Abstract
Named entity recognition (NER) is a fundamental step for many natural language processing tasks and hence enhancing the performance of NER models is always appreciated. With limited resources being available, NER for South-East Asian languages like Telugu is quite a challenging problem. This paper attempts to improve the NER performance for Telugu using gazetteer-related features, which are automatically generated using Wikipedia pages. We make use of these gazetteer features along with other well-known features like contextual, word-level, and corpus features to build NER models. NER models are developed using three well-known classifiers—conditional random field (CRF), support vector machine (SVM), and margin infused relaxed algorithms (MIRA). The gazetteer features are shown to improve the performance, and theMIRA-based NER model fared better than its counterparts SVM and CRF.
1. Introduction
Named entity recognition (NER) is a sub-task of information extraction (IE) to identify and classify textual elements (words or sequences of words) into a pre-defined set of categories called named entities (NEs) such as the name of a person, organization, or location, expressions of time, quantities, monetary values, percentages, etc. The term named entity was first coined at the 6th Message Understanding Conference (MUC-6) [1]. NER plays an essential role in extracting knowledge from the digital information stored in a structured or unstructured form. It acts as a pre-processing tool for many applications, and some of these applications are listed below:
- Information retrieval (IR) is the task of retrieving relevant documents from a collection of documents based on an input query. A study by Guo et al. [2] states that 71% of the queries in search engines are NEs and thus IR [3] can benefit from NER by identifying the NEs within the query.
- Machine translation (MT) is the task of automatically translating a text from a source to a target language. NEs require a different technique of translation than the rest of the words because, in general, NEs are not vocabulary words. If the errors of an MT system are mainly due to incorrect translation of NEs, then the post-editing step is more expensive to handle. The research study by Babych and Hartley [4] showed that including a pre-processing step by tagging text with NEs achieved higher accuracy in the MT system. The quality of the NER system plays a vital role in machine translation [5,6].
- Question answering (QA) systems are tasked with automatically generating answers to questions asked by a human being in natural language. The answers to questions starting with the wh-words (What, When, Which, Where, Who) [7]) are generally NEs. So, incorporating NER in QA systems [8,9,10,11] makes the task of finding answers to questions considerably easier.
- Automatic text summarization includes topic identification of where the NEs are as an essential indication of a topic in the text [12]. It is shown that integrating named entity recognition significantly improves the performance of resulting summaries [13,14].
The problem of the identification and classification of NEs is quite challenging because of the open nature of vocabulary. There has been a significant amount of work on NER in English, wherein the earlier work on NER is based on rule-based and dictionary-based approaches.
Rule-based NER relies on hand-crafted rules for identifying and classifying NEs. These rules can be structural, contextual, or lexical patterns [15]. For example, the following list shows two rules for recognizing organization and person names:
- ⟨proper noun⟩ + ⟨organization designator⟩ ⟶ ⟨organization name⟩
- ⟨capitalized last name⟩, ⟨capitalized first name⟩ ⟶ ⟨person name⟩
The first rule detects organization names that consist of one or more proper nouns followed by an organization designator such as “Corporation” or “Company”. The second rule recognizes person names written in the order of family name, comma, and given the name. The first limitation of the rule-based approach is in the design of generic rules with high precision by the domain expert/linguist. This process takes a significant amount of time and often needs many iterations to improve the performance. Secondly, the rules obtained for a given domain may not be appliccable to other areas for some languages. For example, NEs for the health domain may not be suitable for finance.
Dictionary-based NER uses dictionaries of target entity types (e.g., dictionaries of the names of people, companies, locations, etc.) and identifies the occurrences of the dictionary entries (e.g., Bill Gates, Facebook, Madison Square, etc.) in text [16]. This approach looks very straightforward at first glance but has difficulties due to the ambiguity of natural language. Firstly, the entities can be referred to by different names. For example, Thomas Alva Edison can also be written as Thomas Edison or Edison. It is not practically possible to create a comprehensive dictionary that enumerates all of these variations. Secondly, the same name might represent different entities like a person or location. For example, “Washington” is the name of the first president of the U.S. as well as the name of a state in the U.S. [17]. Since NER systems have to deal with these issues, machine learning approaches have been adopted for NER.
The state-of-the-art of NER systems are machine learning techniques, which can automatically learn to identify and classify NEs based on the data. Supervised learning techniques like hidden Markov model (HMM) [18], maximum entropy model (ME) [19], decision tree [20], conditional random fields [21], neural networks [22], naïve Bayes [23], and support vector machines [24] has been explored to build NER models. There have been few attempts to solve the problem using semi-supervised [25] and unsupervised learning techniques [26]. NER for the English language has been widely researched. However, for South-East Asian languages (especially Telugu) there has not been much progress. Though we may get some insights from the learning models developed for NER in English or other languages, the language-dependent features make it difficult to use similar models for the Telugu language. Telugu (తెలుగు) is a Dravidian language mostly spoken in the states of Andhra Pradesh, Telangana, and other neighboring states of Southern India. Telugu [27] ranks fourth in terms of the number of people speaking it as a first language in India. The main challenges for Telugu NER are listed below:
- Telugu is a highly inflectional and agglutinating language: The way lexical forms get generated in Telugu are different from English. In Telugu, words are formed by inflectional suffixes added to roots or stems. For example: in the word హైదరాబాదులో (haidarAbAdlo (transliteration in English)) (in Hyderabad) = హైదరాబాద్ (haidarAbAd) + లో (lo) (root word + post-position).
- The absence of capitalization: In English, named entities start with a capital letter and this capitalization plays an important role in identifying and classifying NEs, whereas there is no concept of capitalization in Telugu. For example: పూజ (puja) could be the name of a person or the common meaning “worship”. In English, we write “Puja” when it is name of a person and “puja” when it refers to the common noun. In Telugu, we write పూజ (puja) in both cases. Thus, capitalization is an important feature to distinguish proper nouns from common nouns.
- Resource-poor language: For the Telugu language, resources like annotated corpora, name dictionaries (gazetteers), morphological analyzers, part-of-speech (POS) taggers, etc. are not adequately available.
- Relatively free order: The primary word order of Telugu is SOV (subject–object–verb), but the word order of subject and object is largely free. For example, in the sentence: “Ramu sent necklace to sita” can be written as రాము సీతకు హారాన్నిపంపాడు (rAmu sItaku hArAnni oampADu) or రాముహారాన్ని సీతాకు పంపాడు (rAmu hArAnni sItaku pampADu) in Telugu. Internal changes or position swaps among words in sentences or phrases will not affect the meaning of the sentence.
NER for Telugu has been receiving increasing attention, but there are only a few articles in the recent past. Most of the previous works on NER for Telugu [28,29,30,31] build NER models using language-independent features like contextual information, prefix/suffix, orthogonal and POS of current words. The language-dependent features help in improving the performance of the NER task [32] and gazetteers (entity dictionaries) or entity clue lists are part of the language-dependent features. In one of the previous works on Telugu NER [33] the model is built using both language-independent and language-dependent features, but the language-dependent-feature gazetteers are generated manually. However, building and maintaining high-quality gazetteers by hand is time-consuming. Many methods have been proposed for the automatic generation of gazetteers [34]. However, these methods require patterns or statistical methods to extract high-quality gazetteers. The exponential growth in information content, especially in Wikipedia, has made it increasingly popular for solving a wide range of NLP problems across different domains. Wikipedia has 69,450 (https://meta.wikimedia.org/wiki/List_of_Wikipedias) articles in the Telugu language as of July 2018. Each article in Wikipedia is identified by a unique name known as an “entity name”. These articles have many useful structures for knowledge extraction such as headings, lists, internal links, categories, and tables. In this work, we used category labels for the dynamic creation of gazetteer features. The process is explained in Section 3.3.3.
The major contributions in this work are listed below:
- Morphological pre-processing is proposed to handle the inflectional and agglutinating issues of the language.
- We propose to use language-dependent features like clue words (surname, prefix/suffix, location, organization, and designation) to build an NER model.
- We present a methodology for the dynamic generation of gazetteers using Wikipedia categories.
- We extract the proposed features for the FIRE data set and make it publicly available to facilitate future research.
- We perform a comparative study of NER models built using three well-known machine learning algorithms—support vector machine (SVM), conditional random field (CRF), and margin infused relaxed algorithm (MIRA).
- We study the impact of gazetteer-related features on NER models.
The rest of this article is organized as follows: The related work on NER in Indian languages is discussed in Section 2. Section 3 explains the NER corpus, tag-set with potential features, and briefly explains the three different classifiers used to build the models. The experimental results are discussed in Section 4 followed by the conclusion of the article in Section 5.
2. Related Work on NER
In this section, we first discuss NER-related studies in the Telugu language, followed by some studies of other Indian languages—Hindi, Bengali, and Tamil.
Srikanth and Murthy [33] were some of the first authors to explore NER in Telugu. They built a two-stage classifier which they tested using the LERC-UoH (Language Engineering Research Centre at University of Hyderabad) Telugu corpus. In the early stage, they built a CRF-based binary classifier for noun identification, which was trained on manually tagged data of 13,425 words and tested on 6223 words. Then, they developed a rule-based NER system for Telugu, where their primary focus was on identifying the name of person, location, and organization. A manually verified NE-tagged corpus of 72,157 words was used to develop this rule-based tagger through boot-strapping. Then, they developed a CRF-based NER system for Telugu using features such as prefix/suffix, orthographic information, and gazetteers, which were manually generated, and reported an F1-score of 88.5%. In our work we present a methodology for the dynamic generation of gazetteers using Wikipedia categories.
Praneeth et al. [28] proposed a CRF-based NER model for Telugu using contextual word of length three, prefix/suffix of the current word, POS, and chunk information. They conducted experiments on data released as a part of the NER for South and South-East Asian Languages (NERSSEAL) (http://ltrc.iiit.ac.in/ner-ssea-08/) competition with 12 classes. The best-performing model gave an F1-Score of 44.91%.
Ekbal et al. [31] proposed a multiobjective optimization (MOO)-based ensemble classifier using a three-base machine learning algorithm (maximum entropy (ME), CRF, and SVM). The ensemble was used to build NER models for Hindi, Telugu, and Bengali languages. The features used to construct the Bengali NER were contextual words, prefix/suffix, length of the word, the position of the word in the sentence, POS information, digital information, and manually generated gazetteer features. They reported an F1-Score of 94.5%. To build an NER model for Hindi and Telugu, they used the contextual words, prefix/suffix, length of the word, the position of the word in the sentence, and POS information, and reported F1-Scores of 92.80% and 89.85% for Hindi and Telugu, respectively.
Sriparna and Asif [30] extended the above work by building an ensemble classifier using base classifiers ME, Naïve Bayes, CRF, Memory-Based Learner, Decision Tree (DT), SVM, and hidden Markov model (HMM) without using any domain knowledge or language-specific resources. The proposed technique was evaluated for three languages—Bengali, Hindi, and Telugu. Results using a MOO-based method yielded the overall F1-Scores of 94.74% for Bengali, 94.66% for Hindi, and 88.55% for Telugu.
Arjun Das and Utpal Garain [29] proposed CRF-based NER systems for the Indian language on the data set provided as a part of the ICON 2013 conference. In this task, the NER model for the Telugu language was built using language-independent features like contextual words, word prefix and suffix, POS and chunk information, and first and last words of the sentence. The model obtained an F1-Score of 69%.
SaiKiranmai et al. [35] built a Telugu NER model using three classification learning algorithms (i.e., CRF, SVM, and ME) on the data set provided as a part of the NER for South and South-East Asian Languages (NERSSEAL) (http://ltrc.iiit.ac.in/ner-ssea-08/) competition. The features used to build the model were contextual information, POS tags, morphological information, word length, orthogonal information, and sentence information. The results show that the SVM achieved the best F1-Score of 54.78%.
SaiKiranmai et al. [36] developed an NER model which classifies textual content from on-line Telugu newspapers using a well-known generative model. They used generic features like contextual words and their POS tags to build the learning model. By understanding the syntax and grammar of the Telugu language, they introduced some language-dependent features like post-position features, clue word features, and gazetteer features to improve the performance of the model. The model achieved an overall average F1-Score of 88.87% for person, 87.32% for location, and 72.69% for organization identification.
SaiKiranmai et al. [37] attempted to cluster NEs based on semantic similarity. They used vector space models to build a word-context matrix. The row vector was constructed with and without considering the different occurrences of NEs in a corpus. Experimental results show that the row vector considering different occurrences of NEs enhanced the clustering results.
In the Hindi language, Li and McCallum [38] built a CRF-based NER model by making use of 340k words with three NE tags, namely person, location, and organization, and reported an F1-score of 71.5%. Saha et al. [39] developed a Hindi NER model using maximum entropy (ME). They developed the model using language-specific and context pattern features, obtaining an F1-score of 81.52%. Saha et al. [40] proposed a novel kernel function for SVM to build an NER model for Hindi and bio-medical data. The NER model achieved an F1-score of 84.62% for Hindi.
In the Bengali language, Ekbal and Sivaji [41] developed an NER model using SVM. The corpus consisted of 150k words annotated with sixteen NE tags. The features used to build the model were context word, word prefix/suffix, POS information, and gazetteers, and it achieved an average F1-score of 91.8%. Ekbal et al. [42] developed an NER model for Bengali and Hindi using SVM. These models use different contextual information of words in predicting four NE classes, such as a person, location, organization, and miscellaneous. The annotated corpora consist of 122,467 tokens for Bengali and 502,974 tokens for Hindi. This model reported an F1-score of 84.15% for Bengali and 77.17% for Hindi. Ekbal et al. [43] developed an NER model using CRF for Bengali and Hindi using contextual features with an F1-score of 83.89% for Bengali and 80.93% for Hindi. Banerjee et al. [44] developed an NER model for Bengali using the margin infused relaxed algorithm. They used IJCNLP-08 NERSSEAL data, which are annotated with twelve NE tags, and obtained an F1-Score of 89.69%.
Vijayakrishna and Sobha [45] developed a Tamil Named Entity Recognizer for the tourism domain using CRF. It handles nested NEs with a tag-set consisting of 106 tags, and reported an overall F1-Score of 80.44%. Abinaya et al. [46] present a NER model for Tamil using the random kitchen sink (RKS) algorithm, which is a statistical and supervised approach. They also implemented the NER model using SVM and CRF and reported overall F1-Scores of 86.61% for RKS, 81.62% for SVM, and 87.21% for CRF.
3. Proposed Methodology for Telugu NER
NER in Telugu is comparatively challenging as it is highly inflectional and agglutinating in nature. Telugu is morphologically rich language [47]. The significant portion of grammar is managed by morphology in Telugu. Each inflected word starts with a root and has many suffixes. The word suffix used here refers to inflections, post-positions, and markers which indicate tense, number, person and gender, negatives, and imperatives. In English, phrases generally include several words, and in most cases, such phrases are mapped to a single word in Telugu. For example, గెలవలేదనుకొన్నావా (vacciveLLADu) (do you think he will not win?) and రాజమండ్రివైపు (rAjamaMDrovaipu) (towards rajahmundary) are single words in Telugu, which makes the NER task complex.
The application of stochastic models to the NER problem requires a large annotated corpus to achieve a reasonable performance. Stochastic models have been applied to English and other languages due to the availability of sufficiently large annotated corpora. The problem is difficult for Telugu due to the absence of such annotated corpora. HMMs [48] do not work well when small amounts of annotated corpus are used to estimate the model parameters, and the incorporation of diverse features is difficult. In contrast, CRF, SVM, and MIRA learning algorithms can efficiently deal with the diverse and overlapping features of the Telugu language. We implemented these learning algorithms to identify NEs and classify them into predefined NE classes—Name, Location, Organization, and Miscellaneous.
In this section, we describe the corpus and tag-set of NEs with potential features and classifiers used to build the NER models.
3.1. Corpus and Named Entity Tag-Set
The different corpora that have been used so far in literature for NER in Telugu are listed below:
- IJCNLP-Workshop on NER for South and South-East Asian Languages-2008 (http://ltrc.iiit.ac.in/ner-ssea-08/index.cgi?topic=5): This data set consists of 64,026 tokens. The tag-set for the task has 12 tags. The reason they opted for these tags was that they needed a slightly finer tag-set for machine translation (MT) and certain domains like health and tourism.
- ICON-NLP Tools Contest on Named Entity Recognition in Indian languages, 2013 (http://ltrc.iiit.ac.in/icon/2013/nlptools/: The data set has four NE classes, and it is not publicly available.
In this work, we used the bench-marked data set (http://fire.irsi.res.in/fire/2018/home) provided by the Forum of Information Retrieval and Evaluation (FIRE-2018). The main advantage is that the corpus is large enough as compared to other available data sets. The data consists of 767,603 tokens, out of which 200,059 are NEs. The size of the data set is given in Table 1.

Table 1.
Size of the data set.
The data set is annotated with nine named entity tags. A tag conversion routine was implemented on the corpus to scale down the initial nine-member tag-set to the intended four-member tag-set— namely, name, location, organization, and miscellaneous as shown in Table 2.
Table 2.
Named entity tag-set.
3.2. Morphological Pre-Processing
Telugu is a highly inflectional and agglutinating language, and hence it makes all sense to perform morphological pre-processing. Morphology is the study of word formation—how words are formed from smaller morphemes. A morpheme is the smallest part of a word that has grammatical information or meaning. For example, the word హైదరాబాదులో (haidarAbAdlo) in Telugu means “in Hyderabad” in English. The morphemes in this word are హైదరాబాద్ (haidarAbAd) and లో (lo). After the morphological pre-processing, the word హైదరాబాదులో (haidarAbAdlo) will be split into two words హైదరాబాద్ (haidarAbAd) and లో (lo). We propose this kind of morphological pre-processing to enrich the features of the NER model.
The morphological pre-processing was performed using the TnT (Trigrams’n’Tags) tool [49]. For the following example in Figure 1, with the morphological pre-processing the words ముంబైలో (mumbailo) will be split into ముంబై (mumbai) and లో (lo) similarly, సమావేశానికి (samAvESAniki) will be సమావేశం (samAvESAm) and కి (ki).
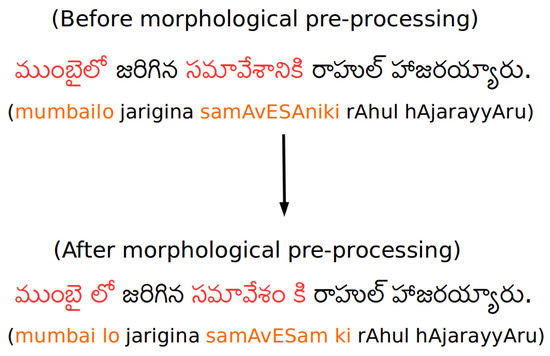
Figure 1.
Morphological pre-processing.
3.3. Features
In this section, we present the features used for the recognition and classification of Telugu NEs. The extraction of features from a text corpus is an essential step in natural language processing (NLP) to apply machine learning (ML) techniques. We organized these features into the following different types: contextual, word-level, gazetteer, and corpus features.
3.3.1. Contextual Features
The neighboring words of a given word carry effective information in classifying whether that word is an NE or not. Hence, we considered words in a sliding window of size k as the contextual features. For example: Given the sentence నాగార్జునసాగర్ జలాశయానికి వరద పూర్తిస్థాయిలో తగ్గుముఖం పట్టింది (nAgArjunasAgar jalASayAniki varada pUrtisthAyilO taggumukham paTTimdi), for the current word వరద (varada) the contextual features for a sliding window of size of are {జలాశయానికి (jalASayAniki), పూర్తిస్థాయిలో (pUrtisthAyilO)}. The the contextual features for the same word for a sliding window of size are {నాగార్జునసాగర్ (nAgArjunasAgar), జలాశయానికి (jalASayAniki), పూర్తిస్థాయిలో (pUrtisthAyilO), తగ్గుముఖం (taggumukham)}. The optimal size of the sliding window is decided by performing a sensitivity analysis.
The challenges of Telugu NER are detailed in Section 1. The contextual features in building NER models tend to address the following challenges:
- Absence of capitalization: Capitalization is not a distinguishing feature of Telugu script, which makes it difficult to differentiate between common nouns and proper nouns.For example: పూజ (puja) can be the name of a person or a common noun meaning “worship”. The ambiguity between common and proper nouns is resolved using the contextual information of a named entity.
- Relatively free order: Internal changes or position swaps among words in sentences or phrases will not affect the meaning of the sentence. This is resolved using the contextual information of a word.For example:
- -
- రాము సీతకు హారాన్ని పంపాడు (rAmu sItaku hArAnni oampADu), for the current word సీతకు (sItaku) the contextual features for a sliding window of size of are {రాము (rAmu), హారాన్ని (hArAnni)}.
- -
- రాము హారాన్ని సీతాకు పంపాడు (rAmu hArAnni sItaku pampADu), for the current word సీతకు (sItaku) the contextual features for a sliding window of size of are {హారాన్ని (hArAnni), పంపాడు (pampADu)}.
3.3.2. Word-Level Features
Word-level features are related to the individual orthographic nature and structure of each word. They specifically describe word length, the position of a word, whether the word contains a number, and the POS tag of a word. Kumar et al. [50] found that short words are most probably not NEs and predefined the threshold to be less than or equal to three. So, we considered word length as a binary feature if the current word length ≥3. In a sentence, the position of a word acts as a good indicator for named entity identification, as NEs tend to appear in the first position of the sentence. In Telugu, verbs typically appear in the last position of the sentence, as it follows a subject–object–verb structure. So, we considered two binary features FirstWord and LastWord.
Previous works in Telugu NER used POS features as a binary feature (i.e., whether a word is a noun or not a noun). The study by SaiKiranmai et al. [51] suggests that other part-of-speech tags like postposition, quantifiers, demonstratives, cardinal/ordinal, NST (noun denoting spatial and temporal expression), and quotative are helpful in identifying whether a given word is a named entity or not. So, in our work we used the TnT [49] POS tagger, which classifies a Telugu word into one of 21 POS tags, and we considered the POS tag of the target word and surrounding words as features for NER.
The Named Entity of previous word(s) was also considered as a dynamic feature in the experiment.
3.3.3. Gazetteer Features
Gazetteers or entity dictionaries play an essential role in improving the performance of the NER task. However, building and maintaining high-quality gazetteers by hand is time-consuming. Many methods have been proposed for the automatic generation of gazetteers from a vast number of text documents [34]. However, these methods require patterns or statistical methods to extract high-quality gazetteers.
The exponential growth in information content, especially in Wikipedia, has made it increasingly popular for solving a wide range of NLP problems across different domains. Wikipedia had 69,450 (https://meta.wikimedia.org/wiki/List_of_Wikipedias) articles in the Telugu language as on July 2018. Each article in Wikipedia is identified by a unique name known as “entity names”. These articles have many useful structures for knowledge extraction, such as headings, lists, internal links, categories, and tables. Further, new articles are added to Wikipedia every day. Hence, many recent studies have made use of Wikipedia as a knowledge source to generate gazetteers [52,53,54].
We explain the procedure of the gazetteer generation of person, location, and organization names by making use of Wikipedia articles in Section 3.3.4 and the generation of clue lists in Section 3.3.5.
3.3.4. Gazetteer Creation Using Wikipedia
Wikipedia maintains a list of categories for each of its title pages. The example Wikipedia page title “Mahendra Singh” and its categories in Telugu and English are as shown in Figure 2 and Figure 3.
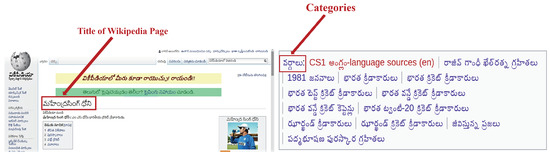
Figure 2.
Title and categories of a Wikipedia page in Telugu.
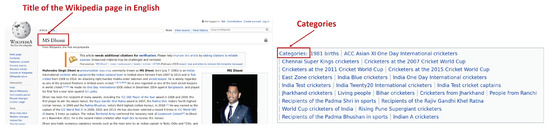
Figure 3.
Title and categories of a Wikipedia page in English.
Zhang et al. [53] made use of these category labels for gazetteer creation for NER. For example, Wikipedia categories such as “Educational institutions established in 1926” and “Companies listed on the Bombay Stock Exchange” refer to organizations; “Living people” and “Player” refer to people; and “States and territories”, “City-states” refer to locations.
In our work, NER experiments were conducted on a resource-poor language (Telugu). We devise a procedure for the dynamic creation of gazetteers using Wikipedia categories.
We manually collected most frequent NEs. These frequent NEs are seed list () of each class C = {person, location, organization} and lists of 1049, 731, and 254 entities for persons, locations, and organizations, respectively. We collected category labels (s) for all the entities in the seed list. For a person-type named entity the category list may contain “actor”, “engineer”, and “famous” and for a location-type named entity the category may contain “city”, “street”, and “famous”. Some of the category labels might be there in both category lists of two distinct NEs (e.g., person and location). In the example above the category label “famous” is in both lists. The next step in our algorithm is to remove the ambiguous category labels that are present in more than one list, and the result is a unique category list () for each class C. The procedure for extracting unique category labels for each NE class is shown in Algorithm 1.
| Algorithm 1 Extracting unique category labels for each NE class. |
| Input : – Seed lists of entities of class C = {person, location, organization} |
Output : – List of unique category labels of C
|
We extracted the category list for each of the Wikipedia titles (s) from the Telugu Wikipedia dump (https://dumps.wikimedia.org/tewiki/) of 69,450 articles. We describe the procedure for the generation of gazetteer lists for each class in Algorithm 2. An example is explained below:
Consider the Wikipedia page of the famous Indian cricket player “Mahendra Singh Dhoni” (మహేంద్రసింగ్ ధోని) as shown in Figure 2 (https://te.wikipedia.org/wiki/మహేంద్రసింగ్;_ధోని) and its category labels (వర్గాలు) such as “జీవిస్తున్న ప్రజలు” (living people), “1981జననాలు” (births). Our algorithm searches the category labels of “Mahendra Singh Dhoni” (మహేంద్రసింగ్ ధోని) in the unique category list () and finds that maximum number of category labels correspond to the class . Consequently, our algorithm classifies “Mahendra Singh Dhoni” (మహేంద్రసింగ్ ధోని) as a person.
| Algorithm 2 Generation of Gazetteers from category labels |
| Input :List of Wikipedia titles |
Output : – List of Gazetteer G of class C
|
After expansion, our list contains 7593 person names, 4791 location names, and 1254 organization names. Examples of NEs collected for each class are shown in Table 3.
Table 3.
Example of named entity instances extracted from Wikipedia.
3.3.5. Gazetteer of Entity Clues
Clue words give some information about whether the current word is a named entity or not. The following are the lists of clue words that have been proposed.
- Surname gazetteer: Surnames occur at the start of person names. We generated a gazetteer of surnames manually by making use of the person gazetteer list obtained from Algorithm 2. For example, in అర్జుల రామచంద్ర రెడ్డి (arjula rAmacmdra reDDi), అర్జుల (arjula) is the surname. If the current word () is present in the surname gazetteer, then the Surname feature is set to 1.
- Person suffix gazetteer: The person suffix occurs at the end of a person’s name. We generated a gazetteer of person suffixes manually by making use of the person gazetteer list obtained from Algorithm 2. For example, in అర్జుల రామచంద్ర రెడ్డి (arjula rAmacmdra reDDi), రెడ్డి (reDDi) is the person suffix. If the current word () is present in the person suffix gazetteer, then the PerSuffix feature is set to 1 for the current () and previous two words (, ).
- Designation gazetteer: Designation words represent the formal and official status of a person. For example, రాష్టపత్రి (rAshTapatri), ప్రధానమంత్రి (pradhAnama mtri). If the current word () is present in the designation gazetteer, then the Desig feature is set to 1 for the next word ().
- Person prefix gazetteer: Person prefixes help in identifying person names (e.g., శ్రీ (SrI), శ్రీమతి (SrImati)). If the current word () is present in a person prefix gazetteer, then the PerPrefix feature is set to 1 for the current () and next two words (, ).
- Month gazetteer: The month gazetteer consists of the names of months of both English and Telugu calendars. There are 24 entries in this list. If the current () word is present in the month gazetteer, then the Month feature is set to 1.
- Location clue gazetteer: The location clue gazetteer consists of the words that give clues about location names—for example, clue words like: -pur, -puram, -gunTa, -nagar, -paTnam (తిరువంతపురం (tiruvamtapuram), కాన్పూర్ (Kanpur), రేణిగుంట (rENugunTa), శ్రీనగర్ (SrInagar), మచిలీపట్నం (macilIpaTnam)). If the current () word contains any of the suffixes listed in the location clue gazetteer, then the LocClue feature is set to 1.
- Organization clue gazetteer: Organization names tend to end with one of a few suffixes, such as మండలి (Council), సంస్థ (Company), సంఘం (Community), సమఖ్యా (Federation), or క్లబ్ (Club). These were collected manually. The feature OrgClue is set to 1 for the current () and previous two words (, ) if the current word () is present in the organization clue gazetteer.
The challenges of Telugu NER are specified in Section 1 and “Absence of capitalization” issues are handled by making use of gazetteers. Capitalization is not a discriminate feature for Telugu script, which makes it difficult to distinguish between common nouns and proper nouns. For example, పూజ (puja) can be the name of a person or the common meaning “worship”. The ambiguity between common and proper nouns is resolved using the contextual information of a named entity. In general, a named entity is identified in context with a trigger word, clue word, and prefix/suffix information to the left and right of the NE.
3.3.6. Corpus Features
In any corpus, the NEs are not as frequent as other words, and hence a rare word is more likely to be a named entity. Therefore we considered a Boolean feature “RareWord” to specify whether a word is rare or not. We defined a word to be a rare word if its frequency was greater than or equal to some threshold value. The threshold frequency of words was tuned by considering different possible threshold values (i.e., 5, 10, 15, and 20). The model obtained the best results when we considered the frequency of 10 as an optimal number of rare words.
The description of all the features used to build NER models are shown in Table 4, where represents the current word.
Table 4.
Features. POS: part-of-speech.
The methods applied to handle the challenges in the Telugu language are listed in Table 5.
Table 5.
Methods to handle the challenges in the Telugu language for named entity recognition (NER).
We extracted the proposed features for the FIRE data set and have made it publicly available to facilitate future research (https://github.com/gsaikiranmai/NER/).
3.4. Classifiers
In this section we briefly describe three different classifiers and the tools used to build the models.
3.4.1. Support Vector Machine (SVM)
The support vector machine was evaluated with polynomial kernels of different degrees, and we observed that the kernel with a polynomial of degree 2 fared better. We also observed that the pairwise multi-class decision method performed better than the one vs. rest method. We used the YamCha (http://chasen.org/~taku/software/yamcha/) toolkit and TinySVM (http://chasen.org/~taku/software/TinySVM/) to implement SVM. The results are shown in Section 4.2 for an SVM with a polynomial kernel of degree 2 and pairwise multi-class decision.
3.4.2. Conditional Random Field (CRF)
Conditional random field (CRF) is a probabilistic framework used for labelling and segmenting sequential data. We used the CRF++ (https://taku910.github.io/crfpp/) toolkit, which is an open source tool. We made use of L2 regularization and the regularization parameter C was set to the default value of 1. The number of iterations processed was 100 and the cut-off threshold for the features was set to the default value of 1.
3.4.3. MIRA
The margin infused relaxed algorithm [55] is a machine learning algorithm for multi-class classification problems. It learns a set of parameters (vector or matrix) by processing all training examples one-by-one and updating the parameters for each training sample. The change in parameters was kept as small as possible. MIRA is also called the passive-aggressive algorithm (PA-I), and it is an extension of the online machine learning perceptron.
We used CRF++ (https://taku910.github.io/crfpp/), an open source tool kit which supports single-best MIRA.
4. Experiment and Results
In this section, we briefly illustrate the performance metrics used in our study to evaluate the models. The results obtained on test data using two different feature sets are explained in Section 4.2.
4.1. Evaluation Metrics
The standard evaluation measures like precision (P), recall (R), and F1-score () were considered to evaluate our experiments.
where r is the number of NEs predicted by the system, t is the total number of NEs present in the test set, and c is the number of NEs correctly predicted by the system.
4.2. Experimental Results on the FIRE Competition Data Set
The data consisted of 767,603 tokens out of which 200,059 were NEs, and we trained the model with 70% of the data and tested on the remaining 30%. Ten sets of training and testing data were generated using the annotated corpus. This split was done randomly and sentences were not repeated in the training and testing data. We then used these 10 sets of test data to evaluate our classifier. The total number of NEs in the test set are shown in Table 6.
Table 6.
Total number of named entities in the test set.
We built two different models for three classifiers, with
- Contextual, word-level, and corpus features (Model A);
- Contextual, word-level, corpus, and gazetteer features (Model B).
The results provided below are the averages of the macro recall, precision, and F1-score for 10 runs.
4.2.1. Evaluation Based on Contextual, Word-Level, and Corpus Features (Model A)
We built three models using contextual, word-level, and corpus features using CRF, SVM, and MIRA. The evaluation results on the test set for each named entity class are presented in Table 7.
Table 7.
Experimental results of each named entity (NE) class in the test set using contextual, word-level, and corpus features. CRF: conditional random field; MIRA: margin infused relaxed algorithm; SVM: support vector machine. P: precision; R: recall; F1: F1-score.
In terms of the F1-score, MIRA performed better than SVM and CRF, with relative percentage point improvements of 3.29% and 6.31% for “name”, 3.31% and 3.52% for “location”, 1.75% and 11.71% for “organization”, and 0.75% and 3.52% for “misc”, respectively.
The overall average precision, recall, and F1-score of different classifiers are shown in Table 8. Results show that the MIRA-based model performed best among all three models, with 80.85% precision, 75.36% recall, and an F1-score of 77.94%.
Table 8.
Overall performance of each classifier.
4.2.2. Evaluation Based on Contextual, Word-Level, Corpus, and Gazetteer Features (Model B)
We built three models for CRF, SVM, and MIRA using contextual, word-level, corpus, and gazetteer features. We strengthened the feature set by including gazetteer features to improve the NER performance. We generated gazetteers for name, location, and organization as explained in Section 3.3.3. We also created entity clues such as surname, person suffix and prefix, location clue, organization clue, designation, and month as explained in the same section. The results obtained by classifiers built using CRF, SVM, and MIRA for each class are presented in Table 9. In terms of precision, CRF performed better than SVM and MIRA for “location”, “organization”, and “misc”. For “name”, MIRA performed better.
Table 9.
Experimental results of each NE class on the test set using contextual, word-level, corpus, and gazetteer features.
In terms of the F1-score, MIRA performed better than SVM and CRF, with relative percentage point improvements of 1.77% and 5.48% for “name”, 0.27% and 1.1% for “location”, and 5.9% and 13.34% for “organization”. For “misc”, SVM performed slightly better than MIRA and CRF, with relative percentage point improvements of 0.03%, 1.59% respectively.
The overall average precision, recall, and F1-score of the three different classifiers are shown in Table 10. For precision, MIRA (96.05%) and SVM (95.45%) performed slightly better than CRF (95.87%), with MIRA showing relative percentage point improvements of 0.6% and 0.18%, respectively. In terms of recall, MIRA (89.91%) performed better than SVM (88.54%) and CRF (83.88%) with relative percentage point improvements of 1.37% and 5.03%, respectively.
Table 10.
Overall performance of each classifier.
The number of correctly classified NEs identified by the NER model implemented using CRF, SVM, and MIRA and the number of misclassifications for each classifier are listed in Table 11.
Table 11.
Number of entities identified by different classifiers for Model A and Model B.
It can be seen that MIRA performed better than SVM and CRF with respect to performance measures like Precision, Recall and F1-score. The main reason for MIRA’s superior performance can be attributed to two factors:
- Its ability to handle overlapping features efficiently.
- MIRA updates the parameters based on a single training instance at a time rather than updating parameters in a batch mode as in SVM.
4.2.3. Improvement of the Performance of NER by including Gazetteer Features
After including gazetteer features, the performance of the NER model increased, irrespective of the classifier. The results in Table 12 depict the percentage point increases in the performance of each NE class after including gazetteer features. The maximum percentage point increase for the NE class “name” was 11.21% by SVM, for “location” it was 17.18% by SVM, for “organization” it was 25.34% by MIRA, and for “miscellaneous”it was 8.9% by CRF. Out of the four NE classes, the organization NE class benefited most from gazetteer features as it is a multi-word entity and each word in an organization has a different POS tag.
Table 12.
Increase in F1-score after including gazetteer features for each class.
The results in Table 13 show that the overall increases in the performance after including gazetteer features were 14.72% for MIRA, 15.95% for SVM, and 17.13% for CRF.
Table 13.
Overall increase in F1-score after including gazetteer features.
Hence, we conclude that the gazetteer features improved the performance of our NER model.
4.2.4. Discussion and Error Analysis
An important characteristic of any data set is the variation in the data. The most common measure of variation, or spread, is the standard deviation. The standard deviation is a number that measures how far data values are from their mean. Table 14 shows the minimum, maximum, mean, median, and standard deviation of the three classifiers (MIRA, SVM, and CRF) using Model A and Model B. The median value of MIRA in both Model A and Model B was greater than that of other classifiers, so MIRA performed better than SVM and CRF.
Table 14.
Measure of dispersion.
A two-tailed t-test was performed using the macro F1-score to check if there was a significant difference between Model A and Model B for MIRA, SVM, and CRF. The corresponding p-values are 3.77 × , 1.88 × , and 1.83 × . Since the p-values are much less than 0.05, we conclude that there was a significant difference between Model A and Model B irrespective of the classifiers.
The procedure that we put forth to create dynamic gazetteers generated rich collections of gazetteer lists: 7593 person names, 4791 location names, and 1254 organization names. The corresponding gazetteer features contributed to the improvement of our NER model.
Further, we performed a pairwise t-test for MIRA–SVM, MIRA–CRF, and SVM–CRF to check if there was a significant difference between these pairs. The corresponding p-values are 5.096 × , 5.327 × , and 2.14 × . As the p-values are less than 0.05, we conclude there was a significant difference between all pairs of classifiers.
We ran an error analysis to identify incorrect predictions for each class. The following are examples of false negatives incorrectly predicted by Model A and correctly predicted by Model B.
- Organization
- -
- ఐక్యరాజ్య సమితి (aikyarAjya Samiti) was misclassified as aikyarAjya<other> Samiti<other> by Model A. By including the organization suffix as a clue feature, Model B was able to classify correctly (i.e., aikyarAjya<organization> Samiti<organization>).
- -
- భారతీయ జనతా పార్టీ (bhAratIya janatA pArtI) was misclassified as bharatiya<location> janata<other> pArtI<other> by Model A. The dynamic gazetteers generated using Wikipedia enabled Model B to classify bhAratIya<organization> janatA<organization> pArtI<organization> correctly.
- Name
- -
- రేవురి ప్రకాష్ రెడ్డి (rEvUri prakAsh reDDi) was misclassified as rEvUri<other> prakAsh<name> reDDi<other> by Model A. By including person prefix/suffix as a clue feature, Model B was able to classify rEvUri<name> prakAsh<name> reDDi<name> correctly.
- -
- శేషరెడ్డి (SeshAreDDI) was misclassified as SeshAreDDI<other> by Model A. The dynamic gazetteers generated using Wikipedia enabled Model B to classify SeshAreDDI<name> correctly.
The following provides an example relevant to morphological pre-processing:
- Location
- -
- భారతదేశంలో (bhAratadESamlo) was misclassifed as bhAratadESamlo<other> before morphological pre-processing. After morphological pre-processing it was classified as bhAratadESam<location> lo<other>.
The following are examples of false positives incorrectly predicted by Model A and correctly predicted by Model B.
- Others
- -
- పార్టీ (pArtI):In the sentence ఈ ఎన్నికల్లో భారతీయ జనతా పార్టీ విజయం సాధించింది. (I ennikallO bhAratIya janatA pArtI vijayam sAdhimcimdi) the word పార్టీ (pArtI) is tagged as <organization>.In the sentence నేను పార్టీ కి వెళ్ళాను. (nEnu pArTI ki vellEnu) the word పార్టీ (pArtI) is tagged as <other> but Model A predicted it as <organization> as in the corpus most of the time pArtI was preceded by an organization name. Model B predicted it correctly as <other> as the organization gazetteer feature for the preceding words was zero, which helped it to classify correctly.
- -
- నరసింహస్వామి (narasimhasvAmi):In the sentence మైదవోలు నరసింహస్వామి గవర్నర్గా ఉన్నారు. (maidavOlu narasimhasvAmi gavarnrgA unnAru) the word నరసింహస్వామి (narasimhasvAmi) is tagged as <name>.In the sentence నేను నరసింహస్వామి ఆలయానికి వెళ్ళాను. (nEnu narasimhasvAmi AlayAniki vellEnu) the word నరసింహస్వామి (narasimhasvAmi) is tagged as <other> but Model A predicted it as <name> as in the corpus most of the time narasimhasvAmi was a person’s name. Model B predicted it correctly as <other> as in the person gazetteer, the person prefix/suffix features was zero for surrounding words, which helped to classify correctly.
4.3. Experimental Results on the NER for South and South-East Asian Languages (NERSSEAL) Competition Data Set
The Telugu NER data set was released as a part of the NER for South and South-East Asian Languages (NERSSEAL) (http://ltrc.iiit.ac.in/ner-ssea-08/index.cgi?topic=3) competition. The data set consists of 64,026 tokens out of which 10,894 are NEs and it is divided into training and testing sets. Characteristics of the data set are shown in Table 15.
Table 15.
NER for South and South-East Asian Languages (NERSSEAL) data set characteristics.
The tag-set as mentioned in the competition was based on AUKBC’s ENAMEX (Named Entities tag), TIMEX (Temporal Expressions), and NUMEX (Number Expressions). It has 12 tags (i.e., NEP-Person, NED-Designation, NEO-Organization, NEA-Abbreviation, NEB-Brand, NETP-Title-Person, NETO-Tile-object, NEL-Location, NETI-Time, NEN-Number, NEM-Measure, NETE-Terms). In order to make consistency between FIRE and NERSSEA data sets we combined the tags. NEP, NED, and NETP were grouped to name; NEO and NEB were grouped to organization; NELis was grouped to location; and NEA, NETO, NETI, NETN, NETM, and NETE were grouped to miscellaneous.
We built a model with contextual word-level corpus features using the NERSSEAL (http://ltrc.iiit.ac.in/ner-ssea-08/index.cgi?topic=3) competition data set and refer to this model as Model A. We built the model with contextual, word-level, corpus, and gazetteer features using the NERSSEAL (http://ltrc.iiit.ac.in/ner-ssea-08) competition data set and refer to this model as Model B. Table 16 shows the per-class F1-score values for Model A (without gazetteer features) and Model B (with gazetteer features). The overall performances of each classifier with respect to precision, recall, and F1-score are shown in Table 17.
Table 16.
Experimental results of each NE class on the test set for Models A and B in terms of F1-score.
Table 17.
Experimental results of each classifier for Models A and B.
Table 18 shows the minimum, maximum, mean, median, and standard deviation of the three classifiers (MIRA, SVM, and CRF) using Model A and Model B. The median values of MIRA in both Model A and Model B were greater than for the other classifiers, and so MIRA performed better than SVM and CRF.
Table 18.
Measure of dispersion.
A two-tailed t-test was performed using the macro F1-Score to check if there was a significant difference between Model A and Model B for MIRA, SVM, and CRF. The corresponding p-values are 2.523 × , 2.056 × , and 2.493 × . Since the p-value is less than 0.05, we conclude that there was a significant difference between Model A and Model B, irrespective of the classifier.
Further, we performed pairwise t-tests for MIRA–SVM, MIRA–CRF, and SVM–CRF to check if there was a significant difference between these pairs. The reported p-values are 2.224 × , 1.158 × , and 1.184 × . Since the p-values are less than 0.05, we conclude there was a significant difference between the pairs of classifiers.
5. Conclusions and Future Work
In this work, we put forth an approach to generate gazetteers dynamically for three named entities—person, location, and organization—and propose gazetteer-based features for Telugu NER. We also performed morphological pre-processing and used language-dependent features to enhance the performance of the NER models. NER models were built with MIRA, SVM, and CRF classifiers, and we demonstrated that MIRA was comparatively better than the other two classifiers. Our experimental results on two benchmark data sets show that the gazetteer features improved the performance of the NER models. With the proposed gazetteer features, the performance (F1-score) of the NER models built using MIRA, SVM, and CRF were increased by 14.72%, 15.95%, and 17.13%, respectively. There are not many open resources available to further the NER research in Telugu, and hence the two data sets along with language-dependent features have been made publicly available. We want to explore deep learning models using different word embeddings and state-of-the-art algorithms to build NER models in the future.
Author Contributions
Conceptualization, S.G., L.B.M.N. and A.M.; methodology, S.G.; software, S.G.; validation, L.B.M.N. and A.M.; formal analysis, S.G.; writing–original draft preparation, S.G.; writing–review and editing, L.B.M.N. and A.M.; supervision, L.B.M.N. and A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Grishman, R. The NYU System for MUC-6 or Where’s the Syntax? In Proceedings of the 6th Conference on Message Understanding. Association for Computational Linguistics, Center for Sprogteknologi, Copenhagen, Denmark, 5–9 August 1995; pp. 167–175. [Google Scholar]
- Guo, J.; Xu, G.; Cheng, X.; Li, H. Named Entity Recognition in Query. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in information retrieval, Boston, MA, USA, 19–23 July 2009; pp. 267–274. [Google Scholar]
- Benajiba, Y.; Diab, M.; Rosso, P. Arabic Named Entity Recognition: A Feature-Driven Study. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 926–934. [Google Scholar] [CrossRef]
- Babych, B.; Hartley, A. Improving Machine Translation Quality with Automatic Named Entity Recognition. In Proceedings of the 7th International EAMT Workshop on MT and Other Language Technology Tools, Improving MT through Other Language Technology Tools, Resource and Tools for Building MT at EACL, Budapest, Hungary, 12–17 April 2003; pp. 1–8. [Google Scholar]
- Hálek, O.; Rosa, R.; Tamchyna, A.; Bojar, O. Named entities from Wikipedia for machine translation. In Proceedings of the CEUR Workshop Proceedings 584, Horský hotel Kralova studna, Harmanec, Slovakia, 25–29 September 2011; pp. 23–30. [Google Scholar]
- Chen, Y.; Zong, C.; Su, K.Y. A joint model to identify and align bilingual named entities. Comput. Linguist. 2013, 39, 229–266. [Google Scholar] [CrossRef]
- Indurkhya, N.; Damerau, F.J. Handbook of Natural Language Processing, 2nd ed.; Chapman & Hall/CRC: London, NY, USA, 2010. [Google Scholar]
- Srihari, R.; Li, W. Information Extraction Supported Question Answering; Technical Report; Cymfony Net Inc.: Williamsville, NY, USA, 1999; pp. 1–13. [Google Scholar]
- Toral, A.; Noguera, E.; Llopis, F.; Muñoz, R. Improving Question Answering Using Named Entity Recognition. In Natural Language Processing and Information Systems; Springer: Berlin/Heidelberg, Germany, 2005; pp. 181–191. [Google Scholar]
- Mollá, D.; Van Zaanen, M.; Smith, D. Named Entity Recognition for Question Answering. In Proceedings of the Australasian Language Technology workshop, Sydney, Australia, 30 November–1 December 2006; pp. 51–58. [Google Scholar]
- Rodrigo, Á.; Pérez-Iglesias, J.; Peñas, A.; Garrido, G.; Araujo, L. Answering questions about European legislation. Expert Syst. Appl. 2013, 40, 5811–5816. [Google Scholar] [CrossRef]
- Nobata, C.; Sekine, S.; Isahara, H.; Grishman, R. Summarization System Integrated with Named Entity Tagging and IE pattern Discovery. In Proceedings of the European Language Resources Association (ELRA), Las Palmas, Canary Island, Spain, 29–31 May 2002; pp. 1–4. [Google Scholar]
- Hassel, M. Exploitation of named entities in automatic text summarization for swedish. In Proceedings of the NODALIDA’03–14th Nordic Conference on Computational Linguistics, Reykjavik, Iceland, 30–31 May 2003; pp. 9–16. [Google Scholar]
- Baralis, E.; Cagliero, L.; Jabeen, S.; Fiori, A.; Shah, S. Multi-document summarization based on the Yago ontology. Expert Syst. Appl. 2013, 40, 6976–6984. [Google Scholar] [CrossRef][Green Version]
- Mikheev, A.; Moens, M.; Grover, C. Named Entity Recognition Without Gazetteers. In Proceedings of the Ninth Conference on European Chapter of the Association for Computational, Association for Computational Linguistics, Bergen, Norway, 8–12 June 1999; pp. 1–8. [Google Scholar]
- Gerner, M.; Nenadic, G.; Bergman, C.M. LINNAEUS: A species name identification system for biomedical literature. Bmc Bioinform. 2010, 11, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Cucerzan, S.; Yarowsky, D. Language Independent Named Entity Recognition Combining Morphological and Contextual Evidence. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999; pp. 90–99. [Google Scholar]
- Bikel, D.M.; Schwartz, R.; Weischedel, R.M. An algorithm that learns what’s in a name. Mach. Learn. 1999, 34, 211–231. [Google Scholar] [CrossRef]
- Borthwick, A.; Sterling, J.; Agichtein, E.; Grishman, R. Exploiting diverse knowledge sources via maximum entropy in named entity recognition. In Proceedings of the Sixth Workshop on Very Large Corpora, Montreal, QC, Canada, 15–16 August 1998; pp. 152–160. [Google Scholar]
- Sekine, S.; Grishman, R.; Shinnou, H. A decision tree method for finding and classifying names in Japanese texts. In Proceedings of the Sixth Workshop on Very Large Corpora, Montreal, QC, Canada, 15–16 August 1998; pp. 171–178. [Google Scholar]
- McCallum, A.; Li, W. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL 2003-Volume 4: Association for Computational Linguistics, Edmonton, AB, Canada, 27 May–1 June 2003; pp. 188–191. [Google Scholar]
- Kazama, J.; Torisawa, K. A New Perceptron Algorithm for Sequence Labeling with Non-Local Features. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 315–324. [Google Scholar]
- Mohit, B.; Hwa, R. Syntax-based Semi-Supervised Named Entity Tagging. In Proceedings of the ACL Interactive Poster and Demonstration Sessions. Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 57–60. [Google Scholar]
- Isozaki, H.; Kazawa, H. Efficient support vector classifiers for named entity recognition. In Proceedings of the 19th International Conference on Computational Linguistics-Volume 1: Association for Computational Linguistics, Taipei, Taiwan, 26–30 August 2002; pp. 1–7. [Google Scholar]
- Collins, M.; Singer, Y. Unsupervised models for named entity classification. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999; pp. 100–110. [Google Scholar]
- Nadeau, D. Semi-supervised named entity recognition: Learning to recognize 100 entity types with little supervision. Ph.D. Thesis, University of Ottawa, Ottawa, ON, Canada, 2007. [Google Scholar]
- List of Languages by Number of Native Speakers in India. Available online: https://en.wikipedia.org/wiki/List_of_languages_by_number_of_native_speakers_in_India (accessed on 20 January 2020).
- Shishtla, P.; Gali, K.; Pingali, P.; Varma, V. Experiments in Telugu NER: A Conditional Random Field Approach. In Proceedings of the Third International Joint Conference on Natural Language Processing, IJCNLP, Hyderabad, India, 7–12 January 2008; pp. 105–110. [Google Scholar]
- Das, A.; Garain, U. CRF-Based Named Entity Recognition @ICON 2013. arXiv 2014, arXiv:1409.8008. [Google Scholar]
- Saha, S.; Ekbal, A. Combining Multiple Classifiers Using Vote Based Classifier Ensemble Technique for Named Entity Recognition. Data Knowl. Eng. 2013, 85, 15–39. [Google Scholar] [CrossRef]
- Ekbal, A.; Saha, S. A Multiobjective Simulated Annealing Approach for Classifier Ensemble: Named Entity Recognition in Indian Languages As Case Studies. Expert Syst. Appl. 2011, 38, 14760–14772. [Google Scholar] [CrossRef]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticae Investig. 2007, 30, 3–26. [Google Scholar]
- Srikanth, P.; Murthy, K.N. Named Entity Recognition for Telugu. In Proceedings of the Third International Joint Conference on Natural Language Processing, IJCNLP, Hyderabad, India, 7–12 January2008; pp. 41–50. [Google Scholar]
- Ciravegna, F.; Chapman, S.; Dingli, A.; Wilks, Y. Learning to harvest information for the semantic web. In European Semantic Web Symposium; Springer: Berlin/Heidelberg, Germany, 2004; pp. 312–326. [Google Scholar]
- Gorla, S.; Murthy, N.L.B.; Malapati, A. A Comparative Study of Named Entity Recognition for Telugu. In Proceedings of the 9th Annual Meeting of the Forum for Information Retrieval Evaluation, Gandhinagar, India, 6–9 December 2017; pp. 21–24. [Google Scholar]
- Gorla, S.; Velivelli, S.; Murthy, N.B.; Malapati, A. Named Entity Recognition for Telugu News Articles using Naïve Bayes Classifier. In Proceedings of the Second International Workshop on Recent Trends in News Information Retrieval co-located with 40th European Conference on Information Retrieval(ECIR), Grenoble, France, 26 March 2018; pp. 33–38. [Google Scholar]
- Gorla, S.; Chandrashekhar, A.; Bhanu Murthy, N.L.; Malapati, A. TelNEClus: Telugu Named Entity Clustering Using Semantic Similarity. In Proceedings of the International Conference on Computational Intelligence: Theories, Applications and Future Directions, Indian Institute of Technology Kanpur, India, 6–8 December 2019; Springer: Singapore, 2019; Volume II, pp. 39–52. [Google Scholar]
- Li, W.; McCallum, A. Rapid Development of Hindi Named Entity Recognition Using Conditional Random Fields and Feature Induction. ACM Transactions on Asian Language Information Processing (TALIP); Association for Computing Machinery: New York, NY, USA, 2003; pp. 290–294. [Google Scholar]
- Saha, S.K.; Sarkar, S.; Mitra, P. A hybrid feature set based maximum entropy Hindi named entity recognition. In Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-I, Hyderabad, India, 12 January 2008; pp. 343–349. [Google Scholar]
- Saha, S.K.; Narayan, S.; Sarkar, S.; Mitra, P. A composite kernel for named entity recognition. Pattern Recognit. Lett. 2010, 31, 1591–1597. [Google Scholar] [CrossRef]
- Ekbal, A.; Bandyopadhyay, S. Bengali named entity recognition using support vector machine. In Proceedings of the IJCNLP-08 Workshop on Named Entity Recognition for South and South East Asian Languages, Hyderabad, India, 12 January 2008; pp. 51–58. [Google Scholar]
- Ekbal, A.; Bandyopadhyay, S. Named entity recognition using support vector machine: A language independent approach. Int. J. Electr. Comput. Syst. Eng. 2010, 4, 155–170. [Google Scholar]
- Ekbal, A.; Bandyopadhyay, S. A conditional random field approach for named entity recognition in Bengali and Hindi. Linguist. Issues Lang. Technol. 2009, 2, 1–44. [Google Scholar]
- Banerjee, S.; Naskar, S.K.; Bandyopadhyay, S. Bengali named entity recognition using margin infused relaxed algorithm. In Proceedings of the International Conference on Text, Speech, and Dialogue, Brno, Czech Republic, 8–12 September 2014; pp. 125–132. [Google Scholar]
- Vijayakrishna, R.; Sobha, L. Domain Focused Named Entity Recognizer for Tamil Using Conditional Random Fields. In Proceedings of the IJCNLP-08 Workshop on Named Entity Recognition for South and South East Asian Languages, Hyderabad, India, 12 January 2008; pp. 59–66. [Google Scholar]
- Abinaya, N.; Kumar, M.A.; Soman, K. Randomized kernel approach for named entity recognition in Tamil. Indian J. Sci. Technol. 2015, 8, 1–7. [Google Scholar] [CrossRef]
- Krishnamurti, B.; Gwynn, J.P.L. A Grammar of Modern Telugu; Oxford University Press: New York, NY, USA, 1985. [Google Scholar]
- Robert, C. Machine Learning, a Probabilistic Perspective; MIT Press: Cambridge, CA, USA, 2014. [Google Scholar]
- Reddy, S.; Sharoff, S. Cross language POS taggers (and other tools) for Indian languages: An experiment with Kannada using Telugu resources. In Proceedings of the Fifth International Workshop On Cross Lingual Information Access, Chiang Mai, Thailand, 8–12 November 2011; pp. 11–19. [Google Scholar]
- Kumar, G.B.; Murthy, K.N.; Chaudhuri, B. Statistical Analyses of Telugu Text Corpora. Int. J. Dravid. Lang. 2007, 36, 1–20. [Google Scholar]
- Gorla, S.; Velivelli, S.; Satpathi, D.K.; Murthy, N.L.B.; Malapati, A. Named Entity Recognition Using Part-of-Speech Rules for Telugu. In Smart Computing Paradigms: New Progresses and Challenges; Springer: Singapore, 2020; pp. 147–157. [Google Scholar]
- Zesch, T.; Gurevych, I.; Mühlhäuser, M. Analyzing and accessing Wikipedia as a lexical semantic resource. In Data Structures for Linguistic Resources and Applications; Gunter Narr: Tübingen, Germany, 2007; pp. 197–205. [Google Scholar]
- Zhang, Z.; Iria, J. A Novel Approach to Automatic Gazetteer Generation using Wikipedia. In Proceedings of the 2009 Workshop on The People’s Web Meets NLP: Collaboratively Constructed Semantic Resources (People’s Web), Suntec, Singapore, 7 August 2009; Association for Computational Linguistics: Suntec, Singapore, 2009; pp. 1–9. [Google Scholar]
- Attia, M.; Toral, A.; Tounsi, L.; Monachini, M.; van Genabith, J. An Automatically Built Named Entity Lexicon for Arabic. In Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC’10), Valletta, Malta, 17–23 May 2010; European Language Resources Association (ELRA): Valletta, Malta, 2010; pp. 3614–3621. [Google Scholar]
- Crammer, K.; Singer, Y. Ultraconservative online algorithms for multiclass problems. J. Mach. Learn. Res. 2003, 3, 951–991. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).