
Design and Implementation of an Intelligent Web Service Agent Based on Seq2Seq and Website Crawler




Abstract

1. Introduction
2. Related Works
2.1. Natural Language Processing Techniques
2.1.1. Rule-Based
2.1.2. Machine Learning
2.1.3. Recurrent Neural Network
2.1.4. Long Short-Term Memory
2.1.5. Encoder-Decoder Framework
2.1.6. Transformer
2.2. Create a Knowledge Base Using Website Crawlers
- Step 1: Analyze the relevance of the hyperlinked content to the target topic. By hyperlinking the relevant HTML tags, the spatial vector of this information is analyzed to determine the target direction of the crawler after the second pass. Baeza-Yates and Ribeiro-Neto [19] used the spatial method to sort words into different vectors based on their relatedness. Assuming the two web pages are related, the vectors point in the same direction.
- Step 2: Decide whether these pages are sufficiently professional to be relevant to the target topic. Kleinberg [20] proposed using a hyperlink-induced topic search (HITS) algorithm to rank these pages according to their authority.
- Step 3: Use the above information to make the final web crawler direction. Many methods can be used, and the one used is the open directory project (ODP).
3. Proposed Methodology
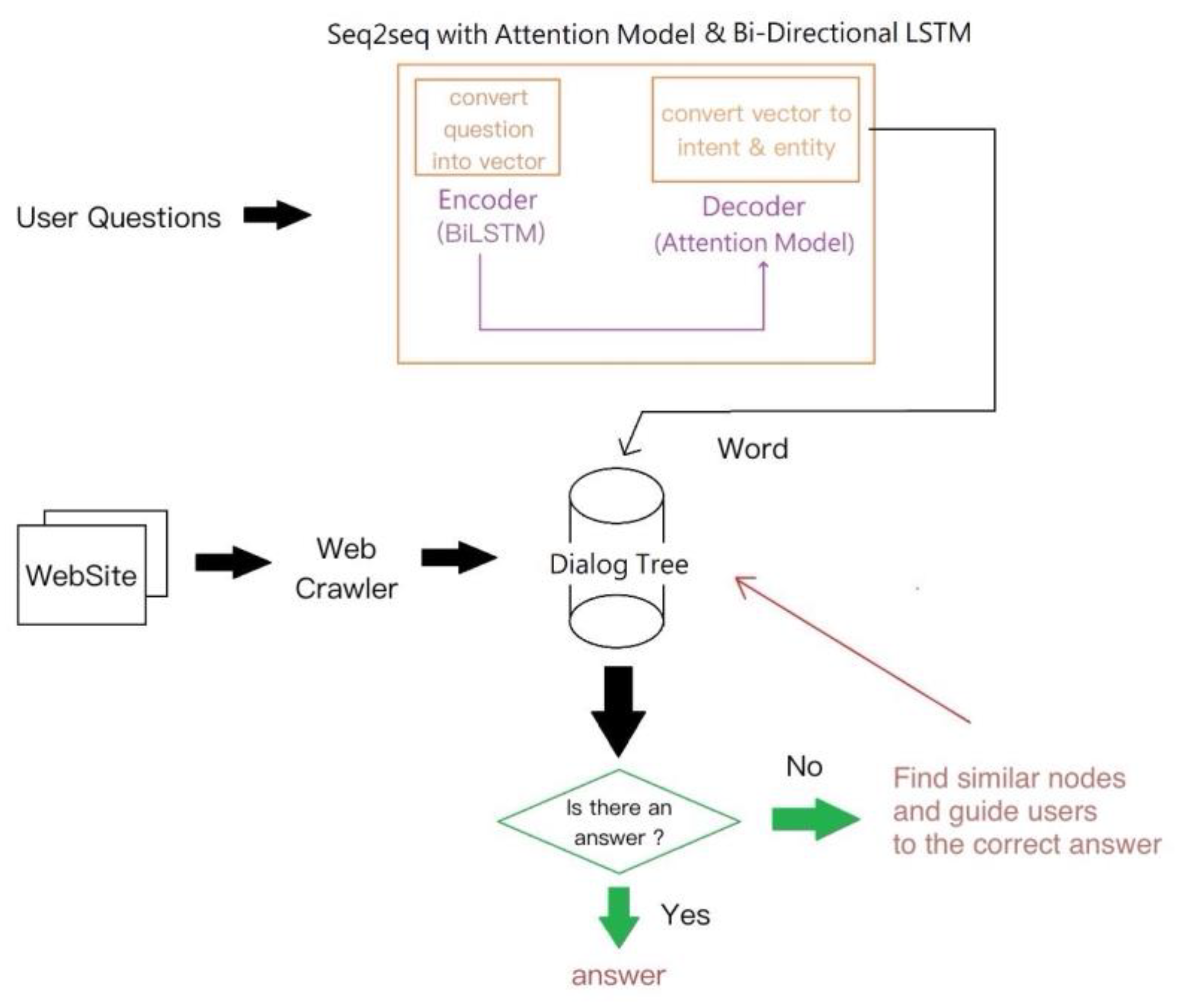
3.1. System Architecture
3.2. Nature Language Processing
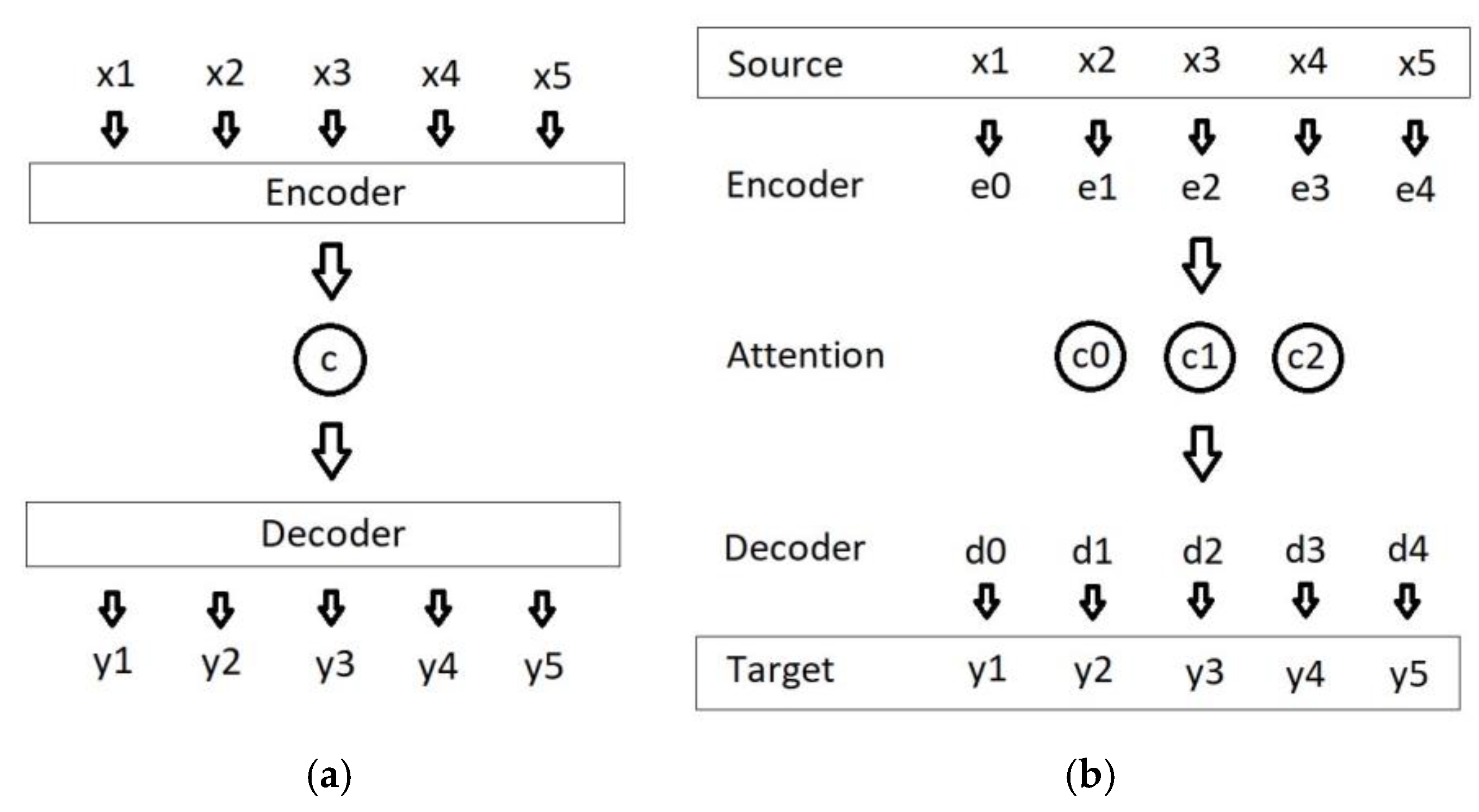
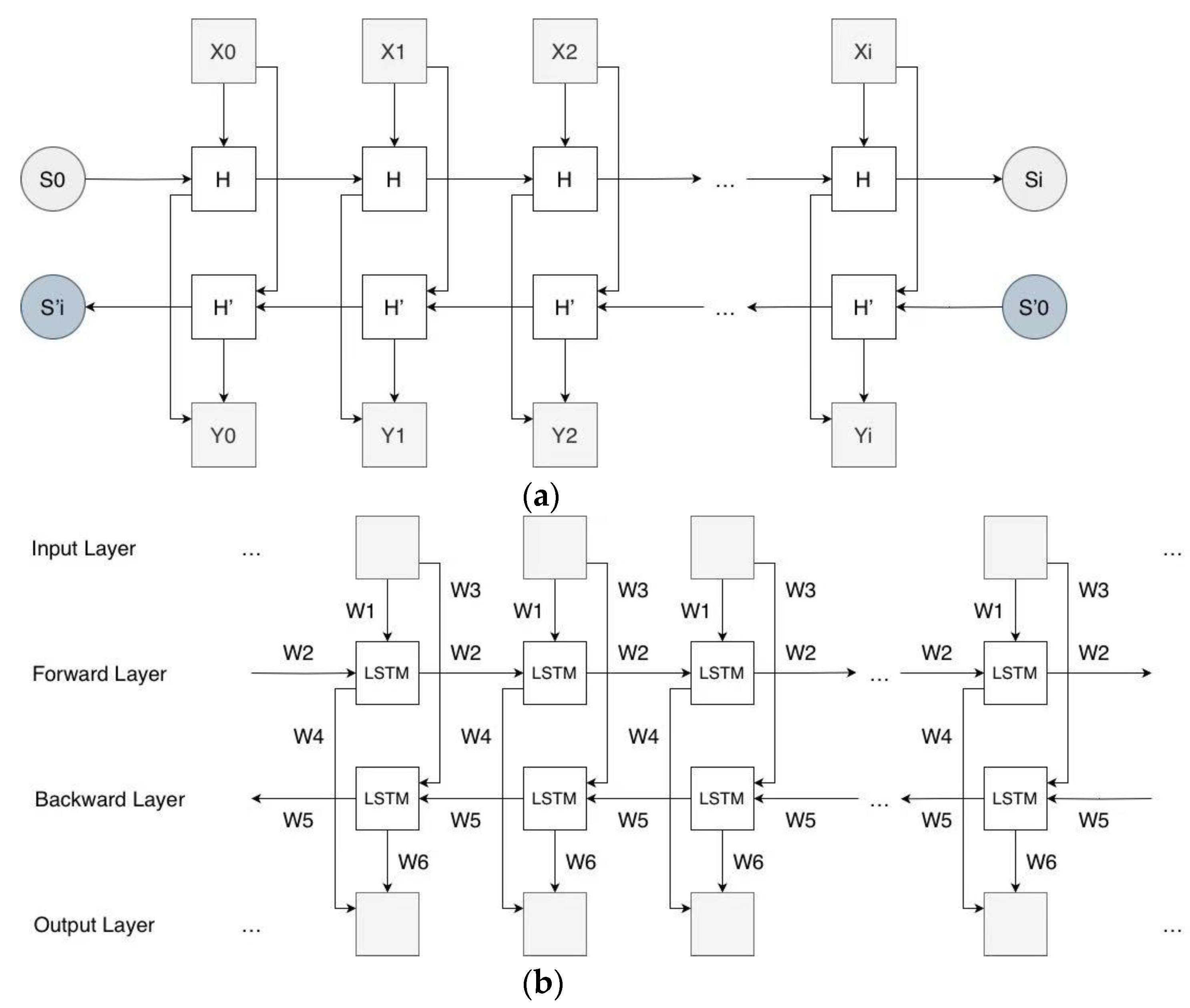
3.2.1. Seq2Seq
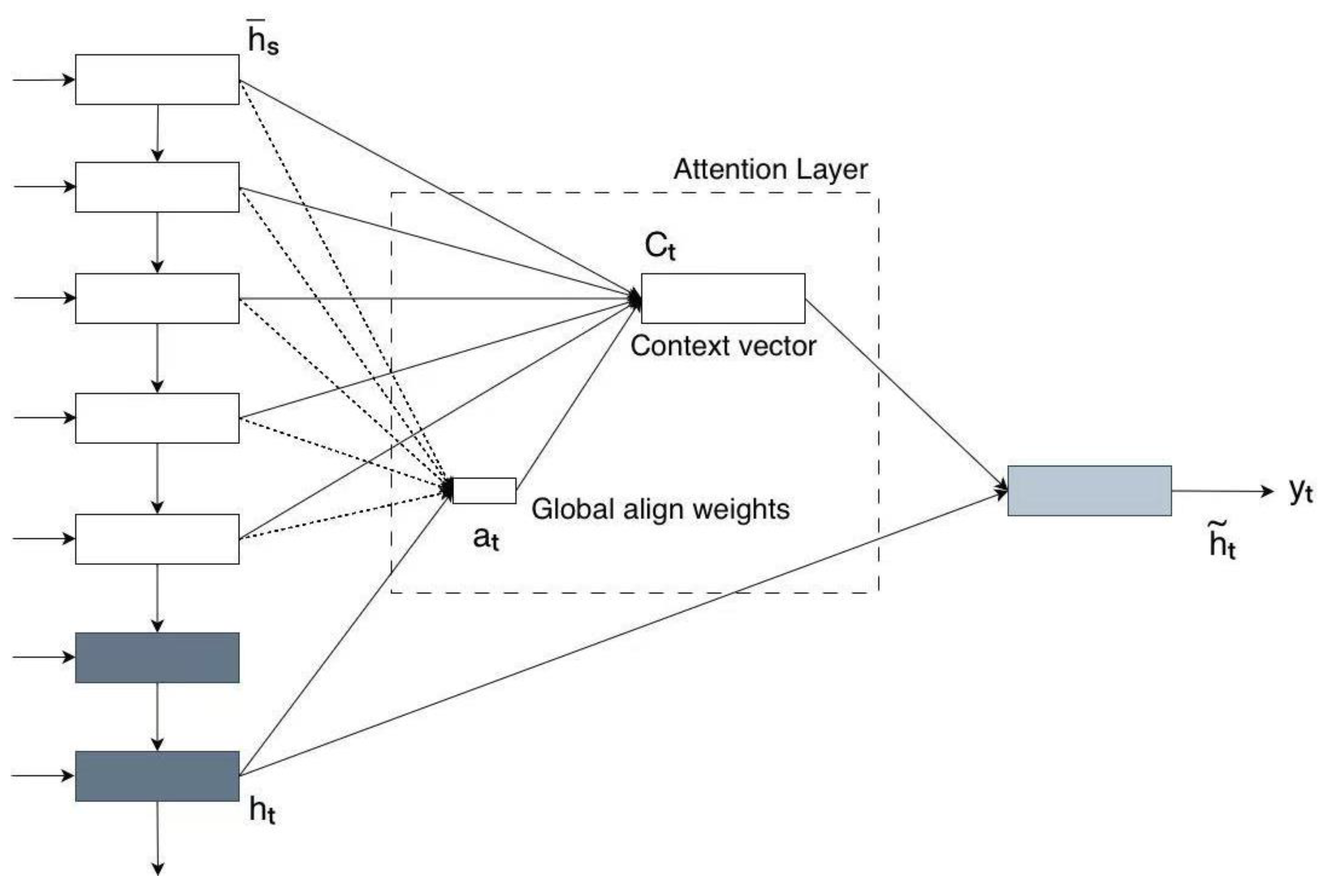
3.2.2. Attention Mechanism
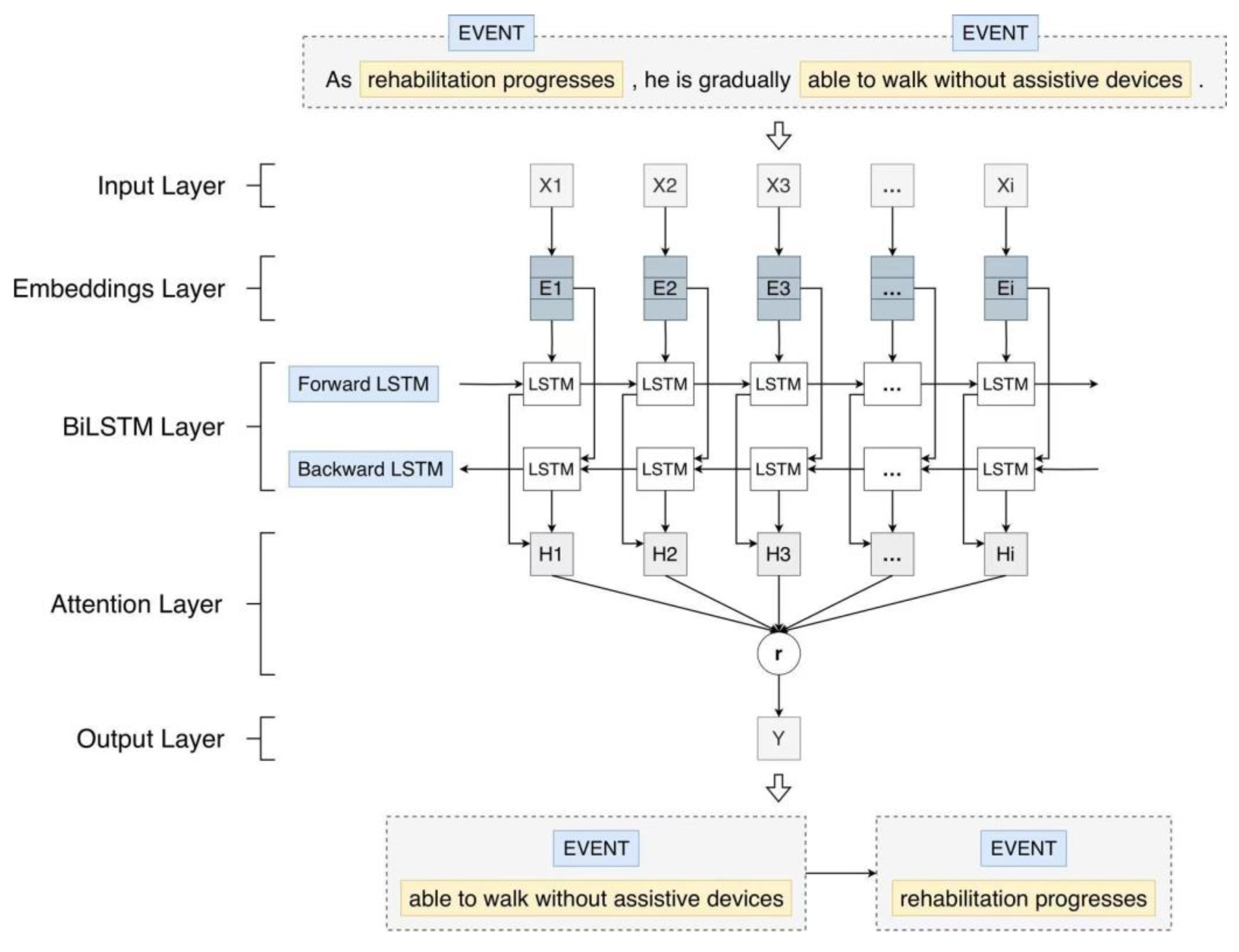
3.2.3. Bidirectional LSTM with Luong Attention Mechanism
3.3. Knowledge Representation
3.3.1. Implementation of the Web Crawler
3.3.2. Depth-First Search
3.3.3. Dialogue Tree
4. Experimental Results
4.1. Public Dataset
4.2. Experimental Environment and the Tested Models
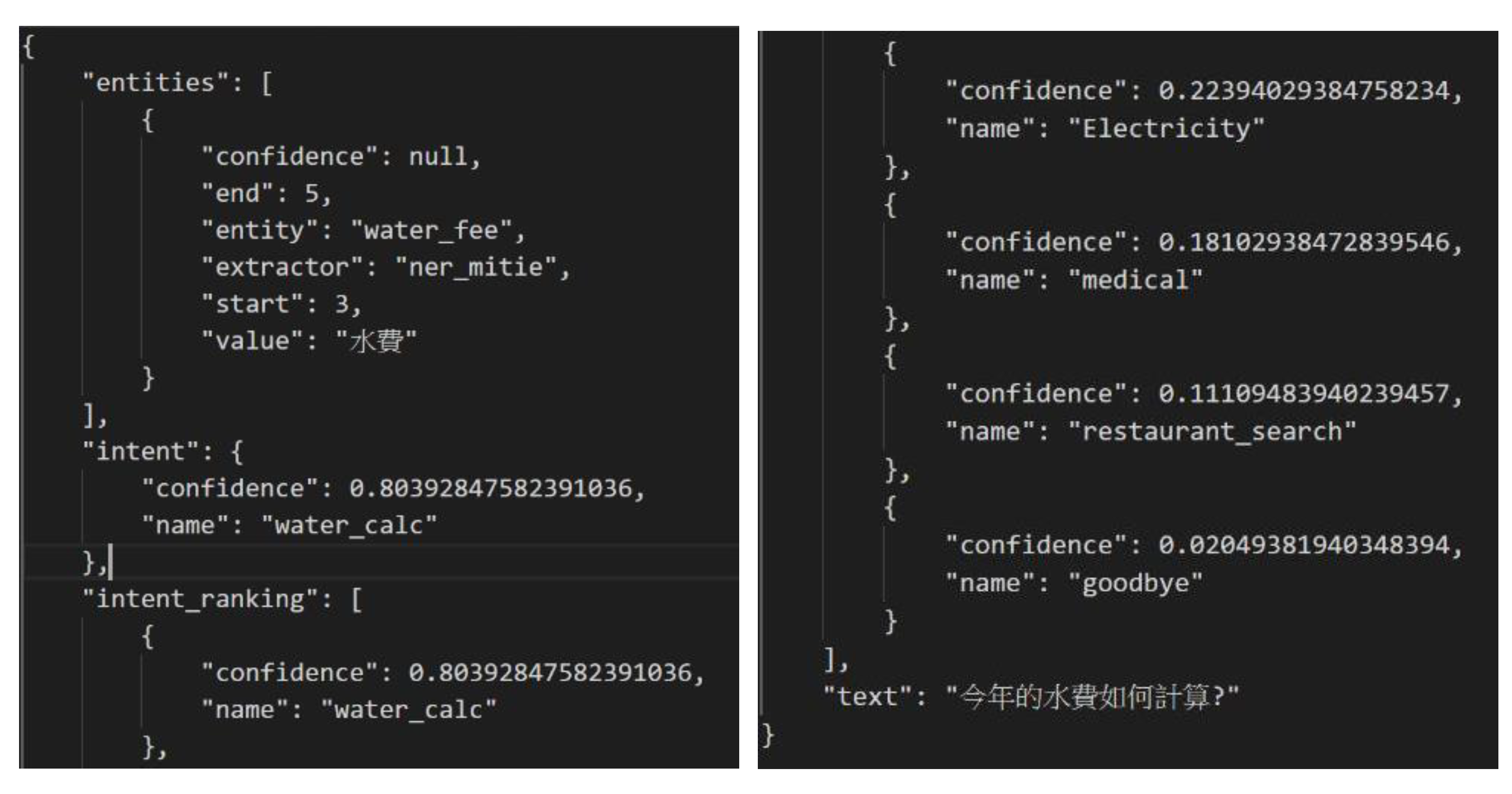
4.2.1. RasaNLU
4.2.2. LSTM
4.2.3. Seq2Seq
4.3. Ablation Test of the Proposed Neural Network Model
4.4. Test in the Target Domain and Non-Target Domain
4.5. Comparisons with Chatbots on the Market
5. Conclusions and Remarks
5.1. Conclusions
5.2. Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, LIX, 433–460. [Google Scholar] [CrossRef]
- Wallace, R.S. The Anatomy of A.L.I.C.E.; Epstein, R., Roberts, G., Beber, G., Eds.; Parsing the Turing Test; Springer: Dordrecht, The Netherlands, 2009. [Google Scholar] [CrossRef]
- Kirrane, S. Intelligent Software Web Agents: A Gap Analysis. J. Web Semant. 2021, 71, 100659. [Google Scholar] [CrossRef]
- Mashaabi, M.; Alotaibi, A.; Qudaih, H.; Alnashwan, R.; Al-Khalifa, H. Natural Language Processing in Customer Service: A Systematic Review. arXiv 2022, arXiv:10.48550/arXiv.2212.09523. [Google Scholar]
- Huang, C. The Intelligent Agent NLP-based Customer Service System. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence in Electronics Engineering (AIEE ‘21), Phuket, Thailand, 15–17 January 2021; ACM: New York, NY, USA, 2021; pp. 41–50. [Google Scholar] [CrossRef]
- Winograd, T. SHRDLU; MIT AI Technical Report 235; MIT: Cambridge, MA, USA, 1971. [Google Scholar]
- Weizenbaum, J. ELIZA—A Computer Program for the Study of Natural Language Communication between Man and Machine. Commun. ACM 1966, 9, 35–36. [Google Scholar] [CrossRef]
- Chen, G.; Liu, R.; Chen, R.; Fu, C.C. A Historical Review of the Key Technologies for Enterprise Brand Impact Assessment. In Proceedings of the 2024 International Conference on Applied Economics, Management Science and Social Development (AEMSS 2024), Luoyang, China, 22–24 March 2024; pp. 240–246. [Google Scholar]
- LeCun, Y. Deep Learning Hardware: Past, Present, and Future. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–17 February 2019; pp. 12–19. [Google Scholar] [CrossRef]
- Rasa: Open Source Conversational AI—Rasa. 2019. Available online: https://rasa.com (accessed on 18 June 2021).
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Xiao, T.; Zhu, J. Introduction to Transformers: An NLP Perspective. arXiv 2023, arXiv:2311.17633. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS ‘20), Vancouver, BC, Canada, 6–12 December 2020; Article 159. pp. 1877–1901. [Google Scholar]
- AIML.com. What Are the Limitations of Transformer Models? Available online: https://aiml.com/what-are-the-drawbacks-of-transformer-models/ (accessed on 18 June 2021).
- Rungsawang, A.; Angkawattanawit, N. Learnable Topic-Specific Web Crawler. J. Netw. Comput. Appl. 2005, 28, 97–114. [Google Scholar] [CrossRef]
- Baeza-Yates, R.; Ribeiro-Neto, B. Modern Information Retrieval; ACM Press: New York, NY, USA, 1999. [Google Scholar]
- Kleinberg, J.M. Authoritative Sources in a Hyperlinked Environment. J. ACM (JACM) 1999, 46, 604–632. [Google Scholar] [CrossRef]
- Lee, T.B. Semantic Web; World Wide Web Consortium: Cambridge, MA, USA, 1998. [Google Scholar]
- Kim, S.M.; Ha, Y.G. Automated Discovery of Small Business Domain Knowledge Using Web Crawling and Data Mining. In Proceedings of the 2016 International Conference on Big Data and Smart Computing (BigComp), Hong Kong, China, 18–20 January 2016; pp. 481–484. [Google Scholar] [CrossRef]
- W3C. RDF—Semantic Web Standards. Available online: http://www.w3.org/RDF/ (accessed on 18 June 2021).
- W3C. OWL—Semantic Web Standards. Available online: http://www.w3.org/2001/sw/wiki/OWL (accessed on 18 June 2021).
- Choudhary, P.; Chauhan, S. An Intelligent Chatbot Design and Implementation Model Using Long Short-Term Memory with Recurrent Neural Networks and Attention Mechanism. Decis. Anal. J. 2023, 9, 100359. [Google Scholar] [CrossRef]
- Budaev, E.S. Development of a Web Application for Intelligent Analysis of Customer Reviews Using a Modified seq2seq Model with an Attention Mechanism. Comput. Nanotechnol. 2024, 11, 151–161. [Google Scholar] [CrossRef]
- Jiang, J.W.; Zhang, H.; Dai, C.; Zhao, Q.; Feng, H.; Ji, Z.; Ganchev, I. Enhancements of Attention-Based Bidirectional LSTM for Hybrid Automatic Text Summarization. IEEE Access 2021, 9, 123660–123671. [Google Scholar] [CrossRef]
- Xie, T.; Ding, W.; Zhang, J.; Wan, X.; Wang, J. Bi-LS-AttM: A Bidirectional LSTM and Attention Mechanism Model for Improving Image Captioning. Appl. Sci. 2023, 13, 7916. [Google Scholar] [CrossRef]
- Su, G. Seq2seq Pay Attention to Self-Attention. 3 October 2018. Available online: https://bgg.medium.com/seq2seq-pay-attention-to-self-attention-part-1-%E4%B8%AD%E6%96%87%E7%89%88-2714bbd92727 (accessed on 18 June 2021).
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Graves, A. Supervised Sequence Labelling with Recurrent Neural Networks; Computer Science; University of Toronto: Toronto, ON, Canada, 2012. [Google Scholar]
- Alfattni, G.; Peek, N.; Nenadic, G. Attention-based Bidirectional Long Short-Term Memory Networks for Extracting Temporal Relationships from Clinical Discharge Summaries. J. Biomed. Inform. 2021, 123, 103915. [Google Scholar] [CrossRef] [PubMed]
- Wikipedia. Depth-First-Search. 2019. Available online: https://zh.wikipedia.org/wiki/Depth-First-Search (accessed on 18 June 2021).
- Wikipedia. Dialogue Tree. 2019. Available online: https://en.wikipedia.org/wiki/Dialogue_tree (accessed on 18 June 2021).
- Borges, J.L. Garden of Forking Paths; Penguin Books: London, UK, 22 February 2018; ISBN -13 9780241339053. [Google Scholar]
- Taiwan Water Company. 2016. Available online: https://www.water.gov.tw/mp.aspx?mp=1 (accessed on 18 June 2021).
- Introduction to Rasa Open Source & Rasa Pro, RasaNLU. Available online: https://rasa.com/docs/rasa/nlu-training-data/ (accessed on 18 June 2021).
- GitHub. Chinese_Chatbot_Corpus. 2018. Available online: https://github.com/codemayq/chinese_chatbot_corpus (accessed on 18 June 2021).
- GitHub. Seq2Seq. 2017. Available online: https://github.com/google/seq2seq (accessed on 18 June 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Cornell University, 16 December 2017. Available online: https://arxiv.org/pdf/1706.03762.pdf (accessed on 18 June 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neural Network Models | Accuracy |
|---|---|
| LSTM | 63.4% |
| Seq2Seq | 69.2% |
| Seq2Seq + Attention | 76.1% |
| Seq2Seq + Bi-LSTM + Attention | 82.1% |
| Accuracy | RasaNLU | Ours |
|---|---|---|
| Target Domain | 86.4% | 87.1% |
| Non-Target Domain | 46.3% | 83.2% |
| Items | This Study | Xiao Ai Classmate | Google Assistant | Siri | Samsung Bixby y |
|---|---|---|---|---|---|
| Trip. co m | 73.4 | 42.5 | 40.2 | 32.6 | 39.2 |
| Taipei MRT | 82.1 | 48.2 | 41.3 | 49.2 | 42.3 |
| Taiwan Water Company | 78.3 | 32.5 | 40.2 | 34.2 | 32.1 |
| Wikipedia | 81.2 | 82.3 | 83.4 | 81.7 | 87.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsih, M.-H.; Yang, J.-X.; Hsieh, C.-C. Design and Implementation of an Intelligent Web Service Agent Based on Seq2Seq and Website Crawler. Information 2024, 15, 818. https://doi.org/10.3390/info15120818
Hsih M-H, Yang J-X, Hsieh C-C. Design and Implementation of an Intelligent Web Service Agent Based on Seq2Seq and Website Crawler. Information. 2024; 15(12):818. https://doi.org/10.3390/info15120818
Chicago/Turabian StyleHsih, Mei-Hua, Jian-Xin Yang, and Chen-Chiung Hsieh. 2024. "Design and Implementation of an Intelligent Web Service Agent Based on Seq2Seq and Website Crawler" Information 15, no. 12: 818. https://doi.org/10.3390/info15120818
APA StyleHsih, M.-H., Yang, J.-X., & Hsieh, C.-C. (2024). Design and Implementation of an Intelligent Web Service Agent Based on Seq2Seq and Website Crawler. Information, 15(12), 818. https://doi.org/10.3390/info15120818