Improving Intrusion Detection Model Prediction by Threshold Adaptation


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
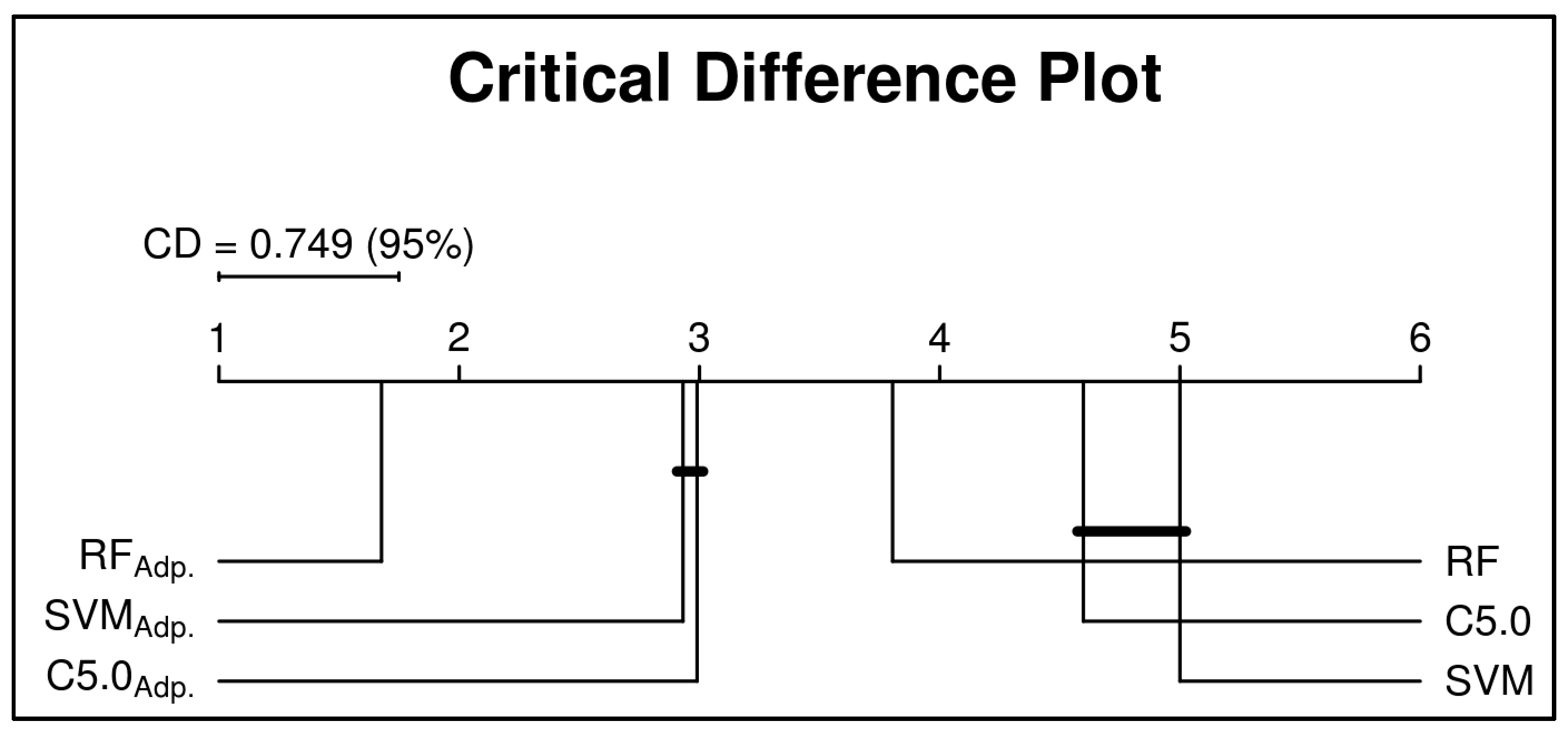{kind=link}
{kind=link}
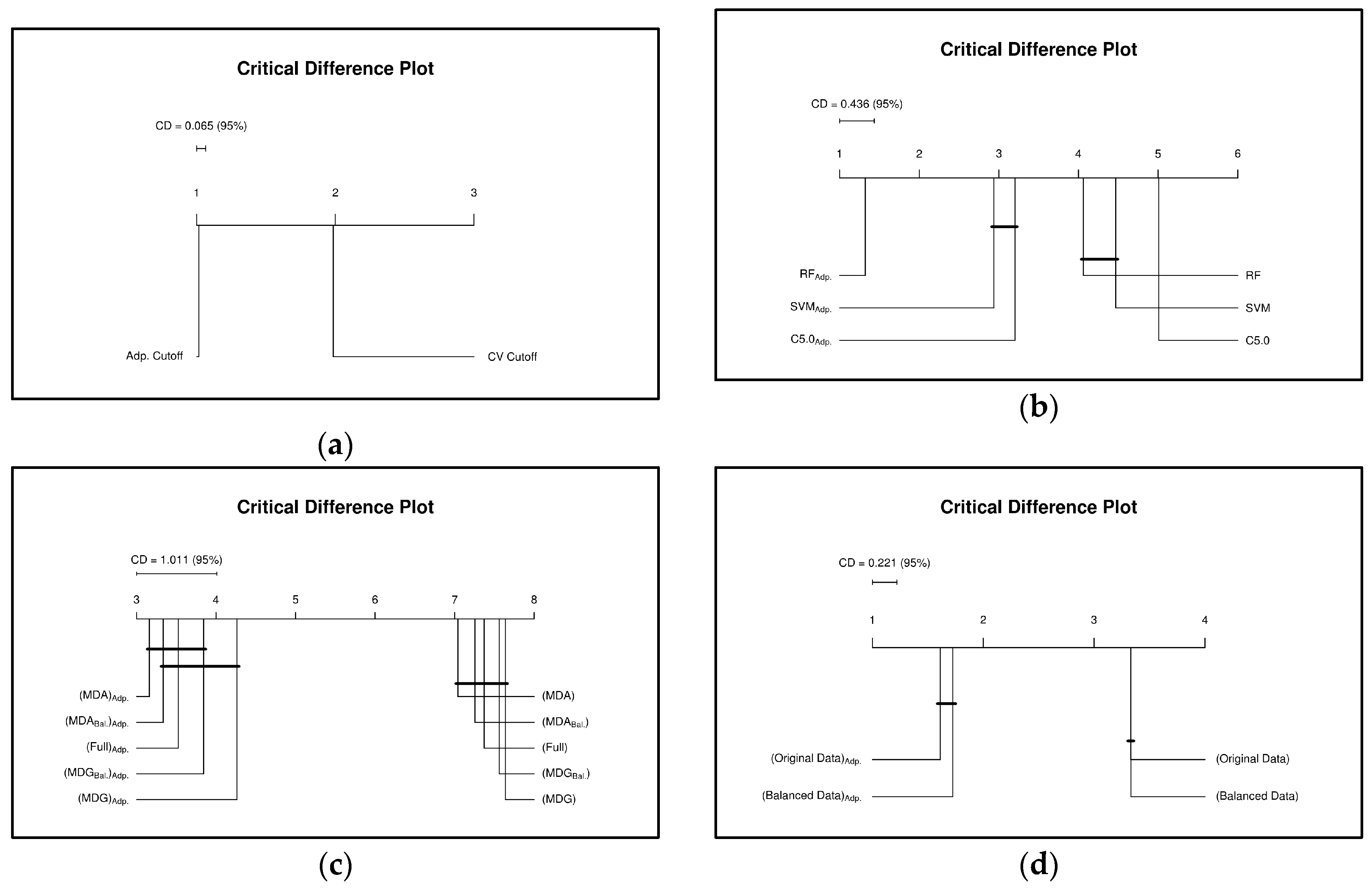{kind=link}
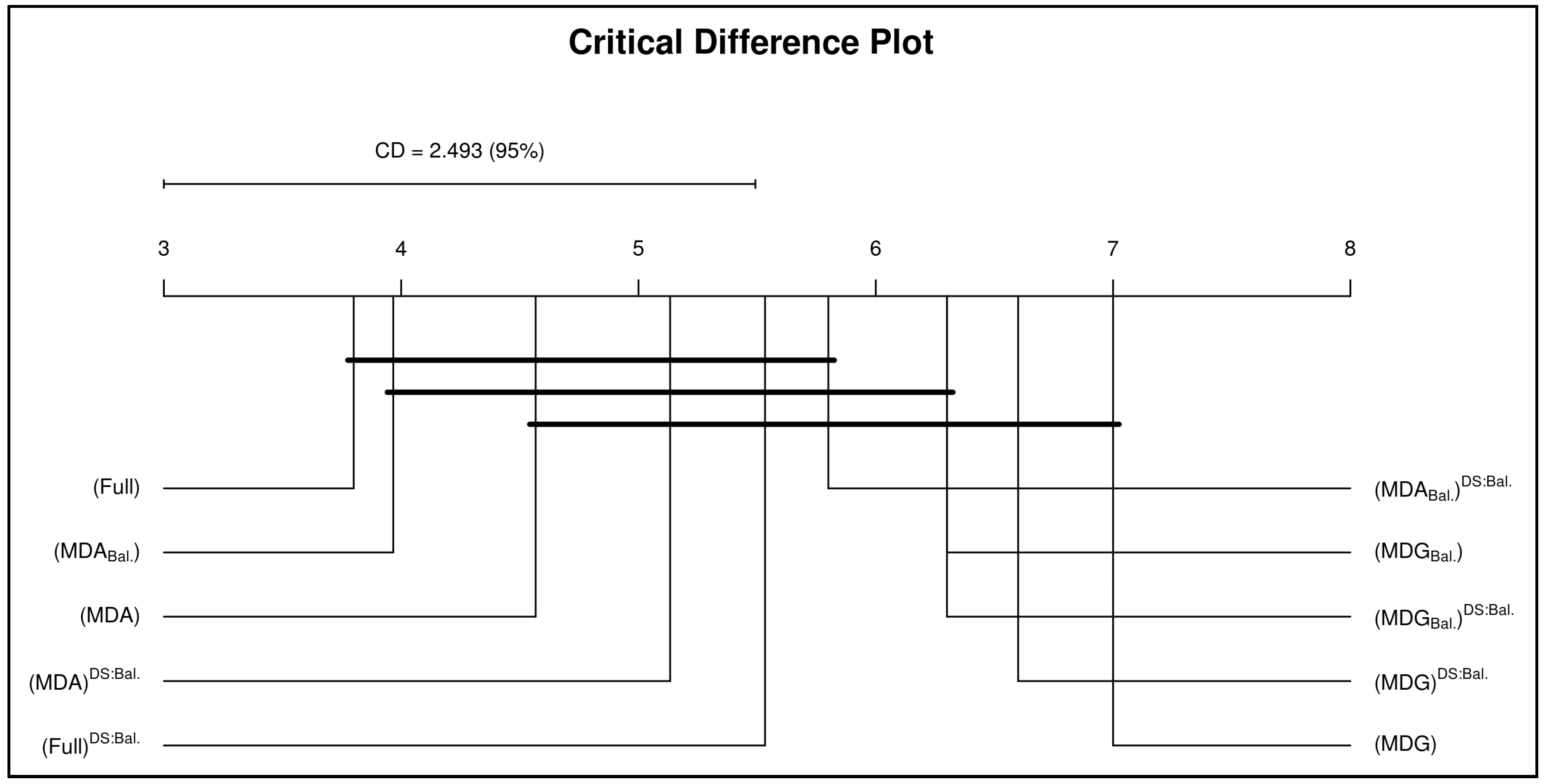{kind=link}
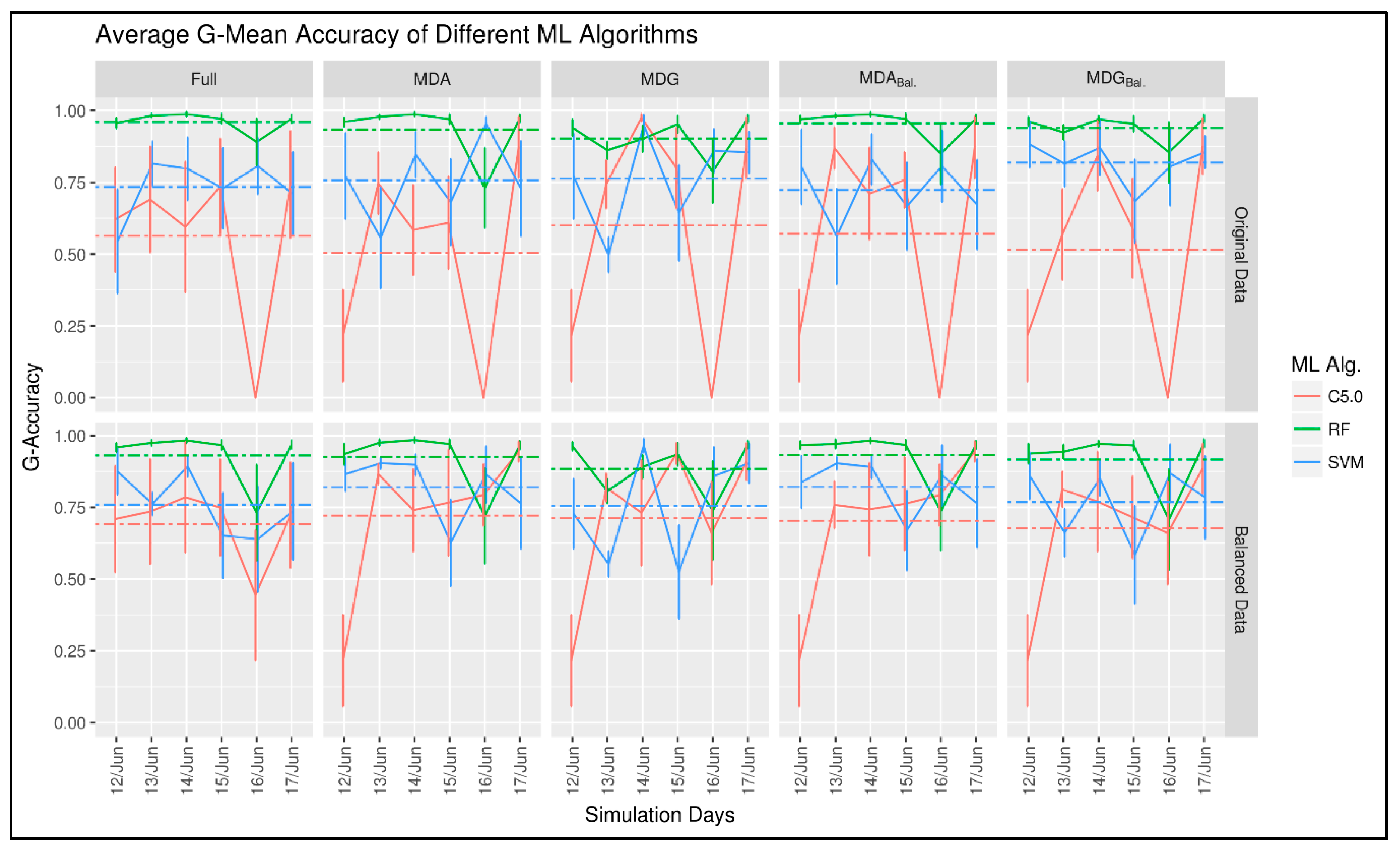{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Share and Cite
Al Tobi, A.M.; Duncan, I. Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information 2019, 10, 159. https://doi.org/10.3390/info10050159
Al Tobi AM, Duncan I. Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information. 2019; 10(5):159. https://doi.org/10.3390/info10050159
Chicago/Turabian StyleAl Tobi, Amjad M., and Ishbel Duncan. 2019. "Improving Intrusion Detection Model Prediction by Threshold Adaptation" Information 10, no. 5: 159. https://doi.org/10.3390/info10050159
APA StyleAl Tobi, A. M., & Duncan, I. (2019). Improving Intrusion Detection Model Prediction by Threshold Adaptation. Information, 10(5), 159. https://doi.org/10.3390/info10050159