Genetic Algorithm-Based Optimization of Offloading and Resource Allocation in Mobile-Edge Computing


Abstract
1. Introduction
- We solve the problem of minimizing the overall completion time in the scenario of multiple mobile devices and the one edge server, as well as the UD’s task, which can be divided proportionally. We also propose a joint optimization algorithm for users’ task partly offloading and resource allocation to solve the problem to solve the problem.
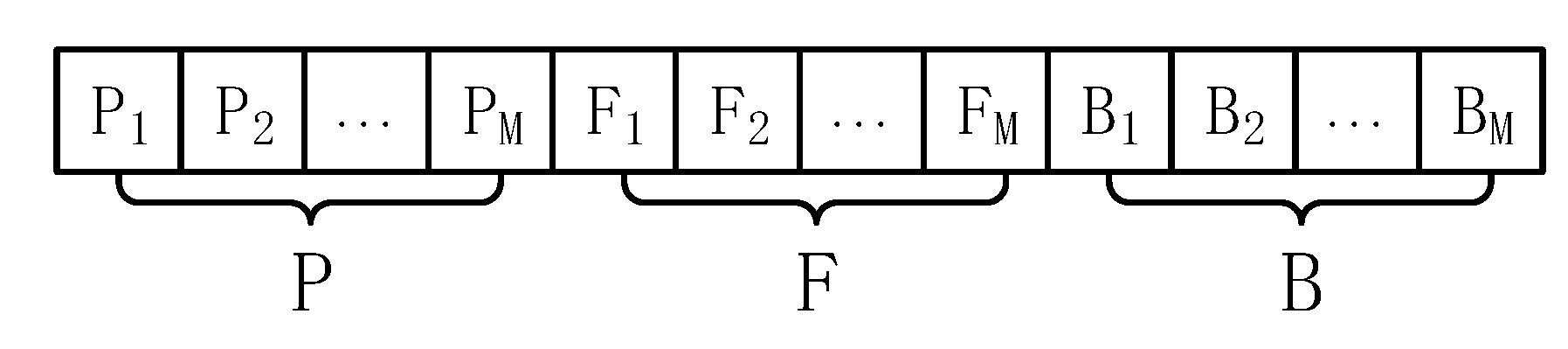
- We propose a joint optimization algorithm of offloading and resource allocation based on the Genetic Algorithm (GA) under the partial offloading task model. A strategy combination composed of the user’s offloading proportion, bandwidth, and computing resources is an individual, and each factor in the individual is a gene. Then, different individuals are combined into a population matrix, and the optimal user’s offloading proportion and resource allocation combination is finally obtained through selection, crossover, and mutation operations.
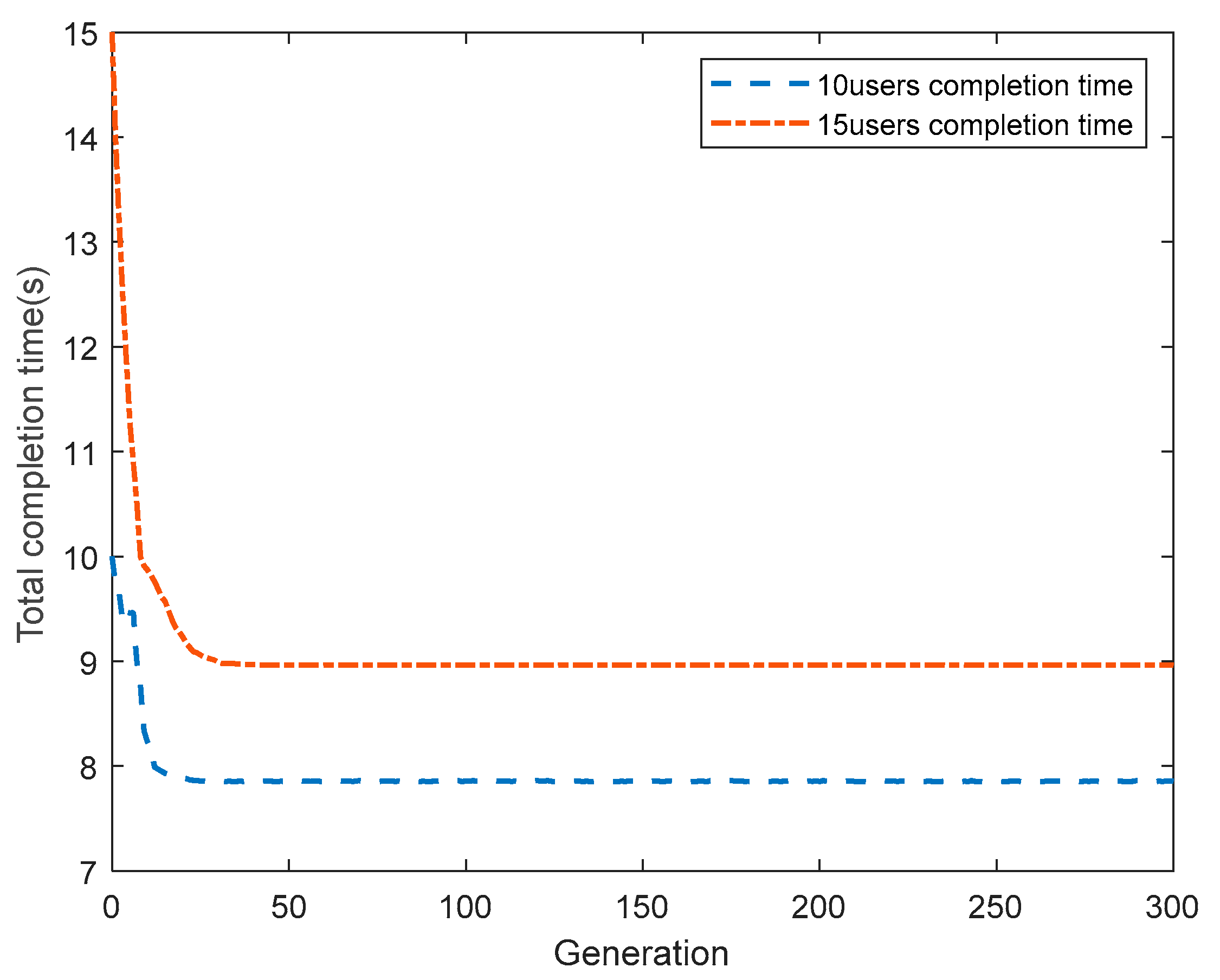
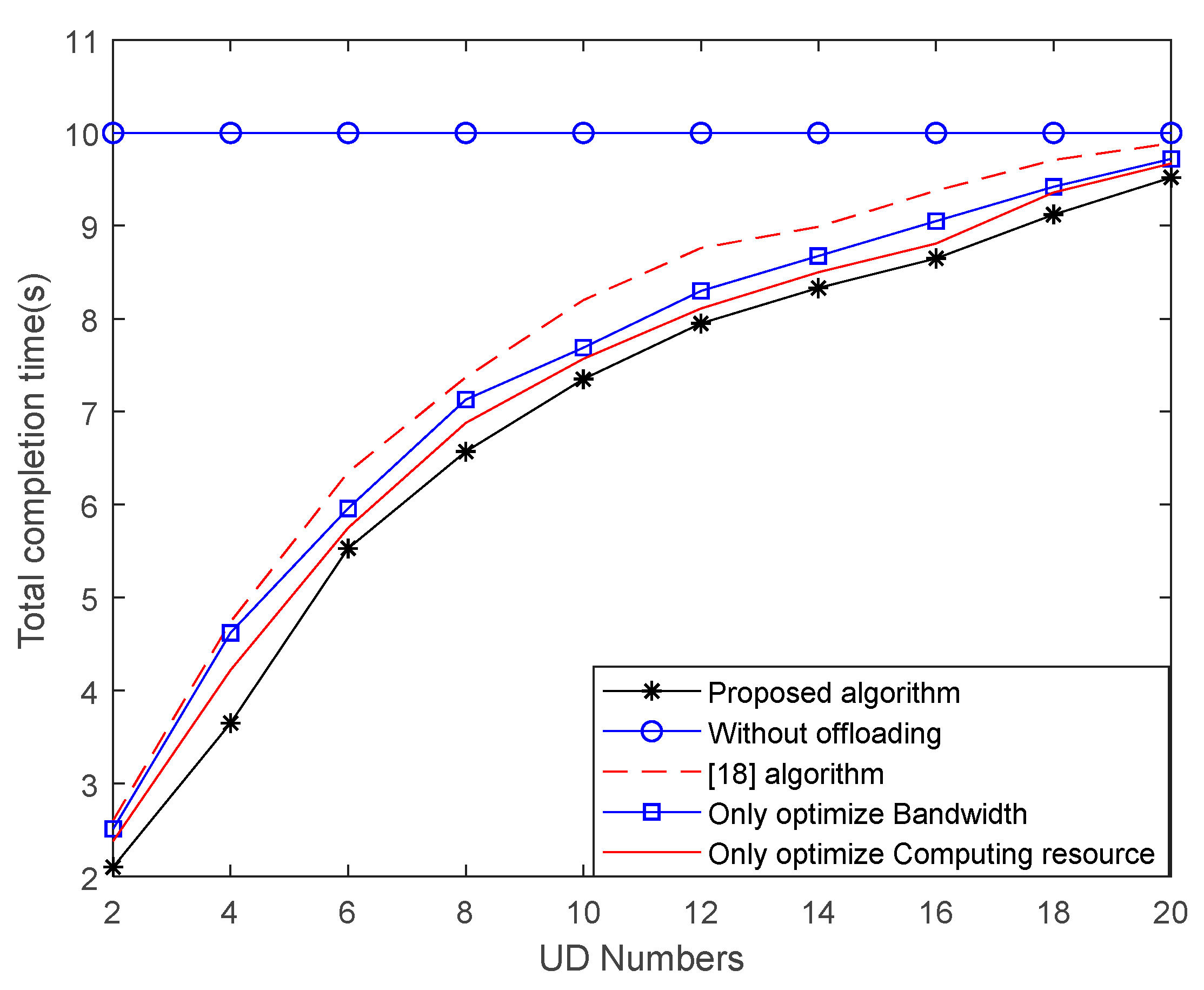
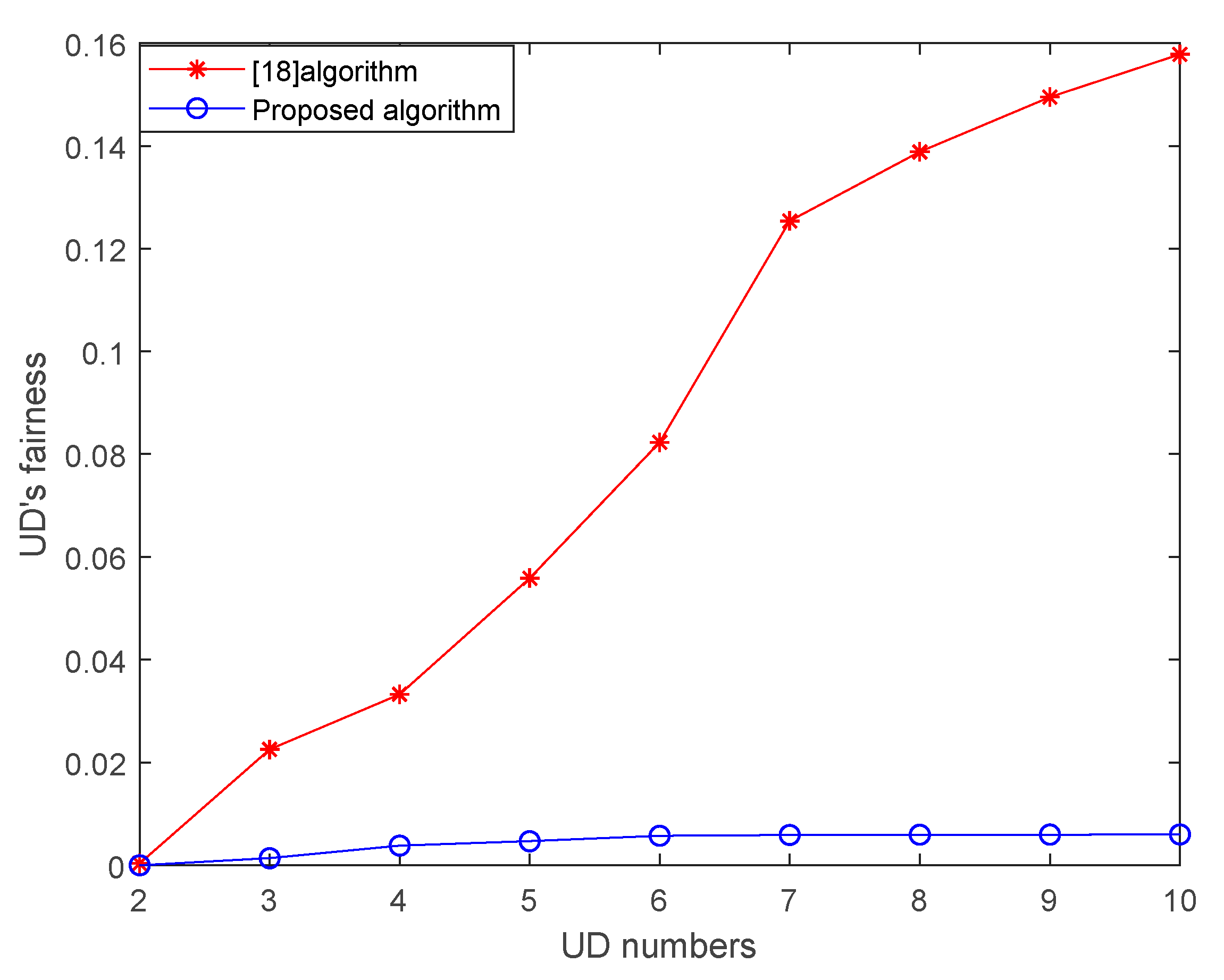
- Simulation results demonstrate that our proposed algorithm can effectively shorten the completion time and guarantee fairness among users. For example, when the UD’s number is 10, the total completion time in this paper is 12.1% lower than that in literature [18].
2. System Model
3. Algorithm Formulation
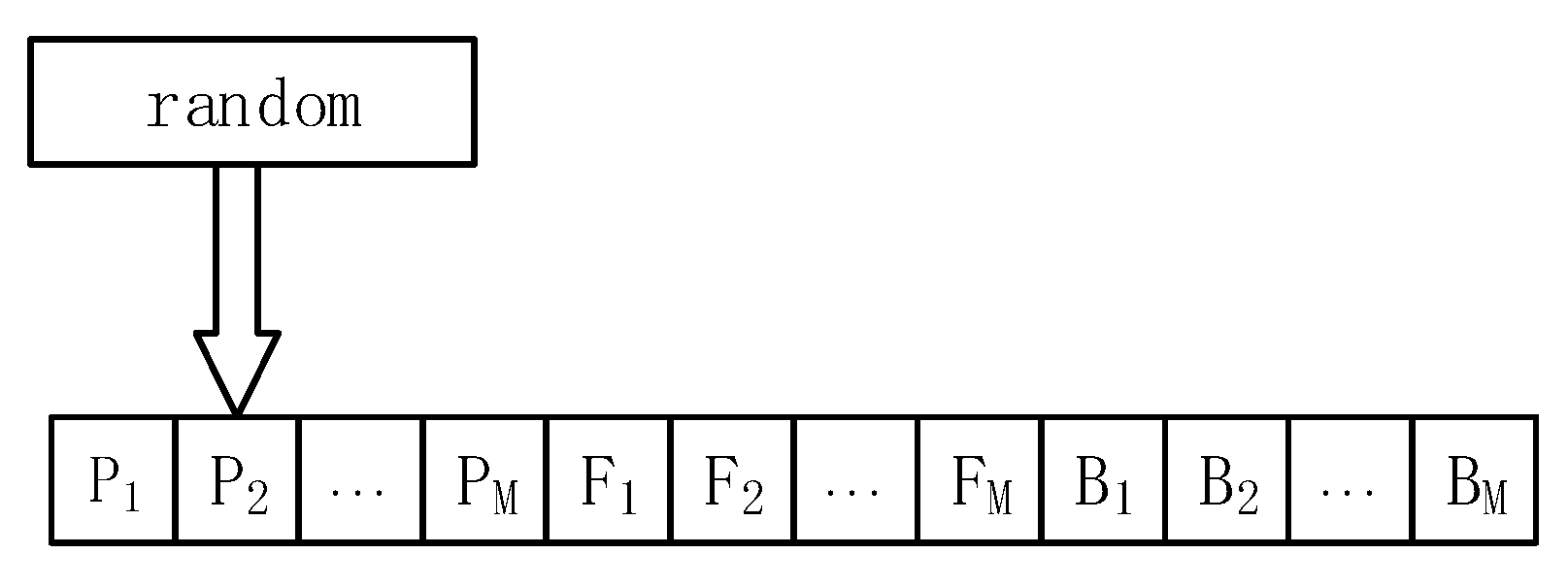
3.1. Population Formation and Optimal Individual Selection
| Algorithm 1 Optimal individual selection |
| 1. Input: , , , . 2. For : 3. For: 4. ; 5. ; 6. ; 7. End 8. ; 9. End 10. ... 11. Generate a random number ([0, 1]). Calculate where x is in . Select the individuals to whom the scope belongs. 12. Output: |
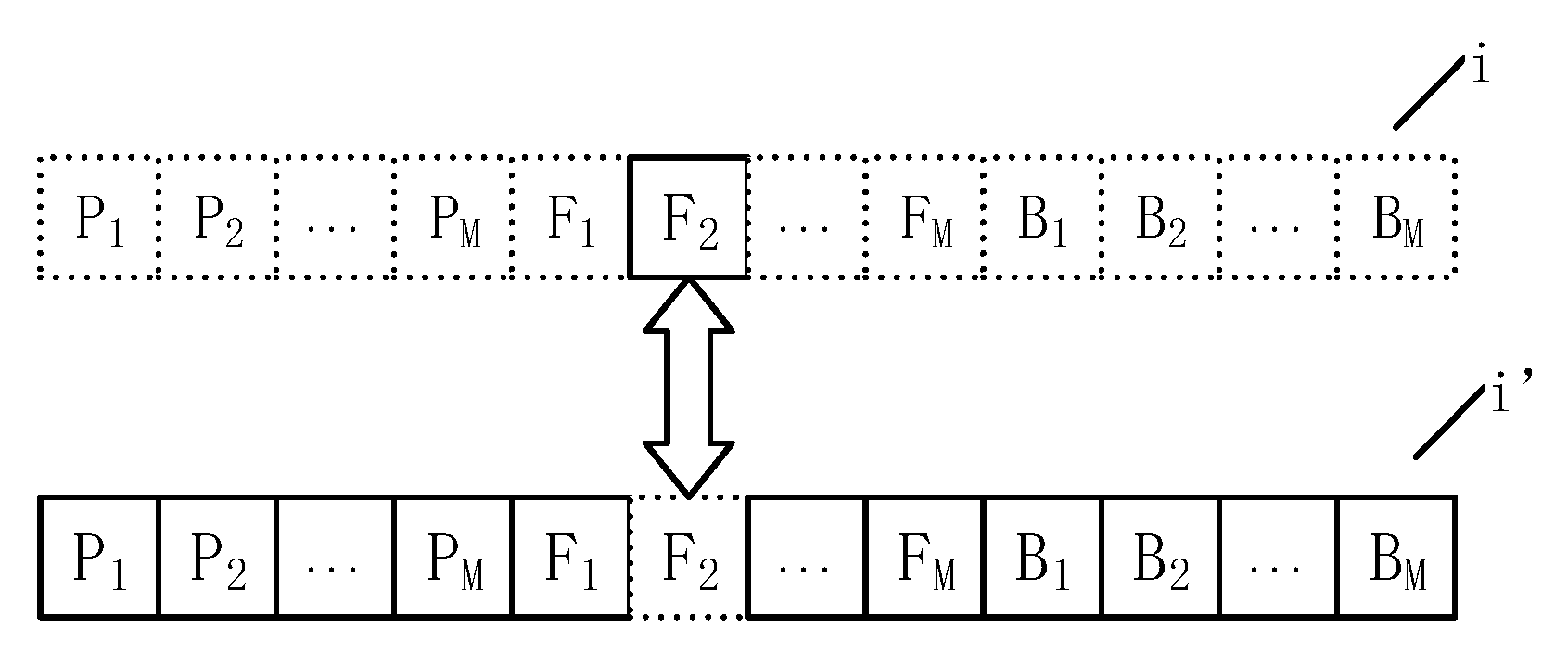
3.2. Crossover and Mutation operation
| Algorithm 2 Crossover and mutation |
|
3.3. Algorithm Overview
| Algorithm 3 A joint optimization algorithm of offloading and resource allocation |
| 1. Input , ,,,. 2. Randomly generate a 3 row 3∗M column matrix 3. For : 4. Randomly generate a row 3∗M column matrix 5. Replace the first 3 lines of with 6. Do Algorithm 1 and Algorithm 2 on . Get ,,. 7. 8. If : 9. break; 10. Else: 11. If : 12. ; 13. End 14. Output: ; |
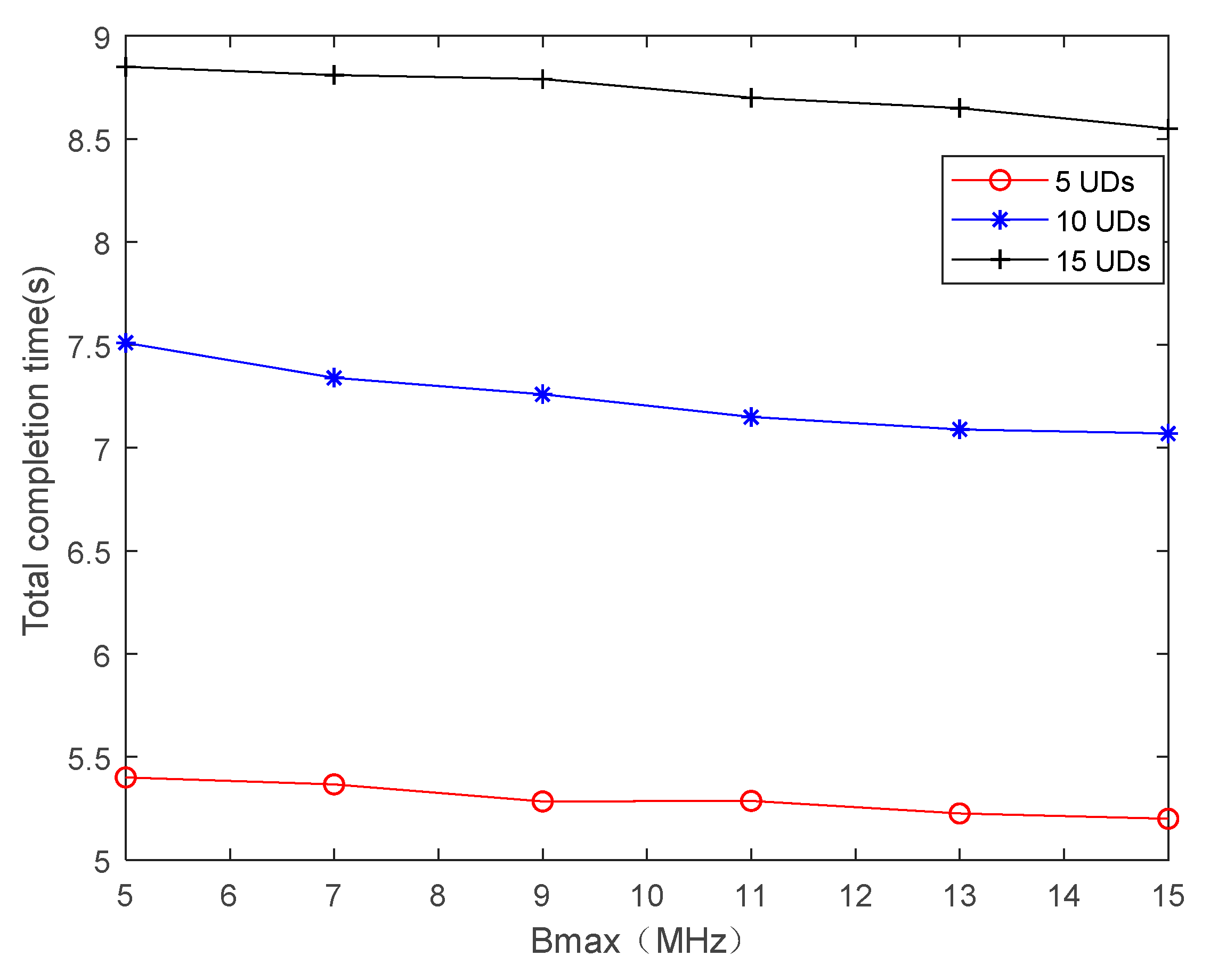
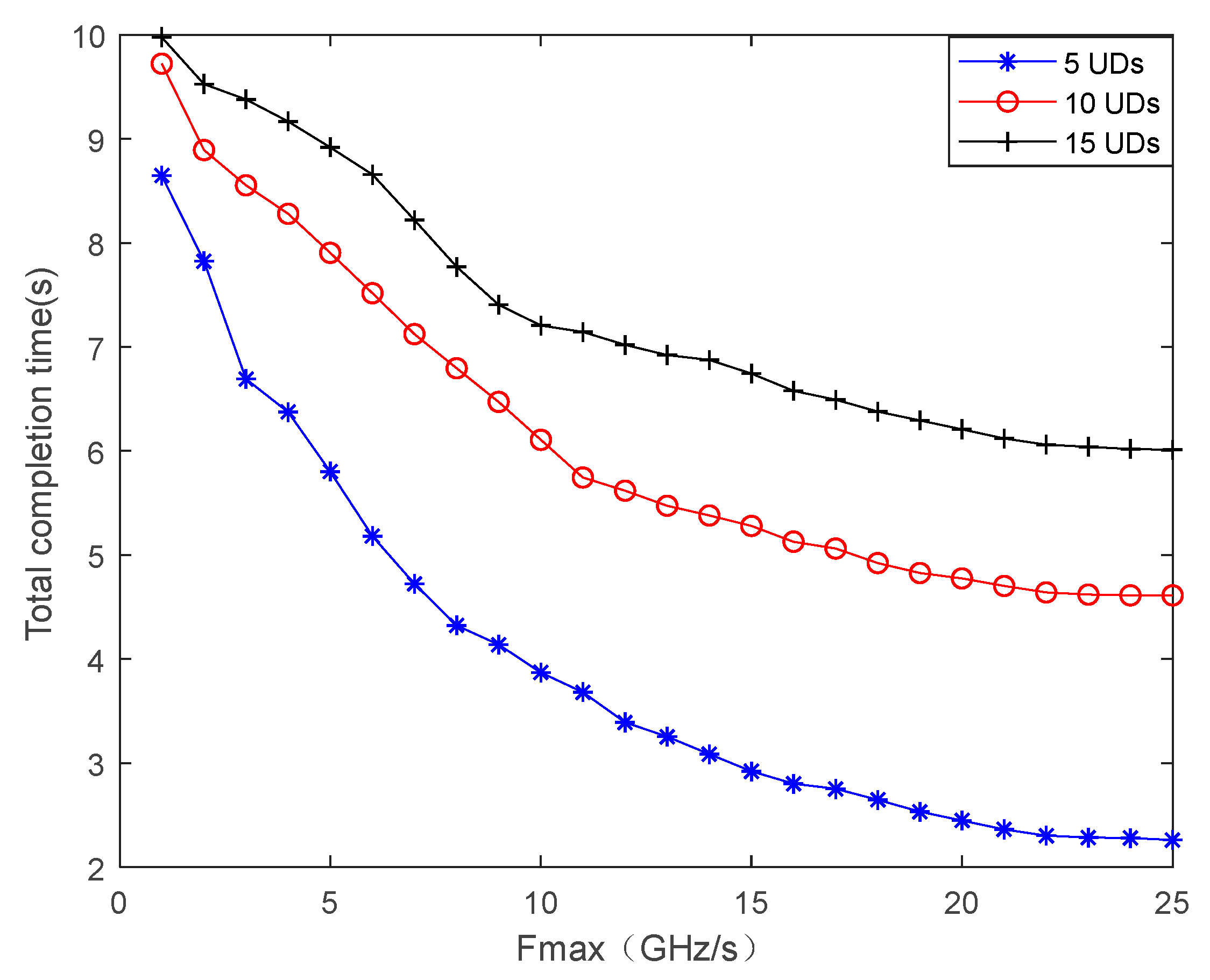
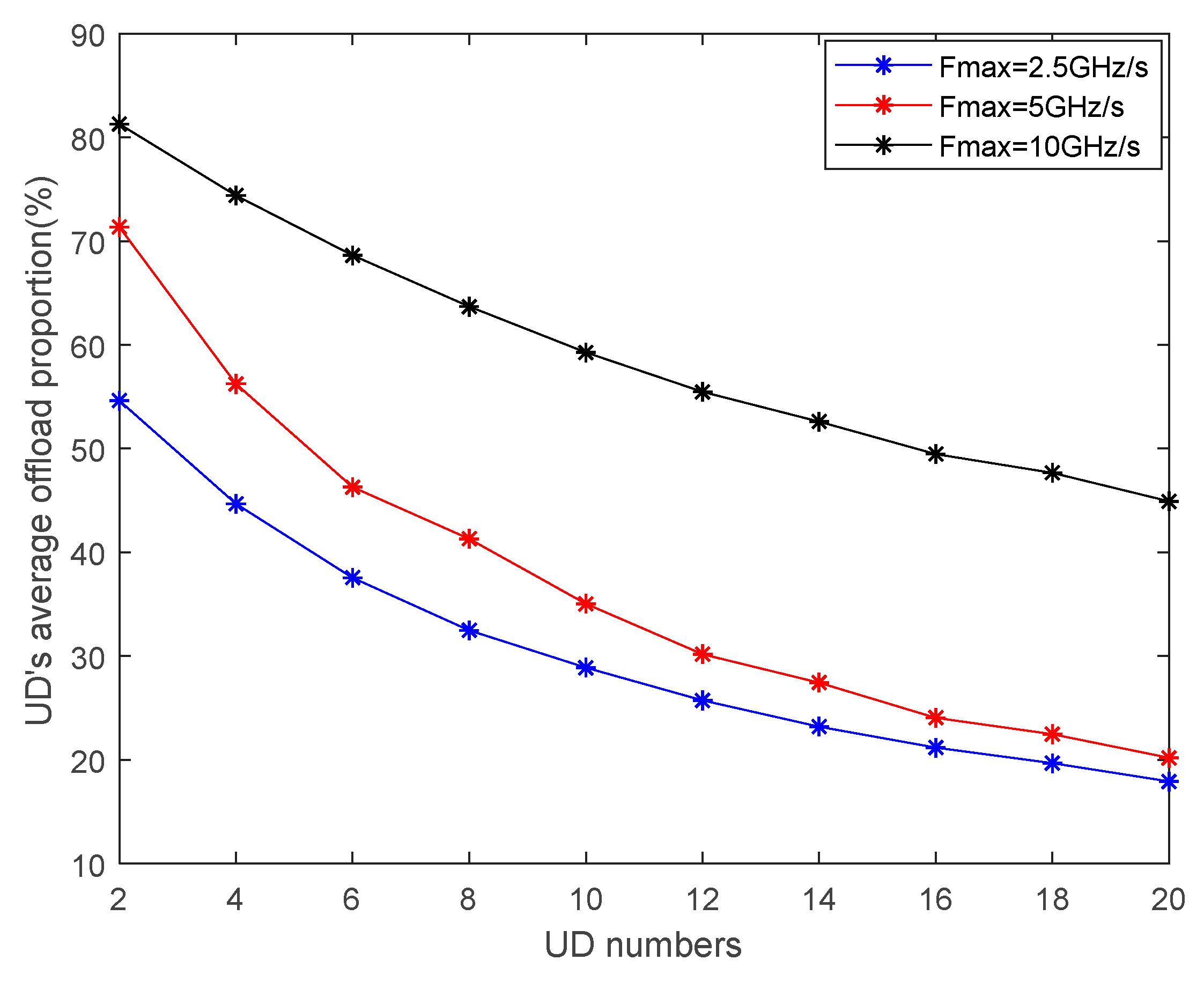
4. Simulation Results and Discussions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2017, 5, 1–12. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, X.; Zhang, Y.; Wang, L.; Yang, J.; Wang, W. A Survey on Mobile Edge Networks: Convergence of Computing, Caching and Communications. IEEE Access 2017, 5, 6757–6779. [Google Scholar] [CrossRef]
- Xu, X.; Liu, J.; Tao, X. Mobile Edge Computing Enhanced Adaptive Bitrate Video Delivery with Joint Cache and Radio Resource Allocation. IEEE Access 2017, 5, 16406–16415. [Google Scholar] [CrossRef]
- Hong, Q.L.; Al-Shatri, H.; Klein, A. Optimal Joint Power Allocation and Task Splitting in Wireless Distributed Computing. In Proceedings of the 11th International ITG Conference on Systems, Communications and Coding, Hamburg, Germany, 6–9 February 2017. [Google Scholar]
- Chen, M.H.; Liang, B.; Min, D. Joint offloading decision and resource allocation for multi-user multi-task mobile cloud. In Proceedings of the IEEE International Conference on Communications, Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Li, L.; Zhang, X.; Liu, K.; Jiang, F.; Peng, J. An Energy-Aware Task Offloading Mechanism in Multiuser Mobile-Edge Cloud Computing. Mob. Inf. Syst. 2018, 18, 1–12. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Xu, C. Decentralized Computation Offloading Game for Mobile Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 974–983. [Google Scholar]
- Zhao, H.; Wang, Y.; Sun, R. Task Proactive Caching Based Computation Offloading and Resource Allocation in Mobile-Edge Computing Systems. In Proceedings of the 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 232–237. [Google Scholar]
- Liu, K.; Peng, J.; Li, H.; Zhang, X.; Liu, W. Multi-device task offloading with time-constraints for energy efficiency in mobile cloud computing. Future Gener. Comput. Syst. 2016, 64, 1–14. [Google Scholar] [CrossRef]
- Cardellini, V.; Personé, V.D.; Di Valerio, V.; Facchinei, F.; Grassi, V.; Presti, F.L.; Piccialli, V. A game-theoretic approach to computation offloading in mobile cloud computing. Math. Program. 2015, 157, 421–449. [Google Scholar] [CrossRef]
- Yu, S.; Langar, R.; Fu, X.; Wang, L.; Han, Z. Computation Offloading With Data Caching Enhancement for Mobile Edge Computing. IEEE Trans. Veh. Technol. 2018, 67, 11098–11112. [Google Scholar] [CrossRef]
- Yi, C.; Cai, J.; Su, Z. A Multi-User Mobile Computation Offloading and Transmission Scheduling Mechanism for Delay-Sensitive Applications. IEEE Trans. Mob. Comput. 2019, 19, 29–43. [Google Scholar] [CrossRef]
- You, C.; Huang, K.; Chae, H. Energy Efficient Mobile Cloud Computing Powered by Wireless Energy Transfer. IEEE J. Sel. Areas in Commun. 2016, 34, 1757–1771. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation Rate Maximization for Wireless Powered Mobile-Edge Computing with Binary Computation Offloading. IEEE Trans. Wirel. Commun. 2017, 17, 4177–4190. [Google Scholar] [CrossRef]
- Meng, S.; Wang, Y.; Miao, Z.; Sun, K. Joint optimization of wireless bandwidth and computing resource in cloudlet-based mobile cloud computing environment. Peer-to-Peer Netw. Appl. 2018, 11, 462–472. [Google Scholar] [CrossRef]
- Xing, H.; Liu, L.; Xu, J.; Nallanathan, A. Joint Task Assignment and Resource Allocation for D2D-Enabled Mobile-Edge Computing. IEEE Trans. Commun. 2019, 67, 4193–4207. [Google Scholar] [CrossRef]
- Nowak, D.; Mahn, T.; Al-Shatri, H.; Schwartz, A.; Klein, A. A Generalized Nash Game for Mobile Edge Computation Offloading. In Proceedings of the 6th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (Mobile Cloud), Bamberg, Germany, 26–29 March 2018. [Google Scholar]
- Prékopa, A. On logarithmic concave measures and functions. Acta Sci. Math. 1973, 34, 335–343. [Google Scholar]
- Galletly, J. Evolutionary Algorithms in Theory and Practice: Evolution Strategies, Evolutionary Programming, Genetic Algorithms; Oxford University Press: New York, NY, USA, 1999. [Google Scholar]
- Morris, G.M.; Goodsell, D.S.; Halliday, R.S.; Huey, R.; Hart, W.E.; Belew, R.K.; Olson, A.J. Automated docking using a Lamarckian genetic algorithm and an empirical binding free energy function. J. Comput. Chem. 2015, 19, 1639–1662. [Google Scholar] [CrossRef]
- Al-Kanj, L.; Poor, H.V.; Dawy, Z. Optimal Cellular Offloading via Device-to-Device Communication Networks with Fairness Constraints. IEEE Trans. Wirel. Commun. 2014, 13, 4628–4643. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| MES computational resource | {2.5, 5, 10, 15} GHz/s |
| Channel bandwidth | [10, 20] MHz |
| Data task | [8, 12] MB |
| Needed cpu cycles to calculate 1 bit task | 1000 cycles/byte |
| 0.001 | |
| UD’s local computational capacity | [0.8, 1.2] GHz/s |
| 4 * 3 * M | |
| UD numbers | [2, 30] |
| [5, 25] dB |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhu, Q. Genetic Algorithm-Based Optimization of Offloading and Resource Allocation in Mobile-Edge Computing. Information 2020, 11, 83. https://doi.org/10.3390/info11020083
Li Z, Zhu Q. Genetic Algorithm-Based Optimization of Offloading and Resource Allocation in Mobile-Edge Computing. Information. 2020; 11(2):83. https://doi.org/10.3390/info11020083
Chicago/Turabian StyleLi, Zhi, and Qi Zhu. 2020. "Genetic Algorithm-Based Optimization of Offloading and Resource Allocation in Mobile-Edge Computing" Information 11, no. 2: 83. https://doi.org/10.3390/info11020083
APA StyleLi, Z., & Zhu, Q. (2020). Genetic Algorithm-Based Optimization of Offloading and Resource Allocation in Mobile-Edge Computing. Information, 11(2), 83. https://doi.org/10.3390/info11020083