
The Development of a Lightweight DE-YOLO Model for Detecting Impurities and Broken Rice Grains


Abstract
1. Introduction
2. Materials and Methods
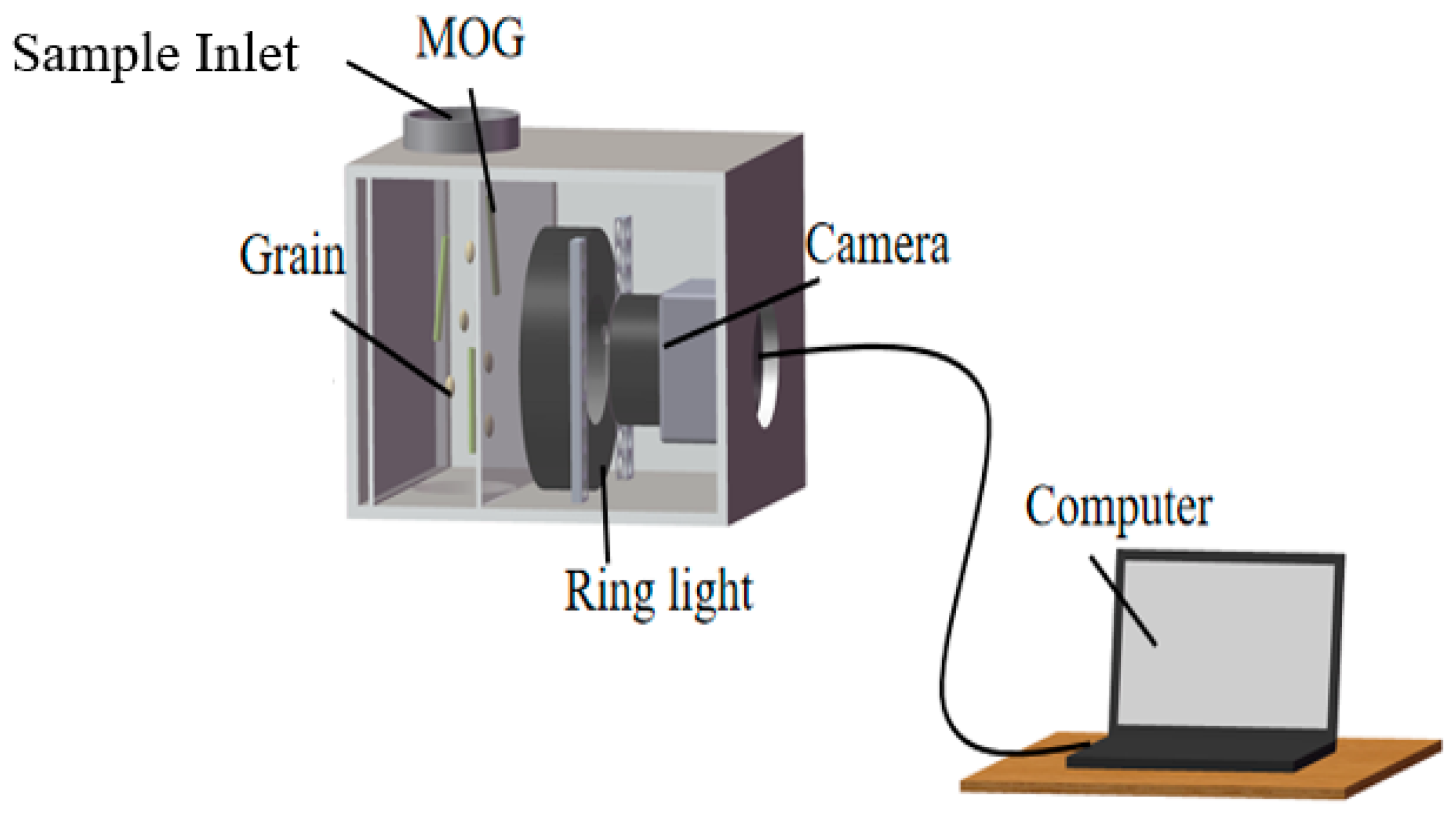
2.1. Data Collection
2.2. Image Annotation and Dataset Creation
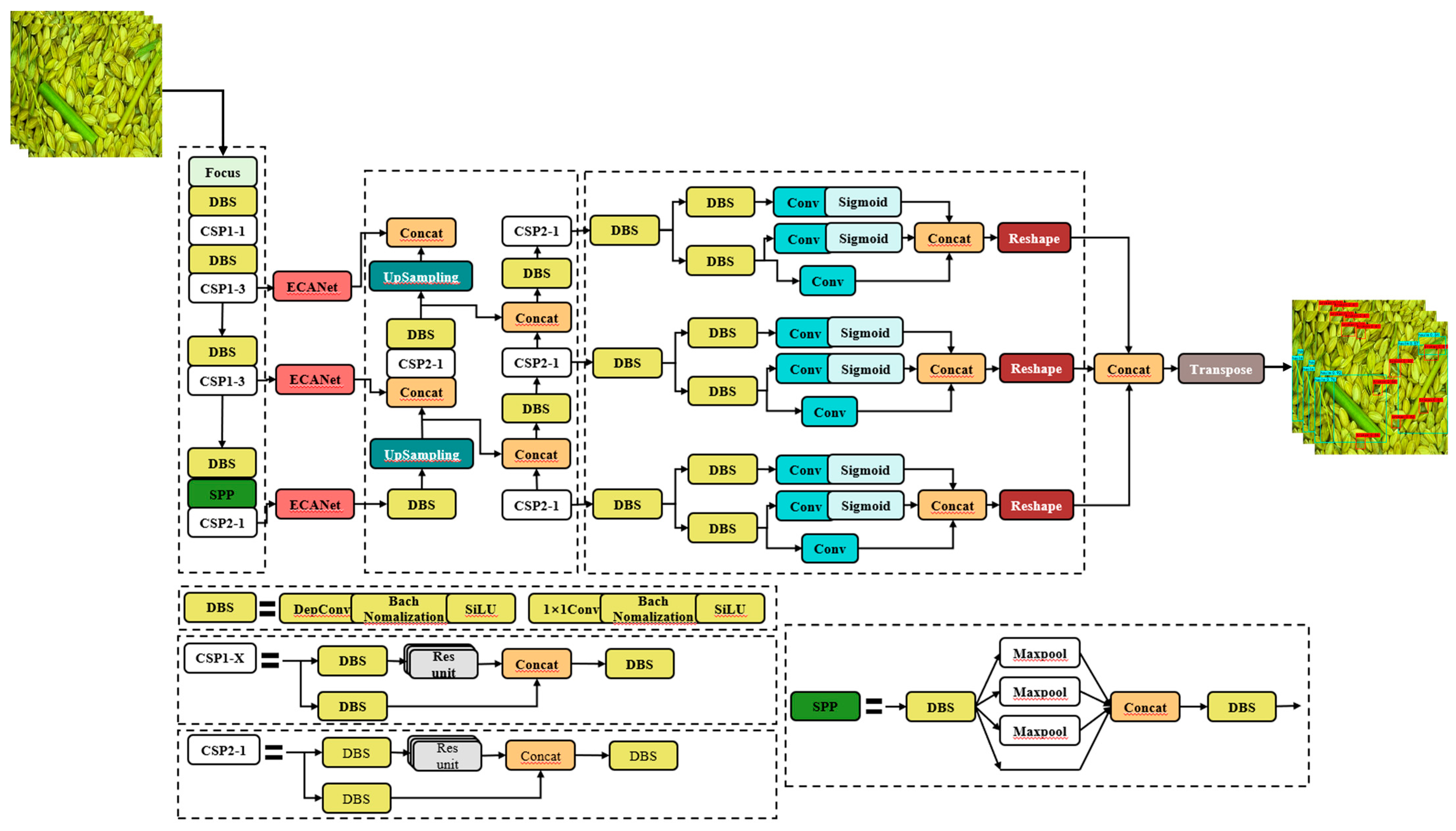
2.3. DE-YOLO Model Methodology
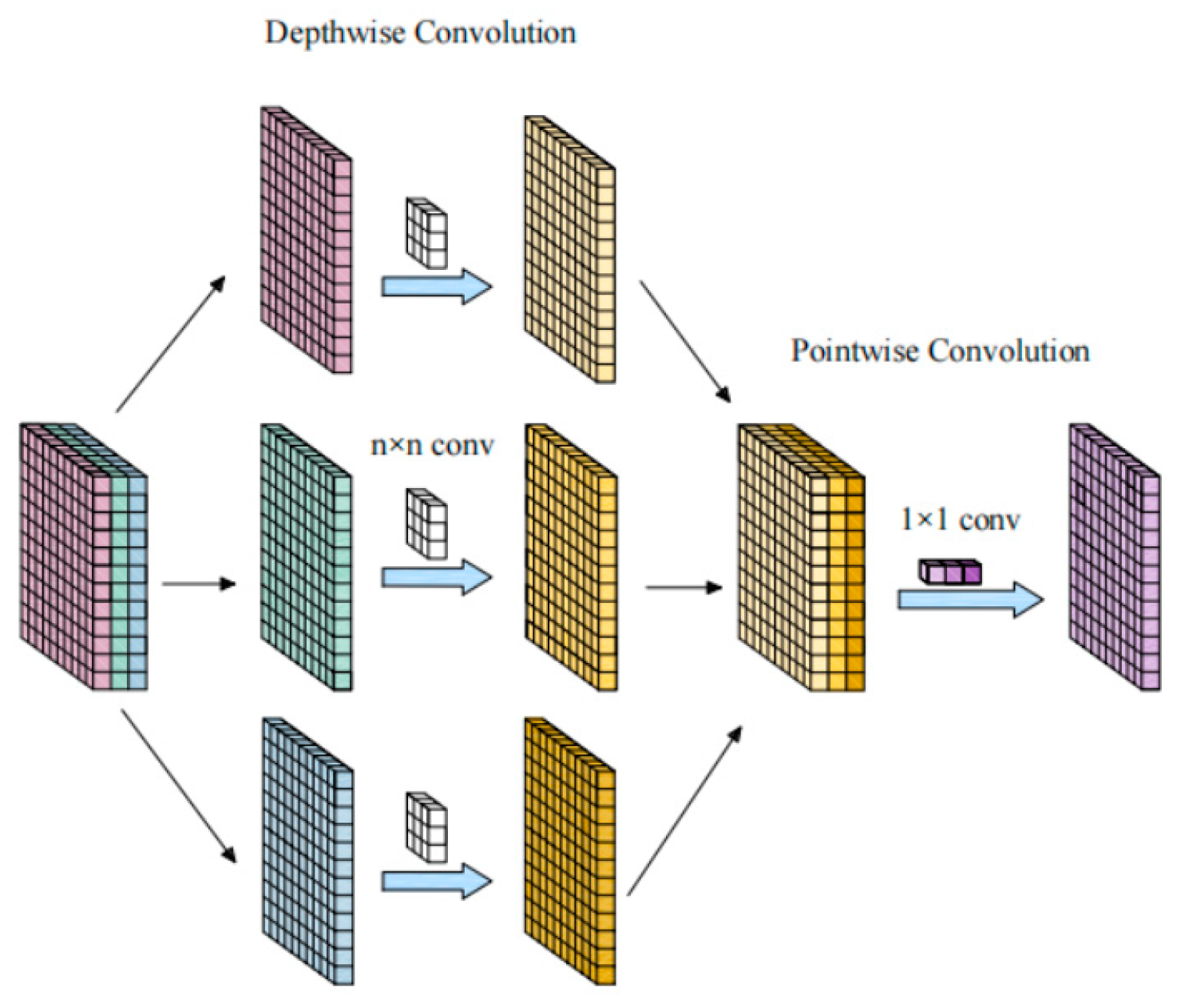
2.3.1. Model Lightweighting
2.3.2. Attention Mechanism
2.3.3. Loss Function: Focal Loss
2.4. Experimental Environment
3. Results and Discussion
3.1. Analysis of Ablation Experiment Results Based on YOLOX
3.2. Comparison of Experimental Results with Different Attention Mechanisms
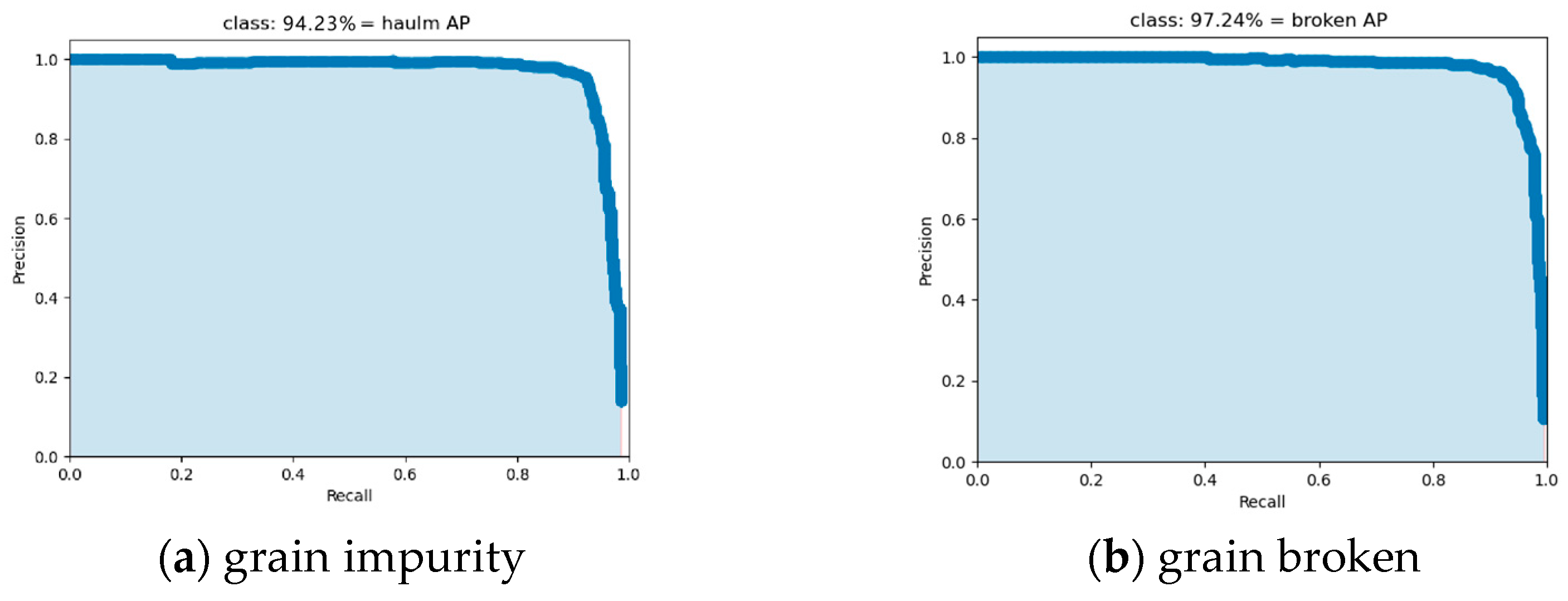
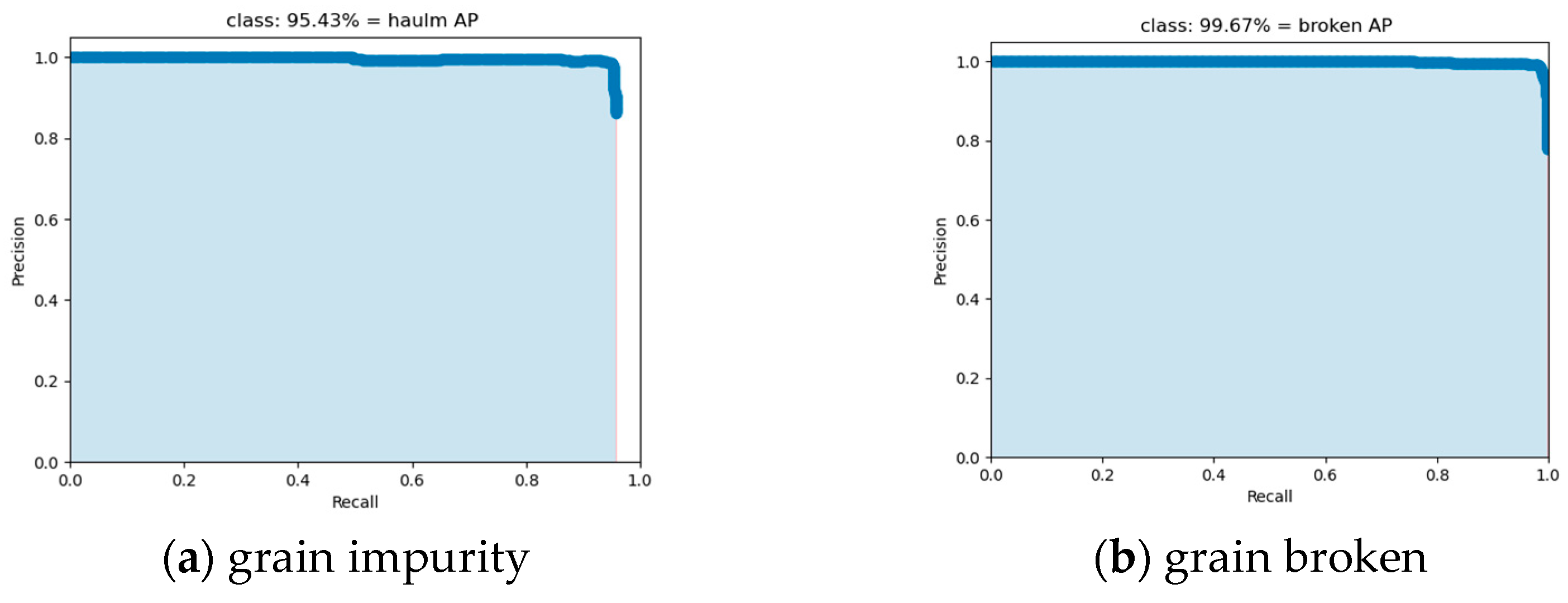
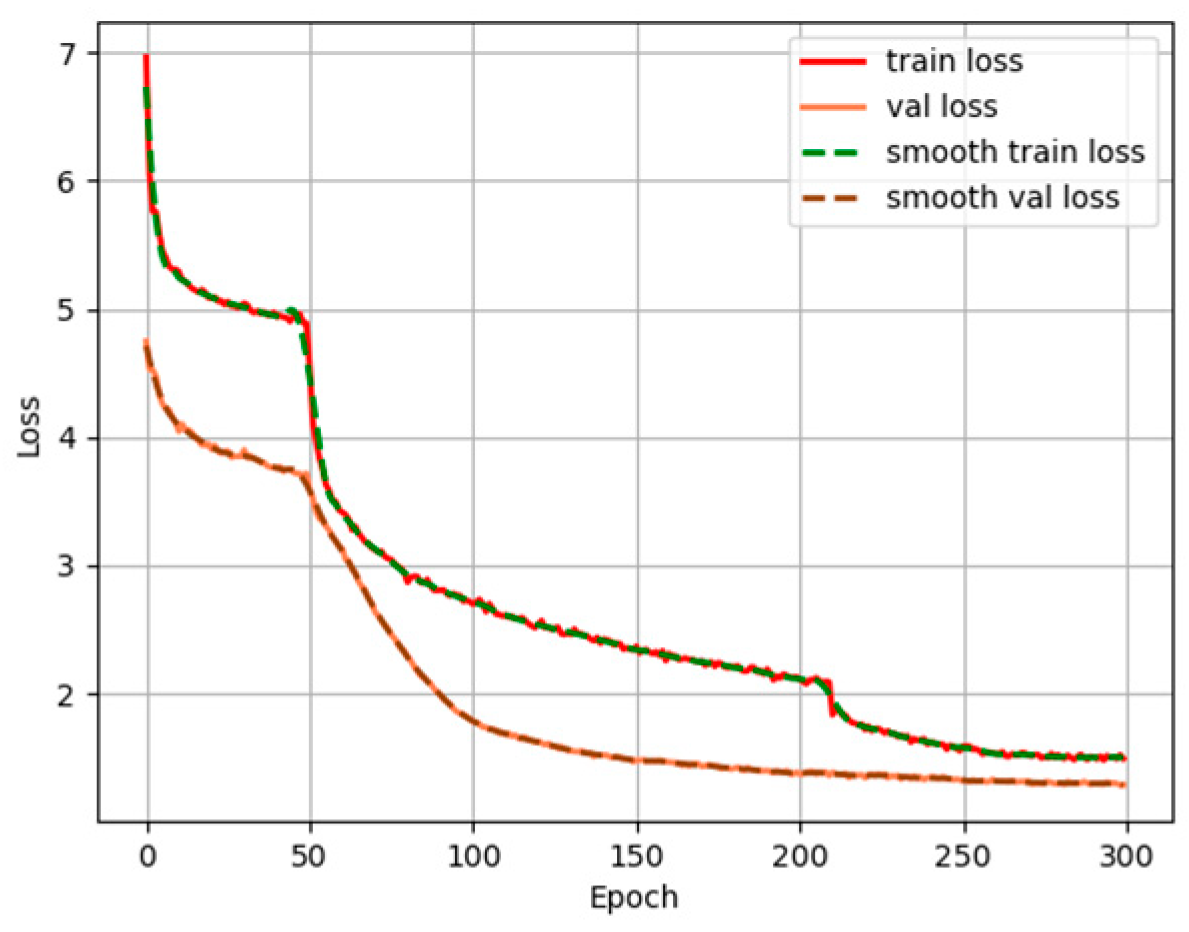
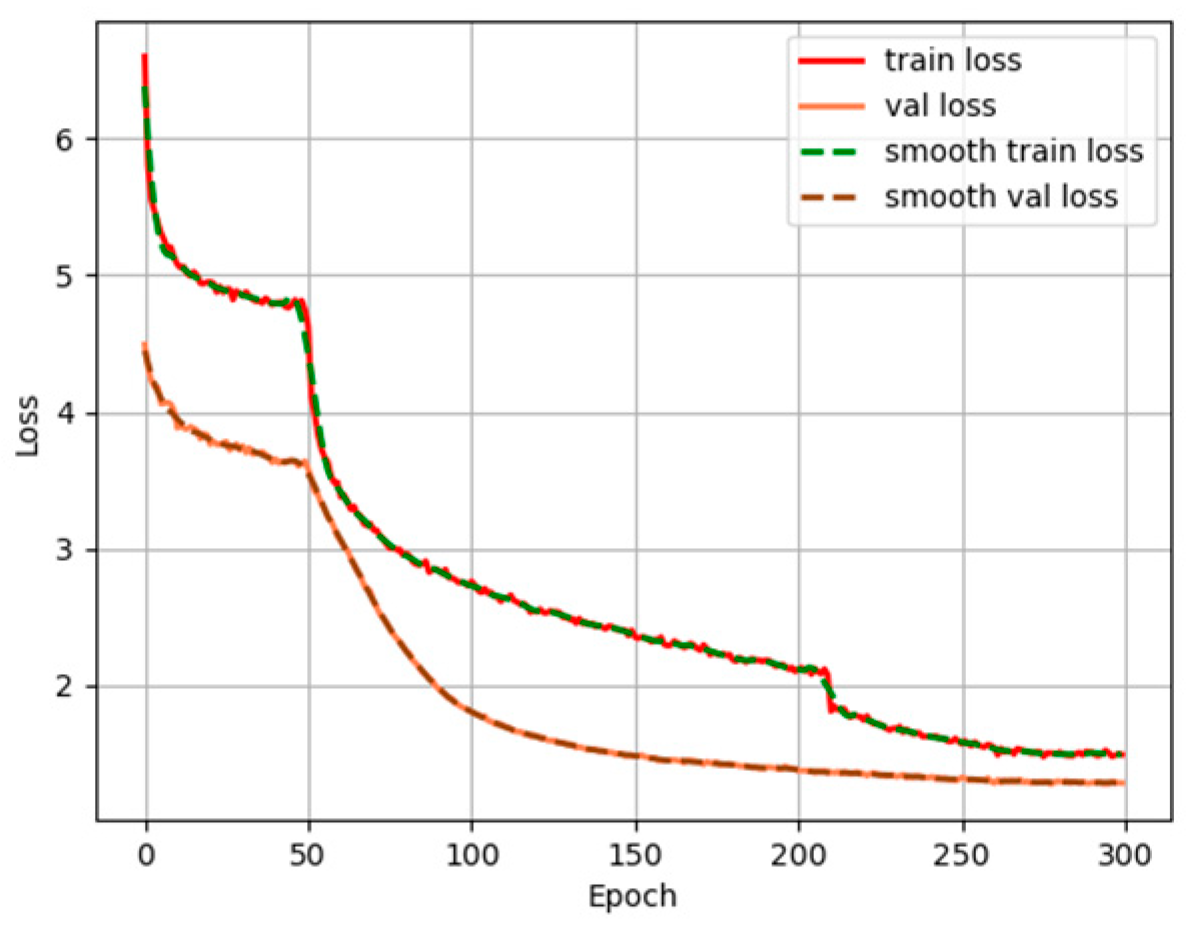
3.3. Comparison of Detection Results of Different Models
4. Conclusions
- (1)
- Research Innovation and Methodology: To improve the detection accuracy of rice impurities and broken grains, this study proposes an improved YOLOX model—DE-YOLO. We replace the standard convolution module (CBS) in the YOLOX-s network with a Depthwise Separable Convolution module (DBS), which significantly reduces the model’s parameter size and achieves lightweight optimization. This makes DE-YOLO more efficient and suitable for deployment on resource-constrained mobile devices. To address the class imbalance caused by color similarity in rice samples, we use the Focal Loss function instead of the traditional binary cross-entropy (BCE) loss function, significantly improving the accuracy when handling small sample classes. To further enhance the detection accuracy of rice targets, particularly small targets such as broken grains and rice straw, the DE-YOLO model incorporates the ECANet attention mechanism module into the YOLOX-s backbone feature extraction network. This module effectively enhances the model’s attention to valid features while suppressing irrelevant features, further improving the detection capability for small targets. These improvements make DE-YOLO a highly efficient, accurate, and lightweight algorithm for rice target detection, so it is particularly suitable for detecting rice impurities and broken grains.
- (2)
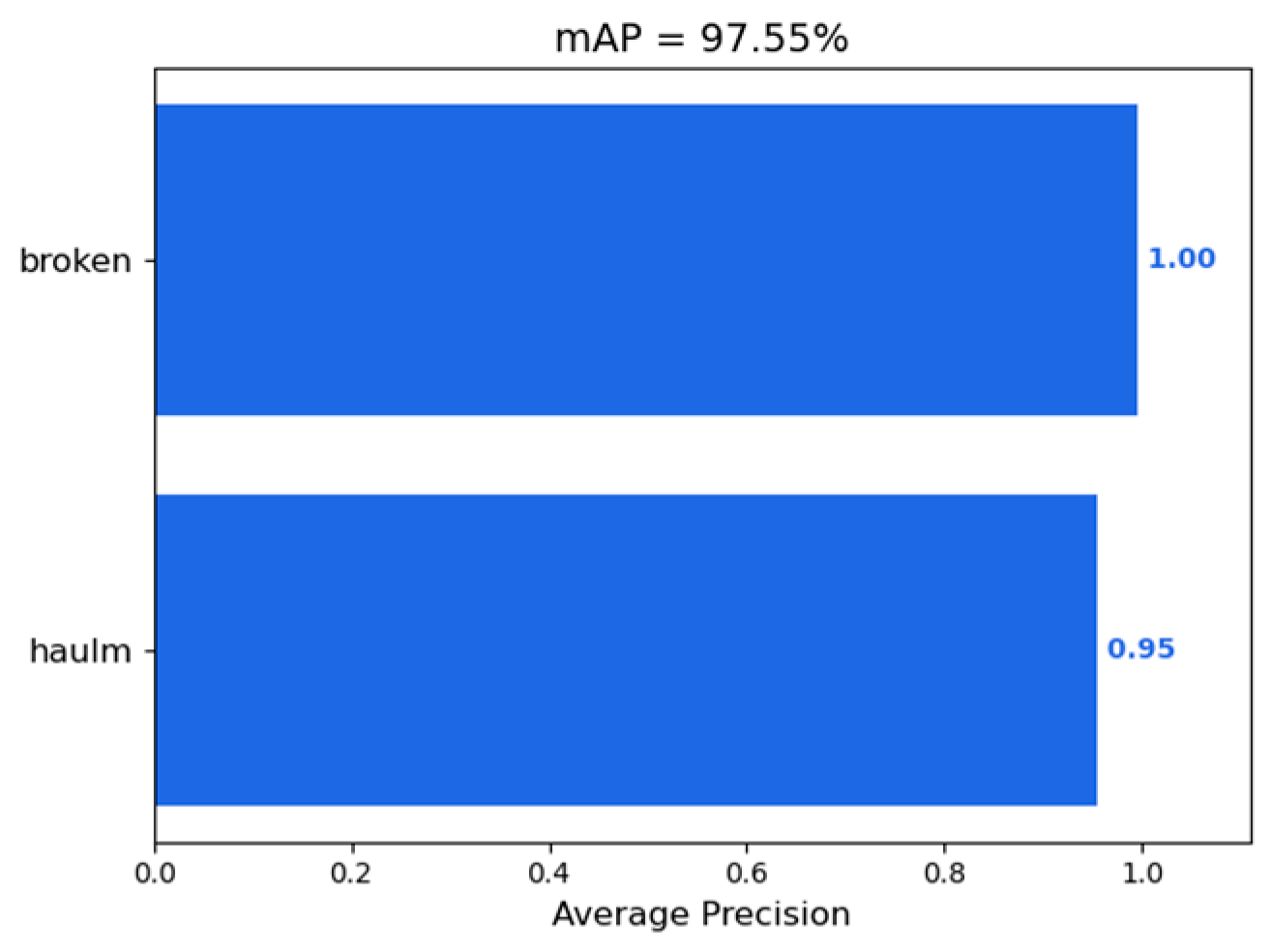
- Experimental Results and Performance Verification: The experimental results show that DE-YOLO significantly outperforms traditional YOLO models in rice target detection. Compared to Faster R-CNN, YOLOv3, YOLOv5, YOLOX, and YOLOv8, DE-YOLO demonstrates superior precision and recall, especially in detecting small rice targets such as broken grains and impurities. Specifically, DE-YOLO achieves a precision of 96.66%, a recall of 94.46%, a mean average precision (mAP) of 97.55%, and an F1-score of 0.96%. These excellent performance results indicate that DE-YOLO not only maintains high accuracy while reducing model computation but also enhances the detection capability for small targets in rice samples. It has a significant advantage in detecting impurities and broken grains in complex backgrounds. Therefore, DE-YOLO provides an efficient and reliable solution for rice target detection, especially for impurity and broken grain detection, with promising application prospects in unmanned combine harvesters for grain impurity and broken monitoring.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ali, F.; Jighly, A.; Joukhadar, R.; Niazi, N.K.; Al-Misned, F. Current Status and Future Prospects of Head Rice Yield. Agriculture 2023, 13, 705. [Google Scholar] [CrossRef]
- Chen, S.; Zhou, Y.; Tang, Z.; Lu, S. Modal vibration response of rice combine harvester frame under multi-source excitation. Biosyst. Eng. 2020, 194, 177–195. [Google Scholar] [CrossRef]
- Qing, Y.R.; Li, Y.M.; Xu, L.Z.; Ma, Z.; Tan, X.L.; Wang, Z. Oilseed rape (Brassica napus L.) pod shatter resistance and its relationship with whole plant and pod characteristics. Ind. Crops Prod. 2021, 166, e113459. [Google Scholar] [CrossRef]
- Qing, Y.; Li, Y.; Yang, Y.; Xu, L.; Ma, Z. Development and experiments on reel with improved tine trajectory for harvesting oilseed rape. Biosyst. Eng. 2021, 206, 19–31. [Google Scholar] [CrossRef]
- Zhang, T.; Li, Y.M.; You, G.L. Experimental study on the cleaning performance of hot air flow cleaning device. Agriculture 2023, 13, 1828. [Google Scholar] [CrossRef]
- Que, K.X.; Tang, Z.; Wang, T.; Su, Z.; Ding, Z. Effects of unbalanced incentives on threshing drum stability during rice threshing. Agriculture 2024, 14, 777. [Google Scholar] [CrossRef]
- Chen, T.; Xu, L.; Ahn, H.S.; Lu, E.; Liu, Y.; Xu, R. Evaluation of headland turning types of adjacent parallel paths for combine harvesters. Biosyst. Eng. 2023, 233, 93–113. [Google Scholar] [CrossRef]
- Ma, Z.; Zhu, Y.L.; Wu, Z.P.; Traore, S.N.; Chen, D.; Xing, L.C. BP neural network model for material distribution prediction based on variable amplitude anti-blocking screening DEM simulations. Int. J. Agric. Biol. Eng. 2023, 16, 190–199. [Google Scholar] [CrossRef]
- Liu, Y.B.; Li, Y.M.; Ji, K.Z.; Yu, Z.W.; Ma, Z.; Xu, L.Z.; Niu, C.H. Development of a hydraulic variable-diameter threshing drum control system for combine harvester, part I: Adaptive monitoring method. Biosyst. Eng. 2025, 250, 174–182. [Google Scholar] [CrossRef]
- Liang, Z.; Wada, M.E. Development of cleaning systems for combine harvesters: A review. Biosyst. Eng. 2023, 236, 79–102. [Google Scholar] [CrossRef]
- Chen, Z.; Wassgren, C.; Kingsly Ambrose, R.P. A review of grain kernel damage: Mechanisms, modeling, and testing procedures. Trans. ASABE 2020, 63, 455–475. [Google Scholar] [CrossRef]
- Liu, Y.; Xin, P.; Sun, J.; Zheng, D. Oat Threshing Damage and Its Effect on Nutritional Components. Agriculture 2024, 14, 842. [Google Scholar] [CrossRef]
- Wallays, C.; Missotten, B.; De Baerdemaeker, J.; Saeys, W. Hyperspectral waveband selection for on-line measurement of grain cleanness. Biosyst. Eng. 2009, 104, 1–7. [Google Scholar] [CrossRef]
- Chen, J.; Song, J.; Guan, Z.H.; Lian, Y. Measurement of the distance from grain divider to harvesting boundary based on dynamic regions of interest. Int. J. Agric. Biol. Eng. 2021, 14, 226–232. [Google Scholar] [CrossRef]
- Luo, Y.; Wei, L.; Xu, L.; Zhang, Q.; Liu, J.; Cai, Q.B.; Zhang, W. Stereo-vision-based multi-crop harvesting edge detection for precise automatic steering of combine harvester. Biosyst. Eng. 2022, 215, 115–128. [Google Scholar] [CrossRef]
- Sun, Y.X.; Luo, Y.S.; Zhang, Q.; Xu, L.Z.; Wang, L.Y.; Zhang, P.P. Estimation of crop height distribution for mature rice based on a moving surface and 3D point cloud elevation. Agronomy 2022, 12, 836. [Google Scholar] [CrossRef]
- Niu, Y.X.; Han, W.T.; Zhang, H.H.; Zhang, L.Y.; Chen, H.P. Estimating maize plant height using a crop surface model constructed from UAV RGB images. Biosyst. Eng. 2024, 241, 56–67. [Google Scholar] [CrossRef]
- Mahirah, J.; Yamamoto, K.; Miyamoto, M.; Kondo, N.; Ogawa, Y.; Suzuki, T.; Habaragamuwa, H.; Ahmad, U. Double lighting machine vision system to monitor harvested paddy grain quality during head-feeding combine harvester operation(Article). Machines 2015, 3, 352–363. [Google Scholar] [CrossRef]
- Suchart, Y.; Chokcharat, R. An Effective Method for Classification of White Rice Grains Using Various Image Processing Techniques. In Proceedings of the 3rd International Conference on Intelligent Technologies and Engineering Systems (ICITES2014), Cheng Shiu University, Kaohsiung, Taiwan, 19–21 December 2014; pp. 91–97. [Google Scholar]
- Chen, J.; Gu, Y.; Lian, Y.; Han, M. Online recognition method of impurities and broken paddy grains based on machine vision. Trans. Chin. Soc. Agric. Eng. 2018, 34, 187–194. [Google Scholar] [CrossRef]
- Ma, Z.Y.; Zhang, X.K.; Yang, G.Y. Research on segmentation method of rice stem impurities based on improved Mask R-CNN. J. Chin. Agric. Mech. 2021, 42, 145–150. [Google Scholar] [CrossRef]
- Chen, J.; Han, M.; Lian, Y.; Zhang, S. Segmentation of impurity rice grain images based on U-Net model. Trans. Chin. Soc. Agric. Eng. 2020, 36, 174–180. [Google Scholar] [CrossRef]
- Wu, Z.P.; Chen, J.; Ma, Z.; Li, Y.M.; Zhu, Y.L. Development of a lightweight online detection system for impurity content and broken rate in rice for combine harvesters. Comput. Electron. Agric. 2024, 218, 108689. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, S.; Li, Y.M.; Zhu, L.J.; Xia, H.; Zhu, Y.H. Research on online identification system of rice broken impurities in combine harvester. J. Chin. Agric. Mech. 2021, 42, 137–144. [Google Scholar] [CrossRef]
- Lian, Y.; Gong, S.J.; Sun, M.Y. Sampling box with damper for grain condition monitoring device of combine harvester. Chin. Hydraul. Pneum. 2022, 46, 71–78. [Google Scholar]
- Cai, Q.B. On-Line Monitoring Method and Experimental Study on Impurity and Broken Rate of Rice, Wheat and Rapeseed; China Jiangsu University: Zhenjiang, China, 2022. [Google Scholar]
- Zhang, Q.; Hu, J.P.; Xu, L.Z.; Cai, X.Y.; Liu, P. Impurity/Breakage assessment of vehicle-mounted dynamic rice grain flow on combine harvester based on improved Deeplabv3+ and YOLOv4. IEEE Access 2023, 11, 49273–49288. [Google Scholar] [CrossRef]
- Han, X.; Chang, J.; Wang, K. You only look once: Unified, real-time object detection. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Ultralytics. Comprehensive Guide to Ultralytics YOLOv5. Available online: https://docs.ultralytics.com/zh/yolov5 (accessed on 28 May 2024).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. Yolov6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar] [CrossRef]
- Wang, H.; Yun, L.; Yang, C.; Wu, M.; Wang, Y.; Chen, Z. OW-YOLO: An Improved YOLOv8s Lightweight Detection Method for Obstructed Walnuts. Agriculture 2025, 15, 159. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Ji, W.; Pan, Y.; Xu, B.; Wang, J. A Real-Time Apple Targets Detection Method for Picking Robot Based on ShufflenetV2-YOLOX. Agriculture 2022, 12, 856. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, Y.; Zhao, Y.; Pan, Q.; Jin, K.; Xu, G.; Hu, Y. Ts-yolo: An all-day and lightweight tea canopy shoots detection model. Agronomy 2023, 13, 1411. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar] [CrossRef]
- Wag, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Eficient channel attention for deep convolutional neural networks. In Proceedings of the Proe, IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Online, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Dina, A.S.; Siddique, A.B.; Manivannan, D. A deep learning approach for intrusion detection in Internet of Things using focal loss function. Internet Things 2023, 22, 100699. [Google Scholar] [CrossRef]
- Srivastava, H.; Sarawadekar, K. A depth wise separable convolution architecture for CNN accelerator. In Proceedings of the 2020 IEEE Applied Signal Processing Conference (ASPCON), Kolkata, India, 7–9 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Rong, Y.; Ma, Z.; Quan, G.; Tong, L.; Shao, G.; Wang, B. Target detection of tea disease based on improved YOLOv5s-ECA-ASFF algorithm. J. Chin. Agric. Mech. 2024, 45, 244. [Google Scholar] [CrossRef]
- Su, J.; Liu, Z.; Zhang, J.; Sheng, V.S.; Song, Y.; Zhu, Y.; Liu, Y. DV-Net: Accurate liver vessel segmentation via dense connection model with D-BCE loss function. Knowl. Based Syst. 2021, 232, 107471. [Google Scholar] [CrossRef]
- Li, Z.C.; Ling, X.J.; Li, H.Q.; Luo, W.P. Object detection method for chestnut peng in the tree based on improved YOLOv3. J. Chin. Agric. Mech. 2024, 45, 209. [Google Scholar] [CrossRef]
- Liang, M.; Zhang, Y.; Zhou, J.; Shi, F.; Wang, Z.; Lin, Y.; Liu, Y. Research on detection of wheat tillers in natural environment based on YOLOv8-MRF. Smart Agric. Technol. 2024, 10, 100720. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DSConv | Focal Loss | ECANet | mAP | Parameters | GFLOPS |
|---|---|---|---|---|---|---|
| YOLOX | 94.65% | 9.0 M | 13.08 | |||
| Model1 | √ | 92.86% | 4.0 M | 6.53 | ||
| Model2 | √ | √ | 95.14% | 4.2 M | 6.71 | |
| Model3 | √ | √ | 94.76% | 4.2 M | 6.88 | |
| Model4 | √ | √ | 97.42% | 9.0 M | 13.26 | |
| DE-YOLO | √ | √ | √ | 97.55% | 4.6 M | 7.02 |
| Serial Number | Precision% | Recall% | mAP% | F1-Score |
|---|---|---|---|---|
| Model2 | 94.08 | 92.46 | 95.14 | 0.94 |
| Model2 + SENet | 95.78 | 93.03 | 96.89 | 0.95 |
| Model2 + CBAM | 95.42 | 94.25 | 97.29 | 0.95 |
| DE-YOLO | 96.66 | 94.46 | 97.55 | 0.96 |
| Model | Precision% | Recall% | mAP% | F1-Score | Parameters |
|---|---|---|---|---|---|
| YOLOv3 | 93.68 | 92.39 | 94.63 | 0.94 | 62 M |
| YOLOv5 | 94.94 | 93.51 | 95.26 | 0.94 | 7.3 M |
| YOLOX | 94.08 | 92.46 | 94.65 | 0.94 | 9.0 M |
| DE-YOLO | 96.66 | 94.46 | 97.55 | 0.96 | 4.6 M |
| YOLOv8 | 96.89 | 95.41 | 98.26 | 0.96 | 11.2 M |
| Faster R-CNN | 88.52 | 86.93 | 89.71 | 0.88 | 41 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Xu, X.; Yang, D.; Liu, Y. The Development of a Lightweight DE-YOLO Model for Detecting Impurities and Broken Rice Grains. Agriculture 2025, 15, 848. https://doi.org/10.3390/agriculture15080848
Liang Z, Xu X, Yang D, Liu Y. The Development of a Lightweight DE-YOLO Model for Detecting Impurities and Broken Rice Grains. Agriculture. 2025; 15(8):848. https://doi.org/10.3390/agriculture15080848
Chicago/Turabian StyleLiang, Zhenwei, Xingyue Xu, Deyong Yang, and Yanbin Liu. 2025. "The Development of a Lightweight DE-YOLO Model for Detecting Impurities and Broken Rice Grains" Agriculture 15, no. 8: 848. https://doi.org/10.3390/agriculture15080848
APA StyleLiang, Z., Xu, X., Yang, D., & Liu, Y. (2025). The Development of a Lightweight DE-YOLO Model for Detecting Impurities and Broken Rice Grains. Agriculture, 15(8), 848. https://doi.org/10.3390/agriculture15080848