Abstract
Underwater target detection plays a crucial role in marine environmental monitoring and early warning systems. It involves utilizing optical images acquired from underwater imaging devices to locate and identify aquatic organisms in challenging environments. However, the color deviation and low illumination in these images, caused by harsh working conditions, pose significant challenges to an effective target detection. Moreover, the detection of numerous small or tiny aquatic targets becomes even more demanding, considering the limited storage and computing power of detection devices. To address these problems, we propose the YOLOv7-CHS model for underwater target detection, which introduces several innovative approaches. Firstly, we replace efficient layer aggregation networks (ELAN) with the high-order spatial interaction (HOSI) module as the backbone of the model. This change reduces the model size while preserving accuracy. Secondly, we integrate the contextual transformer (CT) module into the head of the model, which combines static and dynamic contextual representations to effectively improve the model’s ability to detect small targets. Lastly, we incorporate the simple parameter-free attention (SPFA) module at the head of the detection network, implementing a combined channel-domain and spatial-domain attention mechanism. This integration significantly improves the representation capabilities of the network. To validate the implications of our model, we conduct a series of experiments. The results demonstrate that our proposed model achieves higher mean average precision (mAP) values on the Starfish and DUO datasets compared to the original YOLOv7, with improvements of 4.5% and 4.2%, respectively. Additionally, our model achieves a real-time detection speed of 32 frames per second (FPS). Furthermore, the floating point operations (FLOPs) of our model are 62.9 G smaller than those of YOLOv7, facilitating the deployment of the model. Its innovative design and experimental results highlight its effectiveness in addressing the challenges associated with underwater object detection.
1. Introduction
The Earth’s extensive surface is primarily covered by the ocean, which accounts for more than 70% of its total area. This remarkable natural resource offers humanity a wealth of valuable marine resources that are indispensable to our survival and well-being [1]. Achieving sustainable development through the effective monitoring and protection of the living marine resources necessitates the utilization of a diverse array of detection techniques in an expeditious manner. Traditional underwater target detection methods rely heavily on human divers’ visual assessment of the marine environment, but these tasks can have adverse effects on the divers’ health due to their extended and intricate nature. As robot technology continues to advance, human divers are gradually being replaced by underwater robots equipped with object detection algorithms that can locate and identify underwater targets accurately and promptly [2,3]. The object detection model plays a pivotal role in this success.
Object detection is a crucial task in computer vision, which can be categorized into two-stage and one-stage detection methods based on whether region proposals are generated [4]. The former generates proposed regions before classifying them with refined positions, enabling higher accuracy but slower speed. The latter directly outputs the object’s class probability and position coordinates without generating region proposals, resulting in a faster recognition but lower accuracy. This paper presents a solution to address the cost and real-time limitations of underwater detection devices by introducing a compact network with precise and fast detection capabilities. The underwater environment is characterized by its intricacy and constant change, which lead to environmental noise that can significantly degrade the performance of underwater detection devices [5]. In most captured underwater images, a predominant color palette of blue-green hues dominates, creating a major obstacle in effectively discerning underwater targets from the background. Moreover, the presence of a multitude of small-bodied marine species adds another layer of complexity, as these organisms often conceal themselves, making it challenging to achieve an accurate detection. Figure 1 visually exemplifies the formidable obstacles encountered in the detection of underwater objects.

Figure 1.
Illustrative instances of underwater imaging. (a) Low illumination. (b) Color deviation. (c) Small targets.
This paper has primarily the following contributions:
- Following a comprehensive examination of the correlation between underwater image enhancement and target detection, it is determined that there is no association between the two. This implies that image enhancement is not a mandatory step in the process of detecting targets in underwater environments.
- To enhance the accuracy of underwater detection while minimizing computational complexity, we propose the high-order spatial interaction (HOSI) module as a replacement for efficient layer aggregation networks (ELAN) as the backbone network for YOLOv7. The HOSI module achieves superior flexibility and customization through the incorporation of high-order spatial interactions between gated convolution and recursive convolution, and greatly reduces model complexity.
- Drawing inspiration from the transformer’s working mechanism, we propose the contextual transformer (CT) module to augment our detection network, enabling the integration of both dynamic and static context representations to improve the model’s ability to detect small targets.
- We integrate the simplified parameter-free attention (SPFA) module into the detection network, enabling it to attend to both channel and spatial information simultaneously, thereby improving its ability to selectively extract relevant information.
The present paper is organized into five distinct sections. To appreciate the innovative nature of the research, Section 2 provides a comprehensive summary of prior studies in the field. Section 3, then, introduces the improved network architecture designed for the faster and more precise detection of underwater targets. In Section 4, the experimental setup and analysis are presented to evaluate the performance of the detection network. Finally, Section 5 concludes with the key findings of the investigation and outlines future research directions.
2. Related Work
2.1. Underwater Object Detection
The successful implementation of generic object detection models in common images has demonstrated their versatility and effectiveness, highlighting their utility in various applications. However, detecting objects in underwater images presents a greater challenge due to the complex environmental noise [6]. Despite this, some progress has been made in underwater target detection, which can be broadly categorized into two distinct tasks: underwater image enhancement and generic target detection. The former focuses on improving the quality of degraded underwater images caused by light dispersion and color distortion, while the latter aims to locate and identify underwater targets more accurately and efficiently. Various image enhancement techniques have been investigated in the literature for improving contrast, correcting color shifts, and sharpening edges in underwater images [7,8,9]. Furthermore, other studies aim to counteract the negative effects of image blur by enhancing the network architecture [10,11,12] and refining training strategies [13]. Conversely, there is a high level of interest in improving the accuracy and expeditiousness of generic detection models. V. Malathi et al. [14] proposed an HC2PSO algorithm that leveraged a Resnet model with a convolutional neural network architecture for underwater object recognition. This innovative approach successfully eliminated speckles from images and significantly enhanced detection accuracy. In the literature [15], a novel algorithm based on YOLOv4-tiny has been proposed for constructing a symmetric FPN module, which is claimed to enhance the mAP score. However, this algorithm suffers from certain losses in terms of inference speed. The M-ResNet [16] is a cutting-edge approach that enhances detection efficiency through multi-scale operations, enabling the accurate identification of objects of varying sizes and making it a viable option for real-time applications. However, the literature on this topic has noted certain limitations. Specifically, the datasets utilized in this investigation are relatively small, which may limit its generalizability. In an effort to enhance the effectiveness of underwater target detection, a multi-scale aggregated feature pyramid network has been proposed in the literature [17]. The literature [18] demonstrates a harmonious balance between accuracy and speed through the implementation of two deep learning detectors, which learn from one another during training. Nonetheless, this approach is limited in its ability to detect small and dense objects. In an effort to mitigate the detrimental effects of degraded underwater images on detection accuracy, a novel deep neural network for simultaneous color conversion and underwater target detection has been introduced in the literature [19]. Despite the significant improvement in detection accuracy, challenges still exist in detecting small targets accurately. Zhang et al. [20] proposed a method that integrates MobileNetv2 and depth-separated convolution to effectively reduce the number of parameters while maintaining accuracy. Despite this reduction, the method still entails a significant amount of redundant parameters and channels. The FL-YOLOV3-TINY model [21] is a novel approach that has been proposed for reducing the number of parameters and model size by integrating a depth-separable convolution module. Despite these improvements, there is still room for further accuracy enhancement. Furthermore, to enhance the accuracy of their models, various modifications have been introduced to the underlying frameworks in the literature [22,23,24,25], as extensively documented in all studies.
The goal of this study is to optimize the detection model’s size while improving its accuracy and speed. To achieve this objective, we propose the integration of the HOSI module within the YOLOv7 network, which facilitates a reduction in model size while improving its visual representation. Additionally, the CT module is intended to enhance the model’s accuracy by integrating static and dynamic contexts. Finally, we also present the SPFA module to enhance the model’s accuracy and speed by utilizing a parameter-free attention mechanism.
2.2. Small Object Detection
To the best of our knowledge, there are no satisfactory techniques for detecting small objects [26], particularly in underwater imagery, which are often characterized by incomplete and blurry image features. Given the abundance of small targets present in underwater images, numerous researchers have endeavored to refine the existing models, striving to enhance the accuracy and efficiency of small target detection tasks. The CME-YOLOv5 model [27] employs a novel approach by first replacing the C3CA module with the primary C3 module, followed by expanding the three detection layers to four. Additionally, this model leverages the EIOU loss function in place of the GIOU loss function to enhance small object detection performance. The DLSODC-GWM technique [28] refines the hyperparameters of the improved RefineDet (IRD) model using an arithmetic optimization algorithm (AOA), and then employs the functional link neural network (FLNN) model to classify small targets, leading to an increased detection accuracy. The SWIPENET model [29] was designed to achieve enhanced accuracy in small object detection by utilizing a backbone that generates a plurality of high-resolution, semantically rich hyper-feature graphs. Cao et al. [30] proposed an improved algorithm for small target detection based on Faster-RCNN, which addressed the localization bias issue by enhancing the loss function and RoI pooling operation. Moreover, the accuracy of the algorithm was significantly improved by optimizing the non-maximum suppression (NMS) process to prevent the loss of overlapping objects. Furthermore, Xu et al. [31] implemented the Faster-RCNN and kernelized correlation filter (KFC) tracking algorithm to achieve the real-time detection of small underwater objects. The literature [32] proposed a small target detection algorithm that utilized context and incorporated an attention mechanism. This approach has led to improved accuracy in detecting small targets. The aforementioned advancements in small target detection have led to an improvement in model performance accuracy. However, such progress often comes at the cost of reduced detection speed or increased model size. To address this challenge, we propose the YOLOv7-CHS network, which not only enhances the accuracy of detecting dense underwater small targets but also significantly reduces the model size.
2.3. Image Enhancement
Image enhancement refers to the implementation of digital signal processing techniques to increase the visual quality of images. Enhancing underwater images is a specialized technique that aims to augment specific features of underwater images and suppress noisy and irrelevant background features, in order to improve the overall quality of the image and the visibility of the target of interest [33]. In this study, three underwater image enhancement techniques are explored, namely, Contrast-Limited Adaptive Histogram Equalization (CLAHE) [34], Dark Channel Prior (DCP) [35], and DeblurGAN-v2 [36].
The CLAHE algorithm is a technique for improving the contrast of images while maintaining their details. It achieves this by dividing the image into several regions and processing each region separately using an adaptive histogram equalization method. The algorithm then uses interpolation to stitch together the processed regions, resulting in enhanced image contrast. One of the key advantages of the CLAHE algorithm is its ability to preserve faint detail information in the image while enhancing contrast.
The DCP algorithm is a powerful technique for removing haze from images that employs a two-layer partial differential equation approach. It can effectively clarify an image by estimating the background brightness and distribution of light in the haze. The first step in its implementation is to calculate the dark channel of the image, which represents the minimum pixel value over a local window for each channel. This calculation is mathematically expressed as:
where represents any channel of image , while denotes a rectangular window centered at pixel point . is the dark channel of image. When there is no fog in an outdoor scene, the intensity of the dark channel is low and approaches zero, making it unsuitable for haze thickness estimation. To address this issue, the algorithm employs two additional steps to optimize the defogging effect: global illumination estimation and haze density estimation. These two steps refine the estimation of the global illumination and haze thickness, leading to a better image quality.
The DeblurGAN-v2 algorithm is a cutting-edge deep generative adversarial network (GAN)-based image denoising technique that boasts remarkable speed and efficiency in restoring blurry images to their original clarity. The core of this groundbreaking algorithm lies in the use of an adversarial learning approach for training both the generator and discriminator networks. This enables the generator to produce high-fidelity clear images despite being fed with an unclear input, while simultaneously improving the performance of the discriminator network to better distinguish between the real and fake clear images generated by the generator. To train DeblurGAN-v2, a hybrid loss function is employed, which takes into account multiple aspects of the generated images.
where helps to correct color and texture distortions by measuring the difference between the original image and the denoised image in terms of pixel values. computes the Euclidean loss on the VGG19 conv3_3 feature map, which measures the similarity between the generated image and the ground truth image in terms of visual features. Finally, contains both global and local discriminator losses, which help to improve the performance of the generator by forcing it to produce more realistic and detailed images.
3. Methods
3.1. Network Architecture
The You Only Look Once (YOLO) network is a popular object detection technique that can identify and localize objects efficiently in images. In this study, the YOLOv7 network [37] was employed as the key network for underwater target detection. The YOLOv7 network is composed of four fundamental components, namely, the input, backbone, head, and prediction modules. In the input module, an image undergoes Mosaic data enhancement, adaptive anchor frame calculation, and adaptive image scaling to construct a processed image for further processing. In the backbone network, the CBS module has three color levels, from light to dark, for changing the number of channels, extract features, and downsample. The MP module downsamples the resulting feature map, with the MP-1 and MP-2 modules having different output channel settings but identical structures. The ELAN module improves the model’s adaptability and enhances its robustness by controlling the gradient path. The head network is made up of SPPCSPC module, UPSample module, and concatenation (Cat) operation structure. The SPPCSPC module expands the receptive field and adapts to images with various resolutions. The role of the UPSample module is to scale up the dimensions of the input feature map through an upsampling operation to obtain a higher resolution feature map. The Cat operation merges the features of two branches. Finally, the REP structure is used to tune the output channels, followed by a 1 × 1 convolution to predict the confidence, category, and anchor frame.
The YOLOv7 network, originally designed for generic object detection, often encounters challenges, such as high image quality requirements and insensitivity to small targets, during underwater target detection. Furthermore, the large size of the model makes it impossible to deploy on underwater devices, further complicating underwater detection tasks. To address these issues and enhance the suitability of the detection network for underwater environments, we made significant modifications and optimizations to YOLOv7. Specifically, we replaced the two ELAN modules in the original backbone with two HOSI modules. Additionally, we added downsampling convolutional layers after the first HOSI module and a feature extraction convolutional layer after the second HOSI module. These modifications enable the backbone network to achieve high-order spatial interactions while maintaining a light weight, making it more suitable for underwater detection tasks. Moreover, to enhance the visual modeling capabilities of YOLOv7, we integrated the CT3 module into the head to enable it to detect small targets by combining static and dynamic contexts. Additionally, we incorporated the SPFA attention mechanism into the MP-2 module to improve the model’s representational capabilities and accuracy.
As a consequence of these enhancements, we developed the YOLOv7-CHS network, which is more suitable for underwater target detection. The improved network architecture is depicted in Figure 2.
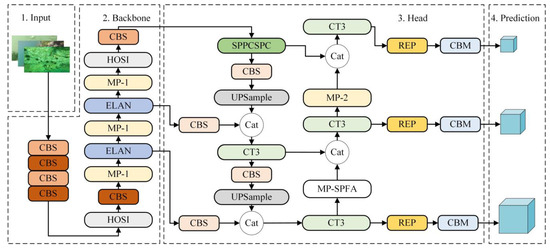
Figure 2.
Structure diagram of the YOLOv7-CHS network.
3.2. High-Order Spatial Interaction (HOSI) Module
The success of self-attentive networks and other dynamic networks has demonstrated the benefits of incorporating higher-order spatial interactions into network structures to enhance visual modeling capabilities. In this paper, we aimed to design a network architecture using recursive gated convolution (RGConv) [38], which is illustrated in Figure 3. RGConv further improves model capacity by introducing higher-order interactions. Firstly, linear projection layers are leveraged to acquire a set of projection features and :
where , , and correspond to the height, width, and channel dimension of the images, respectively. The gated convolution is then applied recursively as outlined below:
where the stability of training is achieved through the modification of , while denotes a set of deep convolutional layers. Additionally, is employed to align dimensions in an alternative manner:
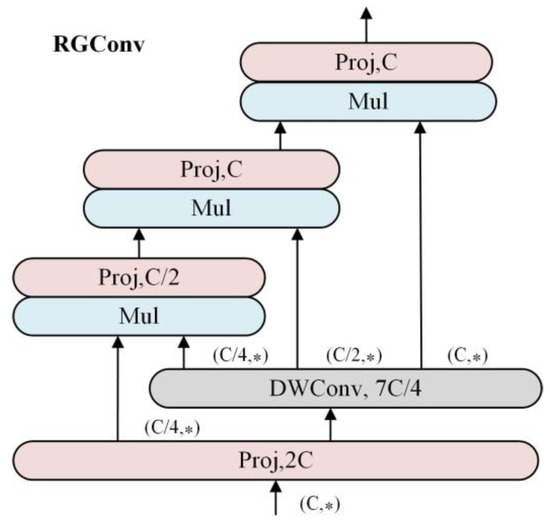
Figure 3.
Structure diagram of RGConv. The “(C, ⁎)” is equivalent to “(C, W, H)”, and the “⁎” represents “W, H”.
Finally, the output of the last recursive step is passed through the projection layer to obtain the output of the recursive gated convolution . In order to mitigate the excessive computational overhead caused by higher-order interactions, we regulated the channel dimensions in each order as , where . RGConv is developed using conventional convolution, linear projection, and element-wise multiplication, incorporating input adaptive spatial mixing akin to self-attentiveness.
The HOSI module was designed using RGConv to facilitate the interaction between long-term and higher-order spaces, as shown in Figure 4. During forward propagation, layer normalization is employed to scale the output values of neurons, which can effectively address gradient vanishing and exploding issues. Additionally, multilayer perceptron (MLP) is incorporated to enhance the model’s accuracy.
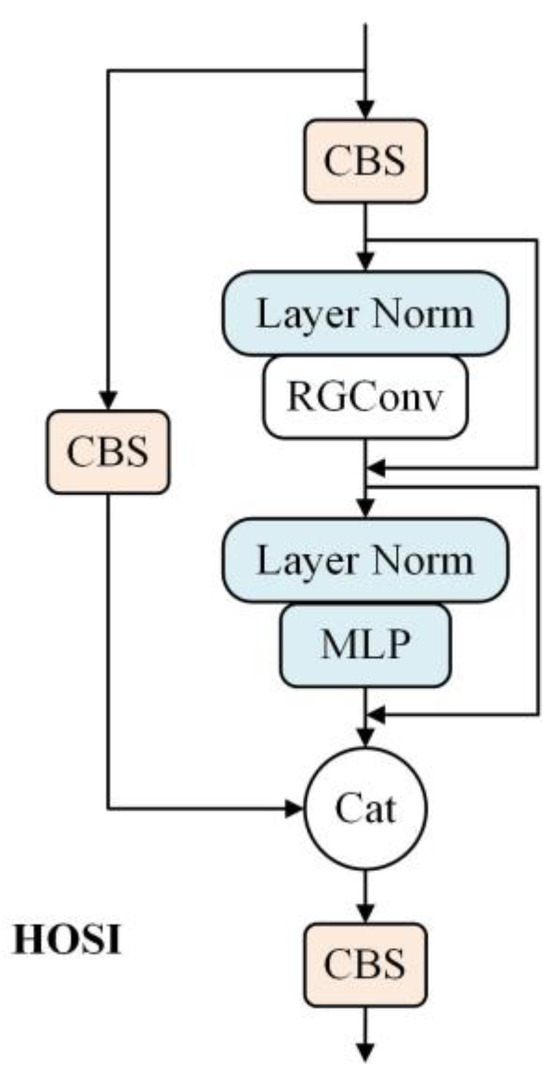
Figure 4.
Structure diagram of the HOSI module.
3.3. Contextual Transformer (CT) Module
The resolution of objects in underwater images is often limited to less than 30 × 30 pixels, resulting in a reduced spatial information. As a result, detecting these small objects becomes a challenging task. To overcome this limitation, this paper proposes a novel method for small object detection by incorporating the CT module, which draws inspiration from the Transformer architecture and exhibits strong visual representation capabilities [39].
Figure 5 illustrates the schematic diagram of the CT module. Initially, the input key undergoes encoding using contextual convolution to capture the static context of the input. Subsequently, the encoded key is connected to the input query through two successive convolutions. By multiplying the attention weights with the input values, the dynamic contextual representation of the input is obtained. Finally, the fusion of the static and dynamic contextual representations serves as the output of the CT module.
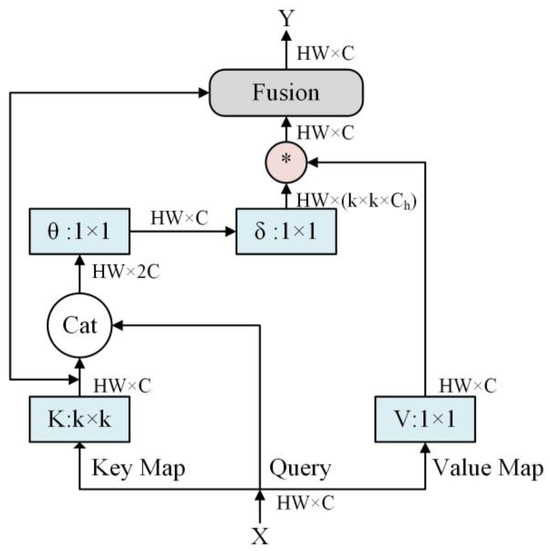
Figure 5.
Structure diagram of the CT module. The “⁎” denotes the local matrix multiplication.
The CT3 module was constructed by utilizing multiple CT modules. The structure diagram of the CT3 module can be seen in Figure 6. This module is composed of two branches, each following a distinct pathway. In the first branch, the input passes through a CBS module and then proceeds to a CTBottleneck module. The CBS module facilitates the integration of contextual information, while the CTBottleneck module takes advantage of the CT module to enhance feature representation. The second branch simply passes through a CBS module. Both branches converge at the Cat operation, where the features from both branches are concatenated. The concatenated features then pass through another CBS module, providing further refinement and integration. The utilization of multiple CT modules allows the module to leverage the complementary characteristics of each branch, thereby improving its efficiency in learning residual features. This module is particularly beneficial for tasks involving small object detection.
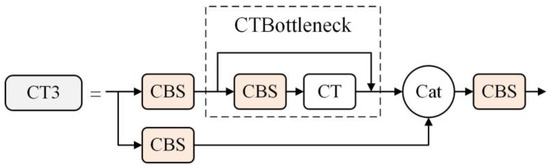
Figure 6.
Structure diagram of the CT3 module.
3.4. Simple Parameter-Free Attention (SPFA) Module
In the human brain, attention is a complex phenomenon that involves two main mechanisms: feature attention and spatial attention [40]. These mechanisms have inspired researchers to develop a module called the SPFA, which efficiently generates real 3D weights [41]. The structure of the SPFA module is depicted in Figure 7. To achieve attention, it is crucial to estimate the importance of individual neurons. For this purpose, researchers introduced an energy function, denoted as , for each neuron. This energy function evaluates the relevance of each neuron based on its features and spatial location. By combining feature-based attention and spatial attention, the SPFA module can effectively capture features under different attention patterns and adapt to various contexts.
where represents the target neuron, while represents the other neurons in a single channel of the input feature denoted as . The subscript denotes the spatial dimension, and represents the total number of neurons in the channel. The term is associated with the coefficient of regularization. The weight and bias in Equation (6) are represented by and . When the energy function reaches its minimum, the closed-form solutions for and are obtained as follows:
where the mean of all neurons except is denoted by , while represents the variance of all neurons except . Subsequently, an energy function is derived to determine the importance of each neuron. Feature refinement is then conducted using the scaling operator. The optimization phase of the module can be concisely described as follows:
where serves as an aggregation of the minimum energy across both channel and spatial dimensions. To mitigate the presence of potential excessive values within , a sigmoid function was employed. Notably, it is crucial to emphasize that the sigmoid function applied does not alter the importance attributed to each neuron.
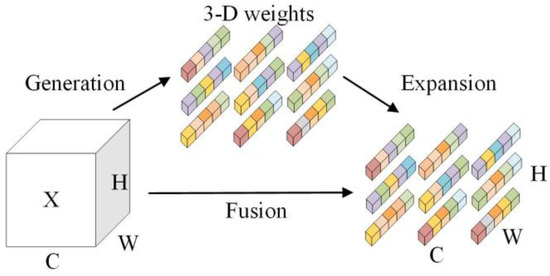
Figure 7.
Structure diagram of the SPFA module.
The module employed in this study exhibits a straightforward architecture and operates as a parameter-free attention mechanism. Unlike the existing channel attention and spatial attention mechanisms, this module directly deduces attention weights in all three dimensions within the network layers, eliminating the need for additional parametric quantities. The module is both adaptable and proficient in enhancing the representational capacity of convolutional networks.
In this paper, we propose the integration of the SPFA module into the MP-2 module of YOLOv7, aiming to enhance feature extraction capabilities. By replacing the CBS module with the SPFA module, we introduced the MP-SPFA module, as illustrated in Figure 8. The MP-SPFA module comprises two branches. The first branch encompasses a maximum pooling layer and a CBS module with a 1 × 1 convolution kernel and a stride size of 1. The second branch involves the SPFA module and a CBS module with a 3 × 3 convolution kernel and a stride size of 2. The outputs of these two branches are combined through a Cat operation. This module facilitates the extraction of deeper features through an attentive mechanism.
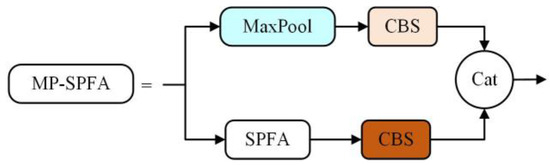
Figure 8.
Structure diagram of the MP-SPFA module.
4. Experiments
4.1. Dataset
To demonstrate the effectiveness and versatility of the object detection model proposed in this paper, we chose two underwater imaging datasets, namely, the Starfish dataset and the DUO dataset, for validation purposes. The utilization of these datasets allowed us to evaluate the model’s performance in different underwater scenarios.
The Starfish dataset [42] was obtained from the official Kaggle website and holds great significance in detecting a specific species of starfish that feeds on corals in the ocean, with the aim of safeguarding the marine environment. The dataset consists of genuine underwater images captured in the Great Barrier Reef of Australia, where the Crown-of-Thorns Starfish (COTS) is the sole object detected in the images. With a resolution of 1280 × 720 pixels, the dataset comprises a total of 23,501 images. Among these, 4919 images contain starfish objects, while 18,582 images do not exhibit any starfish presence. To facilitate effective model training, the dataset is randomly partitioned into three sets: a training set, a validation set, and a testing set, following an 8:1:1 ratio.
The DUO dataset [43] comprises four distinct object categories: holothurian, echinus, scallop, and starfish. Figure 9 illustrates the distribution of objects across these categories, revealing a total of 74,515 objects. The specific counts for each category are as follows: holothurian (7887), echinus (50,156), scallop (1924), and starfish (14,548). The dataset encompasses a collection of 7782 underwater images captured at varying resolutions. These images are further divided into three subsets, namely, training, validation, and testing sets, following an 8:1:1 ratio. This partitioning scheme ensures a balanced representation of the data in each subset, facilitating effective model training and evaluation.
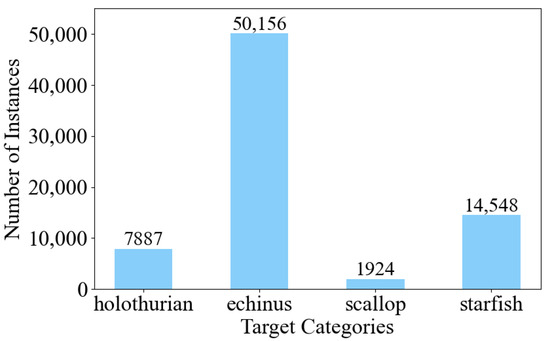
Figure 9.
The distribution of instances for the DUO dataset.
4.2. Experimental Settings
The hardware devices employed in this experiment consisted of a CPU: E5–2678 v3 @ 2.50 GHz, GPU: NVIDIA GeForce RTX 2080 Ti, and RAM: 128 GB. The software environment utilized included Windows 10, Python 3.7, PyTorch 1.10.1, Cuda 10.2, and cuDNN 8.4.1.
To ensure comparability, the hyperparameter settings for all models were as follows. The images were resized to have an input size of 640 × 640 pixels. The training duration spanned 300 epochs, and the batch size was set to 8. In the image enhancement and ablation experiment, the SGD [44] optimizer was utilized with a learning rate of 0.01. In the model comparison experiments, the Adam [45] optimizer was employed with a learning rate of 0.001.
4.3. Evaluation Metrics
Precision (P), recall (R), average precision (AP), and mean average precision (mAP) are commonly employed as evaluation metrics to assess model accuracy. Specifically, they are formulated as follows:
where P denotes the proportion of correctly predicted samples to all predicted samples. Additionally, we considered the ratio of predicted positive samples to all positive samples, denoted byR. The term denotes the number of target types. AP refers to the area enclosed after plotting the P-R curve, with precision on the y-axis and recall on the x-axis. mAP is the average AP calculated across all categories.
Moreover, frame per second (FPS) provides valuable insights into the network’s efficiency and speed in processing frames or data samples, enabling an assessment of its real-time capabilities. The number of network parameters serves as an indicator of the model’s size, offering insights into its memory and storage requirements, which are crucial considerations for practical deployment. Additionally, floating-point operations (FLOPs) provide a quantifiable measure of the algorithm’s computational complexity, facilitating comparisons between the state-of-the-art models based on their utilization of computational resources.
4.4. Image Enhancement
Given the challenges posed by underwater imaging, such as low illumination and color deviation, this paper applied three distinct image enhancement methods to tackle these issues. The effectiveness of these methods is demonstrated in Figure 10. The top row showcases the enhancement effect on the Starfish dataset, while the bottom row displays the enhancement effect on the DUO dataset. As depicted, the CLAHE method enhances the uniformity of the color distribution in the original image. The DCP algorithm effectively reduces the impact of fog, resulting in a clearer appearance. Additionally, the DeblurGAN-v2 algorithm alleviates image blurring and enhances the visibility of previously obscured details.

Figure 10.
Image enhancement results using the different methods. (a) Original image. (b) CLAHE. (c) DCP. (d) DeblurGAN-v2.
To investigate the potential impact of enhanced images on detection accuracy, we applied image enhancement techniques to the training set, validation set, and testing set of both datasets. Subsequently, we conducted training on the YOLOv7-CHS network and evaluated the performance using the testing results presented in Table 1. The experiments were divided into four sets. The first set of experiments utilized the original dataset without any image enhancement. The second to fourth sets of experiments involved the application of the three image enhancement algorithms to the dataset, resulting in enhanced versions. Based on the experimental findings, we observed that the CLAHE method yields improved accuracy on the starfish dataset, but its effectiveness does not extend to the DUO dataset, indicating a lack of generalizability of the enhancement method. Moreover, applying the DCP and DeblurGAN-v2 methods for enhancement on both datasets does not contribute to an enhancement in the detection accuracy. Based on these observations, it can be inferred that the image enhancement algorithm primarily enhances the visual quality of the images as perceived by human vision. However, this enhancement does not facilitate the deep learning network in acquiring additional features, thereby failing to improve the detection accuracy when trained with neural networks. Consequently, it can be concluded that the enhancement of underwater images and the subsequent improvement in the detection accuracy are not positively correlated. Furthermore, the computational burden on underwater object detection devices increases when employing image enhancement algorithms to preprocess underwater images, thus impacting the real-time performance of the detection task. Therefore, unless specifically stated, we refrained from utilizing such algorithms for preprocessing the captured underwater images in the subsequent experiments.

Table 1.
Comparison experiments for image enhancement. The bolded numbers are the best results in that column of numbers.
4.5. Ablation Experiments
Ablation experiments were conducted on the two datasets, namely, the Starfish dataset and the DUO dataset, to evaluate the effectiveness of the three enhancements presented in this paper. The primary objective of the initial set of experiments was to assess the detection performance of the YOLOv7 model in its original form, which serves as a baseline for evaluating the impact of subsequent enhancements. Subsequently, experiments were conducted in sets two to seven to augment the YOLOv7 model with individual or combined improvements. These enhancements, including the CT3, HOSI, and SPFA techniques, were incorporated into the YOLOv7 model individually to assess their individual contributions. Furthermore, combinations of these enhancements were also evaluated to explore potential synergistic effects. The eighth set of experiments focused on examining the detection results of the YOLOv7-CHS model, which incorporates all three improvements (CT3, HOSI, and SPFA) simultaneously into the YOLOv7 model. The primary aim of this integration was to achieve an improved detection performance compared to the original YOLOv7 model.
Table 2 presents the results of the ablation experiments conducted on the two datasets to evaluate the impact of the three improvement points. The initial YOLOv7 model without any enhancements achieved an mAP of 47.3% and 80.1% on the Starfish and DUO datasets, respectively, with a computational cost of 103.2 G FLOPs. In the fourth set of experiments, the inclusion of only the SPFA module in the model resulted in an mAP of 82.0% on the DUO dataset. However, there was no improvement in mAP on the Starfish dataset, and the model’s computational cost is too large for practical application to underwater devices. Subsequently, the sixth set of experiments incorporated both the CT module and the SPFA module, leading to improved mAP values on both datasets. Nevertheless, the computational cost remained high at 90.6 G FLOPs, making it unsuitable for deployment on underwater devices. In the eighth set of experiments, the CT3, HOSI, and SPFA modules were simultaneously incorporated, resulting in mAP values of 48.4% and 84.1% on the Starfish and DUO datasets, respectively. These results represent a 1.1% and 4.0% increase over the initial set of experiments, respectively. Additionally, the computational cost was optimized to 40.3 G FLOPs, making the model more lightweight and suitable for deployment on underwater devices. In summary, the proposed model demonstrates a favorable performance on both underwater datasets, indicating its adaptability and robustness in various underwater environments. Furthermore, the model significantly reduced the model complexity, enabling a convenient deployment on underwater devices.
Table 2.
Ablation experiments. In columns 2 through 4, the “×” sign indicates that the module in line 1 was not added to the YOLOv7 network, and the “✓” sign indicates that the module in line 1 was added to the YOLOv7 network.
4.6. Comparisons with Other Methods
4.6.1. Selection of Optimizer
In the previous section, we conducted ablation experiments using the SGD optimizer, which is commonly employed for object detection. To assess the suitability of optimizers for underwater object detection, we performed a comparative analysis by conducting two sets of experiments on two datasets. We compared the performance of two popular optimizers, namely, SGD and Adam. The SGD optimizer utilizes a learning rate of 0.01, while Adam employs a learning rate of 0.001. The objective of these experiments was to evaluate and determine which optimizer offers a better performance in the context of underwater object detection.
As demonstrated in Table 3, employing the Adam optimizer on the Starfish dataset yielded a significant improvement of 5% in recall and a 4.4% increase in mAP. However, this improvement came at the cost of an 8.2% reduction in precision. Additionally, there was a slight improvement in the detection speed. When applied to the DUO dataset, the use of the Adam optimizer resulted in a 1.3% decrease in recall. However, it led to a modest increase of 0.9% in precision and a 0.5% improvement in mAP. Notably, the detection speed remained consistent at 32 FPS. Overall, these findings suggest that the Adam optimizer is more suitable than the SGD optimizer for underwater object detection tasks.
Table 3.
Experimental results of the comparison of the SGD and Adam optimizers.
4.6.2. Results on the Starfish Dataset
In this study, we conducted comparative experiments on popular object detection models, namely, YOLOv5s, YOLOv7, YOLOv7-tiny, Swin-Transformer, and YOLOv7-CHS, as detailed in Table 4. Leveraging the success of previous experiments that utilize the Adam optimizer, we employed it in our comparison study. Our model achieved an impressive mAP of 52.8%, surpassing Swin-Transformer, YOLOv5, YOLOv7-tiny, and YOLOv7 by 17%, 17.1%, 18.5%, and 4.5%, respectively. These results highlight the effectiveness of our model in accurately detecting and localizing objects. Although our model’s FLOPs were not as low as Swin-Transformer, YOLOv5s, and YOLOv7-tiny, it still managed to save 62.9 G when compared to the YOLOv7 model. This indicates that our model strikes a balance between model accuracy and computational efficiency, resulting in notable computational savings. Additionally, our model demonstrated a detection speed of 32 FPS, enabling real-time object detection. This characteristic is particularly valuable when the timely and efficient detection of underwater objects is required.
Table 4.
Comparisons of different object detectors on the Starfish dataset. The bolded numbers are the best results in that column of numbers.
Figure 11 and Figure 12 display the detection outcomes of images depicting starfish instances that are densely distributed and sparsely distributed, respectively. Notably, the YOLOv7-CHS model demonstrates an exceptional proficiency in detecting diminutive targets as compared to alternative models, irrespective of the density of targets within the images. These observations underscore the YOLOv7-CHS model’s pronounced efficacy in accurately identifying and localizing small objects, further transcending variations in target density. Consequently, the YOLOv7-CHS model exhibits promising capabilities for object detection purposes, particularly in scenarios involving minuscule subaquatic entities.

Figure 11.
Detection results on dense targets. (a) Original image. (b) Results of the Swin-Transformer detector. (c) Results of the YOLOv5s detector. (d) Results of the YOLOv7-tiny detector. (e) Results of the YOLOv7 detector. (f) Results of the YOLOv7-CHS detector.

Figure 12.
Detection results of sparse targets. (a) Original image. (b) Results of the Swin-Transformer detector. (c) Results of the YOLOv5s detector. (d) Results of the YOLOv7-tiny detector. (e) Results of the YOLOv7 detector. (f) Results of the YOLOv7-CHS detector.
4.6.3. Results on the DUO Dataset
Table 5 presents a comparative experiment evaluating various target detection models on the DUO dataset. The results indicate that these models achieve a limited detection accuracy for the scallops category. We surmise that this discrepancy arises from the scarcity of scallop instances in the dataset, leading to the inadequate learning of this specific category during the training phase. Consequently, we can infer that the detection accuracy of a model for any given category is correlated to the number of instances available within the dataset. Regarding the overall results, our model achieved an exceptional mAP of 84.6%, surpassing all other detection models. Additionally, our model exhibited the highest AP among all individual categories. Figure 13 visually portrays the detection outcomes of each target detection model on the DUO dataset. Significantly, our model demonstrated a superior performance by detecting a more comprehensive range of targets with greater confidence. A further analysis revealed that the YOLOv7-CHS model also enhances the detection accuracy on the DUO dataset. This finding underscores the adaptability of the YOLOv7-CHS model in diverse underwater environments.
Table 5.
Comparisons of different object detectors on the DUO dataset. The bolded numbers are the best results in that column of numbers.
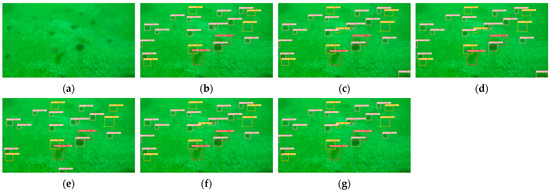
Figure 13.
Detection results on the DUO dataset. (a) Original image. (b) Results of the Swin-Transformer detector. (c) Results of the YOLOv4s-mish detector. (d) Results of the YOLOv5s detector. (e) Results of the YOLOv7-tiny detector. (f) Results of the YOLOv7 detector. (g) Results of the YOLOv7-CHS detector.
Figure 14 illustrates the confusion matrices for the YOLOv7 and YOLOv7-CHS models. Darker color blocks along the diagonal of the confusion matrix indicate a higher accuracy in the model’s detection results. It is evident that the confusion matrix of the YOLOv7 network exhibits a more scattered color block distribution, with lighter color blocks along the diagonal. This suggests that the model has a higher error rate in detecting various classes of objects. In contrast, the confusion matrix of the YOLOv7-CHS network displays a darker color on the diagonal and a more concentrated color block distribution. These characteristics indicate an improvement in accuracy for the enhanced model, particularly in detecting small underwater targets. Therefore, based on the comparison of these confusion matrices, it can be concluded that the YOLOv7-CHS model outperforms the original model in detecting objects across all classes.
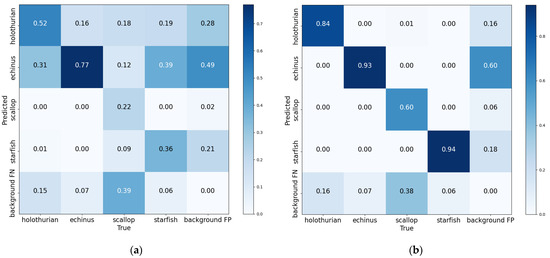
Figure 14.
Confusion matrix comparison results for YOLOv7 and YOLOv7-CHS. (a) YOLOv7. (b) YOLOv7-CHS.
5. Conclusions
This paper presented a comparative analysis of various image enhancement algorithms to assess their effect on target detection accuracy. The findings indicate that there is no positive correlation between image enhancement techniques and improved detection accuracy. Subsequently, it introduced the YOLOv7-CHS model, which incorporates the HOSI module, CT3 module, and SPFA module into the YOLOv7 architecture. The comparative results demonstrate that this model had a lower computational load, with only 40.3 G FLOPs, which is 62.9 G less than the original YOLOv7 model. This reduction in FLOPs is advantageous for model deployment. The evaluation of the Starfish dataset reveals that the YOLOv7-CHS model achieved a mAP of 52.8%, which is 4.5% higher than the performance of the YOLOv7 model. The detection speed reached 32 FPS, enabling real-time detection capabilities. Moreover, when applied to the DUO dataset, the YOLOv7-CHS model achieved an mAP of 84.6%, which is 4.2% better than the YOLOv7 model. This demonstrates the model’s adaptability to diverse underwater environments and highlights its robustness and generalization capabilities. Despite the significant advancements achieved by the YOLOv7-CHS model in underwater object detection, further improvements are warranted, particularly in terms of speed and model size. Future research should focus on optimizing the proposed model to enhance its performance in small target detection tasks within oceanic settings. By addressing these areas of improvement, we aim to contribute to the broader field of underwater object detection and pave the way for practical applications in various domains.
Author Contributions
Conceptualization, L.Z. and Q.Y.; Data curation, X.R.; Formal analysis, L.Z., Q.Y. and F.Y.; Funding acquisition, L.Z.; Investigation, L.Z.; Methodology, L.Z.; Project administration, L.Z.; Resources, J.J. and X.Z.; Software, Q.Y.; Supervision, L.Z. and F.Y.; Validation, Q.Y. and X.R.; Visualization, X.Z.; Writing—original draft, Q.Y.; Writing—review and editing, L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Nature Science Foundation of China (Nos. 61473114 and 62106068), the Science and Technology Research Project of Henan Province (No. 222102210058), the Fundamental Research Funds for Henan Provincial Colleges and Universities at the Henan University of Technology (No. 2018RCJH16), and the Research Foundation for Advanced Talents of Henan University of Technology (No. 31401529).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study can be found at https://github.com/chongweiliu/DUO (accessed on 16 October 2021) and https://www.kaggle.com/competitions/tensorflow-great-barrier-reef/data (accessed on 1 October 2021).
Acknowledgments
This research was supported by the Henan University of Technology, College of Electrical Engineering.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, F.; Zhu, J.; Chen, L.; Zuo, Y.; Hu, X.; Yang, Y. Autonomous and In Situ Ocean Environmental Monitoring on Optofluidic Platform. Micromachines 2020, 11, 69. [Google Scholar] [CrossRef]
- Qi, S.; Du, J.F.; Wu, M.; Yi, H.; Tang, L.; Qian, T.; Wang, X. Underwater Small Target Detection Based on Deformable Convolutional Pyramid. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2784–2788. [Google Scholar]
- Yuan, X.; Guo, L.; Luo, C.; Zhou, X.; Yu, C. A Survey of Target Detection and Recognition Methods in Underwater Turbid Areas. Appl. Sci. 2022, 12, 4898. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2022, 132, 103812. [Google Scholar] [CrossRef]
- Hua, X.; Cui, X.; Xu, X.Y.; Qiu, S.; Liang, Y.-Y.; Bao, X.; Li, Z. Underwater object detection algorithm based on feature enhancement and progressive dynamic aggregation strategy. Pattern Recognit. 2023, 139, 109511. [Google Scholar] [CrossRef]
- Fayaz, S.; Parah, S.A.; Qureshi, G.J. Underwater object detection: Architectures and algorithms—A comprehensive review. Multimed. Tools Appl. 2022, 81, 20871–20916. [Google Scholar] [CrossRef]
- Qi, J.; Gong, Z.; Xue, W.; Liu, X.; Yao, A.; Zhong, P. An Unmixing-Based Network for Underwater Target Detection From Hyperspectral Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5470–5487. [Google Scholar] [CrossRef]
- Li, M.; Mathai, A.; Lau, S.L.H.; Yam, J.W.; Xu, X.; Wang, X. Underwater Object Detection and Reconstruction Based on Active Single-Pixel Imaging and Super-Resolution Convolutional Neural Network. Sensors 2021, 21, 313. [Google Scholar] [CrossRef]
- Khan, S.; Ullah, I.; Ali, F.; Shafiq, M.; Ghadi, Y.Y.; Kim, T. Deep learning-based marine big data fusion for ocean environment monitoring: Towards shape optimization and salient objects detection. Front. Mar. Sci. 2023, 9, 1094915. [Google Scholar] [CrossRef]
- Lei, F.; Tang, F.; Li, S. Underwater Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Dinakaranr, R.; Zhang, L.; Li, C.; Bouridane, A.; Jiang, R.M. Robust and Fair Undersea Target Detection with Automated Underwater Vehicles for Biodiversity Data Collection. Remote Sens. 2022, 14, 3680. [Google Scholar] [CrossRef]
- Fu, C.Z.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2022, 517, 243–256. [Google Scholar] [CrossRef]
- Liang, X.; Song, P. Excavating RoI Attention for Underwater Object Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2651–2655. [Google Scholar]
- Malathi, V.; Manikandan, A.; Krishnan, K. Optimzied resnet model of convolutional neural network for under sea water object detection and classification. Multimed. Tools Appl. 2023, 82, 37551–37571. [Google Scholar] [CrossRef]
- Zhao, S.; Zheng, J.; Sun, S.; Zhang, L. An Improved YOLO Algorithm for Fast and Accurate Underwater Object Detection. Symmetry 2022, 14, 1669. [Google Scholar] [CrossRef]
- Pan, T.-S.; Huang, H.-C.; Lee, J.-C.; Chen, C.-H. Multi-scale ResNet for real-time underwater object detection. Signal Image Video Process. 2020, 15, 941–949. [Google Scholar] [CrossRef]
- Li, X.; Yu, H.; Chen, H. Multi-scale aggregation feature pyramid with cornerness for underwater object detection. Vis. Comput. 2023, 1–12. [Google Scholar] [CrossRef]
- Cai, S.; Li, G.; Shan, Y. Underwater object detection using collaborative weakly supervision. Comput. Electr. Eng. 2022, 102, 108159. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Lin, C.-H.; Kang, L.-W.; Huang, C.-H.; Lin, M.-H.; Chang, C.-Y.; Wang, C.-C. Lightweight Deep Neural Network for Joint Learning of Underwater Object Detection and Color Conversion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6129–6143. [Google Scholar] [CrossRef]
- Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. [Google Scholar] [CrossRef]
- Tan, C.; Chen, D.; Huang, H.; Yang, Q.; Huang, X. A Lightweight Underwater Object Detection Model: FL-YOLOV3-TINY. In Proceedings of the 2021 IEEE 12th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 27–30 October 2021; pp. 127–133. [Google Scholar]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-Time Underwater Maritime Object Detection in Side-Scan Sonar Images Based on Transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Athira, P.K.; Mithun Haridas, T.P.; Supriya, M.H. Underwater Object Detection model based on YOLOv3 architecture using Deep Neural Networks. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 40–45. [Google Scholar]
- Zhang, J.; Zhang, J.; Zhou, K.; Zhang, Y.; Chen, H.; Yan, X. An Improved YOLOv5-Based Underwater Object-Detection Framework. Sensors 2023, 23, 3693. [Google Scholar] [CrossRef]
- Song, P.; Liu, H.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN Samples by RPN’s Error for Underwater Object Detection. arXiv 2022, arXiv:2206.13728. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.M.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Lu, X.; Wu, B. CME-YOLOv5: An Efficient Object Detection Network for Densely Spaced Fish and Small Targets. Water 2022, 14, 2412. [Google Scholar] [CrossRef]
- Alsubaei, F.S.; Al-Wesabi, F.N.; Hilal, A.M. Deep Learning-Based Small Object Detection and Classification Model for Garbage Waste Management in Smart Cities and IoT Environment. Appl. Sci. 2022, 12, 2281. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, F.; Wang, S.; Dong, J.; Li, N.; Ma, H.; Wang, X.; Zhou, H. SWIPENET: Object detection in noisy underwater scenes. Pattern Recognit. 2022, 132, 108926. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Xu, F.; Ding, X.; Peng, J.; Yuan, G.; Wang, Y.; Zhang, J.; Fu, X. Real-Time Detecting Method of Marine Small Object with Underwater Robot Vision. In Proceedings of the 2018 OCEANS—MTS/IEEE Kobe Techno-Oceans (OTO), Kobe, Japan, 28–31 May 2018; pp. 1–4. [Google Scholar]
- Lim, J.-S.; Astrid, M.; Yoon, H.; Lee, S.-I. Small Object Detection using Context and Attention. In Proceedings of the 2021 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 13–16 April 2019; pp. 181–186. [Google Scholar]
- Xu, S.; Zhang, M.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Zuiderveld, K.J. Contrast Limited Adaptive Histogram Equalization. In Graphics Gems; Elsevier B.V.: Amsterdam, the Netherlands, 1994. [Google Scholar]
- Malhotra, M. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 33, 2341–2353. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8877–8886. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.N.; Lu, J. HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions. arXiv 2022, arXiv:2207.14284. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 45, 1489–1500. [Google Scholar] [CrossRef]
- Guo, M.-H.; Xu, T.; Liu, J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2021, 8, 331–368. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.-Y.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Liu, J.; Kusy, B.; Marchant, R.; Do, B.; Merz, T.; Crosswell, J.R.; Steven, A.D.L.; Heaney, N.; Richter, K.v.; Tychsen-Smith, L.; et al. The CSIRO Crown-of-Thorn Starfish Detection Dataset. arXiv 2021, arXiv:2111.14311. [Google Scholar]
- Liu, C.; Li, H.; Wang, S.; Zhu, M.; Wang, D.; Fan, X.; Wang, Z. A Dataset and Benchmark of Underwater Object Detection for Robot Picking. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).