2.1. Subjects and Study Design
The data for 484 healthy subjects were provided from the literature [
16,
30,
31]. The measurement method of the dataset was explained in the work of Cimbiz et al. [
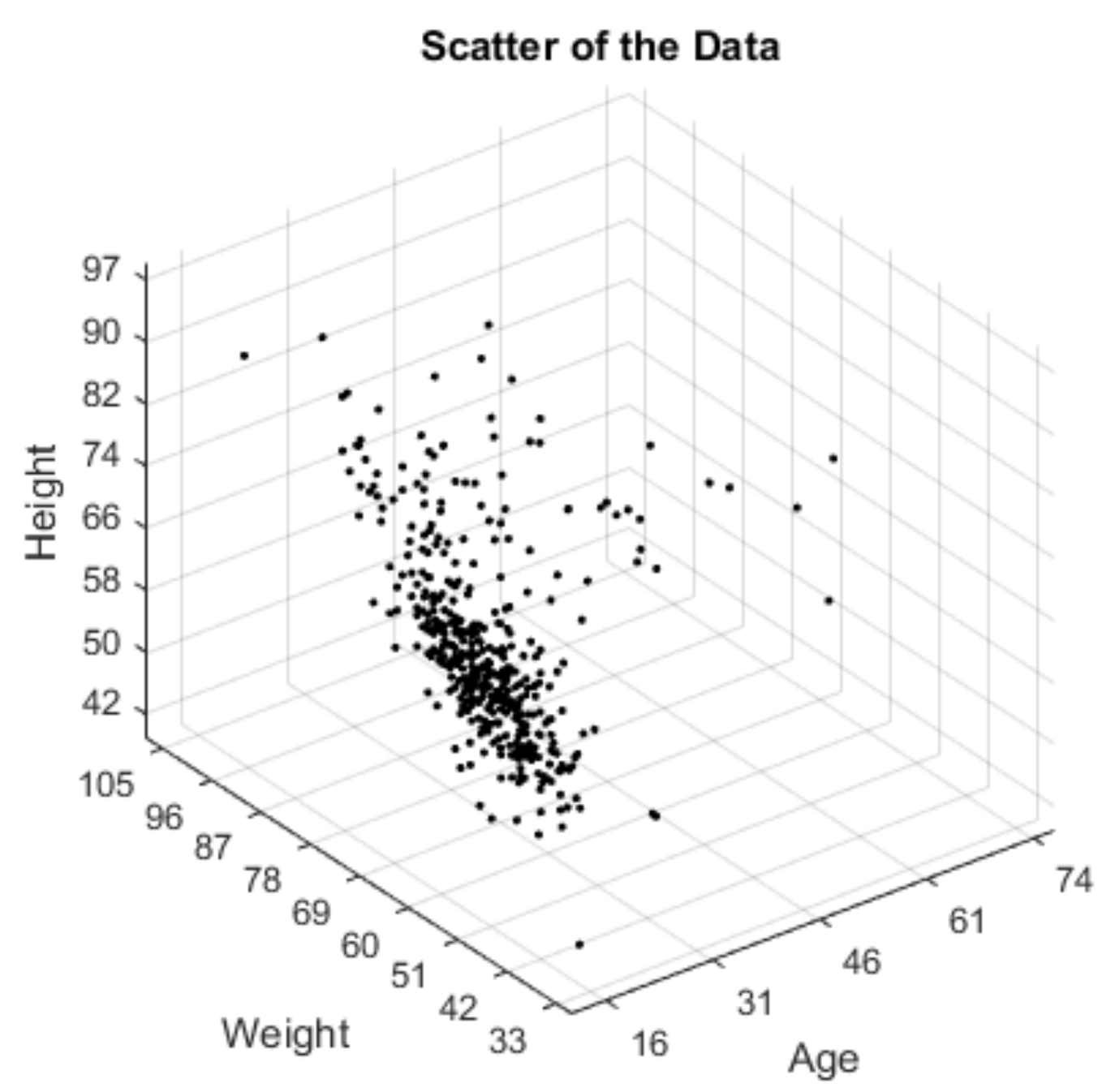
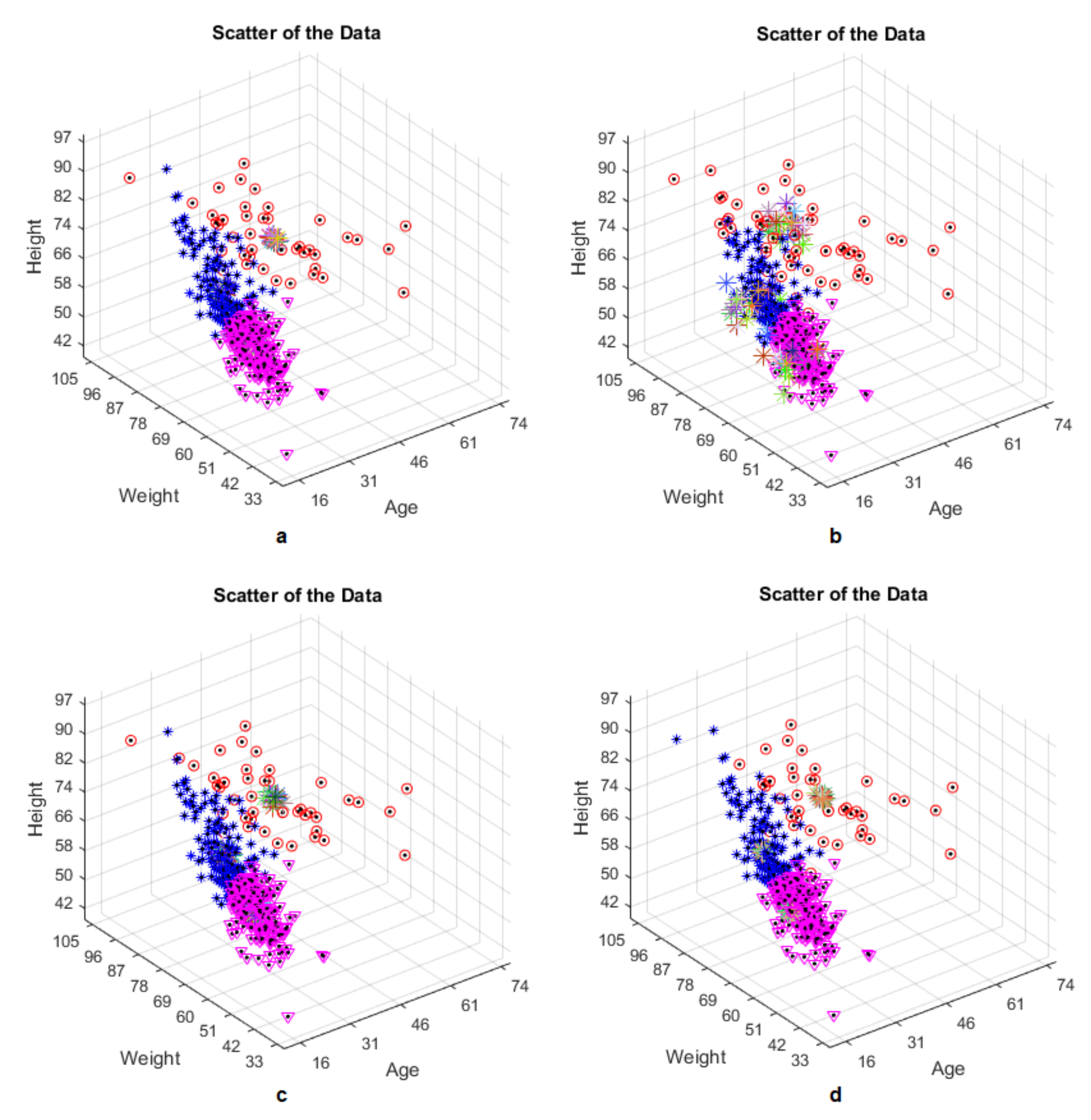
30]. The subjects do not have any health problems or knee joint injuries. The data includes measurement of age, weight and height information of 484 volunteers. The age, weight and height values of each subject are shown in
Figure 1.
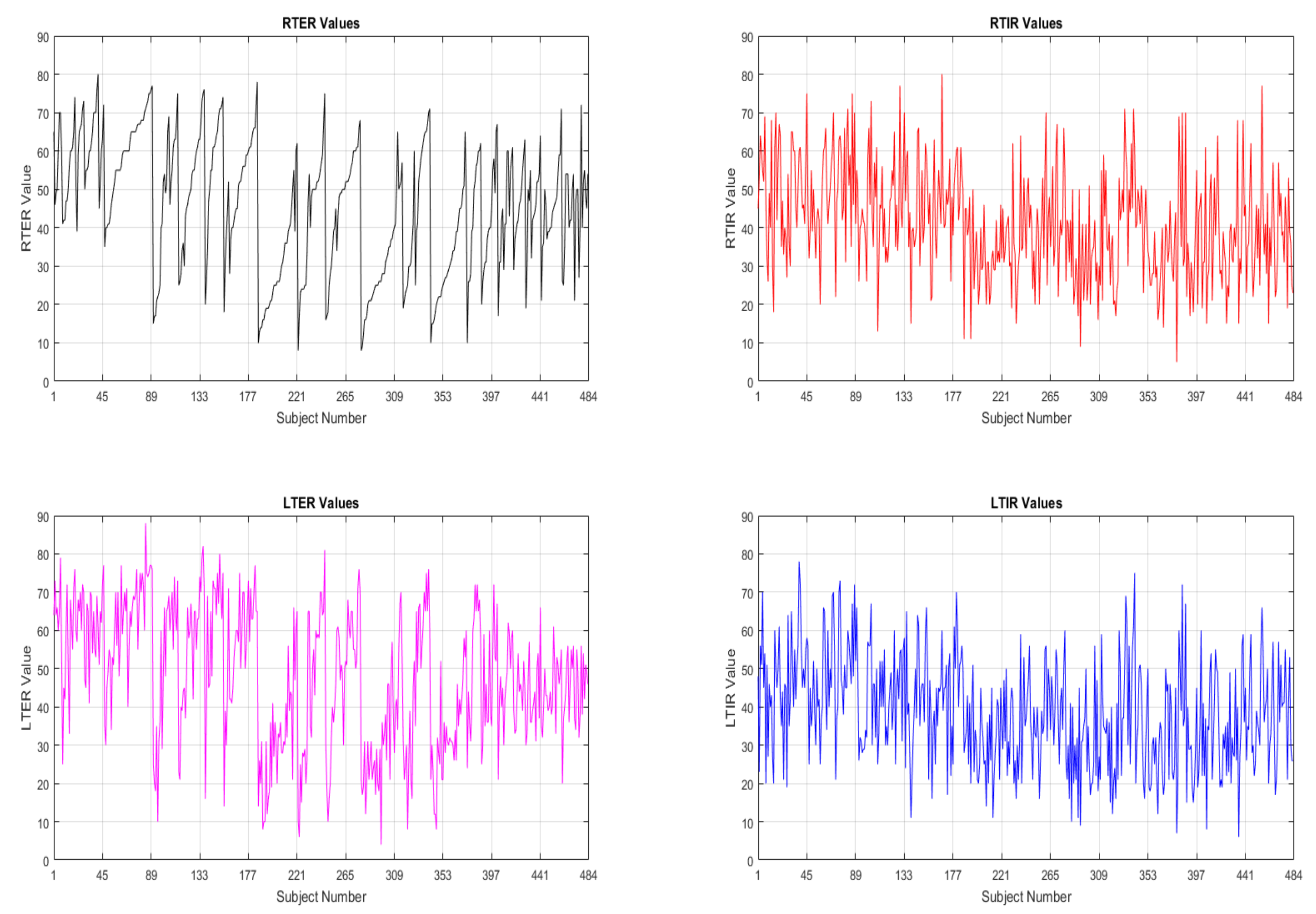
In the data tibial rotation values of each subject were given as right tibial external rotation (RTER), right tibial internal rotation (RTIR), left tibial external rotation (LTER), left tibial internal rotation (LTIR) as seen in
Figure 2. Totally, for every subject, it was 7 parameters as 3 of them are physical factors (age, weight and height) and 4 of them are tibial rotation values (RTER, RTIR, LTER and LTIR). The physical parameters are input and the rotation values are output.
The pragmatic aim of the paper is to discover the tibial rotation pathologies from a population by using the PSO-KM clustering algorithm, different physical characteristics. Primarily, 3 physical factors age, weight and height have been examined for the RTER values. Then, the same analysis has been carried out for the other variables RTIR, LTER, LTIR.
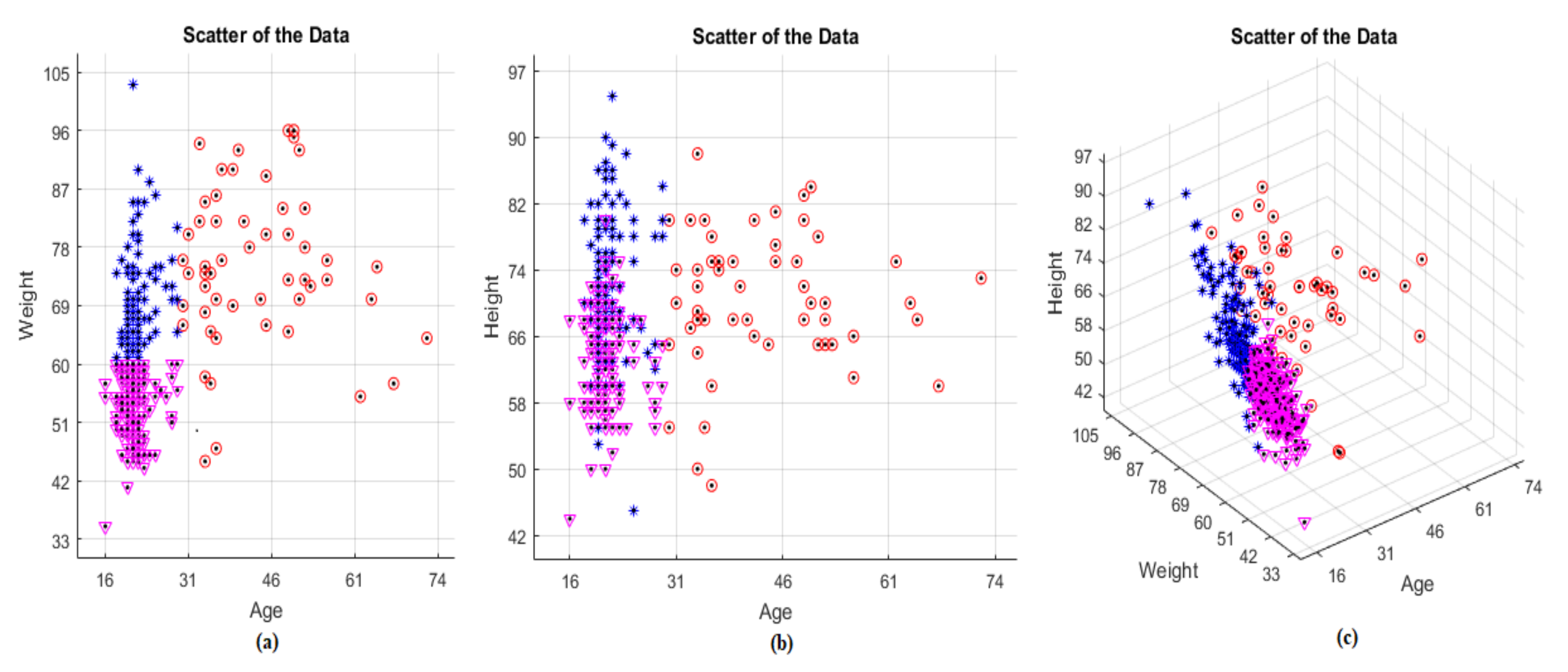
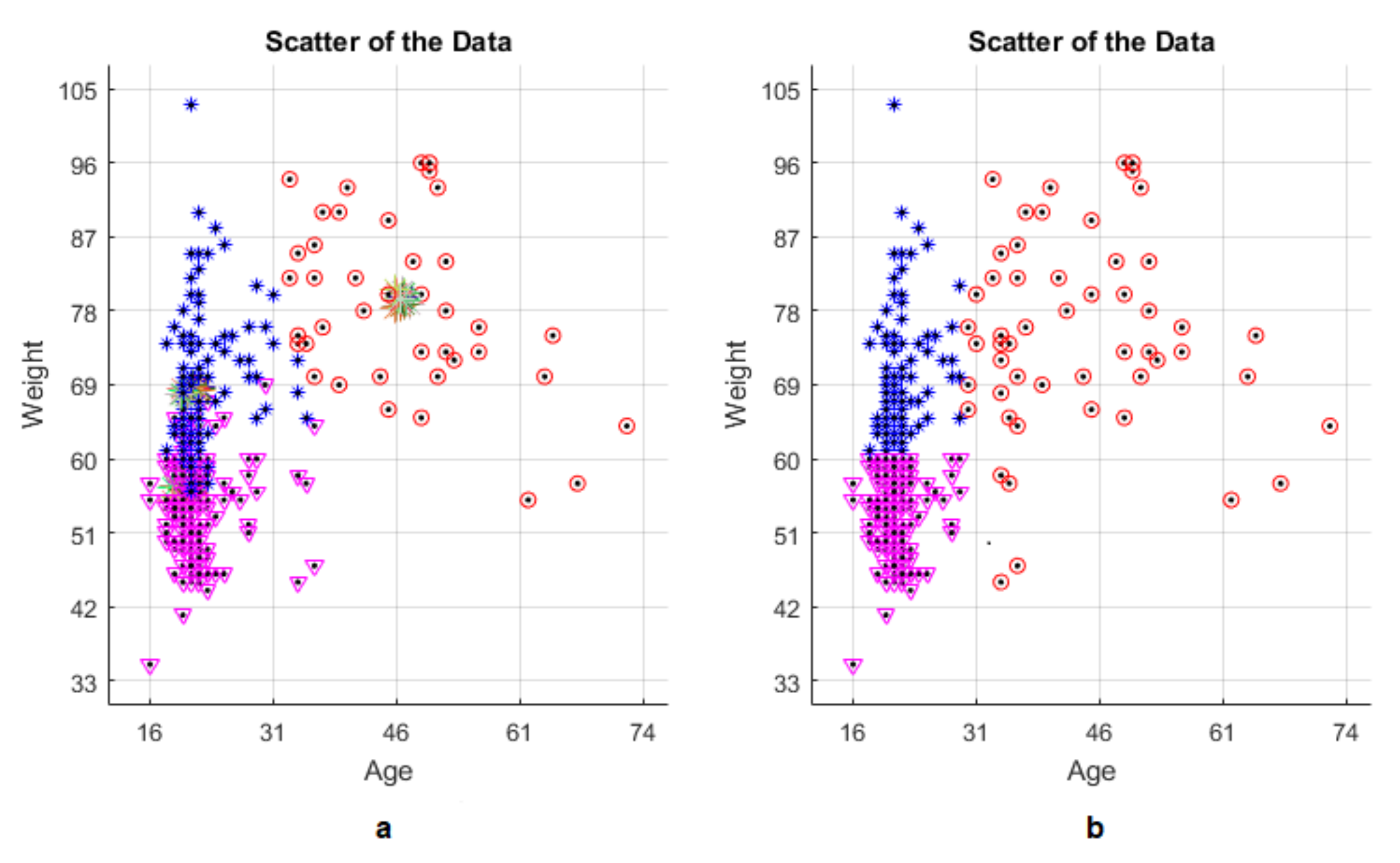
Since clustering is determined as the basic principle, the subjects are divided into three clusters by age and weight parameters. Subjects that their ages are greater than 30 are identified as the first cluster. The remaining subjects that their ages are less than 30 are divided into two clusters by the weight parameter. Subjects that their weights are less than 60 kg (subjects which have 1.70 height) are identified as the second cluster. Again, the remaining subjects that their weights are greater than 60 kg are identified as the third and the last cluster in
Table 1.
Since clustering is done according to age and weight parameters, showing all data in age-weight graph will be more imaginable. In
Figure 3, red, purple and blue parts represent the Cluster 1, Cluster 2 and Cluster 3, respectively.
Clustering has been done according to the scatter of the data. For example, the right side, which represents the subjects are older than 30 years, seems to be more dispersed than the left side. So, this part has been accepted to be Cluster 1.
In the meantime, the left side could be thought of as another cluster but two clusters were very easy for this problem. To have three clusters, the left side is divided into two by considering the weight parameter. The effect of height and weight parameters on clustering is almost the same, as seen in
Figure 3. Since
Figure 3 is displayed in this way, the left side of age-weight graph is divided into two clusters. The purple part which is below the left side represents the subjects are of less than 60 kg of weight while the blue part represents the subjects which are of greater than 60 kg of weight. Thus, establishment of the clustering is seen in
Table 1.
Once the clusters have been identified, the number of people for each type is counted in each cluster. This calculation has been made individually for each rotation type RTER, RTIR, LTER and LTIR. Each rotation has been divided into 3 regions according to whether it is pathological or not.
When the angle of the tibial rotation remains between 0 and 20 degrees, the corresponding subject is pathological in which each rotation type is accepted to be Type 1. If the angle of the tibial rotation of the adult subjects is between approximately 20 and 65 degrees, the subject who has angle in this interval is known to be normal thus, this type is called Type 2. Likewise, the case over approximately 65 degrees is abnormal and thus pathological. This part is accepted to be Type 3 again for each rotation type. The ranges of all types and the number of subjects in each rotation type are shown in
Table 2. After all these calculations have been done, the number of types in each cluster has been examined as seen in
Table 3. All classifications of the subjects done in above are based on the criterion of being pathological or non-pathological [
32,
33,
34].
As seen from the results of
Table 3, the algorithm to be used in this study aims to find the correct number of subjects in the clusters and find out the pathological and non-pathological values (Type 1, Type 2 and Type 3) in those clusters.
Since clusters are categorized according to the physical factors, when the rotation measurements are categorized according to the clusters, it will be examined whether there is a relation between these pathological and the non-pathological cases physical factors.
Table 2 informs that these anomalies are RTER-Type 1, RTER-Type 3, RTIR-Type 1, RTIR-Type 3, LTER-Type 1, LTER-Type 3, LTIR-Type 1 and LTIR-Type 3.
By applying the PSO-KM algorithm to this data, both accuracy of the clustering of the data and effects of the physical information on the tibial motion are investigated. In the literature, various versions of the PSO-KM algorithm were produced for various problems in different areas of science. Separately or combined, PSO and KM clustering algorithm are already reported to be very successful algorithms for their own problems [
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50]. A combined version of this algorithm and its computer codes have been successfully produced in this work. One of the greatest contributions of this study is that the algorithm is applied to the tibial rotation data for the first time.
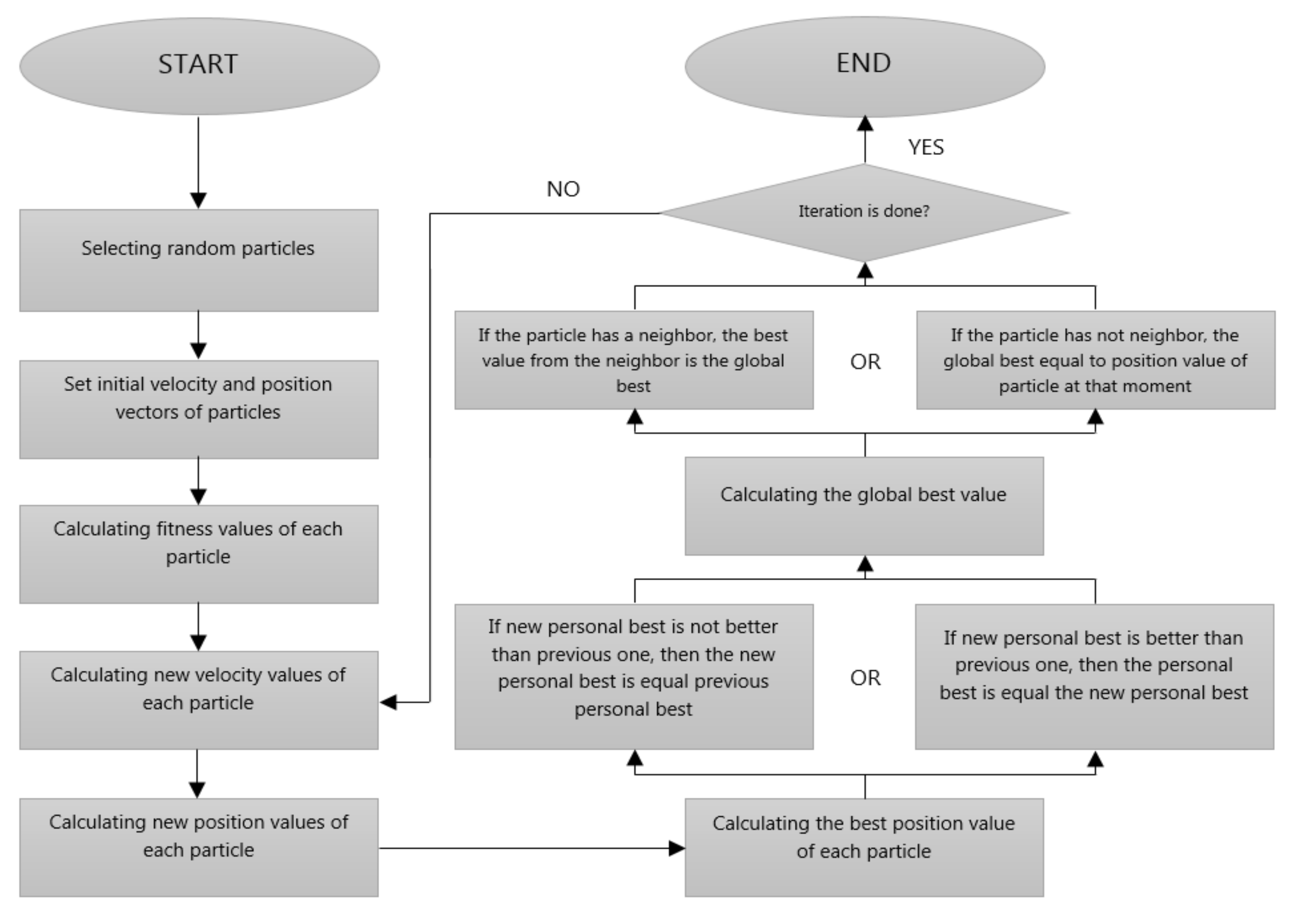
2.3. Particle Swarm Optimization
Particle swarm optimization (PSO) is a population-based, evolutionary optimization algorithm found by Kennedy and Eberhart [
56]. They inspired from the collective movement of birds and fishes. These animals have a major role in the development of the algorithm to escape from dangerous situations or to search food by looking at each other. The PSO is a very fast and more successful method than other optimization algorithms because it requires relatively fewer parameters and is less likely to find local minimum points as a solution [
57,
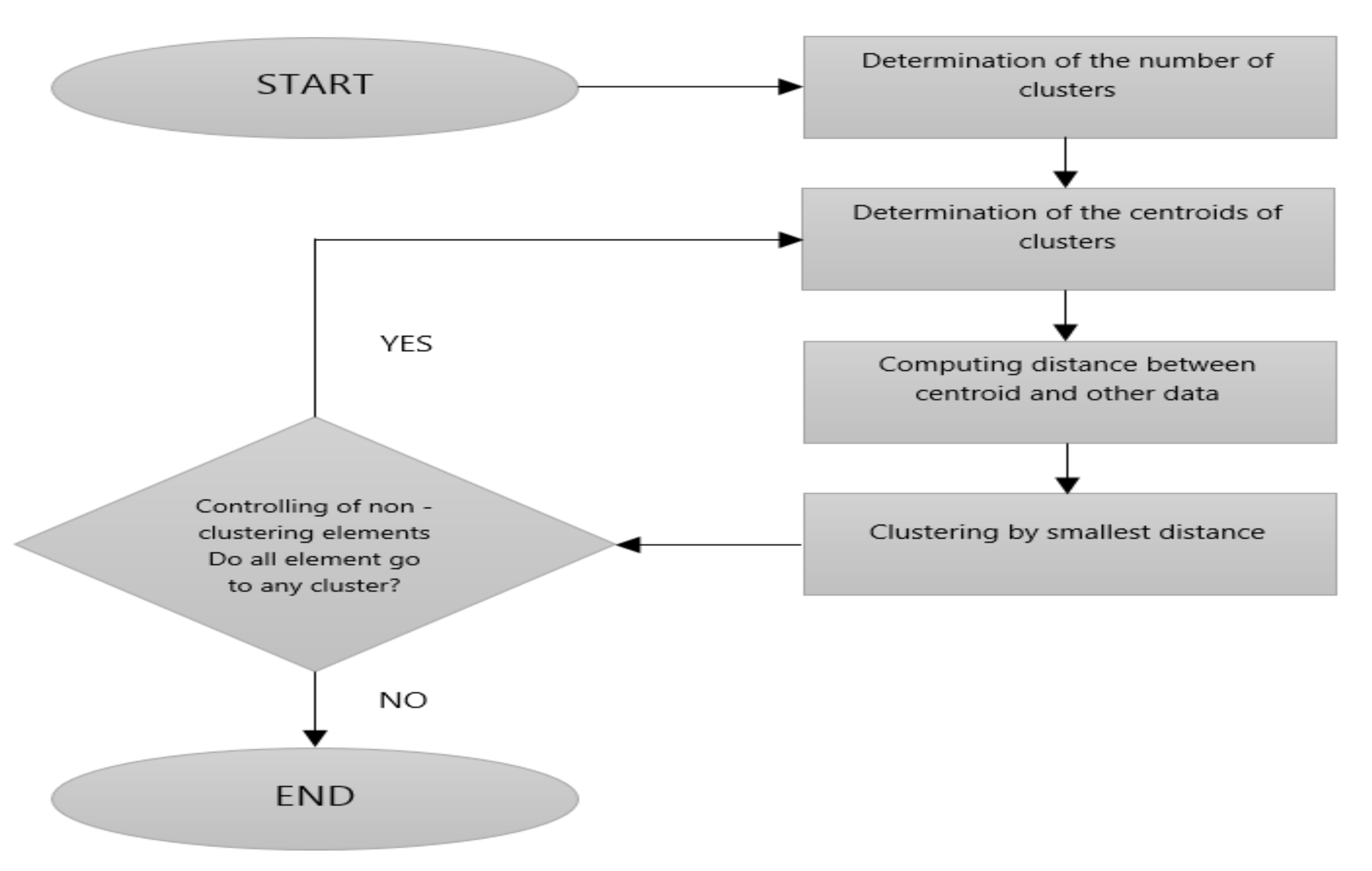
58]. In general, how the PSO works is shown in the flow diagram in
Figure 5.
The main principle of the PSO is that these elements try to find the optimum solution by selecting random elements from the given space. In the PSO, these elements that selected randomly are called “particle”. These randomly selected particles search solution space using information of their neighborhood, personal information, and randomness. Because of these 3-components, the particles go elsewhere at the end of each iteration. This 3-component formula, which takes the particle at any point at the end of each iteration, is considered to be the velocity vector of the particle. The position where the particle goes is the position vector of the particle. These velocity and position vectors are initialized as the information of initial values of the selected particle [
59,
60,
61,
62,
63]. Because of each iteration, the position and velocity vectors are updated as follows:
: Iteration number;
w: Inertia factor;
: Cognitive parameter;
: Social parameter;
: Random numbers between (0, 1);
: Random numbers between (0, 1);
: The best local value of each particle;
: The best value of swarm
The particles hold their best value in their memories. This value is called as
. These values are calculated by the fitness function. When the problem is minimization, the smallest value is
. If the problem is maximization, then the biggest value is
of each particle is listed and the fittest value according to the fitness function is selected as
[
57,
58,
59,
60,
61,
62,
63].
In the experimental studies [
64], the most appropriate value of
was accepted as approximately
. Again, it may change depending on the problem type but
is the most suitable value, usually
. In the same way, in the experimental studies,
values are bounded as
and
and
usually take the same value as
[
64].
As a result, random particles are selected from solution space. These particles are looking randomly for a solution. Particles move with their best value, neighbor’s best value and randomness. Because of this movement, the new position of each particle is determined. At the end of the stated number of iterations, the best one of the values found in the fitness function is accepted to be a solution in the PSO.
2.4. The PSO-KM Algorithm
Optimization is mostly used in biomechanical problems to analyze system identification problems, predict human motion and so on. Biomechanical optimization problems usually have multiple local minima, making it difficult to find the best solution. Hybridization of the PSO with KM clustering algorithm (PSO-KM) is explained in this section. Even if the hybrid algorithm has been seen to be applied in some scientific problems [
35,
36,
37,
38,
40,
41,
47,
48,
50], it is the first time that the algorithm is applied to the tibial rotation. The KM algorithm is a very successful and iterative algorithm. Likewise, the PSO is also a very successful optimization method. The common feature of these two algorithms is their iterative structure. At the cluster center, finding steps of the KM clustering algorithm can be made better by using the PSO approach. Hereby, better cluster center can be found. Thus, the main idea of their combination has been developed in this way. The literature tells us that different methods were applied to deal with the tibial rotation [
16,
17,
30]. However, the currently proposed PSO-KM algorithm has been utilized for the first time in this area.
The PSO-KM algorithm provides a more realistic approach to human nature and recognition than conventional methods. The current algorithm can also be used successfully in very large fields of science such as image recognition, signal processing, financial and economical modeling and control systems. Possibility and ease of the use in many fields make the present optimization approach an ideal solution for many applications.
As declared in the next section, there is considerable relation existing between some of the physical factors even the relation is relatively very strong for all the design variables. The data consists of age, weight and height values as well as left and right external and internal tibial rotations taken from 484 healthy subjects. At the beginning, the three parameters alone have been used to explore the rotation types, i.e., either pathological or non-pathological. The general equation of the PSO becomes:
where
represents the number of dimensions. As an example,
represents the velocity vector of 6th particle in 2nd dimension at 4th iteration. If data is to be spoken, our data has 3 dimensions. It will be age, body mass and height are the first, the second and the third input (or independent) variables, respectively. So,
represents the velocity vector of the sixth one from selected particles for solution on weight parameter in the 4th dimension. In the KM clustering algorithm, our data have the number of clusters
and the number of subjects
. Once the problem is designed in this way, the KM clustering algorithm distinguishes these parameters from each other by the mentality of being similar. Each one of the rotation types RTER, RTIR, LTER, and LTIR is sorted by just age parameter, respectively. Because the clustering was done according to the parameter age. The results of the KM clustering and values of each rotation (as Type 1, Type 2 and Type 3) were compared.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}