Multilingual Transformer-Based Personality Traits Estimation



Abstract
1. Introduction
- RQ1
- Is sentence encoding based on transformer and deep learning effective in personality trait assessment?
- RQ2
- How do we generalize the model to be multilingual?
2. Related Work
2.1. Supervised Learning and Personality Traits Estimation
2.2. Unsupervised Learning and Personality Traits Estimation
2.3. Semi-Supervised Learning and Personality Traits Estimation
2.4. Lexical Hypothesis and NLP in Personality Estimation
3. Five Factor Personality Model
- Openness to experience (Openness in short) indicates how much a person appreciates new experiences, adventures, or if he is prone to exit his comfort zone.
- Conscientiousness describes the human tendency to be loyal to a schedule, to seek long-term goals, and to be more organized rather than creative or spontaneous.
- Extraversion measures if a person is outgoing and enjoys the companionship of others. A low level in Extraversion means that the candidate prefers to be alone and is reserved.
- Agreeableness tells if people are trusting and altruistic and if they prefer collaboration with respect to competition. A high score in Agreeableness indicates the tendency to maintain positive relationships with others.
- Neuroticism measures emotional stability. It is the only trait that indicates negative emotion when the score is high; in fact, it is often computed in a reverse way and called emotion stability.
4. Gold Standard
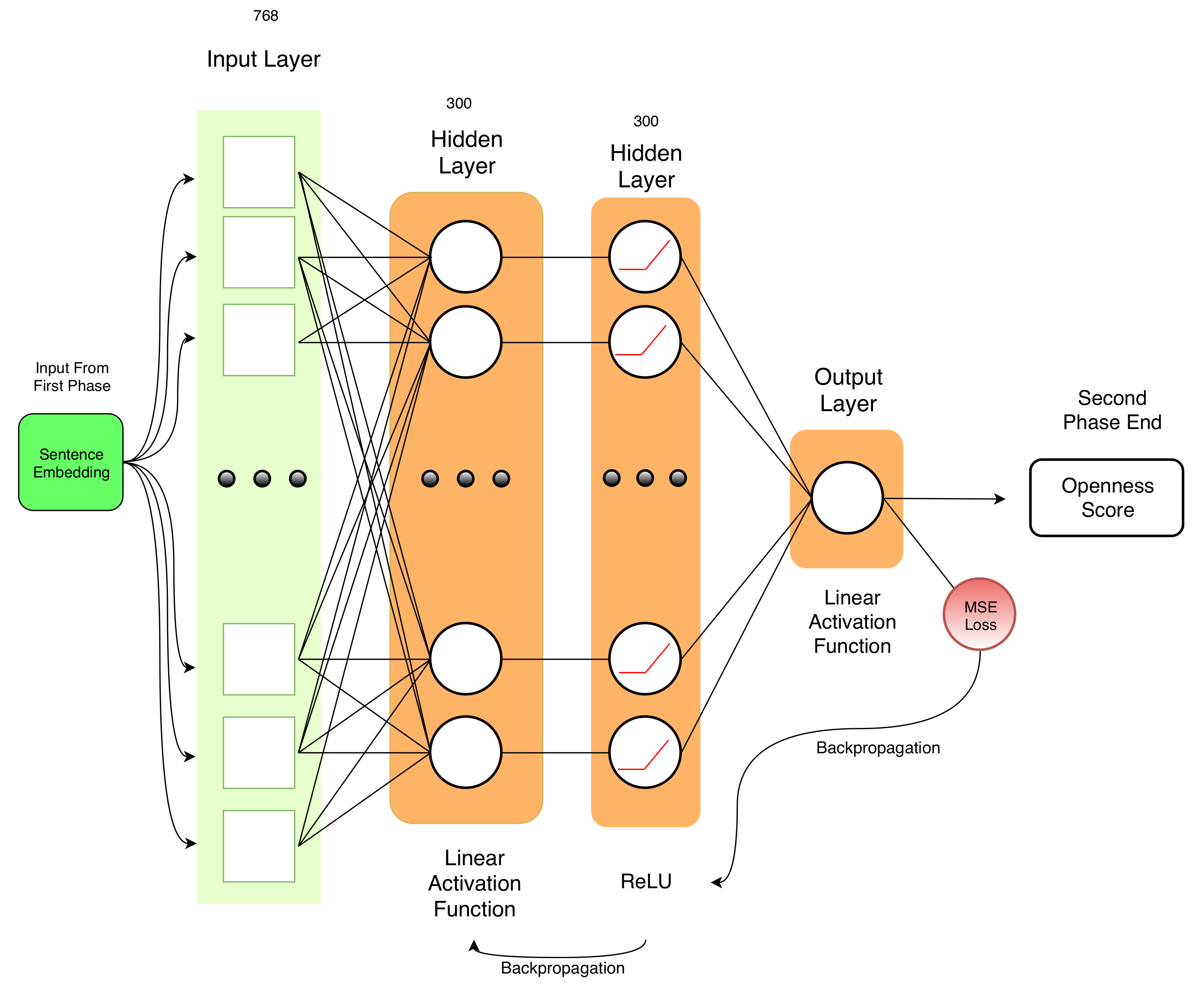
5. Approach and Contribution
5.1. Sentence Embeddings with Transformer
- 😊 becomes smiling face with smiling eyes; and
- 👍 becomes thumbs up.
5.2. Stacked Neural Network
5.3. Model Optimization
- Hidden Size is the number of neurons in each hidden layer.
- Hidden Layers is the number of layers represented with the self-attention plus feed-forward.
- Attention Heads is the number that tunes the self-attention mechanisms described in the work of Vaswani et al. [4].
- Intermediate Size represents the number of neurons in the inner neural network of the encoder feed-forward side.
- Hidden Activation Function t is the non-linear activation function in the encoder. GeLu is the Gaussian Error Linear Unit.
- Dropout Probability is the probability of training a given node in a layer where 0 is no training and 1 always trained.
- Maximum Position Embedding is the maximum sequence length accepted by the model.
- Optimizer changes the weights of the neurons based on loss to obtain the most accurate result possible.
- Learning Rate is the correction factor applied to decrease the loss. Too high values of learning rate lose some details in weights setting, while too low values may lead the model to a very slow convergence.
- Loss Function computes the distance between predicted values and actual values.
- Batch Size is the number of training examples utilized in one iteration.
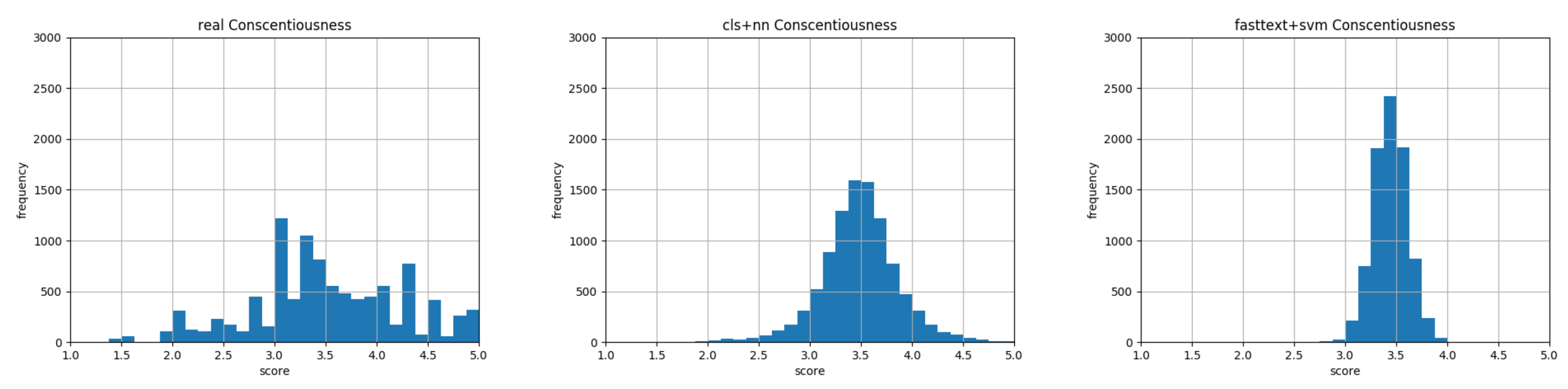
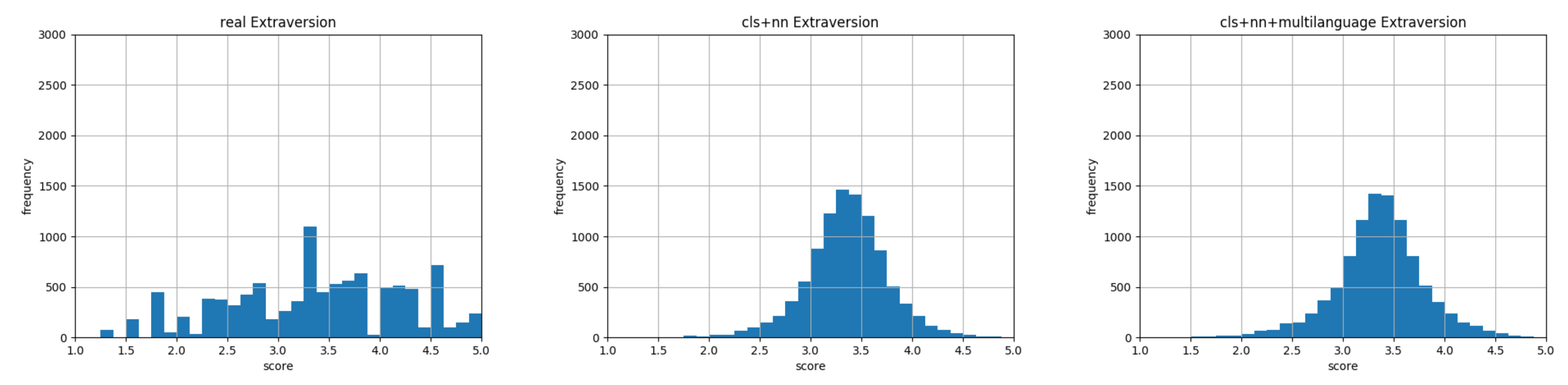
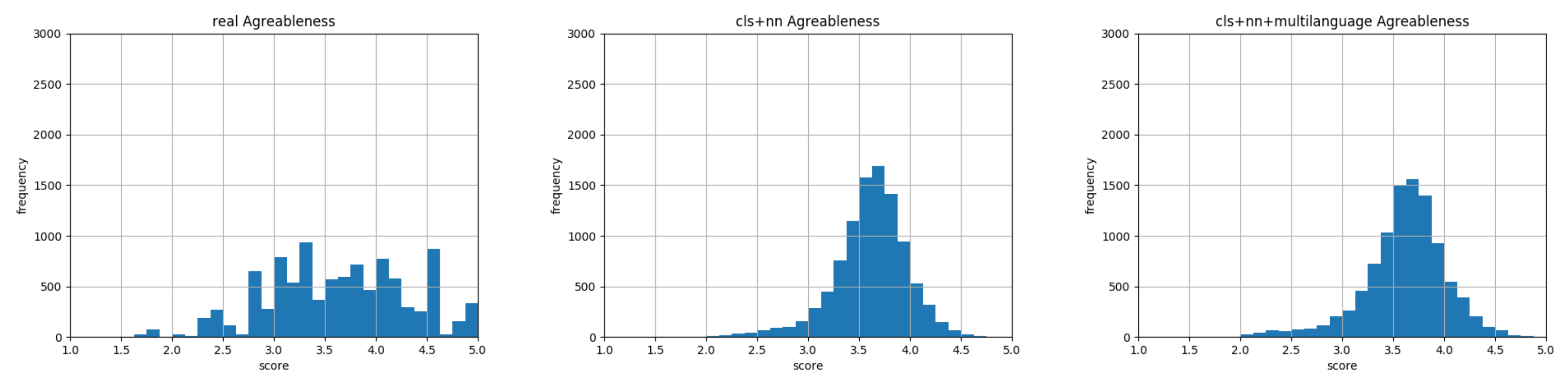
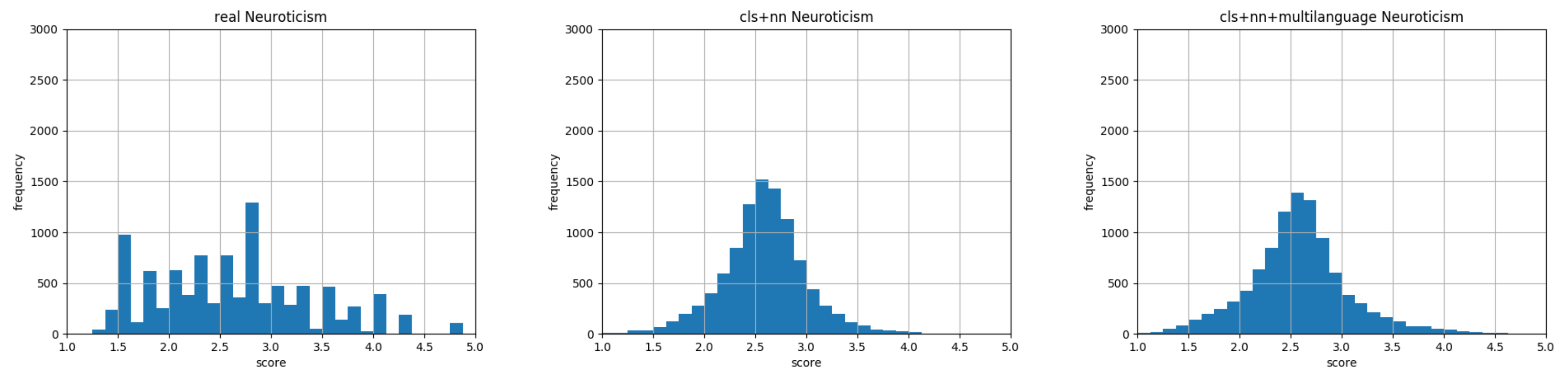
6. Experimental Results
Model Verification and Baselines Comparison
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MSE | Mean Squared Error |
| SVM | Support Vector Machines |
| NN | Neural Network |
| OPE | Openness |
| CON | Conscientiousness |
| EXT | Extraversion |
| AGR | Agreeableness |
| NEU | Neuroticism |
| NLP | Natural Language Processing |
| KL | Kullback–Leibler |
References
- Frommholz, I.; Al-Khateeb, H.M.; Potthast, M.; Ghasem, Z.; Shukla, M.; Short, E. On Textual Analysis and Machine Learning for Cyberstalking Detection. Datenbank-Spektrum 2016, 16, 127–135. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Yaden, D.B.; Kern, M.L.; Ungar, L.H.; Eichstaedt, J.C. Detecting Depression and Mental Illness on Social Media: An Integrative Review. Curr. Opin. Behav. Sci. 2017, 18, 43–49. [Google Scholar] [CrossRef]
- Neal, A.; Yeo, G.; Koy, A.; Xiao, T. Predicting the Form and Direction of Work Role Performance from the Big 5 Model of Personality Traits. J. Organ. Behav. 2012, 33, 175–192. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762v5. [Google Scholar]
- McCrae, R.R.; Costa, P.T. Empirical and Theoretical Status of the Five-Factor Model of Personality Traits. In The SAGE Handbook of Personality Theory and Assessment: Volume 1—Personality Theories and Models; SAGE Publications Ltd.: Los Angeles, CA, USA, 2008; pp. 273–294. [Google Scholar] [CrossRef]
- Kosinski, M.; Stillwell, D.; Graepel, T. Private Traits and Attributes Are Predictable from Digital Records of Human Behavior. Proc. Natl. Acad. Sci. USA 2013, 110, 5802–5805. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Carducci, G.; Rizzo, G.; Monti, D.; Palumbo, E.; Morisio, M. TwitPersonality: Computing Personality Traits from Tweets Using Word Embeddings and Supervised Learning. Information 2018, 9, 127. [Google Scholar] [CrossRef]
- Quercia, D.; Kosinski, M.; Stillwell, D.; Crowcroft, J. Our twitter profiles, our selves: Predicting personality with twitter. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 180–185. [Google Scholar]
- Alam, F.; Stepanov, E.A.; Riccardi, G. Personality Traits Recognition on Social Network—Facebook. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Chaudhary, S.; Sing, R.; Hasan, S.T.; Kaur, I. A comparative Study of Different Classifiers for Myers-Brigg Personality Prediction Model. IRJET 2018, 5, 1410–1413. [Google Scholar]
- Briggs, K.C. Myers-Briggs Type Indicator; Consulting Psychologists Press: Palo Alto, CA, USA, 1976. [Google Scholar]
- Xue, D.; Wu, L.; Hong, Z.; Guo, S.; Gao, L.; Wu, Z.; Zhong, X.F.; Sun, J. Deep Learning-based Personality Recognition from Text Posts of Online Social Networks. Appl. Intell. 2018, 48, 4232–4246. [Google Scholar] [CrossRef]
- Liu, F.; Nowson, S.; Perez, J. A Language-independent and Compositional Model for Personality Trait Recognition from Short Texts. arXiv 2016, arXiv:1610.04345. [Google Scholar]
- Majumder, N.; Poria, S.; Gelbukh, A.; Cambria, E. Deep Learning-Based Document Modeling for Personality Detection from Text. IEEE Intell. Syst. 2017, 32, 74–79. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Celli, F. Unsupervised Personality Recognition for Social Network Sites. In Proceedings of the Sixth International Conference on Digital Society, Valencia, Spain, 30 January–4 February 2012. [Google Scholar]
- Mairesse, F.; Walker, M.A.; Mehl, M.R.; Moore, R.K. Using Linguistic Cues for the Automatic Recognition of Personality in Conversation and Text. J. Artif. Intell. Res. 2007, 30, 457–500. [Google Scholar] [CrossRef]
- Kafeza, E.; Kanavos, A.; Makris, C.; Vikatos, P. T-PICE: Twitter Personality Based Influential Communities Extraction System. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014. [Google Scholar] [CrossRef]
- Sun, X.; Liu, B.; Meng, Q.; Cao, J.; Luo, J.; Yin, H. Group-level Personality Detection Based on Text Generated Networks. World Wide Web 2019. [Google Scholar] [CrossRef]
- Bai, S.; Zhu, T.; Cheng, L. Big-Five Personality Prediction Based on User Behaviors at Social Network Sites. arXiv 2012, arXiv:1204.4809. [Google Scholar]
- Lukito, L.C.; Erwin, A.; Purnama, J.; Danoekoesoemo, W. Social Media User Personality Classification Using Computational Linguistic. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Iacobelli, F.; Culotta, A. Too Neurotic, Not too Friendly: Structured Personality Classification on Textual Data. In Proceedings of the Seventh International AAAI Conference on Weblogs and Social Media, Boston, MA, USA, 8–11 July 201.
- Pennebaker, J.W.; King, L.A. Linguistic Styles: Language Use as an Individual Difference. J. Personal. Soc. Psychol. 1999, 77, 1296. [Google Scholar] [CrossRef]
- Argamon, S.; Dhawle, S.; Koppel, M.; Pennebaker, J.W. Lexical Predictors of Personality Type. In Proceedings of the 2005 Joint Annual Meeting of the Interface and the Classificaton Society of North America, Cincinnati, OH, USA, 8–12 June 2005. [Google Scholar]
- Pennebaker, J.W.; Mehl, M.R.; Niederhoffer, K.G. Psychological Aspects of Natural Language Use: Our words, our selves. Annu. Rev. Psychol. 2003, 54, 547–577. [Google Scholar] [CrossRef]
- Oberlander, J.; Gill, A.J. Language with Character: A Stratified Corpus Comparison of Individual Differences in e-mail Communication. Discourse Process. 2006, 42, 239–270. [Google Scholar] [CrossRef]
- Kumar, U.; Reganti, A.N.; Maheshwari, T.; Chakroborty, T.; Gambäck, B.; Das, A. Inducing Personalities and Values from Language Use in Social Network Communities. Inf. Syst. Front. 2018, 20, 1219–1240. [Google Scholar] [CrossRef]
- Weisbuch, M.; Ivcevic, Z.; Ambady, N. On Being Liked on the Web and in the “Real World”: Consistency in First Impressions across Personal Webpages and Spontaneous Behavior. J. Exp. Soc. Psychol. 2009, 45, 573–576. [Google Scholar] [CrossRef]
- Su, M.; Wu, C.; Zheng, Y. Exploiting Turn-Taking Temporal Evolution for Personality Trait Perception in Dyadic Conversations. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 733–744. [Google Scholar] [CrossRef]
- Tupes, E.C.; Christal, R.E. Recurrent Personality Factors Based on Trait Ratings. J. Personal. 1992, 60, 225–251. [Google Scholar] [CrossRef] [PubMed]
- Digman, J.M. Personality Structure: Emergence of the Five-factor Model. Annu. Rev. Psychol. 1990, 41, 417–440. [Google Scholar] [CrossRef]
- Goldberg, L.R. The Structure of Phenotypic Personality Traits. Am. Psychol. 1993, 48, 26. [Google Scholar] [CrossRef] [PubMed]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]
- Rangel Pardo, F.M.; Celli, F.; Rosso, P.; Potthast, M.; Stein, B.; Daelemans, W. Overview of the 3rd Author Profiling Task at PAN 2015. In Proceedings of the CLEF 2015 Labs and Workshops, Notebook Papers, Toulouse, France, 8–11 September 2015; pp. 1–8. [Google Scholar]
- Rangel, F.; Rosso, P.; Verhoeven, B.; Daelemans, W.; Potthast, M.; Stein, B. Overview of the 4th author profiling task at PAN 2016: Cross-genre evaluations. In Proceedings of the CEUR Workshop of Working Notes of the CLEF 2016 Evaluation Labs, Évora, Portugal, 5–8 September 2016; pp. 750–784. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| hidden_size | 768 | num_hidden_layers | 12 |
| num_attention_heads | 12 | intermediate_size | 3078 (768 × 4) |
| hidden_act | gelu | hidden_dropout_prob | 0.1 |
| attention_probs_dropout_prob | 0.1 | max_position_embedding | 512 |
| Parameter | Value |
|---|---|
| optimizer | Adam, Adagrad, SGD |
| learning rate | 1 × 10−5, 1 × 10−2, 1 × 10−7 |
| loss function | Mean Squared Error Loss |
| batch size | 50, 100, 200 |
| Mean Squared Error (MSE) | |||||
|---|---|---|---|---|---|
| OPE | CON | EXT | AGR | NEU | |
| SentencePersonality Multilingual | 0.1759 | 0.3045 | 0.4750 | 0.2667 | 0.2911 |
| SentencePersonality | 0.2166 | 0.3556 | 0.5271 | 0.3117 | 0.3576 |
| FastText + NN | 0.3917 | 0.4824 | 0.6100 | 0.3643 | 0.5677 |
| IBM Personality Insights | 0.3769 | 0.5550 | 0.7483 | 0.4289 | 0.9303 |
| Transformer + SVM | 0.3867 | 0.5596 | 0.7579 | 0.5889 | 0.7240 |
| Carducci et al. [8] | 0.3316 | 0.5300 | 0.7084 | 0.4477 | 0.5572 |
| Quercia et al. [9] | 0.4761 | 0.5776 | 0.7744 | 0.6241 | 0.7225 |
| Kullback–Leibler Divergence—OPENNESS | ||||
|---|---|---|---|---|
| Sentence Personality | Transformer + SVM | Carducci et al. [8] | Real | |
| Sentence Personality | 0 | 1209.348 | 807.355 | 36.159 |
| Transformer + SVM | - | 0 | 25.65 | 1337.239 |
| Carducci et al. [8] | - | - | 0 | 1067.897 |
| Real | - | - | - | 0 |
| Kullback–Leibler Divergence—CONSCENTIOUSNESS | ||||
|---|---|---|---|---|
| Sentence Personality | Transformer + SVM | Carducci et al. [8] | Real | |
| Sentence Personality | 0 | 281.968 | 375.6 | 565.094 |
| Transformer + SVM | - | 0 | 79.327 | 377.122 |
| Carducci et al. [8] | - | - | 0 | 609.411 |
| Real | - | - | - | 0 |
| Kullback–Leibler Divergence—EXTRAVERSION | ||||
|---|---|---|---|---|
| Sentence Personality | Transformer + SVM | Carducci et al. [8] | Real | |
| Sentence Personality | 0 | 689.846 | 318.312 | 1019.066 |
| Transformer + SVM | - | 0 | 465.049 | 1814.447 |
| Carducci et al. [8] | - | - | 0 | 1368.251 |
| Real | - | - | - | 0 |
| Kullback–Leibler Divergence—AGREABLENESS | ||||
|---|---|---|---|---|
| Sentence Personality | Transformer + SVM | Carducci et al. [8] | Real | |
| Sentence Personality | 0 | 259.779 | 382.841 | 471.031 |
| Transformer + SVM | - | 0 | 255.15 | 891.557 |
| Carducci et al. [8] | - | - | 0 | 266.071 |
| Real | - | - | - | 0 |
| Kullback–Leibler Divergence—NEUROTICISM | ||||
|---|---|---|---|---|
| Sentence Personality | Transformer + SVM | Carducci et al. [8] | Real | |
| Sentence Personality | 0 | 378.843 | 572.621 | 407.553 |
| Transformer + SVM | - | 0 | 424.558 | 1130.947 |
| Carducci et al. [8] | - | - | 0 | 551.615 |
| Real | - | - | - | 0 |
| Real OPE | Real CON | Real EXT | Real AGR | Real NEU | |
|---|---|---|---|---|---|
| SentencePersonality Multilingual | 34.716 | 543.102 | 878.878 | 381.826 | 255.512 |
| SentencePersonality | 36.159 | 565.094 | 1019.066 | 471.031 | 407.553 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leonardi, S.; Monti, D.; Rizzo, G.; Morisio, M. Multilingual Transformer-Based Personality Traits Estimation. Information 2020, 11, 179. https://doi.org/10.3390/info11040179
Leonardi S, Monti D, Rizzo G, Morisio M. Multilingual Transformer-Based Personality Traits Estimation. Information. 2020; 11(4):179. https://doi.org/10.3390/info11040179
Chicago/Turabian StyleLeonardi, Simone, Diego Monti, Giuseppe Rizzo, and Maurizio Morisio. 2020. "Multilingual Transformer-Based Personality Traits Estimation" Information 11, no. 4: 179. https://doi.org/10.3390/info11040179
APA StyleLeonardi, S., Monti, D., Rizzo, G., & Morisio, M. (2020). Multilingual Transformer-Based Personality Traits Estimation. Information, 11(4), 179. https://doi.org/10.3390/info11040179