An Interval Pythagorean Fuzzy Multi-criteria Decision Making Method Based on Similarity Measures and Connection Numbers



Abstract
:1. Introduction
2. Preliminaries
2.1. Concepts of PFS and IPFS
- (1)
- If , then .
- (2)
- If , then, the following are true.
- (a)
- If , then ;
- (b)
- If , then ;
- (c)
- If , then .
2.2. Interval Number
- (O1)
- ;
- (O2)
- ;
- (O3)
- ,where , and ;
- (O4)
- , .
2.3. Connection Number
- (I)
- If and , then ;
- (II)
- If and , then ;
- (III)
- If , then ;
- (V)
- If and , then .
- (C1)
- if , then ;
- (C2)
- if , then,
- if , then ;
- if , then .
3. Similarity Measures Between IPFSs
- (P1) ; (P2) if ; (P3) ;
- (P4) and if for a set .
- (P1); (P2)if; (P3);
- (P4)andiffor an IPFS.
- (P1); (P2)if; (P3);
- (P4)andiffor an, whereandare the weights of two elements (i.e., membership and non-membership) in an IPFS and. Especially, when, Equation (7) reduces to Equation (3).
- (P1); (P2)if; (P3);
- (P4)andiffor an, whereandare the weights of two elements (i.e., membership and non-membership, respectively) in an IPFS and. Especially, when, Equation (8) reduces to Equation (7).
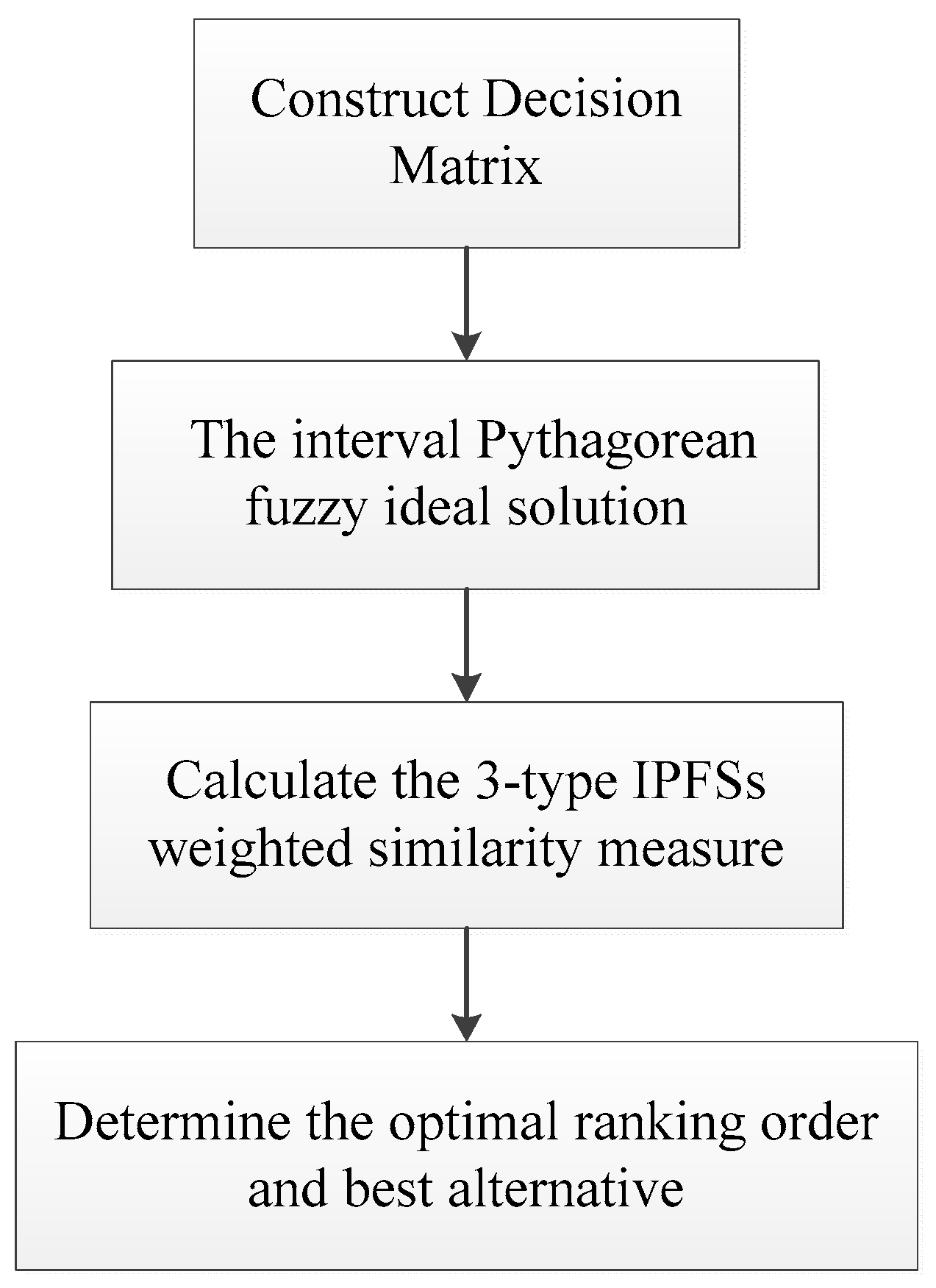
4. Decision-making Method Using the Proposed Similarity Measures
5. Practical Example
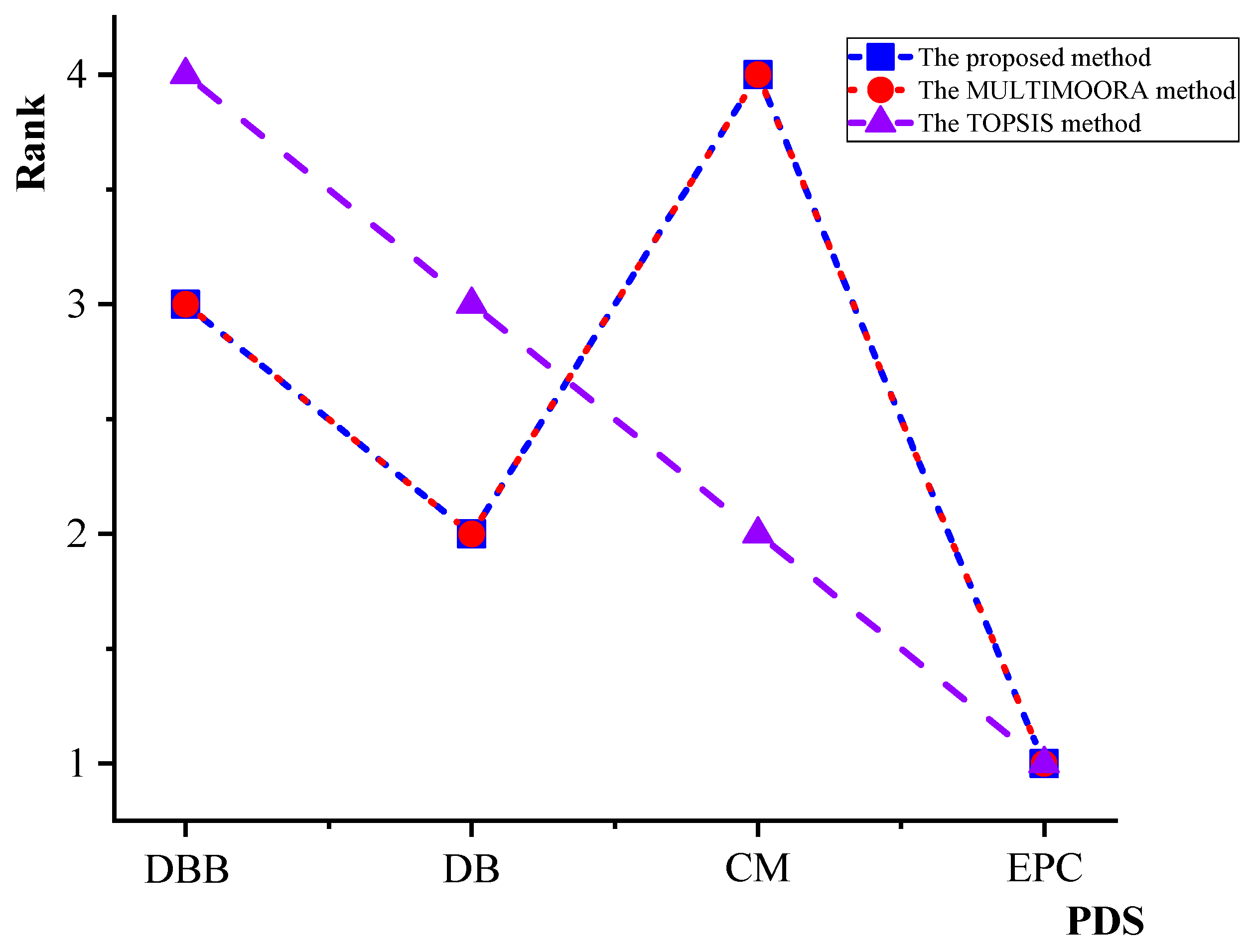
6. Comparison Analysis and Discussion
- (1)
- Calculating the interval number is one of the difficulties when using the interval Pythagorean fuzzy set, although there are many methods to deal with it. This research gives a valuable and easy solution to calculate the interval number by transforming the interval number to the connection number, at the same time reducing the loss of information.
- (2)
- The similarity measure is an important tool to judge the degree between the ideal alternative and the proposal alternative. However, the existing similarity measures under interval Pythagorean fuzzy settings are generally complex due to the tedious operation of the Pythagorean fuzzy setting, which restricts the practical application of IPFS. The proposed similarity measures based on minimum and maximum operators are simple and easy in the calculation process.
- (3)
- The major difference between the proposed method and the existing decision making method is that the proposed decision making method considers not only the weights of criteria, but also the weights of membership and non-membership degrees. This method accurately describes the true psychological behavior of experts when judging the decision making problem, that is, the expert is determinant or indeterminant about their judging. It makes the decision making result more reasonable and reliable.
- (4)
- Interval Pythagorean fuzzy set, as an extension of intuitionistic fuzzy set, is more flexible and suitable in dealing with uncertainty and complex decision making information in practical situations. The proposed decision making method developed under IPFSs has very extensive application fields with decision making under uncertainty.
- (5)
- To make sure that the method is better or at least it is not worse than the other existing methods, it is appropriate to apply several related approaches to compare their ranking results for the same problem. Accordingly, an illustrative example has been presented to fulfill the task. It is encouraging that the results have shown great similarity to other methods. This fact can be considered to be one of the advantages of the novel approach.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bustince, H.; Barrenechea, E.; Pagola, M. Restricted Equivalence Functions. Fuzzy Set. Syst. 2006, 157, 2333–2346. [Google Scholar] [CrossRef]
- Bustince, H.; Barrenechea, E.; Pagola, M. Image Thresholding using Restricted Equivalence Functions and Maximizing the Measures of Similarity. Fuzzy Set. Syst. 2007, 158, 496–516. [Google Scholar] [CrossRef]
- Bustince, H.; Barrenechea, E.; Pagola, M. Relationship between Restricted Dissimilarity Functions, Restricted Equivalence Functions and Normal EN-Functions: Image Thresholding Invariant. Pattern. Recognit. Lett. 2008, 29, 525–536. [Google Scholar] [CrossRef]
- Lee, S.H.; Pedrycz, W.; Sohn, G. Design of Similarity and Dissimilarity Measures for Fuzzy Sets on the Basis of Distance Measure. Int. J. Fuzzy Syst. 2009, 11, 67–72. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–356. [Google Scholar] [CrossRef]
- Atanassov, K. Intuitionistic Fuzzy Sets. Fuzzy Set. Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Atanassov, K. More on Intuitionistic Fuzzy Sets. Fuzzy Set. Syst. 1989, 33, 37–46. [Google Scholar] [CrossRef]
- Li, Y.H.; Olson, D.L.; Zheng, Q. Similarity Measures between Intuitionistic Fuzzy (vague) Sets: A Comparative Analysis. Pattern. Recognit. Lett. 2007, 28, 278–285. [Google Scholar] [CrossRef]
- Meng, F.; Chen, X. Entropy and Similarity Measure of Atanassov’s Intuitionistic Fuzzy Sets and their Application to Pattern Recognition Based on Fuzzy Measures. Pattern. Anal. Appl. 2016, 19, 11–20. [Google Scholar] [CrossRef]
- Liu, D.; Chen, X.; Peng, D. The Intuitionistic Fuzzy Linguistic Cosine Similarity Measure and its Application in Pattern Recognition. Complexity 2018. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. Distances between Intuitionistic Fuzzy Sets. Fuzzy Set. Syst. 2000, 114, 505–518. [Google Scholar] [CrossRef]
- Szmidt, E.; Kacprzyk, J. A new concept of a similarity measure for intuitionistic fuzzy sets and its use in group decision making. In Proceedings of the 2nd International Conference on Modeling Decisions for Artificial Intelligence, MDAI 2005, Tsukuba, Japan, 25–27 July 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 272–282. [Google Scholar]
- Hung, W.L.; Yang, M.S. Similarity Measures of Intuitionistic Fuzzy Sets Based on Hausdorff Distance. Pattern. Recogn. Lett. 2004, 25, 1603–1611. [Google Scholar] [CrossRef]
- Chen, S.J.; Chen, S.M. Fuzzy Risk Analysis Based on Similarity Measures of Generalized Fuzzy Numbers. IEEE T. Fuzzy Syst. 2003, 11, 45–56. [Google Scholar] [CrossRef]
- Hung, W.L.; Yang, M.S. Similarity Measures of Intuitionistic Fuzzy Sets Based on Lp Metric. Int. J. Approx. Reason. 2007, 46, 120–136. [Google Scholar] [CrossRef]
- Xia, M.; Xu, Z. Some New Similarity Measures for Intuitionistic Fuzzy Values and their Application in Group Decision Making. J. Syst. Sci. Eng. 2010, 19, 430–452. [Google Scholar] [CrossRef]
- Ye, J. Cosine Similarity Measures for Intuitionistic Fuzzy Sets and their Applications. Math. Comput. Model. 2011, 53, 91–97. [Google Scholar] [CrossRef]
- Hung, K.C. Applications of Medical Information: Using an Enhanced Likelihood Measured Approach Based on Intuitionistic Fuzzy Sets. IIE Trans. Healthc. Sys. Eng. 2012, 2, 224–231. [Google Scholar] [CrossRef]
- Shi, L.L.; Ye, J. Study on Fault Diagnosis of Turbine using an Improved Cosine Similarity Measure for Vague Sets. J. Appl. Sci. 2013, 13, 1781–1786. [Google Scholar] [CrossRef]
- Tian, M.Y. A New Fuzzy Similarity Based on Cotangent Function for Medical Diagnosis. Adv. Model. Optim. 2013, 15, 151–156. [Google Scholar]
- Rajarajeswari, P.; Uma, N. Intuitionistic Fuzzy Multi Similarity Measure Based on Cotangent Function. Int. J. Eng. Res. Technol. 2013, 2, 1323–1329. [Google Scholar]
- Szmidt, E. Distances and Similarities in Intuitionistic Fuzzy Sets; Springer: Berlin/Heidelberg, Germany, 2013; pp. 52–95. [Google Scholar]
- Ye, J. Similarity Measures of Intuitionistic Fuzzy Sets Based on Cosine Function for the Decision Making of Mechanical Design Schemes. J. Intell. Fuzzy Syst. 2015, 30, 151–158. [Google Scholar] [CrossRef]
- Le, H.S.; Phong, P.H. On the Performance Evaluation of Intuitionistic Vector Similarity Measures for Medical Diagnosis. J. Intell. Fuzzy Syst. 2016, 31, 1597–1608. [Google Scholar]
- Atanassov, K. Intuitionistic Fuzzy Sets; Springer: Berlin/Heidelberg, Germany, 1999; pp. 190–192. [Google Scholar]
- Atanassov, K. Geometrical Interpretation of the Elements of the Intuitionistic Fuzzy Objects. Int. J. Bio. 2016, 20, S27–S42. [Google Scholar]
- Rajesh, K.; Srinivasan, R. Intuitionistic fuzzy sets of second type. Adv. Fuzzy Math. 2017, 12, 845–853. [Google Scholar]
- Yager, R.R. Pythagorean fuzzy subsets. In Proceedings of the 9th Joint World Congress on Fuzzy Systems and NAFIPS Annual Meeting, IFSA/NAFIPS 2013, Edmonton, AB, Canada, 24–28 June 2013; pp. 57–61. [Google Scholar]
- Yager, R.R. Pythagorean Membership Grades in Multicriteria Decision Making. IEEE T. Fuzzy Syst. 2014, 22, 958–965. [Google Scholar] [CrossRef]
- Liang, D.; Xu, Z.; Liu, D.; Wu, Y. Method for Three-Way Decisions using Ideal TOPSIS Solutions at Pythagorean Fuzzy Information. Inf. Sci. 2018, 435, 282–295. [Google Scholar] [CrossRef]
- Perez-Dominguez, L.; Rodriguez-Picon, L.A.; Alvarado-Iniesta, A.; Cruz, D.L.; Xu, Z.S. MOORA under Pythagorean Fuzzy Set for Multiple Criteria Decision Making. Complexity 2018. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Ali, A.; Siddiqui, N.; Amin, F. Pythagorean hesitant fuzzy sets and their application to group decision making with incomplete weight information. J. Intell. Fuzzy Syst. 2017, 33, 3971–3985. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Ali, A.; Amin, F.; Hussain, F. Pythagorean hesitant fuzzy Choquet integral aggregation operators and their application to multi-attribute decision-making. Soft Computing 2018. [Google Scholar] [CrossRef]
- Wei, G.W.; Lu, M. Pythagorean fuzzy power aggregation operators in multiple attribute decision making. Int. J. Intell. Syst. 2018, 33, 169–186. [Google Scholar] [CrossRef]
- Garg, H. A Linear Programming Method Based on an Improved Score Function for Interval-Valued Pythagorean Fuzzy Numbers and Its Application to Decision-Making. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2018, 26, 67–80. [Google Scholar] [CrossRef]
- Mohagheghi, V.; Mousavi, S.M.; Vandani, B. Enhancing decision-making flexibility by introducing a new last aggregation evaluating approach based on multi-criteria group decision making and Pythagorean fuzzy sets. Appl. Soft. Comput. 2017, 61, 527–535. [Google Scholar] [CrossRef]
- Bolturk, E. Pythagorean fuzzy CODAS and its application to supplier selection in a manufacturing firm. J. Enterp. Inf. Manag. 2018, 31, 550–564. [Google Scholar] [CrossRef]
- Xu, Y.; Shang, X.; Wang, J. Pythagorean fuzzy interaction Muirhead means with their application to multi-attribute group decision-making. Information 2018, 9, 157. [Google Scholar] [CrossRef]
- Zhang, X.L.; Xu, Z.S. Extension of Topsis to Multiple Criteria Decision Making with Pythagorean Fuzzy. Int. J. Intell. Syst. 2014, 29, 1061–1078. [Google Scholar] [CrossRef]
- Peng, X.; Yang, Y. Fundamental Properties of Interval-valued Pythagorean Fuzzy Aggregation Operators. Int. J. Intell. Syst. 2016, 31, 444–487. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S. Interval-valued Pythagorean fuzzy GRA method for multiple-attribute decision making with incomplete weight information. Int. J. Intell. Syst. 2018, 33, 1689–1716. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Ali, M.Y.; Hussain, I.; Farooq, M. Extension of TOPSIS method base on Choquet integral under interval-valued Pythagorean fuzzy environment. J. Intell. Fuzzy Syst. 2018, 34, 267–282. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Liu, P. Gray Method for Multiple Attribute Decision Making with Incomplete Weight Information under the Pythagorean Fuzzy Setting. J. Intell. Syst. 2018. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Ali, A.; Abdullah, S.; Amin, F.; Hussain, F. New extension of TOPSIS method based on Pythagorean hesitant fuzzy sets with incomplete weight information. J. Intell. Fuzzy Syst. 2018, 35, 5435–5448. [Google Scholar] [CrossRef]
- Khan, M.S.A.; Abdullah, S.; Ali, A.; Amin, F. Pythagorean fuzzy prioritized aggregation operators and their application to multi-attribute group decision making. Granul. Comput. 2018. [Google Scholar] [CrossRef]
- Wei, G.W. Pythagorean Fuzzy Interaction Aggregation Operators and their Application to Multiple Attribute Decision Making. J. Intell. Fuzzy Syst. 2017, 33, 2119–2132. [Google Scholar] [CrossRef]
- Biswas, P.; Pramanik, S.; Giri, B.C. Cosine Similarity Measure Based Multi-attribute Decision-making with Trapezoidal Fuzzy Neutrosophic Numbers. Neutro. Set. Sys. 2014, 8, 46–56. [Google Scholar]
- Xu, X.; Zhang, L.; Wan, Q. A Variation Coefficient Similarity Measure and its Application in Emergency Group Decision-making. Syst. Eng. Proced. 2012, 5, 119–124. [Google Scholar] [CrossRef]
- Zhang, X. A Novel Approach Based on Similarity Measure for Pythagorean Fuzzy Multiple Criteria Group Decision Making. Int. J. Intell. Syst. 2016, 31, 593–611. [Google Scholar] [CrossRef]
- Wei, G.; Wei, Y. Similarity Measures of Pythagorean Fuzzy Sets Based on the Cosine Function and their Applications. Int. J. Intell. Syst. 2018, 33, 634–652. [Google Scholar] [CrossRef]
- Peng, X.; Yuan, H.; Yang, Y. Pythagorean Fuzzy Information Measures and their Applications. Int. J. Intell. Syst. 2017, 32, 991–1029. [Google Scholar] [CrossRef]
- Zhao, K.Q.; Xuan, A.L. Set pair theory-a new theory method of non-define and its applications. Syst. Eng. 1996, 14, 18–23. (in Chinese). [Google Scholar]
- Moore, R.E. Methods and Applications of Interval Analysis; SIAM: Philadelphia, PA, USA, 1979; pp. 8–11. [Google Scholar]
- Tan, C.Q. A multi-criteria interval-valued intuitionistic fuzzy group decision making with Choquet integral-based TOPSIS. Expert Syst. Appl. 2011, 38, 3023–3033. [Google Scholar] [CrossRef]
- Brauers, W.K.M.; Zavadskas, E.K. Project management by MULTIMOORA as an instrument for transition economies. Technol. Econ. Dev. Econ. 2010, 16, 5–24. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| C | S | Q | Com | |
| DBB | p([0.6,0.7],[0.4,0.5]) | p([0.4,0.6],[0.5,0.7]) | p([0.5,0.7],[0.3,0.5]) | p([0.5,0.7],[0.6,0.7]) |
| DB | p([0.7,0.8],[0.3,0.4]) | p([0.5,0.7],[0.4,0.5]) | p([0.5,0.7],[0.3,0.5]) | p([0.5,0.7],[0.5,0.6]) |
| CM | p([0.3,0.5],[0.6,0.8]) | p([0.5,0.7],[0.3,0.4]) | p([0.2,0.3],[0.3,0.6]) | p([0.2,0.4],[0.6,0.8]) |
| EPC | p([0.8,0.9],[0.2,0.3]) | p([0.5,0.7],[0.1,0.2]) | p([0.6,0.7],[0.2,0.4]) | p([0.1,0.2],[0.6,0.8]) |
| SC | E | FG | RM | |
| DBB | p([0.6,0.7],[0.4,0.6]) | p([0.5,0.7],[0.6,0.7]) | p([0.6,0.7],[0.3,0.5]) | p([0.5,0.7],[0.6,0.8]) |
| DB | p([0.5,0.7],[0.3,0.5]) | p([0.5,0.7],[0.4,0.6]) | p([0.5,0.7],[0.4,0.6]) | p([0.6,0.7],[0.5,0.6]) |
| CM | p([0.6,0.7],[0.4,0.5]) | p([0.2,0.3],[0.6,0.8]) | p([0.4,0.6],[0.6,0.8]) | p([0.4,0.5],[0.6,0.7]) |
| EPC | p([0.2,0.4],[0.3,0.4]) | p([0.8,0.9],[0.1,0.2]) | p([0.7,0.8],[0.3,0.4]) | p([0.6,0.8],[0.3,0.4]) |
| U | Size | |||
| DBB | p([0.6,0.7],[0.5,0.6]) | p([0.4,0.6],[0.5,0.6]) | ||
| DB | p([0.5,0.7],[0.4,0.5]) | p([0.5,0.7],[0.4,0.5]) | ||
| CM | p([0.6,0.7],[0.2,0.3]) | p([0.2,0.3],[0.6,0.8]) | ||
| EPC | p([0.2,0.3],[0.6,0.8]) | p([0.6,0.8],[0.2,0.3]) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Cao, Y.; Su, L.; Xia, Q. An Interval Pythagorean Fuzzy Multi-criteria Decision Making Method Based on Similarity Measures and Connection Numbers. Information 2019, 10, 80. https://doi.org/10.3390/info10020080
Li H, Cao Y, Su L, Xia Q. An Interval Pythagorean Fuzzy Multi-criteria Decision Making Method Based on Similarity Measures and Connection Numbers. Information. 2019; 10(2):80. https://doi.org/10.3390/info10020080
Chicago/Turabian StyleLi, Huimin, Yongchao Cao, Limin Su, and Qing Xia. 2019. "An Interval Pythagorean Fuzzy Multi-criteria Decision Making Method Based on Similarity Measures and Connection Numbers" Information 10, no. 2: 80. https://doi.org/10.3390/info10020080
APA StyleLi, H., Cao, Y., Su, L., & Xia, Q. (2019). An Interval Pythagorean Fuzzy Multi-criteria Decision Making Method Based on Similarity Measures and Connection Numbers. Information, 10(2), 80. https://doi.org/10.3390/info10020080