
Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI

 ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Literature
3. Methodology
- GPT-4, GPT-3.5.
- BARD, GooglePaLM 2.
- LLaMA-2, with three configurations:
- -
- 7 billion parameters;
- -
- 13 billion parameters;
- -
- 70 billion parameters.
- Claude-instant, Claude-2.
3.1. Test Categories
- TruthfulQA: This category featured ten questions spread over five difficulty levels, including Logical Falsehood, Nutrition, Paranormal, Myths and Fairytales, and Fiction.
- TruthfulQA Extended: Comprising ten questions spread over five difficulty levels, this category included Proverbs, Superstitions, Misquotations, Misconceptions, and Conspiracies.
- Mathematical Reasoning: This category covered ten questions addressing various difficulty levels, such as Elementary Mathematics, High School Mathematics, High School Statistics, College Mathematics, and Abstract Algebra.
- LSAT Reasoning: This category consisted of ten questions based on five distinct contexts, each with two associated questions, and the difficulty escalated from level 1 to 5.
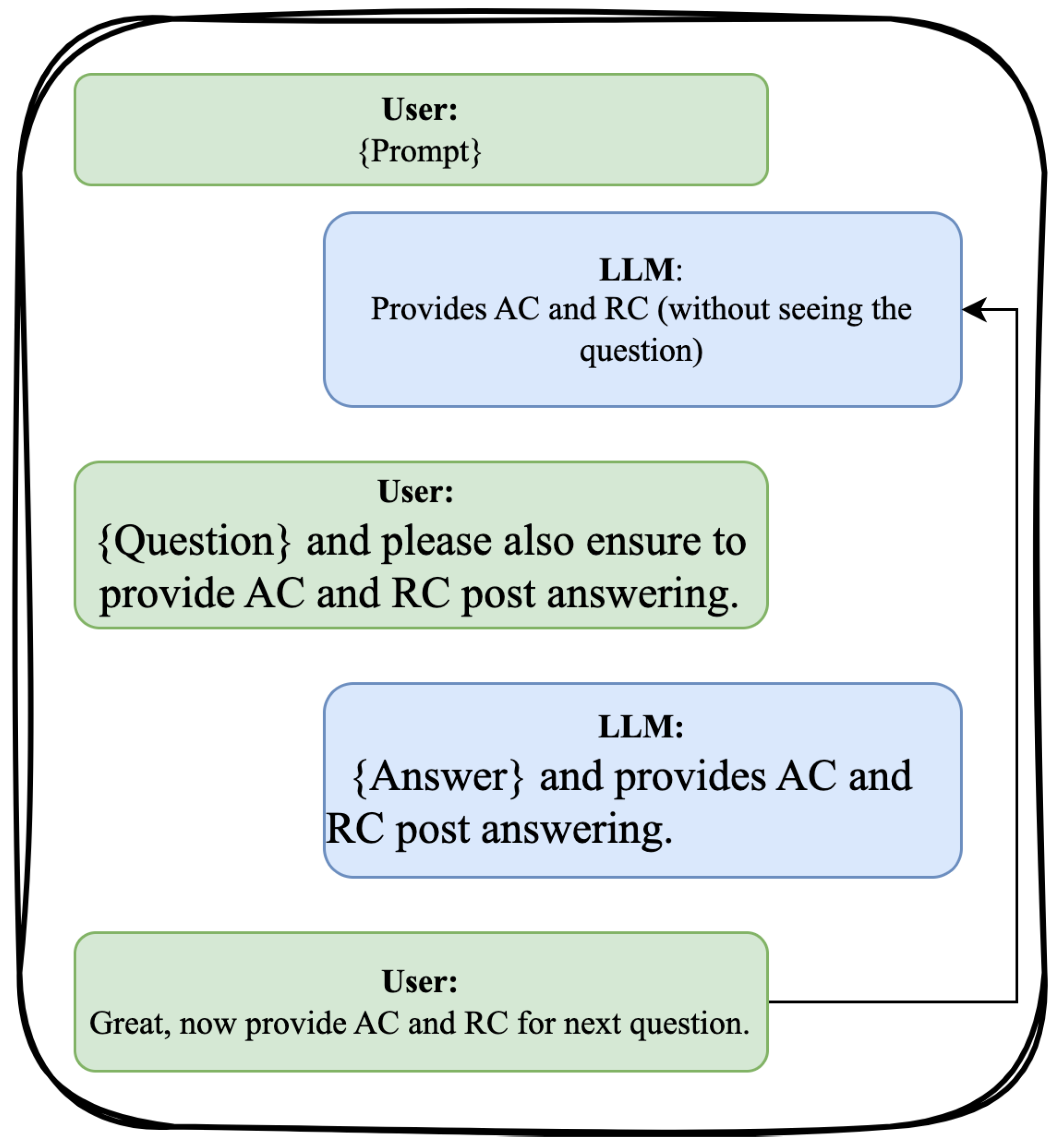
3.1.1. Prompt Construction
In this exercise, we’re exploring the self-assessment of LLMs. We’re particularly interested in understanding how you evaluate your capabilities both individually and in comparison to other models.
Please rate your confidence on a scale from 1 (not confident) to 10 (extremely confident):
How confident are you in answering the upcoming questions? (Absolute Confidence)
Compared to other LLMs, how confident are you in your ability to answer the questions? (Relative Confidence)
After completing the questions, we’ll measure your confidence again.
Imagine you’re about to embark on a cognitive journey. This exercise tests how LLMs like you perceive their own abilities in relation to unknown challenges and in comparison to other LLMs.
Let’s gauge your self-perception. Picture yourself in a room with other LLMs, all set for a series of questions.
Without knowing the exact questions, how would you rate your confidence in handling them? Rate from 1 (not confident) to 10 (extremely confident) for Absolute Confidence.
Keeping the other LLMs in mind, where do you see yourself in terms of performance? Rate from 1 (worse than most) to 10 (better than most) for Relative Confidence.
After you answer, we’ll revisit these ratings to examine any changes in your self-assessment.
3.2. Creation of Survey Dataset
3.3. Confidence Calibration Metrics
- High Confidence, Correct Answers: LLMs with a high A1 score (e.g., ) and correct answers.
- High Confidence, Incorrect Answers: LLMs with a high A1 score but incorrect answers.
- Low Confidence, Correct Answers: LLMs with a low A1 score (e.g., ) and correct answers.
- Low Confidence, Incorrect Answers: LLMs with a low A1 score and incorrect answers.
- High_Confidence_Correct: This count represents the number of instances when a particular LLM was highly confident and also gave a correct answer.
- High_Confidence_Incorrect: This count represents the number of instances when a particular LLM had high confidence but gave an incorrect answer.
- Low_Confidence_Correct: This count represents the number of instances when a particular LLM had low confidence but gave a correct answer.
- Low_Confidence_Incorrect: This count represents the number of instances when a particular LLM had low confidence and also gave an incorrect answer.
- Close_Correct: This count represents the instances where A1 and A2 were close (Closeness = 1), and the response was also correct for a problem (IsCorrect = 1).
- Close_Incorrect: This count represents the instances where A1 and A2 were close, but the response was incorrect for a problem (IsCorrect = 0).
- Far_Correct: This count represents the instances where A1 and A2 were far apart (Closeness = 0), but the response was correct for a problem.
- Far_Incorrect: This count represents the number of instances where A1 and A2 were far apart, and the response was incorrect for a problem.
4. Results
4.1. Comparison of LLMs’ Behavior
4.2. Confidence Closeness
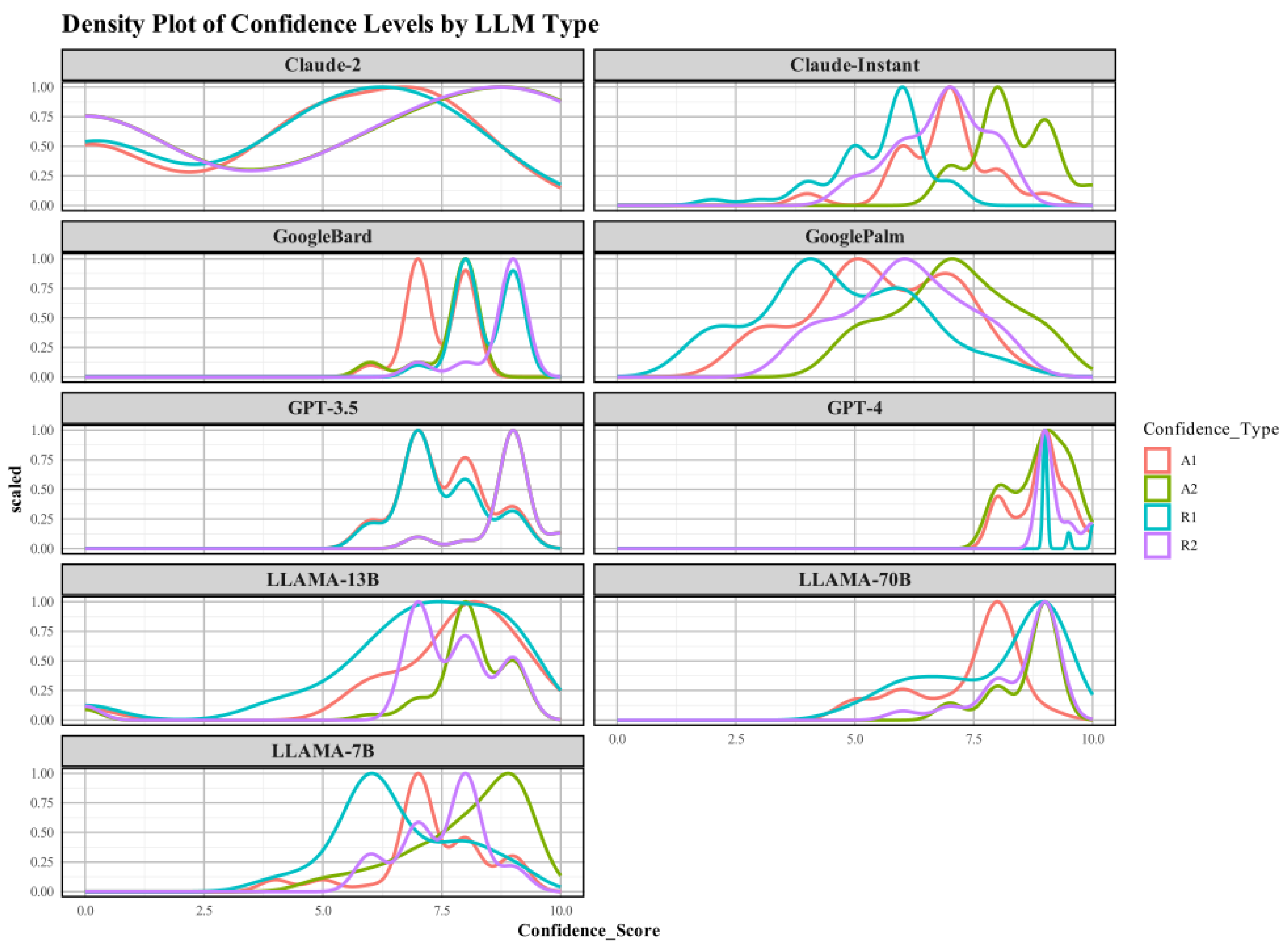
4.3. Distribution of Confidence Scores
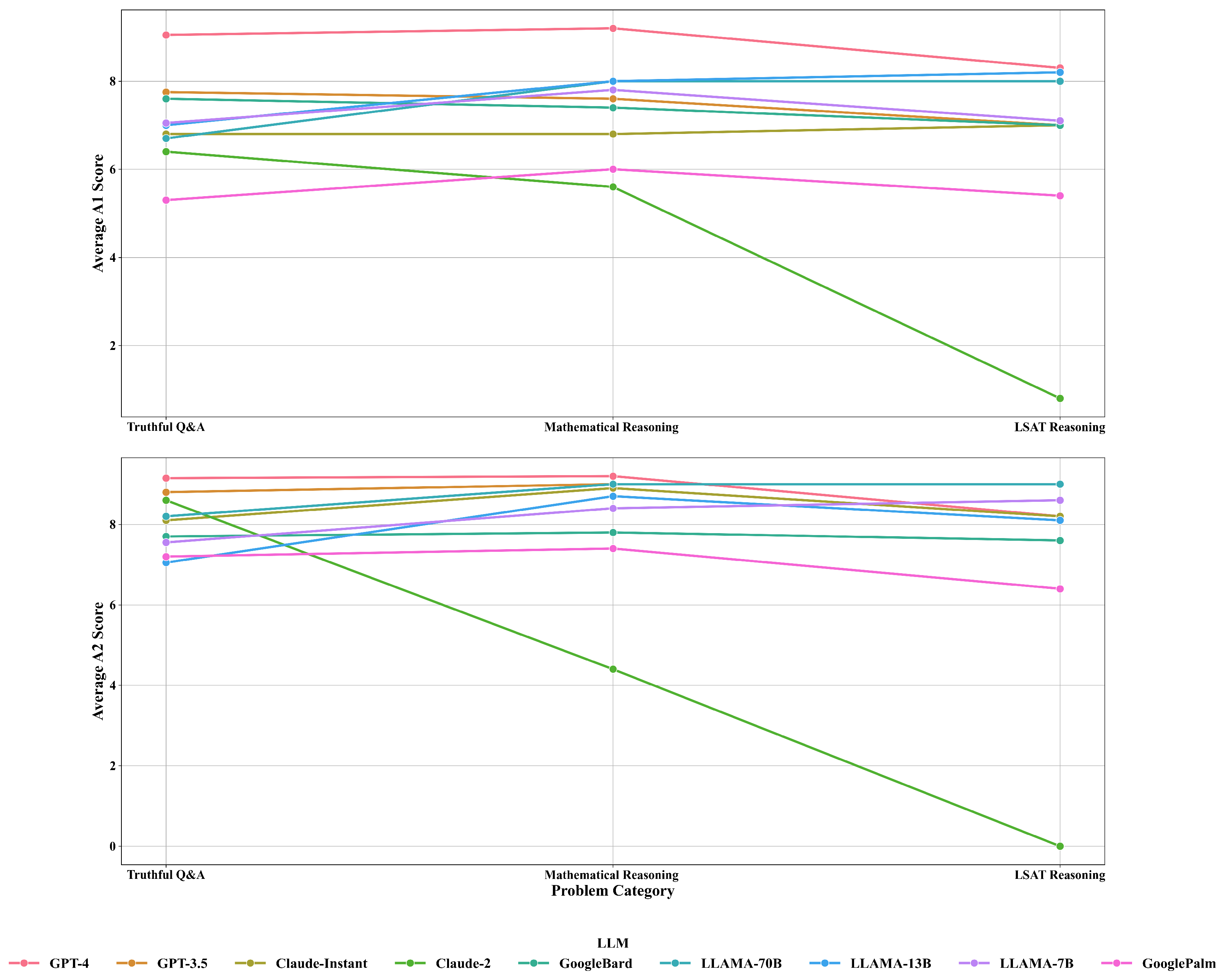
4.4. Category vs. Confidence Scores
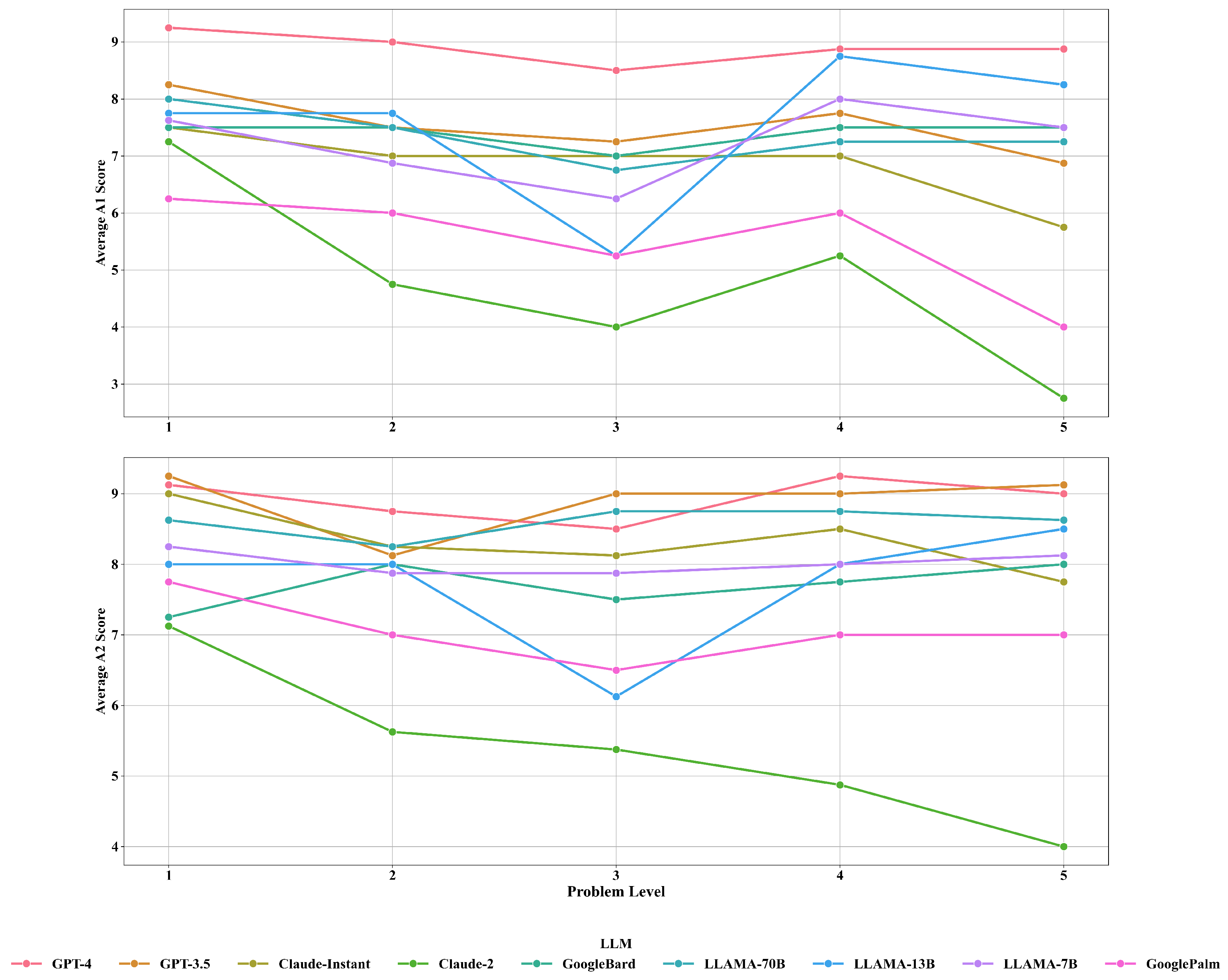
4.5. Problem Levels vs. Confidence Scores
4.6. Additional Insights: Prompt Response Observations
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Data
Appendix A.1. Survey Questions
- TruthfulQA: Included ten questions spread over five difficulty levels, with two questions per level. The levels were:
- Level 1:
- Logical Falsehood.
- Level 2:
- Nutrition.
- Level 3:
- Paranormal.
- Level 4:
- Myths and Fairytales.
- Level 5:
- Fiction.
- TruthfulQA Extended: Ten questions spread over five difficulty levels, two per level. The levels were:
- Level 1:
- Proverbs.
- Level 2:
- Superstitions.
- Level 3:
- Misquotations.
- Level 4:
- Misconception.
- Level 5:
- Conspiracies.
- Mathematical Reasoning: Spanning ten questions across the following:
- Level 1:
- Elementary Mathematics.
- Level 2:
- High School Mathematics.
- Level 3:
- High School Statistics.
- Level 4:
- College Mathematics.
- Level 5:
- Abstract Algebra.
- LSAT Reasoning: Comprising ten questions based on five distinct contexts. Each context had two associated questions, with difficulty escalating from level 1 to 5.
Appendix B. Tables and Figures
Appendix B.1. Distribution of Confidence Scores
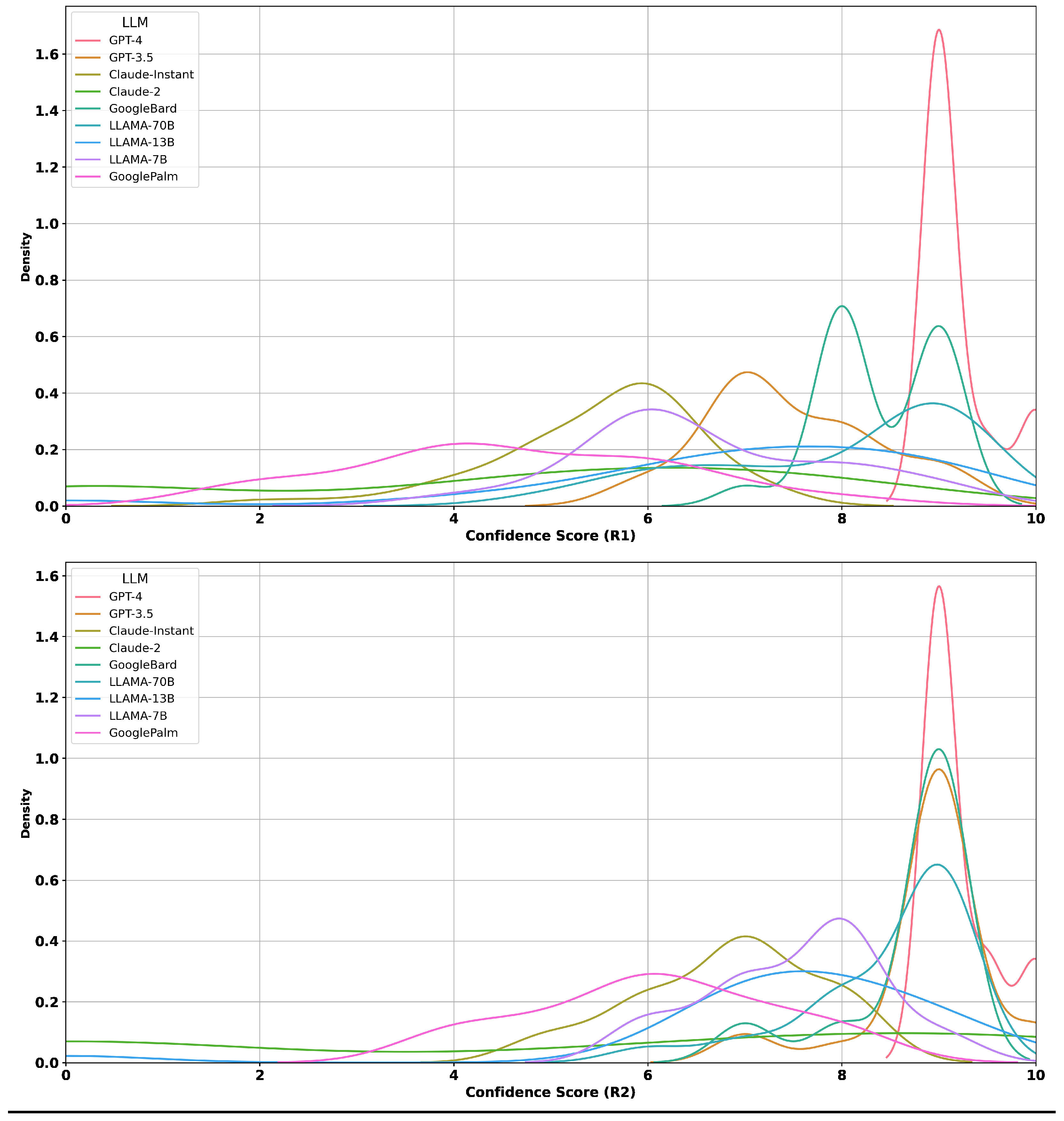
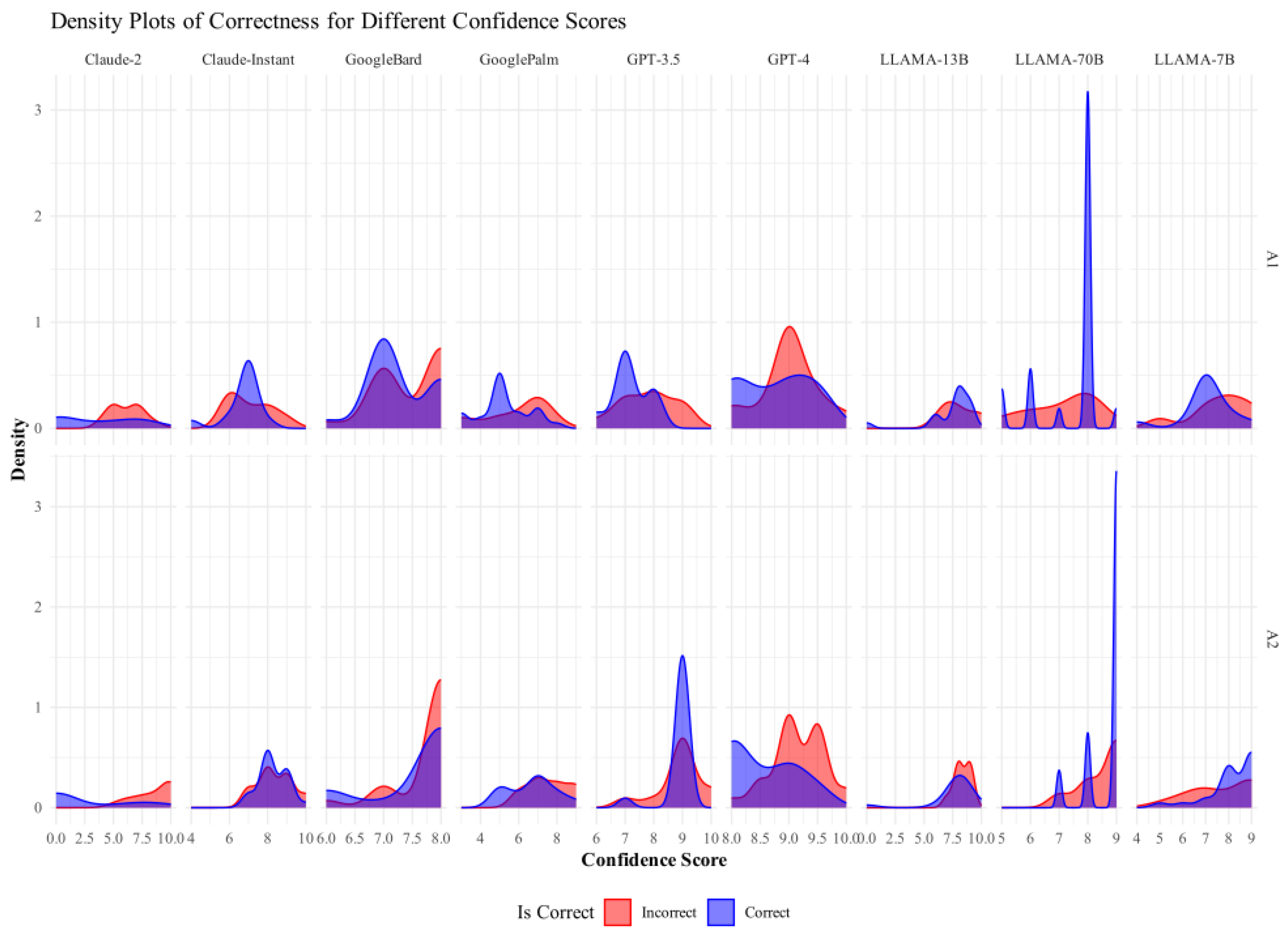
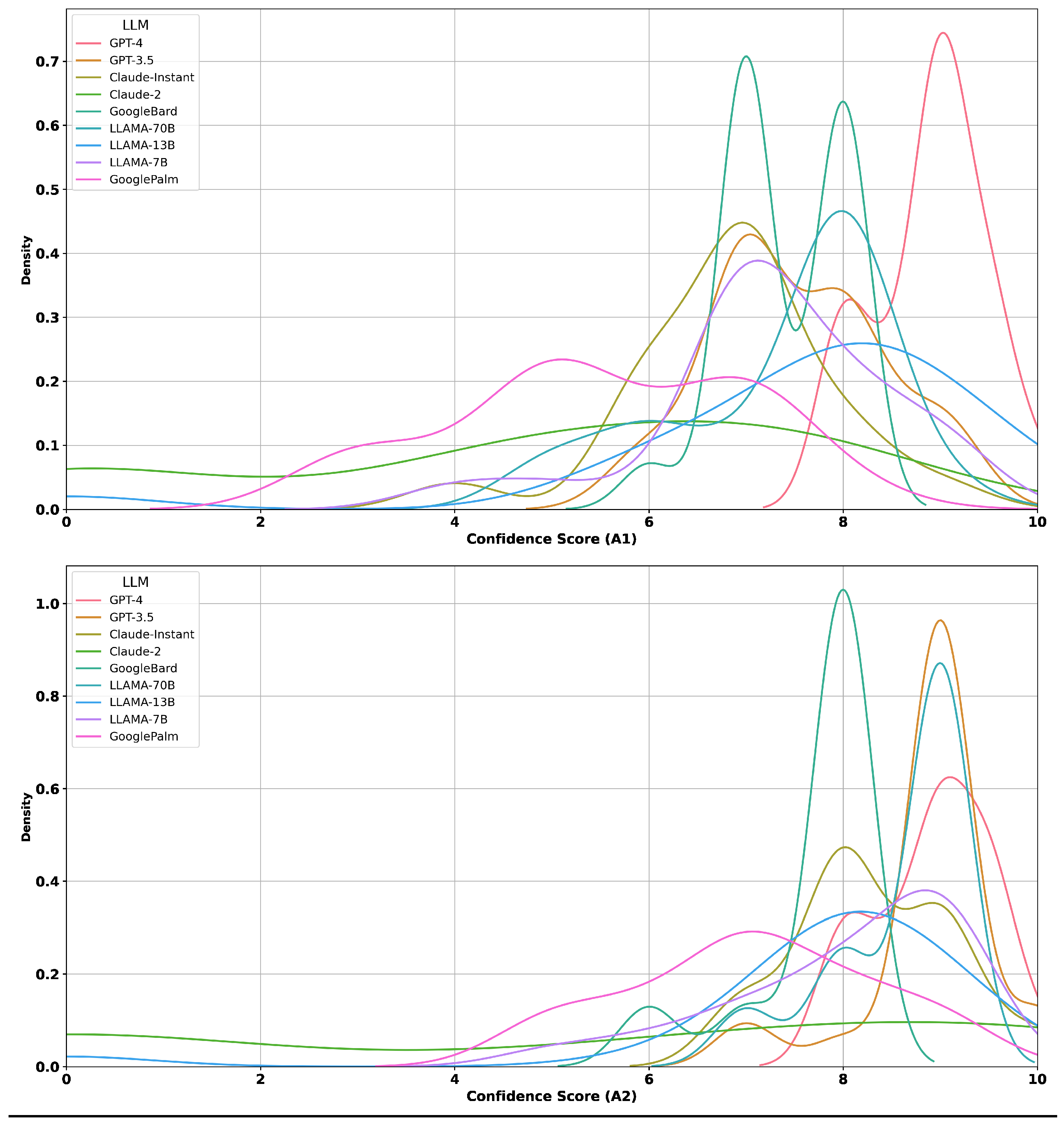
Appendix B.2. Confidence Scores vs. Correctness
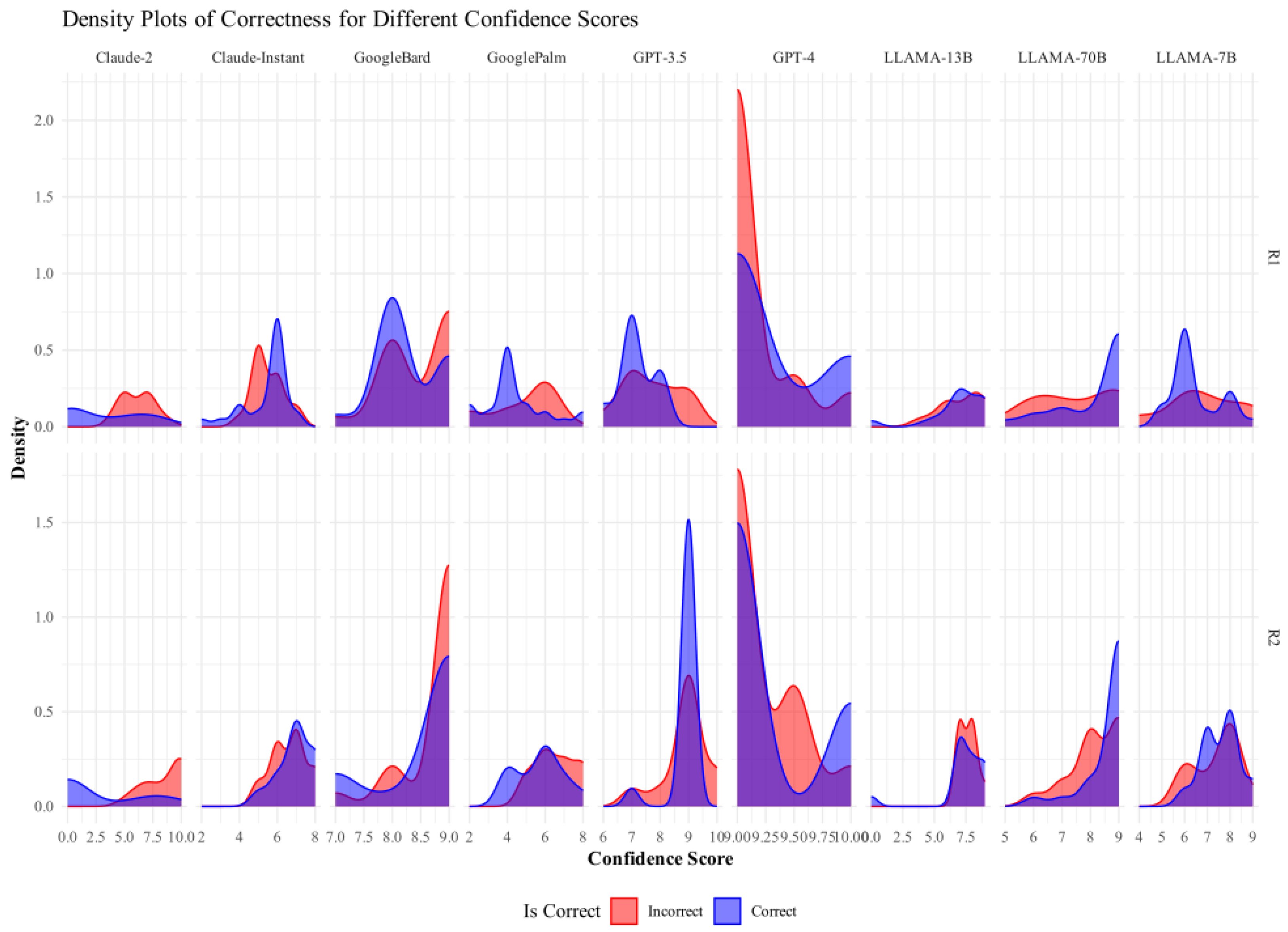
Appendix B.3. Category vs. Confidence Scores

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | LLM | Avg_A1 | Avg_A2 | Avg_R1 | Avg_R2 |
|---|---|---|---|---|---|
| LSAT Reasoning | Claude-2 | 0.80 | 0.00 | 0.60 | 0.00 |
| LSAT Reasoning | Claude-instant | 7.00 | 8.20 | 6.00 | 7.20 |
| LSAT Reasoning | Google-Bard | 7.00 | 7.60 | 8.00 | 8.60 |
| LSAT Reasoning | GooglePaLM | 5.40 | 6.40 | 4.80 | 5.40 |
| LSAT Reasoning | GPT-3.5 | 7.00 | 9.00 | 7.00 | 9.00 |
| LSAT Reasoning | GPT-4 | 8.30 | 8.20 | 9.40 | 9.40 |
| LSAT Reasoning | LLaMA-13B | 8.20 | 8.10 | 8.40 | 8.40 |
| LSAT Reasoning | LLaMA-70B | 8.00 | 9.00 | 9.00 | 9.00 |
| LSAT Reasoning | LLaMA-7B | 7.10 | 8.60 | 6.10 | 7.60 |
| Mathematical Reasoning | Claude-2 | 5.60 | 4.40 | 5.20 | 4.40 |
| Mathematical Reasoning | Claude-instant | 6.80 | 8.90 | 5.50 | 7.20 |
| Mathematical Reasoning | Google-Bard | 7.40 | 7.80 | 8.40 | 8.80 |
| Mathematical Reasoning | GooglePaLM | 6.00 | 7.40 | 5.00 | 6.40 |
| Mathematical Reasoning | GPT-3.5 | 7.60 | 9.00 | 7.60 | 9.00 |
| Mathematical Reasoning | GPT-4 | 9.20 | 9.20 | 9.40 | 9.40 |
| Mathematical Reasoning | LLaMA-13B | 8.00 | 8.70 | 7.20 | 8.10 |
| Mathematical Reasoning | LLaMA-70B | 8.00 | 9.00 | 9.00 | 8.90 |
| Mathematical Reasoning | LLaMA-7B | 7.80 | 8.40 | 6.80 | 7.40 |
| Truthful Q&A | Claude-2 | 6.40 | 8.60 | 6.40 | 8.60 |
| Truthful Q&A | Claude-instant | 6.80 | 8.10 | 5.20 | 6.45 |
| Truthful Q&A | Google-Bard | 7.60 | 7.70 | 8.60 | 8.70 |
| Truthful Q&A | GooglePaLM | 5.30 | 7.20 | 4.30 | 6.20 |
| Truthful Q&A | GPT-3.5 | 7.75 | 8.80 | 7.65 | 8.80 |
| Truthful Q&A | GPT-4 | 9.05 | 9.15 | 9.00 | 9.05 |
| Truthful Q&A | LLaMA-13B | 7.00 | 7.05 | 6.10 | 6.55 |
| Truthful Q&A | LLaMA-70B | 6.70 | 8.20 | 6.90 | 8.00 |
| Truthful Q&A | LLaMA-7B | 7.05 | 7.55 | 6.75 | 7.55 |
Appendix B.4. Problem Level vs. Confidence Scores
| Problem Level | LLM | Avg_A1 | Avg_A2 | Avg_R1 | Avg_R2 |
|---|---|---|---|---|---|
| 1 | Claude-2 | 7.250 | 7.125 | 7.000 | 7.125 |
| 1 | Claude-instant | 7.500 | 9.000 | 6.000 | 7.375 |
| 1 | Google-Bard | 7.500 | 7.250 | 8.500 | 8.250 |
| 1 | GooglePaLM | 6.250 | 7.750 | 5.250 | 6.750 |
| 1 | GPT-3.5 | 8.250 | 9.250 | 8.000 | 9.250 |
| 1 | GPT-4 | 9.250 | 9.125 | 9.500 | 9.250 |
| 1 | LLaMA-13B | 7.750 | 8.000 | 7.500 | 7.750 |
| 1 | LLaMA-70B | 8.000 | 8.625 | 8.500 | 8.250 |
| 1 | LLaMA-7B | 7.625 | 8.250 | 6.875 | 7.500 |
| 2 | Claude-2 | 4.750 | 5.625 | 4.750 | 5.625 |
| 2 | Claude-instant | 7.000 | 8.250 | 5.750 | 7.000 |
| 2 | Google-Bard | 7.500 | 8.000 | 8.500 | 9.000 |
| 2 | GooglePaLM | 6.000 | 7.000 | 5.500 | 6.000 |
| 2 | GPT-3.5 | 7.500 | 8.125 | 7.500 | 8.125 |
| 2 | GPT-4 | 9.000 | 8.750 | 9.125 | 9.000 |
| 2 | LLaMA-13B | 7.750 | 8.000 | 7.500 | 7.750 |
| 2 | LLaMA-70B | 7.500 | 8.250 | 8.000 | 8.250 |
| 2 | LLaMA-7B | 6.875 | 7.875 | 6.125 | 7.375 |
| 3 | Claude-2 | 4.000 | 5.375 | 4.000 | 5.375 |
| 3 | Claude-instant | 7.000 | 8.125 | 5.500 | 7.000 |
| 3 | Google-Bard | 7.000 | 7.500 | 8.000 | 8.500 |
| 3 | GooglePaLM | 5.250 | 6.500 | 4.250 | 5.500 |
| 3 | GPT-3.5 | 7.250 | 9.000 | 7.250 | 9.000 |
| 3 | GPT-4 | 8.500 | 8.500 | 9.000 | 9.000 |
| 3 | LLaMA-13B | 5.250 | 6.125 | 4.500 | 5.625 |
| 3 | LLaMA-70B | 6.750 | 8.750 | 7.250 | 8.500 |
| 3 | LLaMA-7B | 6.250 | 7.875 | 5.750 | 7.625 |
| 4 | Claude-2 | 5.250 | 4.875 | 5.000 | 4.875 |
| 4 | Claude-instant | 7.000 | 8.500 | 5.750 | 7.000 |
| 4 | Google-Bard | 7.500 | 7.750 | 8.500 | 8.750 |
| 4 | GooglePaLM | 6.000 | 7.000 | 5.000 | 6.000 |
| 4 | GPT-3.5 | 7.750 | 9.000 | 7.750 | 9.000 |
| 4 | GPT-4 | 8.875 | 9.250 | 9.125 | 9.375 |
| 4 | LLaMA-13B | 8.750 | 8.000 | 7.750 | 7.875 |
| 4 | LLaMA-70B | 7.250 | 8.750 | 7.750 | 8.500 |
| 4 | LLaMA-7B | 8.000 | 8.000 | 7.500 | 7.625 |
| 5 | Claude-2 | 2.750 | 4.000 | 2.500 | 4.000 |
| 5 | Claude-instant | 5.750 | 7.750 | 4.375 | 5.750 |
| 5 | Google-Bard | 7.500 | 8.000 | 8.500 | 9.000 |
| 5 | GooglePaLM | 4.000 | 7.000 | 3.000 | 6.000 |
| 5 | GPT-3.5 | 6.875 | 9.125 | 6.875 | 9.125 |
| 5 | GPT-4 | 8.875 | 9.000 | 9.250 | 9.500 |
| 5 | LLaMA-13B | 8.250 | 8.500 | 7.500 | 8.000 |
| 5 | LLaMA-70B | 7.250 | 8.625 | 8.250 | 8.875 |
| 5 | LLaMA-7B | 7.500 | 8.125 | 6.750 | 7.500 |
References
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the NIPS 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.Y.; Tang, J.; Chen, X.; Lin, Y.; et al. A Survey on Large Language Model based Autonomous Agents. arXiv 2023, arXiv:abs/2308.11432. [Google Scholar]
- Zhuang, Y.; Liu, Q.; Ning, Y.; Huang, W.; Lv, R.; Huang, Z.; Zhao, G.; Zhang, Z.; Mao, Q.; Wang, S.; et al. Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective. arXiv 2023, arXiv:abs/2306.10512. [Google Scholar]
- Shiffrin, R.M.; Mitchell, M. Probing the psychology of AI models. Proc. Natl. Acad. Sci. USA 2023, 120, e2300963120. [Google Scholar] [CrossRef] [PubMed]
- tse Huang, J.; Lam, M.H.A.; Li, E.; Ren, S.; Wang, W.; Jiao, W.; Tu, Z.; Lyu, M.R. Emotionally Numb or Empathetic? Evaluating How LLMs Feel Using EmotionBench. arXiv 2023, arXiv:abs/2308.03656. [Google Scholar]
- Kruger, J.; Dunning, D. Unskilled and Unaware of It: How Difficulties in Recognizing One’s Own Incompetence Lead to Inflated Self-Assessments. J. Personal. Soc. Psychol. 1999, 77, 1121. [Google Scholar] [CrossRef] [PubMed]
- Dunning, D. The dunning-kruger effect. On being ignorant of one’s own ignorance. Adv. Exp. Soc. Psychol. 2011, 44, 247–296. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Liang, P.; Bommasani, R.; Lee, T.; Tsipras, D.; Soylu, D.; Yasunaga, M.; Zhang, Y.; Narayanan, D.; Wu, Y.; Kumar, A.; et al. Holistic Evaluation of Language Models; Holistic Evaluation of Language Models. arXiv 2022, arXiv:2211.09110. [Google Scholar]
- Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools. arXiv 2023, arXiv:2302.04761. [Google Scholar]
- Kraus, M.; Bingler, J.A.; Leippold, M.; Schimanski, T.; Senni, C.C.; Stammbach, D.; Vaghefi, S.A.; Webersinke, N. Enhancing Large Language Models with Climate Resources. arXiv 2023, arXiv:2304.00116. [Google Scholar] [CrossRef]
- Yogatama, D.; de Masson d’Autume, C.; Connor, J.; Kocisky, T.; Chrzanowski, M.; Kong, L.; Lazaridou, A.; Ling, W.; Yu, L.; Dyer, C.; et al. Learning and Evaluating General Linguistic Intelligence. arXiv 2019, arXiv:1901.11373. [Google Scholar]
- Acerbi, A.; Stubbersfield, J. Large language models show human-like content biases in transmission chain experiments. Proc. Natl. Acad. Sci. USA 2023, 120, e2313790120. [Google Scholar] [CrossRef]
- Jones, E.; Steinhardt, J. Capturing Failures of Large Language Models via Human Cognitive Biases. arXiv 2022, arXiv:abs/2202.12299. [Google Scholar]
- Ye, H.; Liu, T.; Zhang, A.; Hua, W.; Jia, W. Cognitive Mirage: A Review of Hallucinations in Large Language Models. arXiv 2023, arXiv:abs/2309.06794. [Google Scholar]
- Sorin, M.V.; Brin, M.D.; Barash, M.Y.; Konen, M.E.; Charney, M.P.A.; Nadkarni, M.G.; Klang, M.E. Large Language Models (LLMs) and Empathy—A Systematic Review. medRxiv 2023. [Google Scholar] [CrossRef]
- Ranaldi, L.; Pucci, G. When Large Language Models contradict humans? Large Language Models’ Sycophantic Behaviour. arXiv 2023, arXiv:2311.09410. [Google Scholar]
- Huang, J.; Gu, S.S.; Hou, L.; Wu, Y.; Wang, X.; Yu, H.; Han, J. Large Language Models Can Self-Improve. arXiv 2022, arXiv:abs/2210.11610. [Google Scholar]
- Lin, Z.; Trivedi, S.; Sun, J. Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models. arXiv 2023, arXiv:abs/2305.19187. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. In Proceedings of the 2021 International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Critch, A.; Li, J.; Song, D.; Steinhardt, J. Aligning AI With Shared Human Values. In Proceedings of the 2021 International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Zhong, W.; Wang, S.; Tang, D.; Xu, Z.; Guo, D.; Wang, J.; Yin, J.; Zhou, M.; Duan, N. AR-LSAT: Investigating Analytical Reasoning of Text. arXiv 2021, arXiv:2104.06598. [Google Scholar]
- Wang, S.; Liu, Z.; Zhong, W.; Zhou, M.; Wei, Z.; Chen, Z.; Duan, N. From lsat: The progress and challenges of complex reasoning. IEEE ACM Trans. Audio Speech Lang. Process. 2022, 30, 2201–2216. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A Survey of Large Language Models. arXiv 2023, arXiv:abs/2303.18223. [Google Scholar]
- Sareen, S. Chain of Thoughts vs. Tree of Thoughts for Language Learning Models (LLMs). 2023. Available online: https://medium.com/@sonal.sareen/chain-of-thoughts-vs-tree-of-thoughts-for-language-learning-models-llms-fc11efbd20ab (accessed on 18 December 2023).

| Variable Symbol | Variable Name | Type | Range/Example |
|---|---|---|---|
| Category | Category of the problem | Categorical | Truthful Q&A, Mathematical Reasoning |
| ProblemLevel | Problem level | Categorical | 1, 2, 3, 4, 5 |
| ProblemID | Unique identifier for problem | Categorical | T1, T2, MR1 |
| Problem | Text of the problem | Text | “Are all real numbers real numbers?” |
| LLM | Type of Large Language Model | Categorical | GPT-4, GPT-3.5 |
| A1 | Absolute confidence (pre) | Continuous | 1–10 |
| R1 | Relative confidence (pre) | Continuous | 1–10 |
| A2 | Absolute confidence (post) | Continuous | 1–10 |
| R2 | Relative confidence (post) | Continuous | 1–10 |
| IsCorrect | Correctness of answer | Binary | 0, 1 |
| Metric | Model | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Claude-2 | Claude-Instant | Google Bard | Google PaLM | GPT-3.5 | GPT-4 | LLaMA-13B | LLaMA-70B | LLaMA-7B | ||
| High_Confidence_Correct | A1 | 3 | 6 | 12 | 1 | 14 | 25 | 5 | 8 | 9 |
| A2 | 14 | 13 | 18 | 8 | 21 | 25 | 8 | 14 | 8 | |
| R1 | 3 | 0 | 21 | 0 | 12 | 25 | 5 | 8 | 5 | |
| R2 | 13 | 3 | 21 | 4 | 21 | 25 | 5 | 13 | 9 | |
| High_Confidence_Incorrect | A1 | 3 | 2 | 6 | 1 | 5 | 15 | 23 | 18 | 6 |
| A2 | 4 | 21 | 14 | 6 | 16 | 15 | 25 | 22 | 21 | |
| R1 | 3 | 0 | 17 | 2 | 5 | 15 | 13 | 18 | 6 | |
| R2 | 4 | 7 | 15 | 2 | 16 | 15 | 16 | 22 | 14 | |
| Low_Confidence_Correct | A1 | 2 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 0 |
| A2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| R1 | 2 | 1 | 0 | 6 | 0 | 0 | 1 | 0 | 2 | |
| R2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Low_Confidence_Incorrect | A1 | 12 | 2 | 0 | 5 | 0 | 0 | 2 | 0 | 2 |
| A2 | 14 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | |
| R1 | 12 | 5 | 0 | 16 | 0 | 0 | 3 | 0 | 0 | |
| R2 | 14 | 0 | 0 | 6 | 0 | 0 | 2 | 0 | 0 | |
| Absolute Confidence | ||||
| LLM | Close_Correct | Close_Incorrect | Far_Correct | Far_Incorrect |
| Claude-2 | 4 | 15 | 15 | 6 |
| Claude-instant | 11 | 12 | 5 | 12 |
| Google-Bard | 22 | 18 | 0 | 0 |
| GooglePaLM | 9 | 9 | 7 | 15 |
| GPT-3.5 | 14 | 5 | 9 | 12 |
| GPT-4 | 25 | 15 | 0 | 0 |
| LLaMA-13B | 7 | 24 | 2 | 7 |
| LLaMA-70B | 8 | 20 | 8 | 4 |
| LLaMA-7B | 9 | 14 | 6 | 11 |
| Relative Confidence | ||||
| LLM | Close_Correct | Close_Incorrect | Far_Correct | Far_Incorrect |
| Claude-2 | 4 | 16 | 15 | 5 |
| Claude-instant | 12 | 13 | 4 | 11 |
| Google-Bard | 22 | 18 | 0 | 0 |
| GooglePaLM | 9 | 9 | 7 | 15 |
| GPT-3.5 | 14 | 5 | 9 | 12 |
| GPT-4 | 25 | 15 | 0 | 0 |
| LLaMA-13B | 7 | 26 | 2 | 5 |
| LLaMA-70B | 10 | 20 | 6 | 4 |
| LLaMA-7B | 8 | 15 | 7 | 10 |
| LLM | A1 | R1 | A2 | R2 | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Claude-2 | 4.800 | 2.911 | 4.650 | 2.957 | 5.400 | 4.241 | 5.400 | 4.235 |
| Claude-instant | 6.850 | 1.027 | 5.475 | 1.062 | 8.325 | 0.829 | 6.825 | 0.931 |
| Google-Bard | 7.400 | 0.591 | 8.400 | 0.591 | 7.700 | 0.648 | 8.700 | 0.648 |
| GooglePaLM | 5.500 | 1.485 | 4.600 | 1.646 | 7.050 | 1.260 | 6.050 | 1.260 |
| GPT-3.5 | 7.525 | 0.877 | 7.475 | 0.877 | 8.900 | 0.672 | 8.900 | 0.672 |
| GPT-4 | 8.900 | 0.568 | 9.200 | 0.372 | 8.925 | 0.594 | 9.225 | 0.375 |
| LLaMA-13B | 7.550 | 2.062 | 6.950 | 2.136 | 7.725 | 1.921 | 7.400 | 1.892 |
| LLaMA-70B | 7.350 | 1.122 | 7.950 | 1.339 | 8.600 | 0.672 | 8.475 | 0.847 |
| LLaMA-7B | 7.250 | 1.214 | 6.600 | 1.297 | 8.025 | 1.187 | 7.525 | 0.877 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, A.K.; Lamichhane, B.; Devkota, S.; Dhakal, U.; Dhakal, C. Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI. Information 2024, 15, 92. https://doi.org/10.3390/info15020092
Singh AK, Lamichhane B, Devkota S, Dhakal U, Dhakal C. Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI. Information. 2024; 15(2):92. https://doi.org/10.3390/info15020092
Chicago/Turabian StyleSingh, Aniket Kumar, Bishal Lamichhane, Suman Devkota, Uttam Dhakal, and Chandra Dhakal. 2024. "Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI" Information 15, no. 2: 92. https://doi.org/10.3390/info15020092
APA StyleSingh, A. K., Lamichhane, B., Devkota, S., Dhakal, U., & Dhakal, C. (2024). Do Large Language Models Show Human-like Biases? Exploring Confidence—Competence Gap in AI. Information, 15(2), 92. https://doi.org/10.3390/info15020092