
Decoding Methods in Neural Language Generation: A Survey


Abstract
:1. Introduction
1.1. Motivation and Overview
- overview decoding across different neural NLG frameworks (Section 2),
- review of different variants of beam search-based decoding and summarize the debate about strengths and weaknesses of beam search (Section 3),
- discuss different notions of diversity in the decoding literature and summarize work on diversity-oriented decoding methods (Section 4),
- summarize work on task-specific decoding (Section 5), and
- discuss challenges in neural NLG brought up by work on decoding (Section 6).
1.2. Scope and Methodology
2. Decoding across NLG Frameworks and Tasks
2.1. Pre-Neural NLG
2.2. Neural Autoregressive NLG
2.3. Neural Non-Autoregressive Generation
2.4. Summary
- research on decoding in non-neural frameworks based on structured search spaces (e.g., hypergraphs, factored language models),
- autoregressive (left-to-right) neural NLG generally requires a decoding method defining the assembly of the sequence, and
- non-autoregressive generation methods are faster and define operations for assembling the sequences as part of the model, but often perform worse than autoregressive approaches.
3. Decoding as Search for the Optimal Sequence
3.1. Decoding as Search
3.2. Beam Search: Basic Example
| Algorithm 1: Beam search as defined by Graves [39]. |
 |
3.3. Variants of Beam Search
| Algorithm 2: Beam search as defined by Meister et al. [57]. |
 |
| Algorithm 3: Beam search as defined by Stahlberg and Byrne [56]. |
 |
3.4. Beam Search: Curse or Blessing?
3.5. Beam Search in Practice
- beam search is widely used for decoding in different areas of NLG, but many different variants do exist, and they are not generally distinguished in papers,
- many variants and parameters of beam search have been developed and analyzed exclusively for MT,
- papers on NLG systems often do not report on parameters, such as length normalization or stopping criteria, used in the experiments,
- the different variants of beam search address a number of biases found in decoding neural NLG models, e.g., the length bias, performance degradation with larger beam widths, or repetitiveness of generation output,
- there is an ongoing debate on whether some of these biases are inherent in neural generation models or whether they are weaknesses of beam search, and
- the main research gap: studies on beam search, its variants, and potentially further variants for core NLG tasks beyond MT.
4. Decoding Diverse Sets of Sequences
4.1. Definition and Evaluation of Diversity
4.2. Diversifying Beam Search
4.3. Sampling
4.4. Analyses of Trade-Offs in Diversity-Oriented Decoding
4.5. Summary
- different notions of diversity have been investigated in connection with decoding methods in neural NLG,
- diversity-oriented decoding methods are either based on beam search or sampling, or a combination thereof,
- analyses of diversity-oriented decoding methods show trade-offs between diversity, on the one hand, and quality or verifiability, on the other hand,
- diversity-oriented decoding is most often used in open generation tasks, such as, e.g., story generation, and
- the main research gap: studies that investigate and consolidate different notions of diversity, methods that achieve a better trade-off between quality and diversity.
5. Decoding with Linguistic Constraints and Conversational Goals
5.1. Lexical Constraints
5.2. Structure and Form
5.3. Conversational Goals
5.4. Summary
- decoding methods offer themselves to be tailored to incorporate linguistic constraints at different levels of the generation process,
- decoding methods with lexical or structural constraints typically present extensions of beam search where candidates are filtered in more or less sophisticated ways,
- lexical constraints during decoding can extend a model’s vocabulary,
- decoding can be used to incorporate reasoning on high-level conversational or task-related objectives, and
- the main research gap: generalize and transfer these methods across NLG tasks and develop a more systematic understanding of objectives that can be implemented at the decoding stage in NLG.
6. Research Gaps and Future Directions
6.1. Exploring Decoding Parameters for Core NLG Tasks
6.2. The Status of Language Modeling in Neural Generation
6.3. Diversity, Effectiveness, and other Objectives in NLG
6.4. What to Model and How to Decode?
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reiter, E.; Dale, R. Building Natural Language Generation Systems; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Gatt, A.; Krahmer, E. Survey of the state of the art in natural language generation: Core tasks, applications and evaluation. J. Artif. Intell. Res. 2018, 61, 65–170. [Google Scholar] [CrossRef]
- Wen, T.H.; Gašić, M.; Mrkšić, N.; Su, P.H.; Vandyke, D.; Young, S. Semantically Conditioned LSTM-based Natural Language Generation for Spoken Dialogue Systems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1711–1721. [Google Scholar]
- Gehrmann, S.; Dai, F.; Elder, H.; Rush, A. End-to-End Content and Plan Selection for Data-to-Text Generation. In Proceedings of the 11th International Conference on Natural Language Generation, Tilburg, The Netherlands, 5–8 November 2018; pp. 46–56. [Google Scholar]
- Castro Ferreira, T.; Moussallem, D.; Kádár, Á.; Wubben, S.; Krahmer, E. NeuralREG: An end-to-end approach to referring expression generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1959–1969. [Google Scholar]
- Castro Ferreira, T.; van der Lee, C.; van Miltenburg, E.; Krahmer, E. Neural data-to-text generation: A comparison between pipeline and end-to-end architectures. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 552–562. [Google Scholar]
- Dušek, O.; Novikova, J.; Rieser, V. Evaluating the state-of-the-art of end-to-end natural language generation: The e2e nlg challenge. Comput. Speech Lang. 2020, 59, 123–156. [Google Scholar] [CrossRef]
- Lowerre, B.T. The HARPY Speech Recognition System. Ph. D. Thesis, Carnegie Mellon University, Pittsburgh, PN, USA, 1976. [Google Scholar]
- Reiter, E.; Dale, R. Building applied natural language generation systems. Nat. Lang. Eng. 1997, 3, 57–87. [Google Scholar] [CrossRef] [Green Version]
- Rothe, S.; Narayan, S.; Severyn, A. Leveraging pre-trained checkpoints for sequence generation tasks. Trans. Assoc. Comput. Linguist. 2020, 8, 264–280. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Serban, I.; Sordoni, A.; Bengio, Y.; Courville, A.; Pineau, J. Building end-to-end dialogue systems using generative hierarchical neural network models. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Kukich, K. Design of a knowledge-based report generator. In Proceedings of the 21st Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Cambridge, MA, USA, 1983; pp. 145–150. [Google Scholar]
- McKeown, K. Text Generation; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar]
- Busemann, S.; Horacek, H. A Flexible Shallow Approach to Text Generation. Available online: https://aclanthology.org/W98-1425.pdf (accessed on 27 August 2021).
- Gatt, A.; Reiter, E. SimpleNLG: A realisation engine for practical applications. In Proceedings of the 12th European Workshop on Natural Language Generation (ENLG 2009), Athens, Greece, 30–31 March 2009; pp. 90–93. [Google Scholar]
- van Deemter, K.; Theune, M.; Krahmer, E. Real versus template-based natural language generation: A false opposition? Comput. Linguist. 2005, 31, 15–24. [Google Scholar] [CrossRef]
- Langkilde, I. Forest-based statistical sentence generation. In Proceedings of the 1st Meeting of the North American Chapter of the Association for Computational Linguistics, Seattle, WA, USA, 29 April 2000. [Google Scholar]
- Ratnaparkhi, A. Trainable Methods for Surface Natural Language Generation. In Proceedings of the 1st Meeting of the North American Chapter of the Association for Computational Linguistics, Seattle, WA, USA, 29 April 2000. [Google Scholar]
- Cahill, A.; Forst, M.; Rohrer, C. Stochastic Realisation Ranking for a Free Word Order Language. In Proceedings of the Eleventh European Workshop on Natural Language Generation (ENLG 07), Saarbrücken, Germany, 17–20 June 2007; pp. 17–24. [Google Scholar]
- White, M.; Rajkumar, R.; Martin, S. Towards broad coverage surface realization with CCG. In Proceedings of the Workshop on Using Corpora for NLG: Language Generation and Machine Translation (UCNLG+ MT), Columbus, OH, USA, 11 September 2007. [Google Scholar]
- Belz, A. Automatic generation of weather forecast texts using comprehensive probabilistic generation-space models. Nat. Lang. Eng. 2008, 14, 431. [Google Scholar] [CrossRef] [Green Version]
- Angeli, G.; Liang, P.; Klein, D. A simple domain-independent probabilistic approach to generation. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 502–512. [Google Scholar]
- Konstas, I.; Lapata, M. Unsupervised concept-to-text generation with hypergraphs. In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Stroudsburg, PA, USA, 3–8 June 2012; pp. 752–761. [Google Scholar]
- Chiang, D. Hierarchical phrase-based translation. Comput. Linguist. 2007, 33, 201–228. [Google Scholar] [CrossRef]
- Mairesse, F.; Young, S. Stochastic Language Generation in Dialogue using Factored Language Models. Comput. Linguist. 2014, 40, 763–799. [Google Scholar] [CrossRef]
- Mairesse, F.; Walker, M.A. Controlling User Perceptions of Linguistic Style: Trainable Generation of Personality Traits. Comput. Linguist. 2011, 37, 455–488. [Google Scholar] [CrossRef]
- Belz, A.; White, M.; Espinosa, D.; Kow, E.; Hogan, D.; Stent, A. The first surface realisation shared task: Overview and evaluation results. In Proceedings of the 13th European Workshop on Natural Language Generation, Nancy, France, 28–31 September 2011; pp. 217–226. [Google Scholar]
- Mille, S.; Belz, A.; Bohnet, B.; Graham, Y.; Wanner, L. The second multilingual surface realisation shared task (SR’19): Overview and evaluation results. In Proceedings of the 2nd Workshop on Multilingual Surface Realisation (MSR 2019), Hong Kong, China, 3 November 2019; pp. 1–17. [Google Scholar]
- Bohnet, B.; Wanner, L.; Mille, S.; Burga, A. Broad coverage multilingual deep sentence generation with a stochastic multi-level realizer. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), Beijing, China, 23–27 August 2010; pp. 98–106. [Google Scholar]
- Bohnet, B.; Björkelund, A.; Kuhn, J.; Seeker, W.; Zarriess, S. Generating non-projective word order in statistical linearization. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 928–939. [Google Scholar]
- Pourdamghani, N.; Knight, K.; Hermjakob, U. Generating English from Abstract Meaning Representations. In Proceedings of the 9th International Natural Language Generation Conference; Association for Computational Linguistics: Edinburgh, UK, 2016; pp. 21–25. [Google Scholar] [CrossRef]
- Flanigan, J.; Dyer, C.; Smith, N.A.; Carbonell, J. Generation from Abstract Meaning Representation using Tree Transducers. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 731–739. [Google Scholar] [CrossRef] [Green Version]
- Tillmann, C.; Ney, H. Word reordering and a dynamic programming beam search algorithm for statistical machine translation. Comput. Linguist. 2003, 29, 97–133. [Google Scholar] [CrossRef]
- Koehn, P. Pharaoh: A beam search decoder for phrase-based statistical machine translation models. In Conference of the Association for Machine Translation in the Americas; Springer: Berlin/Heidelberg, Germany, 2004; pp. 115–124. [Google Scholar]
- Rush, A.M.; Collins, M. Exact decoding of syntactic translation models through lagrangian relaxation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Oregon, Portland, 19–24 June 2011; pp. 72–82. [Google Scholar]
- Rush, A.; Chang, Y.W.; Collins, M. Optimal beam search for machine translation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 210–221. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems-Volume 2; MIT Press: Cambridge, MA, USA, 2014. NIPS’14. pp. 3104–3112. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Chen, H.; Ding, G.; Zhao, S.; Han, J. Temporal-Difference Learning With Sampling Baseline for Image Captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.C.; Bengio, Y. An Actor-Critic Algorithm for Sequence Prediction. arXiv 2017, arXiv:1607.07086. [Google Scholar]
- Zhang, L.; Sung, F.; Liu, F.; Xiang, T.; Gong, S.; Yang, Y.; Hospedales, T.M. Actor-Critic Sequence Training for Image Captioning. arXiv 2017, arXiv:1706.09601. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 2004, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Oord, A.; Li, Y.; Babuschkin, I.; Simonyan, K.; Vinyals, O.; Kavukcuoglu, K.; Driessche, G.; Lockhart, E.; Cobo, L.; Stimberg, F.; et al. Parallel wavenet: Fast high-fidelity speech synthesis. In Proceedings of the International conference on machine learning, Stockholm, Sweden, 10–15 July 2018; pp. 3918–3926. [Google Scholar]
- Gu, J.; Bradbury, J.; Xiong, C.; Li, V.O.; Socher, R. Non-autoregressive neural machine translation. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lee, J.; Mansimov, E.; Cho, K. Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1173–1182. [Google Scholar]
- Gu, J.; Liu, Q.; Cho, K. Insertion-based Decoding with Automatically Inferred Generation Order. Trans. Assoc. Comput. Linguist. 2019, 7, 661–676. [Google Scholar] [CrossRef]
- Stern, M.; Chan, W.; Kiros, J.; Uszkoreit, J. Insertion transformer: Flexible sequence generation via insertion operations. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5976–5985. [Google Scholar]
- Chen, Y.; Gilroy, S.; Maletti, A.; May, J.; Knight, K. Recurrent Neural Networks as Weighted Language Recognizers. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LO, USA, 1–6 June 2018; pp. 2261–2271. [Google Scholar]
- Li, J.; Monroe, W.; Jurafsky, D. A Simple, Fast Diverse Decoding Algorithm for Neural Generation. arXiv 2016, arXiv:1611.08562. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 67–72. [Google Scholar]
- Stahlberg, F.; Byrne, B. On NMT Search Errors and Model Errors: Cat Got Your Tongue? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–4 November 2019; pp. 3356–3362. [Google Scholar]
- Meister, C.; Vieira, T.; Cotterell, R. Best-First Beam Search. Trans. Assoc. Comput. Linguist. 2020, 8, 795–809. [Google Scholar] [CrossRef]
- Huang, L.; Zhao, K.; Ma, M. When to Finish? Optimal Beam Search for Neural Text Generation (modulo beam size). In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2134–2139. [Google Scholar]
- Newman, B.; Hewitt, J.; Liang, P.; Manning, C.D. The EOS Decision and Length Extrapolation. In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 276–291. [Google Scholar]
- He, W.; He, Z.; Wu, H.; Wang, H. Improved neural machine translation with SMT features. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Murray, K.; Chiang, D. Correcting Length Bias in Neural Machine Translation. In Proceedings of the Third Conference on Machine Translation, Belgium, Brussels, 31 October–1 November 2018; pp. 212–223. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Freitag, M.; Al-Onaizan, Y. Beam Search Strategies for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 56–60. [Google Scholar]
- Yang, Y.; Huang, L.; Ma, M. Breaking the Beam Search Curse: A Study of (Re-)Scoring Methods and Stopping Criteria for Neural Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3054–3059. [Google Scholar]
- Koehn, P.; Knowles, R. Six Challenges for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 28–39. [Google Scholar]
- Cohen, E.; Beck, C. Empirical analysis of beam search performance degradation in neural sequence models. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 1290–1299. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Sountsov, P.; Sarawagi, S. Length bias in Encoder Decoder Models and a Case for Global Conditioning. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1516–1525. [Google Scholar]
- Zarrieß, S.; Schlangen, D. Decoding Strategies for Neural Referring Expression Generation. In Proceedings of the 11th International Conference on Natural Language Generation, Tilburg, The Netherlands, 5–8 November 2018; pp. 503–512. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Shao, Y.; Gouws, S.; Britz, D.; Goldie, A.; Strope, B.; Kurzweil, R. Generating High-Quality and Informative Conversation Responses with Sequence-to-Sequence Models. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 December 2017; pp. 2210–2219. [Google Scholar] [CrossRef]
- Kulikov, I.; Miller, A.; Cho, K.; Weston, J. Importance of Search and Evaluation Strategies in Neural Dialogue Modeling. In Proceedings of the 12th International Conference on Natural Language Generation, Tokyo, Japan, 29 October–1 November 2019; pp. 76–87. [Google Scholar]
- Meister, C.; Cotterell, R.; Vieira, T. If beam search is the answer, what was the question? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2173–2185. [Google Scholar]
- Huang, T.H.; Ferraro, F.; Mostafazadeh, N.; Misra, I.; Agrawal, A.; Devlin, J.; Girshick, R.; He, X.; Kohli, P.; Batra, D.; et al. Visual storytelling. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1233–1239. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levy, R.; Jaeger, T.F. Speakers optimize information density through syntactic reduction. Adv. Neural Inf. Process. Syst. 2007, 19, 849. [Google Scholar]
- Ghazvininejad, M.; Brockett, C.; Chang, M.W.; Dolan, B.; Gao, J.; Yih, W.t.; Galley, M. A knowledge-grounded neural conversation model. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018. [Google Scholar]
- Shuster, K.; Humeau, S.; Bordes, A.; Weston, J. Image-Chat: Engaging Grounded Conversations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 June 2020; pp. 2414–2429. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Johnson, M.; Schuster, M.; Le, Q.V.; Krikun, M.; Wu, Y.; Chen, Z.; Thorat, N.; Viégas, F.; Wattenberg, M.; Corrado, G.; et al. Google’s multilingual neural machine translation system: Enabling zero-shot translation. Trans. Assoc. Comput. Linguist. 2017, 5, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A.N.; Gouws, S.; Jones, L.; Kaiser, Ł.; Kalchbrenner, N.; Parmar, N.; et al. Tensor2tensor for neural machine translation. arXiv 2018, arXiv:1803.07416. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the NAACL-HLT 2019: Demonstrations, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.Y. MASS: Masked Sequence to Sequence Pre-training for Language Generation. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5926–5936. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Gehrmann, S.; Deng, Y.; Rush, A. Bottom-Up Abstractive Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4098–4109. [Google Scholar]
- Kryściński, W.; Paulus, R.; Xiong, C.; Socher, R. Improving Abstraction in Text Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1808–1817. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1797–1807. [Google Scholar]
- Liu, Y.; Lapata, M. Text Summarization with Pretrained Encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3730–3740. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified Language Model Pre-training for Natural Language Understanding and Generation. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Vinyals, O.; Le, Q. A neural conversational model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Dušek, O.; Jurčíček, F. A Context-aware Natural Language Generator for Dialogue Systems. In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Los Angeles, CA, USA, 13–15 September 2016; pp. 185–190. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Jurafsky, D.; Galley, M.; Gao, J. Deep Reinforcement Learning for Dialogue Generation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1192–1202. [Google Scholar]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Moura, J.M.; Parikh, D.; Batra, D. Visual dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 326–335. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 110–119. [Google Scholar]
- Baheti, A.; Ritter, A.; Li, J.; Dolan, B. Generating More Interesting Responses in Neural Conversation Models with Distributional Constraints. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3970–3980. [Google Scholar] [CrossRef]
- Wolf, T.; Sanh, V.; Chaumond, J.; Delangue, C. TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents. arXiv 2019, arXiv:1901.08149. [Google Scholar]
- Fan, A.; Lewis, M.; Dauphin, Y. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 889–898. [Google Scholar] [CrossRef]
- Holtzman, A.; Buys, J.; Forbes, M.; Bosselut, A.; Golub, D.; Choi, Y. Learning to Write with Cooperative Discriminators. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1638–1649. [Google Scholar]
- See, A.; Pappu, A.; Saxena, R.; Yerukola, A.; Manning, C.D. Do Massively Pretrained Language Models Make Better Storytellers? In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 843–861. [Google Scholar]
- Zhai, F.; Demberg, V.; Koller, A. Story Generation with Rich Details. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 2346–2351. [Google Scholar]
- Caccia, M.; Caccia, L.; Fedus, W.; Larochelle, H.; Pineau, J.; Charlin, L. Language GANs Falling Short. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kiddon, C.; Zettlemoyer, L.; Choi, Y. Globally coherent text generation with neural checklist models. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 329–339. [Google Scholar]
- Wiseman, S.; Shieber, S.; Rush, A. Challenges in Data-to-Document Generation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 1–7 September 2017; pp. 2253–2263. [Google Scholar]
- Puzikov, Y.; Gurevych, I. E2E NLG challenge: Neural models vs. templates. In Proceedings of the 11th International Conference on Natural Language Generation, Tilburg, The Netherlands, 5–8 November 2018; pp. 463–471. [Google Scholar]
- Gehrmann, S.; Dai, F.Z.; Elder, H.; Rush, A.M. End-to-end content and plan selection for data-to-text generation. arXiv 2018, arXiv:1810.04700. [Google Scholar]
- Marcheggiani, D.; Perez-Beltrachini, L. Deep Graph Convolutional Encoders for Structured Data to Text Generation. In Proceedings of the 11th International Conference on Natural Language Generation, Tilburg, The Netherlands, 5–8 November 2018; pp. 1–9. [Google Scholar]
- Puduppully, R.; Dong, L.; Lapata, M. Data-to-text generation with content selection and planning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6908–6915. [Google Scholar]
- Kale, M.; Rastogi, A. Text-to-Text Pre-Training for Data-to-Text Tasks. In Proceedings of the 13th International Conference on Natural Language Generation, Dublin, Ireland, 15–18 December 2020; pp. 97–102. [Google Scholar]
- Zhao, C.; Walker, M.; Chaturvedi, S. Bridging the Structural Gap Between Encoding and Decoding for Data-To-Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2481–2491. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10578–10587. [Google Scholar]
- Ippolito, D.; Kriz, R.; Sedoc, J.; Kustikova, M.; Callison-Burch, C. Comparison of Diverse Decoding Methods from Conditional Language Models. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3752–3762. [Google Scholar]
- Yu, L.; Tan, H.; Bansal, M.; Berg, T.L. A joint speakerlistener-reinforcer model for referring expressions. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2. [Google Scholar]
- Panagiaris, N.; Hart, E.; Gkatzia, D. Generating unambiguous and diverse referring expressions. Comput. Speech Lang. 2021, 68, 101184. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4584–4593. [Google Scholar]
- Krause, J.; Johnson, J.; Krishna, R.; Fei-Fei, L. A hierarchical approach for generating descriptive image paragraphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–216 July 2017; pp. 317–325. [Google Scholar]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Carlos Niebles, J. Dense-captioning events in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar]
- Melas-Kyriazi, L.; Rush, A.M.; Han, G. Training for diversity in image paragraph captioning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 757–761. [Google Scholar]
- Chatterjee, M.; Schwing, A.G. Diverse and coherent paragraph generation from images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 729–744. [Google Scholar]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.F.; Wang, W.Y. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4213–4222. [Google Scholar]
- Salvador, A.; Drozdzal, M.; Giro-i Nieto, X.; Romero, A. Inverse cooking: Recipe generation from food images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10453–10462. [Google Scholar]
- Song, L.; Zhang, Y.; Wang, Z.; Gildea, D. A Graph-to-Sequence Model for AMR-to-Text Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 1616–1626. [Google Scholar]
- Wang, T.; Wan, X.; Jin, H. AMR-to-text generation with graph transformer. Trans. Assoc. Comput. Linguist. 2020, 8, 19–33. [Google Scholar] [CrossRef]
- Mager, M.; Fernandez Astudillo, R.; Naseem, T.; Sultan, M.A.; Lee, Y.S.; Florian, R.; Roukos, S. GPT-too: A Language-Model-First Approach for AMR-to-Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; pp. 1846–1852. [Google Scholar]
- McKeown, K.; Kukich, K.; Shaw, J. Practical issues in automatic documentation generation. In Proceedings of the 3rd Applied Natural Language Processing Conference (ANLP 94), Trento, Italy, 31 March–3 April 1992. [Google Scholar]
- Shetty, R.; Rohrbach, M.; Anne Hendricks, L.; Fritz, M.; Schiele, B. Speaking the Same Language: Matching Machine to Human Captions by Adversarial Training. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards Diverse and Natural Image Descriptions via a Conditional GAN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- van Miltenburg, E.; Elliott, D.; Vossen, P. Measuring the Diversity of Automatic Image Descriptions. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; pp. 1730–1741. [Google Scholar]
- Paiva, D.S.; Evans, R. Empirically-based Control of Natural Language Generation. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05); Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 58–65. [Google Scholar] [CrossRef] [Green Version]
- Viethen, J.; Dale, R. Speaker-dependent variation in content selection for referring expression generation. In Proceedings of the Australasian Language Technology Association Workshop, Melbourne, Australia, 9–10 December 2010; pp. 81–89. [Google Scholar]
- Castro Ferreira, T.; Krahmer, E.; Wubben, S. Towards more variation in text generation: Developing and evaluating variation models for choice of referential form. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Berlin, Germany, 2016; pp. 568–577. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Ji, R.; Sun, X.; Wu, Y.; Su, J. Groupcap: Group-based image captioning with structured relevance and diversity constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1345–1353. [Google Scholar]
- Dai, B.; Fidler, S.; Lin, D. A neural compositional paradigm for image captioning. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 658–668. [Google Scholar]
- Deshpande, A.; Aneja, J.; Wang, L.; Schwing, A.G.; Forsyth, D. Fast, diverse and accurate image captioning guided by part-of-speech. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10695–10704. [Google Scholar]
- Wang, Q.; Chan, A.B. Describing like humans: On diversity in image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4195–4203. [Google Scholar]
- Belz, A.; Reiter, E. Comparing automatic and human evaluation of NLG systems. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics; Association for Computational Linguistics: Trento, Italy, 2006. [Google Scholar]
- Reiter, E.; Belz, A. An investigation into the validity of some metrics for automatically evaluating natural language generation systems. Comput. Linguist. 2009, 35, 529–558. [Google Scholar] [CrossRef]
- Gkatzia, D.; Mahamood, S. A snapshot of NLG evaluation practices 2005-2014. In Proceedings of the 15th European Workshop on Natural Language Generation (ENLG), Brighton, UK, 10–11 September 2015; pp. 57–60. [Google Scholar]
- Novikova, J.; Dušek, O.; Cercas Curry, A.; Rieser, V. Why We Need New Evaluation Metrics for NLG. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2241–2252. [Google Scholar] [CrossRef]
- Howcroft, D.M.; Belz, A.; Clinciu, M.A.; Gkatzia, D.; Hasan, S.A.; Mahamood, S.; Mille, S.; van Miltenburg, E.; Santhanam, S.; Rieser, V. Twenty Years of Confusion in Human Evaluation: NLG Needs Evaluation Sheets and Standardised Definitions. In Proceedings of the 13th International Conference on Natural Language Generation; Association for Computational Linguistics: Dublin, Ireland, 2020; pp. 169–182. [Google Scholar]
- Nichols, J. Linguistic Diversity in Space and Time; University of Chicago Press: Chicago, IL, USA, 1992. [Google Scholar]
- Gimpel, K.; Batra, D.; Dyer, C.; Shakhnarovich, G. A Systematic Exploration of Diversity in Machine Translation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Seattle, DC, USA, 2013; pp. 1100–1111. [Google Scholar]
- Vijayakumar, A.K.; Cogswell, M.; Selvaraju, R.R.; Sun, Q.; Lee, S.; Crandall, D.; Batra, D. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv 2016, arXiv:1610.02424. [Google Scholar]
- Zhang, Y.; Galley, M.; Gao, J.; Gan, Z.; Li, X.; Brockett, C.; Dolan, B. Generating Informative and Diverse Conversational Responses via Adversarial Information Maximization. In Proceedings of the 32nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 1815–1825. [Google Scholar]
- Wang, Z.; Wu, F.; Lu, W.; Xiao, J.; Li, X.; Zhang, Z.; Zhuang, Y. Diverse Image Captioning via GroupTalk. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2957–2964. [Google Scholar]
- Zhu, Y.; Lu, S.; Zheng, L.; Guo, J.; Zhang, W.; Wang, J.; Yu, Y. Texygen: A benchmarking platform for text generation models. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 1097–1100. [Google Scholar]
- Alihosseini, D.; Montahaei, E.; Soleymani Baghshah, M. Jointly Measuring Diversity and Quality in Text Generation Models. In Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 90–98. [Google Scholar] [CrossRef]
- Hashimoto, T.; Zhang, H.; Liang, P. Unifying Human and Statistical Evaluation for Natural Language Generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 1689–1701. [Google Scholar] [CrossRef]
- Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; Weston, J. Personalizing Dialogue Agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 2204–2213. [Google Scholar] [CrossRef] [Green Version]
- Kriz, R.; Sedoc, J.; Apidianaki, M.; Zheng, C.; Kumar, G.; Miltsakaki, E.; Callison-Burch, C. Complexity-weighted loss and diverse reranking for sentence simplification. arXiv 2019, arXiv:1904.02767. [Google Scholar]
- Tam, Y.C. Cluster-based beam search for pointer-generator chatbot grounded by knowledge. Comput. Speech Lang. 2020, 64, 101094. [Google Scholar] [CrossRef]
- Hotate, K.; Kaneko, M.; Komachi, M. Generating Diverse Corrections with Local Beam Search for Grammatical Error Correction. In Proceedings of the 28th International Conference on Computational Linguistics; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 2132–2137. [Google Scholar] [CrossRef]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Massarelli, L.; Petroni, F.; Piktus, A.; Ott, M.; Rocktäschel, T.; Plachouras, V.; Silvestri, F.; Riedel, S. How Decoding Strategies Affect the Verifiability of Generated Text. Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 223–235. [Google Scholar] [CrossRef]
- Schüz, S.; Han, T.; Zarrieß, S. Diversity as a By-Product: Goal-oriented Language Generation Leads to Linguistic Variation. In Proceedings of the 22nd Annual SIGdial Meeting on Discourse and Dialogue. Association for Computational Linguistics, Singapore, 29–31 July 2021. [Google Scholar]
- Zhang, H.; Duckworth, D.; Ippolito, D.; Neelakantan, A. Trading Off Diversity and Quality in Natural Language Generation. In Proceedings of the Workshop on Human Evaluation of NLP Systems (HumEval); Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 25–33. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Guided Open Vocabulary Image Captioning with Constrained Beam Search. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 936–945. [Google Scholar] [CrossRef] [Green Version]
- Balakrishnan, A.; Rao, J.; Upasani, K.; White, M.; Subba, R. Constrained Decoding for Neural NLG from Compositional Representations in Task-Oriented Dialogue. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 831–844. [Google Scholar] [CrossRef]
- Hokamp, C.; Liu, Q. Lexically constrained decoding for sequence generation using grid beam search. arXiv 2017, arXiv:1704.07138. [Google Scholar]
- Post, M.; Vilar, D. Fast Lexically Constrained Decoding with Dynamic Beam Allocation for Neural Machine Translation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 1314–1324. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Lapata, M. Chinese Poetry Generation with Recurrent Neural Networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Doha, Qatar, 2014; pp. 670–680. [Google Scholar] [CrossRef]
- Ghazvininejad, M.; Shi, X.; Choi, Y.; Knight, K. Generating Topical Poetry. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 1183–1191. [Google Scholar] [CrossRef] [Green Version]
- Hopkins, J.; Kiela, D. Automatically Generating Rhythmic Verse with Neural Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, USA, 2017; pp. 168–178. [Google Scholar] [CrossRef]
- Andreas, J.; Klein, D. Reasoning about Pragmatics with Neural Listeners and Speakers. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 1173–1182. [Google Scholar] [CrossRef] [Green Version]
- Cohn-Gordon, R.; Goodman, N.; Potts, C. Pragmatically Informative Image Captioning with Character-Level Inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers); Association for Computational Linguistics: New Orleans, LO, USA, 2018; pp. 439–443. [Google Scholar]
- Vedantam, R.; Bengio, S.; Murphy, K.; Parikh, D.; Chechik, G. Context-aware captions from context-agnostic supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 251–260. [Google Scholar]
- Zarrieß, S.; Schlangen, D. Know What You Don’t Know: Modeling a Pragmatic Speaker that Refers to Objects of Unknown Categories. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 654–659. [Google Scholar] [CrossRef]
- Shen, S.; Fried, D.; Andreas, J.; Klein, D. Pragmatically Informative Text Generation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4060–4067. [Google Scholar] [CrossRef]
- Kim, H.; Kim, B.; Kim, G. Will I Sound Like Me? Improving Persona Consistency in Dialogues through Pragmatic Self-Consciousness. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 904–916. [Google Scholar] [CrossRef]
- Gu, J.; Cho, K.; Li, V.O. Trainable Greedy Decoding for Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1968–1978. [Google Scholar]
- Krahmer, E.; van Deemter, K. Computational Generation of Referring Expressions: A Survey. Comput. Linguist. 2011, 38. [Google Scholar] [CrossRef]
- Dale, R.; Reiter, E. Computational interpretations of the Gricean maxims in the generation of referring expressions. Cogn. Sci. 1995, 19, 233–263. [Google Scholar] [CrossRef]
- Frank, M.C.; Goodman, N.D. Predicting pragmatic reasoning in language games. Science 2012, 336, 998. [Google Scholar] [CrossRef] [Green Version]
- Dušek, O.; Novikova, J.; Rieser, V. Findings of the E2E NLG Challenge. In Proceedings of the 11th International Conference on Natural Language Generation; Association for Computational Linguistics: Tilburg, The Netherlands, 2018; pp. 322–328. [Google Scholar] [CrossRef]
- Chen, Y.; Cho, K.; Bowman, S.R.; Li, V.O. Stable and Effective Trainable Greedy Decoding for Sequence to Sequence Learning. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Workshop Track, Online. 30 April–3 May 2018. [Google Scholar]
- Belinkov, Y.; Glass, J. Analysis methods in neural language processing: A survey. Trans. Assoc. Comput. Linguist. 2019, 7, 49–72. [Google Scholar] [CrossRef]
- Devlin, J.; Cheng, H.; Fang, H.; Gupta, S.; Deng, L.; He, X.; Zweig, G.; Mitchell, M. Language Models for Image Captioning: The Quirks and What Works. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers); Association for Computational Linguistics: Beijing, China, 2015; pp. 100–105. [Google Scholar]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T.L. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 787–798. [Google Scholar]
- De Vries, H.; Strub, F.; Chandar, S.; Pietquin, O.; Larochelle, H.; Courville, A. Guesswhat?! visual object discovery through multi-modal dialogue. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5503–5512. [Google Scholar]
- Grice, H.P. Logic and conversation. In Speech Acts; Brill: Leiden, The Nertherlands, 1975; pp. 41–58. [Google Scholar] [CrossRef]
- Clark, H.H. Using Language; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar]
- Gkatzia, D.; Hastie, H.; Lemon, O. Finding middle ground? Multi-objective Natural Language Generation from time-series data. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; Volume 2, pp. 210–214. [Google Scholar]
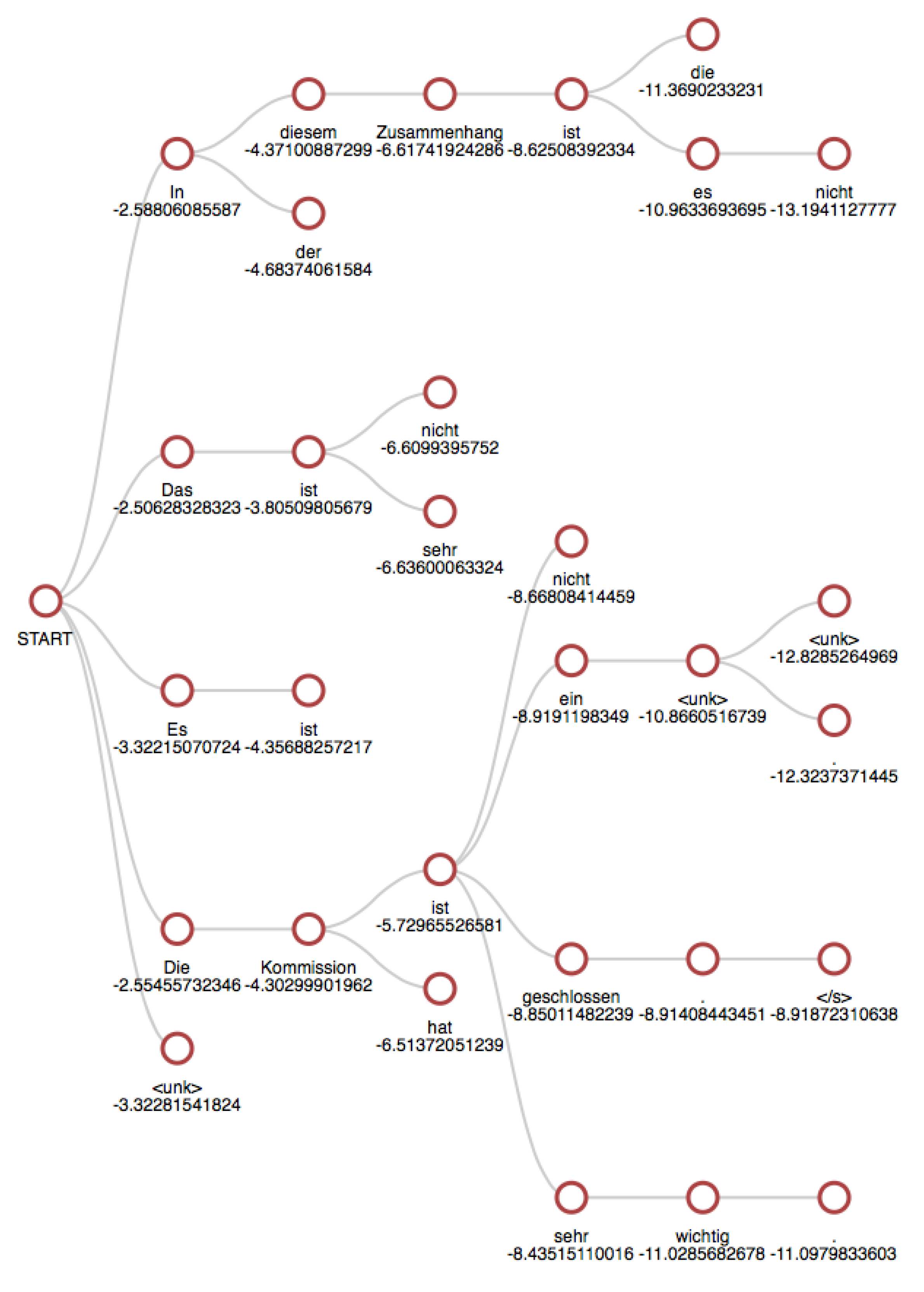
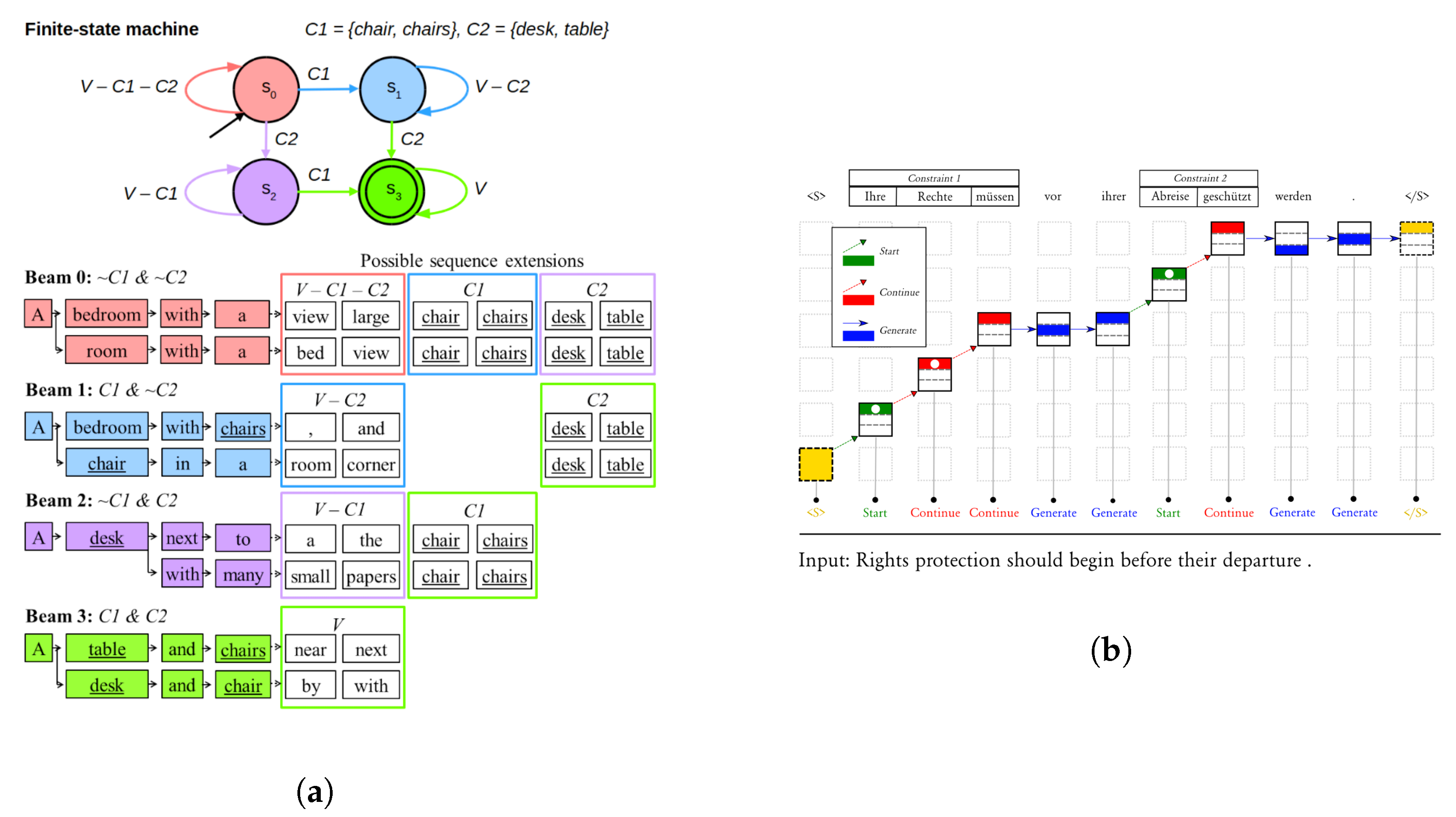

{kind=link}
{kind=link}
| Papers | |
|---|---|
| Standard definitions | Lowerre [8], Graves [39], Klein et al. [55], Stahlberg and Byrne [56], Meister et al. [57] |
| Variants | |
| stopping criteria | Klein et al. [55], Huang et al. [58], Newman et al. [59] |
| length normalization | Graves [39], Klein et al. [55] |
| length reward | Huang et al. [58], He et al. [60], Murray and Chiang [61] |
| shrinking beam | Bahdanau et al. [62] |
| coverage | Klein et al. [55] |
| pruning thresholds | Freitag and Al-Onaizan [63] |
| formal reformulations | Rush et al. [37], Meister et al. [57] |
| Analyses | |
| negative effect of large beam width | Yang et al. [64], Koehn and Knowles [65], Cohen and Beck [66] |
| positive effect of large beam width | Vinyals et al. [67], Karpathy and Fei-Fei [68] |
| bias towards short sequences | Graves [39], Huang et al. [58], Murray and Chiang [61], Sountsov and Sarawagi [69], Zarrie and Schlangen [70], Newman et al. [59] |
| repetitive output | Karpathy and Fei-Fei [68], Li et al. [54], Holtzman et al. [71] |
| bias towards same prefix hypotheses | Freitag and Al-Onaizan [63], Shao et al. [72], Kulikov et al. [73] |
| usefulness of beam search objective | Stahlberg and Byrne [56], Meister et al. [74] |
| System | Search | Sampling | Hyperparameters | Eval |
|---|---|---|---|---|
| Machine Translation | ||||
| Bahdanau et al. [62] | ✓ | - | - (shrinking beam, cf. Reference [58]) | - |
| Wu et al. [80] | ✓ | - | length penalty 0.2, coverage penalty 0.2, pruning, beam width 3 | ✓ |
| Sennrich et al. [81] | ✓ | - | width 12, probs normalized by sentence length | |
| Johnson et al. [82] | ? | ? | ? | ? |
| Klein et al. [55] | ✓ | - | width 5 | - |
| Vaswani et al. [83] | ✓ | - | width 4, length penalty = 0.6 | - |
| Ott et al. [84] | ✓ | - | width 4, length penalty = 0.6 | - |
| Song et al. [85] | ? | ? | ? | ? |
| Rothe et al. [10] | - | width 4, length penalty 0.6 | - | |
| Summarization | ||||
| See et al. [86] | ✓ | - | width 4 | - |
| Gehrmann et al. [87] | ✓ | - | length penalty, coverage penalty, repetition penalty, trigram blocking | ✓ |
| Kryściński et al. [88] | ✓ | - | trigram blocking | - |
| Narayan et al. [89] | ✓ | - | width 10 | - |
| Liu and Lapata [90] | ✓ | - | width 5, tuned length penalty, trigram blocking | - |
| Dong et al. [91] | ✓ | - | width 5, trigram blocking, tuned max. length | |
| Song et al. [85] | ✓ | - | width 5 | - |
| Radford et al. [11] | - | ✓ | top-k sampling, | |
| Rothe et al. [10] | ? | ? | ? | ? |
| Dialog Response Generation | ||||
| Vinyals and Le [92] | ✓ | - | greedy | - |
| Wen et al. [3] | - | ✓ | - | - |
| Serban et al. [12] | ✓ | ✓ | - | ✓ |
| Dušek and Jurčíček [93] | ✓ | - | width 20 | - |
| Li et al. [94] | ✓ | - | width 20 | - |
| Shao et al. [72] | ✓ | ✓ | stochastic beam search | ✓ |
| Das et al. [95] | ? | ? | ? | ? |
| Ghazvininejad et al. [78] | ✓ | - | width 200, max. length 30, word count penalty, likelihood penalty as in Reference [96] | - |
| Baheti et al. [97] | ✓ | - | width 20, distributional constraints | |
| Wolf et al. [98] | ✓ | ✓ | width 5 | - |
| Shuster et al. [79] | - | width 2, trigram blocking | - | |
| Story and Open-ended Text Generation | ||||
| Fan et al. [99] | - | ✓ | top-k sampling, | - |
| Holtzman et al. [100] | ✓ | ✓ | width 10, top-k sampling (temp. 1.8) | - |
| See et al. [101] | - | ✓ | top-k sampling, | ✓ |
| Zhai et al. [102] | ✓ | - | width 100 | - |
| Caccia et al. [103] | ✓ | ✓ | temperature range, stochastic beam search | ✓ |
| System | Search | Sampling | Hyperparameters | Eval |
|---|---|---|---|---|
| Data-To-Text Generation | ||||
| Kiddon et al. [104] | ✓ | - | width 10, custom candidate selection (checklist) | - |
| Wiseman et al. [105] | ✓ | - | width 1/5 | ✓ |
| Puzikov and Gurevych [106] | ✓ | - | custom candidate selection | - |
| Gehrmann et al. [107] | ✓ | - | width 10, length and coverage penalty, custom repetition blocking | - |
| Marcheggiani and Perez-Beltrachini [108] | ? | ? | ? | ? |
| Puduppully et al. [109] | ✓ | - | width 5 | - |
| Kale and Rastogi [110] | ✓ | - | width 1 | - |
| Zhao et al. [111] | ? | ? | ? | ? |
| Image Captioning | ||||
| Vinyals et al. [67] | ✓ | - | width 20 | ✓ |
| Xu et al. [112] | ? | ? | ? | ? |
| Karpathy and Fei-Fei [68] | ✓ | - | width 7 | ✓ |
| Rennie et al. [42] | ✓ | - | width 1/3 | ✓ |
| Lu et al. [113] | ✓ | - | width 3 | - |
| Anderson et al. [114] | ? | ? | ? | ? |
| Cornia et al. [115] | ✓ | - | - | - |
| Ippolito et al. [116] | ✓ | ✓ | diverse settings | ✓ |
| Referring Expression Generation | ||||
| Yu et al. [117] | ✓ | - | - | |
| Castro Ferreira et al. [5] | ✓ | - | tuned with between 1 and 5, length normalization () | |
| Zarrie and Schlangen [70] | ✓ | - | diverse settings | ✓ |
| Panagiaris et al. [118] | ✓ | ✓ | diverse settings | ✓ |
| Image or Video Paragraph Generation | ||||
| Yu et al. [119] | ✓ | - | customized stopping criterion | - |
| Krause et al. [120] | ✓ | ✓ | 1st sentence beam, then sampling (baseline) | - |
| Krishna et al. [121] | ✓ | ✓ | width 5 | |
| Melas-Kyriazi et al. [122] | ✓ | - | repetition penalty, trigram blocking | ✓ |
| Chatterjee and Schwing [123] | - | ✓ | - | |
| Wang et al. [124] | ✓ | - | - | - |
| Salvador et al. [125] | - | ✓ | - | - |
| AMR-To-Text Generation | ||||
| Song et al. [126] | ✓ | - | width 6 | - |
| Wang et al. [127] | ✓ | - | width 6 | - |
| Mager et al. [128] | ✓ | ✓ | width 5/10/15, nucleus sampling | ✓ |
| Papers | |
|---|---|
| Evaluation approaches | |
| local diversity | Gimpel et al. [146], Vijayakumar et al. [147], Li et al. [96], Ippolito et al. [116], Zhang et al. [153] |
| global diversity | van Miltenburg et al. [132] |
| BLEU-based | Shetty et al. [130], Wang et al. [149], Zhu et al. [150], Alihosseini et al. [151] |
| other | Hashimoto et al. [152], Zhang et al. [148] |
| Methods | |
| Diversified beam search | Li et al. [54], Freitag and Al-Onaizan [63], Kulikov et al. [73], Ippolito et al. [116], Kriz et al. [154], Tam [155], Melas-Kyriazi et al. [122], Hotate et al. [156] |
| Sampling | Ackley et al. [157], Holtzman et al. [71], Fan et al. [99], Caccia et al. [103] |
| Combined search and sampling | Caccia et al. [103], Massarelli et al. [158] |
| Analyses | |
| quality-diversity trade-off | Ippolito et al. [116], Panagiaris et al. [118], Mager et al. [128], Schüz et al. [159], Zhang et al. [160] |
| verifiability-diversity trade-off | Massarelli et al. [158] |
| Task | Decoding Method | |
|---|---|---|
| Lexical constraints | long text generation | beam search with simple candidate filter, Kiddon et al. [104] |
| data-to-text | bema search with simple candidate filter, Puzikov and Gurevych [106] | |
| open vocabulary image captioning | constrained beam search Anderson et al. [161] | |
| post-editing in MT | grid beam search, Hokamp and Liu [163]; grid beam search, Post and Vilar [164] | |
| dialog generation | beam search with topical and distributional constraints, Baheti et al. [97] | |
| Structure and form | poetry generation | beam search with simple filtering, Zhang and Lapata [165]; automaton-based decoding, Ghazvininejad et al. [166] and Hopkins and Kiela [167] |
| task-oriented dialog | constrained beam search, Balakrishnan et al. [162] | |
| Pragmatics | image captioning | RSA, Andreas and Klein [168], Cohn-Gordon et al. [169]; discriminative beam search, Vedantam et al. [170] |
| zero-shot REG | modified RSA, Zarrie and Schlangen [171] | |
| data-to-text | distractor-based and reconstructor-based decoding, Shen et al. [172] | |
| dialog generation | modified RSA, Kim et al. [173] | |
| MT | trainable decoding, Gu et al. [174] | |
| REG | trainable decoding, Zarrie and Schlangen [70] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zarrieß, S.; Voigt, H.; Schüz, S. Decoding Methods in Neural Language Generation: A Survey. Information 2021, 12, 355. https://doi.org/10.3390/info12090355
Zarrieß S, Voigt H, Schüz S. Decoding Methods in Neural Language Generation: A Survey. Information. 2021; 12(9):355. https://doi.org/10.3390/info12090355
Chicago/Turabian StyleZarrieß, Sina, Henrik Voigt, and Simeon Schüz. 2021. "Decoding Methods in Neural Language Generation: A Survey" Information 12, no. 9: 355. https://doi.org/10.3390/info12090355
APA StyleZarrieß, S., Voigt, H., & Schüz, S. (2021). Decoding Methods in Neural Language Generation: A Survey. Information, 12(9), 355. https://doi.org/10.3390/info12090355