2.3. Code Readability and Comments
Software readability or “code readability” is an important part to assess software maintainability: “How quickly can a new developer understand the code?” [
4,
6,
10,
16,
17,
18]. It has various definitions; i.e., it is the human judgement of how easy a source code is understood by programmers, or the process by which a programmer makes sense of a programming code [
8,
16,
19,
20,
21,
22]. Most companies’ developers are working as a team instead of working individually, thus most of the software codes are written by different teams; the code must be reusable and maintainable, so it is important that this code must be understandable. Therefore, readability becomes a priority, also it has always been the reason behind the maintainable code, so readability is needed. Thus, readability becomes a dominant topic in software engineering especially in software quality [
3,
11,
23]. “Maintenance programmers” tasks are analogous to those of archaeologists who investigate some situations, trying to understand what they are looking at and how it all fits together. To do this, they must be careful to preserve the artifacts they find and respect and understand the cultural forces that produced them” [
16]. The difficulty of understanding code influences the high cost of software maintenance [
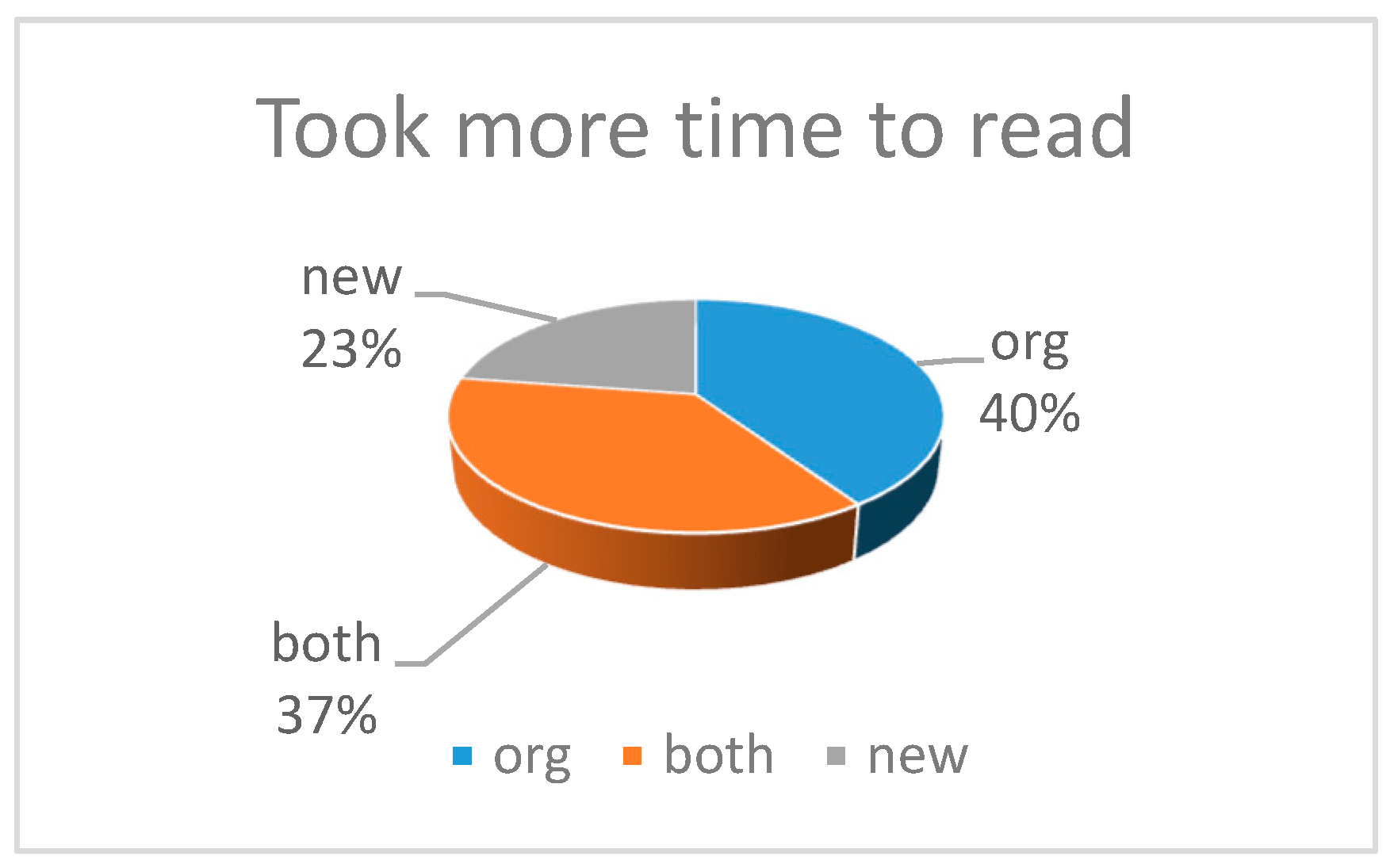
5]. Moreover, reducing the reusability of this source code especially a source code may be considered a readable one for a programmer but it might not be for another. This can be applied in two situations when others need to understand the code or the author of the code after a while (month, year), he/she could not remember the written code or took a long time to do. Most researches show that the reading the code and understanding it, takes a longer time compared to maintenance activities [
16,
21,
22].
“Unfortunately, computer system documentation is difficult to understand, badly written, out-of-date or incomplete.”
The complexity of the code and readability are not the same although they are closely interrelated; complexity is code property based on the problem domain, the method behind solving each scenario will not be avoided completely in developing the process. Whereas readability is, an accidental property that can be avoided independent of the problem domain or problem complexity [
21]. Code readability is not easy to measure by a deterministic function similar to maintainability, reliability, and reusability. Readability measures formula care about and changed by independent individual elements, such as identifiers, statements, comments, indentation, and program style. However, complexity measurements depending on static components as well as dynamic interactions among program components [
21,
25,
26].
Although most of the evidences show the importance of commenting on the code, some programmers adopt the opposite point of this view. They say the good code does not need to comment on it because the code itself is clear and understandable [
8,
27] says “The frequency of comments sometimes reflects the poor quality of code. When you feel compelled to add a comment, consider rewriting the code to make it clearer”. Developers don’t need to comment on every line of code, because when the programmer needs to comment on every line of code to make it understandable, this might indicate that the code is low quality or have lacked in structure, in this case, programmers should rewrite it instead of commented it. However, as mentioned before comments are necessary for the development process and maintenance and also to make the code more readable even when the code itself is low quality [
4,
11,
19,
21,
28].
Students study codes from examples in textbooks, outline documents, other colleague’s code; these resources and others are used as learning tools in academic environments. These codes or programs can be unhelpful if their readability is too high or if it is too low. That makes understanding the code hard and increases the difficulty of maintainability or reusability of these codes [
25].
Software code is divided into two types: the code itself, and comments on the code. Comments are a block of source that the compiler ignores in the compilation process, so you can put in it any information that you desire. However, a programmer should keep in mind that the main aim of using these comments are notation of the source code and help the developer and other software implementer team members to understand the source code in the process of upgrading or bugs fixing or to make software fits with new or modified requirements. In other words, to aid in software maintenance and therefore reduce maintenance costs. Several researchers have conducted experiments showing that commented code is easier to understand than code without comments. Besides, these comments are used as internal documentation for code and system [
19,
29].
We should keep in mind that the comments are used to make the code more readable not to replace it. In addition, if the code is inadequate we should make changes to have an adequate code not to have a good comment. However, we can say that bad comments are worse than no comments at all, for this, “We should only be writing comments when they really add meaning” [
29]. By the way, some concerns should be taken into consideration when writing comments as [
10,
29] mentions:
Quality of the comments is more important than quantity.
Good comments explain why and how.
The code should not be duplicated in the commenting.
Comments should be clear and concise.
Functions should start with a block commenting
Comments should be indented the same way as the rest of the code
Comments should be used in a way that reads naturally before a function, not below.
There are different styles used in commenting, each language almost has its own commenting style. Most of which are set in green color, i.e., C language comments come in blocks between /* and */ and can span any number of lines. C++, C#, Java add the single line comment that follows //, and vb.net used single comma [
29].
2.7. Source Code Comments Assessment
In the coding area, many tools used previous formulas or create their own formula. An approach for quality analysis and assessment of code comments by [
8]. The provided approach defined a model based on categories of the comments. Researchers applied a machine learning technique on the developed application which is programmed in Java and C/C++. Authors used a metric to evaluate the coherence between codes and comments of methods, for example, the name of the routine and its related comment. In addition, they used another metric that investigates the length of experimented comments. As for coherence, authors compare the words in comments with ones that founded in the method name. Moreover, the aim of using the length of the comment is coming from the assumption that the short inline comment may contain less information compared with long ones. To apply this study, they use surveys that distributed over 16 experienced software developers. This work is related to our work by assessing the source code comment, but authors do not care about the readability level of comments as written text; they only care if there is a relation between the code and the comment itself. However, in our research, we focus on readability level of comments and its words completion to achieve the purpose of existence of these comments [
26,
32].
The authors of [
33], in their research collected methods for java programs from six popular open-source applications. They applied analyses on comments from collected datasets; to do this they conducted two preliminary studies on words appearing in comments and on amounts of comments. The results demonstrated that most of the comments were categorized as short sentences that contain at most 10 words. Besides, the methods that inner code has more lines of comments could need more changes in the feature. Therefore, it would require more time to fix, especially after the product is released as a production version. This result may conflict with the work that we can use good comments besides good source code. In addition, if these comments are not as the user expected, we can improve the readability without affecting the code quality itself.
According to [
19], the researchers developed the Javadoc Miner tool to assess the quality of one type of comment, which is in-line documentation by using a set of heuristics. To assess the quality of language and consistency between source code and its related comments. Authors measure the readability of comments by assessing the quality of language that comments were written with heuristics by counting the number of tokens, nouns, and verbs, calculating the average number of words, or counting the number of abbreviations. In addition, they used the fog index or the Flesch reading ease level to assess the readability level of comment text. The main aim of authors in this research is to detect inconsistencies between code and comments, by checking all properties of methods and even these properties documented in comments and explained as others can understand it. Authors found that the comments are not up to date which caused misunderstanding in the working of these methods. In addition, authors noticed that the codes which are well commented have less faults or problems reported than ones that have a bad comment that has more fault and bugs.
Researchers in [
34] were created two data sets from tow corpora which were Penn Discourse Treebank and the Simple English Wikipedia corpora to be used as a sample in their research and apply the researched feature that used to assess the complexity of the text. These features were divided into five groups as surface, lexical, syntactic, cohesion and coherence features. They found that coherence features are needed to be in combination with others and if these features dropped from combination there is a significant decrease in accuracy, this led to result as there is a strong correlation between text coherence and text complexity [
35].
Researchers of [
33] amid to prove the relationship between the fault-proneness and the commenting manner in methods declared in Java classes. They focus on two types of comments which were: documentation comments and inner comments. To achieve their aim they used two methods (Analysis-1 and Analysis-2). The results of this research were that a function with inner comments is faultier than a non-commented method; in addition, using comments may indicate that programmers write poor code or faulty code.
2.7.2. The Proposed Approach
The proposed system used consists of two modules, the measurement readability module, and the replacement words module. As the following
Figure 2 and
Figure 3 show, the general processes that are executed in each phase of comment text readability measurement and alternative terms suggestion.
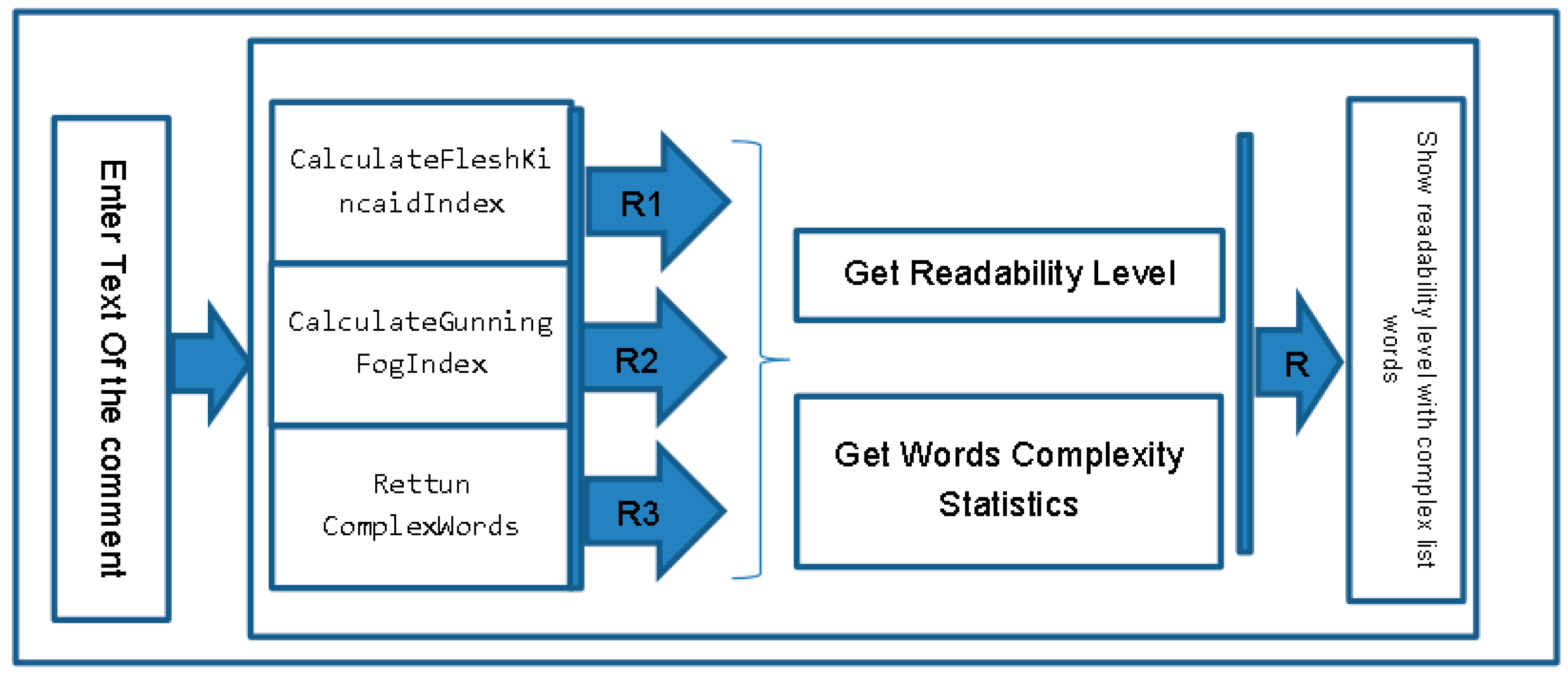
In each part of the system, there is a sub-process executed to get to the final stage the required text with simple words and terms the following diagram. The overall system process shows how text passes through system modules and what is happing in each stage.
The main two modules that the system consists of are measurement readability and the replacement module. The following two sections explain what is happening at each module stage.
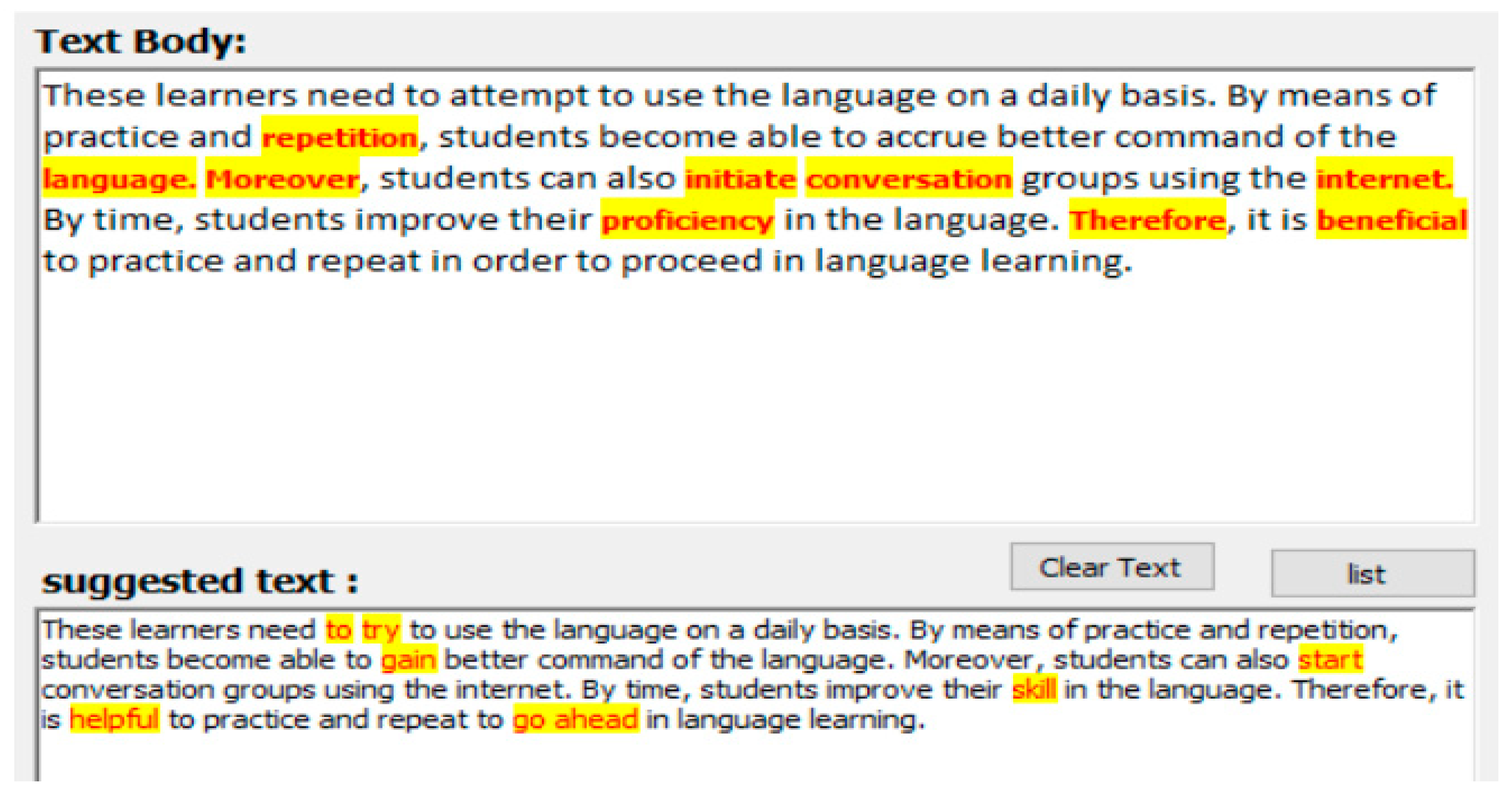
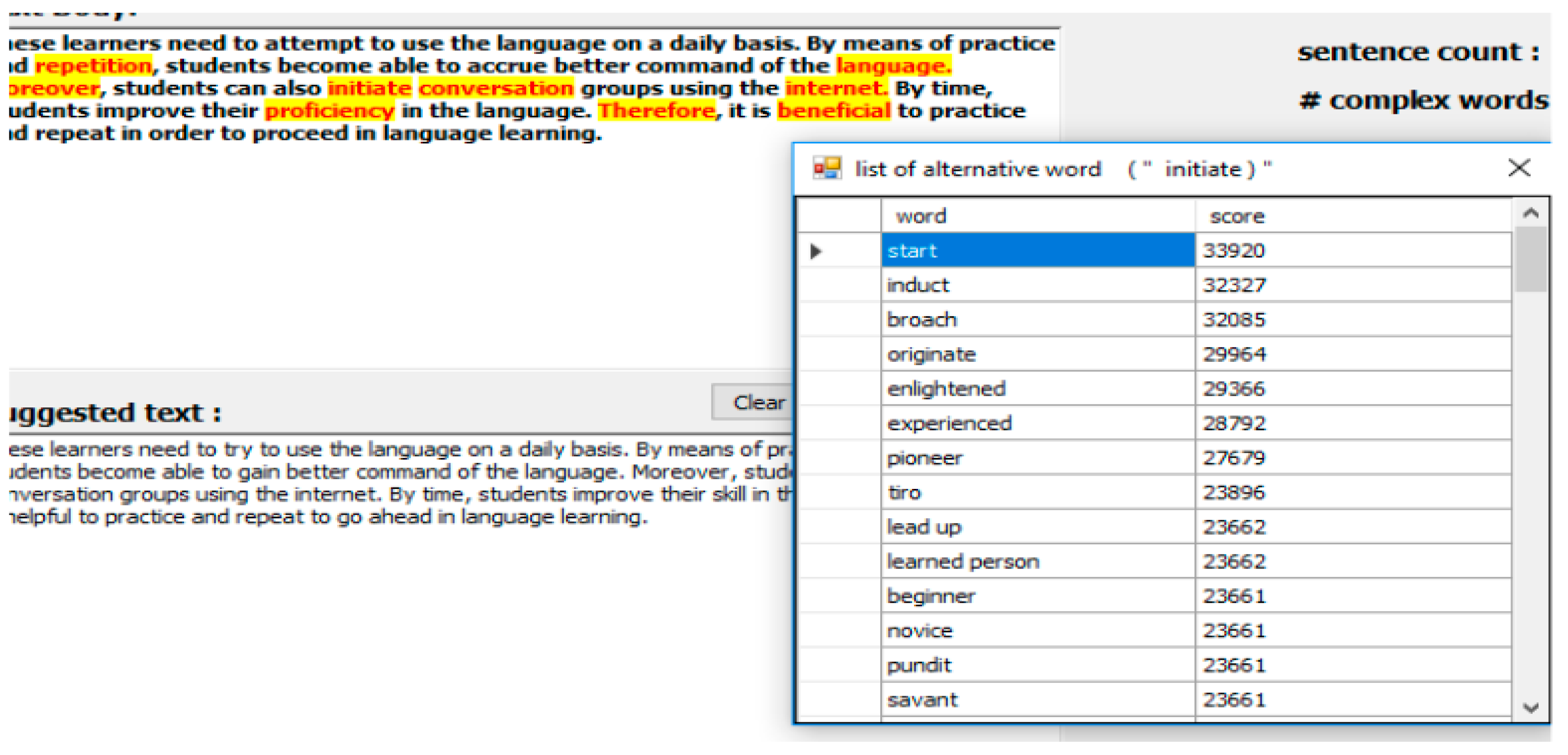
The measurement readability module is used to measure the comment text readability level by using three equations from the three formulas used in this research. To assess the readability level for a text of target comment and extend the complex words from the text and set those as recommended words that should be replaced. This replacement module is used to replace the suggested word from a local database or an online database consumed from Application Programming Interface (API). The replacement term retrieved locally was replaced automatically but when online it gives the user a list of suggestions selected manually, and for which terms are more readable for him/her. On the other hand, the listed term is scored by API teams to show the most suitable term for the requested word as semantic or as generally used in daily life. By combining these two ways we will get more options for the current text to determine the best alternative word, which gives other people the chance to understand what the writer means from these comments.
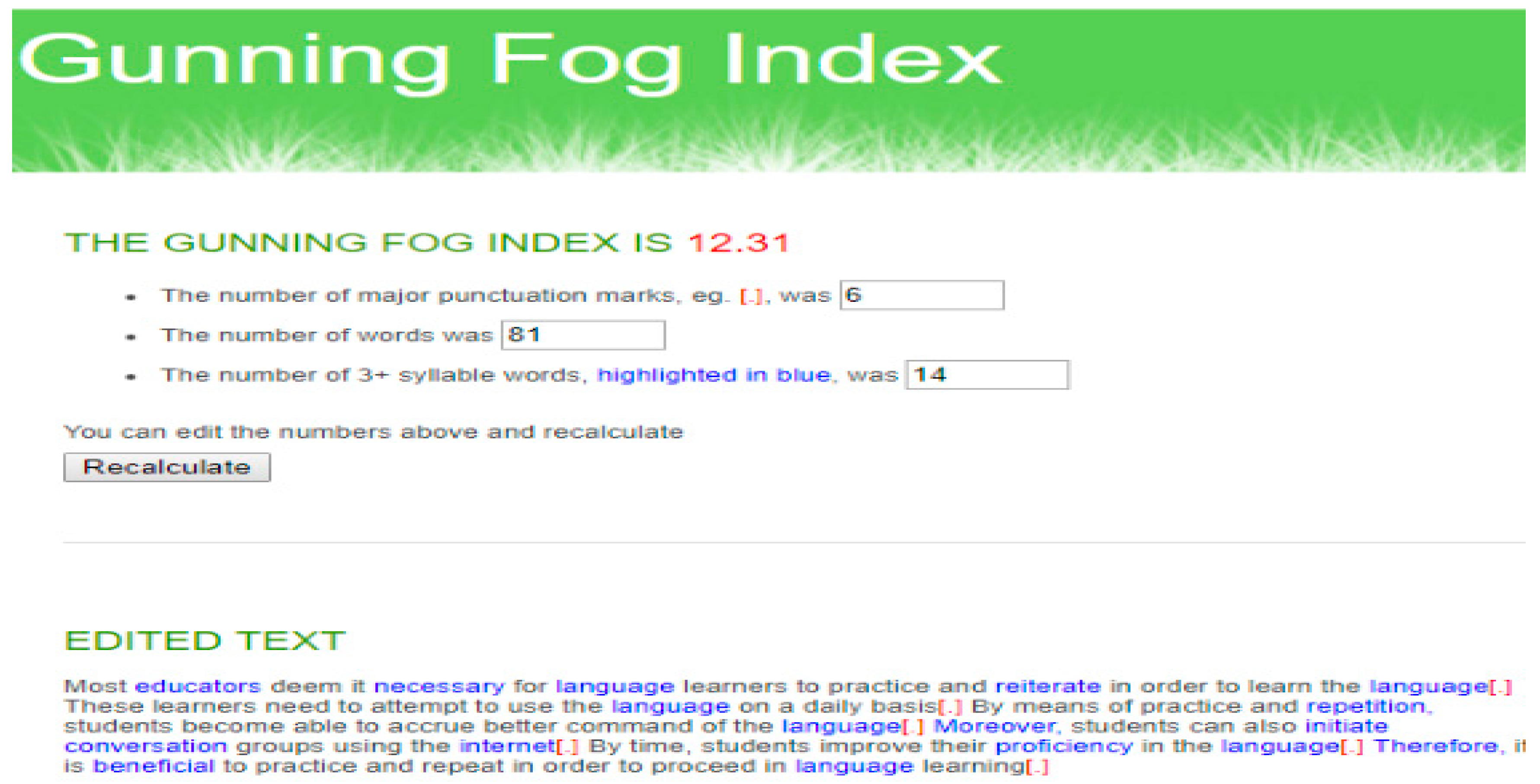
Figure 3 shows the text readability enhancement process which will be applied to generate the proposed system. The readability measurement module is considered the heart of the proposed tool. It depends on three formulas to measure the level of text readability (fog index, Flesch reading-ease, Flesch–Kincaid).
Figure 4 shows the internal process done from entering text, and checking readability, from three formulas as functions. Finally, we get the level of readability as a number with a listing of complex words that could be replaced with simple ones.
Each calculation formula is created as an individual function called from the main screen, in addition to supported functions used to extract entrances and extract words from each sentence.
The following code for the fog index formula calculated:
As we see, the formula depends on word count, the count of sentences, complex word (this part depends on the count of syllables where we use three and more), and the word count in the submitted text. The score as we mentioned before, while it increased the readability also increased.
The Flesck Incaid index is calculated using the following formula:
This formula depends on different parameters in which fog depends on which is syllables count.
Furthermore, there is a SyllableCount function, which is used to get the complex words, in addition to the syllable count, and return the complex word into an array of words to be changed after the whole function and process is done for this phase of the module.
By way of the measurement process, the result of text ratability can be evaluated and determined. The complex words that should be replaced are identified to make the text more readable therefore more understandable.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}