
Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning


Abstract
:1. Introduction
2. Domain-Independent Self-Supervised Learning Framework
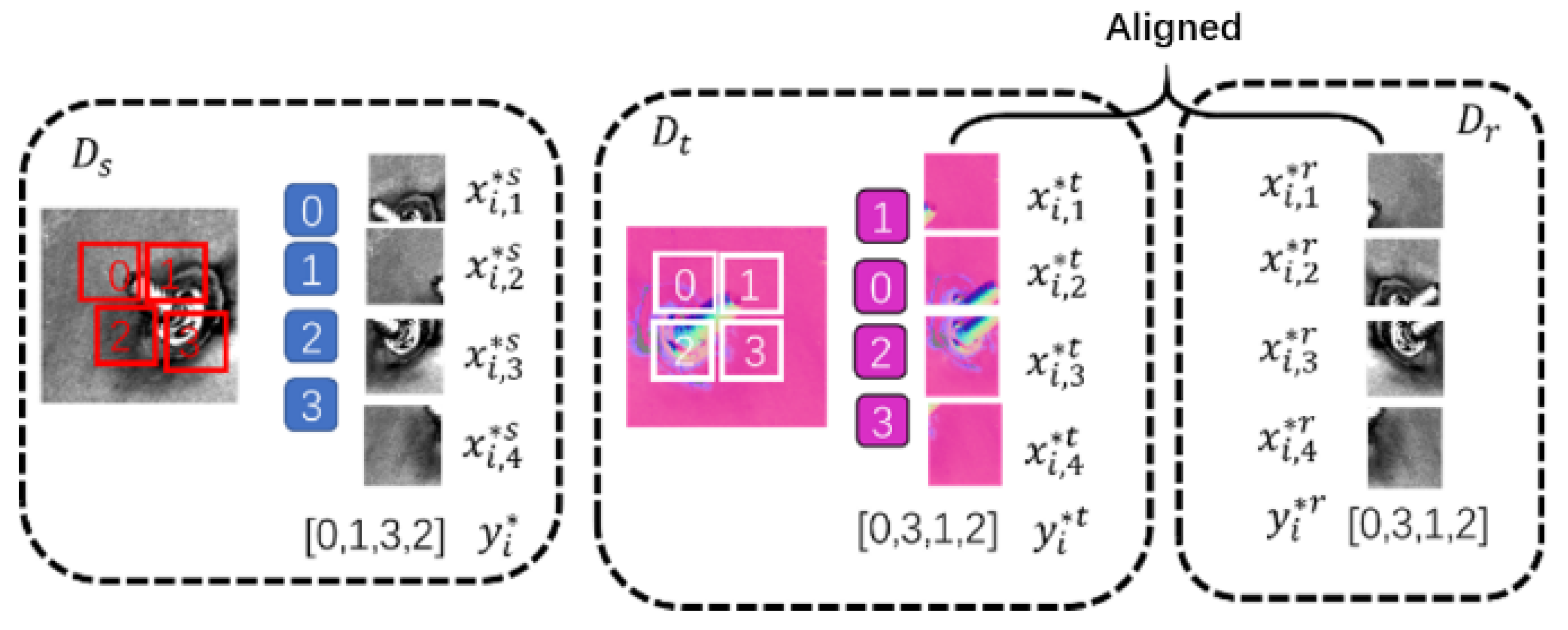
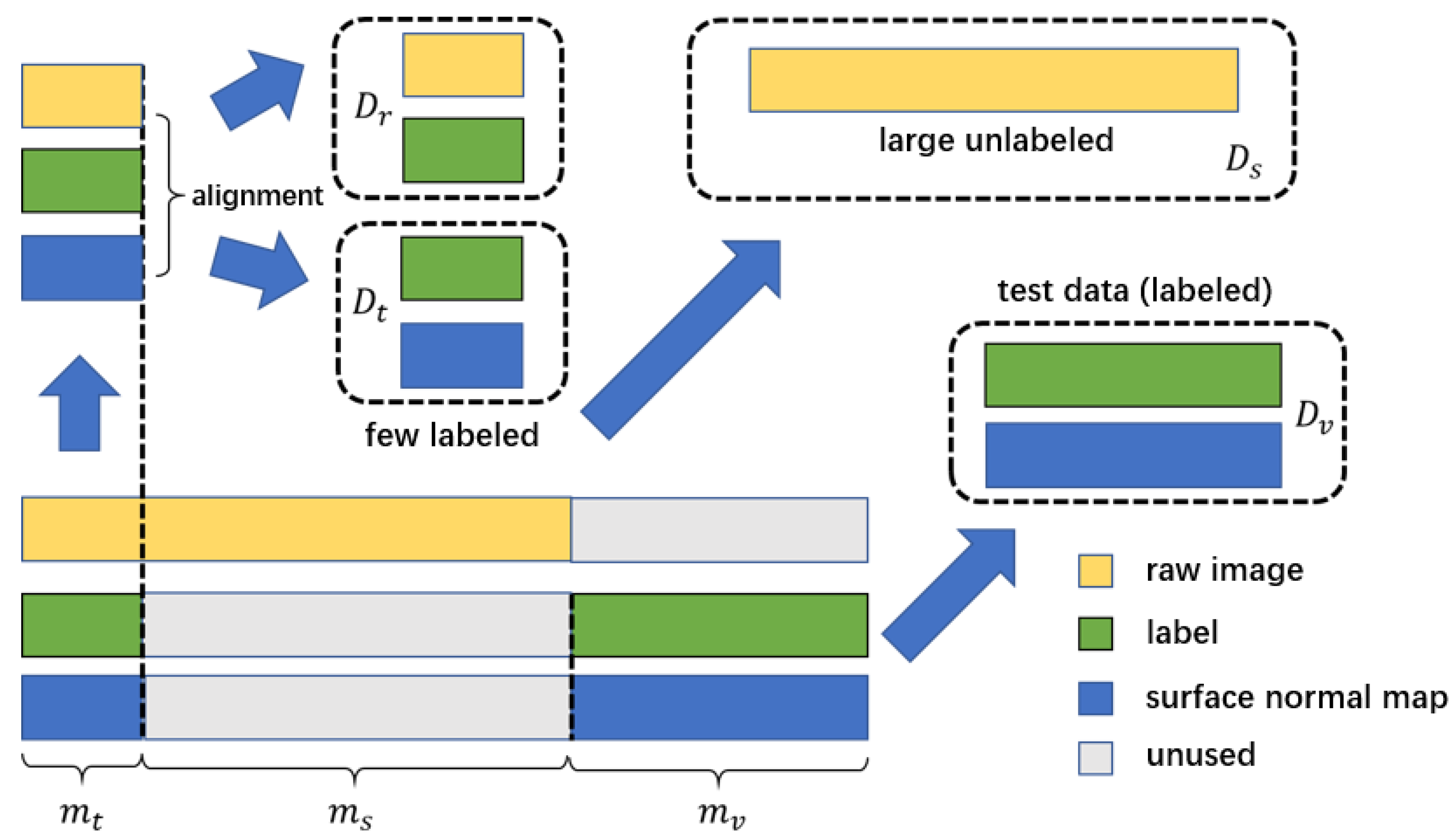
2.1. Training Data and Problem Description
2.2. Pre-Task Training
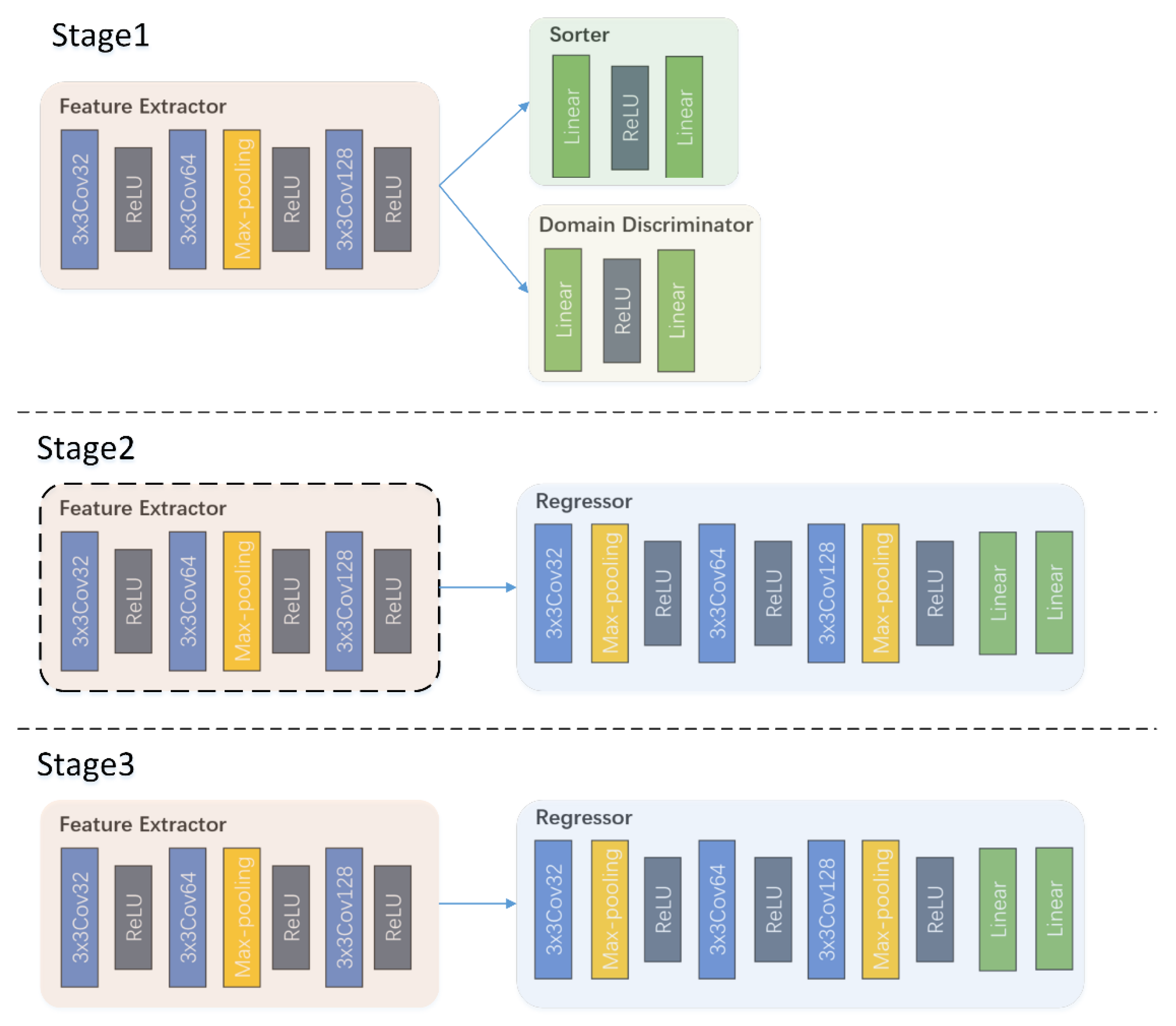
2.3. Network Architecture
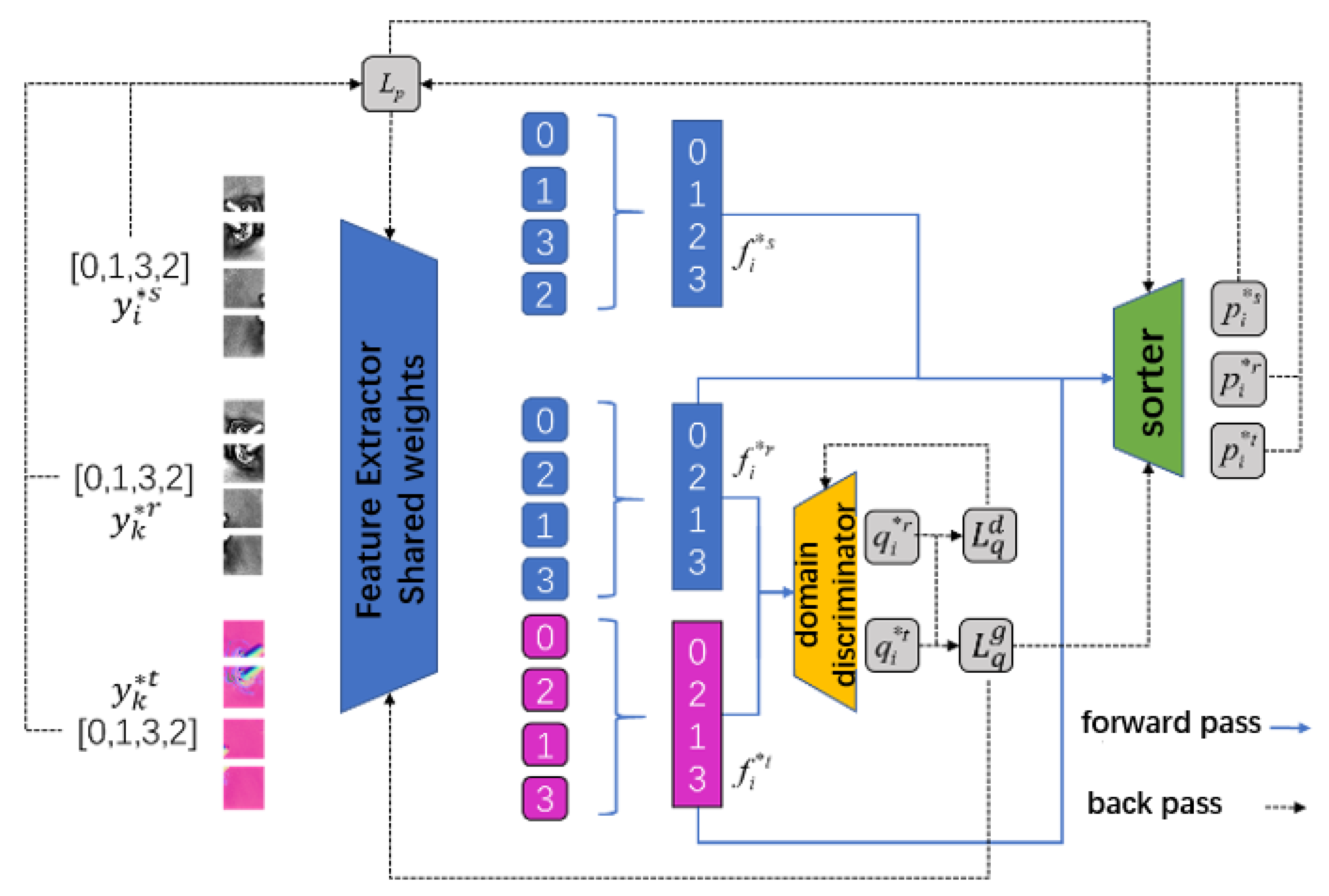
2.4. Training Process
| Algorithm 1 Pre-task training algorithm |
| Input: |
| Initialize weights |
| for do |
| Extract features according to formula (1) and (2) |
| if then |
| Calculate according to formula (4) |
| Calculate the discriminative domain loss function according to formula (6) |
| Calculate the extractor domain loss function according to formula (7) |
| Update |
| else |
| Calculate the sort prediction according to formula (3) |
| Calculate the ranking loss function according to formula (5) |
| Update |
| Update |
| end if |
| end for |
| Algorithm 2 Regression task training algorithm |
| Input: |
| Initialize weights |
| for do |
| for do |
| Extract features according to formula (8) |
| Extract features according to formula (9) |
| Calculate |
| end for |
| if then |
| Update |
| else |
| Update |
| Update |
| end if |
| if then |
| end if |
| end for |
3. Experimental Results and Analysis
3.1. Acquisition of Datasets
3.2. Complex Feature Keypoint Regression Experiments
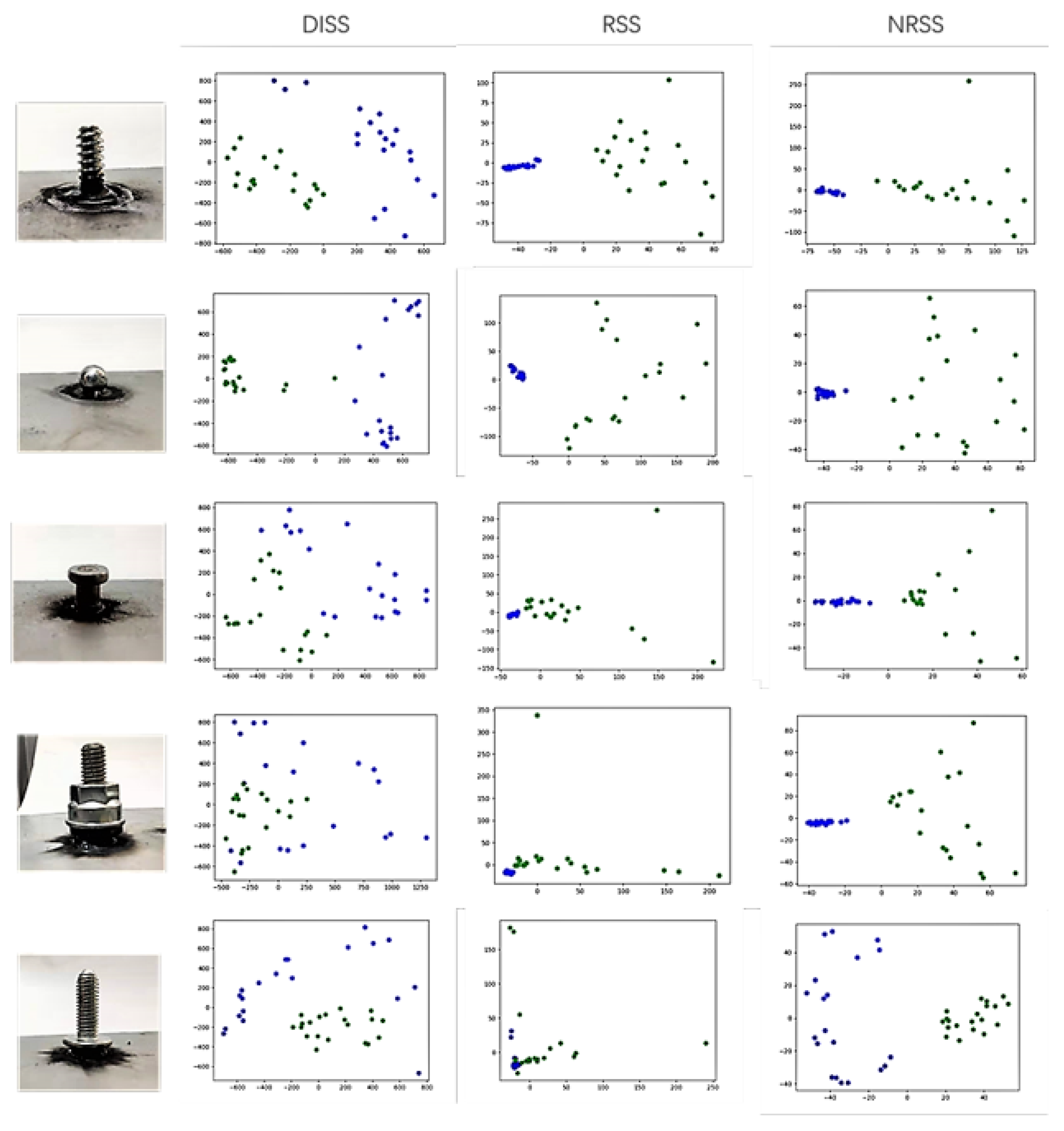
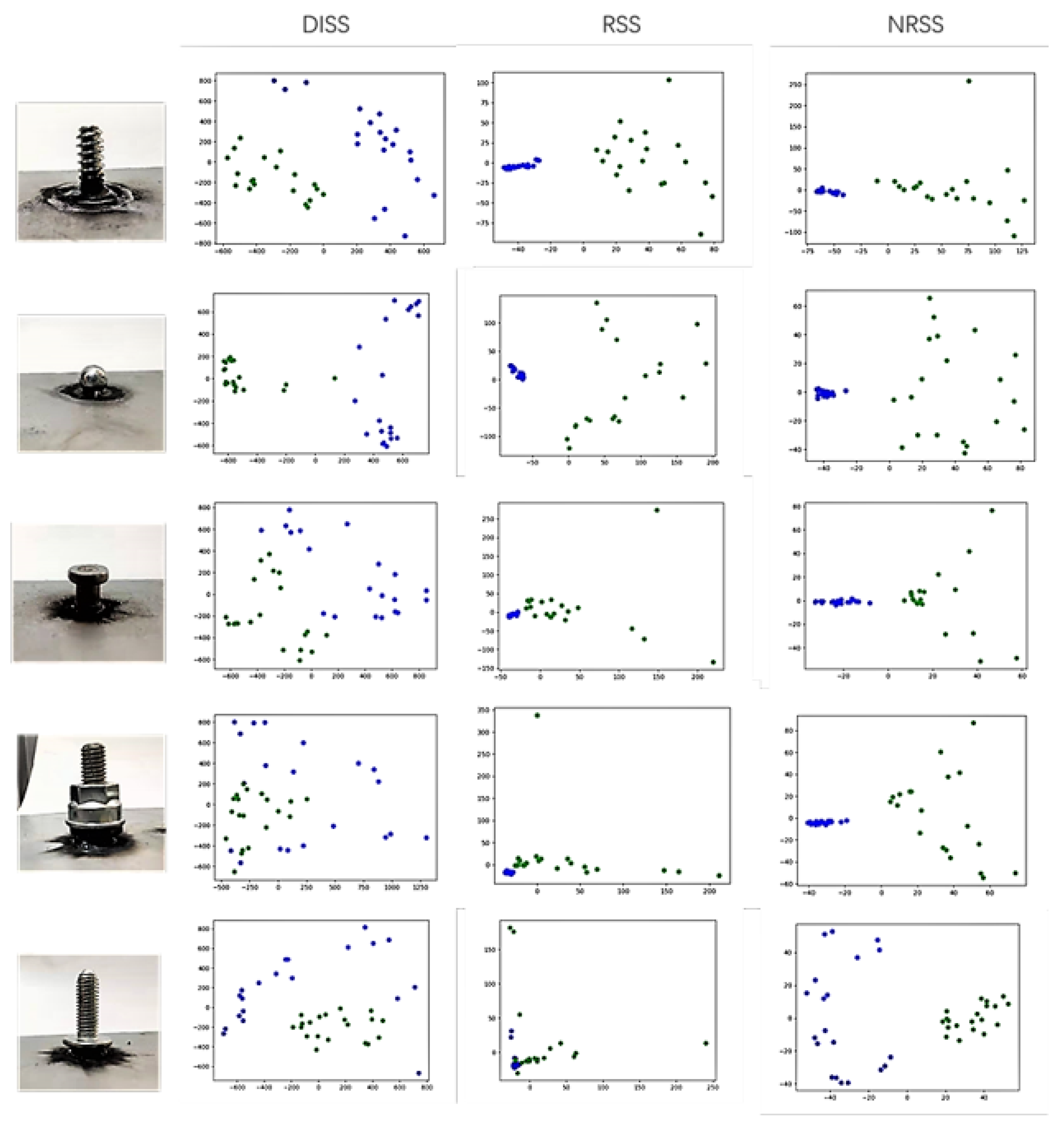
3.3. Principal Component Analysis of Extracted Features
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liang, J.; Xu, K.; Xu, J. Sub-Pixel Feature Extraction and Edge Detection in 3-D Measuring Using Structured Lights. Chin. J. Mech. Eng. 2004, 12, 100–103. [Google Scholar] [CrossRef]
- Kiraci, E. Moving towards in-line metrology: Evaluation of a Laser Radar system for in-line dimensional inspection for automotive assembly systems. Int. J. Adv. Manuf. Technol. 2017, 91, 69–78. [Google Scholar] [CrossRef] [Green Version]
- Yue, H.; Dantanarayana, H.; Wu, Y. Reduction of systematic errors in structured light metrology at discontinuities in surface reflectivity. Opt. Lasers Eng. 2019, 112, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Luo, Z.; Zhang, K.; Wang, Z. 3D pose estimation of large and complicated workpieces based on binocular stereo vision. Appl. Opt. 2017, 56, 6822–6836. [Google Scholar] [CrossRef] [PubMed]
- Dang, Q.; Yin, J.; Wang, B. Deep learning based 2d human pose estimation: A survey. Tsinghua Sci. Technol. 2019, 24, 663–676. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Doersch, C.; Gupta, A.; Efros, A. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13 December 2015. [Google Scholar]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8 October 2016. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8 September 2018. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8 October 2016. [Google Scholar]
- Pathak, D.; Girshick, R.; Dollár, P. Learning features by watching objects move. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2701–2710. [Google Scholar]
- Liu, H.; Yan, Y.; Song, K. Efficient Optical Measurement of Welding Studs with Normal Maps and Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2020, 70, 5000614. [Google Scholar] [CrossRef]
- Liu, H.; Yan, Y.; Song, K. Optical challenging feature inline measurement system based on photometric stereo and HON feature extractor. In Proceedings of the Optical Micro- and Nanometrology VII, Strasbourg, France, 18 June 2018. [Google Scholar]
- Wilson, G.; Cook, D. A survey of unsupervised deep domain adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–46. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Peculiarity | |||
|---|---|---|---|---|
| Use the Original Image | Surface Normal Diagram | Self-Supervision | Confrontation Training | |
| SL | not | Yes | not | not |
| RSS | Yes | Yes | not | not |
| NRSS | Yes | Yes | Yes | not |
| DISS | Yes | Yes | Yes | Yes |
| The Characteristic Type | Feature Recognition | Average Error (in Pixels) | |||
|---|---|---|---|---|---|
| DISS (Our Method) | SL | RSS | NRSS | ||
| N-type features | nut bolt | 9.22 | 11.88 | 10.82 | 11.12 |
| P-type features | flat bolt | 9.87 | 12.42 | 10.61 | 10.79 |
| S-type features | standard bolt | 8.23 | 9.33 | 8.88 | 8.94 |
| T-type features | t-bolt | 8.55 | 8.87 | 8.75 | 8.76 |
| Type B features | Ball-stud | 7.43 | 7.42 | 7.44 | 7.56 |
| average | - | 8.66 | 9.98 | 9.30 | 9.43 |
| α Value | Average Error (in Pixels) | |||
|---|---|---|---|---|
| DISS (Text Method) | SL | RSS | NRSS | |
| 5% | 8.66 | 9.98 | 9.30 | 9.43 |
| 10% | 7.69 | 9.07 | 8.23 | 8.20 |
| 20% | 5.88 | 6.38 | 6.40 | 6.48 |
| 40% | 4.52 | 4.68 | 6.62 | 6.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Su, K.; Yang, L.; Li, J.; Guo, J. Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning. Coatings 2022, 12, 614. https://doi.org/10.3390/coatings12050614
Liu C, Su K, Yang L, Li J, Guo J. Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning. Coatings. 2022; 12(5):614. https://doi.org/10.3390/coatings12050614
Chicago/Turabian StyleLiu, Chuang, Kang Su, Long Yang, Jie Li, and Jingbo Guo. 2022. "Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning" Coatings 12, no. 5: 614. https://doi.org/10.3390/coatings12050614
APA StyleLiu, C., Su, K., Yang, L., Li, J., & Guo, J. (2022). Detection of Complex Features of Car Body-in-White under Limited Number of Samples Using Self-Supervised Learning. Coatings, 12(5), 614. https://doi.org/10.3390/coatings12050614