1. Introduction
The presence of multimedia content, namely, images and videos, is continuously increasing in the disseminating messages exchanged in the online social networks (OSNs). Since all modern mobile devices (e.g., cellular phones and tablets) integrate superior cameras and support high speed broadband connections (i.e., 4G technology), this trend is facilitated. According to [
1], images in Twitter are not only disseminated in an increased fashion, but also appear in a significant portion of social posts, gaining substantially more engagement, in terms of retweets, likes, and replies, contrary to those without. Therefore, social images have transformed into an indispensable characteristic of the OSNs, complementing or often overshadowing the textual information. However, despite the well-known adage “a picture is worth a thousand words”, little attention has been paid to that type of content and to the insights they can provide for enriching the social profiles.
Until only recently, when research interest arose for the accompanying multimedia content of OSNs posts, social analytics were exclusively oriented toward the textual information. As the volume of videos and images disseminated in the OSNs is constantly increasing, these types of content should also be evaluated, as they could contain valuable latent data. As reported in [
2], social images can supplement the textual information found in the posts, by containing additional context, thereby being capable of further enriching the diffused messages. As a result of the recent rise of deep neural network (DNN) architectures, several commercial products for image classification and analysis are available (Microsoft Azure Computer Vision (
https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/); Google Cloud Vision API (
https://cloud.google.com/vision/)) in the form of software-as-a-service (SaaS), relying on state-of-the-art machine learning (ML) pre-trained models. These services can extract a wide spectrum of information from images, including text, labels, colors, logos, objects, and emotions. Consequently, the incorporation and combination of this latent context with the established textual information of the social messages can lead to a more holistic and accurate representation of the Twittersphere.
Since the context and the information depicted in the OSNs images can be textually defined, all applications and frameworks relying on text can now be applied to that type of content as well. Such an exercise is the identification of similar images by evaluating their semantic similarity, purely relying on the textual representations of their contexts. The semantic similarity of two or more terms measures how similar their meaning is. Despite their syntactic differences, two words can have the same interpretation, such as the words “dog” and “hound”. Due to the recent advancements in the area of natural language processing (NLP), the identification of semantic similarities among individual terms or even documents is possible. Semantic similarity can be utilized in a variety of text-based tasks, including—but not limited to—classification, recommendation, summarization, synonymity identification, and clustering. The predominant technique for measuring the relevance and similarity of terms’ meanings is the Word2Vec ([
3,
4]) model, relying on word embeddings, where real-valued vectors in a multi-dimensional space represent words. The encoded patterns of the vectors can be represented as linear functions. As an example, the vector calculation of [v(“Athens”) − v(“Greece”) + v(“Italy”)] is closer to [v(“Rome”)] than any other term vector. Based on said model, which has been trained on a corpus of sufficient and appropriate data, the similarity scores can be calculated using the cosine similarity metric of the terms’ vector values.
There were three aims for this study. Firstly, a framework was proposed based on the latent and depicted context of Twitter images towards the enrichment of social analytics with textual information and semantics. The aforementioned image context is acquired by employing the Google Cloud Vision API along with OCR (optical character recognition) techniques for recognizing and extracting the depicted text. Our evaluation revealed that the overwhelming majority of the disseminated images contain valuable information and the dynamics of such latent information should not be ignored any longer. Secondly, this latent textual and semantic information was utilized towards the identification of images with similar semantic content. Our intention was to evaluate this type of information for further improving image search, retrieval, and recommendation tasks. Our evaluation indicated that the usage of latent labels also complemented by the OCR-derived text generate the best results, compared to the extracted OCR text alone. Thirdly, we prepared a dataset consisting of 197 Twitter accounts, classified into three broad communities (i.e., politics, celebrities, press), having 94,745 annotated images, which in turn have been classified by 7098 labels. This dataset will be available to the research community. Text extracted using OCR techniques is depicted in the majority of these images (62.2%), thereby validating our intuitions for conducting this study.
The Twitter accounts and their disseminated images and tweets described in this study can be also retrieved from InfluenceTracker (
http://InfluenceTracker.com/), a publicly available website providing Twitter-related information as linked data and various social analytics. As case studies, the proposed framework was applied twice; firstly, on a community of 130 accounts related to the domain of “Politics”, and secondly, to 54 accounts characterized as “Celebrities”. In both scenarios the communities can be further split into smaller and possibly overlapping ones. In order to classify the accounts in these communities, they had firstly to be associated with the DBpedia resources (URIs) best describing them, a methodology presented in our previous work [
5].
The remainder of this study is organized as follows. In the next section, we provide an overview of the related work on the analysis of image content in OSNs and its applications, and on the utilization of Word2Vec word embedding and semantic similarity techniques for a series of OSN analytics tasks. In
Section 3 we analytically present the proposed framework towards the enrichment of social analytics with semantics and textual context. In
Section 4 we provide an overview of the methodology towards the identification of accounts related to the examined communities (i.e., “Politics” and “Celebrities”). In
Section 5 we present in detail the case studies, analyze the experimental results of our methodology, and discuss the interpretations of our findings. In
Section 6 we employ word embedding techniques for investigating the best type of latent semantic information towards the identification of similar images. Finally,
Section 7 provides the conclusions of our study by summarizing the derived outcomes while providing considerations of our future directions.
5. Experimental Results and Dataset
In this section, we analytically present and discuss the results of the proposed framework presented in
Section 3, towards the enrichment of the social analytics with semantics and hidden textual information. To this end, we exploit the latent information of Twitter images of the “Politics” and “Celebrities” communities, by automatically labeling them and extracting the depicted text by employing the Google Cloud Vision API platform. Despite the fact that our published dataset also contains related social information about the press, we did not analyze its results, as this category is quite generic (includes Twitter accounts related to news press agencies); thus, it cannot be further split into smaller groups, contrary to the other examined communities. In addition, the number of Twitter accounts in the “Press” community is uneven with respect to the ones labeled “Politics” and “Celebrities”.
5.1. Case Study 1: Political Accounts
The first case study is focused on a community of 130 Twitter accounts of the political domain, which can be further divided into smaller and overlapping groups, as derived from the methodology described in
Section 4. For each account, up to 500 images were extracted from the tweets and downloaded, which were then submitted to the Google Cloud Vision API for labelling and text extraction, as presented in
Section 3.2.
The details of the dataset used for the aims of this case study are presented in
Table 2. Specifically, it consists of 39,499 annotated images, classified by 4059 unique labels, shared by these 130 accounts, which in turn can be further classified into 12 categories, a subset of the ones presented in
Table 1. On average, approximately 312 images were collected for each account. Furthermore, text is depicted in 26,953 of these images, which was extracted using OCR techniques, consisting of 188,077 unique terms of several languages (e.g., Greek, English, Spanish, and French). As can be observed, the majority of the images (68.2%) contain textual information, thereby validating our intuitions for conducting this study. On average, each social image of this dataset is associated with 7.6 labels and 16.9 textual terms. Finally, 1086 of these images were shared by multiple accounts, as presented in the first row of
Table 2.
The examined Twitter accounts of this case study include foreign and Greek active or ex members of parliament and political parties. On a broad level, three principal categories of political positions are considered in Greece, namely “right”, “center” and “left”; each of them can be further divided into more fine-grained groups. In order to perform our analysis and assess the existence of behavioral patterns based on the disseminated multimedia content, the accounts were grouped into the following four broad communities:
Politics: all foreign and Greek political accounts.
Right: Greek accounts classified as “far right”, “right wing” and “center right.”
Center: Greek accounts classified as “center”, “center right” and “center left.”
Left: Greek accounts classified as “left wing” and “center left.”
Our investigation is oriented toward the latent context of the accounts’ disseminated images. Therefore, two types of analyses were performed on these four communities of accounts—firstly on the labels as derived from the Google Cloud Vision API, and secondly, on the extracted by OCR techniques text.
As presented in
Section 3.2, each assigned label is complemented with a corresponding confidence score, where score ∈ (0, 1]. In order for the most dominant ones to be calculated, a formula was employed relying both on the values of the confidence score and the number of occurrences. In Equation (1) the “
” measurement is introduced, deriving as the multiplication of the sum of a label’s confidence score values by the label’s number of occurrences. The latter is adjusted according to the base-10 logarithmic scale for avoiding outlier values, properly set to preventing being equal to zero.
where n > 0 and
.
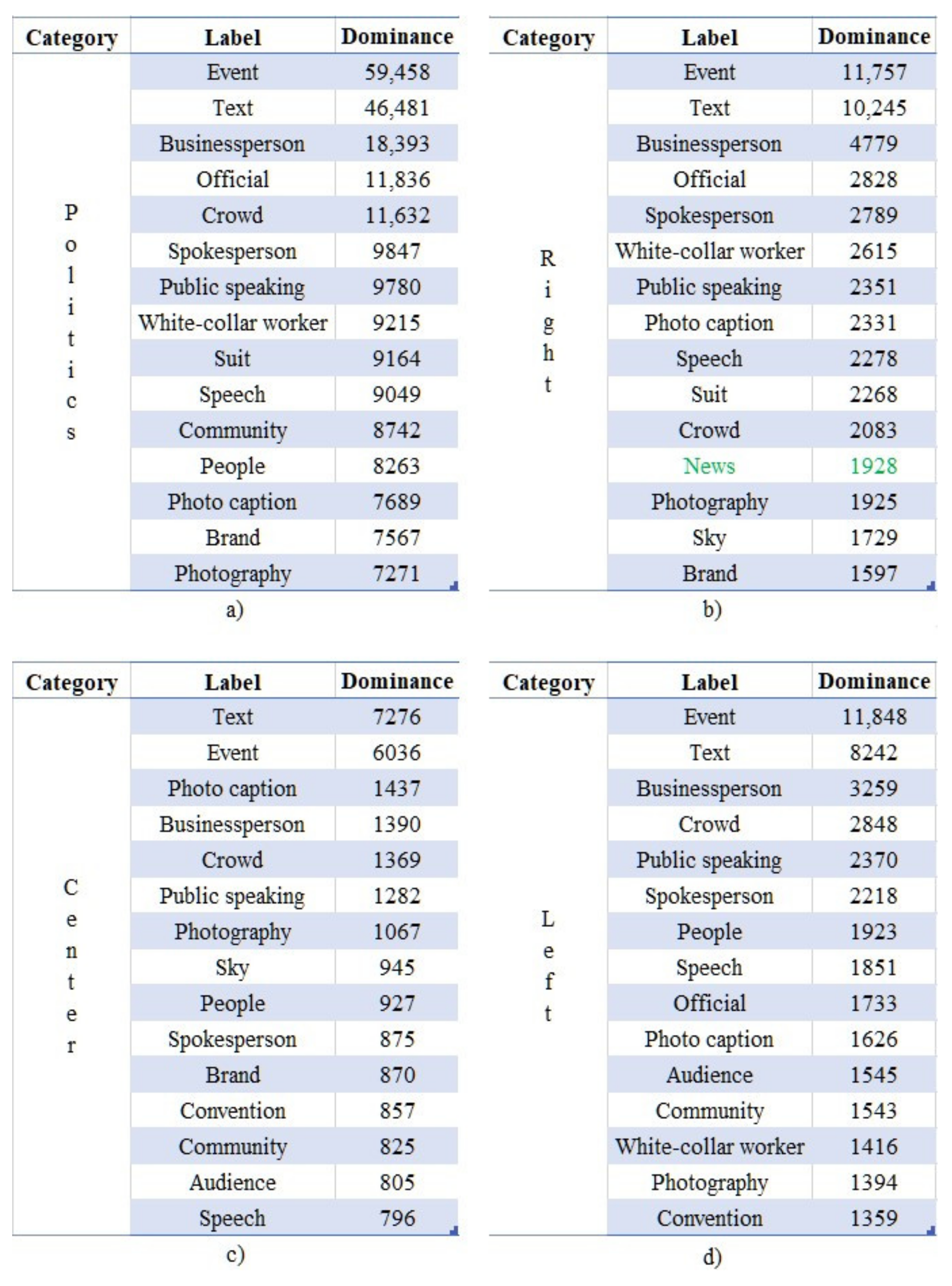
The top 15 labels of the political account’s images according to their corresponding values of “
” are presented in
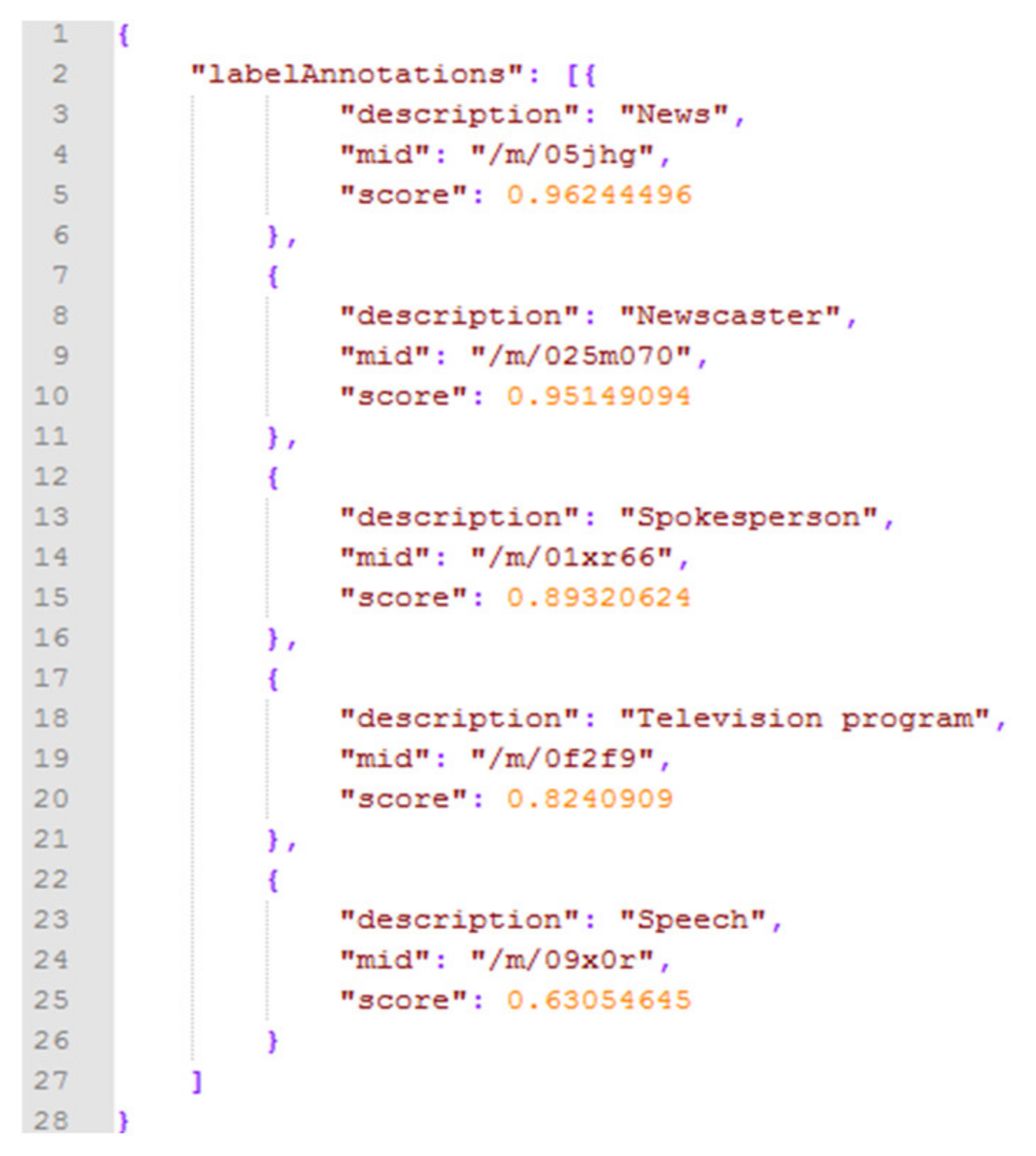
Figure 5a–d. As can be observed, all four communities are associated with the labels “Text” and “Photo caption”, indicating the rich textual information existing in those images. Furthermore, since politicians often give public speeches or interviews, the generic label “Event” appears, along with several related labels, such as “Crowd”, “Speech” and “Spokesperson”. Finally, the concepts of “Businessperson” and “White-collar worker” appear as a result of the formal dress code applied in such events.
A more in-depth investigation of these labels unveiled the existence of patterns in the latent context of the social images of accounts belonging to broad or overlapping communities. Specifically, 60% of the top 15 most dominant labels (i.e., 9 out of 15) can be found in all communities, even with interchanged ranks, while 93% of those labels (i.e., 14 out of 15) can be found at least in three communities. The only exception is the label “News”, appearing only once (highlighted in green in
Figure 5b), due to interviews of news agencies (similarly to the case of
Figure 3). This fact showcases the strong ties of the underlying patterns of the latent information shared among these overlapping groups.
An interesting fact has been revealed regarding the behavioral patterns of the members of the subcommunities “right” and “left”, which are considered to be opposite in terms of their political views and ideas. Specifically, the label “Sky” is associated with the first group, and the second one with the label “Convention”. Our investigation revealed that the members of the first group gave speeches in open spaces, and those of the second in convention centers.
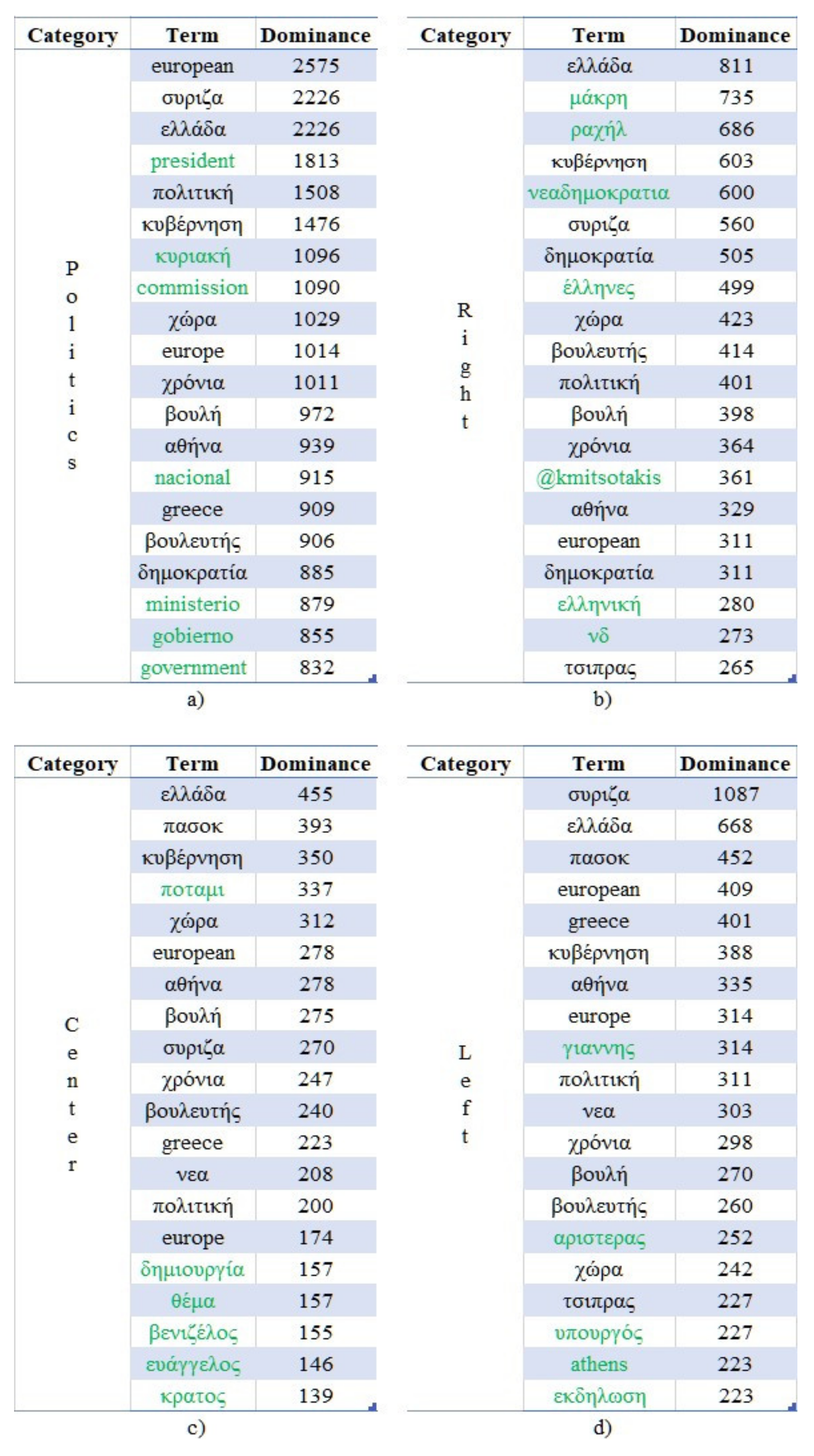
The top 20 terms of the extracted using OCR techniques text are presented in
Figure 6a–d, as ranked by a variation of the aforementioned “
.” Specifically, in Equation (2) the “
” measurement is described. In this case, the sum of the confidence score values has been replaced by the number of images in which a specific term appeared (i.e., the score is set as equal to one). Prior to measuring the dominance of the terms, all were transformed to lowercase and the Greek, English, Spanish, German, and French stopwords were removed. The investigation revealed that 68.7% of the most dominant terms (i.e., 55 out of 80) can also be found in other communities as well. The unique terms are highlighted in green.
where n > 0 and
.
As can be seen, most of the dominant terms are in Greek, since the majority of the accounts belonged to Greek politicians. However, terms in the Spanish (e.g., “gobierno”, “ministerio”) and English (e.g., “government”, “commission”) languages can also be found in the generic “Politics” community, being highly related to the examined domain. Moreover, a more thorough analysis on the other communities reveals the strong correlations of the dominant terms and the represented political positions.
Indicative examples include the following cases:
The terms “νεαδημοκρατια”, “δημοκρατια”, “νδ” and “@kmitsotakis” which directly reference the right wing “New Democracy” political party and the Twitter account of its leader (Kyriakos Mitsotakis) respectively;
The terms “πασοκ”, “ευάγγελος”, and “βενιζέλος” which directly reference the center-left wing “PASOK” political party and of one its members (specifically, his first and last names, Evangelos Venizelos) respectively;
The terms and “συριζα”, “τσιπρας”, “αριστερας” and “γιαννης” of which the first three directly reference the left wing political party “SYRIZA”, its leader (Alexis Tsipras), and the left political position respectively, and the fourth term indirectly references Yanis Varoufakis, an ex-member.
As in the case of the labels, an in-depth investigation of the depicted text of the images also unveiled the existence of patterns in the latent information of the social images of accounts belonging to broad or overlapping communities, thereby being capable of enriching the context of the social analytics.
5.2. Case Study 2: Celebrities’ Accounts
As an effort to further validate our experimental results, an additional case study was conducted focusing on a community of 54 different Twitter accounts belonging to famous celebrities which can also be further divided into smaller and overlapping groups. Similarly to the first scenario, this community can also be further divided into three groups; for each account up to 500 images were extracted, downloaded, and finally processed by the Google Cloud Vision API.
Table 3 presents the details of the dataset used in this case study. Specifically, 22,331 images were annotated and classified by 3790 unique labels; they were shared by these 54 accounts, and in turn can be further classified into 10 categories, subsets of the ones presented in
Table 1. On average, approximately 415 images were collected for each account. Furthermore, text is depicted in 13,138 of these images, consisting of 46,243 unique terms, the overwhelming majority of which are in the English language. As in our previous case, the majority of the images (58.8%) contain textual information. On average, each social image of this dataset is associated with 8.2 labels and 6.8 textual terms. Finally, 62 of these images were shared by multiple accounts, as presented in the first row of
Table 3.
Comparing the characteristics of the two “Politics” and “Celebrities” datasets, it is evident that both groups rely on images for complementing their social posts. However, while the members of the first group shared almost 100 fewer images on average (312 vs. 415), the text depicted was significantly richer and more diverse compared to that of the second group. This is not only showcased by the approximately 10 percentage units of difference (68.2% vs. 58.8%) in the images containing text, but also by the 2.5 times greater average number of the textual terms per image (16.9 vs. 6.8). The direct comparison of the latent context of the disseminated images of these communities provides us with further insights regarding the underlying behavioral patterns.
As already mentioned, the examined celebrities’ Twitter accounts of this case study can be further divided into more fine-grained groups. In order to analyze the content and assess the existence of behavioral patterns based on the disseminated multimedia content, these accounts were grouped into the following four communities:
Celebrities: all accounts of this dataset;
Athlete: accounts owned by professional sports players (basketball, soccer, tennis, etc.);
Music: accounts owned by singers;
TV: accounts owned by actors and tv personas.
In order to investigate the latent context of the disseminated images by the accounts belonging to these four communities, the same methodology as in the previous case study (
Section 5.1) was applied.
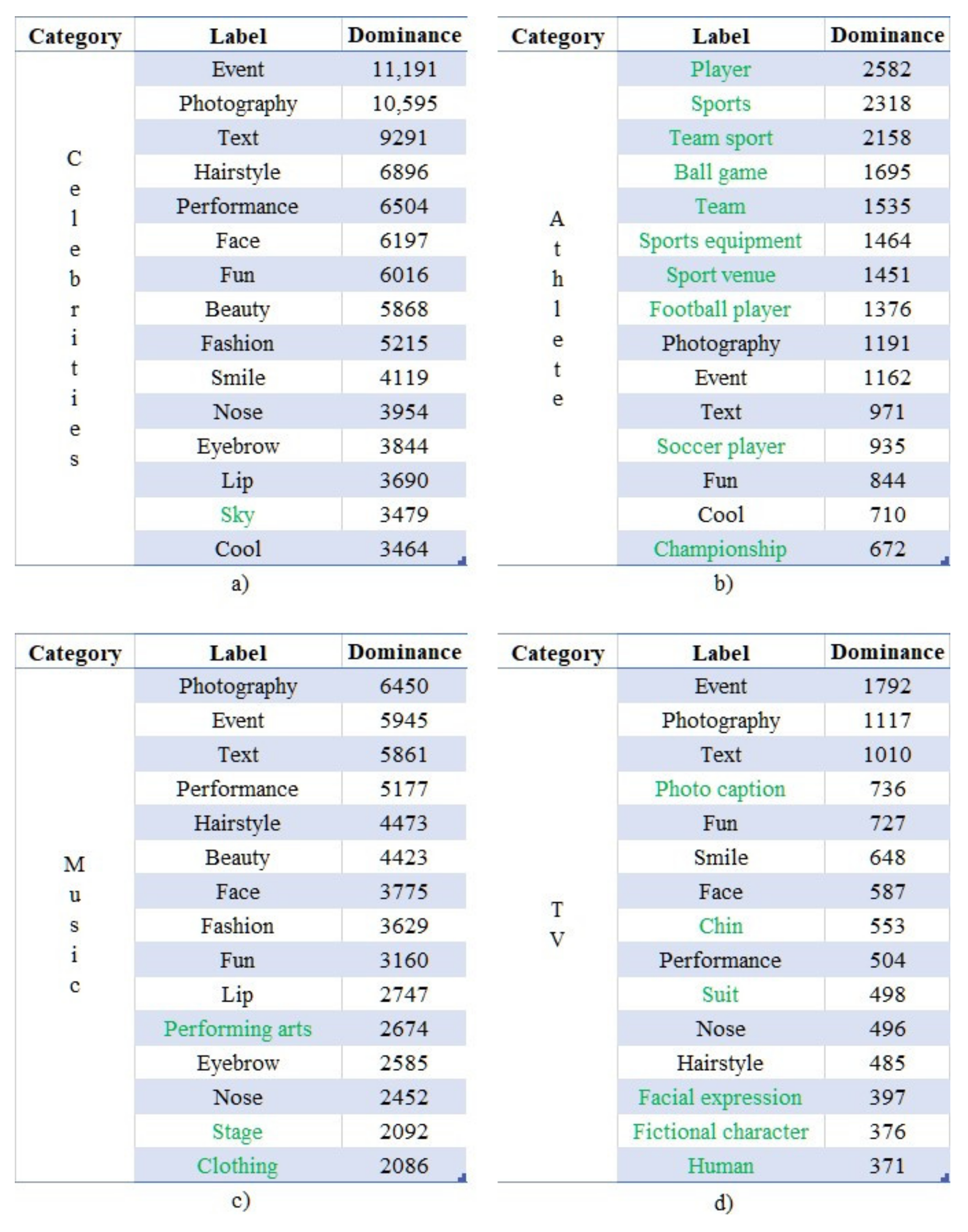
The top 15 labels of the examined accounts’ images according to their corresponding values of “
” are presented in
Figure 7a–d. As can be observed, all four communities are associated with the label “Text”, indicating the rich textual information existing in those images. Furthermore, since celebrities participate in several types of happenings, the generic label “Event” appears, along with related labels, such as “Fun” and “Performance”. Finally, a plethora of concepts related to physical appearance are present, such as “Face”, “Hairstyle”, “Nose” and “Lip”, since a celebrity’s appearance is usually central in the social images.
As in the case of the previous case study, a more in-depth investigation of these labels unveiled the existence of patterns. Specifically, 27% of the top 15 most dominant labels (i.e., 4 out of 15) could be found in all communities, while 58% of them (i.e., 8 out of 15) at least in three. Despite the fact that these numbers are lower compared to the respective ones of the first use case, the fact that the three subcommunities of “Athlete”, “Music”, and “TV” do not overlap showcases the existence of strong ties regarding the underlying patterns of the latent information shared by the community of celebrities.
An interesting fact is the correlation of the context of the labels appearing only in one of the aforementioned three subcommunities with the activities of their members. Specifically, the labels “Sports equipment” and “Sport venue” are related to the “Athlete” group; the labels “Performing arts” and “Stage” to the “Music” group (since it mainly consists of singers); and the labels “Fictional character” and “Facial expression” with the “TV” group (since it mainly consists of actors). The labels appearing only once are highlighted in green in
Figure 7a–d.
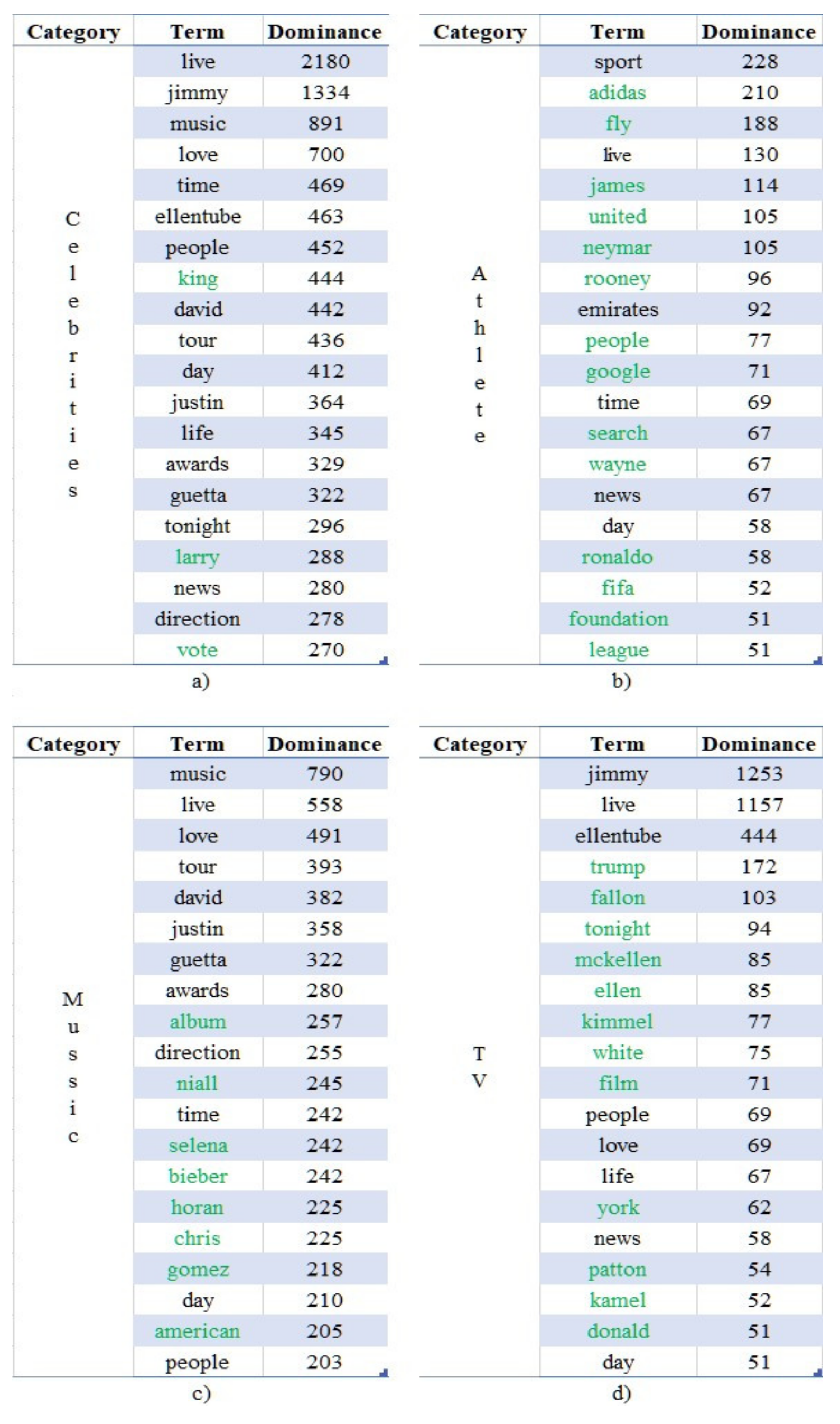
The top 20 terms of the extracted using OCR techniques text according to their corresponding values of “
” are presented in
Figure 8a–d. The investigation revealed that 53.8% of the most dominant terms (i.e., 43 out of 80) can also be found in other communities as well. The unique terms are highlighted in green. A thorough analysis on the other communities revealed the strong correlations of the dominant terms and the context of the analyzed communities. Indicative examples include the following cases:
The terms “james”, “ronaldo”, “rooney” and “fifa”, which directly reference the famous athletes and the football federation respectively;
The terms “bieber”, “guetta”, “gomez” and “awards”, which directly reference the surnames of three popular singers who participated in a music award show;
The terms “tonight”, “jimmy” and “fallon”, which directly reference the “The Tonight Show” television show along with its presenter (Jimmy Fallon);
The terms “sport”, “music” and “film” which accurately describe the context of the communities they were mostly used, namely, “Athlete”, “Music” and “TV” respectively.
Finally, the purely political terms “vote”, “donald” and “trump” appear in the communities of “Celebrities” and “TV”, but are seemingly not relevant to the overall context. However, the investigation of the images revealed that these communities ran campaigns via Twitter in order to urge the US citizens to vote in the imminent (during the data collection period) US elections of November 2020, while commenting mostly negatively against the active president Donald Trump. The interpretation of these findings is threefold:
Firstly, social communities should not be regarded as static but rather as evolving structures acquiring new characteristics and behaviors compared to the expected ones, which can lead them to be further divided into smaller groups or also become members of others.
Secondly, communities or individuals with high social authority and reach have the ability to influence their direct and indirect social peers deliberately or not.
Thirdly, the dynamics of OSNs are continuously increasing and evolving, escaping from the narrow boundaries of typical interaction and information exchange, and can be used for mass misinformation and manipulation, as also mentioned in [
28].
As in the case of the labels, an in-depth investigation of the text depicted in the images also unveiled the existence of patterns in the latent information of the social images of accounts belonging to broad or overlapping communities, thereby being capable of enriching the context of the social analytics.
6. Identifying Similar Images Using Latent Contextual Features
As described in
Section 3, the Google Cloud Vision API has been employed for labeling Twitter images and extracting their depicted text using OCR techniques. As a result, OSN images are represented with textual information; thus, all document-based applications and frameworks can now be applied on this type of multimedia content, which was not possible before. As a second research direction of this study, we investigated the identification of similar images by evaluating their semantic similarity, relying on the aforementioned extracted contextual features.
Towards this aim, the Word2Vec [
3,
4] model was employed, relying on word embeddings, where real-valued vectors in a multi-dimensional space represent words. The encoded patterns of the vectors can be represented as linear functions, and the similarity scores can be calculated using the cosine similarity metrics of the terms’ vector values. It should be noted that the semantic similarity of two terms measures how similar their meanings are, despite their any syntactic differences (e.g., “dog” and “hound”). In our study, the pre-trained word-embedding model (
https://code.google.com/p/word2vec/) of [
4] was used. It was trained on a part of the Google News dataset of approximately 100 billion words. The resulting model contains the vectors of approximately three-million unique English words and phrases, in a 300-dimensional space.
Our investigation was based on 5000 images of our dataset, and three types of experiments were performed, one for each latent contextual type of information. Specifically, we considered the factors of (a) the extracted labels, transformed into a concatenated string sequence (the space character was inserted between each label), (b) the extracted via OCR text, and (c) the combination of the concatenated labels with the extracted text. Our aim was to evaluate the merits of each latent-type factor on the semantic similarity scores.
Each of these factors are provided as input to a Word2Vec function, for being represented into a single word-embedding vector. If a factor consists of more than one term, then the average value of the individual vectors of the terms is derived. Since all factors of the images are represented by their corresponding real-valued vectors, the cosine similarity metric can be employed for measuring the semantic similarities of the images. The similarity values produced by the employed Word2Vec model range from −1 to 1, where 1 is the highest value. Euclidean distance measures the magnitude of two points in a multi-dimensional space by considering the length of the straight line between them. Contrary, cosine similarity relies on the angle between two points with vertex at zero, thereby considering the directions of the vectors and not their magnitudes, and therefore is able to identify terms with opposing meanings. In this study, we are mostly interested in the orientations of the vectors; thus, cosine similarity is preferred in the domain of similarity identification. Assume that the interests of two users regarding books are represented by the vectors V1 and V2 respectively, and the function SIM(V1,V2) measures the similarity of their tastes; then:
SIM(V1,V2) = 1: if the users have exactly the same interests (i.e., V1 = V2);
SIM(V1,V2) = 0: if there is no correlation between the users’ interests (e.g., do not read any common books);
SIM(V1,V2) = −1: if users have opposing interests (e.g., rated the same book in an opposite way).
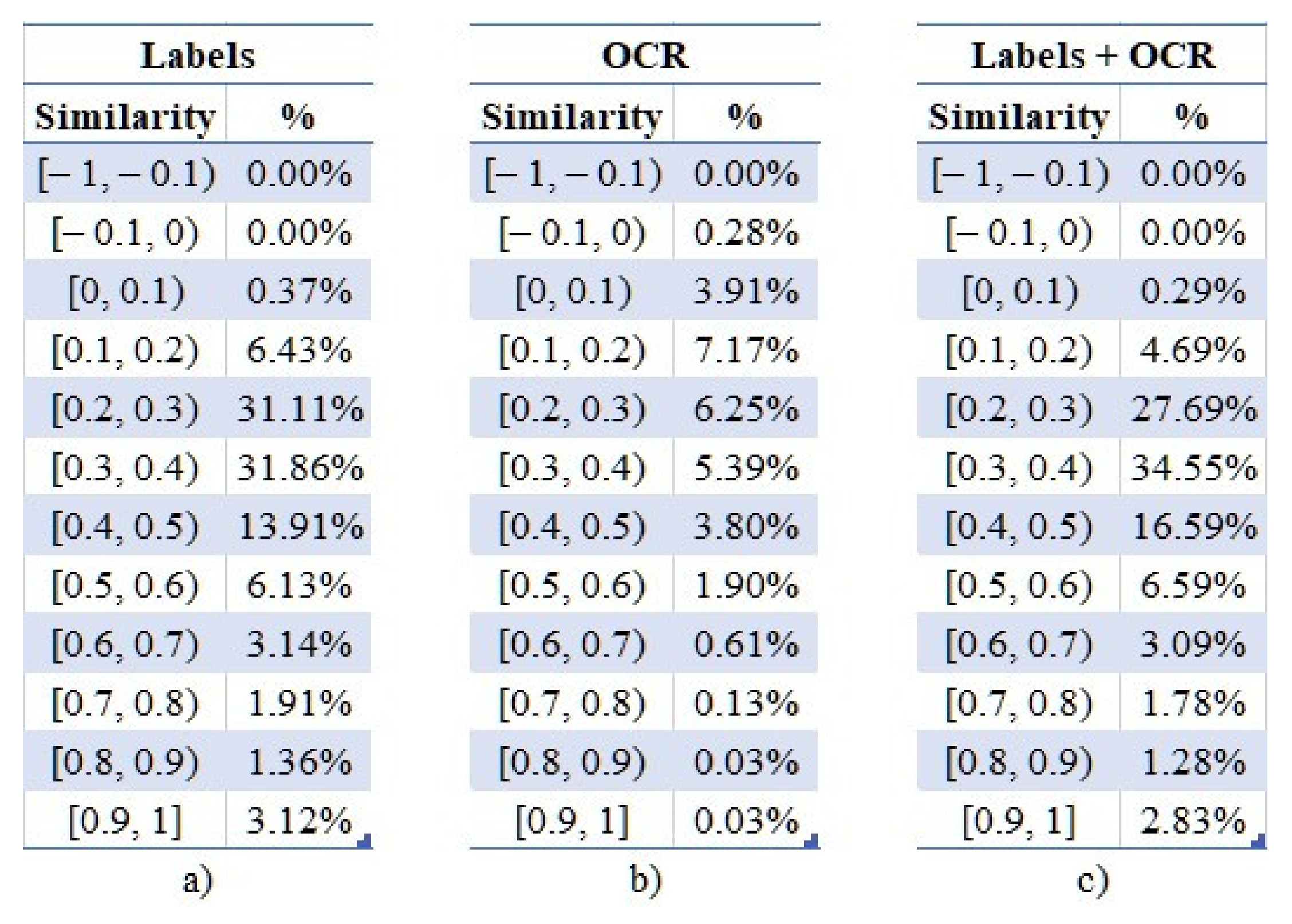
Using the cosine similarity, the vectors representing the latent textual information of an examined image are compared against the respective ones of the others. Consequently, a square similarity matrix of order N is created, where N is the number of the examined images, containing the derived similarity scores ranging from −1 to 1. In our case, 12,497,500 unique values were derived, namely, those above the main diagonal of the matrix. These values were then assigned to 20 groups ranging between [−1, 1], with an incremental step of 0.1, whose distributions are presented in
Figure 9a–c.
Two main observations can be derived from
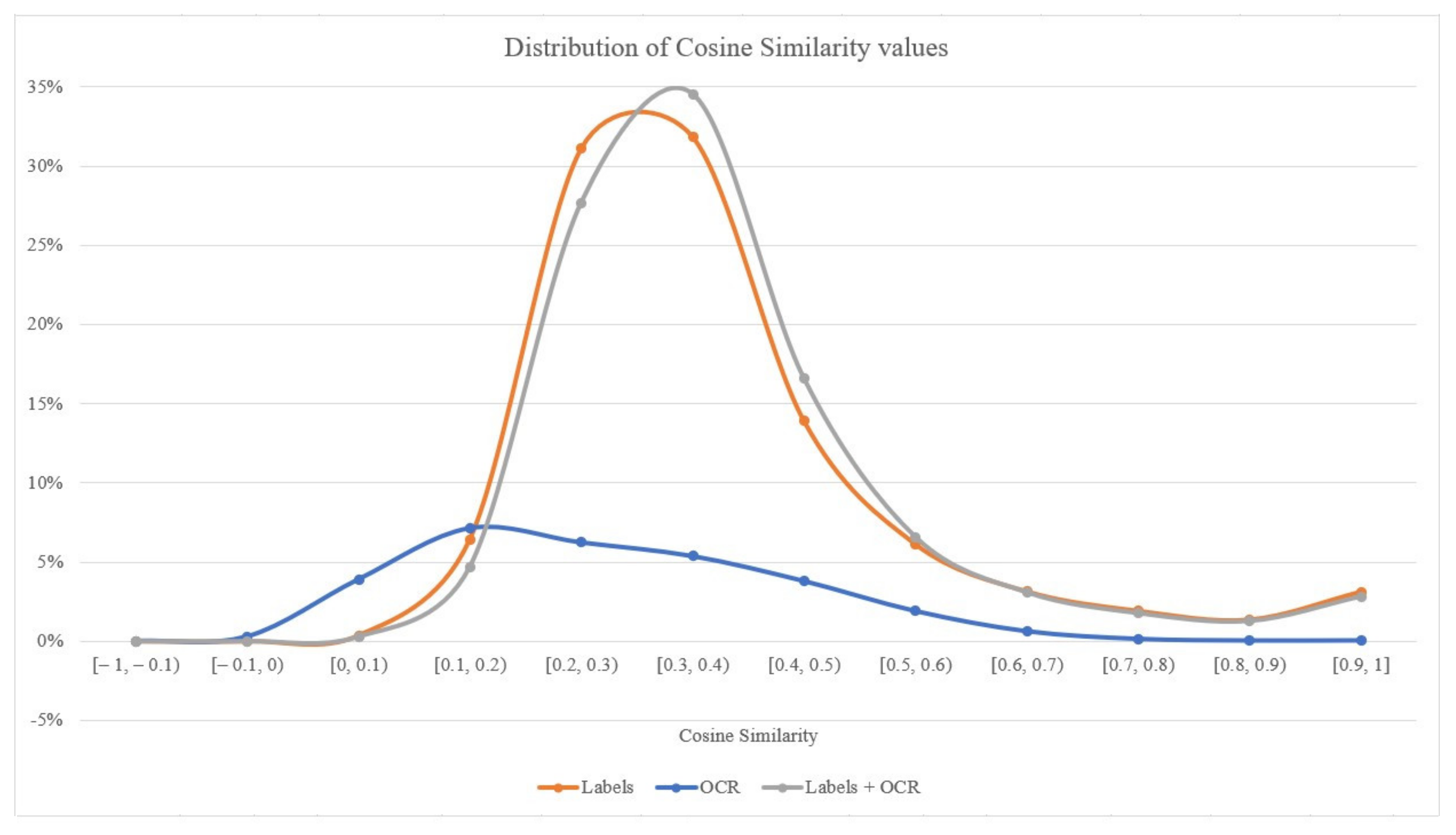
Figure 9. Firstly, only 30% of the text extracted using OCR techniques has been useful during this process, whereas in the cases of labels the percentage exceeds 99%. As the investigation revealed, misrecognized characters lead to erroneous terms that could not be transformed into vectors, since they do not exist in the pre-trained word embeddings model. Secondly, as also visible in the visual representation of the aforementioned distributions of
Figure 10, the majority of images lie in the range of [0.1, 0.5], meaning that no correlations have been identified in the evaluated content. Typically, values of cosine similarity greater than 0.5 mean that the examined word vectors have similar meanings.
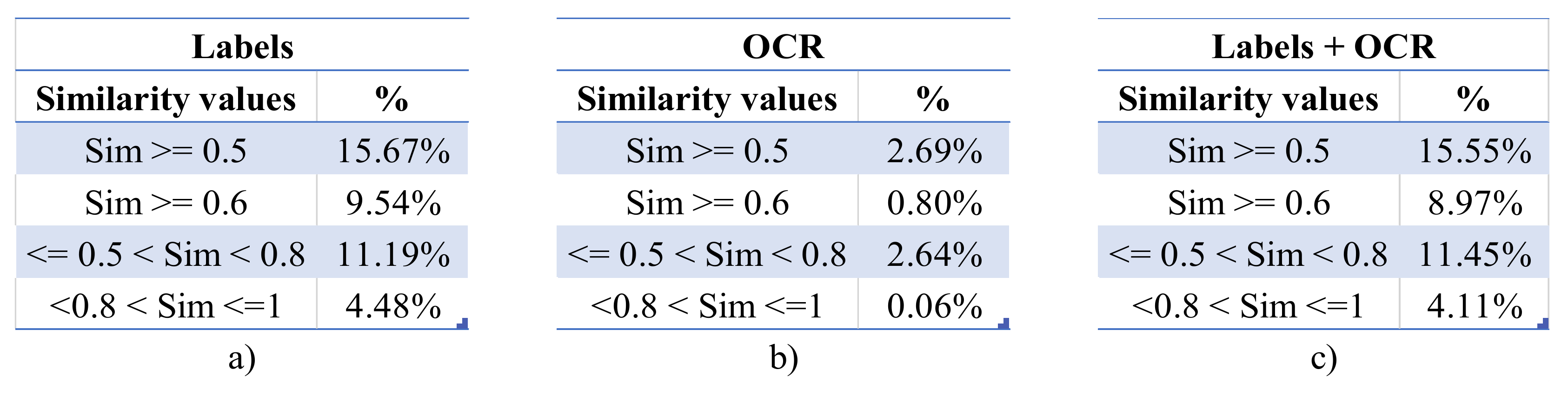
A more in-depth analysis of these values is presented in
Figure 11a–c, where the distribution values of four groups are available. Specifically, the first two rows present the distributions of the similarity values greater than 0.5 and 0.6 respectively, and the last two the distribution values ranging between 0.5 and 0.8 (medium level similarity) and 0.8 and 1 (high level similarity) respectively.
As can be observed in
Figure 11b, there are cases of the OCR-derived text wherein the value of the semantic similarity of images was negative, indicating the presence of slightly opposing opinions in the depicted content. Moreover, the OCR text by itself does not seem suitable for a similarity identification task, as only 2.64% of the images were identified as slightly similar, and a mere 0.06% as highly similar. Contrarily, the similarities derived from the usage of labels and their combinations with the OCR text led to greatly improved results, as seen in
Figure 11a,c. Despite the distribution values being very close, the percentage of images having similarity values equal to or greater than 0.5 was approximately 7.7% higher in the case of labels only, and 6.3% higher when the values of 0.6 or more were evaluated. Similarly, 2.3% fewer medium similarity values (i.e., ranging between 0.5 and 0.8) appeared in the case of labels only, compared to the joint usage of labels and OCR text. Finally, 9% more OSN images were identified as highly similar (i.e., semantic similarity greater than 0.8) when only the labels were considered.
Our evaluation indicates that when OSN content is examined towards the identification of semantic similarities, the usage of labels only tends to generate the best results, despite the fact that the labels joint with the OCR text led to quite similar results. Thus, the semantic context of the OCR extracted text should not be ignored, as in other scenarios where more qualitative text can be extracted (e.g., captions in figures of scientific publications), its consideration could greatly improve this information retrieval task. One important remark is that the labels and the extracted text of the images were not stemmed, as stemming had a negative effect on the similarity results by approximately 20%.
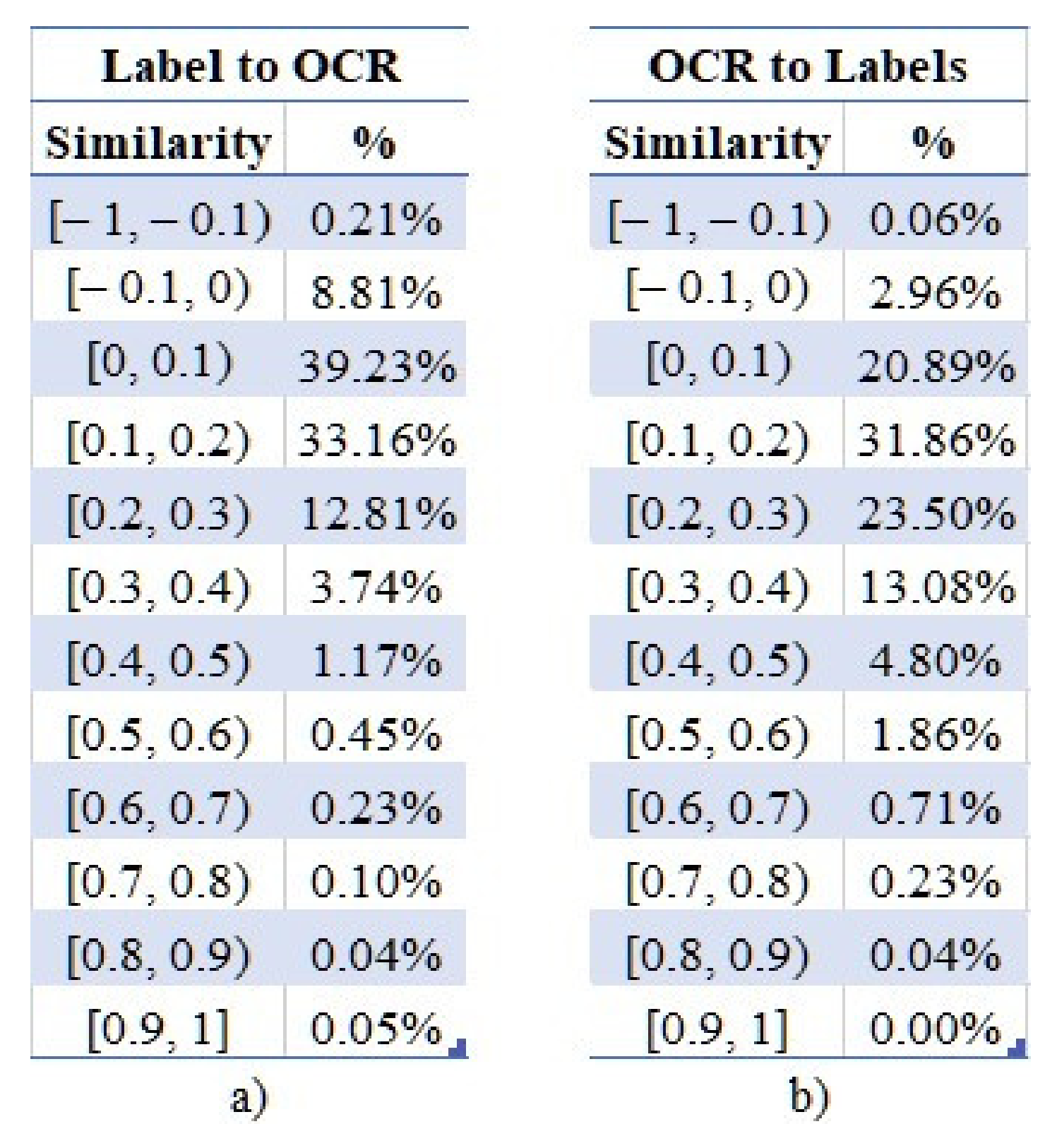
Finally, as in [
6] where the authors examined the correlations between the disseminated posts and their accompanying images, we performed a similar analysis on the labels of an image and its OCR-derived text. Specifically, we wanted to investigate the correlations among these types of latent information and evaluate their degrees of complementarity. To this end, two types of semantic similarities were explored for each image in our dataset. Firstly, the similarity of each label to the OCR-derived text, and secondly the similarity of all labels, as a concatenated string sequence (the space character was inserted between each label), compared to the OCR-derived text. However, as presented in
Figure 12a,b, the results indicate that the vast majority of the labels, the individual and the concatenated ones, do not correlate with the text. Specifically, less than 0.01% of the extracted OCR texts have a semantic similarity greater than 0.5 with the assigned individual labels (
Figure 12a), and approximately 0.03% with the concatenated ones (
Figure 12b).
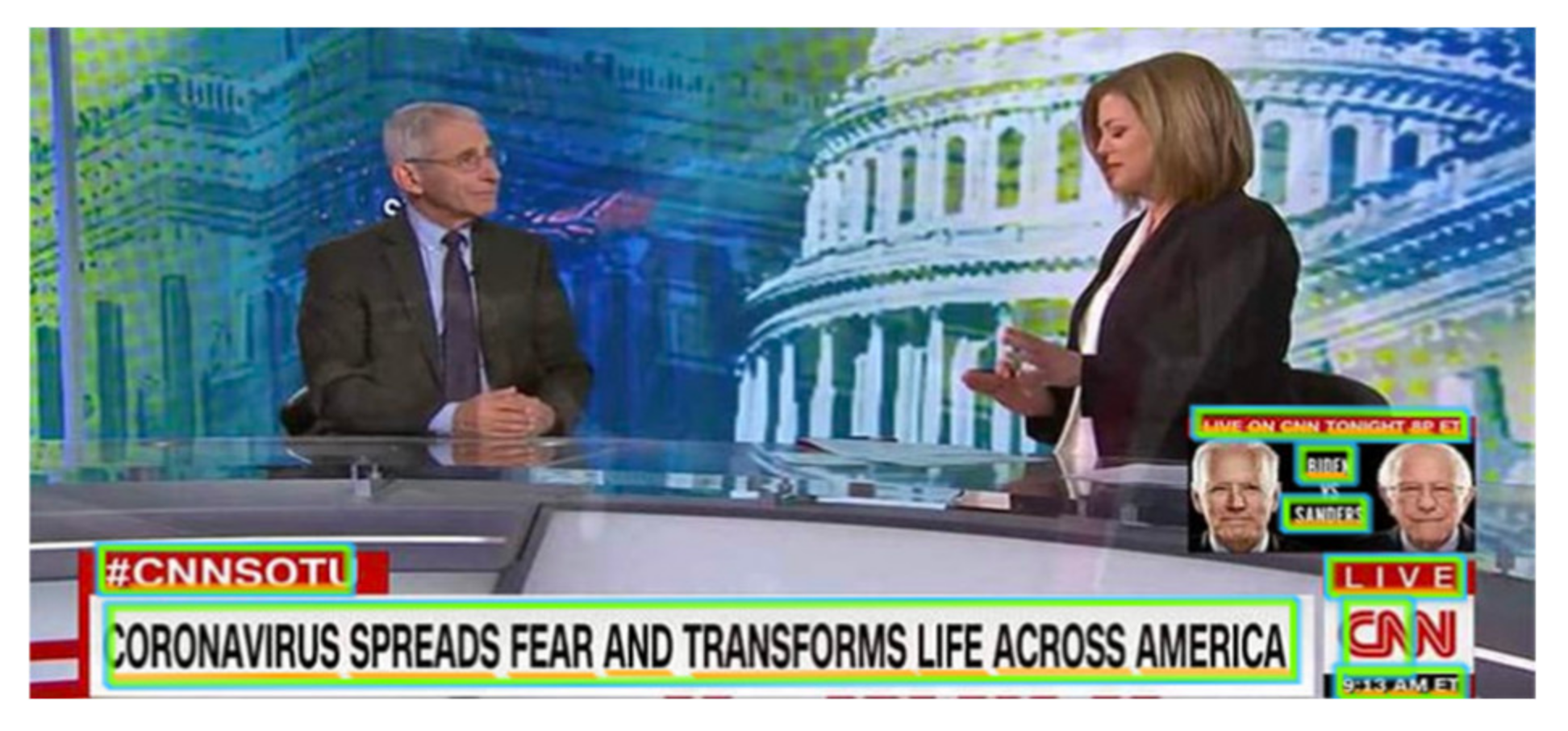
Our experiment revealed that on the one hand, the text depicted in OSN images does not describe the represented entities, but rather provides information about a specific context. Such a case is
Figure 2, where an abstract description of the image could be “a news report and people discussing it” (as also implied by the labels); however, the depicted text is in a different context, providing additional information about the interview and specifically about the effects of coronavirus in the USA. However, on the other hand, image classification systems tend to completely ignore the latent semantic information existing in the images, thereby relying entirely on their represented entities. Thus, the incorporation of these semantics could provide a more complete representation of an image.
7. Conclusions and Future Work
In this paper we proposed a framework which leverages the latent context of Twitter images deriving from the Google Cloud Vision API platform, aiming to enrich the social analytics with semantics and textual information. Furthermore, we employed OCR techniques in order to extract the text from these images. We made three contributions. Firstly, our in-depth investigation of the derived information unveiled useful insights regarding the existence of patterns in the latent context of the images which are disseminated by Twitter accounts belonging to the same or overlapping communities. The conducted case studies revealed that user-generated content, linked data, along with the latent concepts and textual information retrieved from the images, can enrich the social analytics task, revealing valuable information which was until now disregarded.
Secondly, our evaluation indicates that when OSN images are examined towards the identification of semantic similarities, the usage of latent labels tends to generate the best results, despite the fact that the labels joined with the OCR text led to quite similar results. Thus, we suggest that the semantic context of the OCR extracted text should not be ignored, as in other scenarios where more qualitative text can be extracted (e.g., captions in figures of scientific publications), its consideration could greatly improve this information retrieval task.
Thirdly, we published the annotated dataset (
https://www.doi.org/10.34740/kaggle/ds/732777) derived from our study with the aim of providing usefulness to our research field and community for further use and evaluation. Since the development of efficient ML models requires a sufficient volume of data, this extended dataset could prove valuable for a series of classification, information retrieval, or recommendation tasks.
Compared to the related literature, our study differentiates itself in two important aspects. Firstly, our proposed framework is based on all types of latent contextual features of Twitter images (i.e., labels and OCR-derived text), rather than a subset of them (i.e., labels). Our analysis revealed that the overwhelming majority of the images disseminated in OSNs depict text, and our experimental results on social communities (
Section 5) revealed the dynamics of such latent information, which should not be ignored any longer. Secondly, since the latent context and depicted text of Twitter images are represented by textual information, all document-based applications can now be applied to this type of multimedia content. Therefore, we evaluated the merits of this latent textual and semantic information towards the identification of images with similar semantic content, for further improving image searching, retrieval, and recommendation tasks.
Moreover, by further analyzing the text which was extracted from the disseminated social images of members of seemingly distinct communities, we derived to the following findings:
Over the course of time, social communities should be regarded as evolving structures in terms of their size, attributes, and behavior, which can lead them to be further divided into smaller groups or also participate in others;
Communities or individuals with high social authority have the ability to influence their direct and indirect social peers deliberately or not;
OSNs are a powerful means of information spread whose dynamics constantly increase and evolve, escaping from the narrow boundaries of typical interaction, and can be used for mass misinformation and manipulation, as also mentioned in [
28].
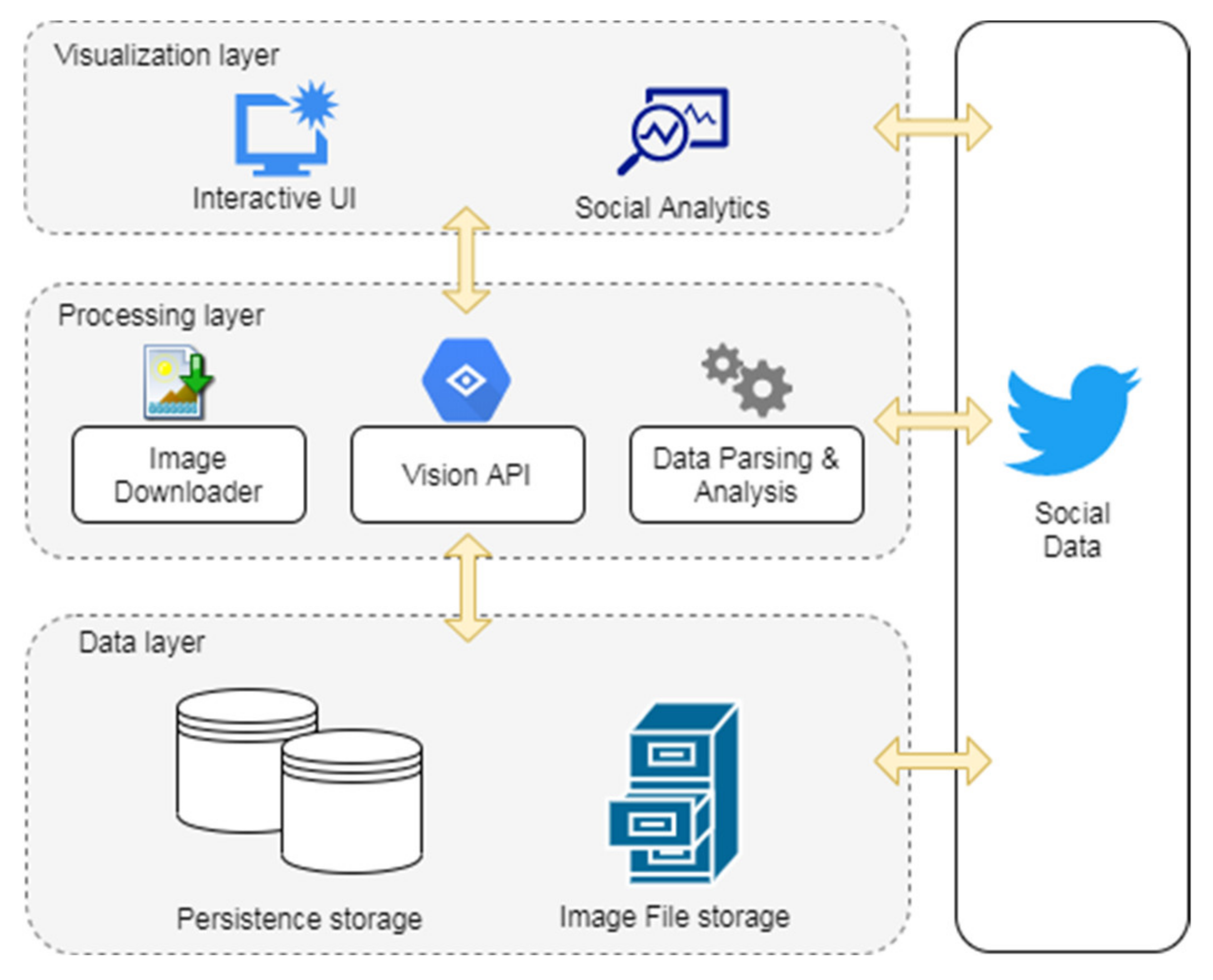
The layered architecture of our service (
Section 3.1) makes our methodology extensible by design to all types of commercial or research image classification and analysis services. Consequently, our proposed framework can be enhanced with the incorporation of Microsoft Azure Computer Vision (
https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/) along with the existing Google Cloud Vision API (
https://cloud.google.com/vision/), leading to an ensemble method towards the classification and analysis of social images. Multiple services should be able to analyze the social images providing the weighted labels and the depicted text. The derived information should be properly combined and can then be used in order for the proposed dominance metric values to be calculated for each latent information type. Apparently, the adoption of a different image analysis platform (or a combination of services via an ensemble scheme) would affect the results (in terms of labels’ appearances and weights); however, the application of our methodology would still be able to identify the most representative latent image information (i.e., labels and OCR-derived terms).
The added value of our study compared to the related literature can be summarized as follows. Firstly, two types of latent textual information in images are considered—the labels (i.e., semantic tags) providing the represented entities or concepts, and the actual depicted text. Our evaluation revealed that both types of latent information result in valuable insights regarding the patterns of the user-generated content disseminated by accounts of broad or overlapping communities. Secondly, the existence of semantics, both on social content and OSN account level, can be utilized for further improving tasks relevant to the analysis of behavioral patterns, identification of similar accounts, community detection, and enhancement of interest profiles. Thirdly, we investigated the identification of similar images by evaluating their semantic similarity, relying on the aforementioned latent contextual features. Specifically, the Word2Vec word embedding model was employed for transforming the text into vectors, thereby enabling us to calculate the cosine similarity of any textual information. Finally, we investigated the correlation of the two types of latent information and evaluated their degree of complementarity.
In the future, we plan to rely on the results of this study in order to enhance the methodologies proposed in our previous works [
5,
29]. The first one, already used as the basis for this study, involved the enrichment of Twitter accounts with thematic categories deriving from DBpedia, and the second one the identification of similar accounts based on their shared Twitter entities (e.g., mentions, URLs, hashtags). The incorporation of additional information derived from the latent contexts of their disseminated images would further improve the efficiency of these methodologies and could be transformed into a Twitter account follower recommendation system (i.e., “who to follow”). Moreover, our latent contextual-based semantic similarity image identifier could be adapted into a content recommendation system where relevant Twitter images and posts are suggested to users, based on their disseminated content. To this end, the latest data of the interested users should be considered, and due to the vast volume of the candidate social data, suitable big data techniques should be applied. Consequently, the similarities among the images should not be calculated as presented in this study (since big data analytics was outside of our research scope), but by employing scalable techniques, such as locality-sensitive hashing. Finally, we intend to analyze the extracted OCR text to a greater extent, in order to identify the mentioned entities or concepts and interconnect them with established knowledge bases (e.g., DBpedia and Wikidata), for enhancing the representational quality of the individual Twitter accounts and communities.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}