Modeling Sequential Dependencies in Progressive Matrices: An Auto-Regressive Item Response Theory (AR-IRT) Approach


Abstract
1. Introduction
1.1. Significance of Progressive Matrices Tests
1.2. Psychometric Modeling of Progressive Matrices
1.3. Local Dependencies and Their Violations
1.4. Sequential Local Dependencies
2. Auto-Regressive IRT Models
2.1. The 2-Parameter Logistic Model
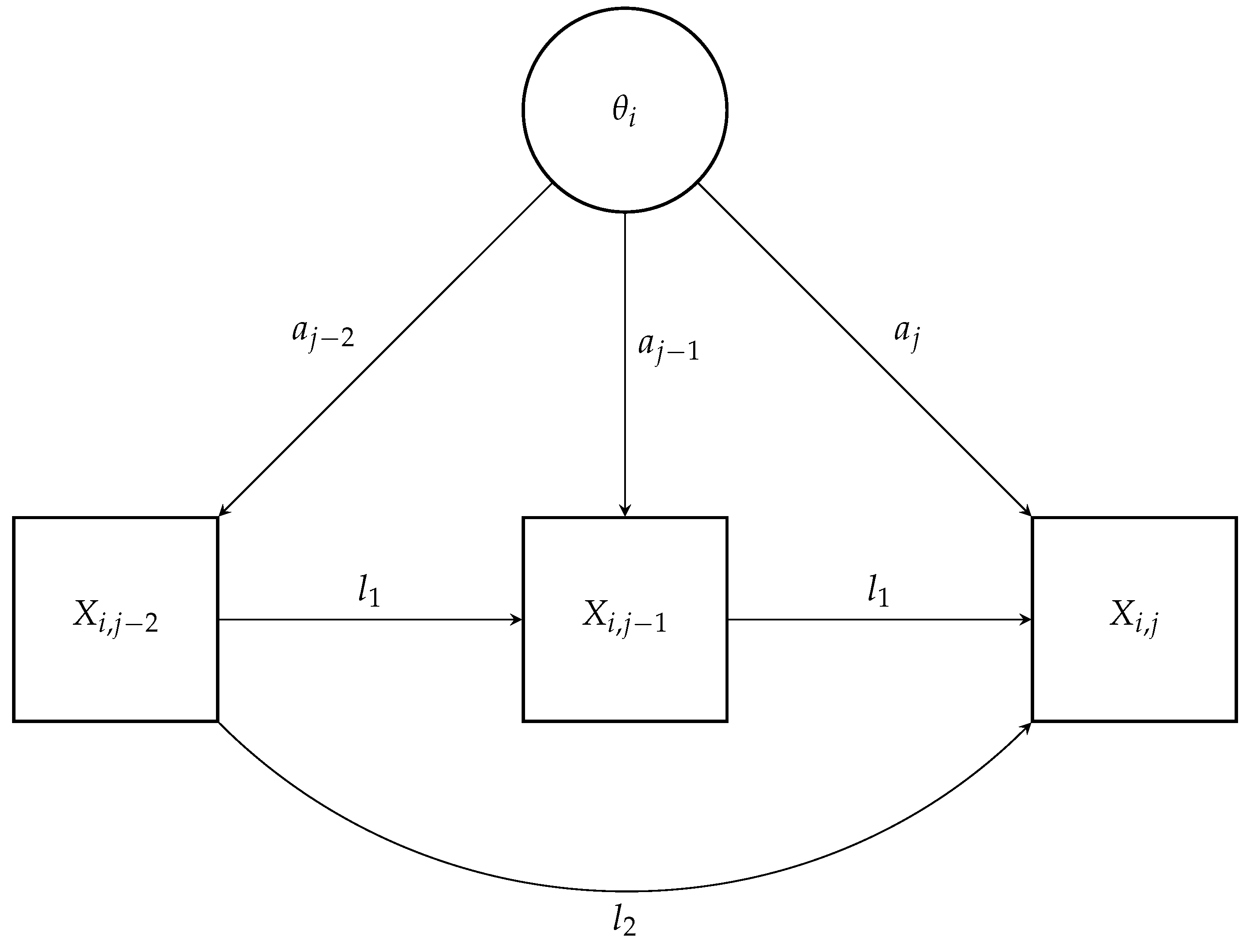
2.1.1. Auto-Regressive 2-Parameter Logistic Model with Lag 1
2.1.2. Auto-Regressive 2-Parameter Logistic Model with k Lags
2.2. Model Selection Considerations
2.2.1. Choosing between Fixed and Variable Lag Parameters
2.2.2. Selecting a Number of Lags (k)
2.3. Information
2.4. Objectives and Hypothesis
- an auto-regressive IRT model would outperform a non-auto-regressive model in model fit;
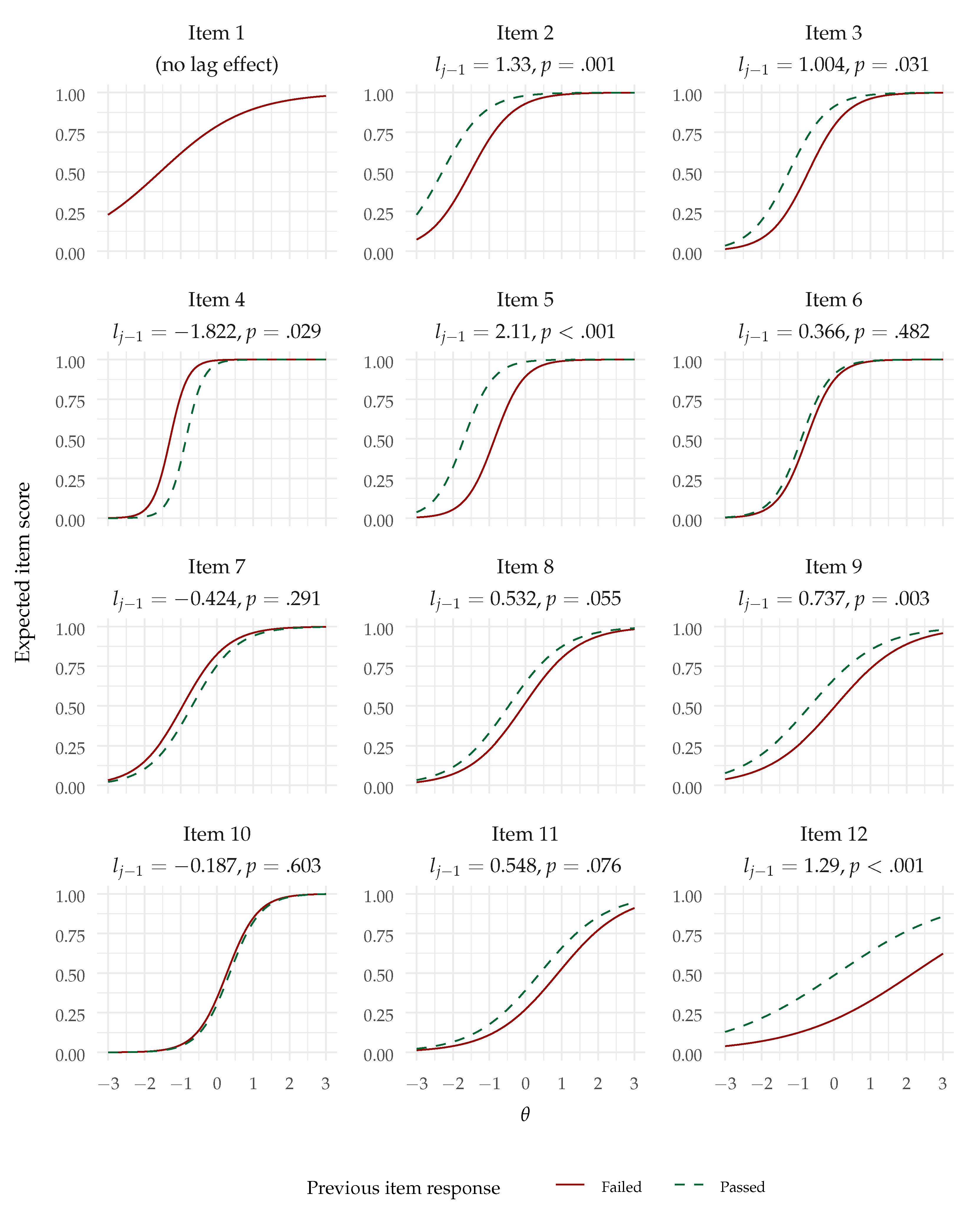
- a non-negligible positive lag-1 effect would be observed, indicating that successfully solving an item increases the probability of correctly responding to the next item (over and beyond the effect of the common factor);
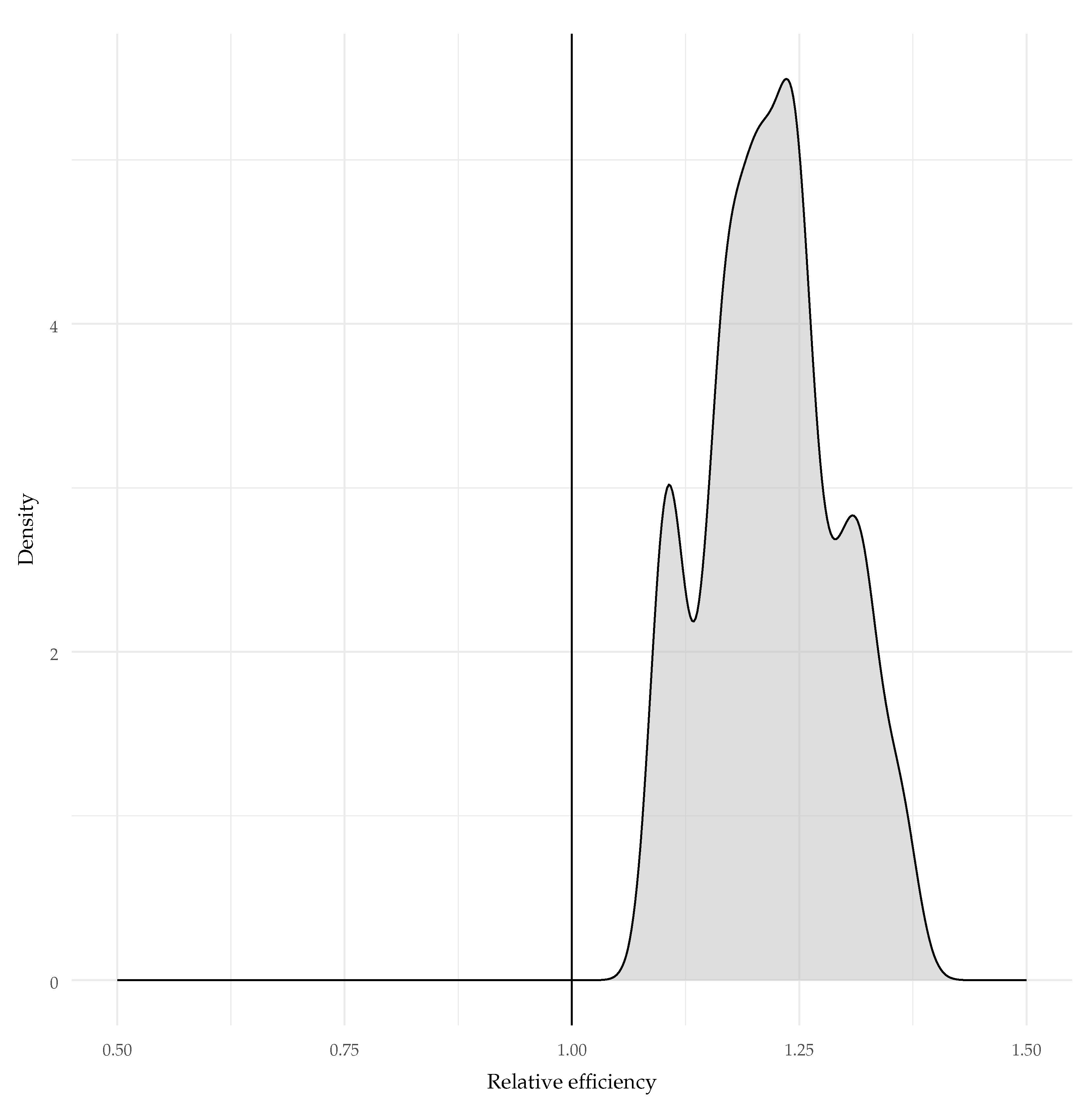
- standard errors of person estimates would be larger in the auto-regressive model, indicating that using a traditional IRT (i.e., non-auto-regressive)—in cases where an auto-regressive approach is relevant conceptually (like we argued) and empirically (like we hypothesized)—results in overestimating test information/reliability.
3. Methods
3.1. Dataset
3.2. Models Estimated
3.3. Model Parameterization and Estimation
3.4. Model Comparisons and Interpretations
3.5. Additional Explorations
4. Results
4.1. Fixed Lag-1 Effect
4.2. Additional Analyses
4.2.1. Variable Lag Model
4.2.2. Lag-2 model
5. Discussion
5.1. Summary of Findings
5.2. Limitations and Future Studies
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AIC | Akaike information criterion |
| AR | Auto-regressive |
| BCI | Bootstrapped confidence interval |
| BIC | Bayesian information criterion |
| CTT | Classical test theory |
| GLMM | Generalized Linear Multilevel Modeling |
| IRT | Item response theory |
| 1PL | One-parameter logistic |
| 2PL | Two-parameter logistic |
| 3PL | Three-parameter logistic |
| 4PL | Four-parameter logistic |
| RMSD | Root mean squared difference |
| SE | Standard error |
| SEM | Structural equation modeling |
| TAR | Threshold auto-regressive |
References
- Annis, Jeffrey, and Kenneth J. Malmberg. 2013. A model of positive sequential dependencies in judgments of frequency. Journal of Mathematical Psychology 57: 225–36. [Google Scholar] [CrossRef]
- Bandura, Albert. 1977. Self-efficacy: Toward a unifying theory of behavioral change. Psychological Review 84: 191–215. [Google Scholar] [CrossRef] [PubMed]
- Bock, R. Darrell. 1972. Estimating item parameters and latent ability when responses are scored in two or more nominal categories. Psychometrika 37: 29–51. [Google Scholar] [CrossRef]
- Bors, Douglas A., and Tonya L. Stokes. 1998. Raven’s Advanced Progressive Matrices: Norms for First-Year University Students and the Development of a Short Form. Educational and Psychological Measurement 58: 382–98. [Google Scholar] [CrossRef]
- Borsboom, Denny. 2006. The attack of the psychometricians. Psychometrika 71: 425. [Google Scholar] [CrossRef]
- Bürkner, Paul-Christian. 2017. brms: An R Package for Bayesian Multilevel Models Using Stan. Journal of Statistical Software 80: 1–28. [Google Scholar] [CrossRef]
- Bürkner, Paul-Christian. 2020. Analysing Standard Progressive Matrices (SPM-LS) with Bayesian Item Response Models. Journal of Intelligence 8: 5. [Google Scholar] [CrossRef]
- Carpenter, Patricia A., Marcel A. Just, and Peter Shell. 1990. What one intelligence test measures: A theoretical account of the processing in the Raven Progressive Matrices Test. Psychological Review 97: 404–31. [Google Scholar] [CrossRef]
- Chalmers, R. Philip. 2012. mirt: A Multidimensional Item Response Theory Package for the R Environment. Journal of Statistical Software 48: 1–29. [Google Scholar] [CrossRef]
- Chen, Cheng-Te, and Wen-Chung Wang. 2007. Effects of Ignoring Item Interaction on Item Parameter Estimation and Detection of Interacting Items. Applied Psychological Measurement 31: 388–411. [Google Scholar] [CrossRef]
- Chen, Wen-Hung, and David Thissen. 1997. Local Dependence Indexes for Item Pairs Using Item Response Theory. Journal of Educational and Behavioral Statistics 22: 265–89. [Google Scholar] [CrossRef]
- Cronbach, Lee J. 1951. Coefficient alpha and the internal structure of tests. Psychometrika 16: 297–334. [Google Scholar] [CrossRef]
- Forthmann, Boris, Natalie Förster, Birgit Schütze, Karin Hebbecker, Janis Flessner, Martin T. Peters, and Elmar Souvignier. 2020. How Much g Is in the Distractor? Re-Thinking Item-Analysis of Multiple-Choice Items. Journal of Intelligence 8: 11. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garzon, Eduardo, Francisco J. Abad, and Luis E. Garrido. 2019, September. Searching for G: A New Evaluation of SPM-LS Dimensionality. Journal of Intelligence 7: 14. [CrossRef]
- Gignac, Gilles E. 2015. Raven’s is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g. Intelligence 52: 71–79. [Google Scholar] [CrossRef]
- Golino, Hudson F., and Sacha Epskamp. 2017. Exploratory graph analysis: A new approach for estimating the number of dimensions in psychological research. PLoS ONE 12: e0174035. [Google Scholar] [CrossRef] [PubMed]
- Golino, Hudson F., Dingjing Shi, Alexander P. Christensen, Luis Eduardo Garrido, Maria Dolores Nieto, Ritu Sadana, Jotheeswaran Amuthavalli Thiyagarajan, and Agustin Martinez-Molina. 2020. Investigating the performance of exploratory graph analysis and traditional techniques to identify the number of latent factors: A simulation and tutorial. Psychological Methods 25: 292–320. [Google Scholar] [CrossRef]
- Hallquist, Michael N., and Joshua F. Wiley. 2018. Mplus Automation: An R package for facilitating large-scale latent variable analyses in Mplus. Structural Equation Modeling 25: 621–38. [Google Scholar] [CrossRef]
- Jeon, Minjeong, and Nicholas Rockwood. 2018. PLmixed: An R Package for Generalized Linear Mixed Models With Factor Structures. Applied Psychological Measurement 42: 401–2. [Google Scholar] [CrossRef]
- Kaufman, Scott Barry, Colin G. DeYoung, Jeremy R. Gray, Jamie Brown, and Nicholas Mackintosh. 2009. Associative learning predicts intelligence above and beyond working memory and processing speed. Intelligence 37: 374–82. [Google Scholar] [CrossRef]
- Kunda, Maithilee. 2020. AI, visual imagery, and a case study on the challenges posed by human intelligence tests. Proceedings of the National Academy of Sciences 117: 29390–97. [Google Scholar] [CrossRef]
- Langener, Anna M., Anne-Wil Kramer, Wouter van den Bos, and Hilde M. Huizenga. 2022. A shortened version of Raven’s standard progressive matrices for children and adolescents. British Journal of Developmental Psychology 40: 35–45. [Google Scholar] [CrossRef] [PubMed]
- Luchins, Abraham S. 1942. Mechanization in problem solving: The effect of Einstellung. Psychological Monographs 54: i–95. [Google Scholar] [CrossRef]
- McNeish, Daniel, and Melissa Gordon Wolf. 2020. Thinking twice about sum scores. Behavior Research Methods 52: 2287–305. [Google Scholar] [CrossRef] [PubMed]
- Mokken, Robert J. 1971. A Theory and Procedure of Scale Analysis. The Hague and Berlin: Mouton/De Gruyter. [Google Scholar]
- Mokken, Robert J., and Charles Lewis. 1982. A Nonparametric Approach to the Analysis of Dichotomous Item Responses. Applied Psychological Measurement 6: 417–430. [Google Scholar] [CrossRef]
- Muthén, Linda K., and Bengt O. Muthén. 1998. Mplus User’s Guide. Los Angeles: Muthén & Muthén. [Google Scholar]
- Myszkowski, Nils. 2020a. Analysis of an Intelligence Dataset. Journal of Intelligence 8: 39. [Google Scholar] [CrossRef]
- Myszkowski, Nils. 2020b. A Mokken Scale Analysis of the Last Series of the Standard Progressive Matrices (SPM-LS). Journal of Intelligence 8: 22. [Google Scholar] [CrossRef]
- Myszkowski, Nils, ed. 2021. Analysis of an Intelligence Dataset. Basel: MDPI. [Google Scholar]
- Myszkowski, Nils, and Martin Storme. 2018. A snapshot of g? Binary and polytomous item-response theory investigations of the last series of the Standard Progressive Matrices (SPM-LS). Intelligence 68: 109–16. [Google Scholar] [CrossRef]
- Myszkowski, Nils, Martin Storme, Emeric Kubiak, and Simon Baron. 2022. Exploring the associations between personality and response speed trajectories in low-stakes intelligence tests. Personality and Individual Differences 191: 111580. [Google Scholar] [CrossRef]
- Ozkok, Ozlem, Michael J. Zyphur, Adam P. Barsky, Max Theilacker, M. Brent Donnellan, and Frederick L. Oswald. 2019. Modeling Measurement as a Sequential Process: Autoregressive Confirmatory Factor Analysis (AR-CFA). Frontiers in Psychology 10: 2108. [Google Scholar] [CrossRef]
- Raven, John. 2000. The Raven’s Progressive Matrices: Change and Stability over Culture and Time. Cognitive Psychology 41: 1–48. [Google Scholar] [CrossRef] [PubMed]
- Raven, John C. 1941. Standardization of Progressive Matrices, 1938. British Journal of Medical Psychology 19: 137–50. [Google Scholar] [CrossRef]
- Reise, Steven P., Tyler M. Moore, and Mark G. Haviland. 2010. Bifactor Models and Rotations: Exploring the Extent to which Multidimensional Data Yield Univocal Scale Scores. Journal of Personality Assessment 92: 544–59. [Google Scholar] [CrossRef]
- Rosseel, Yves. 2012. lavaan: An R package for structural equation modeling. Journal of Statistical Software 48: 1–36. [Google Scholar] [CrossRef]
- Shimada, Daisuke, and Kentaro Katahira. 2023. Sequential dependencies of responses in a questionnaire survey and their effects on the reliability and validity of measurement. Behavior Research Methods 55: 3241–3259. [Google Scholar] [CrossRef] [PubMed]
- Storme, Martin, Nils Myszkowski, Simon Baron, and David Bernard. 2019. Same Test, Better Scores: Boosting the Reliability of Short Online Intelligence Recruitment Tests with Nested Logit Item Response Theory Models. Journal of Intelligence 7: 1–17. [Google Scholar] [CrossRef] [PubMed]
- Suh, Youngsuk, and Daniel M. Bolt. 2010. Nested Logit Models for Multiple-Choice Item Response Data. Psychometrika 75: 454–73. [Google Scholar] [CrossRef]
- Tang, Xiaodan, George Karabatsos, and Haiqin Chen. 2020. Detecting Local Dependence: A Threshold-Autoregressive Item Response Theory (TAR-IRT) Approach for Polytomous Items. Applied Measurement in Education 33: 280–92. [Google Scholar] [CrossRef]
- Van der Ark, L. Andries. 2007. Mokken Scale Analysis in R. Journal of Statistical Software 20: 1–19. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Item | (Discrimination) | SE | (Difficulty) | SE |
|---|---|---|---|---|---|
| 2PL | 1 | 0.855 | 0.146 | −1.322 | 0.129 |
| 2 | 1.997 | 0.324 | −3.554 | 0.375 | |
| 3 | 1.692 | 0.232 | −2.068 | 0.208 | |
| 4 | 4.089 | 0.730 | −4.106 | 0.647 | |
| 5 | 4.933 | 1.018 | −5.489 | 1.010 | |
| 6 | 2.375 | 0.317 | −2.129 | 0.253 | |
| 7 | 1.550 | 0.198 | −1.230 | 0.155 | |
| 8 | 1.612 | 0.199 | −0.502 | 0.136 | |
| 9 | 1.264 | 0.163 | −0.402 | 0.120 | |
| 10 | 2.196 | 0.286 | 0.703 | 0.166 | |
| 11 | 1.513 | 0.186 | 0.816 | 0.137 | |
| 12 | 1.136 | 0.157 | 0.910 | 0.125 | |
| AR1-2PL | 1 | 0.856 | 0.150 | −1.322 | 0.129 |
| 2 | 1.816 | 0.318 | −3.051 | 0.375 | |
| 3 | 1.502 | 0.228 | −1.464 | 0.228 | |
| 4 | 3.950 | 0.833 | −3.631 | 0.731 | |
| 5 | 4.187 | 0.936 | −4.490 | 0.938 | |
| 6 | 2.019 | 0.311 | −1.465 | 0.264 | |
| 7 | 1.243 | 0.197 | −0.715 | 0.172 | |
| 8 | 1.379 | 0.199 | −0.063 | 0.153 | |
| 9 | 0.971 | 0.165 | −0.043 | 0.131 | |
| 10 | 2.016 | 0.307 | 1.045 | 0.177 | |
| 11 | 1.173 | 0.192 | 1.013 | 0.133 | |
| 12 | 0.911 | 0.159 | 1.097 | 0.126 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Myszkowski, N.; Storme, M. Modeling Sequential Dependencies in Progressive Matrices: An Auto-Regressive Item Response Theory (AR-IRT) Approach. J. Intell. 2024, 12, 7. https://doi.org/10.3390/jintelligence12010007
Myszkowski N, Storme M. Modeling Sequential Dependencies in Progressive Matrices: An Auto-Regressive Item Response Theory (AR-IRT) Approach. Journal of Intelligence. 2024; 12(1):7. https://doi.org/10.3390/jintelligence12010007
Chicago/Turabian StyleMyszkowski, Nils, and Martin Storme. 2024. "Modeling Sequential Dependencies in Progressive Matrices: An Auto-Regressive Item Response Theory (AR-IRT) Approach" Journal of Intelligence 12, no. 1: 7. https://doi.org/10.3390/jintelligence12010007
APA StyleMyszkowski, N., & Storme, M. (2024). Modeling Sequential Dependencies in Progressive Matrices: An Auto-Regressive Item Response Theory (AR-IRT) Approach. Journal of Intelligence, 12(1), 7. https://doi.org/10.3390/jintelligence12010007