
Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS Kyber Postquantum Cryptography Scheme

 , , , , , and
, , , , , and
Abstract
:1. Introduction
1.1. Related Work
1.2. Key Contributions
- 1.
- We developed a new data accessing pattern on the NTT algorithm as well as appropriate reordering in order to reduce the BRAM to just the LUT-RAM of the FPGA Architecture, which can support shallow-depth and long-width requirements for unrolling.
- 2.
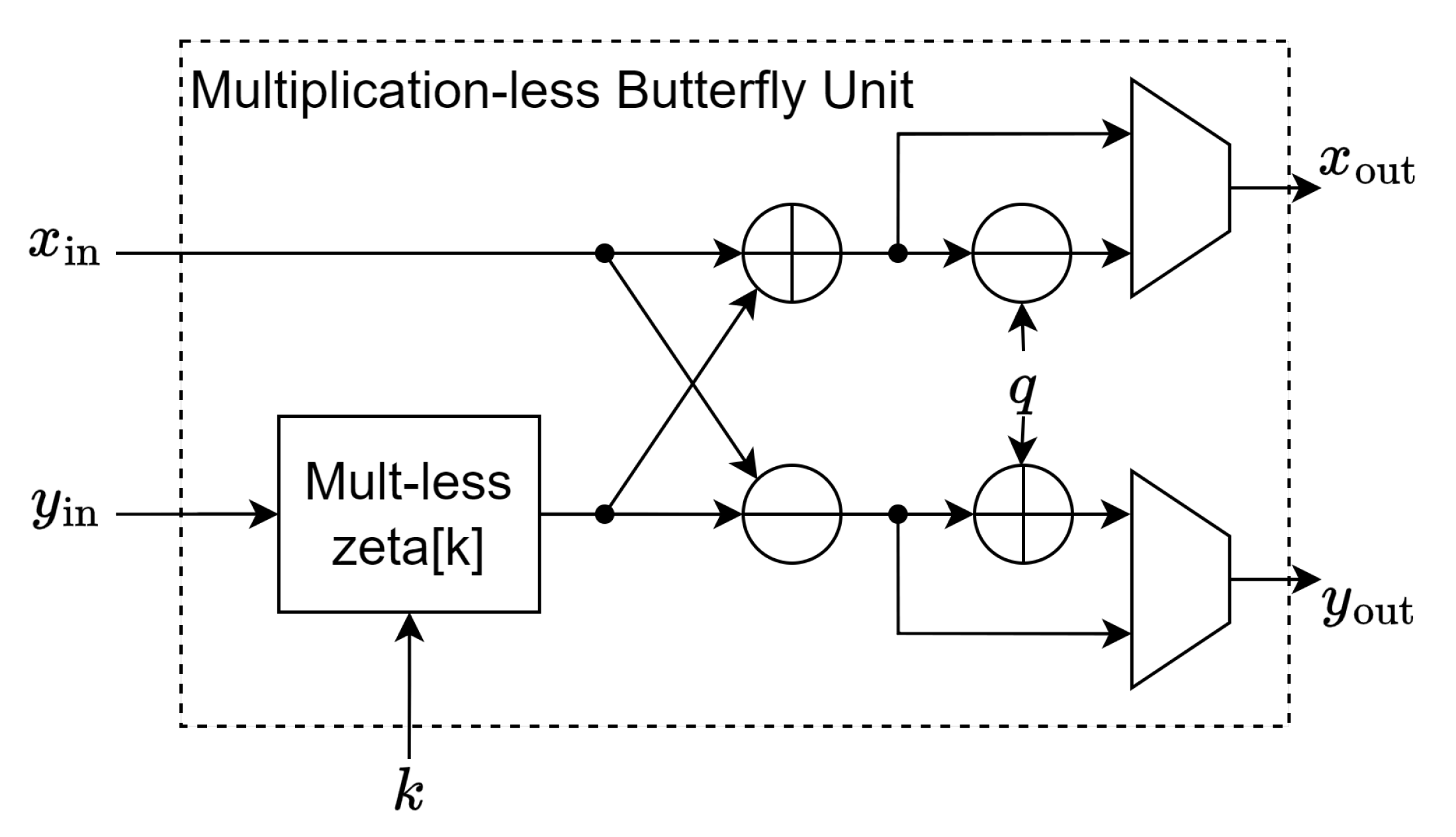
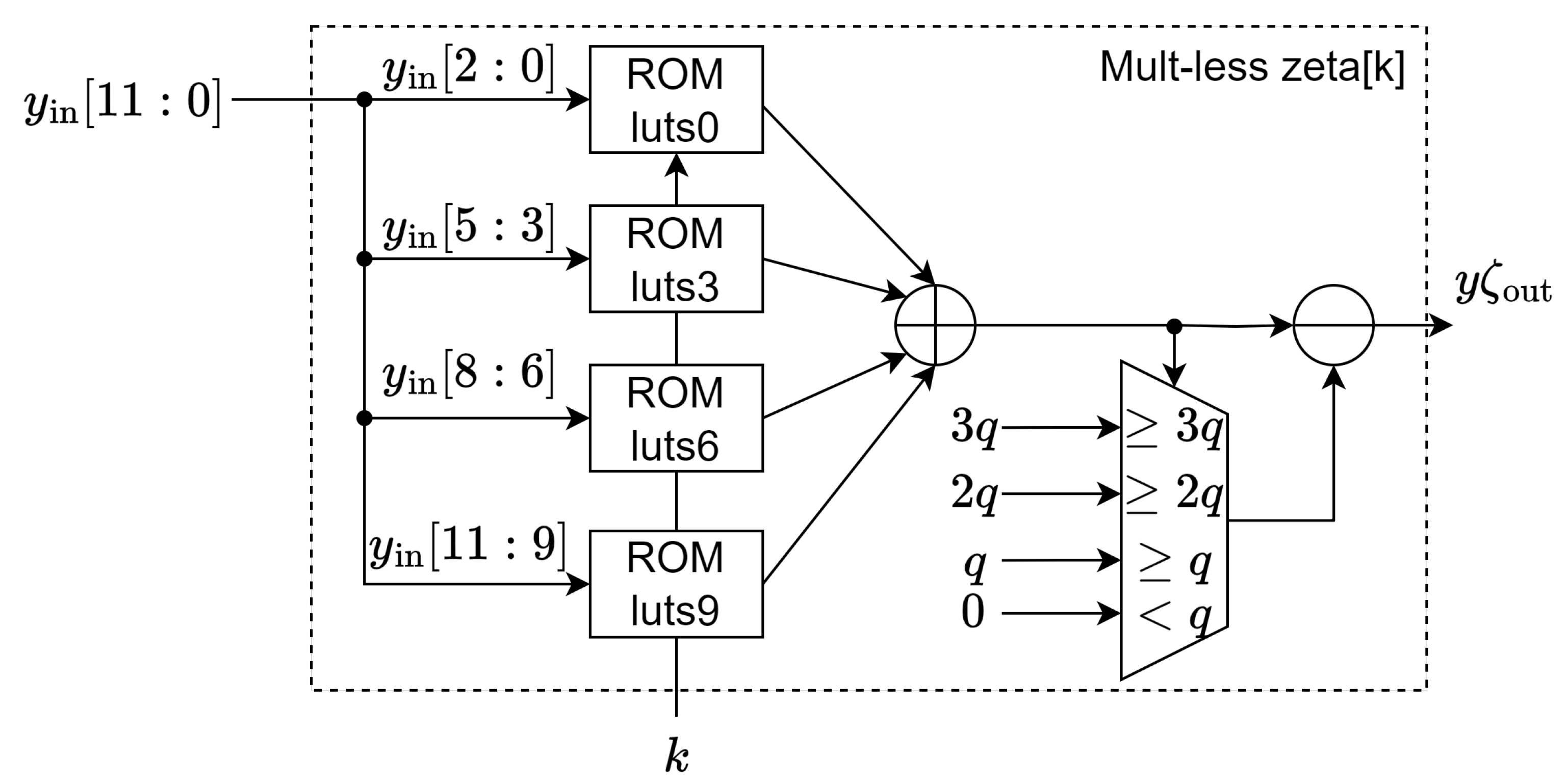
- We also proposed two novel butterfly units that are DSP-free and have low resource utilization. The most expensive operation of the butterfly unit in NTT, in terms of resources and time, is the modular multiplication of the coefficient with the root of unities. The first approach we developed utilizes the fact that, with parameter , which means the coefficient is up to long, we can split the parameter to the sum of multiple precomputed products with the roots of unity and can completely eliminate the full multiplication and as well as the need for dedicated storage for the root of unitie.
- 3.
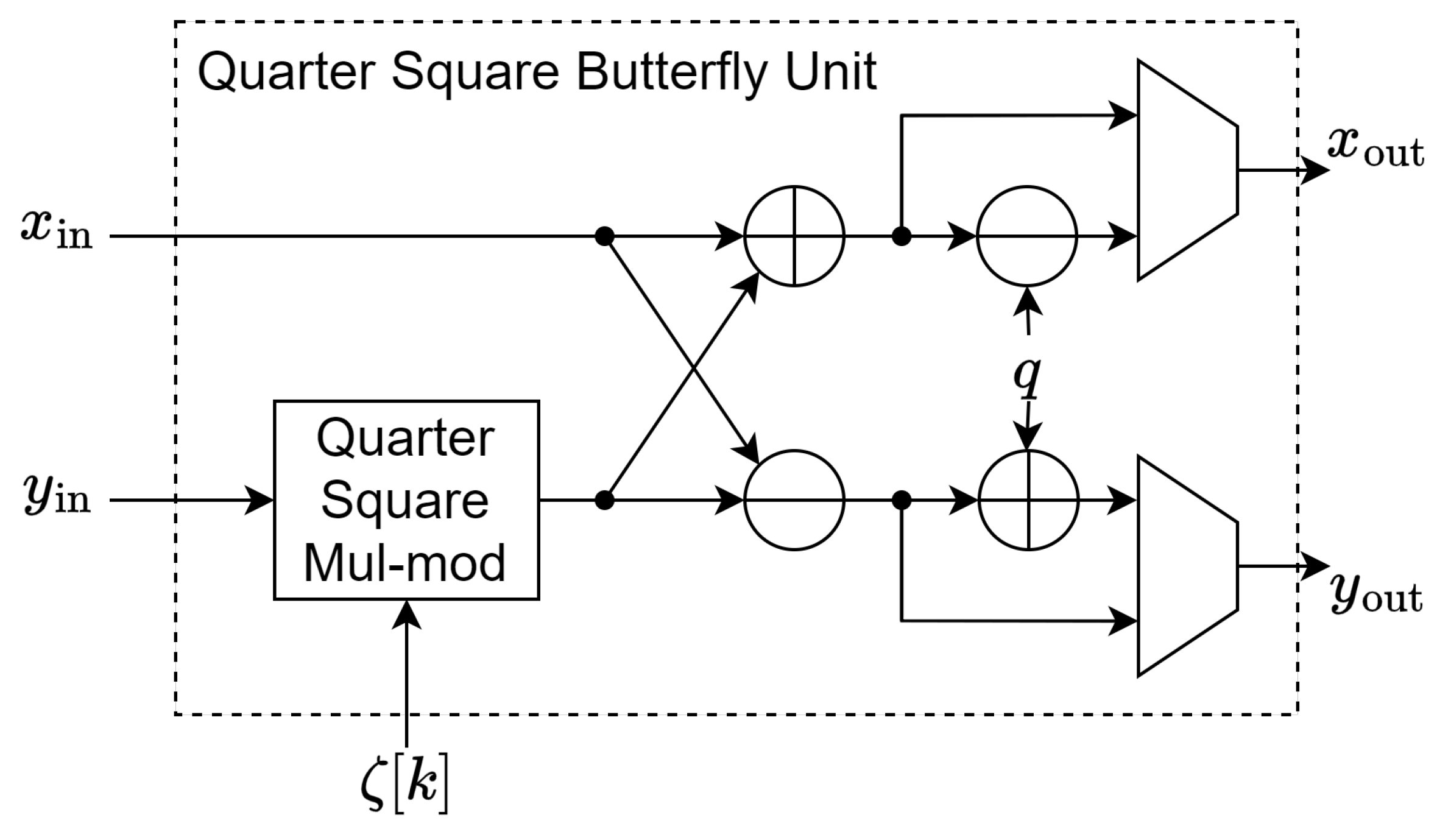
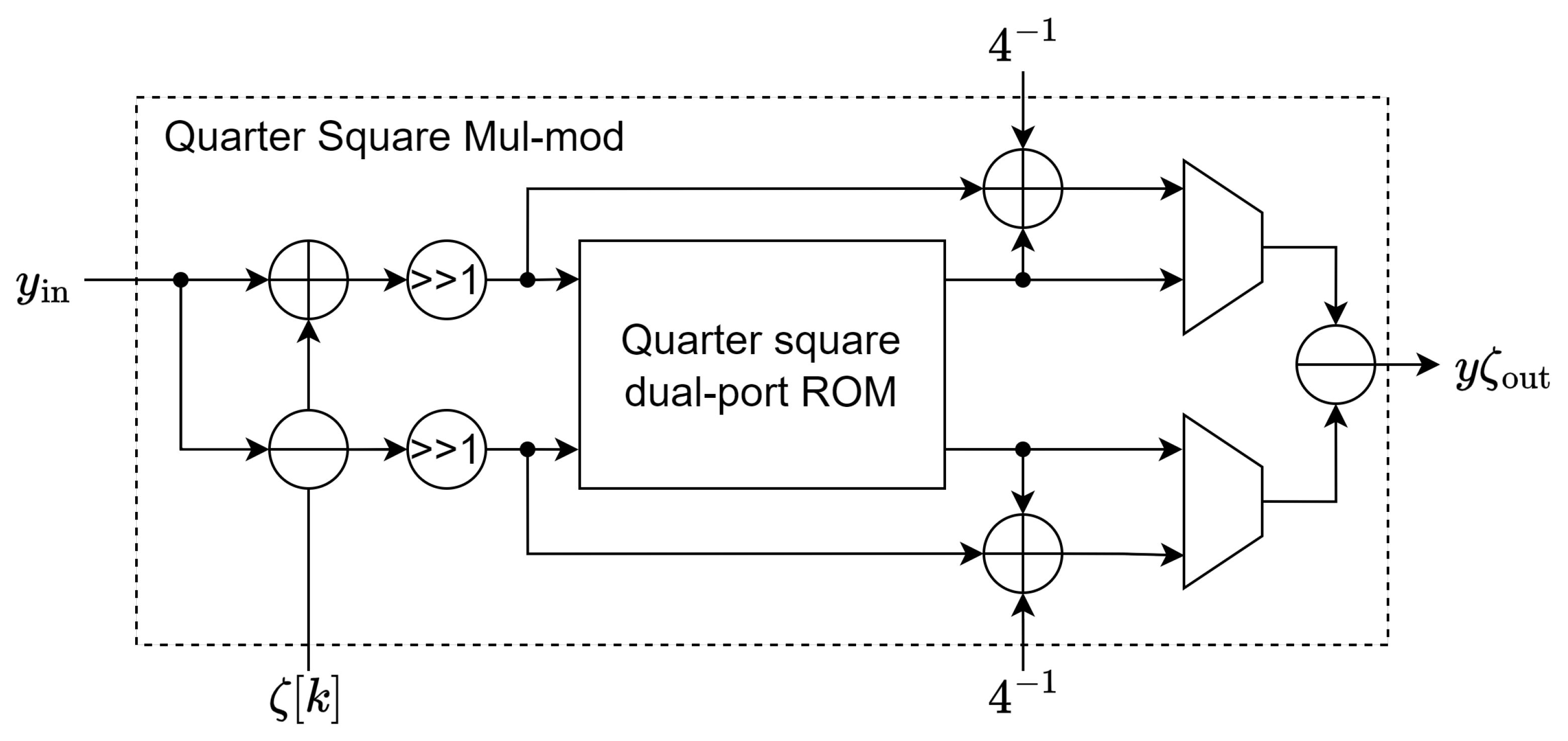
- The second butterfly unit we constructed utilizes quarter square multiplication to perform modular multiplication , by realizing the fact that although a multiplication typically requires a -depth look-up table, squares only requires . Therefore, by replacing multiplication by squares with additional processing, we can fit the quarter squares on a single dual-port ROM that fits neatly onto one BRAM. This approach also avoids the need for the full product to be computed and reduced.
- 4.
- We developed a detailed pipelined butterfly unit based on the proposed approach with a short critical path that can thus operate at a higher frequency.
- 5.
- Finally, we synthesized place and route (PnR) and verified its functionality on an Xilinx Artix-7 FPGA, which can run at up to 417 MHz.
2. Background Knowledge
| Algorithm 1: Cooley–Tukey forward NTT |
 |
| Algorithm 2: Gentleman–Sande inverse NTT |
 |
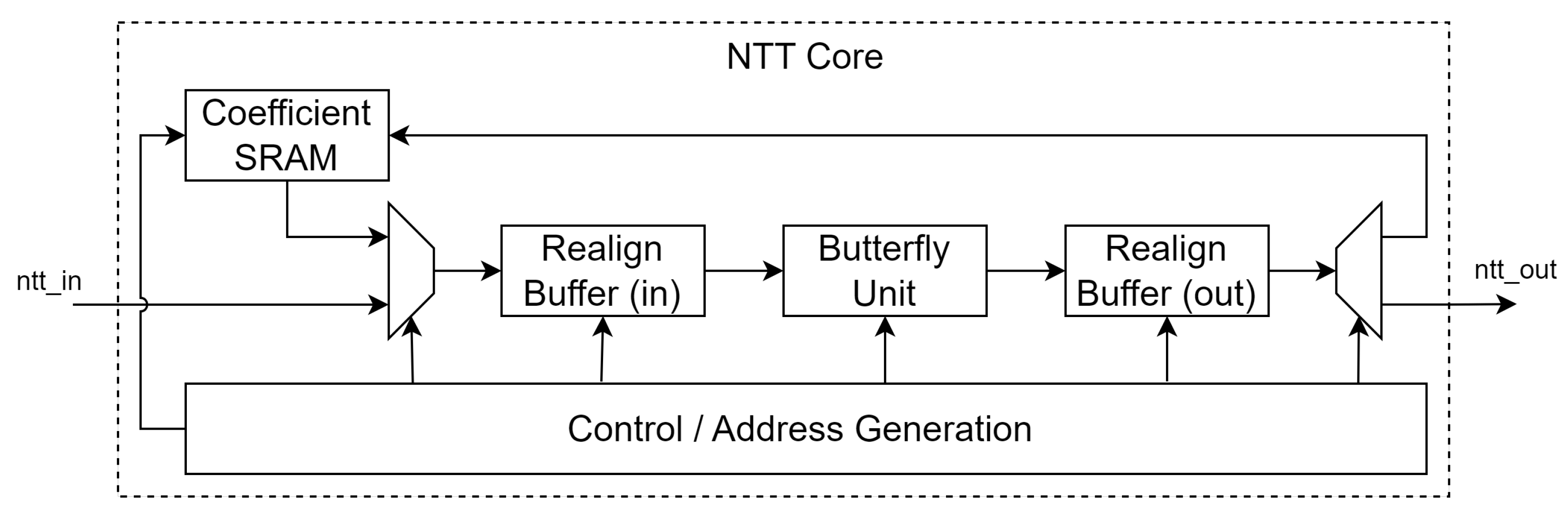
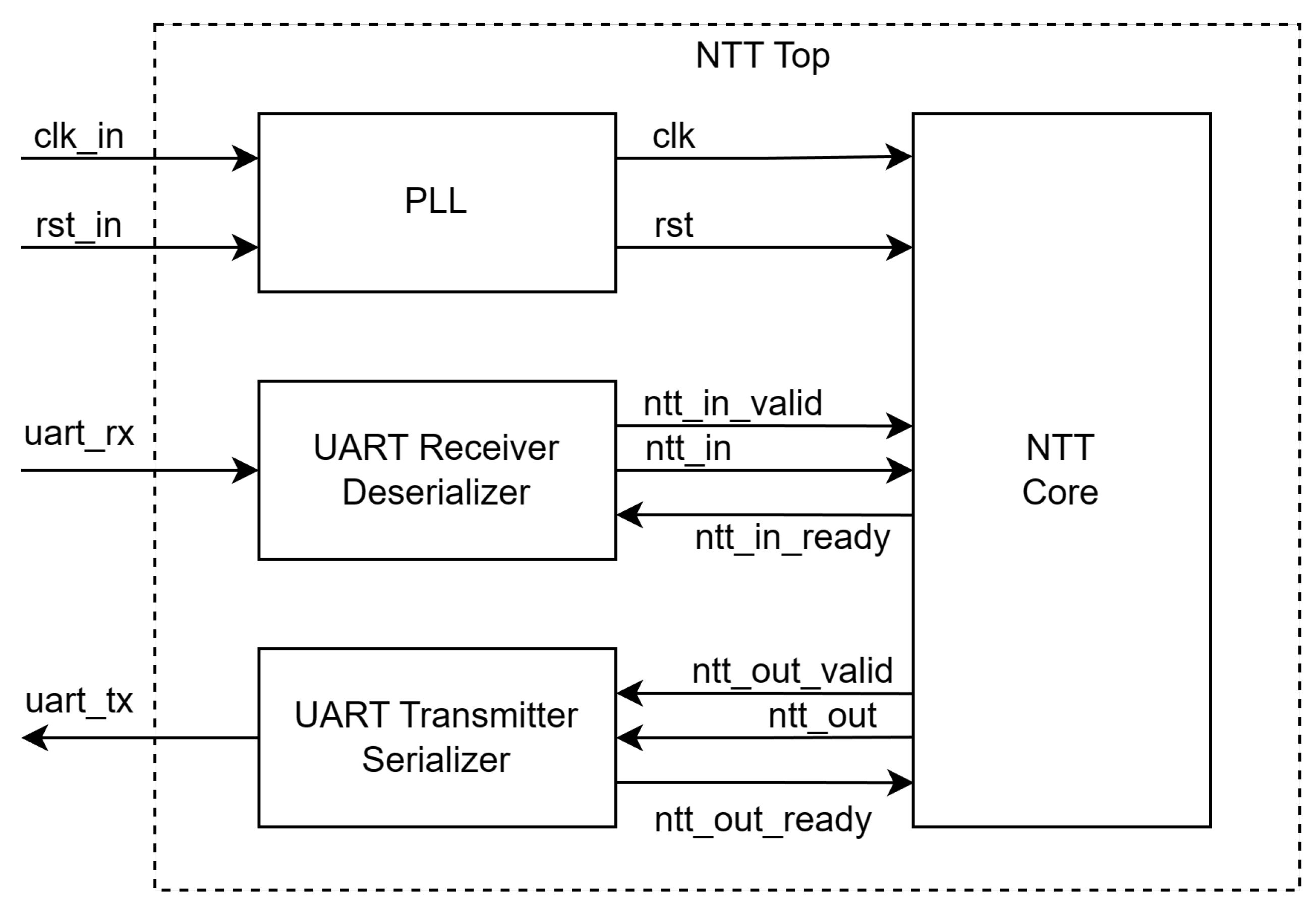
3. Proposed NTT Architecture
3.1. Butterfly Unit
3.1.1. Multiplicationless Method
3.1.2. Quarter Square Multiplication Method
3.1.3. Hybrid Butterfly Unit
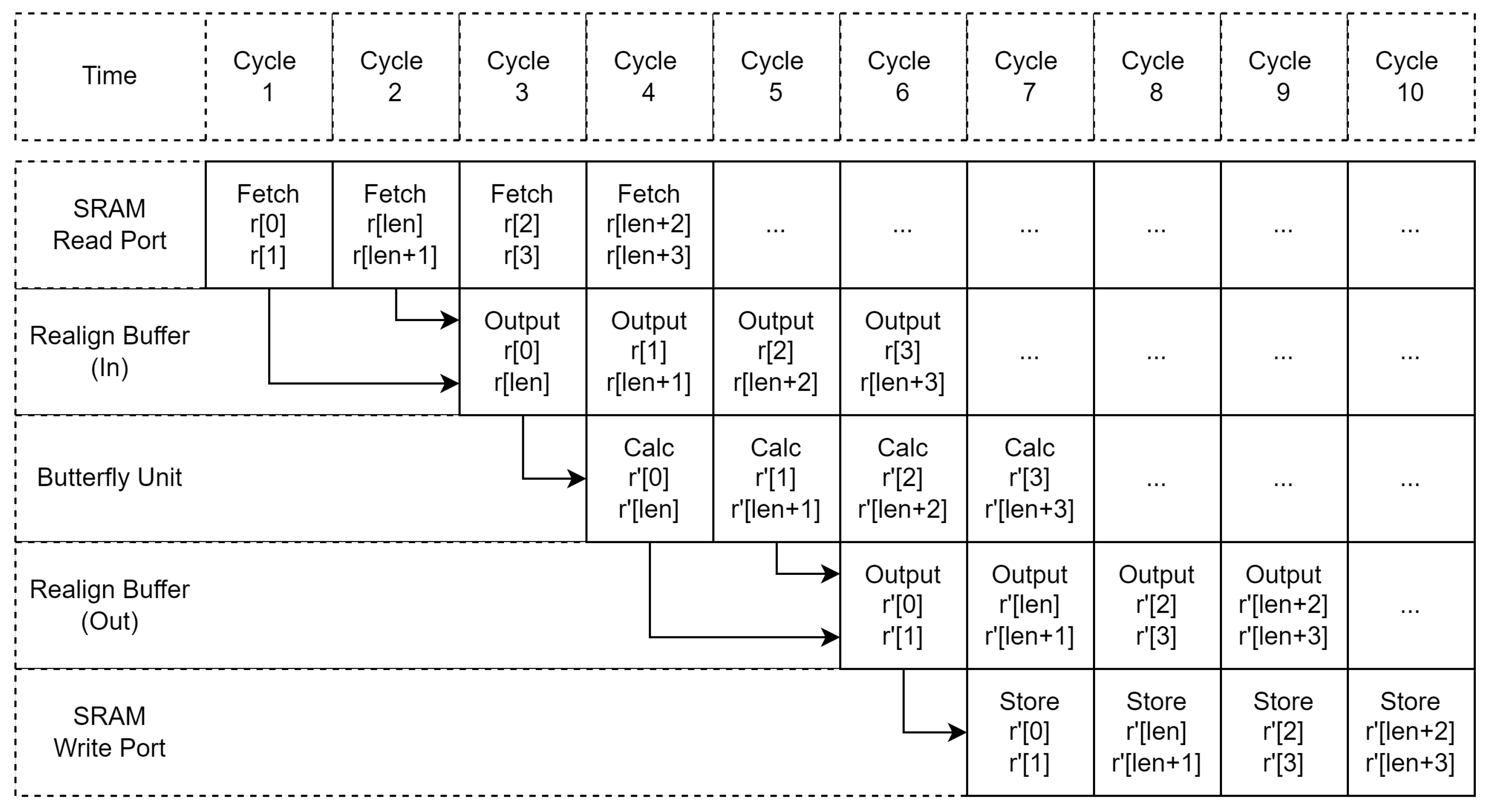
3.2. Realign Buffer
4. Experimental Results
4.1. Experimental Setup
| Algorithm 3: UART software driver |
 |
4.2. Results and Comparison
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J. Sci. Statist. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Grover, L.K. A Fast Quantum Mechanical Algorithm for Database Search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996; pp. 212–219. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A Method for Obtaining Digital Signatures and Public-key Cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Miller, V.S. Use of Elliptic Curves in Cryptography. In Proceedings of the Advances in Cryptology (CRYPTO), Santa Barbara, CA, USA, 18–22 August 1985; pp. 417–426. [Google Scholar]
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehle, D.D. CRYSTALS—Kyber: A CCA-Secure Module-Lattice-Based KEM. In Proceedings of the European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 353–367.
- Lyubashevsky, V.; Peikert, C.; Regev, O. On Ideal Lattices and Learning with Errors Over Rings. In Proceedings of the Advances in Cryptology (EUROCRYPT), Santa Barbara, CA, USA, 15–19 August 2010; pp. 1–23. [Google Scholar]
- Lindner, R.; Peikert, C. Better Key Sizes (and Attacks) for LWE-Based Encryption. In Proceedings of the Topics in Cryptology (CT-RSA), San Francisco, CA, USA, 14–18 February 2011; pp. 319–339. [Google Scholar]
- Das, M.; Jajodia, B.B. Hardware Design of Optimized Large Integer Schoolbook Polynomial Multiplications on FPGA. In Proceedings of the International SoC Design Conference (ISOCC), Gangneung-si, Republic of Korea, 19–22 October 2022; pp. 65–66. [Google Scholar]
- Zhang, Y.; Cui, Y.; Ni, Z.; Kundi, D.; Liu, D.; Liu, W. A Lightweight and Efficient Schoolbook Polynomial Multiplier for Saber. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2251–2255. [Google Scholar]
- Birgani, Y.A.; Timarchi, S.; Khalid, A. Area-Time-Efficient Scalable Schoolbook Polynomial Multiplier for Lattice-Based Cryptography. IEEE Trans. Circ. Syst. II Express Briefs (TCAS-II) 2022, 69, 5079–5083. [Google Scholar] [CrossRef]
- Yang, S.; Liu, D.; Hu, A.; Li, A.; Zhang, J.; Li, X.; Lu, J.; Mo, C. An Instruction-configurable Post-quantum Cryptographic Processor Towards NTRU. In Proceedings of the Asian Hardware Oriented Security and Trust Symposium (AsianHOST), Singapore, 14–16 December 2022; pp. 1–6. [Google Scholar]
- Wong, Z.Y.; Wong, D.C.K.; Lee, W.K.; Mok, K.M.; Yap, W.S.; Khalid, A. KaratSaber: New Speed Records for Saber Polynomial Multiplication Using Efficient Karatsuba FPGA Architecture. IEEE Trans. Comput. 2023, 72, 1830–1842. [Google Scholar] [CrossRef]
- Ghosh, A.; Mera, J.M.B.; Karmakar, A.; Das, D.; Ghosh, S.; Verbauwhede, I.; Sen, S. A 334 μW 0.158 mm2 ASIC for Post-Quantum Key-Encapsulation Mechanism Saber With Low-Latency Striding Toom–Cook Multiplication. IEEE J. Solid-State Circ. 2023, 58, 2383–2398. [Google Scholar] [CrossRef]
- Wang, J.; Yang, C.; Zhang, F.; Meng, Y.; Su, Y. TCPM: A Reconfigurable and Efficient Toom-Cook-Based Polynomial Multiplier Over Rings Using a Novel Compressed Postprocessing Algorithm. IEEE Trans. Very Large Scale Integr. (Vlsi) Syst. 2023, 31, 1153–1166. [Google Scholar] [CrossRef]
- Ye, Z.; Cheung, R.; Huang, K. PipeNTT: A Pipelined Number Theoretic Transform Architecture. IEEE Trans. Circ. Syst. II Express Briefs (TCAS-II) 2022, 69, 4068–4072. [Google Scholar] [CrossRef]
- Xin, M.; Xu, C.; Huang, K.; Yu, H.; Yao, H.; Jiang, X.; Liu, D. Implementation of Number Theoretic Transform Unit for Polynomial Multiplication of Lattice-based Cryptography. In Proceedings of the International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 14–16 January 2022; pp. 323–327. [Google Scholar]
- Nguyen, T.H.; Binh, K.D.N.; Pham, C.K.; Hoang, T.T. High-Speed NTT Accelerator for CRYSTAL-Kyber and CRYSTAL-Dilithium. IEEE Access 2024, 12, 34918–34930. [Google Scholar] [CrossRef]
- Gauss, C.F. Nachlass: Theoria Interpolationis Methodo Nova Tractata. Carl Friedrich Gauss 1866, 3, 265–303. [Google Scholar]
- Pollard, J.M. The Fast Fourier Transform in a Finite Field. Math. Comput. 1971, 25, 365–374. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, D.; Liu, X.; Zou, X.; Niu, G.; Liu, B.; Jiang, Q. Towards Efficient Hardware Implementation of NTT for Kyber on FPGAs. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021. [Google Scholar]
- Ni, Z.; Khalid, A.; Liu, W.; O’Neill, M. Towards a Lightweight CRYSTALS-Kyber in FPGAs: An Ultra-lightweight BRAM-free NTT Core. In Proceedings of the IEEE International Symposium on Circuits and Systems 2023, Monterey, CA, USA, 21–25 May 2023. [Google Scholar]
- Imran, M.; Khan, S.; Khalid, A.; Rafferty, C.; Shah, Y.A.; Pagliarini, S.; Rashid, M.; O’Neill, M. Evaluating NTT/INTT Implementation Styles for Post-Quantum Cryptography. IEEE Embed. Syst. Lett. 2024; early access. [Google Scholar] [CrossRef]
- Yang, H.; Chen, R.; Wang, Q.; Wu, Z.; Peng, W. Hardware Acceleration of NTT-Based Polynomial Multiplication in CRYSTALS-Kyber. In Information Security and Cryptology; Ge, C., Yung, M., Eds.; Springer: Singapore, 2024; pp. 111–129. [Google Scholar]
- Longa, P.; Naehrig, M. Speeding Up the Number Theoretic Transform for Faster Ideal Lattice-Based Cryptography. Cryptology ePrint Archive, Paper 2016/504, 2016. Available online: https://eprint.iacr.org/2016/504 (accessed on 7 July 2024).
- Niasar, M.B.; Azarderakhsh, R.; Kermani, M.M. Instruction-Set Accelerated Implementation of CRYSTALS-Kyber. IEEE Trans. Circ. Syst. I Regul. Pap. (TCAS-I) 2021, 68, 4648–4659. [Google Scholar] [CrossRef]
- Bisheh-Niasar, M.; Azarderakhsh, R.; Mozaffari-Kermani, M. High-Speed NTT-based Polynomial Multiplication Accelerator for Post-Quantum Cryptography. In Proceedings of the 2021 IEEE 28th Symposium on Computer Arithmetic (ARITH), Lyngby, Denmark, 14–16 June 2021. [Google Scholar]
- Yaman, F.; Mert, A.C.; Öztürk, E.; Savas, E. A Hardware Accelerator for Polynomial Multiplication Operation of CRYSTALS-KYBER PQC Scheme. In Proceedings of the 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 1–5 February 2021. [Google Scholar]
- Xing, Y.; Li, S. A Compact Hardware Implementation of CCA-Secure Key Exchange Mechanism CRYSTALS-KYBER on FPGA. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 328–356. [Google Scholar] [CrossRef]
- Matteo, S.D.; Sarno, I.; Saponara, S. CRYPHTOR: A Memory-Unified NTT-Based Hardware Accelerator for Post-Quantum CRYSTALS Algorithms. IEEE Access 2024, 12, 25501–25511. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mode | LUTs | FFs | DSPs | BRAMs (18 Kb) | Freq (MHz) | Cycles | Time (s) | Platform | LUT ATP | FF ATP | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| This () ×2 | ◐ | 429 | 538 | 0 | 4 | 446 | 459 | 1.03 | Artix-7 | 441.87 | 554.14 |
| This () ×1 (quarter sq.) | ◐ | 379 | 414 | 0 | 1 | 435 | 910 | 2.05 | Artix-7 | 792.11 | 865.26 |
| [23] (FNTT) | ◐ | 9187 | 9328 | 0 | 0 | 100 | 1410 | 14.10 | Virtex-7 | 129,536.7 | 131,524.8 |
| This () ×2 | 541 | 680 | 0 | 4 | 417 | 461 | 1.10 | Artix-7 | 595.10 | 748.00 | |
| [27] | 810 | 717 | 4 | 2 | 222 | 324 | 1.46 | Artix-7 | 1182.60 | 1046.82 | |
| [21] | 609 | 640 | 2 | 4 | 257 | 490 | 1.91 | Artix-7 | 1163.19 | 1222.40 | |
| [22] | 1154 | 1031 | 2 | 0 | 300 | 456 | 1.52 | Zynq US+ | 1754.08 | 1567.12 | |
| [26] ×1 | 360 | 145 | 3 | 2 | 115 | 940 | 8.17 | Artix-7 | 2941.20 | 1184.65 | |
| [26] ×2 | 737 | 290 | 6 | 4 | 115 | 474 | 4.12 | Artix-7 | 3036.44 | 1194.80 | |
| [28] ×1 | 948 | 325 | 1 | 5 | 190 | 904 | 4.76 | Artix-7 | 4512.48 | 1547.00 | |
| [28] ×4 | 2543 | 792 | 4 | 18 | 182 | 232/233 | 1.27 | Artix-7 | 3229.61 | 1005.84 | |
| [28] ×16 | 9508 | 2684 | 16 | 70 | 172 | 69/71 | 0.40 | Artix-7 | 3803.20 | 1073.60 | |
| [29] | 1737 | 1167 | 2 | 3 | 161 | 512 | 3.18 | Artix-7 | 5523.66 | 3711.06 | |
| [23] (UNTT) | 9298 | 9402 | 0 | 0 | 20 | 1410 | 70.50 | Virtex-7 | 655,509.0 | 662,841.0 | |
| [24] | 4969 | 1616 | 9 | 35 | N/A | 126/127 | N/A | Artix-7 | N/A | N/A | |
| [30] | 1243 | 562 | 11 | 7 | 118 | 933 | 7.91 | Artix-7 | 9832.13 | 4445.42 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kieu-Do-Nguyen, B.; The Binh, N.; Pham-Quoc, C.; Nghi, H.P.; Tran, N.-T.; Hoang, T.-T.; Pham, C.-K. Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS Kyber Postquantum Cryptography Scheme. Information 2024, 15, 400. https://doi.org/10.3390/info15070400
Kieu-Do-Nguyen B, The Binh N, Pham-Quoc C, Nghi HP, Tran N-T, Hoang T-T, Pham C-K. Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS Kyber Postquantum Cryptography Scheme. Information. 2024; 15(7):400. https://doi.org/10.3390/info15070400
Chicago/Turabian StyleKieu-Do-Nguyen, Binh, Nguyen The Binh, Cuong Pham-Quoc, Huynh Phuc Nghi, Ngoc-Thinh Tran, Trong-Thuc Hoang, and Cong-Kha Pham. 2024. "Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS Kyber Postquantum Cryptography Scheme" Information 15, no. 7: 400. https://doi.org/10.3390/info15070400
APA StyleKieu-Do-Nguyen, B., The Binh, N., Pham-Quoc, C., Nghi, H. P., Tran, N.-T., Hoang, T.-T., & Pham, C.-K. (2024). Compact and Low-Latency FPGA-Based Number Theoretic Transform Architecture for CRYSTALS Kyber Postquantum Cryptography Scheme. Information, 15(7), 400. https://doi.org/10.3390/info15070400