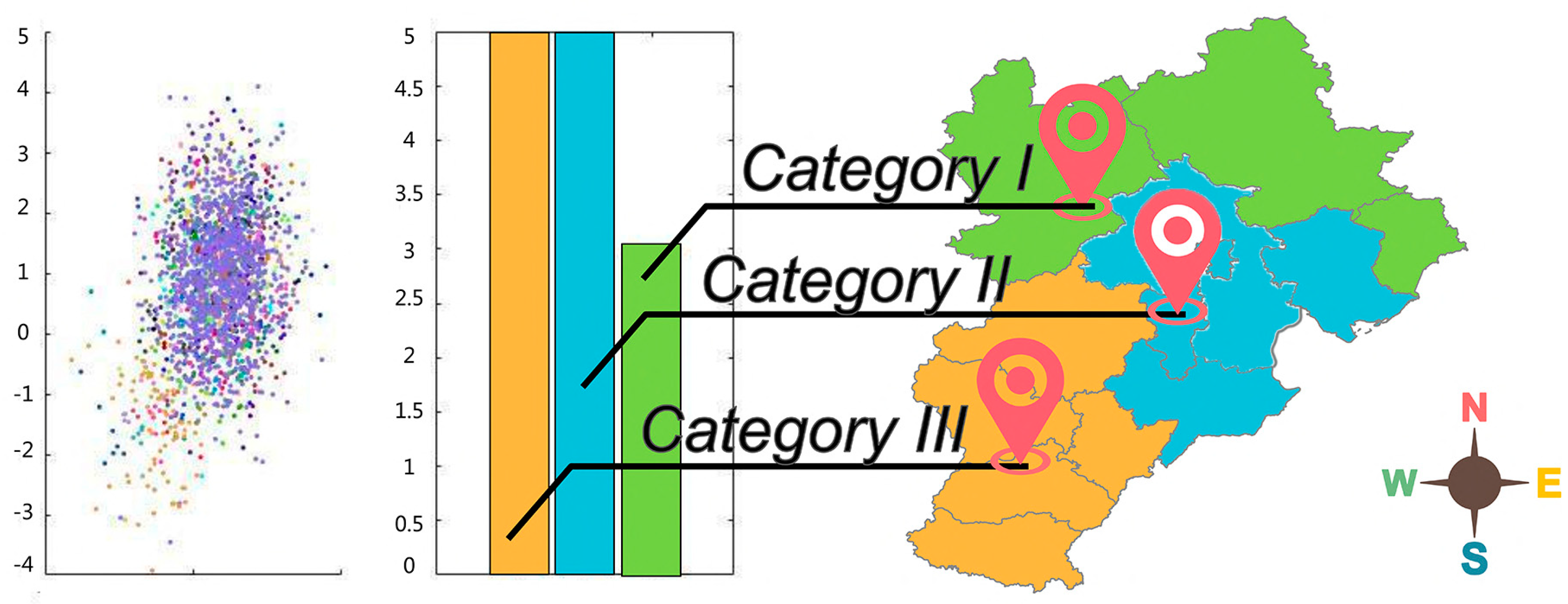
3.2.2. Local Gravitational Clustering
3.3. Model Comparison Results
3.3.1. Feature Extraction Strategy
3.3.2. Probabilistic Hesitation Fuzzy Set Strategy
3.3.3. Comparison of Mixed Models in Different Data Preprocessing Environments
4. Discussion
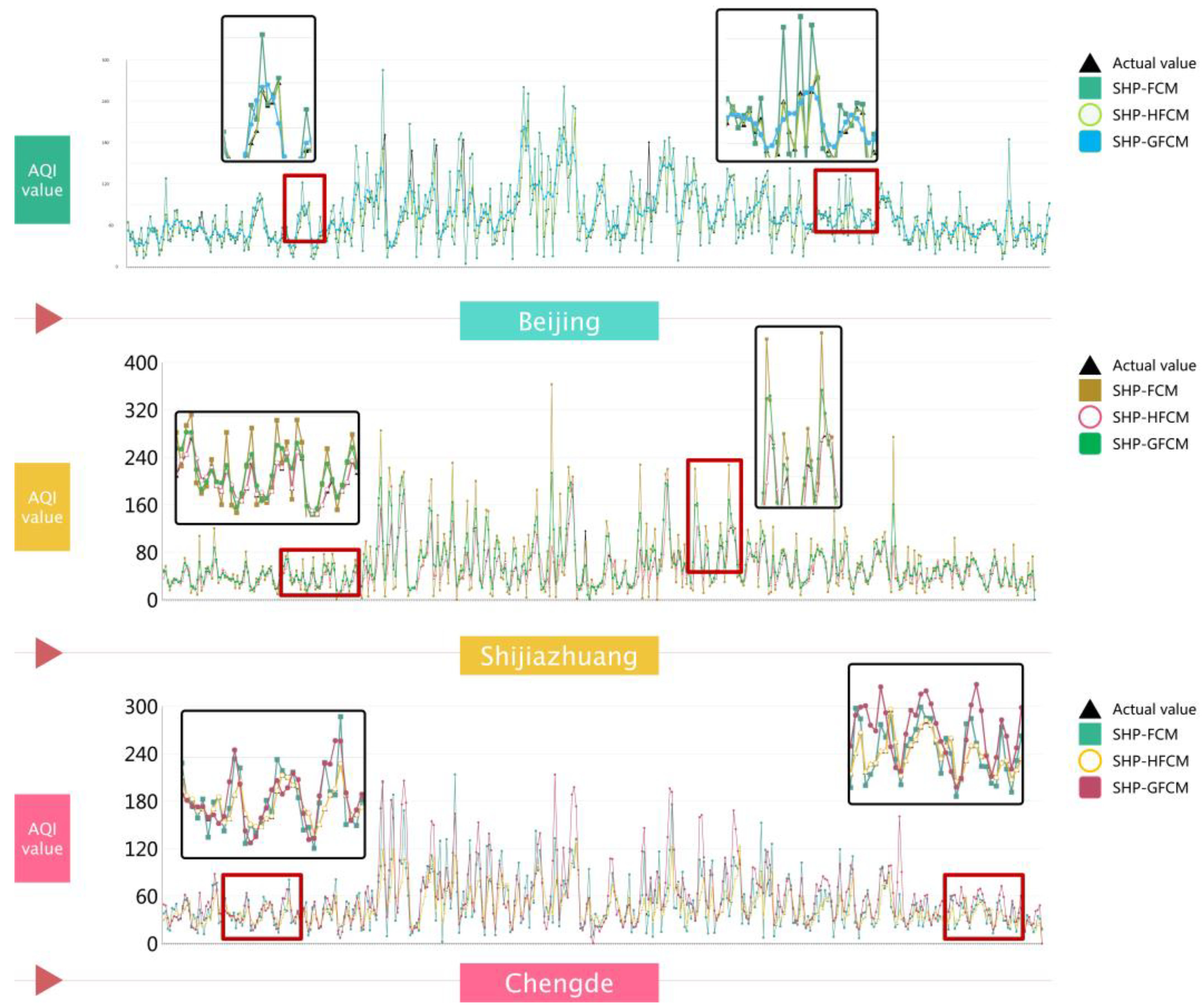
4.1. Robustness of the Proposed Model
4.2. Differences of the Proposed Model
4.3. Application of the Proposed Model
- Air pollution has spatial spillover effects, so the spatial feature analysis module can comprehensively consider the interaction of urban agglomerations. In addition, it also provides theoretical support for the formulation of pollution control policies among urban agglomerations and facilitates coordinated governance among urban agglomerations.
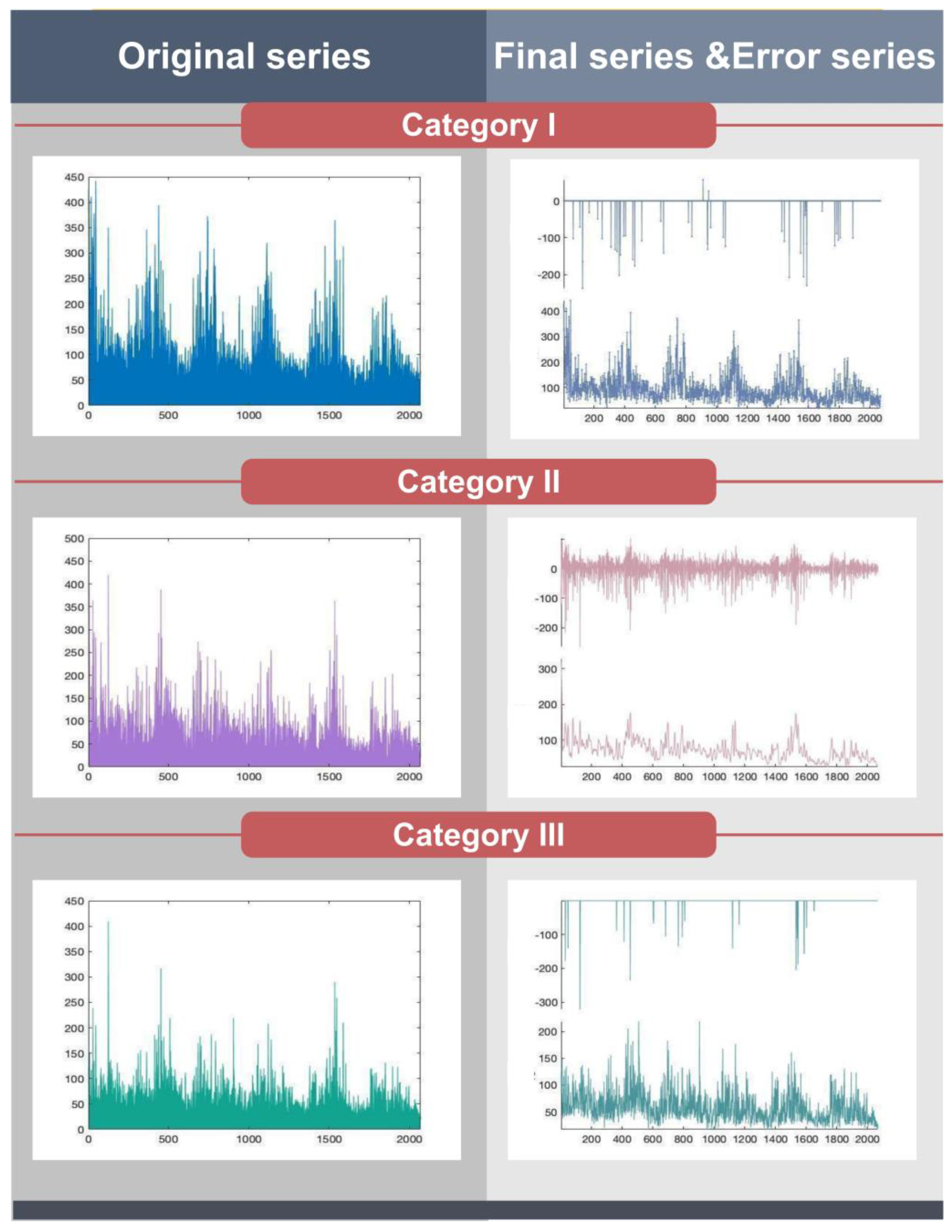
- In fact, air quality is affected by many factors, including information ambiguity and uncertainty. Through the data preprocessing module, it can remove the outliers and noise from the data, making the data features more obvious and achieving better forecasting performance.
- Accurate AQI forecasting results can provide early warning information for actual life and production activities. From the perspective of the public, the forecasting of air quality can let the public understand the air quality, the scope of air quality dete-rioration, the degree of deterioration, and the development trend; secondly, it guides the daily activities and behaviors of residents, protects the physical and mental health of the people, and reduces the incidence of diseases. From the perspective of social economy, it can not only provide the theoretical basis for pollution control measures, such as strict control of motor vehicle pollution, reduction of coal consumption, shut-down of polluting enterprises, control of construction sites and road dust, and super-vision of factories with large pollutant emissions.
5. Conclusions
- First, the spatial feature extraction module is built. The module successfully extracted the spatial overflow features, captured the dynamic transition of air quality, and per-formed cluster analysis with different sizes and weights for irregular data.
- The adaptive Hampel filtering model improved by SSA is the best data processing sub-module for comparison with FCM, DHP-FCM, and HHP-FCM.
- The first proposed HFCM forecasting model plays an irreplaceable role in time series forecasting in the same data preprocessing environment. The model reduced MAPE by 94.1083%, 96.9120%, and 98.2361% for three different urban clusters.
- In the environment of different data preprocessing methods, the model proposed in this paper can still make accurate forecasts for data with large fluctuations and mu-tations. MAPE, RMSE, and MAE reach the minimum values in the three urban ag-glomerations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| AR | Auto-regressive model |
| ANN | Artificial neural network |
| API | Air pollution index |
| AQI | Air quality index |
| ARMA | Auto-regressive moving average model |
| CDF | Cumulative distribution function |
| CE | Centrality |
| CO | Coordination |
| DA | Dragonfly algorithm |
| DM | Diebold–Mariano |
| FCM | Fuzzy cognitive maps |
| FLG | Fuzzy logic group |
| FLR | Fuzzy logic relation |
| FTS | Fuzzy time series |
| HBA | Honey badger algorithm |
| HFCM | Hesitant fuzzy cognitive maps |
| LGC | Local gravitational clustering |
| LRF | Local resultant force |
| MA | Moving average model |
| MAD | Median absolute difference |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| MDM | Modified Diebold–Mariano |
| RF | Random foresting |
| RMSE | Root mean square error |
| RNN | Recurrent neural network |
| SSA | Squirrel search algorithm |
| SVM | Support vector machine |
References
- Wang, Y.; Yao, L.; Xu, Y.; Sun, S.; Li, T. Potential Heterogeneity in the Relationship between Urbanization and Air Pollution, from the Perspective of Urban Agglomeration. J. Clean. Prod. 2021, 298, 126822. [Google Scholar] [CrossRef]
- Ulpiani, G. On the Linkage between Urban Heat Island and Urban Pollution Island: Three-Decade Literature Review towards a Conceptual Framework. Sci. Total Environ. 2021, 751, 141727. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Guo, X.; Marinova, D.; Fan, J. Industrial SO2 Pollution and Agricultural Losses in China: Evidence from Heavy Air Polluters. J. Clean. Prod. 2014, 64, 404–413. [Google Scholar] [CrossRef]
- de Groot, P.; Munden, R.F. Lung Cancer Epidemiology, Risk Factors, and Prevention. Radiol. Clin. N. Am. 2012, 50, 863–876. [Google Scholar] [CrossRef] [PubMed]
- Poursafa, P.; Mansourian, M.; Motlagh, M.-E.; Ardalan, G.; Kelishadi, R. Is Air Quality Index Associated with Cardiometabolic Risk Factors in Adolescents? The CASPIAN-III Study. Environ. Res. 2014, 134, 105–109. [Google Scholar] [CrossRef]
- Rajagopalan, S.; Brook, R.D. Air Pollution and Type 2 Diabetes: Mechanistic Insights. Diabetes 2012, 61, 3037–3045. [Google Scholar] [CrossRef]
- Chen, P.; Yuan, Z.; Miao, L.; Yang, L.; Wang, H.; Xu, D.; Lin, Z. Acute Cardiorespiratory Response to Air Quality Index in Healthy Young Adults. Environ. Res. 2022, 214, 113983. [Google Scholar] [CrossRef]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A Review of Wind Power and Wind Speed Forecasting Methods with Different Time Horizons. In Proceedings of the North American Power Symposium 2010, Online, 26–28 September 2010; pp. 1–8. [Google Scholar]
- Li, Y.; He, Y.; Su, Y.; Shu, L. Forecasting the Daily Power Output of a Grid-Connected Photovoltaic System Based on Multivariate Adaptive Regression Splines. Appl. Energy 2016, 180, 392–401. [Google Scholar] [CrossRef]
- You, J.; Yu, C.; Sun, J.; Chen, J. Generalized Maximum Entropy Based Identification of Graphical ARMA Models. Automatica 2022, 141, 110319. [Google Scholar] [CrossRef]
- Liu, C.-C.; Lin, T.-C.; Yuan, K.-Y.; Chiueh, P.-T. Spatio-Temporal Prediction and Factor Identification of Urban Air Quality Using Support Vector Machine. Urban Clim. 2022, 41, 101055. [Google Scholar] [CrossRef]
- Murillo-Escobar, J.; Sepulveda-Suescun, J.P.; Correa, M.A.; Orrego-Metaute, D. Forecasting Concentrations of Air Pollutants Using Support Vector Regression Improved with Particle Swarm Optimization: Case Study in Aburrá Valley, Colombia. Urban Clim. 2019, 29, 100473. [Google Scholar] [CrossRef]
- Yoo, B.H.; Kim, K.S.; Park, J.Y.; Moon, K.H.; Ahn, J.J.; Fleisher, D.H. Spatial Portability of Random Forest Models to Estimate Site-Specific Air Temperature for Prediction of Emergence Dates of the Asian Corn Borer in North Korea. Comput. Electron. Agric. 2022, 199, 107113. [Google Scholar] [CrossRef]
- Noi, P.T.; Degener, J.; Kappas, M. Comparison of Multiple Linear Regression, Cubist Regression, and Random Forest Algorithms to Estimate Daily Air Surface Temperature from Dynamic Combinations of MODIS LST Data. Remote Sens. 2017, 9, 398. [Google Scholar] [CrossRef]
- Goudarzi, G.; Hopke, P.K.; Yazdani, M. Forecasting PM2.5 Concentration Using Artificial Neural Network and Its Health Effects in Ahvaz, Iran. Chemosphere 2021, 283, 131285. [Google Scholar] [CrossRef] [PubMed]
- Fallahizadeh, S.; Kermani, M.; Esrafili, A.; Asadgol, Z.; Gholami, M. The Effects of Meteorological Parameters on PM10: Health Impacts Assessment Using AirQ+ Model and Prediction by an Artificial Neural Network (ANN). Urban Clim. 2021, 38, 100905. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S. Air Quality Index Forecast in Beijing Based on CNN-LSTM Multi-Model. Chemosphere 2022, 308, 136180. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily Air Quality Index Forecasting with Hybrid Models: A Case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, J. A Robust Time Series Prediction Method Based on Empirical Mode Decomposition and High-Order Fuzzy Cognitive Maps. Knowl.-Based Syst. 2020, 203, 106105. [Google Scholar] [CrossRef]
- Yang, S.; Liu, J. Time-Series Forecasting Based on High-Order Fuzzy Cognitive Maps and Wavelet Transform. IEEE Trans. Fuzzy Syst. 2018, 26, 3391–3402. [Google Scholar] [CrossRef]
- Liang, W.; Zhang, Y.; Liu, X.; Yin, H.; Wang, J.; Yang, Y. Towards Improved Multifactorial Particle Swarm Optimization Learning of Fuzzy Cognitive Maps: A Case Study on Air Quality Prediction. Appl. Soft Comput. 2022, 130, 109708. [Google Scholar] [CrossRef]
- Korkmaz, D. SolarNet: A Hybrid Reliable Model Based on Convolutional Neural Network and Variational Mode Decomposition for Hourly Photovoltaic Power Forecasting. Appl. Energy 2021, 300, 117410. [Google Scholar] [CrossRef]
- Wu, Q.; Lin, H. Daily Urban Air Quality Index Forecasting Based on Variational Mode Decomposition, Sample Entropy and LSTM Neural Network. Sustain. Cities Soc. 2019, 50, 101657. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Wei, L.; Che, J.; Shen, X.; Yang, L.; Qiu, X.; Liu, X.; Gao, W.; Ren, X.; et al. PM2.5 Forecasting Using SVR with PSOGSA Algorithm Based on CEEMD, GRNN and GCA Considering Meteorological Factors. Atmos. Environ. 2018, 183, 20–32. [Google Scholar] [CrossRef]
- Li, H.; Wang, J.; Lu, H.; Guo, Z. Research and Application of a Combined Model Based on Variable Weight for Short Term Wind Speed Forecasting. Renew. Energy 2018, 116, 669–684. [Google Scholar] [CrossRef]
- Yang, W.; Hao, M.; Hao, Y. Innovative ensemble system based on mixed frequency modeling for wind speed point and interval forecasting. Inf. Sci. 2023, 622, 560–586. [Google Scholar] [CrossRef]
- Yang, W.; Sun, S.; Hao, Y.; Wang, S. A novel machine learning-based electricity price forecasting model based on optimal model selection strategy. Energy 2022, 238, 121989. [Google Scholar] [CrossRef]
- Lv, Y.-W.; Yang, G.-H. Centralized and Distributed Adaptive Cubature Information Filters for Multi-Sensor Systems with Unknown Probability of Measurement Loss. Inf. Sci. 2023, 630, 173–189. [Google Scholar] [CrossRef]
- Liu, X.; Zhong, S.; Li, S.; Yang, M. Evaluating the Impact of Central Environmental Protection Inspection on Air Pollution: An Empirical Research in China. Process Saf. Environ. Prot. 2022, 160, 563–572. [Google Scholar] [CrossRef]
- Moran, P.A.P. The Interpretation of Statistical Maps. J. R. Stat. Soc. Ser. B 1948, 10, 243–251. [Google Scholar] [CrossRef]
- Zhang, C.; Luo, L.; Xu, W.; Ledwith, V. Use of Local Moran’s I and GIS to Identify Pollution Hotspots of Pb in Urban Soils of Galway, Ireland. Sci. Total Environ. 2008, 398, 212–221. [Google Scholar] [CrossRef]
- On Extreme Values of Moran’s I and Geary’s c—Jong—1984—Geographical Analysis—Wiley Online Library. Available online: https://onlinelibrary.wiley.com/doi/10.1111/j.1538-4632.1984.tb00797.x (accessed on 8 May 2023).
- Sadeghi, M.; Naghedi, R.; Behzadian, K.; Shamshirgaran, A.; Tabrizi, M.R.; Maknoon, R. Customisation of Green Buildings Assessment Tools Based on Climatic Zoning and Experts Judgement Using K-Means Clustering and Fuzzy AHP. Build. Environ. 2022, 223, 109473. [Google Scholar] [CrossRef]
- Setiawan, K.E.; Kurniawan, A.; Chowanda, A.; Suhartono, D. Clustering Models for Hospitals in Jakarta Using Fuzzy C-Means and k-Means. Procedia Comput. Sci. 2023, 216, 356–363. [Google Scholar] [CrossRef] [PubMed]
- Kaloni, S.; Singh, G.; Tiwari, P. Nonparametric Damage Detection and Localization Model of Framed Civil Structure Based on Local Gravitation Clustering Analysis. J. Build. Eng. 2021, 44, 103339. [Google Scholar] [CrossRef]
- Liu, H.; Shah, S.; Jiang, W. On-Line Outlier Detection and Data Cleaning. Comput. Chem. Eng. 2004, 28, 1635–1647. [Google Scholar] [CrossRef]
- Allen, D.P. A Frequency Domain Hampel Filter for Blind Rejection of Sinusoidal Interference from Electromyograms. J. Neurosci. Methods 2009, 177, 303–310. [Google Scholar] [CrossRef]
- Song, Q.; Chissom, B.S. Forecasting Enrollments with Fuzzy Time Series—Part II. Fuzzy Sets Syst. 1994, 62, 1–8. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing Predictive Accuracy. J. Bus. Econ. Stat. 2002, 20, 134–144. [Google Scholar] [CrossRef]
- Harvey, D.; Leybourne, S.; Newbold, P. Testing the Equality of Prediction Mean Squared Errors. Int. J. Forecast. 1997, 13, 281–291. [Google Scholar] [CrossRef]
- Zheng, D.; Shi, M.; Pang, R. Agglomeration Economies and Environmental Regulatory Competition: Evidence from China. J. Clean. Prod. 2021, 280, 124506. [Google Scholar] [CrossRef]
- Hao, Y.; Guo, Y.; Li, S.; Luo, S.; Jiang, X.; Shen, Z.; Wu, H. Towards Achieving the Sustainable Development Goal of Industry: How Does Industrial Agglomeration Affect Air Pollution? Innov. Green Dev. 2022, 1, 100003. [Google Scholar] [CrossRef]
- Tan, G.; Cao, Y.; Xie, R.; Fang, J. Intergovernmental Competition, Industrial Spatial Distribution, and Air Quality in China. J. Environ. Manag. 2022, 310, 114721. [Google Scholar] [CrossRef]
- Cheng, Y.; Loo, B.P.Y.; Vickerman, R. High-Speed Rail Networks, Economic Integration and Regional Specialisation in China and Europe. Travel Behav. Soc. 2015, 2, 1–14. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, B. How Does New-Type Urbanization Affect Air Pollution? Empirical Evidence Based on Spatial Spillover Effect and Spatial Durbin Model. Environ. Int. 2022, 165, 107304. [Google Scholar] [CrossRef] [PubMed]
- Ruggieri, M.; Plaia, A. An Aggregate AQI: Comparing Different Standardizations and Introducing a Variability Index. Sci. Total Environ. 2012, 420, 263–272. [Google Scholar] [CrossRef]
- GB3095-2012; National Ambient Air Quality Standard of China. Ministry of Ecology and Environment of the People’s Republic of China: Beijing, China, 2012.
- Chen, W.; Tang, H.; Zhao, H. Urban Air Quality Evaluations under Two Versions of the National Ambient Air Quality Standards of China. Atmos. Pollut. Res. 2016, 7, 49–57. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AQI | Level | I | Descriptions | Color |
|---|---|---|---|---|
| 0–50 | I | 0.155 | Good | Green |
| 51–100 | II | 0.207 | Moderate | Yellow |
| 101–150 | III | 0.176 | Lightly polluted | Orange |
| 151–200 | IV | 0.095 | Moderately polluted | Red |
| 201–300 | V | 0.066 | Heavily polluted | Purple |
| >300 | VI | 0.195 | Severely polluted | Maroon |
| No. | City Name | Longitude | Latitude | Training | Testing | Max | Min | Mean | Std |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Shijiazhuang | 114.502461 | 38.045474 | 1656 | 413 | 442 | 19 | 97.85 | 57.78 |
| 2 | Hengshui | 115.665993 | 37.735097 | 1656 | 413 | 377 | 16 | 89.68 | 50.88 |
| 3 | Baoding | 115.482331 | 38.867657 | 1656 | 413 | 476 | 17 | 92.46 | 56.39 |
| 4 | Xingtai | 114.508851 | 37.068256 | 1656 | 413 | 463 | 17 | 97.28 | 56.61 |
| 5 | Handan | 114.490686 | 36.612273 | 1656 | 413 | 389 | 16 | 99.81 | 56.43 |
| 6 | Beijing | 116.405285 | 39.904989 | 1656 | 413 | 454 | 11 | 72.05 | 47.77 |
| 7 | Cangzhou | 116.857461 | 38.310582 | 1656 | 413 | 346 | 16 | 81.99 | 45.15 |
| 8 | Langfang | 116.713873 | 39.529244 | 1656 | 413 | 413 | 13 | 78.05 | 46.25 |
| 9 | Tianjin | 117.190182 | 39.125596 | 1656 | 413 | 365 | 14 | 78.29 | 42.51 |
| 10 | Tangshan | 118.175393 | 39.635113 | 1656 | 413 | 399 | 16 | 84.83 | 45.85 |
| 11 | Chengde | 117.939152 | 40.976204 | 1656 | 413 | 409 | 17 | 59.69 | 31.20 |
| 12 | Qinhuangdao | 119.586579 | 39.942531 | 1656 | 413 | 364 | 16 | 66.22 | 35.44 |
| 13 | Zhangjiakou | 114.884091 | 40.811901 | 1656 | 413 | 488 | 19 | 59.34 | 36.17 |
| Year | I | E(I) | Sd(I) | z | p-Value * |
|---|---|---|---|---|---|
| 2017 | 0.155 | −0.083 | 0.092 | 2.599 | 0.005 |
| 2018 | 0.207 | −0.083 | 0.092 | 3.164 | 0.001 |
| 2019 | 0.176 | −0.083 | 0.09 | 2.873 | 0.002 |
| 2020 | 0.095 | −0.083 | 0.09 | 1.983 | 0.024 |
| 2021 | 0.066 | −0.083 | 0.09 | 1.661 | 0.048 |
| 2022 | 0.195 | −0.083 | 0.091 | 3.064 | 0.001 |
| Cities | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|
| 1 | LL | LL | LL | LL | LL | LL |
| 2 | LL | LL | LL | HL | LL | LL |
| 3 | HH | HH | HH | HH | HH | HH |
| 4 | HL | HL | HL | HL | HL | HL |
| 5 | LL | LL | LL | LL | LL | LL |
| 6 | HH | HH | HH | HH | HH | HH |
| 7 | HH | HH | HH | HH | HH | HH |
| 8 | HH | HH | HH | HH | HL | HH |
| 9 | LH | LH | LH | LH | LH | LH |
| 10 | LL | LL | LL | LL | LL | LL |
| 11 | HH | HL | HH | HL | LL | HL |
| 12 | LL | LL | LL | LL | LL | LL |
| 13 | HH | HH | HH | HH | HH | HH |
| Cities | Method | MAPE | RMSE | MAE |
|---|---|---|---|---|
| Category I Beijing | FCM | 25.54 | 25.15 | 17.76 |
| DHP-FCM | 39.47 | 37.52 | 24.25 | |
| SHP-FCM | 25.12 | 26.34 | 17.79 | |
| HHP-FCM | 25.40 | 21.94 | 15.91 | |
| Category II Shijiazhuang | FCM | 40.51 | 37.73 | 21.18 |
| DHP-FCM | 31.96 | 24.38 | 15.43 | |
| SHP-FCM | 36.27 | 21.02 | 15.36 | |
| HHP-FCM | 36.25 | 21.08 | 15.40 | |
| Category III Chengde | FCM | 29.50 | 20.66 | 14.25 |
| DHP-FCM | 28.85 | 20.31 | 13.93 | |
| SHP-FCM | 27.78 | 19.22 | 13.29 | |
| HHP-FCM | 29.56 | 19.62 | 13.87 |
| Cities | Method | MAPE (%) | RMSE | MAE |
|---|---|---|---|---|
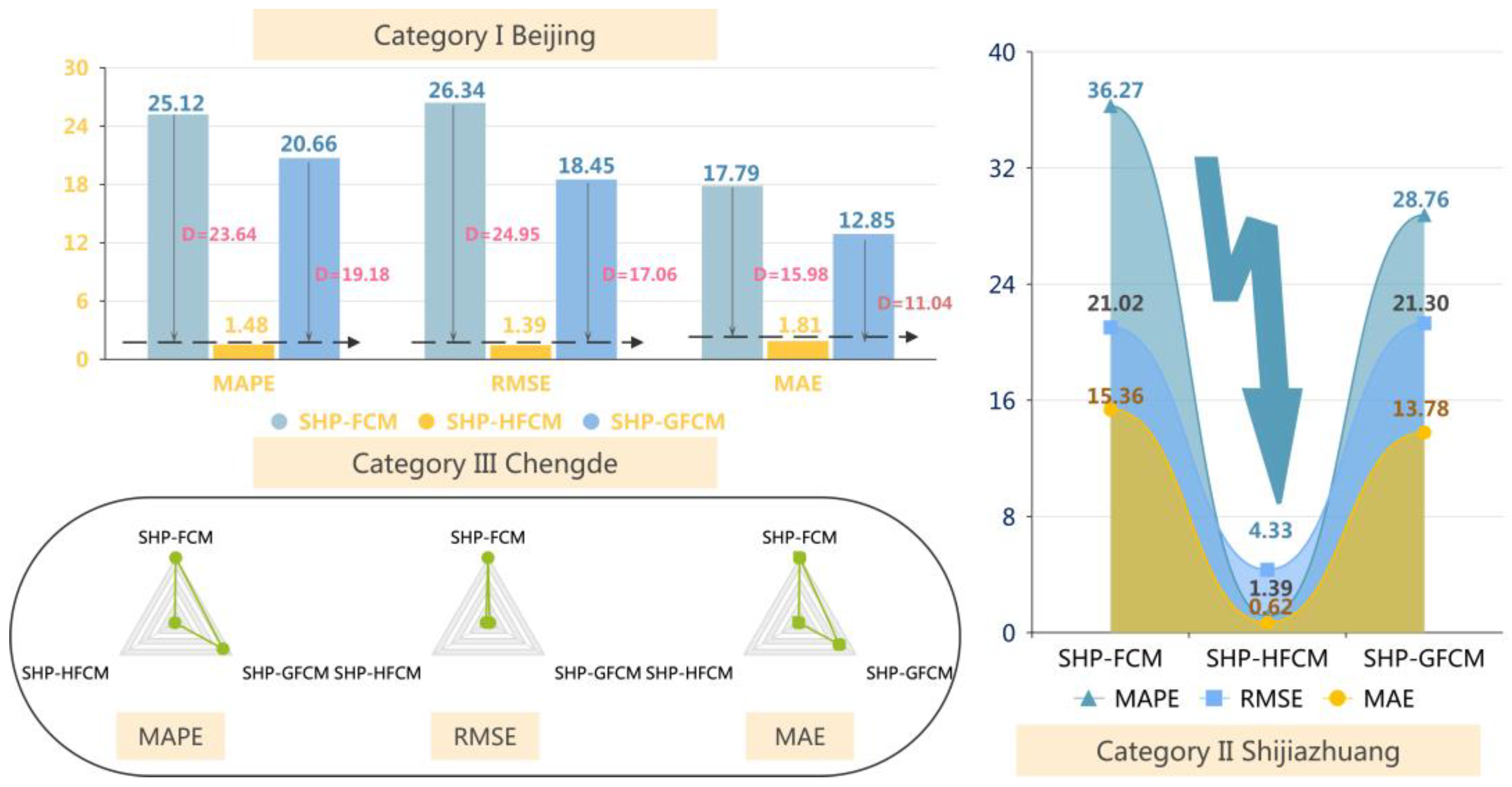
| Category I Beijing | SHP-FCM | 25.12 | 26.34 | 17.79 |
| SHP-GFCM | 20.66 | 18.45 | 12.85 | |
| SHP-HFCM | 1.48 | 1.39 | 1.81 | |
| Category II Shijiazhuang | SHP-FCM | 36.27 | 21.02 | 15.36 |
| SHP-GFCM | 28.76 | 21.30 | 13.78 | |
| SHP-HFCM | 1.12 | 4.33 | 0.69 | |
| Category III Chengde | SHP-FCM | 27.78 | 19.22 | 13.29 |
| SHP-GFCM | 24.14 | 1.11 | 9.75 | |
| SHP-HFCM | 0.49 | 0.62 | 0.23 |
| Cities | Method | MAPE (%) | RMSE | MAE |
|---|---|---|---|---|
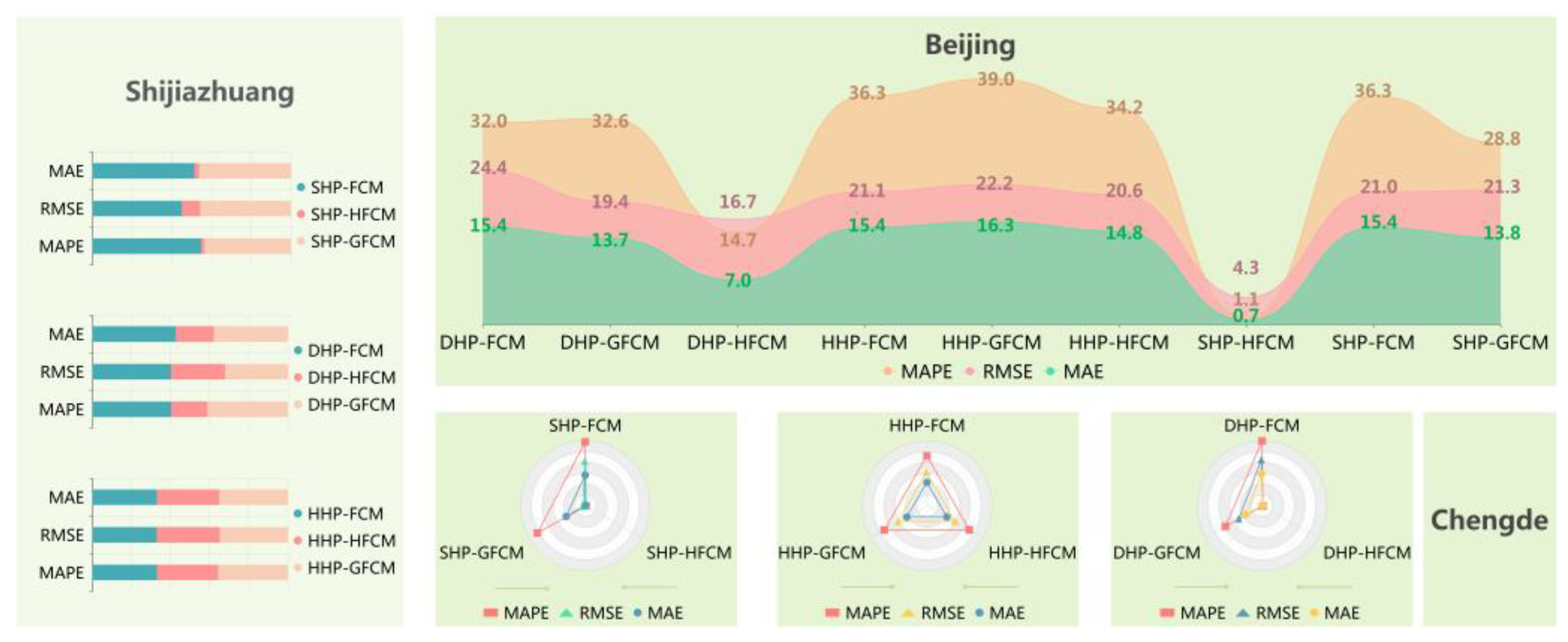
| Category I Beijing | DHP-FCM | 39.47 | 37.52 | 24.25 |
| DHP-GFCM | 30.21 | 26.19 | 18.98 | |
| DHP-HFCM | 21.45 | 21.74 | 13.48 | |
| HHP-FCM | 25.40 | 21.94 | 15.91 | |
| HHP-GFCM | 27.24 | 23.24 | 16.89 | |
| HHP-HFCM | 25.00 | 21.48 | 15.58 | |
| SHP-FCM | 25.12 | 26.34 | 17.79 | |
| SHP-GFCM | 20.66 | 18.45 | 12.85 | |
| SHP-HFCM | 1.48 | 1.39 | 1.81 | |
| Category II Shijiazhuang | DHP-FCM | 31.96 | 24.38 | 15.43 |
| DHP-GFCM | 32.64 | 19.40 | 13.66 | |
| DHP-HFCM | 14.66 | 16.72 | 7.01 | |
| HHP-FCM | 36.25 | 21.08 | 15.40 | |
| HHP-GFCM | 38.97 | 22.18 | 16.30 | |
| HHP-HFCM | 34.24 | 20.64 | 14.83 | |
| SHP-FCM | 36.27 | 21.02 | 15.36 | |
| SHP-GFCM | 28.76 | 21.30 | 13.78 | |
| SHP-HFCM | 1.12 | 4.33 | 0.69 | |
| Category III Chengde | DHP-FCM | 28.85 | 20.31 | 13.93 |
| DHP-GFCM | 18.67 | 11.87 | 8.38 | |
| DHP-HFCM | 0.53 | 0.47 | 0.25 | |
| HHP-FCM | 29.56 | 19.62 | 13.87 | |
| HHP-GFCM | 29.27 | 19.61 | 13.82 | |
| HHP-HFCM | 29.46 | 19.63 | 13.87 | |
| SHP-FCM | 27.78 | 19.22 | 13.29 | |
| SHP-GFCM | 24.14 | 1.11 | 9.75 | |
| SHP-HFCM | 0.49 | 0.62 | 0.23 |
| MAPE (%) | RMSE | MAE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Random | Proposed | Change | Random | Proposed | Change | Random | Proposed | Change | |
| Beijing | |||||||||
| FCM | 32.15 | 25.54 | 6.61 | 30.15 | 25.15 | 5.00 | 20.26 | 17.76 | 2.5 |
| SHP-FCM | 30.72 | 25.12 | 5.6 | 28.61 | 26.34 | 2.27 | 19.89 | 17.79 | 2.1 |
| SHP-HFCM | 1.39 | 1.48 | 0.09 | 1.58 | 1.39 | 0.19 | 1.76 | 1.81 | 0.05 |
| Mean | 21.42 | 17.38 | 4.04 | 20.11 | 17.63 | 2.49 | 13.97 | 12.45 | 1.52 |
| Std | 17.36 | 13.77 | 3.59 | 16.07 | 14.07 | 1.99 | 10.58 | 9.22 | 1.36 |
| Shijiazhuang | |||||||||
| FCM | 45.49 | 40.51 | 4.98 | 28.28 | 37.73 | 9.45 | 19.63 | 21.18 | 1.55 |
| SHP-FCM | 45.71 | 36.27 | 9.44 | 28.16 | 21.02 | 7.14 | 19.57 | 15.36 | 4.21 |
| SHP-HFCM | 0.83 | 1.12 | 0.29 | 4.17 | 4.33 | 0.16 | 0.52 | 0.69 | 0.17 |
| Mean | 30.68 | 25.97 | 4.71 | 20.20 | 21.03 | 0.82 | 13.24 | 12.41 | 0.83 |
| Std | 25.85 | 21.62 | 4.23 | 13.89 | 16.70 | 2.81 | 11.02 | 10.56 | 0.46 |
| Chengde | |||||||||
| FCM | 32.26 | 29.50 | 2.76 | 20.34 | 20.66 | 0.32 | 13.81 | 14.25 | 0.44 |
| SHP-FCM | 32.04 | 27.78 | 4.26 | 20.55 | 19.22 | 1.33 | 13.98 | 13.29 | 0.69 |
| SHP-HFCM | 0.67 | 0.49 | 0.18 | 0.50 | 0.62 | 0.12 | 0.31 | 0.23 | 0.08 |
| Mean | 21.66 | 19.26 | 2.40 | 13.80 | 13.50 | 0.30 | 9.37 | 9.26 | 0.11 |
| Std | 18.18 | 16.28 | 1.90 | 11.52 | 11.18 | 0.34 | 7.84 | 7.83 | 0.01 |
| Category | Method | DM | P | MDM | P |
|---|---|---|---|---|---|
| Category I Beijing | DHP-FCM | 15.2192 | 8.39 × 10−42 | 15.2007 | 1.01 × 10−41 |
| DHP-GFCM | 9.7186 | 3.11 × 10−20 | 9.7068 | 3.42 × 10−20 | |
| DHP-HFCM | 8.0531 | 3.88 × 10−25 | 8.0423 | 2.63 × 10−25 | |
| HHP-FCM | 13.6566 | 2.83 × 10−35 | 13.6401 | 3.31 × 10−35 | |
| HHP-GFCM | 5.8835 | 8.34 × 10−9 | 5.8764 | 8.67 × 10−9 | |
| HHP-HFCM | 5.1544 | 3.26 × 10−7 | 5.1478 | 3.19 × 10−7 | |
| SHP-FCM | 5.7104 | 2.16 × 10−8 | 5.7034 | 2.25 × 10−8 | |
| SHP-GFCM | 6.4946 | 2.41 × 10−10 | 6.4867 | 2.52 × 10−10 | |
| Category II Shijiazhuang | DHP-FCM | 16.4863 | 3.10 × 10−47 | 16.4663 | 3.78 × 10−47 |
| DHP-GFCM | 10.0901 | 1.55 × 10−21 | 10.0778 | 1.71 × 10−21 | |
| DHP-HFCM | 5.9216 | 8.34 × 10−11 | 5.9148 | 8.34 × 10−11 | |
| HHP-FCM | 15.9536 | 6.12 × 10−45 | 15.9342 | 7.42 × 10−45 | |
| HHP-GFCM | 9.5553 | 1.14 × 10−19 | 9.5437 | 1.25 × 10−19 | |
| HHP-HFCM | 9.1332 | 1.25 × 10−13 | 9.1277 | 1.36 × 10−13 | |
| SHP-FCM | 10.5755 | 2.79 × 10−23 | 10.5626 | 3.11 × 10−23 | |
| SHP-GFCM | 11.6521 | 2.63 × 10−27 | 11.6380 | 2.98 × 10−27 | |
| Category III Chengde | DHP-FCM | 13.0401 | 4.63 × 10−41 | 13.0242 | 5.54 × 10−41 |
| DHP-GFCM | 12.9219 | 8.93 × 10−34 | 12.9062 | 1.04 × 10−33 | |
| DHP-HFCM | 1.4234 | 3.74 × 10−51 | 1.4217 | 4.62 × 10−51 | |
| HHP-FCM | 10.3126 | 4.40 × 10−43 | 10.3001 | 5.30 × 10−43 | |
| HHP-GFCM | 10.2920 | 1.39 × 10−39 | 10.2795 | 1.65 × 10−39 | |
| HHP-HFCM | 10.3339 | 2.25 × 10−36 | 10.3214 | 2.64 × 10−36 | |
| SHP-FCM | 13.4234 | 9.09 × 10−33 | 13.4071 | 1.05 × 10−32 | |
| SHP-GFCM | 13.2622 | 2.72 × 10−32 | 13.2461 | 3.14 × 10−32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, X.; Li, H.; Fan, H. Spatiotemporal Hybrid Air Pollution Early Warning System of Urban Agglomeration Based on Adaptive Feature Extraction and Hesitant Fuzzy Cognitive Maps. Systems 2023, 11, 286. https://doi.org/10.3390/systems11060286
Gu X, Li H, Fan H. Spatiotemporal Hybrid Air Pollution Early Warning System of Urban Agglomeration Based on Adaptive Feature Extraction and Hesitant Fuzzy Cognitive Maps. Systems. 2023; 11(6):286. https://doi.org/10.3390/systems11060286
Chicago/Turabian StyleGu, Xiaoyang, Hongmin Li, and Henghao Fan. 2023. "Spatiotemporal Hybrid Air Pollution Early Warning System of Urban Agglomeration Based on Adaptive Feature Extraction and Hesitant Fuzzy Cognitive Maps" Systems 11, no. 6: 286. https://doi.org/10.3390/systems11060286
APA StyleGu, X., Li, H., & Fan, H. (2023). Spatiotemporal Hybrid Air Pollution Early Warning System of Urban Agglomeration Based on Adaptive Feature Extraction and Hesitant Fuzzy Cognitive Maps. Systems, 11(6), 286. https://doi.org/10.3390/systems11060286