
Research on Anti-Interference Performance of Spiking Neural Network Under Network Connection Damage

 , , ,
, , ,
Abstract
1. Introduction
- (1)
- Verify the anti-interference performance of SNN and ANN. Construct two types of SNN models: VGG-SNN and FCNN-SNN, and compare them with traditional ANN (VGG and FCNN). VGG-SNN and FCNN-SNN are constructed to help us effectively and fairly evaluate the response ability of SNN and ANN in the face of interference and verify the anti-interference performance of SNN and ANN through experiments. The experimental results show that the SNN model has better anti-interference performance than the traditional ANN.
- (2)
- Analyze the reasons why SNN has anti-interference performance. By analyzing the essential difference between SNN and ANN, the reasons for the different anti-interference performances of SNN and ANN are considered. The main difference between SNN and ANN is the encoding method.
2. Related Work
2.1. Artificial Neural Network
2.2. Spiking Neural Network
2.3. Comparison of Advantages and Disadvantages Between ANN and SNN
2.4. Pruning Algorithm
2.5. Research on Anti-Interference of Spiking Neural Network
3. Methods
3.1. Spike Neuron Model
3.2. Structure of Spiking Neural Network Model
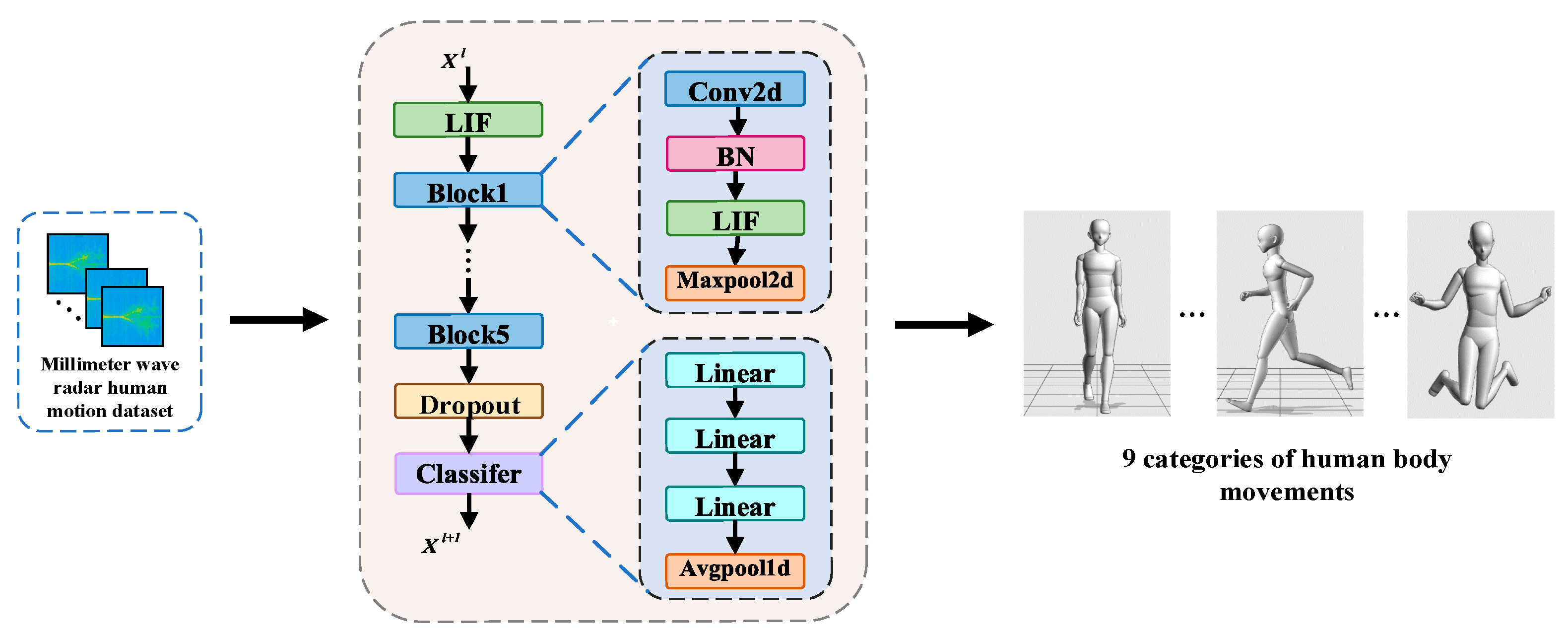
3.2.1. VGG-SNN
| Algorithm 1: Deep R Algorithm |
| Input: Output: 1: for i in [1, ] do 2: for all active connections do 3: ; 4: if then set connection k dormant; 5: end 6: while number of active connections lower than K do 7: select a dormant connection with uniform probability and activate it; 8: 9: end 10: end |
3.2.2. FCNN-SNN
4. Results
4.1. Datasets
4.1.1. Radar Action Dataset
4.1.2. MNIST Dataset
4.2. Experimental Setup
4.3. Experimental Results and Analysis
4.3.1. Comparison of Experimental Results Between VGG-SNN and VGG
4.3.2. Comparison of Experimental Results Between FCNN-SNN and FCNN
4.3.3. Resource Analysis of SNN and ANN
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, T.; Gao, L.; Tian, Y.; Tang, S. Memristor-based feature learning for pattern classification. Nat. Commun. 2025, 16, 913. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Ma, G.; Man, M.; Zhang, M.; Zhang, Y. Progress in bionic research of electromagnetic protection. High Volt. Technol. 2022, 5, 1750–1762. [Google Scholar] [CrossRef]
- Guo, L.; Guo, M.; Wu, Y.; Xu, G. Anti-Disturbance of Scale-Free Spiking Neural Network against Impulse Noise. Brain Sci. 2023, 13, 837. [Google Scholar] [CrossRef] [PubMed]
- Niu, L.; Wei, Y.; Liu, B.; Long, Y.; Xue, H. Research Progress of spiking neural network in image classification: A review. Appl. Intell. 2023, 53, 19466–19490. [Google Scholar] [CrossRef]
- Yamazaki, K.; Vo-Ho, V.-K.; Bulsara, D.; Le, N. Spiking Neural Networks and Their Applications: A Review. Brain Sci. 2022, 12, 863. [Google Scholar] [CrossRef]
- Tavanaei, A.; Ghodrati, M.; Kheradpisheh, S.R.; Masquelier, T.; Maida, A. Deep learning in spiking neural networks. Neural Netw. 2019, 111, 47–63. [Google Scholar] [CrossRef]
- Guo, L.; Wang, Y.; Shi, H. Comparative analysis of anti disturbance function of spiking neural networks with different topological structures. Comput. Appl. Softw. 2021, 38, 46–50. [Google Scholar] [CrossRef]
- Guo, L.; Liu, D.; Wu, Y.; Xu, G. Comparison of spiking neural networks with different topologies based on anti–disturbance ability under external noise. Neurocomputing 2023, 529, 113–127. [Google Scholar] [CrossRef]
- Zhang, C.; Guo, Y.; Li, M. Overview of the Development and Application of Artificial Neural Network Models. Comput. Eng. Appl. 2021, 57, 57–69. Available online: https://kns.cnki.net/kcms/detail/11.2127.TP.20210402.1348.004.html (accessed on 17 February 2025).
- Ding, S.; Li, H.; Su, C.; Yu, J.; Jin, F. Evolutionary artificial neural networks: A review. Artif. Intell. Rev. 2013, 39, 251–260. [Google Scholar] [CrossRef]
- Tian, W.; Zhang, L.; Qiu, R.; Lu, J.; Liu, Y.; Wang, W. Electrical performance of conductive cementitious composites under different curing regimes: Enhanced conduction by carbon fibers towards self-sensing function. Constr. Build. Mater. 2024, 421, 135771. [Google Scholar] [CrossRef]
- Bahrami, S.; Alamdari, S.; Farajmashaei, M.; Behbahani, M.; Jamshidi, S.; Bahrami, B. Application of artificial neural network to multiphase flow metering: A review. Flow Meas. Instrum. 2024, 97, 102601. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural network. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Hodgkin, A.L.; Huxley, A.F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 1952, 117, 500–544. [Google Scholar] [CrossRef]
- Brunel, N.; Mark, C.; Rossum, W. Lapicque’s 1907 paper: From frogs to integrate-and-fire. Biol. Cybern. 2007, 97, 337–339. [Google Scholar] [CrossRef]
- Segee, B. Methods in Neuronal Modeling: From Ions to Networks, 2nd Edition. Comput. Sci. Eng. 1999, 1, 81. [Google Scholar] [CrossRef]
- Zhu, H.; Zeng, X.; Zou, Y.; Zhou, J. Sensitivity of Spiking Neural Networks Due to Input Perturbation. Brain Sci. 2024, 14, 1149. [Google Scholar] [CrossRef]
- Deng, L.; Wu, Y.; Hu, X.; Liang, L.; Ding, Y.; Li, G.; Zhao, G.; Li, P.; Xie, Y. Rethinking the performance comparison between SNNS and ANN. Neural Netw. 2020, 121, 294–307. [Google Scholar] [CrossRef]
- Wang, H.; Qin, C.; Bai, Y.; Zhang, Y.; Fu, Y. Recent advances on neural network pruning at initialization. In Proceedings of the International Joint Conference on Artificial Intelligence(IJCAI), Vienna, Austria, 23–29 July 2022; pp. 5638–5645. [Google Scholar] [CrossRef]
- Deng, L.; Li, G.; Han, S.; Shi, L.; Xie, Y. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proc. IEEE 2020, 108, 485–532. [Google Scholar] [CrossRef]
- Xue, Y.; Yao, W.; Peng, S.; Yao, S. Automatic filter pruning algorithm for image classification. Appl. Intell. 2024, 54, 216–230. [Google Scholar] [CrossRef]
- Wang, Y.; Li, F.; Shi, G.; Xie, X.; Wang, F. Network pruning using sparse learning and genetic algorithm. Neurocomputing 2020, 404, 247–256. [Google Scholar] [CrossRef]
- Belle, G.; Kappe, D.; Maass, W.; Legenstein, R. Deep rewiring: Training very sparse deep networks. In Proceedings of the International Conference on Learning Representations(ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; Available online: https://openreview.net/forum?id=BJ_wN01C- (accessed on 17 February 2025).
- Liu, C.; Bellec, G.; Vogginger, B.; Kappel, D.; Partzsch, J.; Neumärker, F.; Höppner, S.; Maass, W.; Furber, S.; Legenstein, R.; et al. Memory-Efficient Deep Learning on a SpiNNaker 2 Prototype. Front. Neurosci. 2018, 12, 840. [Google Scholar] [CrossRef]
- Ebid, S.; El-Tantawy, S.; Shawky, D.; Abdel-Malek, H. Correlation-based pruning algorithm with weight compensation for feedforward neural networks. Neural Comput. Appl. 2025, 1–7. [Google Scholar] [CrossRef]
- Deng, L.; Wu, Y.; Hu, Y.; Liang, L.; Li, G.; Hu, X.; Ding, Y.; Li, P.; Xie, Y. Comprehensive SNN Compression Using ADMM Optimization and Activity Regularization. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 2791–2805. [Google Scholar] [CrossRef]
- Kappel, D.; Habenschuss, S.; Legenstein, R.; Maass, W. Network plasticity as Bayesian inference. PLoS Comput. Biol. 2015, 11, e1004485. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, Z.; Fang, W.; Huang, T.; Tian, Y. Pruning of deep spiking neural networks through gradient rewiring. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI), Montreal, BC, Canada, 19–27 August 2021; Volume 8, pp. 1713–1721. [Google Scholar] [CrossRef]
- Guo, L.; Feng, H.; Shi, H. Research on the anti-interference function of small world spiking neural networks with different reconnection probabilities. Comput. Eng. Sci. 2020, 42, 1325–1330. [Google Scholar] [CrossRef]
- Guo, L.; Man, R.; Wu, Y.; Yu, H.; Xu, G. Anti-injury function of complex spiking neural networks under targeted attack. Neurocomputing 2021, 462, 260–271. [Google Scholar] [CrossRef]
- Gerstner, W.; Kistler, W.M. Spiking Neuron Models: SingleNeurons, Populations, Plasticit; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Direct training for spiking neural networks: Faster, larger, better. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1311–1318. [Google Scholar] [CrossRef]
- Wei, F.; Chen, Y.; Ding, J.; Masquelier, T.; Chen, D.; Huang, L.; Zhou, H.; Li, G.; Tian, Y. SpikingJelly: An open-source machine learning infrastructure platform for spike-based intelligence. Sci. Adv. 2023, 9, eadi1480. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Radar Action | MNIST |
|---|---|---|
| Max Epoch | 200 | 200 |
| Batch Size | 128 | 128 |
| Learning Rate | 0.001 | 0.001 |
| T | 8 | 20 |
| 1.0 | 1.0 | |
| 2.0 | 2.0 |
| Model | Sparsity | Acc (%) | Percentage Decrease in Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| VGG-SNN | -- | 98.93 ± 0.12% 99.16 | -- | 98.91 ± 0.16 99.18 | 99.00 ± 0.10 99.15 | 98.79 ± 0.21% 99.16 |
| VGG-SNN + Deep R | 30% | 91.96 ± 1.11% 93.37 | 4.48 ± 0.66% 4.79 | 93.00 ± 0.98% 94.13 | 91.82 ± 1.25% 93.37 | 91.44 ± 1.53% 93.65 |
| VGG-SNN + Deep R | 70% | 81.59 ± 1.34% 83.33 | 15.84 ± 0.81% 14.73 | 84.91 ± 1.89% 87.10 | 81.42 ± 1.61% 83.33 | 82.19 ± 2.05% 85.3 |
| Model | Sparsity | Acc (%) | Percentage Decrease in Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| VGG | -- | 97.85 ± 1.32% 99.32% | -- | 97.42 ± 0.13% 97.99 | 96.99 ± 0.12% 97.96 | 97.2 ± 0.28% 97.98 |
| VGG + Deep R | 30% | 80.34 ± 1.03% 82.62 | 16.46 ± 0.97% 15.81% | 80.65 ± 0.64% 81.67 | 78.97 ± 0.92% 79.62 | 78.67 ± 1.21% 80.57 |
| VGG + Deep R | 70% | 72.74 ± 2.29% 75.26 | 25.23 ± 4.61 22.06% | 72.37 ± 1.88% 74.78 | 68.94 ± 2.12% 72.49 | 70.69 ± 1.37% 73.65 |
| Model | Sparsity | Acc (%) | Percentage Decrease in Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| FCNN-SNN | -- | 98.11 ± 0.10% 98.25 | -- | 97.73 ± 0.15% 97.95 | 97.36 ± 0.36% 97.94 | 97.68 ± 0.13% 97.94 |
| FCNN-SNN + Deep R | 30% | 92.99 ± 1.01% 94.40 | 4.96 ± 0.85% 3.92% | 92.38 ± 1.38% 94.33 | 92.57 ± 1.29% 94.31 | 93.16 ± 0.78% 94.32 |
| FCNN-SNN + Deep R | 70% | 87.57 ± 2.12% 90.16 | 9.76 ± 2.34% 6.7% | 88.67 ± 1.73% 90.62 | 88.53 ± 1.12% 90.16 | 87.88 ± 1.96% 90.39 |
| Model | Sparsity | Acc (%) | Percentage Decrease in Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|---|
| FCNN | -- | 97.78 ± 0.53% 98.60% | -- | 97.55 ± 0.12% 97.65 | 97.08 ± 0.34% 97.89 | 97.45 ± 0.10% 98.14 |
| FCNN + Deep R | 30% | 86.10 ± 1.31% 88.53 | 10.43 ± 1.64% 9.16% | 86.38 ± 1.13% 88.05 | 86.26 ± 1.26% 87.97 | 86.65 ± 1.02% 87.90 |
| FCNN + Deep R | 70% | 69.38 ± 2.21% 72.15 | 28.9 ± 1.82% 26.38% | 67.94 ± 1.98% 70.19 | 68.52 ± 1.41% 70.66 | 68.39 ± 2.17% 71.28 |
| Index | FCNN-SNN | FCNN-SNN + 0.7 Deep R | FCNN | FCNN + 0.7 Deep R |
|---|---|---|---|---|
| Parameter quantity | 535,040 | 374,073 | 535,818 | 374,528 |
| Internal memory | 1027 MiB | 327 MiB | 1039 MiB | 875 MiB |
| Training time | 17.03 s/epoch | 14.82 s/epoch | 14.21 s/epoch | 11.76 s/epoch |
| Acc | 98.11 ± 0.10% 98.25% | 87.57 ± 2.12% 90.16% | 97.78 ± 0.53% 98.60% | 69.38 ± 2.21% 72.15% |
| Model | Whether to Add Pruning | Accuracy of the Original Weight (%) | Accuracy of Introducing SNN Weights (%) |
|---|---|---|---|
| FCNN | × | 97.78 ± 0.53% 98.60% | 98.12 ± 0.78% 99.03% |
| √ | 86.10 ± 1.31% 88.53% | 87.62 ± 1.64% 89.61% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Pang, H.; Ma, J.; Ma, G.; Zhang, X.; Man, M. Research on Anti-Interference Performance of Spiking Neural Network Under Network Connection Damage. Brain Sci. 2025, 15, 217. https://doi.org/10.3390/brainsci15030217
Zhang Y, Pang H, Ma J, Ma G, Zhang X, Man M. Research on Anti-Interference Performance of Spiking Neural Network Under Network Connection Damage. Brain Sciences. 2025; 15(3):217. https://doi.org/10.3390/brainsci15030217
Chicago/Turabian StyleZhang, Yongqiang, Haijie Pang, Jinlong Ma, Guilei Ma, Xiaoming Zhang, and Menghua Man. 2025. "Research on Anti-Interference Performance of Spiking Neural Network Under Network Connection Damage" Brain Sciences 15, no. 3: 217. https://doi.org/10.3390/brainsci15030217
APA StyleZhang, Y., Pang, H., Ma, J., Ma, G., Zhang, X., & Man, M. (2025). Research on Anti-Interference Performance of Spiking Neural Network Under Network Connection Damage. Brain Sciences, 15(3), 217. https://doi.org/10.3390/brainsci15030217