
DIANA, a Process-Oriented Model of Human Auditory Word Recognition


Abstract
:1. Introduction
1.1. Computational Models of Speech Processing
1.1.1. Cohort Model
1.1.2. TRACE
1.1.3. Shortlist and Shortlist B
1.1.4. Fine-Tracker
1.1.5. EARSHOT and LDL-AURIS
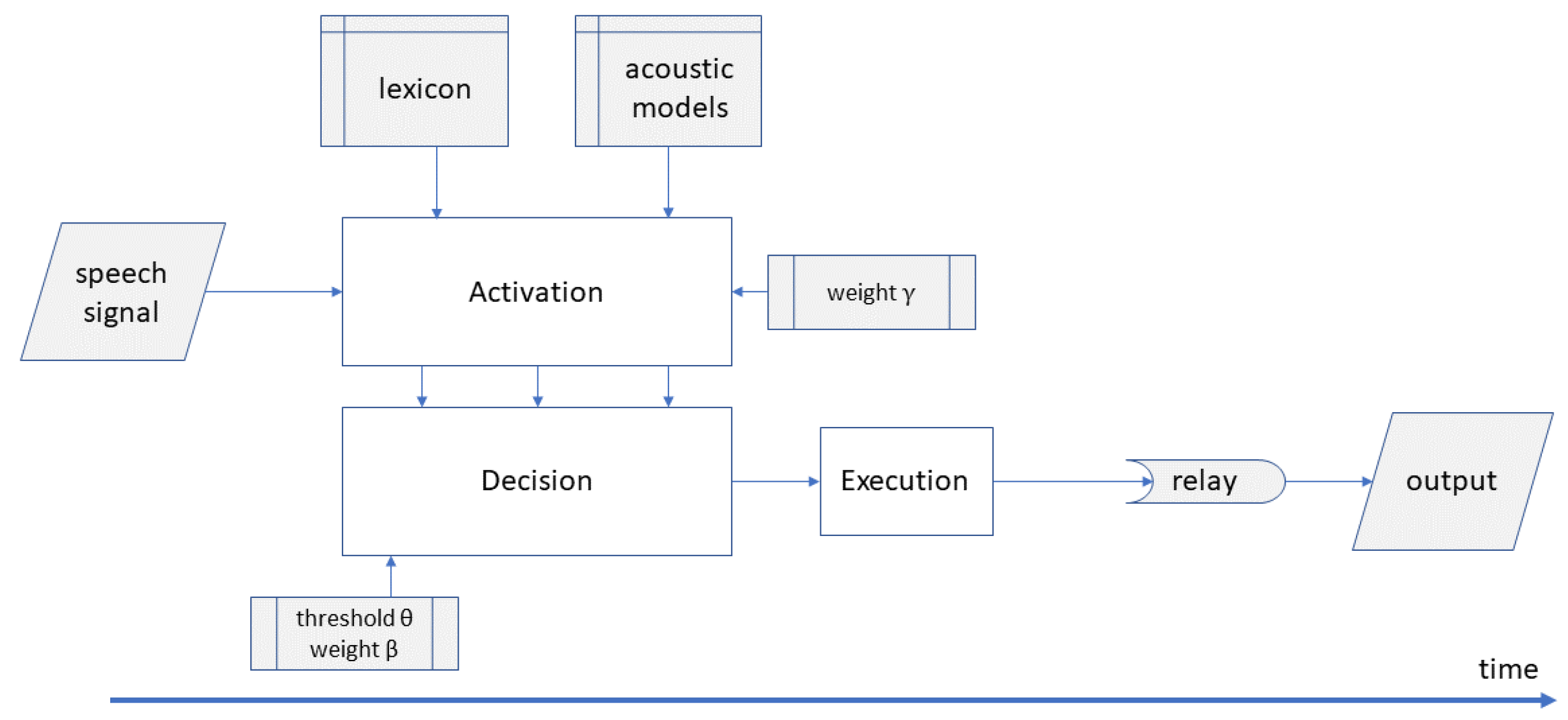
2. Towards DIANA, A Novel Process-Oriented Model
3. The Activation Component
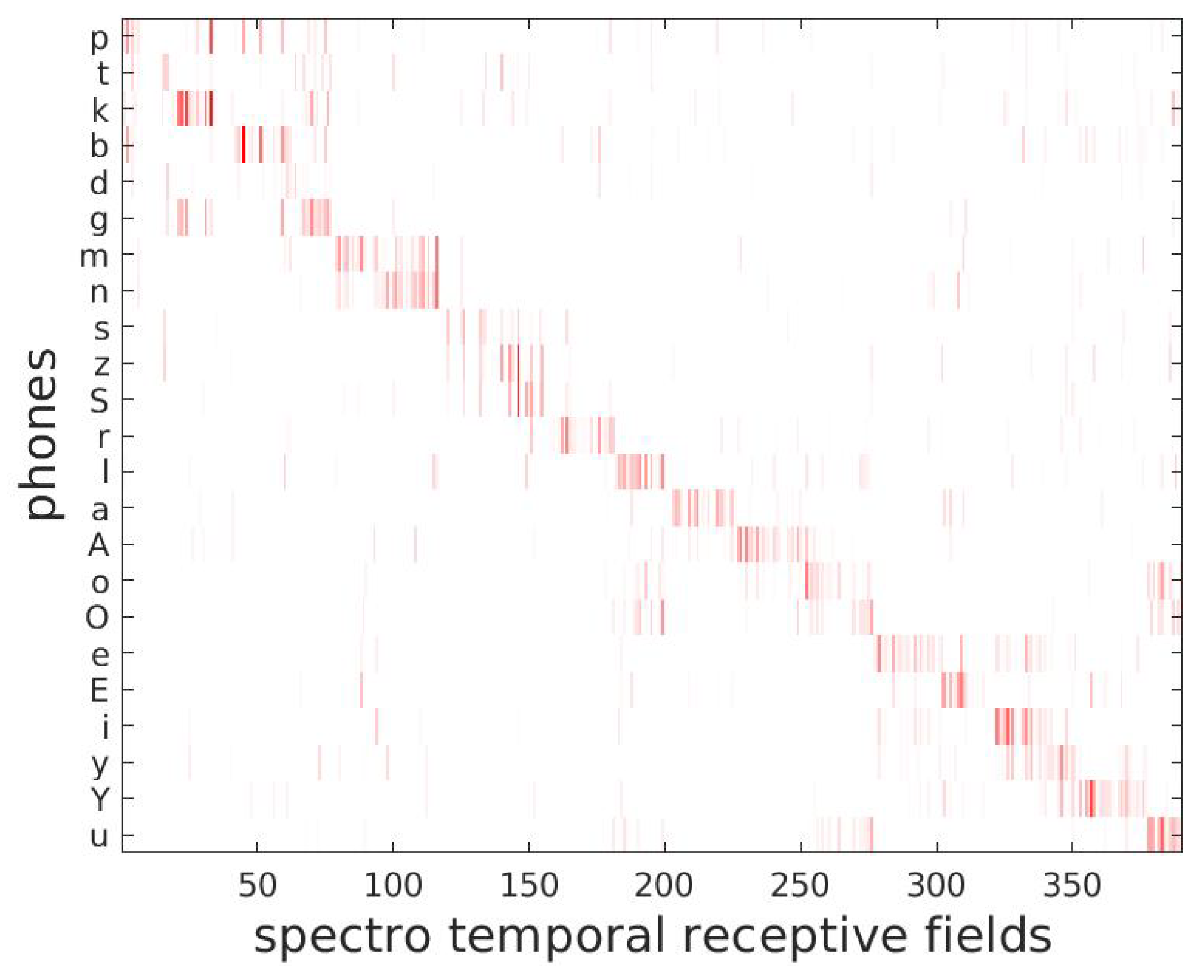
3.1. From the Input Signal to Spectro-Temporal Receptive Fields
3.2. The Lexicon in DIANA
3.3. Obtaining Activation Scores from Bottom-Up and Top-Down Information
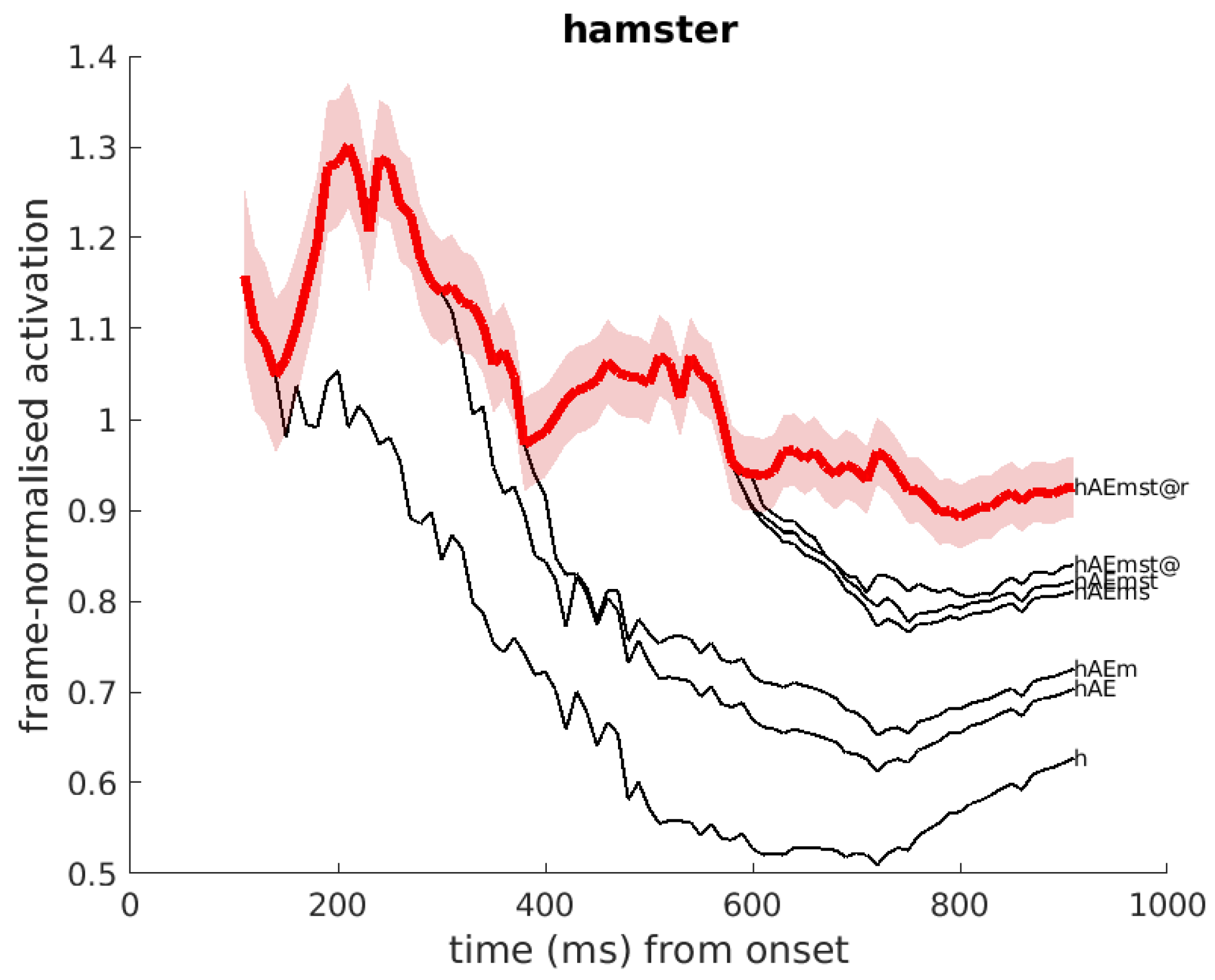
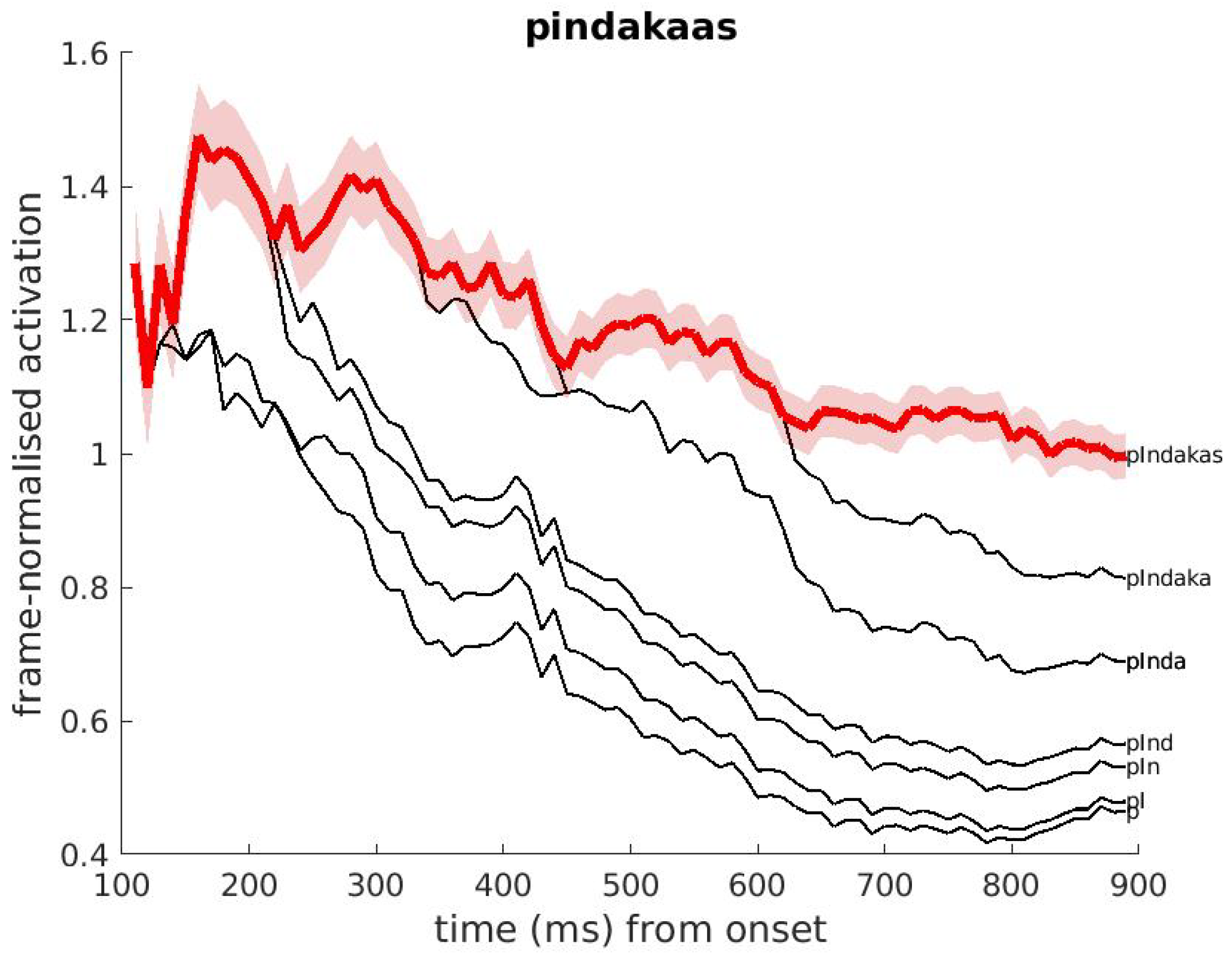
3.4. Examples of Word Activations
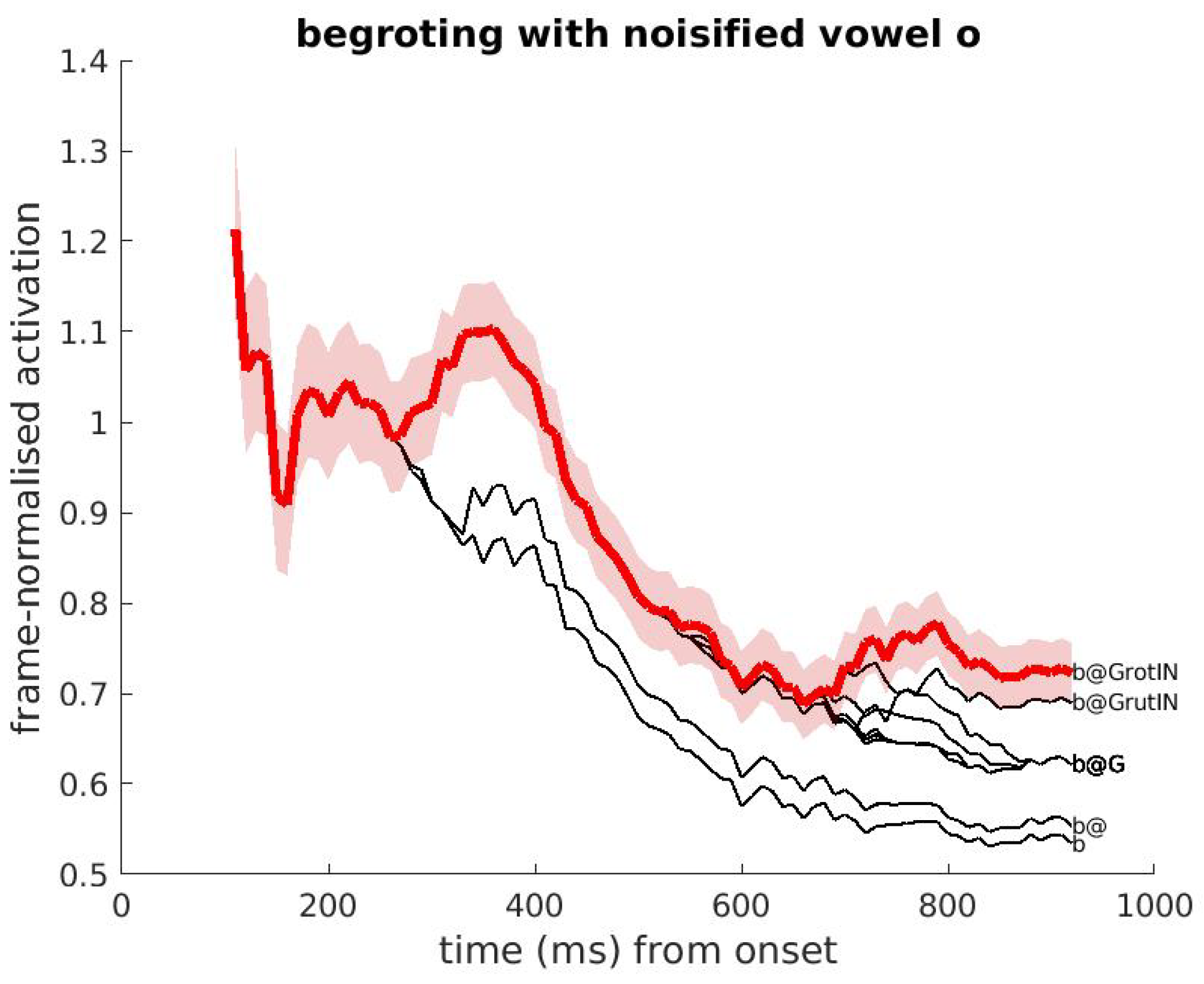
3.5. Presence of Noise in the Input
4. The Decision Component
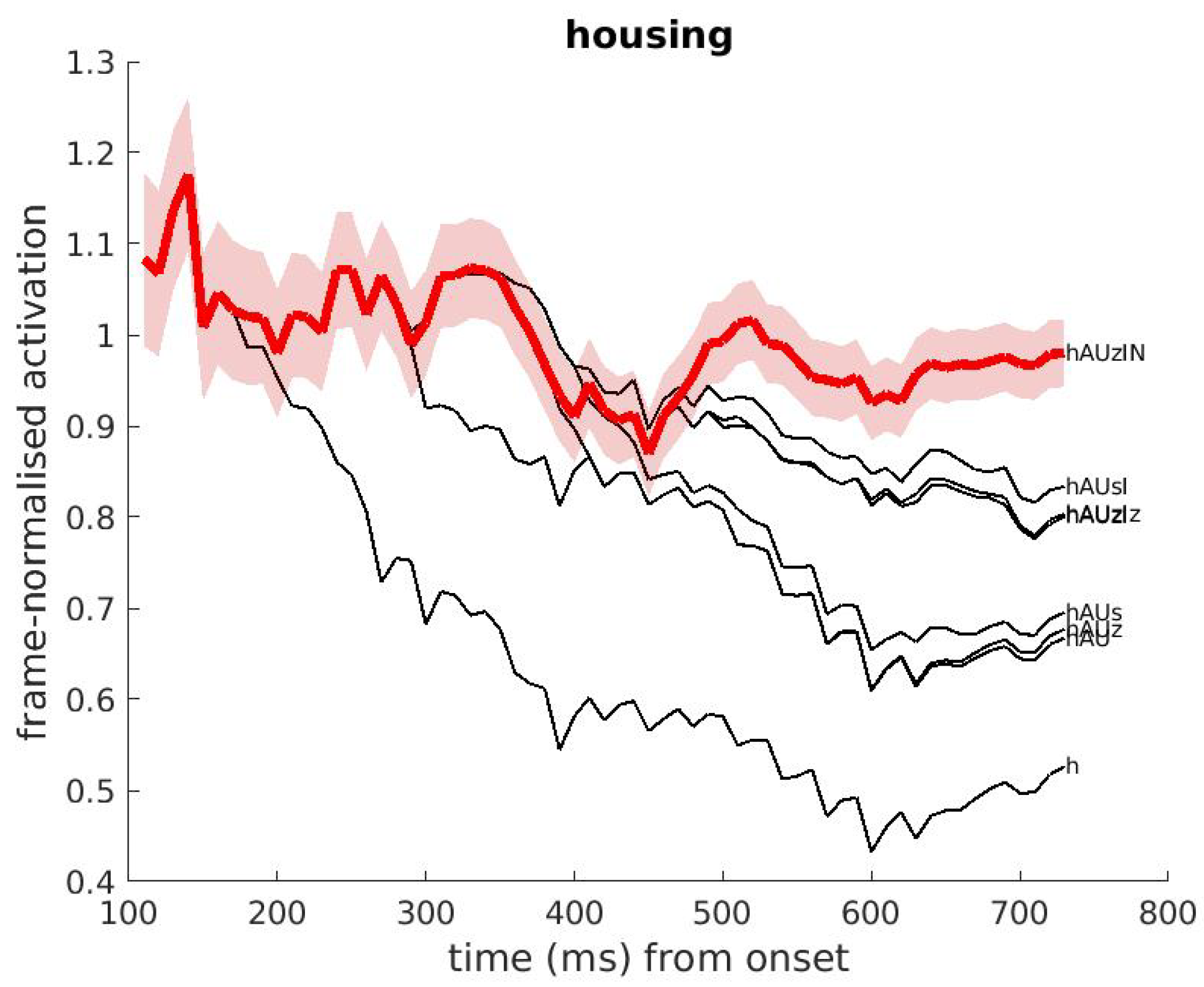
4.1. Selecting Promising Word Candidates
4.2. The Decision Strategy for Simple Word Identification
4.3. The Decision Strategy for Lexical Decision
4.4. Ambiguity during DIANA’s Search Process
5. Future Research Directions
5.1. Lexicon
5.2. Generalizing to Other Languages
5.3. Top-Down Information
5.4. Is DIANA A Learning Model?
5.5. Implementation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | artificial neural network |
| CCN | cognitive control network |
| DMN | default mode network |
| DNN | deep neural network |
| ECoG | electrocortocography |
| STRF | spectro-temporal receptive field |
| MFCC | mel-frequency cepstral coefficient |
| RT | reaction time |
| LM | language model |
| SLM | statistical language model |
| NDL | naive discriminative learner |
| LDL | linear discriminative learner |
Appendix A. Appendices
Appendix A.1. MFCC Feature Vectors and Spectro-Temporal Receptive Fields
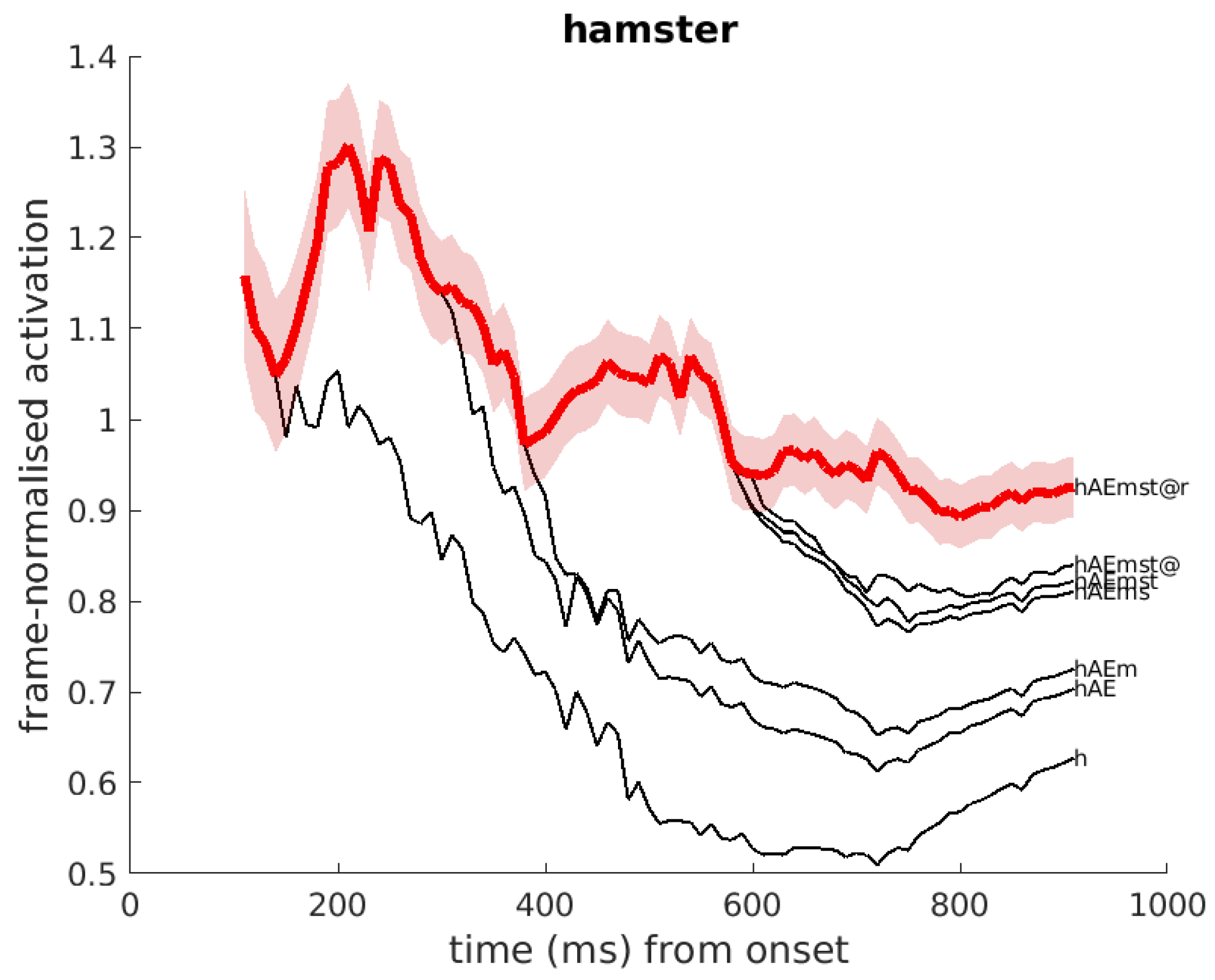
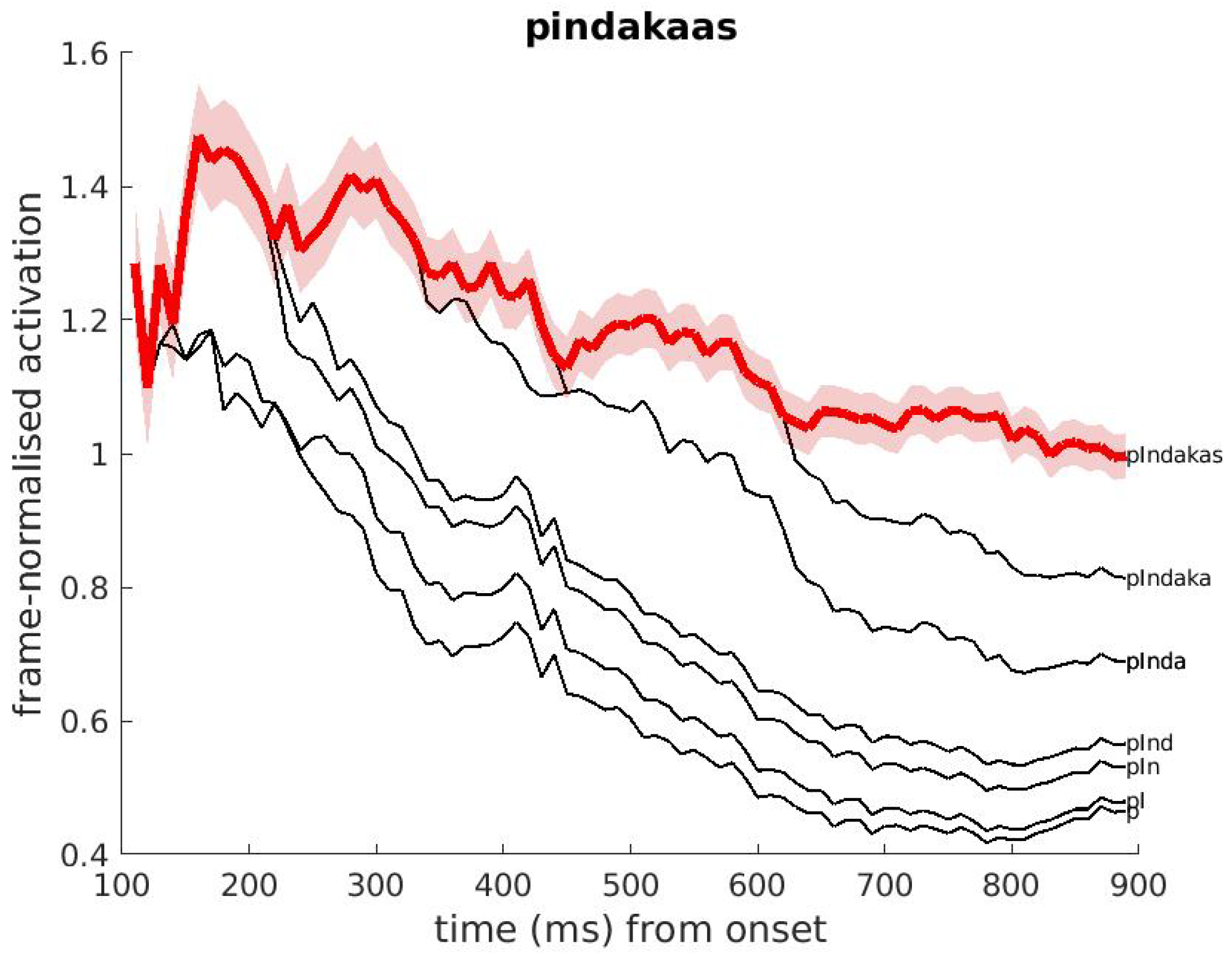
Appendix A.2. Activation of Words, Pseudo-Words and Word Cohorts
Appendix A.3. Lexical Activation Score and Lexically Unrestricted Activation Score
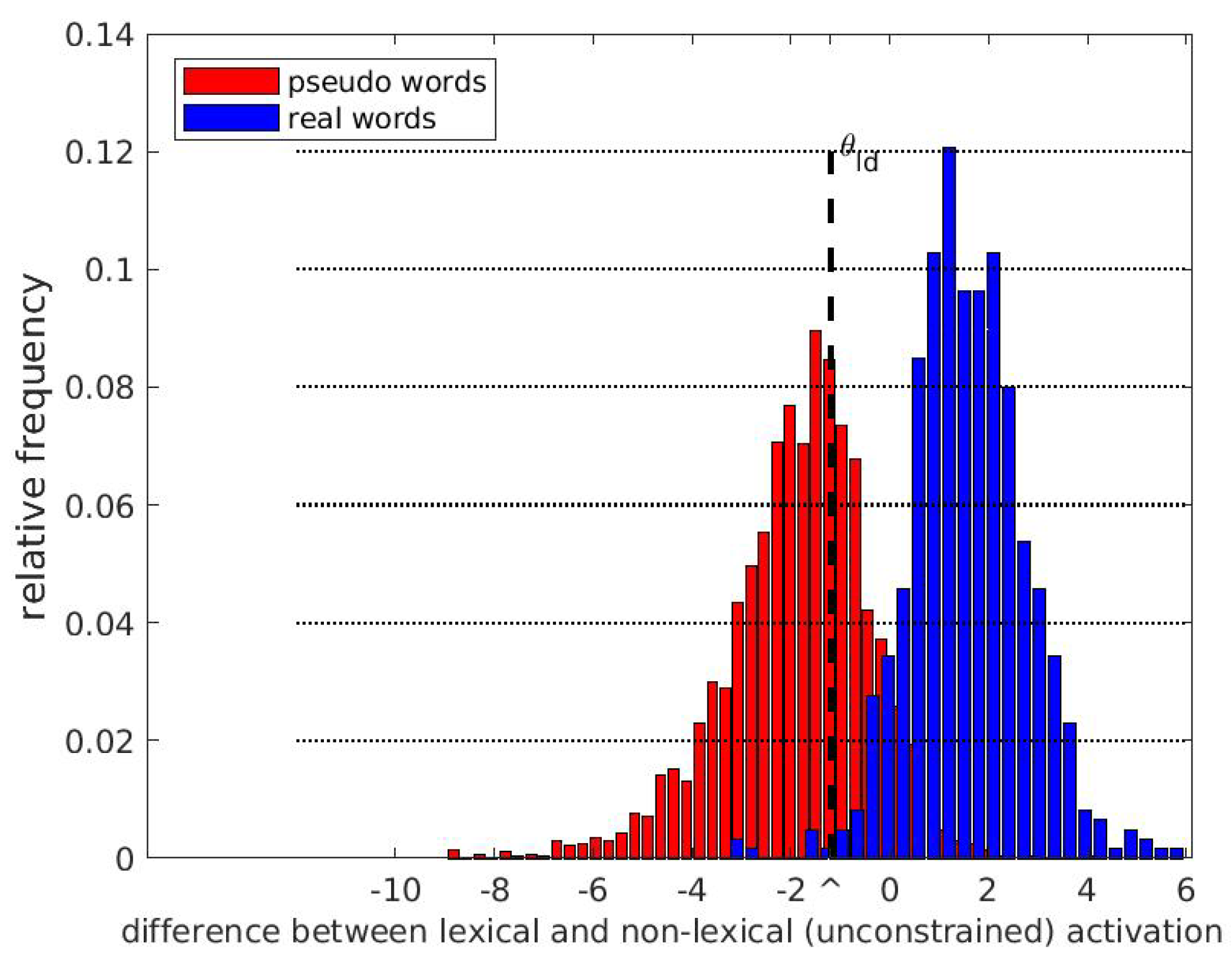
Appendix A.4. Computation of Entropy
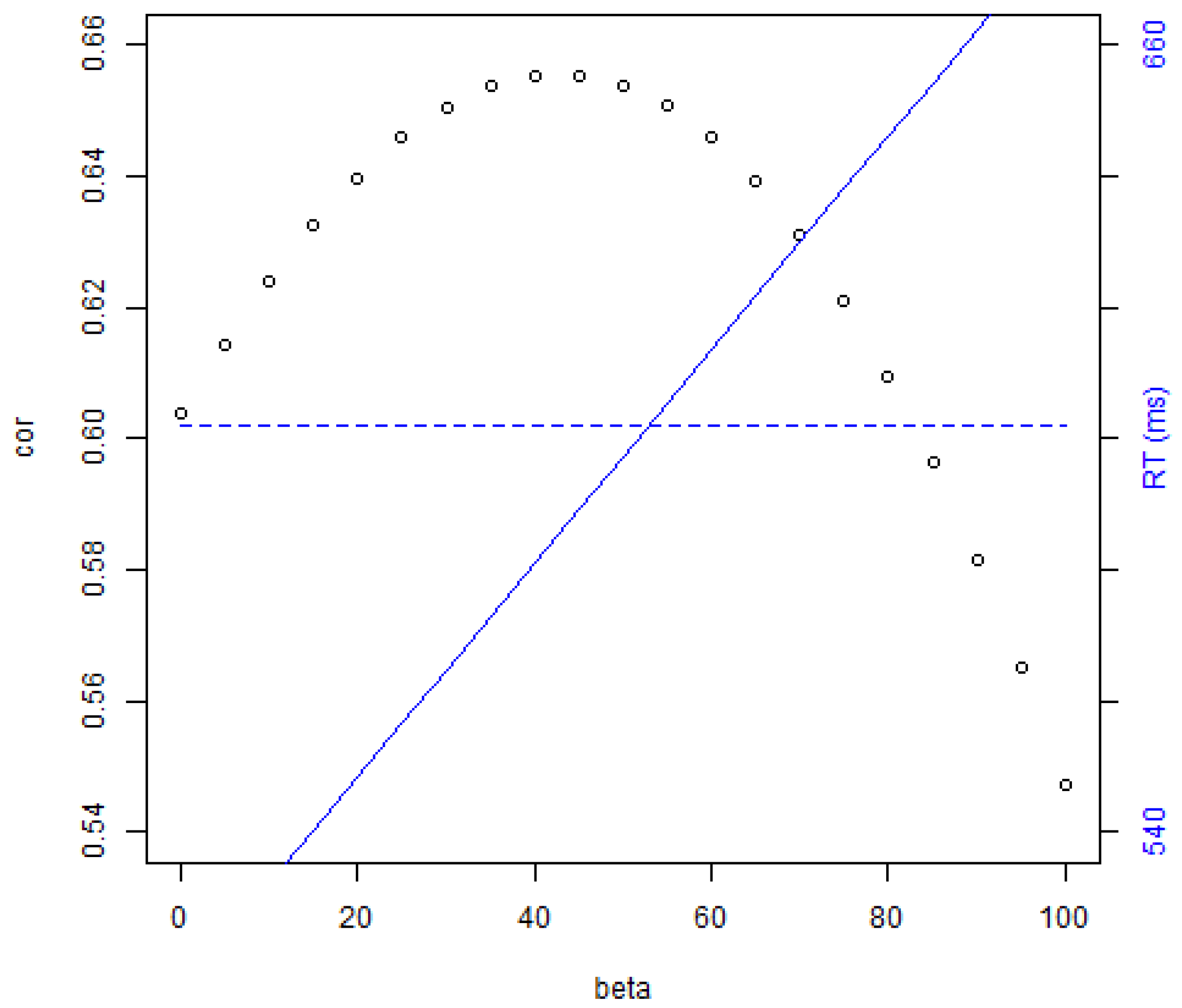
Appendix A.4.1. Entropy as a Contributing Factor of Reaction Time
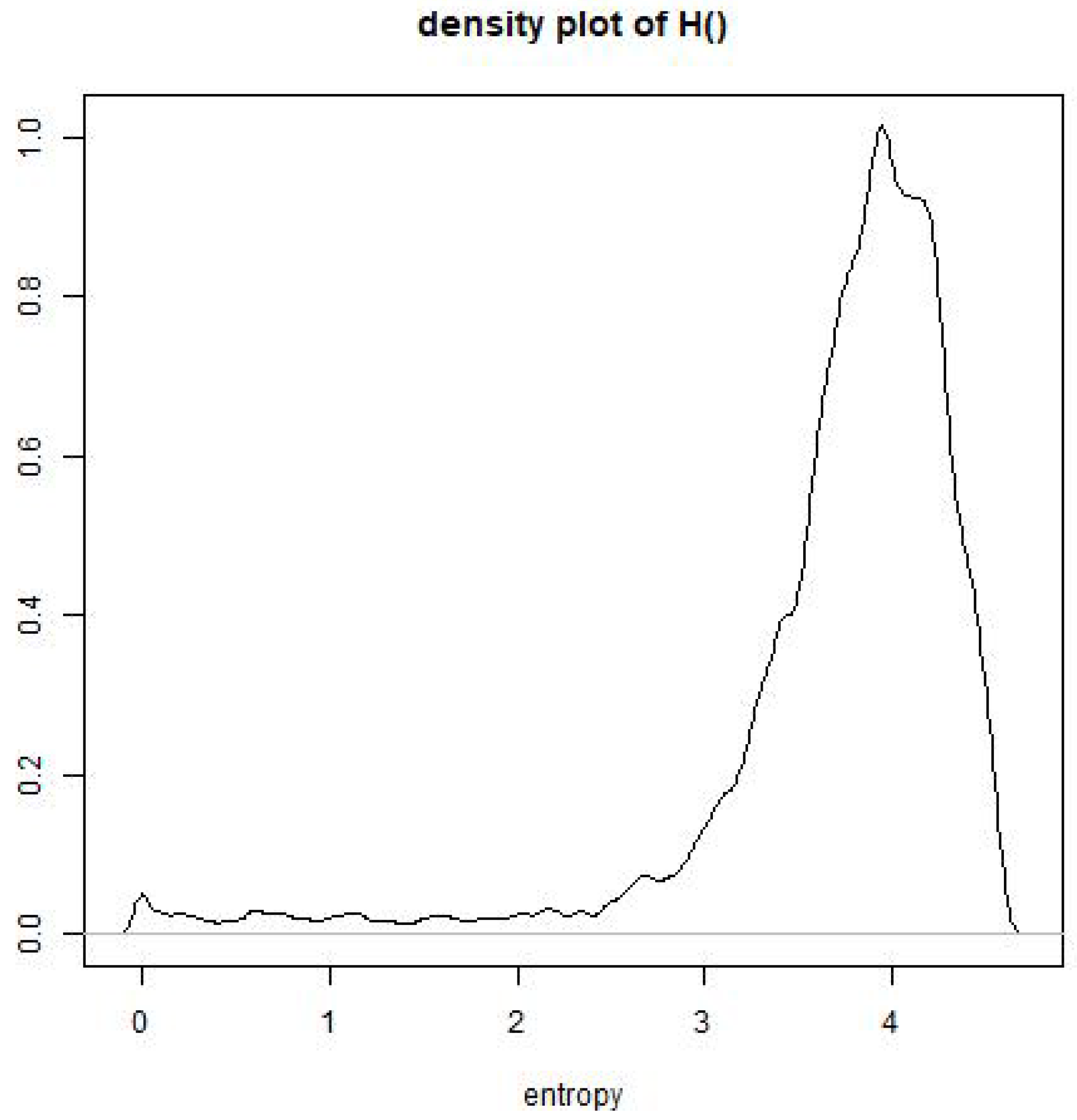
Appendix A.4.2. Entropy as a Predictor of the RTs in BALDEY

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RTonset | |||
|---|---|---|---|
| Estimate | Std. Error | t Value | |
| (Intercept) | 6.742 × | 3.265 × | 2.065 |
| logwdur | 3.306 × | 6.513 × | 50.760 |
| logFreq | 7.011 × | 1.135 × | 6.178 |
| entrlogwdur | 2.354 × | 2.039 × | 11.548 |
| wordiness | 5.559 × | 9.084 × | 6.119 |
| session | 2.564 × | 2.919 × | 8.783 |
| trial | 2.672 × | 4.883 × | 5.472 |
| wordclass(nom) | 6.933 × | 2.965 × | 2.338 |
| wordclass(verb) | 3.106 × | 2.951 × | 10.526 |
| maRT | 6.000 × | 4.299 × | 13.958 |
| prevBVis | 2.651 × | 2.883e × | 9.196 |
| compoundtype(A+N) | −3.023 × | 8.855 × | −3.414 |
| compoundtype(N+A) | −7.375 × | 1.018 × | −0.724 |
| compoundtype(N+N) | 4.197 × | 4.236 × | 0.991 |
| logwdur:logFreq | −1.277 × | 1.785 × | −7.153 |
References
- Ten Bosch, L.; Boves, L.; Ernestus, M. Towards an end-to-end computational model of speech comprehension: Simulating a lexical decision task. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013. [Google Scholar]
- Ten Bosch, L.; Ernestus, M.; Boves, L. Comparing reaction times from human participants and computational models. In Proceedings of the Interspeech, Singapore, 14–18 September 2014. [Google Scholar]
- Ten Bosch, L.; Boves, L.; Tucker, B.; Ernestus, M. DIANA: Towards computational modeling reaction times in lexical decision in North American English. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Ten Bosch, L.; Boves, L.; Ernestus, M. Combining data-oriented and process-oriented approaches to modeling reaction time data. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Ten Bosch, L.; Boves, L.; Ernestus, M. The recognition of compounds: A computational account. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 September 2017. [Google Scholar]
- Nenadić, F.; ten Bosch, L.; Tucker, B.V. Implementing DIANA to Model Isolated Auditory Word Recognition in English. Proc. Interspeech 2018, 2018, 3772–3776. [Google Scholar] [CrossRef] [Green Version]
- Ten Bosch, L.; Boves, L. Word Competition: An Entropy-Based Approach in the DIANA Model of Human Word Comprehension. Proc. Interspeech 2021, 2021, 531–535. [Google Scholar] [CrossRef]
- Scharenborg, O.; Boves, L. Computational modelling of spoken-word recognition processes: Design choices and evaluation. Pragmat. Cogn. 2010, 18, 136–164. [Google Scholar] [CrossRef] [Green Version]
- Marslen-Wilson, W.; Welsh, A. Processing interactions and lexical access during word recognition in continuous speech. Cogn. Psychol. 1978, 10, 29–63. [Google Scholar] [CrossRef]
- Marslen-Wilson, W. Functional parallellism in spoken word recognition. Cognition 1987, 25, 71–102. [Google Scholar] [CrossRef]
- Marslen-Wilson, W.; Tyler, L. The temporal structure of spoken language understanding. Cognition 1980, 8, 1–71. [Google Scholar] [CrossRef] [Green Version]
- Cutler, A. Native Listening: Language Experience and the Recognition of Spoken Words; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Marslen-Wilson, W. Activation, competition and frequency in lexical access. In Cognitive Models of Speech Processing: Psycholinguistic and Computational Perspectives; Altman, G.T.M., Ed.; MIT Press: Cambridge, MA, USA, 1990; pp. 148–172. [Google Scholar]
- Marslen-Wilson, W.; Brown, C.; Tyler, L. Lexical representations in spoken language comprehension. Lang. Cogn. Process. 1988, 3, 1–16. [Google Scholar] [CrossRef]
- Bard, E.; Shillcock, R.; Altmann, G. The recognition of words after their acoustic offsets in spontaneous speech: Effects of subsequent context. Percept. Psychophys. 1988, 44, 395–408. [Google Scholar] [CrossRef] [Green Version]
- Marr, D. Vision: A Computational Approach; Freeman & Co.: San Francisco, CA, USA, 1982. [Google Scholar]
- Silva, S.; Vigário, M.; Fernandez, B.L.; Jerónimo, R.; Alter, K.; Frota, S. The Sense of Sounds: Brain Responses to Phonotactic Frequency, Phonological Grammar and Lexical Meaning. Front. Psychol. 2019, 10, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Gow, D.; Olson, B. Lexical mediation of phonotactic frequency effects on spoken word recognition: A Granger causality analysis of MRI-constrained MEG/EEG data. J. Mem. Lang. 2015, 82, 41–55. [Google Scholar] [CrossRef] [Green Version]
- Gwilliams, L.; King, J.R.; Marantz, A.; Poeppel, D. Neural dynamics of phoneme sequencing in real speech jointly encode order and invariant content. 2020, preprint. 2020; preprint. [Google Scholar] [CrossRef] [Green Version]
- Port, R.F. Rich memory and distributed phonology. Lang. Sci. 2009, 32, 43–55. [Google Scholar] [CrossRef]
- McClelland, J.L.; Elman, J.L. The TRACE model of speech perception. Cogn. Psychol. 1986, 18, 1–86. [Google Scholar] [CrossRef]
- Usher, M.; McClelland, J.L. On the time course of perceptual choice: The leaky competing accumulator model. Psychol. Rev. 2001, 108, 550–592. [Google Scholar] [CrossRef] [Green Version]
- Norris, D. Shortlist: A connectionist model of continuous speech recognition. Cognition 1994, 52, 189–234. [Google Scholar] [CrossRef]
- Magnuson, J.S.; You, H.; Luthra, S.; Li, M.; Nam, H.; Escabí, M.; Brown, K.; Allopenna, P.D.; Theodore, R.M.; Monto, N.; et al. EARSHOT: A Minimal Neural Network Model of Incremental Human Speech Recognition. Cogn. Sci. 2020, 44, e12823. [Google Scholar] [CrossRef] [Green Version]
- Norris, D.; McQueen, J. Shortlist B: A Bayesian Model of Continuous Speech Recognition. Psychol. Rev. 2008, 115, 357–395. [Google Scholar] [CrossRef] [Green Version]
- Smits, R.; Warner, N.; McQueen, J.; Cutler, A. Unfolding of phonetic information over time: A database of Dutch diphone perception. J. Acoust. Soc. Am. 2003, 113, 563–574. [Google Scholar] [CrossRef] [Green Version]
- Warner, N.; Smits, R.; McQueen, J.; Cutler, A. Phonological and frequency effects on timing of speech perception: A database of Dutch diphone perception. Speech Commun. 2005, 46, 53–72. [Google Scholar] [CrossRef] [Green Version]
- Scharenborg, O. Modelling fine-phonetic detail in a computational model of word recognition. In Proceedings of Interspeech; Causal Productions Pty Ltd.: Brisbane, Australia, 2008. [Google Scholar]
- Scharenborg, O. Modeling the use of durational information in human spoken-word recognition. J. Acoust. Soc. Am. 2010, 127, 3758–3770. [Google Scholar] [CrossRef] [Green Version]
- Salverda, A.P.; Dahan, D.; McQueen, J.M. The role of prosodic boundaries in the resolution of lexical embedding in speech comprehension. Cognition 2003, 90, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Shafaei-Bajestan, E.; Moradipour-Tari, M.; Uhrig, P.; Baayen, R.H. LDL-AURIS: A computational model, grounded in error-driven learning, for the comprehension of single spoken words. Lang. Cogn. Neurosci. 2021, 1–28. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Mesgarani, N.; Cheung, C.; Johnson, K.; Chang, E.F. Phonetic Feature Encoding in Human Superior Temporal Gyrus. Science 2014, 343, 1006–1010. [Google Scholar] [CrossRef] [Green Version]
- Bhaya-Grossman, I.; Chang, E.F. Speech Computations of the Human Superior Temporal Gyrus. Annu. Rev. Psychol. 2021, 73, 1–24. [Google Scholar] [CrossRef]
- Love, B.C. The Algorithmic Level Is the Bridge Between Computation and Brain. Top. Cogn. Sci. 2015, 7, 230–242. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Lieder, F.; Goodman, N.D. Rational use of cognitive resources: Levels of analysis between the computational and the algorithmic. Top. Cogn. Sci. 2015, 7, 217–229. [Google Scholar] [CrossRef]
- Cooper, R.P.; Peebles, D. On the Relation Between Marr’s Levels: A Response to Blokpoel. Top. Cogn. Sci. 2017, 10, 649–653. [Google Scholar] [CrossRef]
- Aertsen, A.; Johannesma, P.I. The spectro-temporal receptive field. A functional characteristic of auditory neurons. Biol. Cybern. 1981, 42, 133–143. [Google Scholar] [CrossRef]
- Hullett, P.W.; Hamilton, L.S.; Mesgarani, N.; Schreiner, C.E.; Chang, E.F. Human Superior Temporal Gyrus organization of spectrotemporal modulation tuning derived from speech stimuli. J. Neurosci. Off. J. Soc. Neurosci. 2016, 36, 2014–2026. [Google Scholar] [CrossRef]
- Chang, K.; Mitchell, T.; Just, M. Quantitative modeling of the neural representation of objects: How semantic feature norms can account for fMRI activation. Neuroimage 2011, 56, 716–727. [Google Scholar] [CrossRef]
- Joos, M. Acoustic Phonetics. Language Monograph 23; Linguistic Society of America: Baltimore, ML, USA, 1948. [Google Scholar]
- Talavage, T.; Sereno, M.; Melcher, J.; Ledden, P.; Rosen, B.; Dale, A.M. Tonotopic organization in human auditory cortex revealed by progressions of frequency sensitivity. J. Neurophysiol. 2004, 91, 1282–1296. [Google Scholar] [CrossRef] [Green Version]
- Fant, G. Speech Sounds and Features; MIT Press: Cambridge, MA, USA, 1973. [Google Scholar]
- Liberman, A.; Delattre, P.; Cooper, F.; Gerstman, L. The Role of Consonant-Vowel Transitions in the Perception of the Stop and Nasal Consonants. Psychol. Monogr. Gen. Appl. 1954, 68, 1–13. [Google Scholar] [CrossRef]
- Gordon-Salant, S. Recognition of Natural and Time/Intensity altered CVs by Young and Elderly Subjects with Normal Hearing. JASA 1986, 80, 1599–1607. [Google Scholar] [CrossRef] [Green Version]
- Davis, S.; Mermelstein, P. Comparison of Parametric Representations for Monosyllabic Word Recognition in Continuously Spoken Sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- Holmes, J.; Holmes, W. Speech Synthesis and Recognition, 2nd ed.; Taylor and Francis: London, UK; New York, NY, USA, 2002. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech and Language Processing (Online), 3rd ed.; Pearson: London, UK, 2021. [Google Scholar]
- Riad, R.; Karadayi, J.; Bachoud-Lévi, A.; Dupoux, E. Learning spectro-temporal representations of complex sounds with parameterized neural networks. J. Acoust. Soc. Am. 2021, 150, 353–366. [Google Scholar] [CrossRef]
- Connolly, J.F.; Phillips, N.A. Event-related potential components reflect phonological and semantic processing of the terminal word of spoken sentences. J. Cogn. Neurosci. 1994, 6, 256–266. [Google Scholar] [CrossRef]
- Bentum, M.; ten Bosch, L.; van den Bosch, A.; Ernestus, M. Listening with Great Expectations: An Investigation of Word Form Anticipations in Naturalistic Speech. Proc. Interspeech 2019, 2019, 2265–2269. [Google Scholar] [CrossRef] [Green Version]
- Wells, J. SAMPA computer readable phonetic alphabet. In Handbook of Standards and Resources for Spoken Language Systems; Part IV, Section B; Gibbon, D., Moore, R., Winski, R., Eds.; Mouton de Gruyter: Berlin, Germany; New York, NY, USA, 1997. [Google Scholar]
- Brown, S.; Heathcote, A. The simplest complete model of choice response time: Linear Ballistic Accumulation. Cogn. Psychol. 2008, 57, 153–178. [Google Scholar] [CrossRef]
- Noorani, I.; Carpenter, R.H. The LATER model of reaction time and decision. Neurosci. Biobehav. Rev. 2016, 64, 229–251. [Google Scholar] [CrossRef]
- Nakahara, H.; Nakamura, K.; Hikosaka, O. Extended LATER model can account for trial-by-trial variability of both pre- and post-processes. Neural Netw. 2006, 19, 1027–1046. [Google Scholar] [CrossRef]
- Salinas, E.; Scerra, V.E.; Hauser, C.K.; Costello, M.G.; Stanford, T.R. Decoupling speed and accuracy in an urgent decision-making task reveals multiple contributions to their trade-off. Front. Neurosci. 2014, 8, 85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bogacz, R.; Brown, E.; Moehlis, E.; Holmes, P.; Cohen, J.D. The physics of optimal decision making: A formal analysis of models of performance in two-alternative forced choice tasks. Psychol. Rev. 2006, 113, 700–765. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.J. Decision making in recurrent neuronal circuits. Neuron 2008, 60, 215–234. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Summerfield, C.; Blangero, A. Chapter 12 - Perceptual Decision-Making: What Do We Know, and What Do We Not Know? In Decision Neuroscience; Dreher, J.C., Tremblay, L., Eds.; Academic Press: San Diego, CA, USA, 2017; pp. 149–162. [Google Scholar] [CrossRef]
- Suri, G.; Gross, J.J.; McClelland, J.L. Value-based decision making: An interactive activation perspective. Psychol. Rev. 2020, 127, 153–185. [Google Scholar] [CrossRef]
- Lepora, N.; Pezzulo, G. Embodied Choice: How Action Influences Perceptual Decision Making. PLoS Comput. Biol. 2015, 11, e1004110. [Google Scholar] [CrossRef]
- Ernestus, M.; Cutler, A. BALDEY: A database of auditory lexical decisions. Q. J. Exp. Psychol. 2015, 68, 1469–1488. [Google Scholar] [CrossRef]
- Hick, W.E. On the Rate of Gain of Information. Q. J. Exp. Psychol. 1952, 4, 11–26. [Google Scholar] [CrossRef]
- Hyman, R. Stimulus information as a determinant of reaction time. J. Exp. Psychol. 1953, 45, 188–196. [Google Scholar] [CrossRef] [Green Version]
- Proctor, R.W.; Schneider, D.W. Hick’s law for choice reaction time: A review. Q. J. Exp. Psychol. 2018, 71, 1281–1299. [Google Scholar] [CrossRef]
- Wu, T.; Dufford, A.J.; Egan, L.J.; Mackie, M.A.; Chen, C.; Yuan, C.; Chen, C.; Li, X.; Liu, X.; Hof, P.R.; et al. Hick–Hyman Law is Mediated by the Cognitive Control Network in the Brain. Cereb. Cortex 2017, 28, 2267–2282. [Google Scholar] [CrossRef]
- Usher, M.; Olami, Z.; McClelland, J.L. Hick’s law in a stochastic race model with speed-accuracy trade-off. J. Math. Psychol. 2002, 46, 704–715. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Guise, K.G.; Liu, X.; Wang, H. Searching for the Majority: Algorithms of Voluntary Control. PLoS ONE 2008, 3, e3522. [Google Scholar] [CrossRef]
- Hawkins, G.; Brown, S.D.; Steyvers, M.; Wagenmakers, E.J. Context Effects in Multi-Alternative Decision Making: Empirical Data and a Bayesian Model. Cogn. Sci. 2012, 36, 498–516. [Google Scholar] [CrossRef] [PubMed]
- Miller, E.K.; Cohen, J.D. An Integrative Theory of Prefrontal Cortex Function. Annu. Rev. Neurosci. 2001, 24, 167–202. [Google Scholar] [CrossRef] [Green Version]
- Fan, J. An information theory account of cognitive control. Front. Hum. Neurosci. 2014, 8, 680. [Google Scholar] [CrossRef] [Green Version]
- Harding, I.H.; Yücel, M.; Harrison, B.J.; Pantelis, C.; Breakspear, M. Effective connectivity within the frontoparietal control network differentiates cognitive control and working memory. NeuroImage 2015, 106, 144–153. [Google Scholar] [CrossRef] [PubMed]
- Fedorenko, E.; Duncan, J.; Kanwisher, N. Broad domain generality in focal regions of frontal and parietal cortex. Proc. Natl. Acad. Sci. USA 2013, 110, 16616–16621. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Niendam, T.; Laird, A.; Ray, K.; Dean, Y.; Glahn, D.; Carter, C. Meta-analytic evidence for a superordinate cognitive control network subserving diverse executive functions. Cogn. Affect. Behav. Neurosci. 2012, 12, 241–268. [Google Scholar] [CrossRef]
- Cocchi, L.; Zalesky, A.; Fornito, A.; Mattingley, J. Dynamic cooperation and competition between brain systems during cognitive control. Trends Cogn. Sci. 2013, 17, 493–501. [Google Scholar] [CrossRef]
- Gahl, S. “Thyme” and “time” are not homophones. The effect of lemma frequency on word durations in spontaneous speech. Languge 2008, 84, 474–496. [Google Scholar] [CrossRef]
- Hawkins, S. Roles and representations of systematic fine phonetic detail in speech understanding. J. Phon. 2003, 31, 373–405. [Google Scholar] [CrossRef]
- Balling, L.W.; Baayen, R.H. Probability and surprisal in auditory comprehension of morphologically complex words. Cognition 2012, 125, 80–106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bybee, J.L. Morphology as lexical organization. Theor. Morphol. 1988, 1988, 119141. [Google Scholar]
- Dilkina, K.; McClelland, J.L.; Plaut, D.C. Are there mental lexicons? The role of semantics in lexical decision. Brain Res. 2010, 1365, 66–81. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Li, J.; Wang, X.; Li, Y. The Speechtransformer for Large-scale Mandarin Chinese Speech Recognition. In Proceedings of the ICASSP 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 7095–7099. [Google Scholar] [CrossRef]
- Dijkstra, T. The Multilingual Lexicon In Handbook of Psycholinguistics; Oxford University Press: Oxford, UK, 2007; pp. 251–265. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM Neural Networks for Language Modeling. Proc. Interspeech 2012, 2012, 1–4. [Google Scholar] [CrossRef]
- Chen, D.; Manning, C. A fast and accurate dependency parser using neural networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 74–750. [Google Scholar]
- Merkx, D.; Frank, S.L.; Ernestus, M. Language learning using speech to image retrieval. Proc. Interspeech 2019, 2019, 1841–1845. [Google Scholar]
- Tsuji, S.; Cristia, A.; Dupoux, E. SCALa: A blueprint for computational models of language acquisition in social context. Cognition 2021, 213, 104779. [Google Scholar] [CrossRef]
- Boves, L.; ten Bosch, L.; Moore, R.K. ACORNS-towards computational modeling of communication and recognition skills. In Proceedings of the Sixth IEEE International Conference on Cognitive Informatics, Lake Tahoe, CA, USA, 6–8 August 2007; pp. 349–356. [Google Scholar] [CrossRef]
- Driesen, J.; Van hamme, H. Modelling vocabulary acquisition, adaptation and generalization in infants using adaptive Bayesian PLSA. Neurocomputing 2011, 74, 1874–1882. [Google Scholar] [CrossRef] [Green Version]
- Romberg, A.; Saffran, J. Statistical learning and language acquisition. Wiley Interdiscip. Rev. Cogn. Sci. 2010, 1, 906–914. [Google Scholar] [CrossRef]
- McMurray, B.; Horst, J.; Samuelson, L. Word learning emerges from the interaction of online referent selection and slow associative learning. Psychol. Rev. 2012, 119, 831–877. [Google Scholar] [CrossRef] [Green Version]
- Smith, L.; Yu, C. Infants rapidly learn word-referent mappings via cross-situational statistics. Cognition 2008, 106, 1558–1568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Räsänen, O.; Rasilo, H. A joint model of word segmentation and meaning acquisition through cross-situational learning. Psychol. Rev. 2015, 122, 792. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Räsänen, O.; Doyle, G.; Frank, M.C. Pre-linguistic segmentation of speech into syllable-like units. Cognition 2018, 171, 130–150. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dupoux, E. Category Learning in Songbirds: Top-down effects are not unique to humans. Curr. Biol. 2015, 25, R718–R720. [Google Scholar] [CrossRef] [Green Version]
- Young, S.; Evermann, G.; Gales, M.; Hain, T.; Kershaw, D.; Liu, X.A.; Moore, G.; Odell, J.; Ollason, D.; Povey, D.; et al. The HTK Book (for HTK Version 3.4); Technical Report; Cambridge University Engineering Department: Cambridge, UK, 2009. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, Waikoloa, HI, USA, 11–15 December 2011. IEEE Catalog No.: CFP11SRW-USB. [Google Scholar]
- Scharenborg, O.; Norris, D.; ten Bosch, L.; McQueen, J. How should a speech recognizer work? Cogn. Sci. 2005, 29, 867–918. [Google Scholar] [CrossRef] [Green Version]
- Nenadić, F.; Tucker, B.V. Computational modelling of an auditory lexical decision experiment using jTRACE and TISK. Lang. Cogn. Neurosci. 2020, 35, 1326–1354. [Google Scholar] [CrossRef]
- Wessel, F.; Schlüter, R.; Macherey, K.; Ney, H. Confidence Measures for Large Vocabulary Continuous Speech Recognition. IEEE Trans. Speech Audio Process. 2001, 9, 288–298. [Google Scholar] [CrossRef] [Green Version]
- Oneata, D.; Caranica, A.; Stan, A.; Cucu, H. An evaluation of word-level confidence estimation for end-to-end automatic speech recognition. arXiv 2021, arXiv:2101.05525. [Google Scholar]
- Baayen, H.R.; Milin, P. Analyzing reaction times. Int. J. Psychol. Res. 2010, 3, 12–28. [Google Scholar] [CrossRef]
- Wagenmakers, E.J.; Lodewyckx, T.; Kuriyal, H.; Grasman, R. Bayesian hypothesis testing for psychologists: A tutorial on the Savage-Dickey method. Cogn. Psychol. 2010, 60, 158–189. [Google Scholar] [CrossRef] [Green Version]
- Ten Bosch, L.; Boves, L.; Mulder, K. Analyzing reaction time and error sequences in lexical decision experiments. Proc. Interspeech 2019, 2019, 2280–2284. [Google Scholar]
- Tucker, B.V.; Brenner, D.; Danielson, D.K.; Kelley, M.C.; Nenadić, F.; Sims, M. The Massive Auditory Lexical Decision (MALD) database. Behav. Res. Methods 2019, 51, 1187–1204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013. [Google Scholar]
- Brand, S.; Mulder, K.; ten Bosch, L.; Boves, L. Models of Reaction Times in Auditory Lexical Decision: RTonset versus RToffset. Proc. Interspeech 2021, 2021, 541–545. [Google Scholar] [CrossRef]
- Matuschek, H.; Kliegl, R.; Vasishth, S.; Baayen, H.; Bates, D. Balancing Type I error and power in linear mixed models. J. Mem. Lang. 2017, 94, 305–315. [Google Scholar] [CrossRef]
- Meteyard, L.; Davies, R.A. Best practice guidance for linear mixed-effects models in psychological science. J. Mem. Lang. 2020, 112, 104092. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
ten Bosch, L.; Boves, L.; Ernestus, M. DIANA, a Process-Oriented Model of Human Auditory Word Recognition. Brain Sci. 2022, 12, 681. https://doi.org/10.3390/brainsci12050681
ten Bosch L, Boves L, Ernestus M. DIANA, a Process-Oriented Model of Human Auditory Word Recognition. Brain Sciences. 2022; 12(5):681. https://doi.org/10.3390/brainsci12050681
Chicago/Turabian Styleten Bosch, Louis, Lou Boves, and Mirjam Ernestus. 2022. "DIANA, a Process-Oriented Model of Human Auditory Word Recognition" Brain Sciences 12, no. 5: 681. https://doi.org/10.3390/brainsci12050681
APA Styleten Bosch, L., Boves, L., & Ernestus, M. (2022). DIANA, a Process-Oriented Model of Human Auditory Word Recognition. Brain Sciences, 12(5), 681. https://doi.org/10.3390/brainsci12050681